In today's society, every family basically has a car. They basically go to the car home to check the detailed parameters of the car (css anti climbing, which will be introduced in the next article), go to the car home forum to express some opinions or look at other people's opinions (font anti climbing), So let's take a look at the font anti crawling of Auto Home Forum today. What's strange (auto home was the first to use font anti crawling on the website)
- Determine the page to crawl
Stop at high speed to pick wild fruits, and the traffic police of Lu'an Expressway quickly investigate and eliminate hidden dangers
- Since we are sure that the font is anti crawling, let's find the font file directly
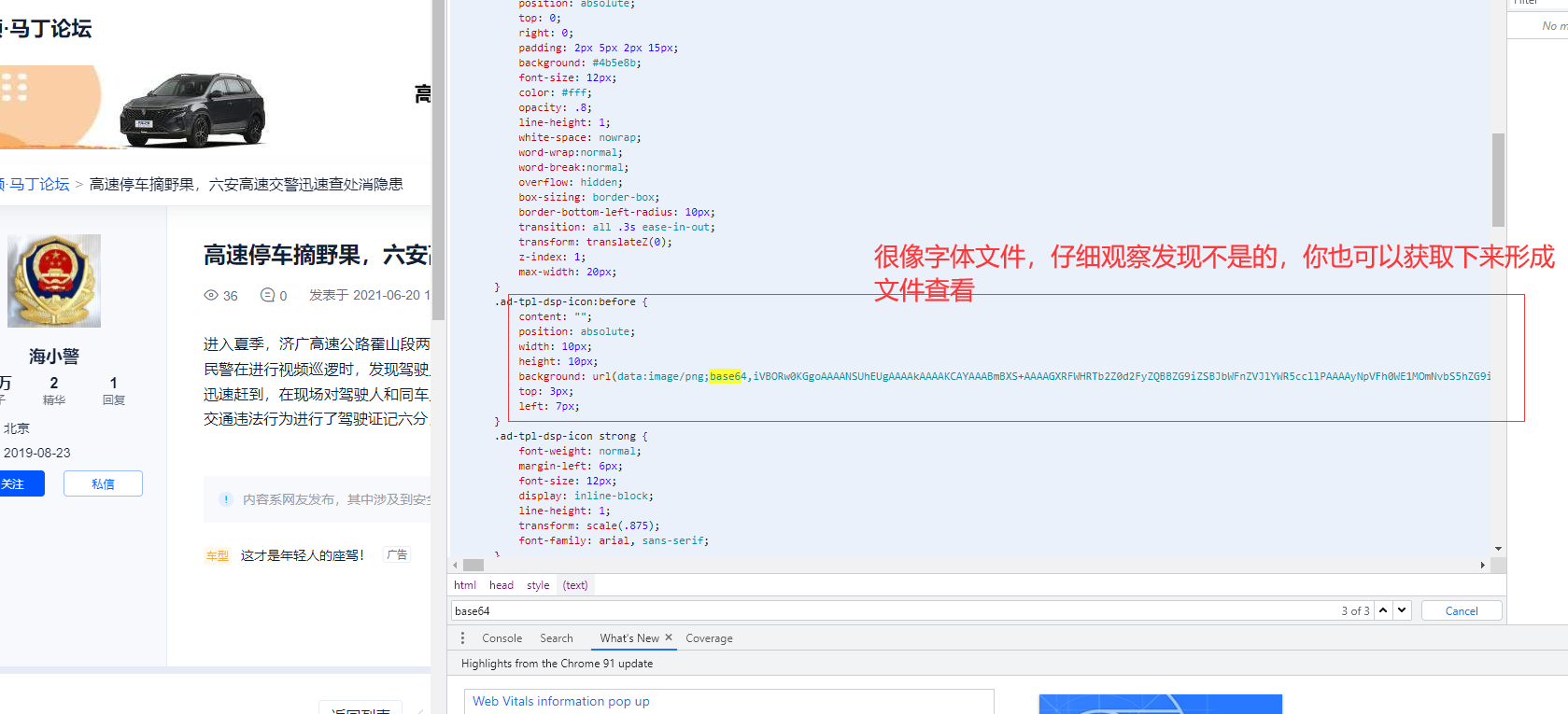
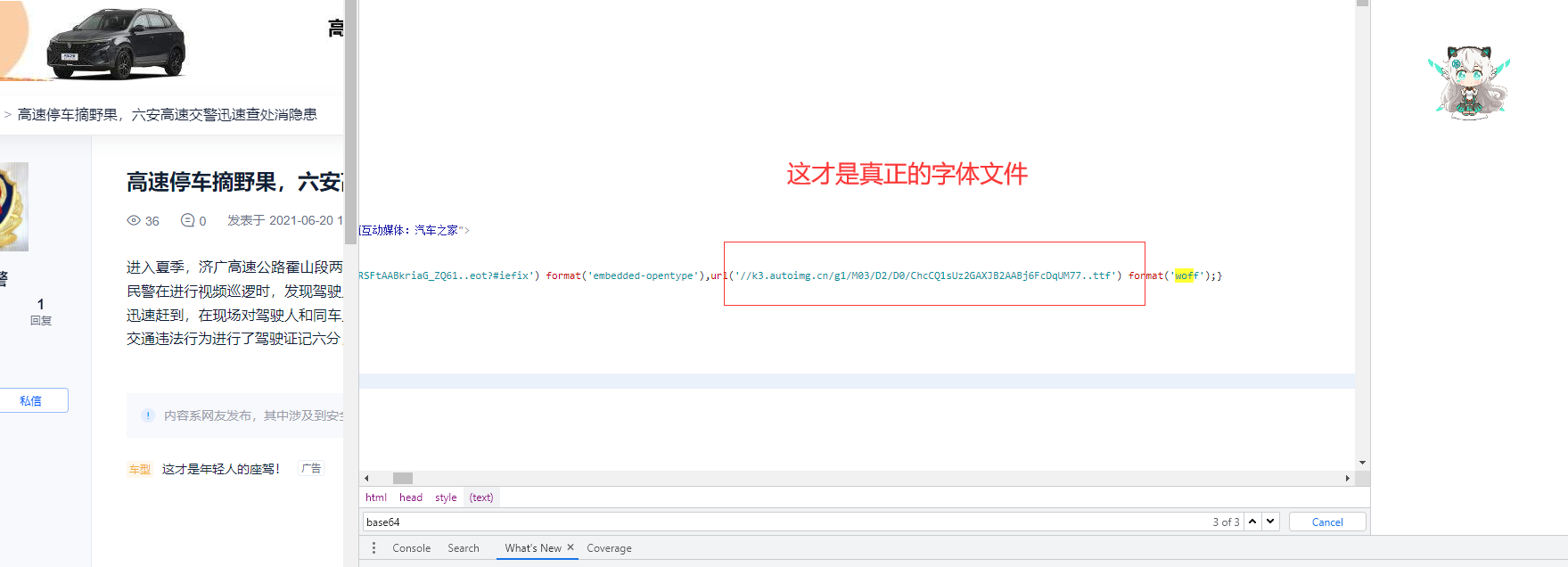
- The normal idea is to download the font file for viewing

The text in each requested font file is the same, in different order, and the name value corresponding to the text is also different. You can know that it is a dynamic font - According to the normal idea, it is necessary to analyze the similarities of the same different font files, but it can't be like this for this website. It is a bug (in fact, it's just a small problem, which will be told later)
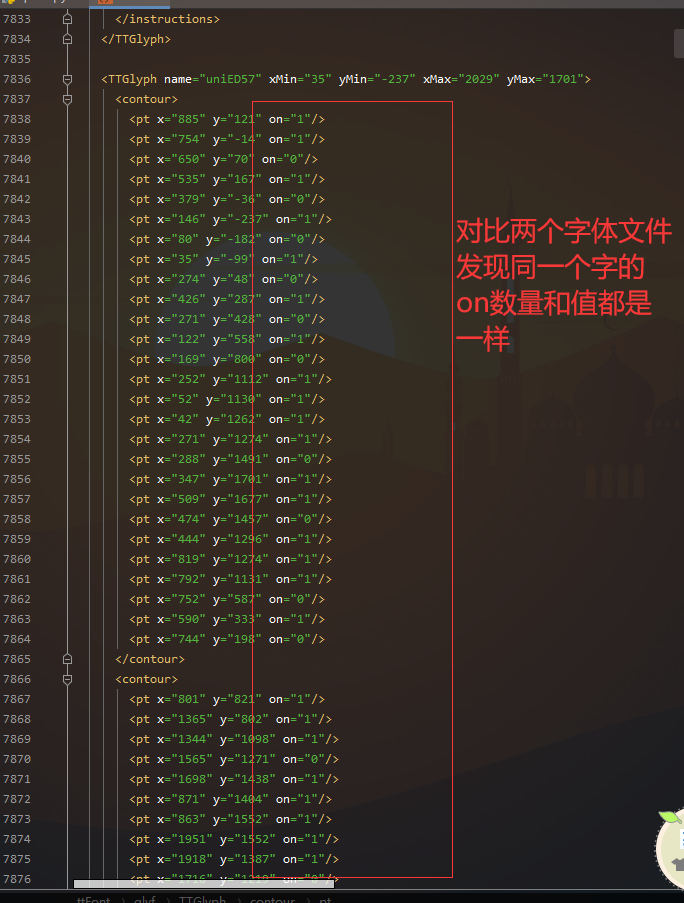
- We make a correspondence between the on value of a font file (I am all right. The obtained on value is encrypted with md5) and the text
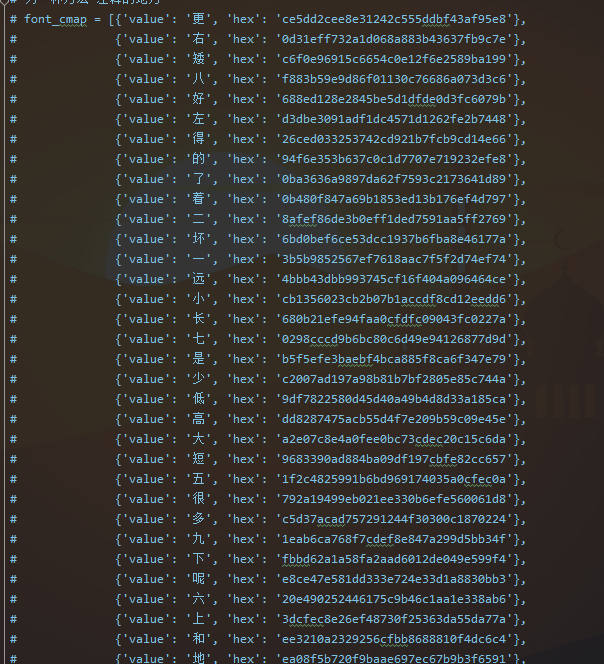
Then, each time a request is made, the on value of each word in the new font file and the dictionary constructed by yourself are used to find it, and then they are replaced in the web page - At this time, the pit comes. Most fonts can be replaced. When the three words, up, 10, and 3, appear in the encrypted data of a web page at the same time, I now replace these three words with one of them. Then I check the font and the encrypted data, and find that the font of these three words is the same, and other words are replaced normally, After thinking for a while, I came up with an opportunistic method, that is to delete 2 characters from the back of the font of the last two words, and 4 characters are md5 encrypted, which is different (too clever, hahaha). After some operations, I successfully replaced it, and I changed several web pages to test it, which can be replaced successfully (this is an evil and evil way, or go the right way)
- Then I studied the font file, and finally I found it
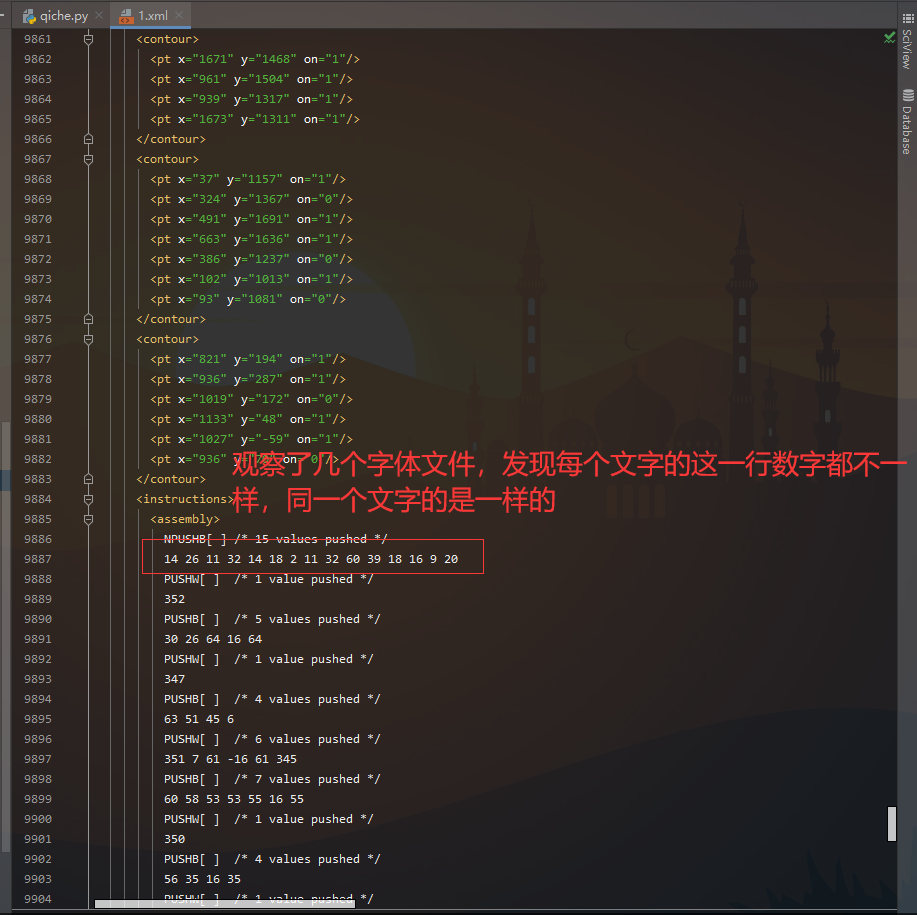
In this way, you can replace the corresponding relationship
The code is as follows (I won't let go of evil and evil, but it's better to be sunny and upright, hahaha) let's have a key three times for the students we like
from hashlib import md5
from lxml import etree
import requests
import base64
import re
from fontTools.ttLib import TTFont
# url = 'https://club.autohome.com.cn/bbs/thread/fa46ecd8093668f7/96974096-1.html#pvareaid=6830286'
url = 'https://club.autohome.com.cn/bbs/thread/5a9162acffa561c0/96605902-1.html#pvareaid=6830286'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"
}
ret = requests.get(url=url, headers=headers).text
# print(ret)
with open('qc.html', 'w', encoding='utf8') as f:
f.write(ret)
with open('qc.html', 'r', encoding='utf8') as f:
ret = f.read()
font_url = re.findall("format\('embedded-opentype'\),url\('(.*?)'\) format\('woff'\)", ret)[0]
cont = requests.get(url='http:' + font_url).content
with open('1.woff', 'wb') as f:
f.write(cont)
font = TTFont('1.woff')
font.saveXML('1.xml')
uni_list = font.getGlyphOrder()[1:]
with open('1.xml', 'r', encoding='utf8') as f:
ans = f.read().replace('\n', '').replace(' ', '')
font_dict = {'2ee6282ddbee9f53de340fb93a156da1': 'bad', '5de9503e9e8fb0b817c0e8046f68ea06': 'less',
'b85e1e0e4e0a3da21c7688d3734fbff4': 'long', '7f6ffaa6bb0b408017b62254211691b5': 'and',
'd93d9c5cd0b124fe9a149e024230aedc': 'three', 'a2044e0a05697a397d218ff3c7d58b14': 'land',
'284956d829845ea88648224b413ecfef': 'have to', '99b43a161e1b91fe521f4a956d0e461b': 'And',
'96b244bd16f9e9b680668740b5f05f58': 'yes', '352a3fb74479f898abed255da7874f08': 'eight',
'34145f477f06b62717bd3b9e550f2f59': 'one', '8420d359404024567b5aefda1231af24': 'right',
'17bd84e98cb7dac55b8235e17f39e0c1': 'good', '7bb21f3c5f26aa3004e7858c1708a171': 'means',
'84f04ce0e18cd521b3e4cc4d583c3804': 'Yes', '70dc463ea84ed61832aad4be801dc590': 'five',
'cbe2b18c050de78223be644f1cbdf3e9': 'large', '2dd8c79d2fa42c863c906142393b5672': 'lower',
'739602f7c6011723ad000dc75a020d81': 'near', '8602f737ddba61fa08d59db4a9ac304e': 'ten',
'56b5240074776d63a3157985164e1347': 'four', '2013ad23b3c0e210a3c06a6f0b32d7ff': 'very',
'fe306921fac2991ddeebc24f11083ccd': 'Left', 'f4e14bd8b0f0f4ac2b5b626868b46c0c': 'short',
'0f1ed2182ab8a1d32ee53de13778dedb': 'short', 'd1375517bb56ee0a6670ead7ee1b09fc': 'nine',
'afac95ed683c255be0fb579dcc286a97': 'far', 'cb35257195916c3eec46c5a8fd331d5d': 'many',
'618ad2ac1054473d4c77a483d65fee64': 'low', '4f36bcfc60dc716bd3434d9c36762a27': 'Small',
'e644a5af2b0b0834f14f1a0d2dfdd728': 'seven', 'b0169350cd35566c47ba83c6ec1d6f82': 'six',
'ca4de99bb59a97972fbc21b6d886e83a': 'upper', '70c480369c5a95ee190c178729322738': 'no',
'2421fcb1263b9530df88f7f002e78ea5': 'high', 'd2b80d6d0aa059da6f71b58592c1c7b5': 'of',
'1d6f9e61e720fca9598bd3099739c37a': 'more', 'e79c567ac2f3aa160297a5580ff96cbd': 'two'}
k = {}
for i, uni in enumerate(uni_list):
ev = eval("'\\u" + uni[3:] + "'").encode("utf-8")
name, nub = re.findall(f'<TTGlyphname="({uni})"xMin=.*?valuespushed\*/(\d+)', ans)[0]
md = md5(nub.encode('utf8')).hexdigest()
tex = tex.replace(ev, font_dict[md].encode('utf8'))
print(tex.decode('utf8'))