1. How to add a new node to the cluster?
(1) Build k8s environment in kubeadmin mode
Here we can review the process of community k8s creating clusters. The process of binary installation is very complex. Let's discuss the way of kubeadmin
There are many materials, such as: https://zhuanlan.zhihu.com/p/265968760
- There are three nodes, one master and two nodes
- Install docker kubelet kubedm kubectl on three nodes
- Execute the kubedm init command on the master node to initialize
- Execute the kubedm join command on the node node to add the node node to the current cluster
- Configure CNI network plug-in for connectivity between nodes
- By pulling an nginx for testing, can we conduct external network testing
It can be seen that a line of commands will appear after the initialization of the master
kubeadm join 192.168.177.130:6443 --token 8j6ui9.gyr4i156u30y80xf \
--discovery-token-ca-cert-hash sha256:eda1380256a62d8733f4bddf926f148e57cf9d1a3a58fb45dd6e80768af5a500
Run on node to join
The errors and solutions in this process are summarized as follows:
(2) Error summary
Error one
This problem occurs when the Kubernetes init method is executed
error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
This is because VMware sets the number of cores to 1, while the minimum number of cores required for K8S should be 2. Adjust the number of cores and restart the system
Error two
When we use the kubernetes join command for the node node, the following error occurs
error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR Swap]: running with swap on is not supported. Please disable swap
The reason for the error is that we need to close swap
# Close swap # temporary swapoff -a # temporary sed -ri 's/.*swap.*/#&/' /etc/fstab
Error three
When using the kubernetes join command for the node node, the following error occurs
The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused
To solve the problem, first go to the master node and create a file
# create folder mkdir /etc/systemd/system/kubelet.service.d # create a file vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf # Add the following Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false" # Reset kubeadm reset
Then delete the configuration directory you just created
rm -rf $HOME/.kube
Then reinitialize in the master
kubeadm init --apiserver-advertise-address=202.193.57.11 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
After the initial completion, we go to node1 node and execute kubedm join command to join the master
kubeadm join 202.193.57.11:6443 --token c7a7ou.z00fzlb01d76r37s \
--discovery-token-ca-cert-hash sha256:9c3f3cc3f726c6ff8bdff14e46b1a856e3b8a4cbbe30cab185f6c5ee453aeea5
After adding, we use the following command to check whether the node is successfully added
kubectl get nodes
Error 4
When we check the nodes again, there will be a problem with kubectl get nodes
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
This is because the configuration files we created before still exist, that is, these configurations
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
All we need to do is delete the configuration file and execute it again
rm -rf $HOME/.kube
Then create it again
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
The main reason for this problem is that we didn't put $home /. When executing kubedm reset If Kube is removed, there will be a problem when it is created again
Error five
The following error occurred during installation
Another app is currently holding the yum lock; waiting for it to exit...
It's because the lock is occupied, and the solution is
yum -y install docker-ce
Error six
When using the following command to add node nodes to the cluster
kubeadm join 192.168.177.130:6443 --token jkcz0t.3c40t0bqqz5g8wsb --discovery-token-ca-cert-hash sha256:bc494eeab6b7bac64c0861da16084504626e5a95ba7ede7b9c2dc7571ca4c9e5
Then this error occurs
[root@k8smaster ~]# kubeadm join 192.168.177.130:6443 --token jkcz0t.3c40t0bqqz5g8wsb --discovery-token-ca-cert-hash sha256:bc494eeab6b7bac64c0861da16084504626e5a95ba7ede7b9c2dc7571ca4c9e5 W1117 06:55:11.220907 11230 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set. [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher
For security reasons, the Linux system prohibits packet forwarding by default. The so-called forwarding means that when the host has more than one network card, one of them receives the data packet and sends the packet to another network card of the host according to the destination ip address of the data packet, and the network card continues to send the data packet according to the routing table. This is usually the function of the router. That is, / proc / sys / net / IPv4 / ip_ The value of the forward file does not support forwarding
- 0: prohibited
- 1: Forward
So we need to change the value to 1
echo "1" > /proc/sys/net/ipv4/ip_forward
After modification, execute the command again
2. So how to add new nodes in eks?
If node wants to join the eks cluster, it must have an instance role that can be recognized by the cluster. This is realized through config map, which is usually used to configure app s
There is a special config map in eks, namely AWS auth
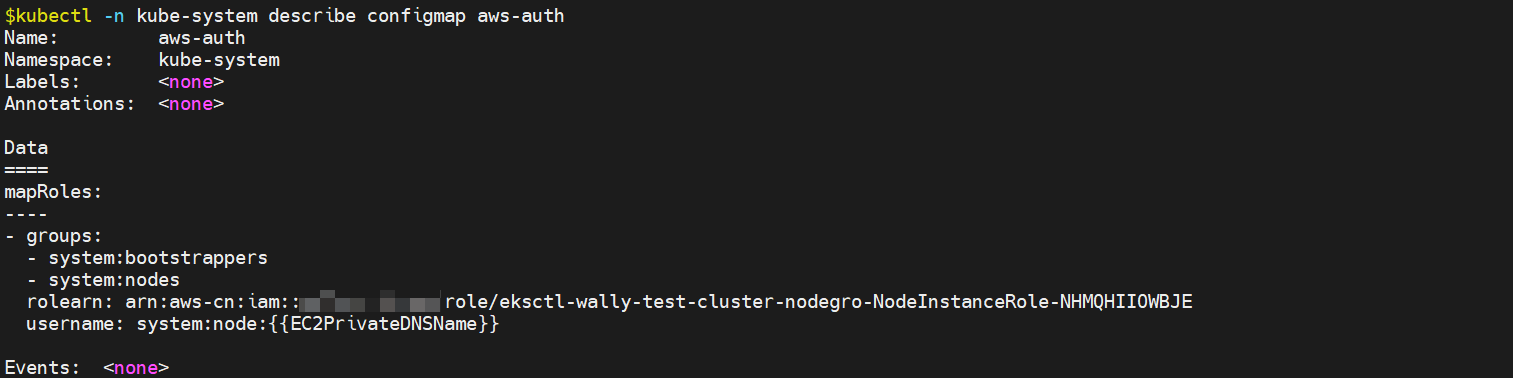
Therefore, if the node cannot join the cluster, it may be because the config map is not configured, which is the difference between eks and the community k8s. The roles in the config map should be correct. The roles automatically generated by eksctl have the following permissions and have established a trust relationship with ec2.

In addition to the issue of permissions, we should also pay attention to the security group, Amazon EKS security group considerations
In addition, you can query the node log
- Systems using systemd use journalctl -u kubelet
- Inapplicable view / var/log
If an error is reported, Error from server: "error:You must be logged in to the server (Unauthorized)
- Check the version of kubectl
- Check the version of cli
- Ensure that kubeconfig has the correct endpoint and authentication information
- Add - v9 when running the command to view the debug information
Note: for the newly created cluster, the users allowed to access are limited to the users who created the cluster. This should be paid special attention to. You can confirm it through AWS STS get caller identity
If identity authentication is provided in the form of oidc, refer to
Authenticate users of the cluster through the OpenID Connect identity provider
3. How to solve the problem of pod falling into pending state?
Use kubectl describt pod ${pod_name}
Or kuebctl get pods -n xxx -o wide to view the abnormal status
How can I change the state of my node from NotReady or Unknown to Ready?
The purpose is to install metric server, but the image cannot be pulled down (k8s. GCR. IO / metrics server / metrics server: v0.6.0)
Episode: I tried to go ssh to the eks node to modify the docker. As a result, the node hung up directly. See this blog to solve it
https://blog.csdn.net/qxqxqzzz/article/details/109712603
Then continue to modify the docker configuration file. It's not easy to restart this time. Just restart ec2. The restart method is good, and the cluster returns to normal again
Question:
- Can you directly modify the docker configuration file of node, and whether there are secret and other things on k8s?
- How to solve the problem of ImagePullBackOff?
reference resources https://www.tutorialworks.com/kubernetes-imagepullbackoff/
One solution is to manually pull and then transfer it to the private ecr for reference https://docs.aws.amazon.com/zh_cn/AmazonECR/latest/userguide/ECR_on_EKS.html
Find an article Easy and safe use of overseas open container images in AWS China
Leave a hole first
Use kubectl describe pod to view relevant info. node may be unable to schedule pod due to various pressure s
Troubleshooting idea of pod in pending state
- If it's waiting, check the use of various resources in the cluster to see if there is pressure
- If it's a crash, check the pod log to see if it's down
- If it's running but it doesn't meet expectations, kubectl exec goes to the pod to check the situation
- The service is not resolved. There may be a problem with the endpoing configuration
- For inaccessible problems, check the core dns component