Attention mechanism
In the "encoder decoder (seq2seq)" section, the decoder relies on the same context vector to obtain the input sequence information in each time step. When the encoder is a cyclic neural network, the background variable is used to detect the hidden state of its final time step. The source sequence input information is encoded in a cyclic unit state and then passed to the decoder to generate the target sequence. However, there are some problems with this structure, especially the problem of long-range gradient disappearing in RNN mechanism. For long sentences, it is very difficult for us to hope to save all the effective information by transforming the input sequence into a fixed length vector. Therefore, with the increase of the length of the required translation sentence, the effect of this structure will decline significantly.
At the same time, the decoded target words may only be related to part of the original input words, not all the input words. For example, when "Hello world" is translated into "Bonjour Le Monte," hello "is mapped to" Bonjour "and" world "to" Monte ". In the seq2seq model, the decoder can only implicitly select the corresponding information from the final state of the encoder. However, attention mechanism can explicitly model the selection process.
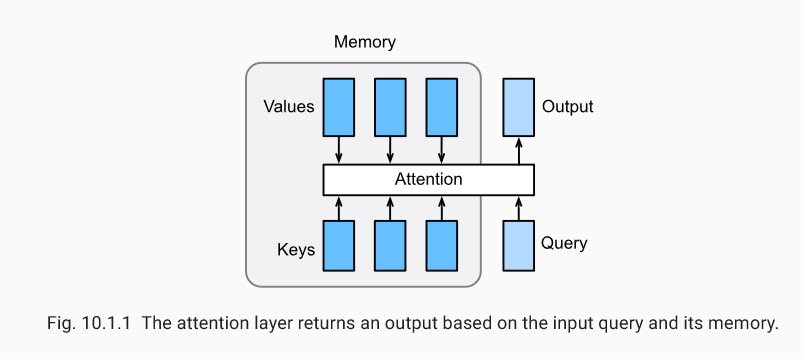
Attention mechanism framework
To calculate the output, we first assume that there is a function α \ alpha α used to calculate the similarity between query and key, and then we can calculate all the attention scores a1 ,ana_1, \ldots, a_na1,… an by
ai=α(q,ki). a_i = \alpha(\mathbf q, \mathbf k_i). ai=α(q,ki).
We use the softmax function to get the attention weight:
b1,...,bn=softmax(a1,...,an). b_1, \ldots, b_n = \textrm{softmax}(a_1, \ldots, a_n). b1,...,bn=softmax(a1,...,an).
The final output is the weighted sum of value s:
o=∑i=1nbivi. \mathbf o = \sum_{i=1}^n b_i \mathbf v_i. o=i=1∑nbivi.
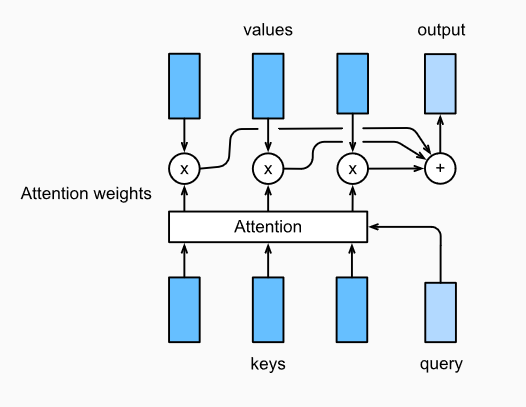
The difference between different attention layers lies in the choice of score function. In the rest of this section, we will discuss two commonly used attention layers, dot product attention and Multilayer Perceptron Attention. Then we will implement a seq2seq model with attention and train and test it on English French translation corpus.
import math import torch import torch.nn as nn
import os def file_name_walk(file_dir): for root, dirs, files in os.walk(file_dir): # print("root", root) # Current directory path print("dirs", dirs) # All subdirectories under the current path print("files", files) # All non directory sub files under the current path file_name_walk("/home/kesci/input/fraeng6506")
Softmax shield
Before we go into the implementation, we first introduce a mask operation of softmax operator.
def SequenceMask(X, X_len,value=-1e6): maxlen = X.size(1) #print(X.size(),torch.arange((maxlen),dtype=torch.float)[None, :],'\n',X_len[:, None] ) mask = torch.arange((maxlen),dtype=torch.float)[None, :] >= X_len[:, None] #print(mask) X[mask]=value return X
def masked_softmax(X, valid_length): # X: 3-D tensor, valid_length: 1-D or 2-D tensor softmax = nn.Softmax(dim=-1) if valid_length is None: return softmax(X) else: shape = X.shape if valid_length.dim() == 1: try: valid_length = torch.FloatTensor(valid_length.numpy().repeat(shape[1], axis=0))#[2,2,3,3] except: valid_length = torch.FloatTensor(valid_length.cpu().numpy().repeat(shape[1], axis=0))#[2,2,3,3] else: valid_length = valid_length.reshape((-1,)) # fill masked elements with a large negative, whose exp is 0 X = SequenceMask(X.reshape((-1, shape[-1])), valid_length) return softmax(X).reshape(shape)
masked_softmax(torch.rand((2,2,4),dtype=torch.float), torch.FloatTensor([2,3]))
Multiplication beyond 2-dimensional matrix
XXX and YYY are tensors with dimensions of (b,n,m)(b,n,m)(b,n,m) and (b,m,k)(b, m, k)(b,m,k), respectively. After two-dimensional matrix multiplication of bbb, ZZZ is obtained, with dimensions of (b,n,k)(b, n, k)(b,n,k).
Z[i,:,:]=dot(X[i,:,:],Y[i,:,:])for i=1,...,n . Z[i,:,:] = dot(X[i,:,:], Y[i,:,:])\qquad for\ i= 1,...,n\ . Z[i,:,:]=dot(X[i,:,:],Y[i,:,:])for i=1,...,n .
torch.bmm(torch.ones((2,1,3), dtype = torch.float), torch.ones((2,3,2), dtype = torch.float))
# Save to the d2l package. class DotProductAttention(nn.Module): def __init__(self, dropout, **kwargs): super(DotProductAttention, self).__init__(**kwargs) self.dropout = nn.Dropout(dropout) # query: (batch_size, #queries, d) # key: (batch_size, #kv_pairs, d) # value: (batch_size, #kv_pairs, dim_v) # valid_length: either (batch_size, ) or (batch_size, xx) def forward(self, query, key, value, valid_length=None): d = query.shape[-1] # set transpose_b=True to swap the last two dimensions of key scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d) attention_weights = self.dropout(masked_softmax(scores, valid_length)) print("attention_weight\n",attention_weights) return torch.bmm(attention_weights, value)
test
Now we have created two batches, each with a query and 10 key values pairs. We specify by valid [length], for the first batch, we only focus on the first two key value pairs, while for the second batch, we will check the first six key value pairs. Therefore, although the two batches have the same query and key value pair, the output we get is different.
atten = DotProductAttention(dropout=0) keys = torch.ones((2,10,2),dtype=torch.float) values = torch.arange((40), dtype=torch.float).view(1,10,4).repeat(2,1,1) atten(torch.ones((2,1,2),dtype=torch.float), keys, values, torch.FloatTensor([2, 6]))
Attention of multi-layer perceptron
The key and value are combined on the feature dimension (concatenate), and then sent to a single hidden layer perceptron. The size of hidden layer is ℎ and the output is 1. The activation function of hidden layer is tanh, no bias
# Save to the d2l package. class MLPAttention(nn.Module): def __init__(self, units,ipt_dim,dropout, **kwargs): super(MLPAttention, self).__init__(**kwargs) # Use flatten=True to keep query's and key's 3-D shapes. self.W_k = nn.Linear(ipt_dim, units, bias=False) self.W_q = nn.Linear(ipt_dim, units, bias=False) self.v = nn.Linear(units, 1, bias=False) self.dropout = nn.Dropout(dropout) def forward(self, query, key, value, valid_length): query, key = self.W_k(query), self.W_q(key) #print("size",query.size(),key.size()) # expand query to (batch_size, #querys, 1, units), and key to # (batch_size, 1, #kv_pairs, units). Then plus them with broadcast. features = query.unsqueeze(2) + key.unsqueeze(1) #print("features:",features.size()) #--------------On scores = self.v(features).squeeze(-1) attention_weights = self.dropout(masked_softmax(scores, valid_length)) return torch.bmm(attention_weights, value)
test
Although MLPAttention contains an additional MLP model, given the same input and the same key, we will get the same output as DotProductAttention
atten = MLPAttention(ipt_dim=2,units = 8, dropout=0) atten(torch.ones((2,1,2), dtype = torch.float), keys, values, torch.FloatTensor([2, 6]))
summary
- The attention level explicitly selects relevant information.
- Note that the memory of the layer consists of key value pairs, so its output is close to the value of the key similar to the query.
Seq2seq model with attention mechanism
In this section, the attention mechanism is added to the sequence to sequence model to explicitly aggregate states using weights. The following figure shows the model structure of encoding and decoding, when the time step is t. At the moment, the attention layer holds all the information that encoding sees - the output of each step of encoding. In the coding stage, the hidden state of ttt time of decoder is regarded as query, and the hidden states of each time step of encoder are regarded as key and value to aggregate attention. The output of attention model is regarded as context vector, and is spliced with the input DTD ﹣ TDT of decoder and sent to decoder:
The second step of decoding the seq − to − seq model with attention mechanism in Fig1 The second step of decoding Fig1's SEQ to SEQ model with attention mechanism The second step of decoding the seq − to − seq model with attention mechanism in Fig1
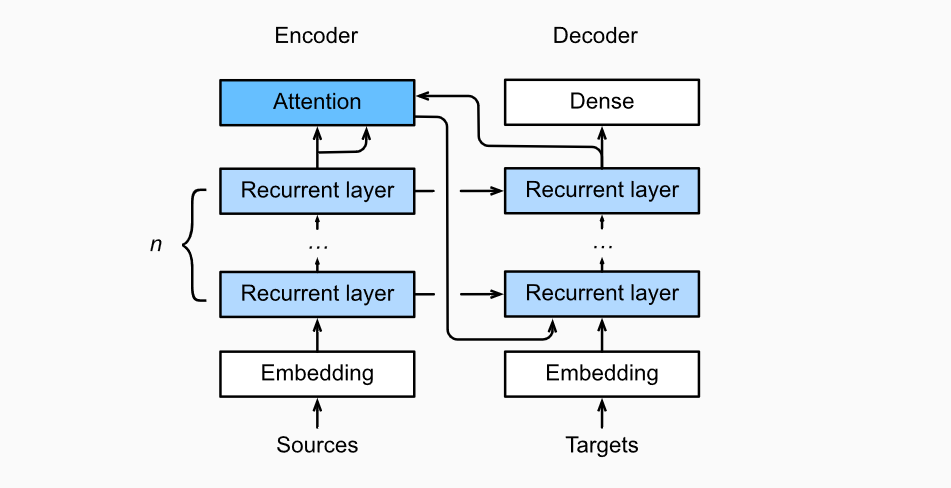
The following figure shows the relationship between all layers of seq2seq mechanism, and the layer structure of encoder and decoder

Fig2 middle layer structure of seq to seq model with attention mechanism Fig2 middle layer structure of SEQ to SEQ model with attention mechanism Fig2 middle layer structure of seq to seq model with attention mechanism
import sys sys.path.append('/home/kesci/input/d2len9900') import d2l
Decoder
Since the encoder of seq2seq with attention mechanism is the same as Seq2SeqEncoder in the previous chapter, we only focus on the decoder here. We added an MLP attention layer (MLPAttention), which has the same hidden size as the LSTM layer in the decoder. Then we initialize the state of the decoder by passing three parameters from the encoder:
-
the encoder outputs of all timesteps: each state of the encoder output is used in the memory part of the attachment layer, with the same key and values
-
the hidden state of the encoder's final timestep: the hidden state of the last time step of the encoder, which is used to initialize the decoder's hidden state
-
the encoder valid length: the effective length of the encoder, by which the layer will not consider the padding in the encoder output
At each time step of decoding, we use the output of the last RNN layer of the decoder as the query of the attention layer. Then, the output of the attention model is connected with the input embedding vector and input to the RNN layer. Although the hidden state of RNN layer also contains the historical information from decoder, the output of attention model explicitly selects the encoder output within enc_valid_len, so that the attention mechanism will exclude other irrelevant information as much as possible.
class Seq2SeqAttentionDecoder(d2l.Decoder): def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs): super(Seq2SeqAttentionDecoder, self).__init__(**kwargs) self.attention_cell = MLPAttention(num_hiddens,num_hiddens, dropout) self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = nn.LSTM(embed_size+ num_hiddens,num_hiddens, num_layers, dropout=dropout) self.dense = nn.Linear(num_hiddens,vocab_size) def init_state(self, enc_outputs, enc_valid_len, *args): outputs, hidden_state = enc_outputs # print("first:",outputs.size(),hidden_state[0].size(),hidden_state[1].size()) # Transpose outputs to (batch_size, seq_len, hidden_size) return (outputs.permute(1,0,-1), hidden_state, enc_valid_len) #outputs.swapaxes(0, 1) def forward(self, X, state): enc_outputs, hidden_state, enc_valid_len = state #("X.size",X.size()) X = self.embedding(X).transpose(0,1) # print("Xembeding.size2",X.size()) outputs = [] for l, x in enumerate(X): # print(f"\n{l}-th token") # print("x.first.size()",x.size()) # query shape: (batch_size, 1, hidden_size) # select hidden state of the last rnn layer as query query = hidden_state[0][-1].unsqueeze(1) # np.expand_dims(hidden_state[0][-1], axis=1) # context has same shape as query # print("query enc_outputs, enc_outputs:\n",query.size(), enc_outputs.size(), enc_outputs.size()) context = self.attention_cell(query, enc_outputs, enc_outputs, enc_valid_len) # Concatenate on the feature dimension # print("context.size:",context.size()) x = torch.cat((context, x.unsqueeze(1)), dim=-1) # Reshape x to (1, batch_size, embed_size+hidden_size) # print("rnn",x.size(), len(hidden_state)) out, hidden_state = self.rnn(x.transpose(0,1), hidden_state) outputs.append(out) outputs = self.dense(torch.cat(outputs, dim=0)) return outputs.transpose(0, 1), [enc_outputs, hidden_state, enc_valid_len]
Now we can use the attention model to test seq2seq. In order to be consistent with the model in section 9.7, we use the same super parameters for vocab? Size, embedded? Size, Num? Hiddens, and num? Layers. As a result, we get the same decoder output shape, but the state structure changes.
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2) # encoder.initialize() decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2) X = torch.zeros((4, 7),dtype=torch.long) print("batch size=4\nseq_length=7\nhidden dim=16\nnum_layers=2\n") print('encoder output size:', encoder(X)[0].size()) print('encoder hidden size:', encoder(X)[1][0].size()) print('encoder memory size:', encoder(X)[1][1].size()) state = decoder.init_state(encoder(X), None) out, state = decoder(X, state) out.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape
train
Similar to section 9.7.4, a simple entertainment model is tried by applying the same training super parameters and the same training loss. From the results, we can see that the additional attention layer does not bring significant improvement because of the relatively short sequence in the training data set. Due to the computational overhead of the attention layer of the encoder and decoder, this model is much slower than the seq2seq model without attention.
import zipfile import torch import requests from io import BytesIO from torch.utils import data import sys import collections class Vocab(object): # This class is saved in d2l. def __init__(self, tokens, min_freq=0, use_special_tokens=False): # sort by frequency and token counter = collections.Counter(tokens) token_freqs = sorted(counter.items(), key=lambda x: x[0]) token_freqs.sort(key=lambda x: x[1], reverse=True) if use_special_tokens: # padding, begin of sentence, end of sentence, unknown self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3) tokens = ['', '', '', ''] else: self.unk = 0 tokens = [''] tokens += [token for token, freq in token_freqs if freq >= min_freq] self.idx_to_token = [] self.token_to_idx = dict() for token in tokens: self.idx_to_token.append(token) self.token_to_idx[token] = len(self.idx_to_token) - 1 def __len__(self): return len(self.idx_to_token) def __getitem__(self, tokens): if not isinstance(tokens, (list, tuple)): return self.token_to_idx.get(tokens, self.unk) else: return [self.__getitem__(token) for token in tokens] def to_tokens(self, indices): if not isinstance(indices, (list, tuple)): return self.idx_to_token[indices] else: return [self.idx_to_token[index] for index in indices] def load_data_nmt(batch_size, max_len, num_examples=1000): """Download an NMT dataset, return its vocabulary and data iterator.""" # Download and preprocess def preprocess_raw(text): text = text.replace('\u202f', ' ').replace('\xa0', ' ') out = '' for i, char in enumerate(text.lower()): if char in (',', '!', '.') and text[i-1] != ' ': out += ' ' out += char return out with open('/home/kesci/input/fraeng6506/fra.txt', 'r') as f: raw_text = f.read() text = preprocess_raw(raw_text) # Tokenize source, target = [], [] for i, line in enumerate(text.split('\n')): if i >= num_examples: break parts = line.split('\t') if len(parts) >= 2: source.append(parts[0].split(' ')) target.append(parts[1].split(' ')) # Build vocab def build_vocab(tokens): tokens = [token for line in tokens for token in line] return Vocab(tokens, min_freq=3, use_special_tokens=True) src_vocab, tgt_vocab = build_vocab(source), build_vocab(target) # Convert to index arrays def pad(line, max_len, padding_token): if len(line) > max_len: return line[:max_len] return line + [padding_token] * (max_len - len(line)) def build_array(lines, vocab, max_len, is_source): lines = [vocab[line] for line in lines] if not is_source: lines = [[vocab.bos] + line + [vocab.eos] for line in lines] array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines]) valid_len = (array != vocab.pad).sum(1) return array, valid_len src_vocab, tgt_vocab = build_vocab(source), build_vocab(target) src_array, src_valid_len = build_array(source, src_vocab, max_len, True) tgt_array, tgt_valid_len = build_array(target, tgt_vocab, max_len, False) train_data = data.TensorDataset(src_array, src_valid_len, tgt_array, tgt_valid_len) train_iter = data.DataLoader(train_data, batch_size, shuffle=True) return src_vocab, tgt_vocab, train_iter
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.0 batch_size, num_steps = 64, 10 lr, num_epochs, ctx = 0.005, 500, d2l.try_gpu() src_vocab, tgt_vocab, train_iter = load_data_nmt(batch_size, num_steps) encoder = d2l.Seq2SeqEncoder( len(src_vocab), embed_size, num_hiddens, num_layers, dropout) decoder = Seq2SeqAttentionDecoder( len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout) model = d2l.EncoderDecoder(encoder, decoder)
Training and forecasting
d2l.train_s2s_ch9(model, train_iter, lr, num_epochs, ctx)
for sentence in ['Go .', 'Good Night !', "I'm OK .", 'I won !']: print(sentence + ' => ' + d2l.predict_s2s_ch9( model, sentence, src_vocab, tgt_vocab, num_steps, ctx))

