This article uses simple Python crawler, email sending and scheduled tasks to realize the function of sending bedtime stories regularly every day. It is an article with detailed steps. After testing, the program can still run normally.
Recently, a cute asked me to tell her a little story before going to bed every night after I was busy. I thought, there should be various resources on the Internet, and small stories can be found, but the number is relatively small, and the format is not unified enough, so it is difficult to extract. On second thought, bedtime stories for children may also be more applicable, so I'm going to draw materials from children's bedtime stories
There are 700 stories in total. Well, one story a day can meet the number, and the html format is relatively unified, so it's decided to be it! In addition, note: no matter whether you are for Python employment or hobbies, remember: project development experience is always the core. If you lack new project practice or do not have Python intensive tutorial, you can [forward this article + pay attention, private mail me 'p' to get it automatically], and you can also communicate with old drivers for advice!
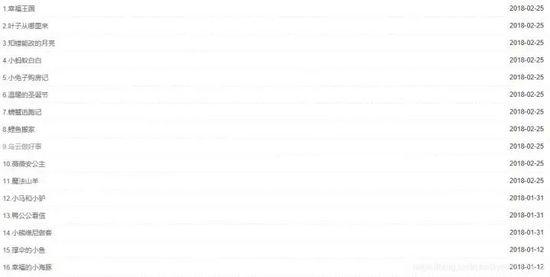
View the web page source code, enter the query keyword happiness kingdom with ctrl+F, and locate the relevant information:

Find the href attribute in the a tag of the dl tag that contains the story link. The next step is to extract the link:
Simulate the browser to visit the web page and use the requests library to request access
Code implementation:
def getHTMLText(url,headers): try: r=requests.get(url,headers=headers,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "Crawl failed"
Simply use the beautiful soup library to parse html pages
After finding the content of dl tag, find the content in a tag and splice the extracted link with the original page header:
def parsehtml(namelist,urllist,html): url='http://www.tom61.com/' soup=BeautifulSoup(html,'html.parser') t=soup.find('dl',attrs={'class':'txt_box'})
i=t.find_all('a')
for link in i:
urllist.append(url+link.get('href')) namelist.append(link.get('title'))
After getting the link addresses of all web pages, visit the web page
View web page source code

story
Re analyze the page and extract the contents of all p tags
Since str type string is required below, it is used The join method splits the text list with a newline character
def parsehtml2(html):
text=[]
soup=BeautifulSoup(html,'html.parser') t=soup.find('div',class_='t_news_txt')
for i in t.findAll('p'):
text.append(i.text)
#print(text)
return "\n".join(text)
Send crawling stories to email
def sendemail(url,headers):
msg_from=''
#Sender email
passwd=''
#Fill in the authorization code of the sender's mailbox
receivers=[',']
#Recipient mailbox
subject='Today's bedtime story'
#Topic HTML = gethtmltext (URL, headers) content = parsehtml2 (HTML)
#Body msg = MIMEText(content)
msg['Subject'] = subject
msg['From'] = msg_from
msg['To'] = ','.join(receivers)
try:
s=smtplib.SMTP_SSL("smtp.qq.com",465)
#Mail server and port number
s.login(msg_from, passwd)
s.sendmail(msg_from, msg['To'].split(','), msg.as_string()) print("Sent successfully")
except:
print("fail in send")
finally:
s.quit()
Simply use the smtp protocol to send mail to the target mailbox through QQmail. The port number is 465, and the body content is a crawling story
Realize timing sending function
In the windows environment, enter compmgmt. In cmd MSc, add the script file to the task scheduling library, and set the running time and frequency
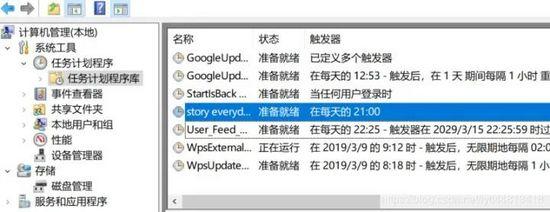
system
In this way, we can send bedtime stories at 9 o'clock every night!

story
Later, I found an English story website and used the same idea to complete the operation of crawling and pushing. You can choose to push Chinese stories one day and English stories one day. Isn't it wonderful? In addition, note: no matter whether you are for Python employment or hobbies, remember: project development experience is always the core. If you lack new project practice or do not have Python intensive tutorial, you can [forward this article + pay attention, private mail me 'p' to get it automatically], and you can also communicate with old drivers for advice!
The text and pictures of this article come from the Internet and their own ideas. They are only for learning and communication. They do not have any commercial use. The copyright belongs to the original author. If you have any questions, please contact us in time for handling.