1, Introduction to Azkaban
1.1 why workflow scheduling system is needed
- A complete data analysis system is usually composed of a large number of task units: Shell script program, Java program, MapReduce program, Hive script, etc;
- There are time sequence and before and after dependency among task units;
- In order to organize such a complex execution plan well, a workflow scheduling system is needed to schedule execution;
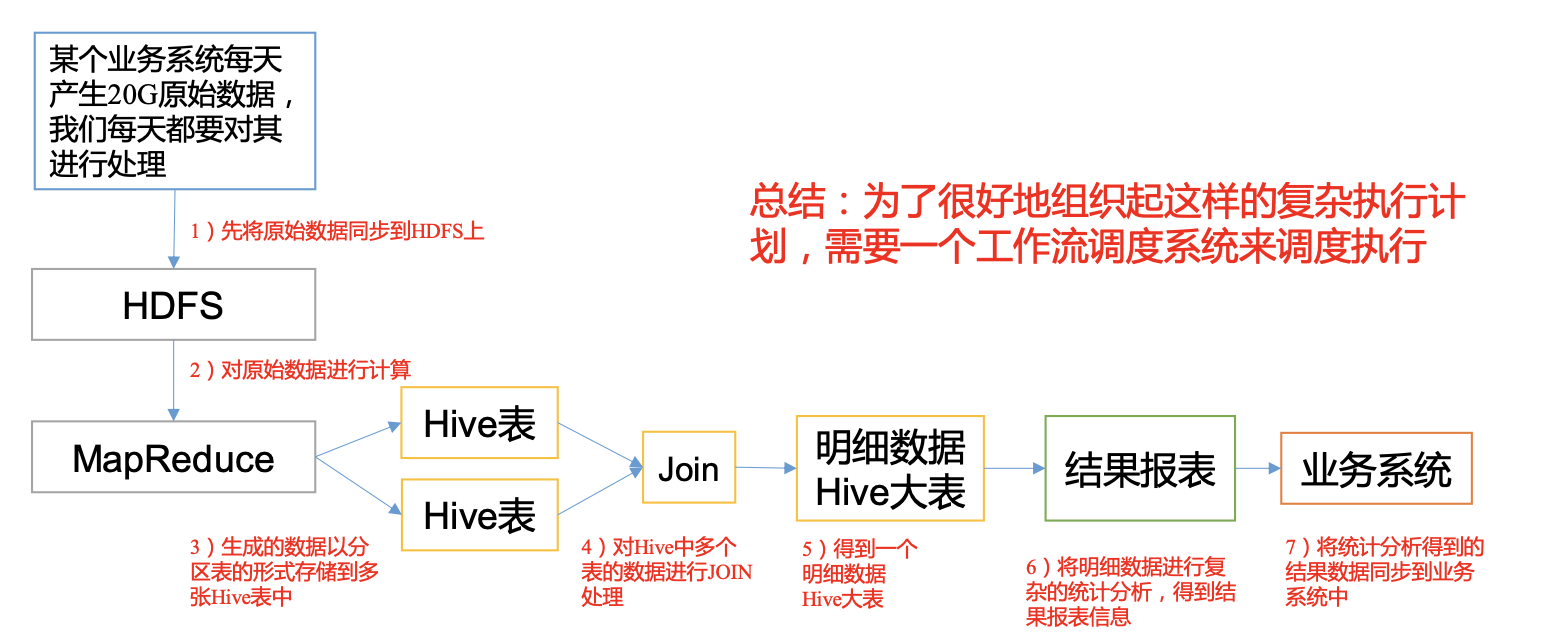
1.2 common workflow scheduling systems
- Simple task scheduling: directly use Crontab of Linux to define;
notes ⚠️: Crontab cannot handle task scheduling with dependencies! - Complex task scheduling: develop scheduling platform or use ready-made open source scheduling systems, such as Ooize, Azkaban, Airflow, dolphin scheduler, etc.
1.3 comparison between Azkaban and Oozie
Compared with Ooize, Azkaban is a heavyweight task scheduling system with comprehensive functions, but the configuration is used
And more complicated. If you can ignore the lack of some functions, the lightweight scheduler Azkaban is a good candidate.
2, Azkaban cluster installation
2.1 cluster mode installation
2.1.1 preparation of installation package
-
Upload azkaban-db-3.84.4.tar.gz, azkaban-exec-server-3.84.4.tar.gz, azkaban-web-server-3.84.4.tar.gz to / opt/software path of Hadoop 102;

-
Create a new / opt/module/azkaban directory and unzip all tar packages to this directory:
[xiaobai@hadoop102 azkaban]$ mkdir /opt /module/azkaban [xiaobai@hadoop102 azkaban]$ tar -zxvf azkaban-web-server-3.84.4.tar.gz -C /opt/module/azkaban/ [xiaobai@hadoop102 azkaban]$ tar -zxvf azkaban-exec-server-3.84.4.tar.gz -C /opt/module/azkaban/ [xiaobai@hadoop102 azkaban]$ tar -zxvf azkaban-db-3.84.4.tar.gz -C /opt/module/azkaban/
- Enter the / opt/module/azkaban directory and modify the name:
[xiaobai@hadoop102 azkaban]$ mv azkaban-web-server-3.84.4/ azkaban-web [xiaobai@hadoop102 azkaban]$ mv azkaban-exec-server-3.84.4/ azkaban-exec [xiaobai@hadoop102 azkaban]$ ll total 4 drwxr-xr-x. 2 xiaobai xiaobai 4096 Apr 18 2020 azkaban-db-3.84.4 drwxr-xr-x. 6 xiaobai xiaobai 55 Apr 18 2020 azkaban-exec drwxr-xr-x. 6 xiaobai xiaobai 51 Apr 18 2020 azkaban-web
2.1.2 configuring MySQL
- Start MySQL:
[xiaobai@hadoop102 azkaban]$ mysql -uroot -p******
- Log in to MySQL and create Azkaban database:
mysql> create database azkaban; Query OK, 1 row affected (0.19 sec)
- Create azkaban user and give permission to set the effective length of password to 4 digits or more
mysql> set global validate_password_length=4; Query OK, 0 rows affected (0.07 sec)
- Set the minimum level of password policy (ps: test only!)
mysql> set global validate_password_policy=0; Query OK, 0 rows affected (0.00 sec)
- Create Azkaban user, and any host can access Azkaban with password **********************************************************
mysql> CREATE USER 'azkaban'@'%' IDENTIFIED BY '******'; Query OK, 0 rows affected (0.17 sec)
Give Azkaban user the authority to add, delete, modify and query:
mysql> GRANT SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION; Query OK, 0 rows affected (0.03 sec)
- Create Azkaban table and exit MySQL after completion:
mysql> use azkaban; Database changed mysql> source /opt/module/azkaban/azkaban-db-3.84.4/create-all-sql-3.84.4.sql; mysql> show tables; +-----------------------------+ | Tables_in_azkaban | +-----------------------------+ | QRTZ_BLOB_TRIGGERS | | QRTZ_CALENDARS | | QRTZ_CRON_TRIGGERS | | QRTZ_FIRED_TRIGGERS | | QRTZ_JOB_DETAILS | | QRTZ_LOCKS | | QRTZ_PAUSED_TRIGGER_GRPS | | QRTZ_SCHEDULER_STATE | | QRTZ_SIMPLE_TRIGGERS | | QRTZ_SIMPROP_TRIGGERS | | QRTZ_TRIGGERS | | active_executing_flows | | active_sla | | execution_dependencies | | execution_flows | | execution_jobs | | execution_logs | | executor_events | | executors | | project_events | | project_files | | project_flow_files | | project_flows | | project_permissions | | project_properties | | project_versions | | projects | | properties | | ramp | | ramp_dependency | | ramp_exceptional_flow_items | | ramp_exceptional_job_items | | ramp_items | | triggers | | validated_dependencies | +-----------------------------+ 35 rows in set (0.01 sec) mysql> quit; Bye
The required script is create-all-sql-3.84.4.sql, as shown in the figure:

- Change MySQL package size; To prevent Azkaban MySQL connection from blocking:
[xiaobai@hadoop102 azkaban]$ sudo vim /etc/my.cnf max_allowed_packet=1024M
notes ⚠️: Put it under [mysqld]!

- Restart MySQL:
[xiaobai@hadoop102 azkaban]$ sudo systemctl restart mysqld
2.1.3 configuring the Executor Server
Azkaban Executor Server handles the actual execution of workflows and jobs.
- Edit azkaban.properties in the / opt / module / Azkaban / Azkaban exec / conf Directory:
[xiaobai@hadoop102 conf]$ vim azkaban.properties default.timezone.id=Asia/Shanghai
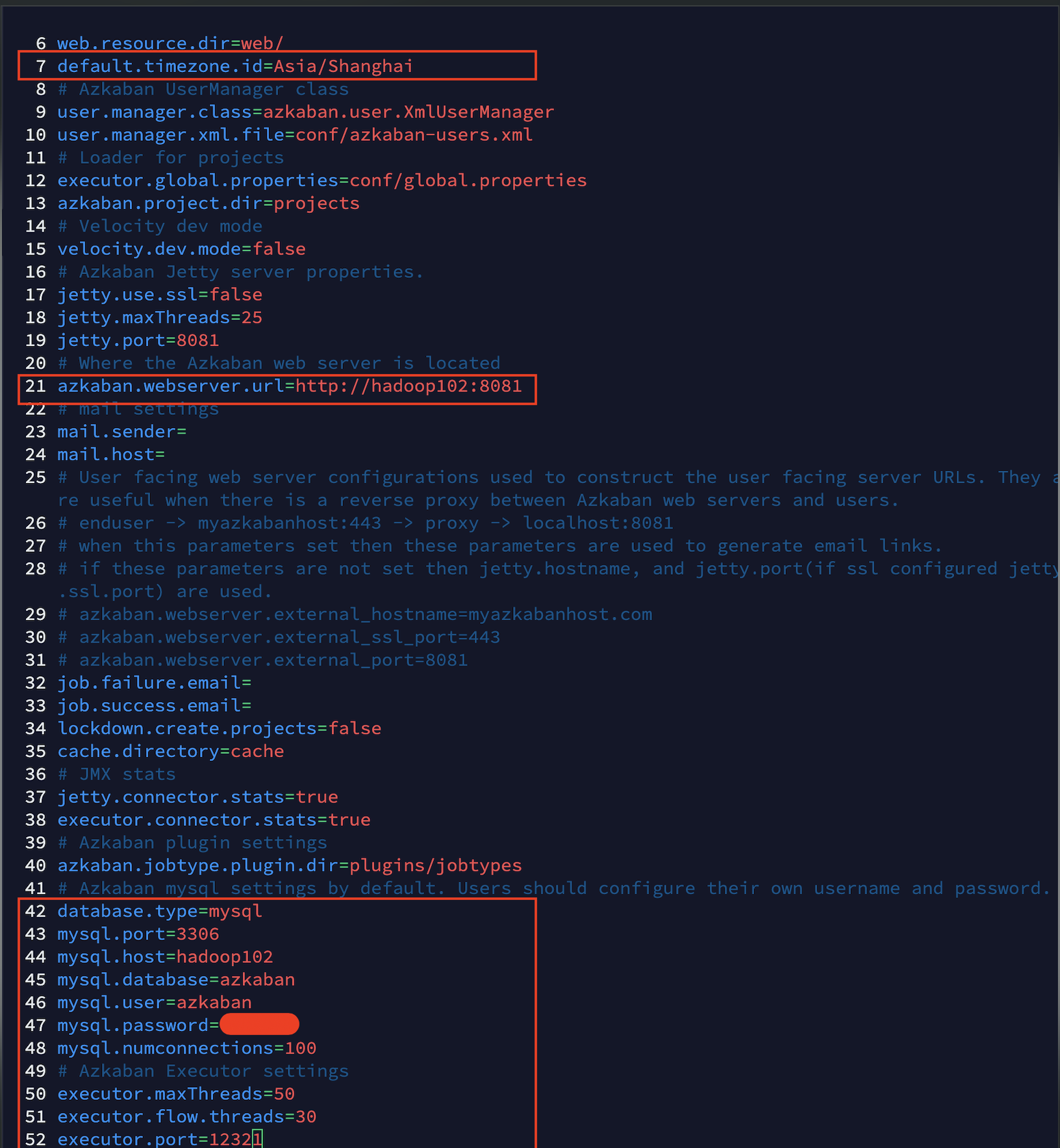
- Synchronous distribution Azkaban exec:
[xiaobai@hadoop102 conf]$ xsync /opt/module/azkaban/azkaban-exec/
- Enter the / opt / module / Azkaban / Azkaban exec path and start the executor server on three machines:
[xiaobai@hadoop102 azkaban-exec]$ bin/start-exec.sh [xiaobai@hadoop103 azkaban-exec]$ bin/start-exec.sh [xiaobai@hadoop104 azkaban-exec]$ bin/start-exec.sh
Stop command:
[xiaobai@hadoop102 azkaban-exec]$ bin/shutdown-exec.sh
notes ⚠️:
If the executor.port file appears in / opt / module / Azkaban / Azkaban exec Directory: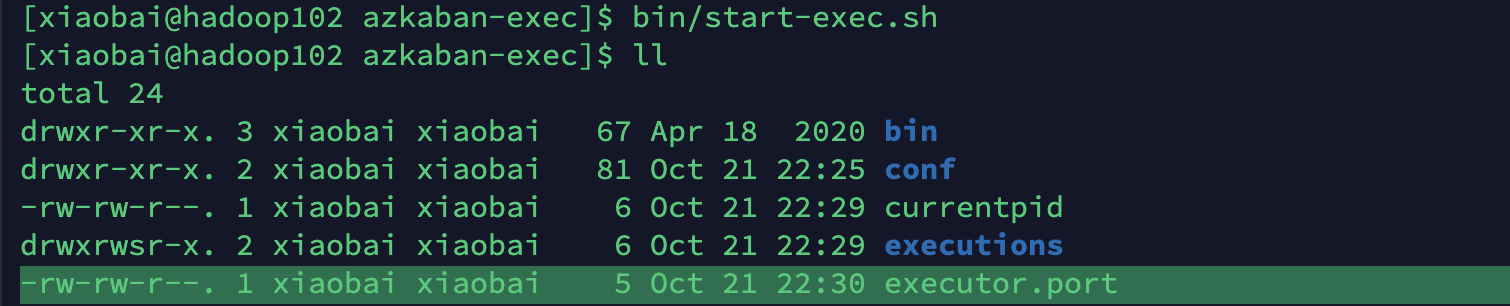
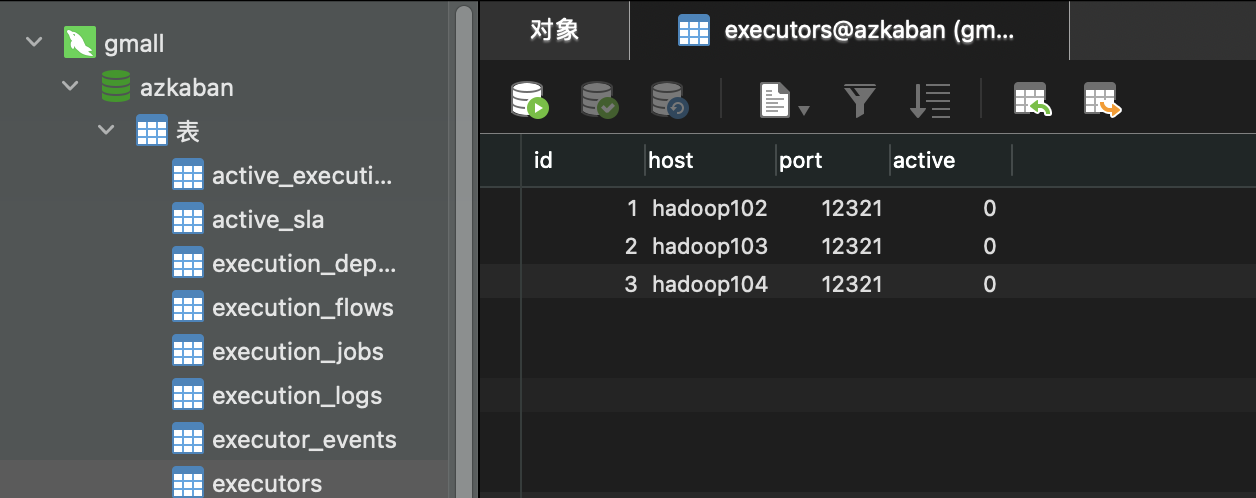
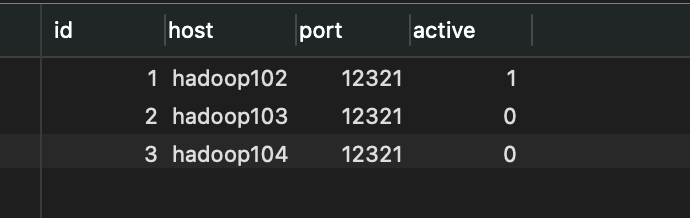
Or the connected host name and port number appear in the executors table in azkaban database, indicating that the startup is successful!
- Activate the executor. If the status below shows success, the activation is successful!
[xiaobai@hadoop102 azkaban-exec]$ curl -G "hadoop102:12321/executor?action=activate" && echo
{"status":"success"}
[xiaobai@hadoop103 azkaban-exec]$ curl -G "hadoop102:12321/executor?action=activate" && echo
{"status":"success"}
[xiaobai@hadoop104 azkaban-exec]$ curl -G "hadoop102:12321/executor?action=activate" && echo
{"status":"success"}
As shown in the figure, after successful activation, the active column is displayed as 1!
2.1.4 configuring Web Server
Azkaban Web Server handles project management, authentication, planning and execution triggers.
- Edit azkaban.properties in / opt / module / Azkaban / Azkaban Web / conf Directory:
[xiaobai@hadoop102 conf]$ vim azkaban.properties
Modify the following properties:
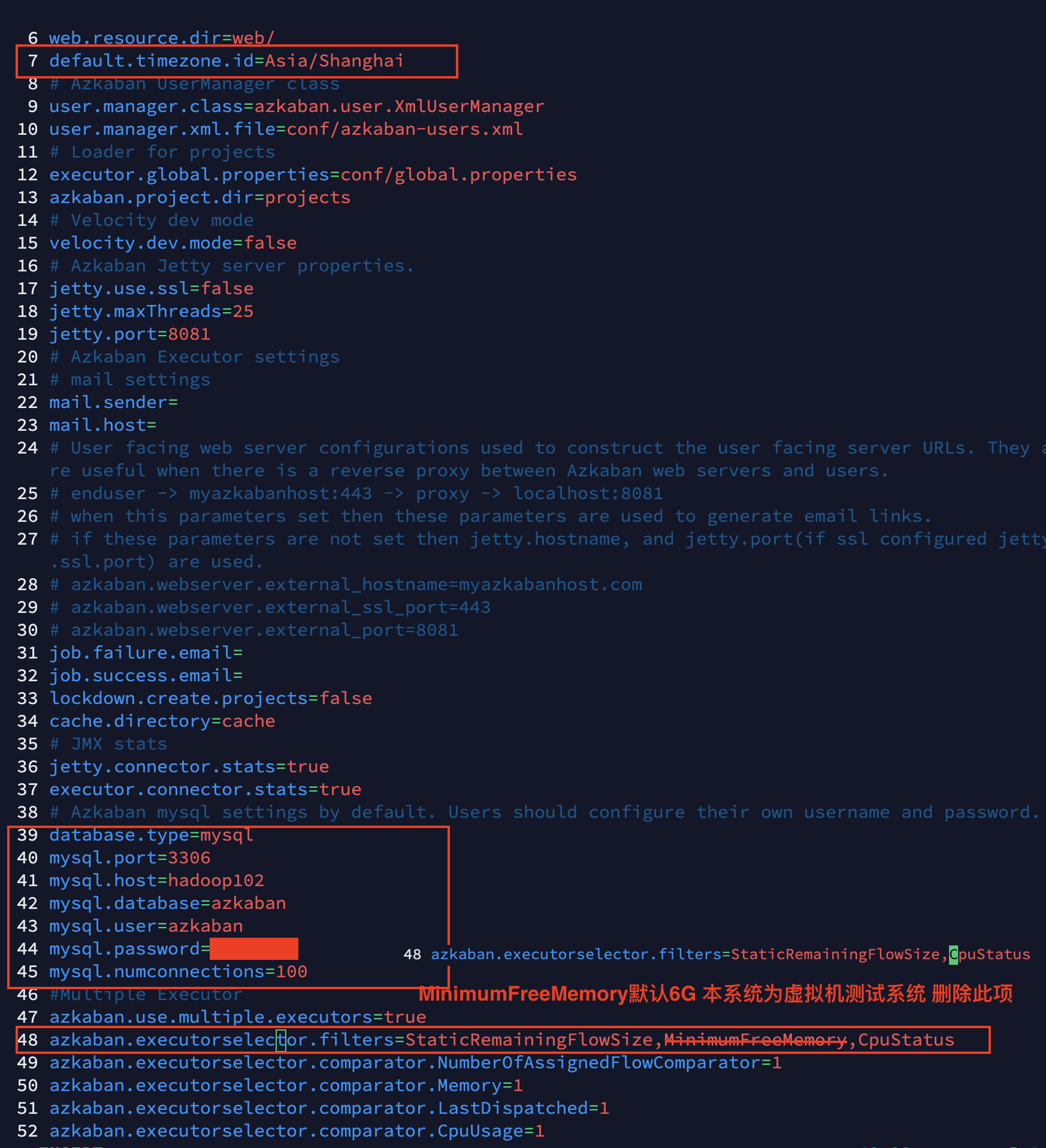
tips:
StaticRemainingFlowSize: the number of tasks being queued;
CpuStatus: CPU usage:
MinimumFreeMemory: memory usage.
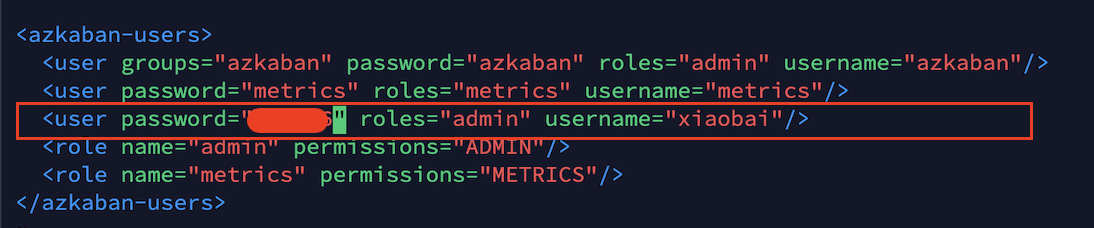
- Modify the azkaban-users.xml file and add the user xiaobai:
[xiaobai@hadoop102 conf]$ vim azkaban-users.xml <user password="******" roles="admin" username="xiaobai"/>
- Enter the / opt / module / Azkaban / Azkaban web path of Hadoop 102 and start the web server:
[xiaobai@hadoop102 azkaban-web]$ bin/start-web.sh
Stop command:
[xiaobai@hadoop102 azkaban-web]$ bin/shutdown-web.sh
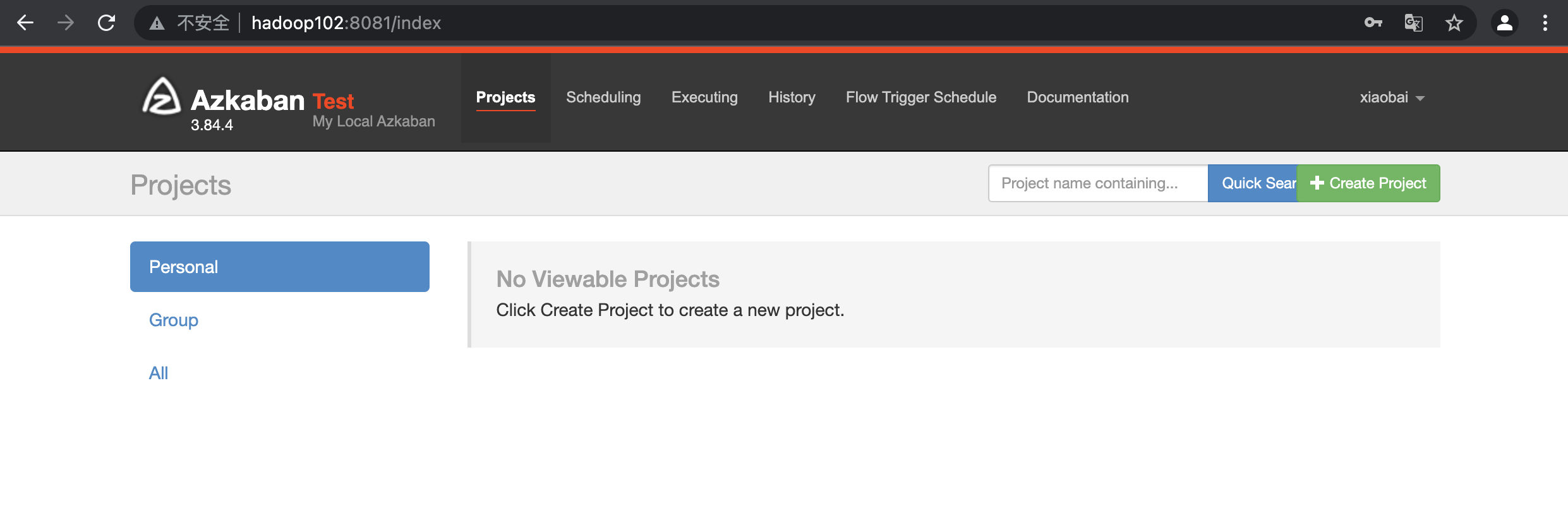
- visit http://hadoop102:8081 , and log in as xiaobai user:
2.2 Work Flow cases
2.2.1 HelloWorld
- Create the command.job file:
jane@janedeMacBook-Pro Desktop % vim command.job
#command.job type=command command=echo 'hello world'
Compress command.job, create a new project in WebServer, and click create project = = > upload = = > command.job ⬇️
 Click Execute Flow ⬇️
Click Execute Flow ⬇️
Click Execute ⬇️
Continue⬇️
The unit of work log is in the Job List ⬇️
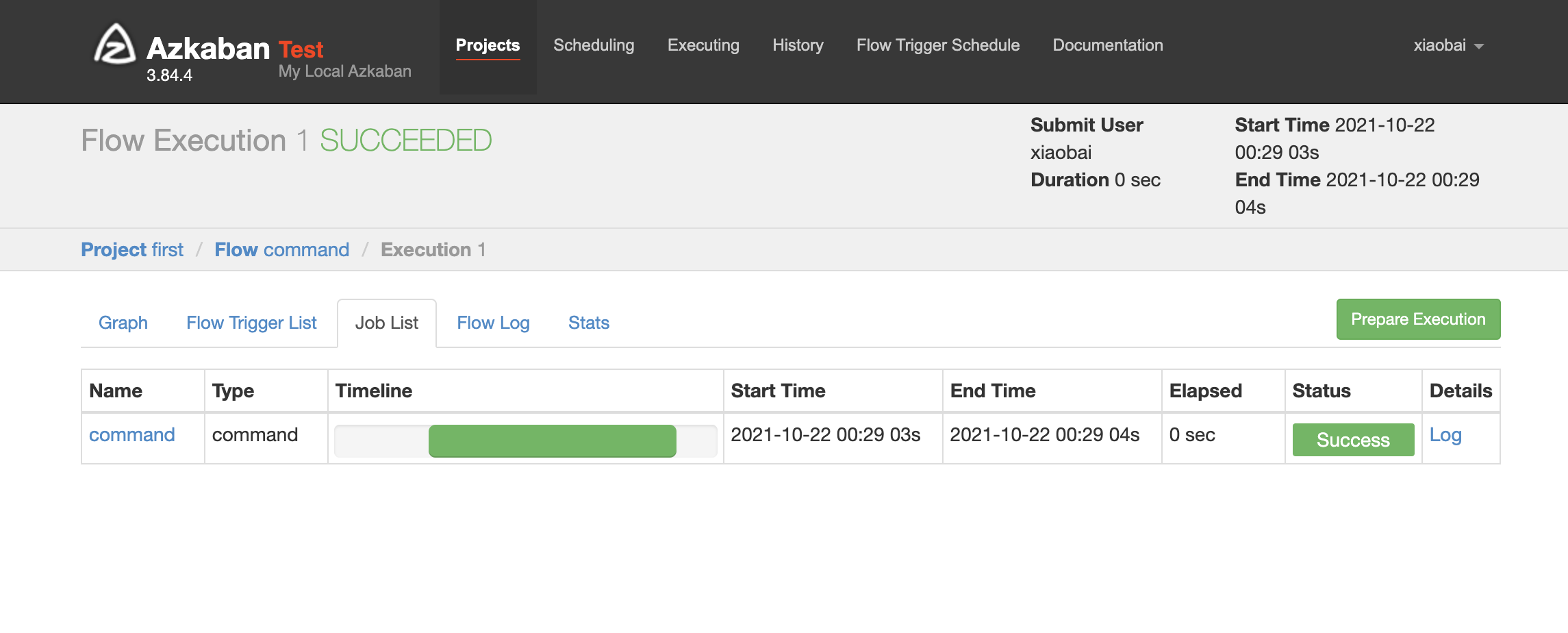
2.2.2 job dependency cases
Requirements:
jobC cannot be executed until job A and job B are executed.
realization:
- Create a new first.project file and edit the contents as follows:
azkaban-flow-version: 2.0
notes ⚠️: The function of this file is to parse the flow file in a new flow API way.
- Create a new first.flow file as follows
nodes:
- name: jobA
type: command
config:
command: echo "hello world A"
- name: jobB
type: command
config:
command: echo "hello world B"
- name: jobC
type: command
#jobC depends on jobA and jobB
dependsOn:
- jobA
- jobB
config:
command: echo "hello world C"
notes ⚠️:
dependsOn aligned with name/type is an array type!
1). Name: job name;
2). Type: job type; Command indicates that the way to execute the job is command;
3). Config: job configuration.
Upload the compressed file to Azkaban Web Client and click Execute flow to see the dependency relationship between jobA / joB / jobC:
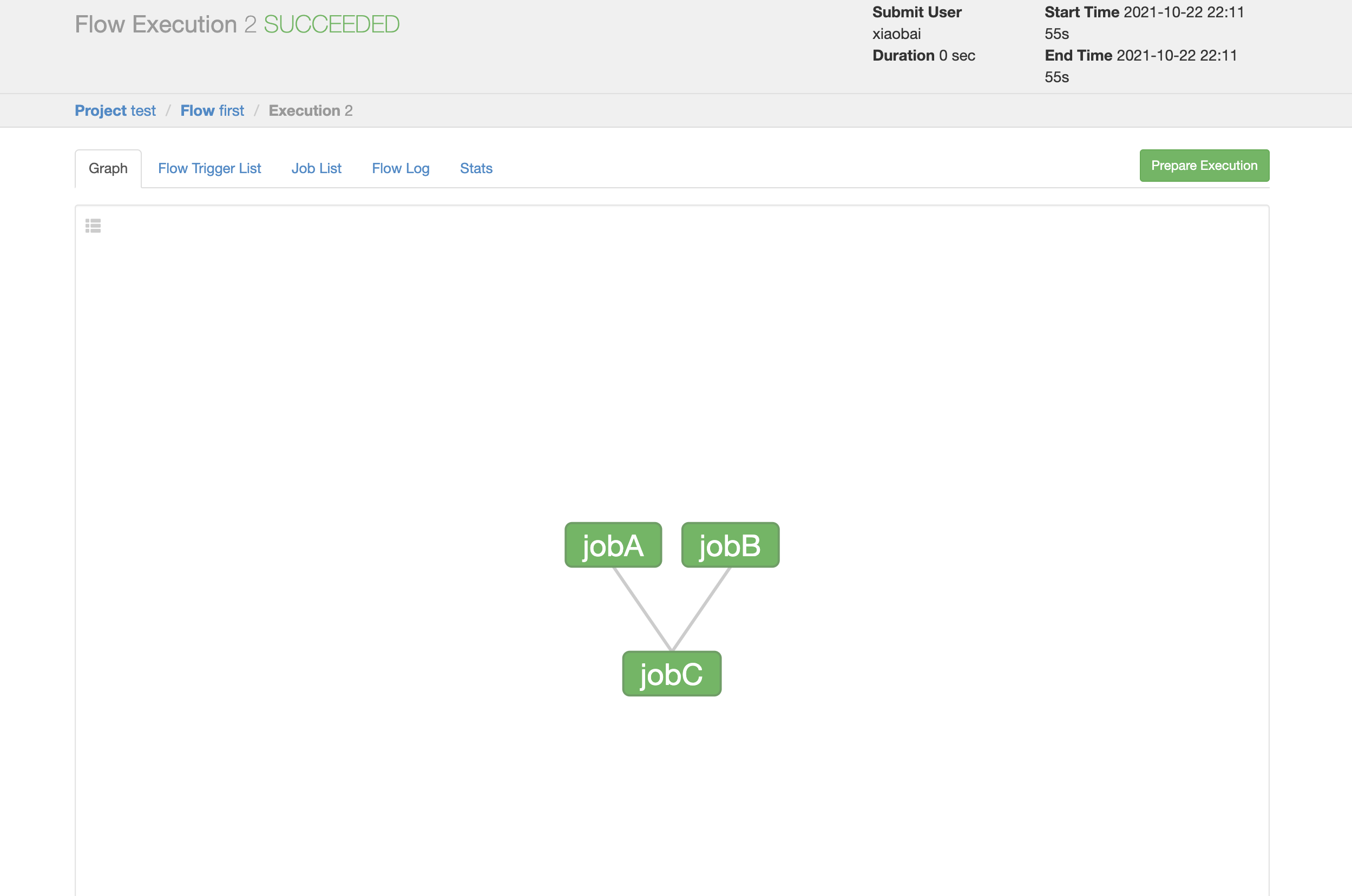
To view the job list:
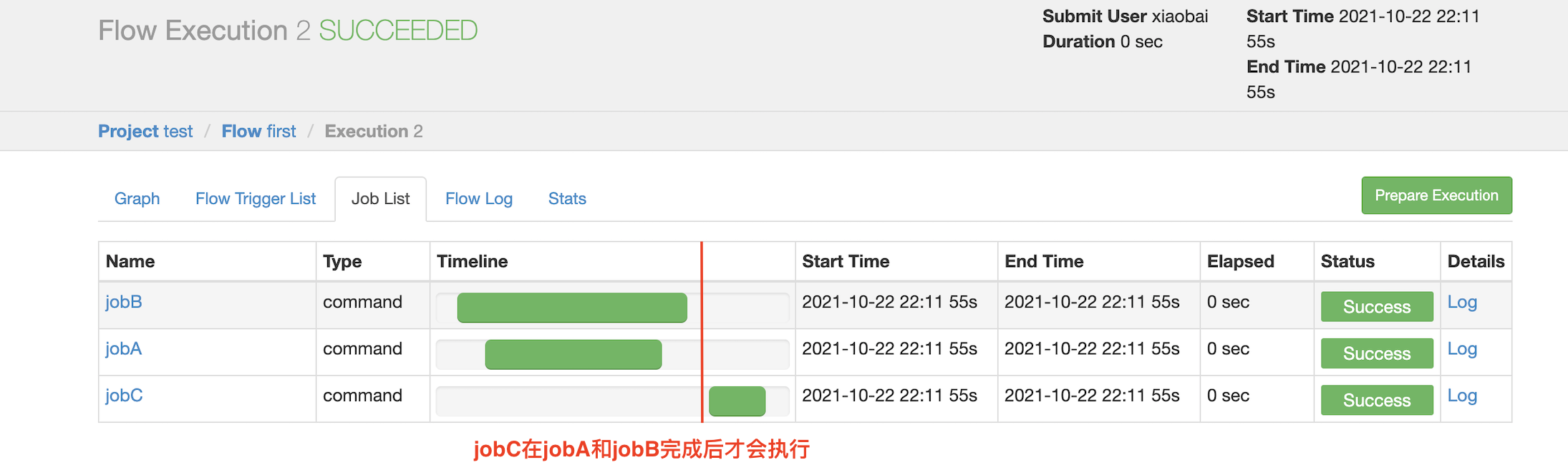
2.2.3 automatic failure retry cases
Requirements:
If the task fails to execute, it needs to be retried 3 times, and the retry interval is 10000ms.
realization:
Compile configuration flow: autoretry.flow:
nodes:
- name: jobA
type: command
config:
command: sh /not_exists.sh
retries: 3
retry.backoff: 5000
tips:
Retries: number of retries;
retry.backoff: retry interval
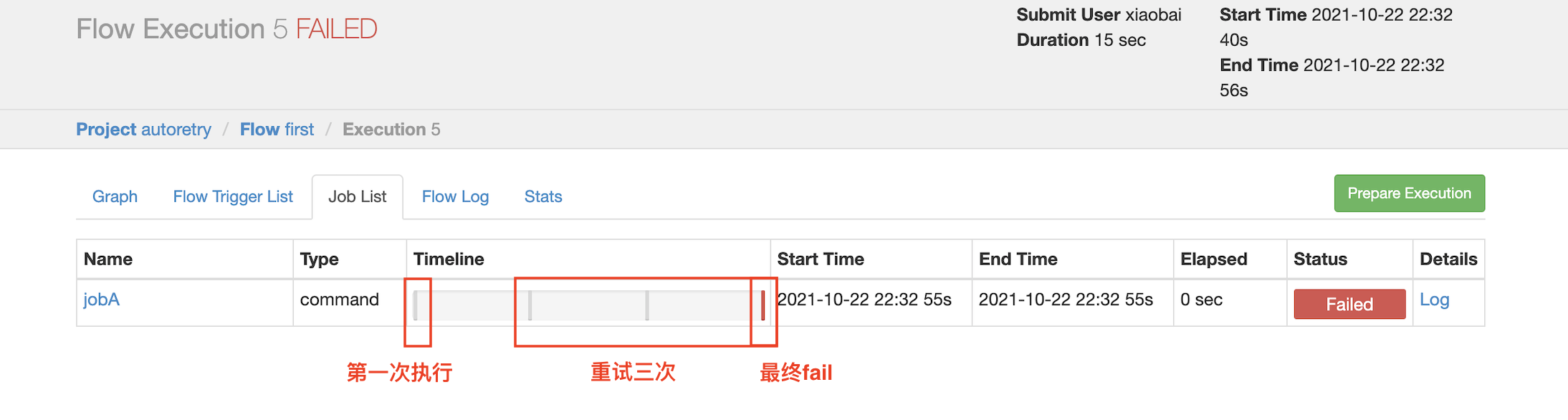
notes ⚠️:
You can add the task failure retry configuration in the Flow global configuration. At this time, the retry configuration will be applied to all jobs:
config:
retries: 3
retry.backoff: 10000
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
2.2.4 manual failure retry cases
Requirements:
JobA = "jobb (dependent on A) =" JobC = "JobD =" JobE = "JobF". In the production environment, any Job may hang up. You can execute the Job you want to execute according to your needs.
realization:
Compile the configuration stream handsretry.flow:
nodes:
- name: JobA
type: command
config:
command: echo "This is JobA."
- name: JobB
type: command
dependsOn:
- JobA
config:
command: echo "This is JobB."
- name: JobC
type: command
dependsOn:
- JobB
config:
command: echo "This is JobC."
- name: JobD
type: command
dependsOn:
- JobC
config:
command: echo "This is JobD."
- name: JobE
type: command
dependsOn:
- JobD
config:
command: echo "This is JobE."
- name: JobF
type: command
dependsOn:
- JobE
config:
command: echo "This is JobF."
Joba jobf execution diagram:
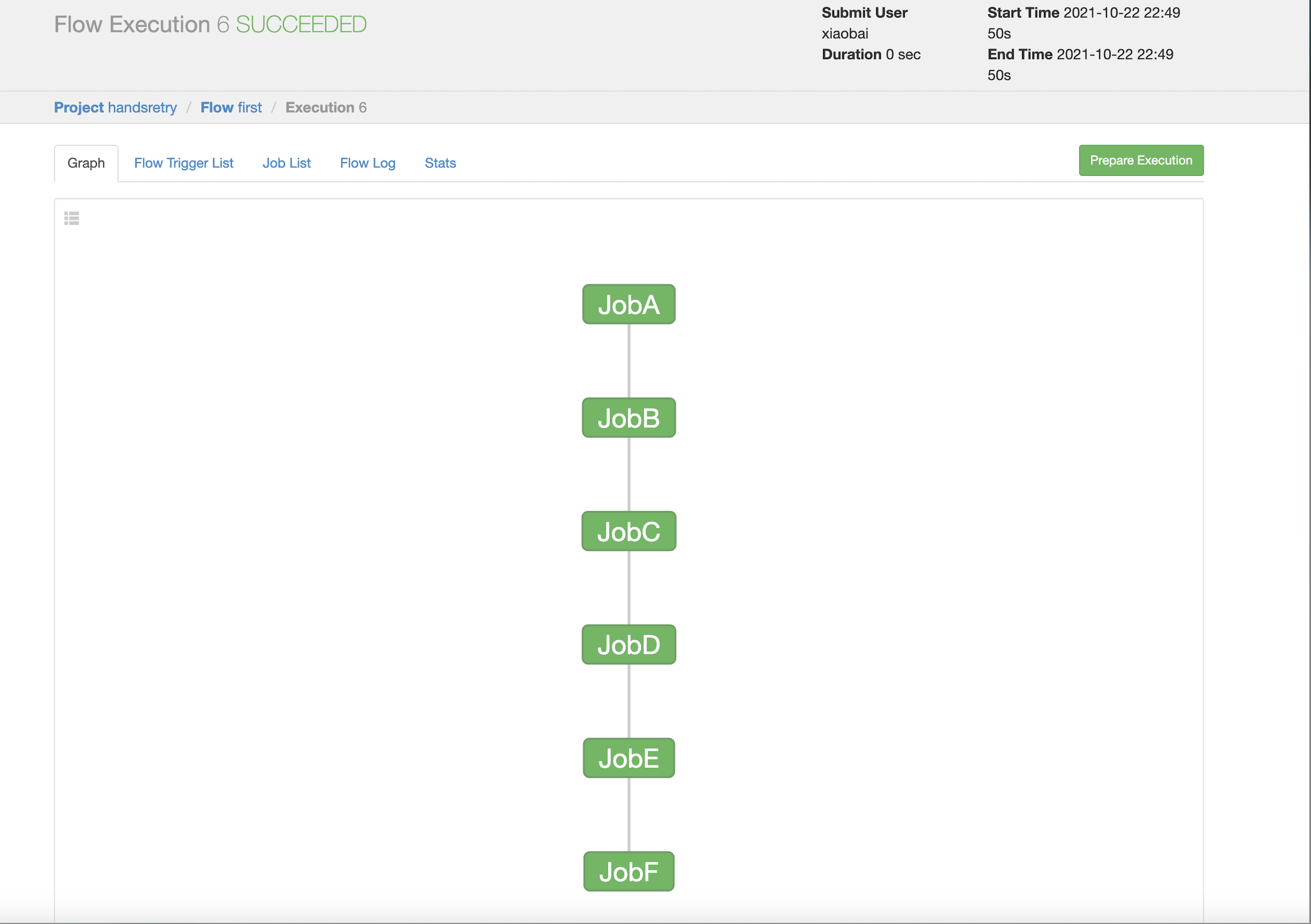
If there are failed job s, you can view them in history = = > flow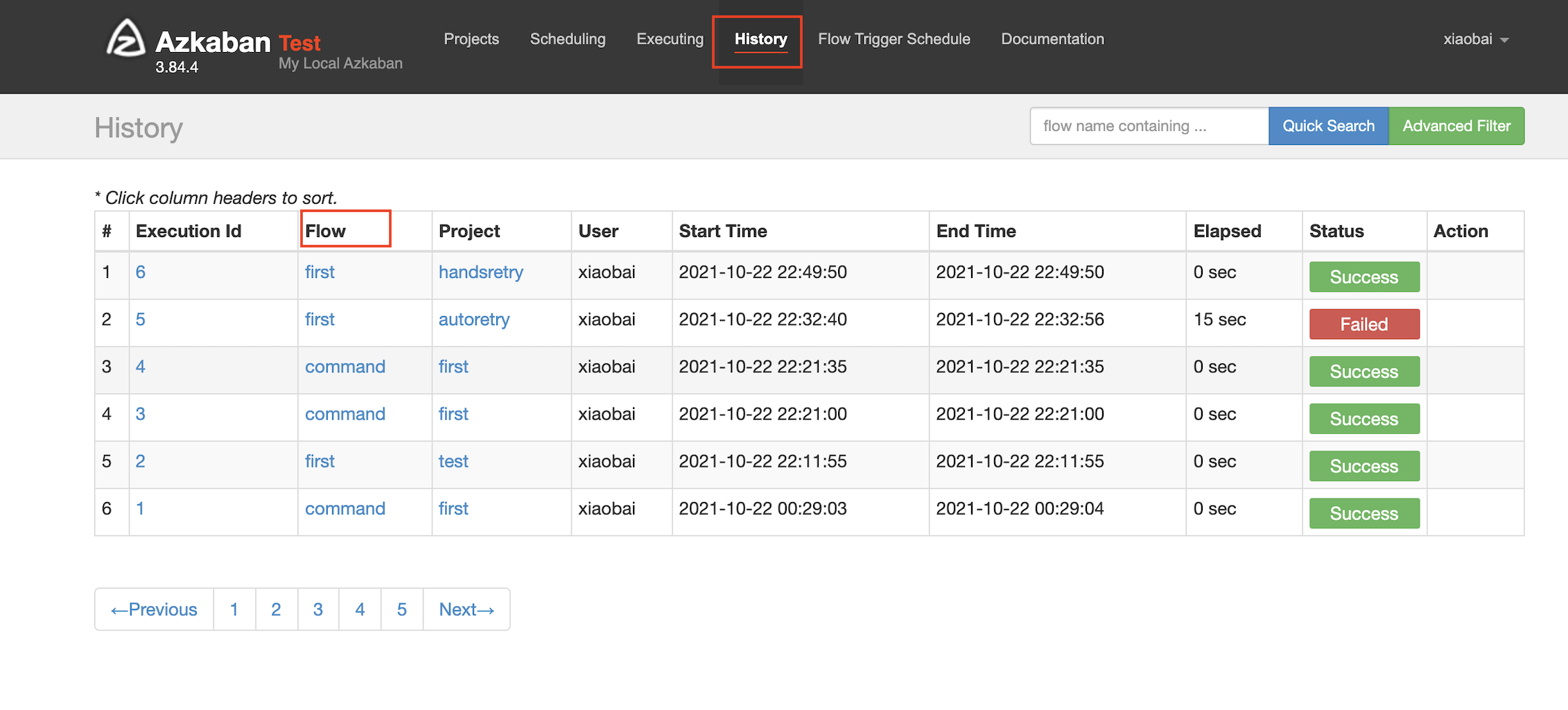
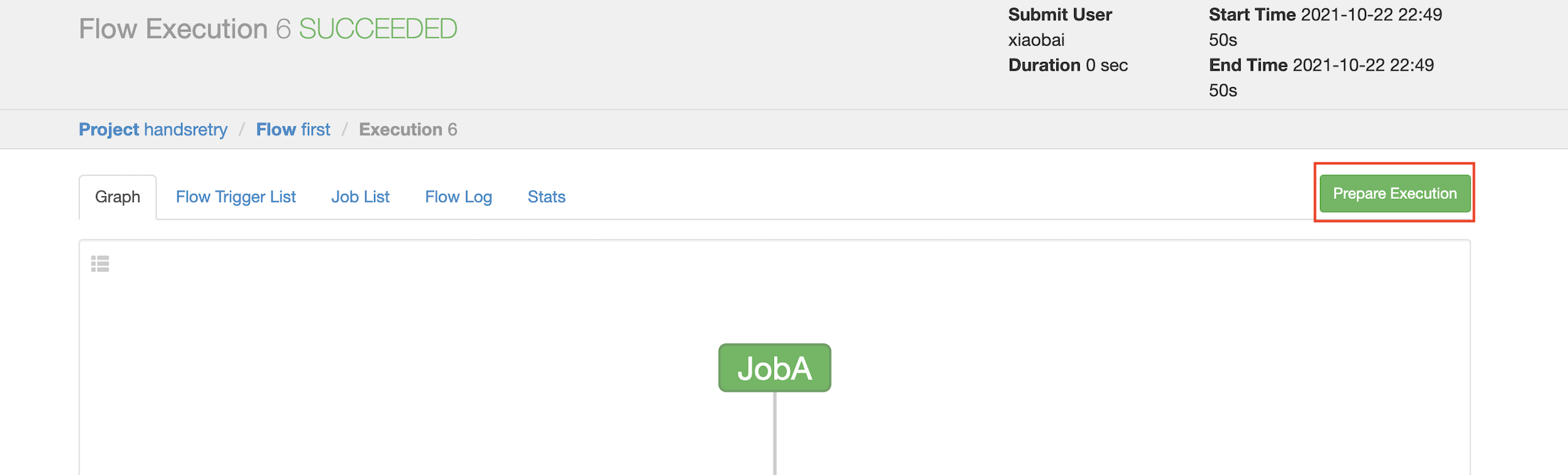
Then click prepare execution to start execution from the failed job:
Or manually set the successful job to disable / children in execute flow, and then click execute!
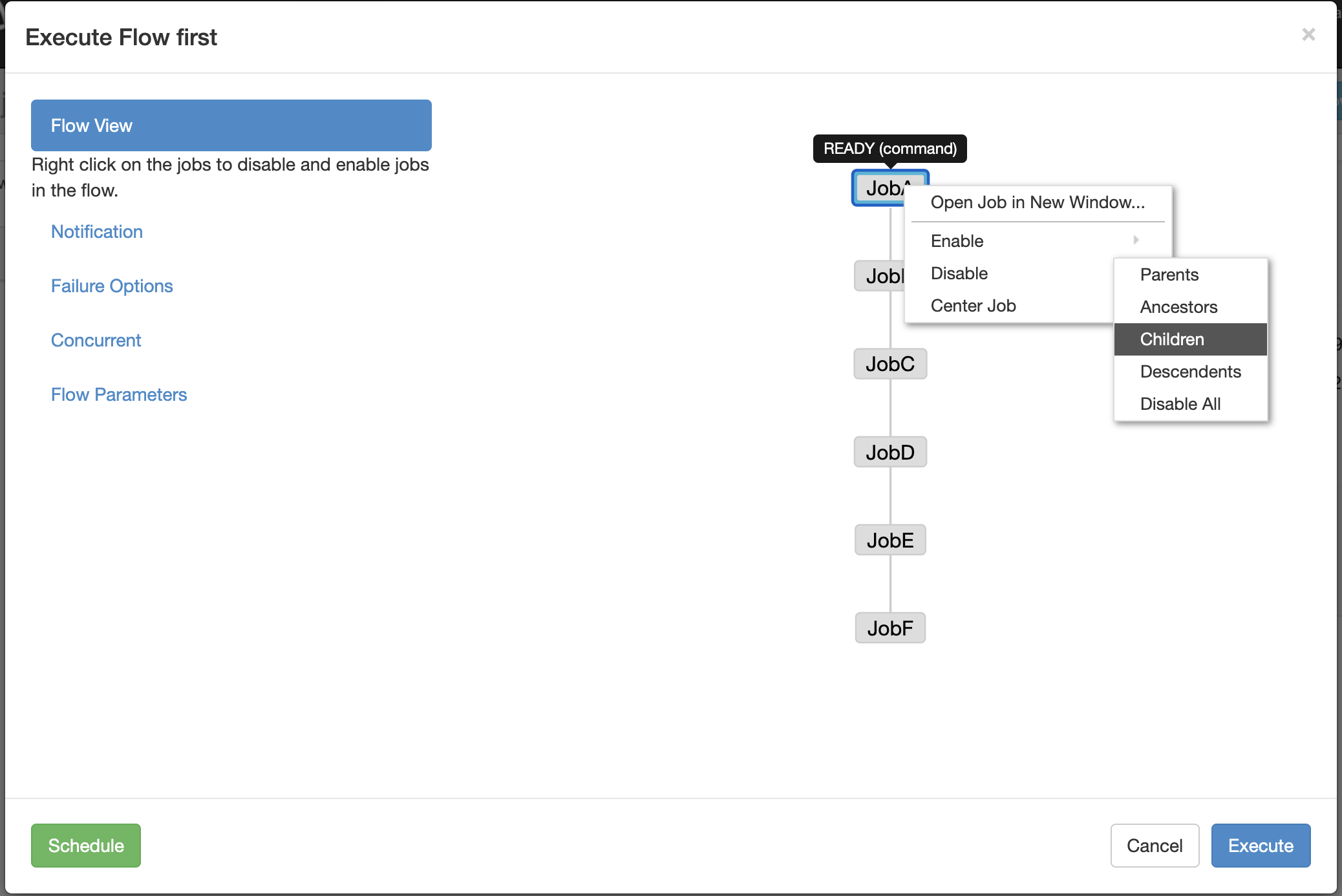
tips:
Both Enable and Disable have the following parameters:
Parents: the previous task of the job;
Antecessors: all tasks before the job;
Children: a task after the job;
Descendants: all tasks after the job;
Enable All: all tasks.
3, Azkaban advanced
3.1 JavaProcess job type cases
javaprocess type can run a user-defined main class method. The type is javaprocess, and the available configurations are:
Xms: minimum heap;
Xmx: maximum heap;
Classpath: classpath;
java.class: the Java object to run, which must contain the parameters of the Main method main.args:main method.
🌰:
- Build a maven project in azkaban;
- Create package name: cpm.xiaobai;
- Create TestJavaProcess class:
package com.xiaobai;
public class TestJavaProcess {
public static void main(String[] args) {
System.out.println("Java Process Test!");
}
}
- Package azkaban-javaprocess-1.0-SNAPSHOT.jar
- Create a new javatest.flow:
nodes:
- name: test_java
type: javaprocess
config:
Xms: 96M
Xmx: 200M
java.class: com.xiaobai.TestJavaProcess
- Package the jar package / flow package / project file into javatest.zip;
- Create prohect – > upload – > executor:
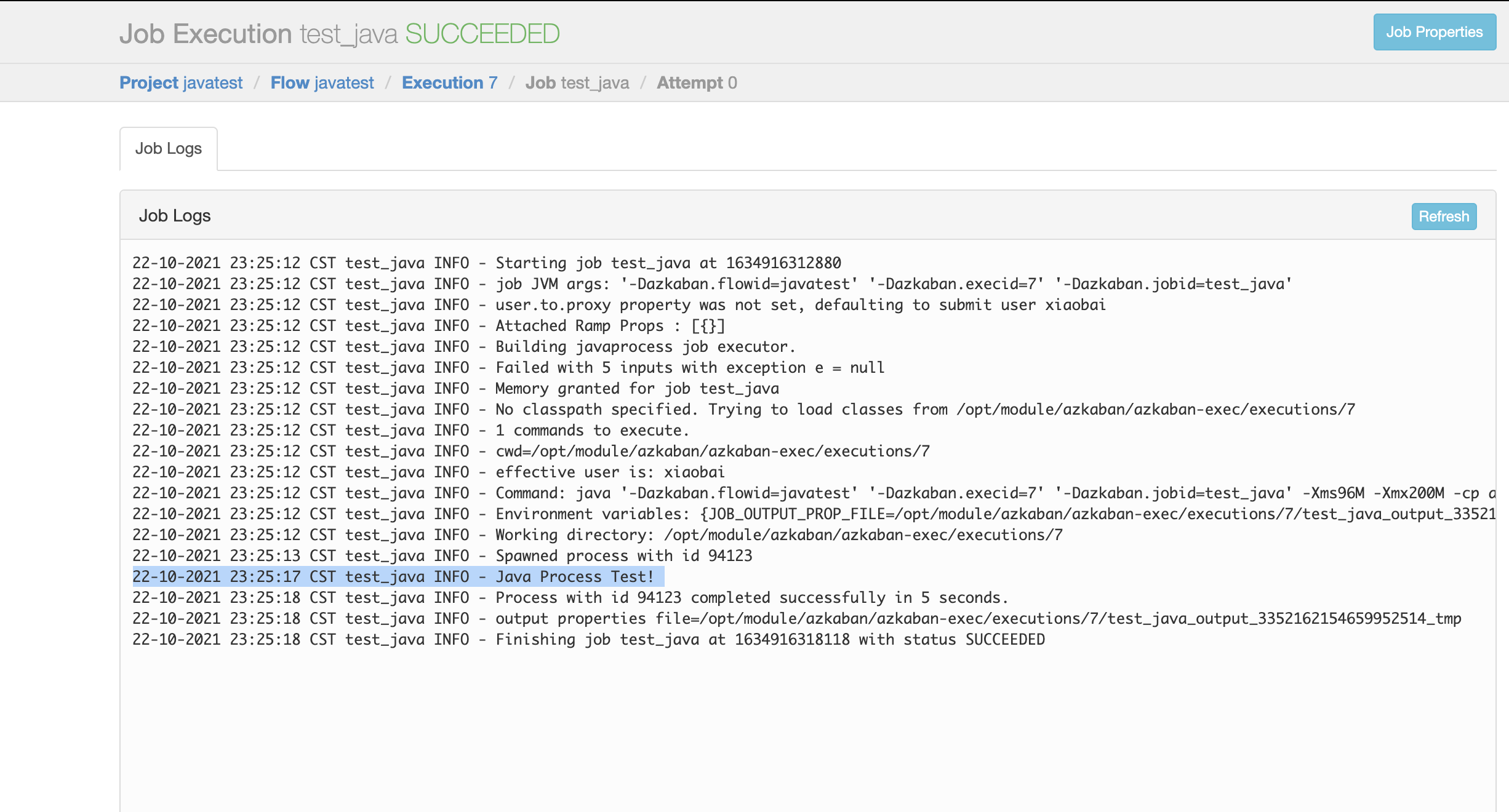
3.2 conditional workflow cases
The conditional workflow function allows users to customize execution conditions to decide whether to run some jobs. Conditions can consist of run-time parameters of the parent Job output of the current Job, or predefined macros can be used. Under these conditions, users can gain more flexibility in determining the Job execution logic. For example, as long as one of the parent jobs is successful, they can run the current Job.
3.2.1 runtime parameter cases
Basic principles
- Parent Job writes parameters to Job_ OUTPUT_ PROP_ The file pointed to by the file environment variable;
- The child Job uses ${jobName:param} to obtain the parameters of the parent Job output and define the execution conditions.
Supported conditional operators
- ==Equals
- != Not equal to
- >Greater than
- >=Greater than or equal to
- < less than
- < = less than or equal to
- &&And
- ||Or
- ! wrong
🌰:
Requirements:
JobA executes a shell script.
JobB executes a shell script, but JobB does not need to execute every day, but only every Monday.
realization:
- New JobA.sh:
#!/bin/bash
echo "do JobA"
wk=`date +%w`
echo "{\"wk\":$wk}" > $JOB_OUTPUT_PROP_FILE
- New JobB.sh:
#!/bin/bash echo "do JobB"
- New condition.flow:
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
dependsOn:
- JobA
config:
command: sh JobB.sh
condition: ${JobA:wk} == 1
Package JobA.sh, JobB.sh, condition.flow and frist.project into condition.zip; On Azkaban Web Client:
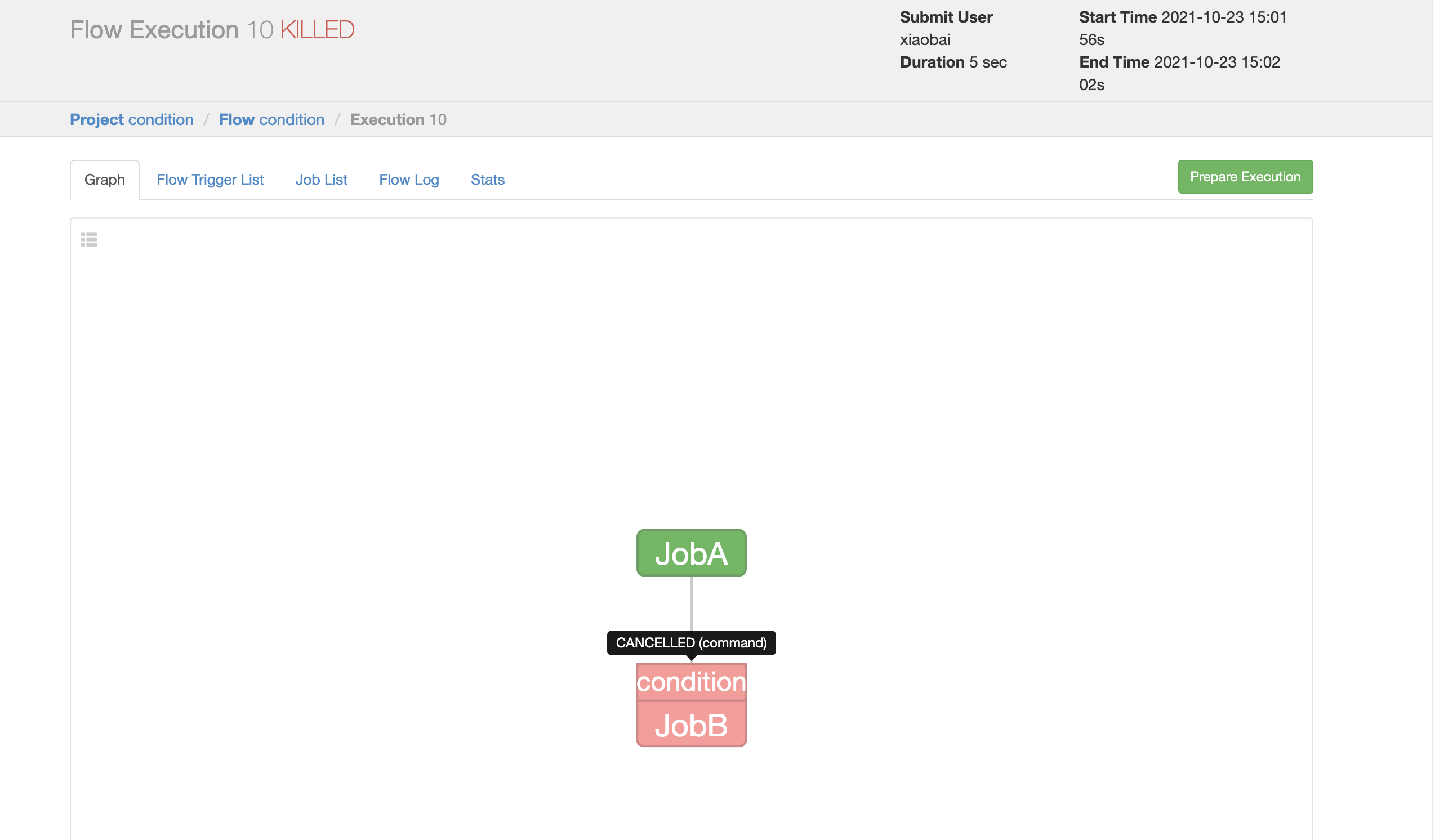
Job a is executed successfully and job B is cancelled. Job B will not be executed until Monday.
3.2.2 predefined macro cases
Several special judgment conditions are preset in Azkaban, which are called predefined macros.
The predefined macro will judge according to the completion of all parent jobs, and then decide whether to execute it; The predefined macros available are as follows:
- all_success: indicates that all parent jobs are executed successfully (default);
- all_done: indicates that the parent Job is not executed until it is completed;
- all_failed: indicates that all parent jobs failed before execution;
- one_success: indicates that at least one parent Job is executed successfully;
- one_failed: indicates that at least one parent Job failed to execute.
Requirements:
JobA executes a shell script;
JobB executes a shell script;
JobC executes a shell script that requires one of JobA and JobB to be executed successfully;
realization:
- Create a new JobA.sh:
#!/bin/bash echo "do JobA"
- Create a new JobC.sh:
#!/bin/bash echo "do JobC"
- Create a new macro.flow:
nodes:
- name: JobA
type: command
config:
command: sh JobA.sh
- name: JobB
type: command
config:
command: sh JobB.sh
- name: JobC
type: command
dependsOn:
- JobA
- JobB
config:
command: sh JobC.sh
condition: one_success
JobA.sh, JobC.sh, macro.flow and frist.project files are packaged into macro.zip; On Azkaban Web Client:
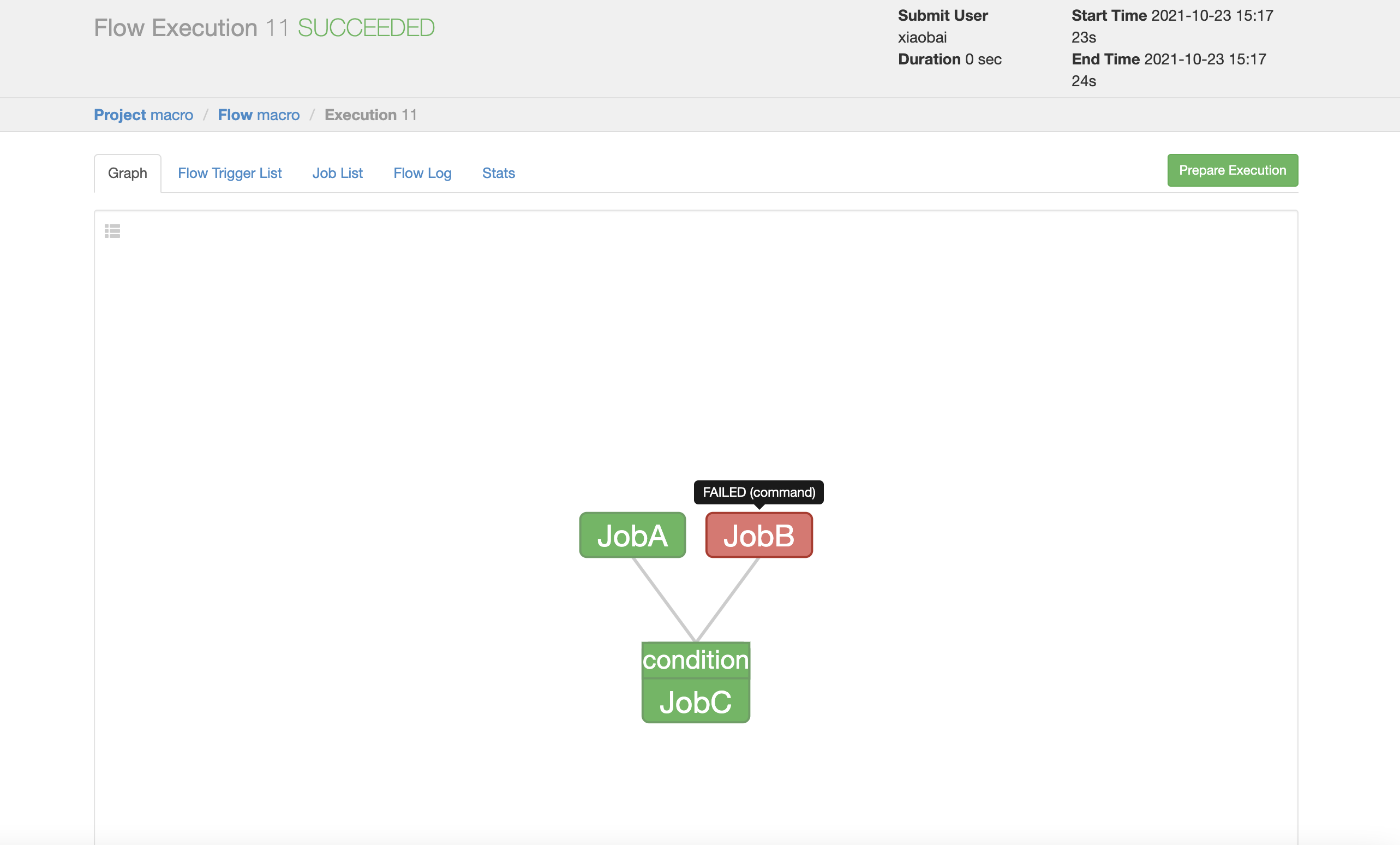
JobA success,JobB fail,JobC success!
3.3 regular execution cases
Requirements:
JobA is executed every 1 minute;
realization:
When executing the workflow, select Schedule in the lower left corner
Fill in timing rules:
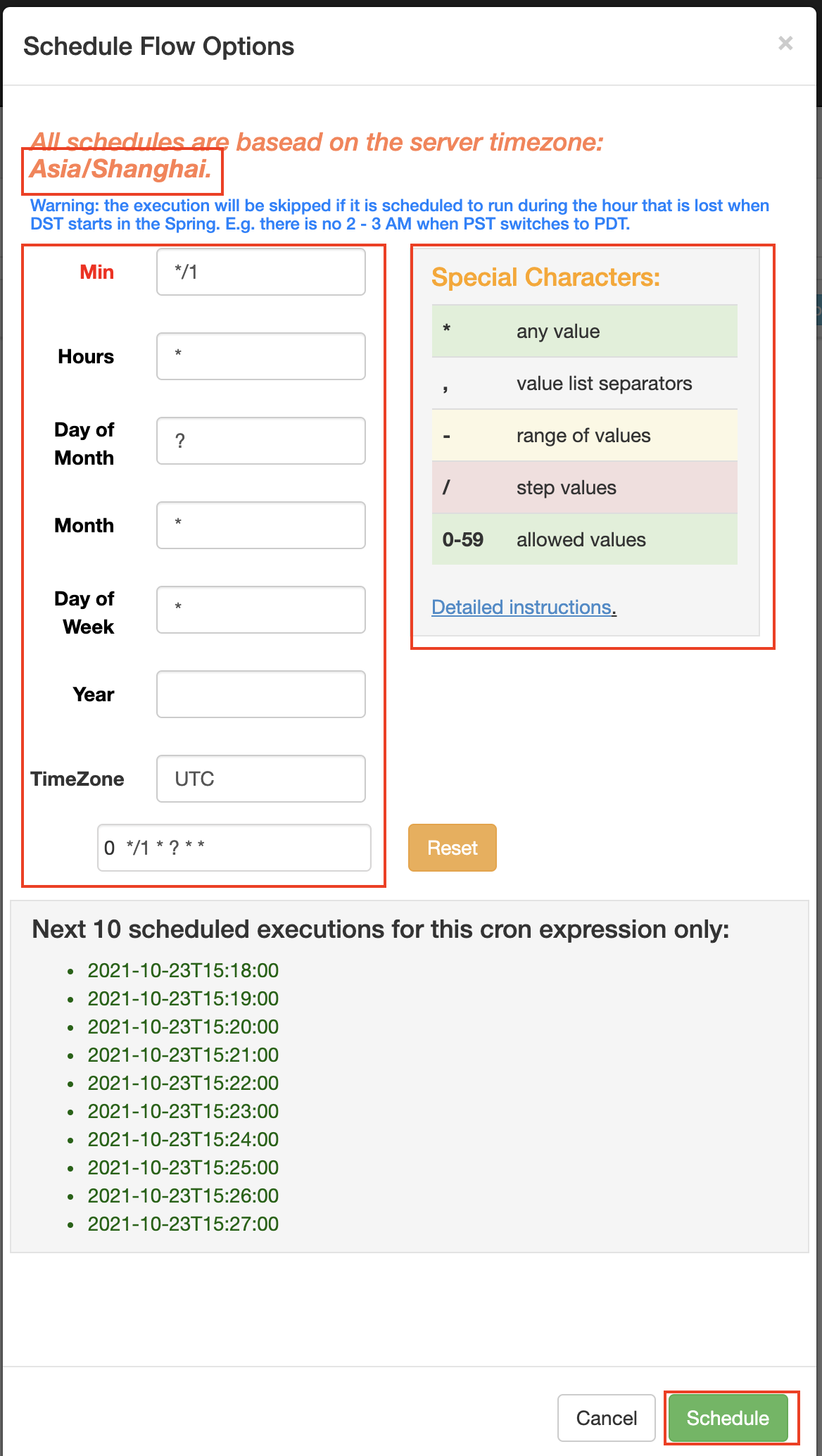
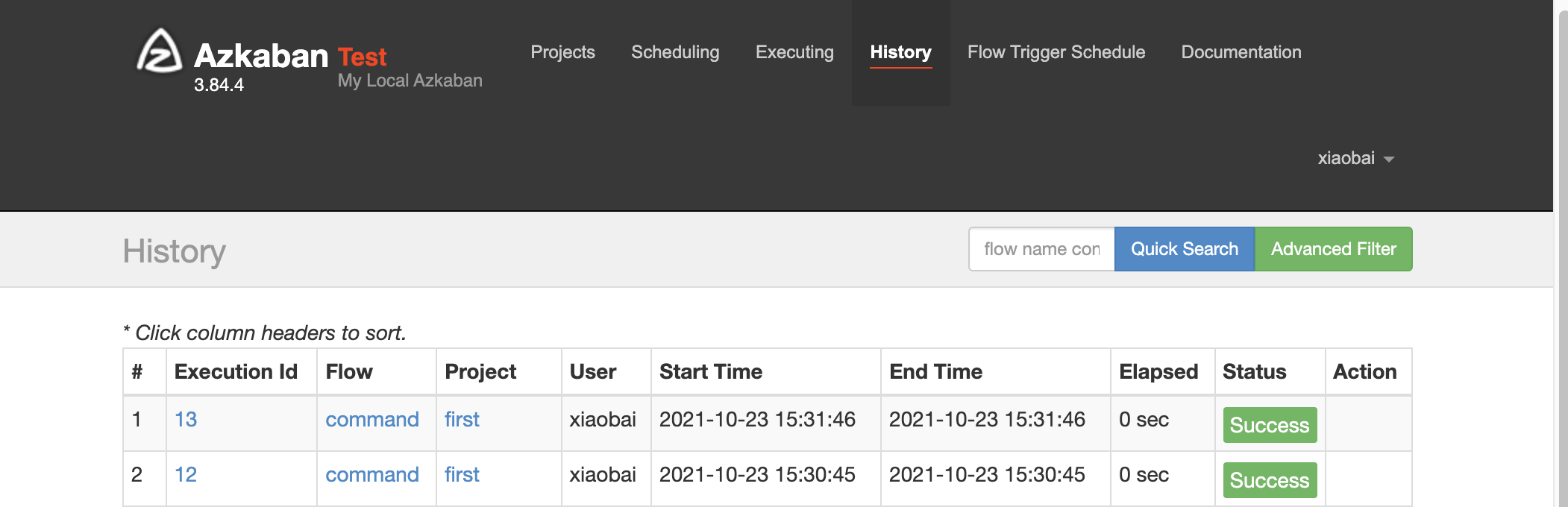
You can view the execution of first in history, and execute it every one minute:
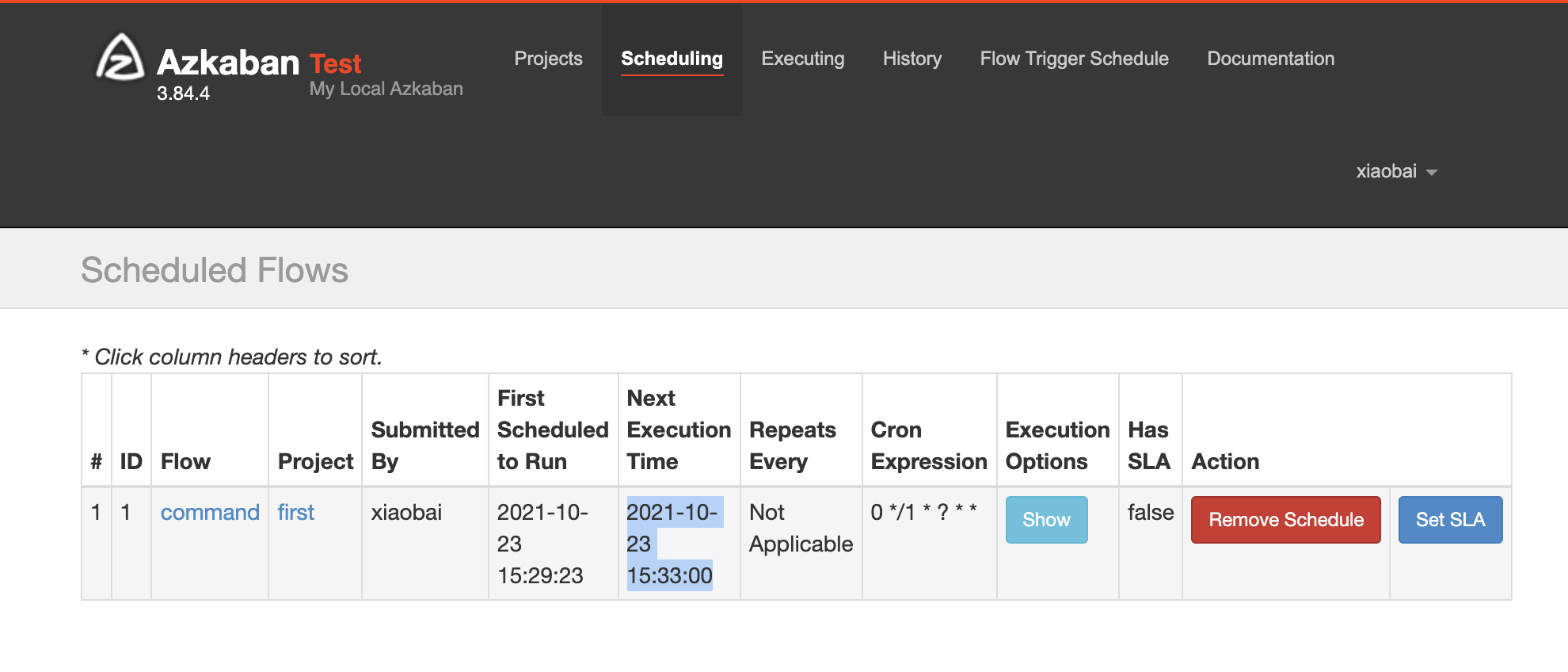
Next execution time is available in the scheduling to view the next execution time and remove the scheduled task:
3.4 email alarm cases
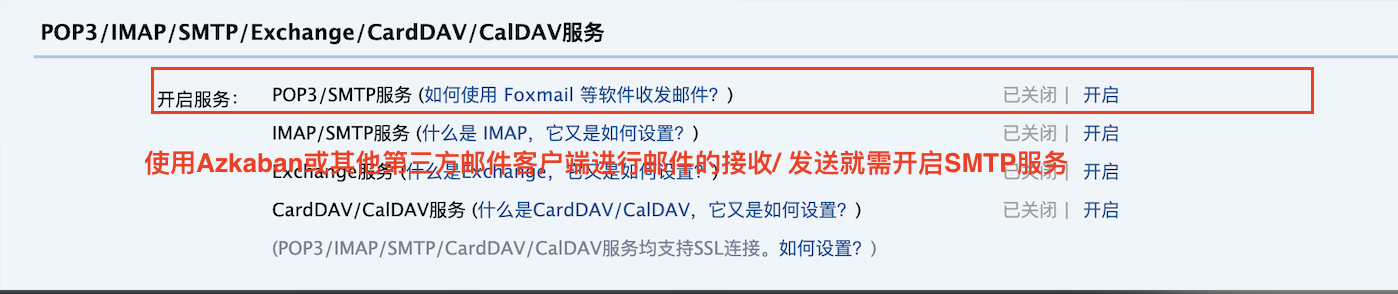
3.4.1 log in to the mailbox and start SMTP
Open the SMTP service in the email account:
Copy authorization code:
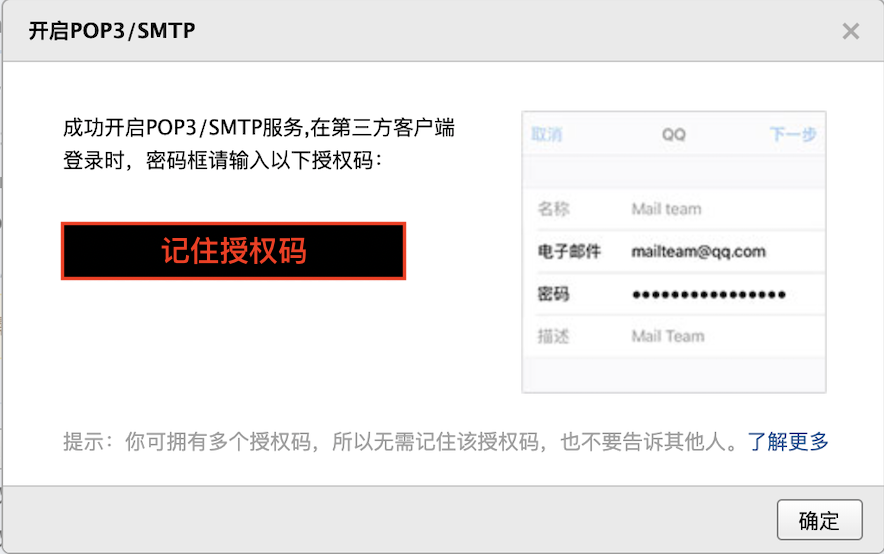
3.4.2 default mail alarm cases
Azkaban supports the alarm of failed tasks by mail by default. The configuration method is as follows:
- Modify the azkaban.properties file in the / opt / module / Azkaban / Azkaban Web / conf Directory:
[xiaobai@hadoop102 conf]$ vim azkaban.properties
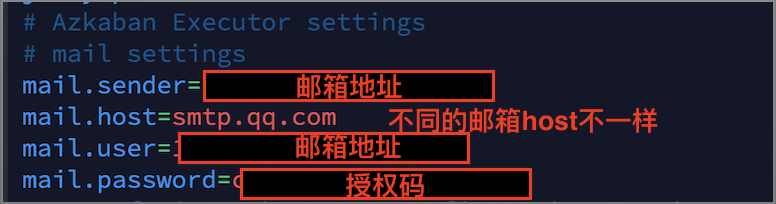
- To restart the web server:
[xiaobai@hadoop102 azkaban-web]$ bin/shutdown-web.sh [xiaobai@hadoop102 azkaban-web]$ bin/start-web.sh
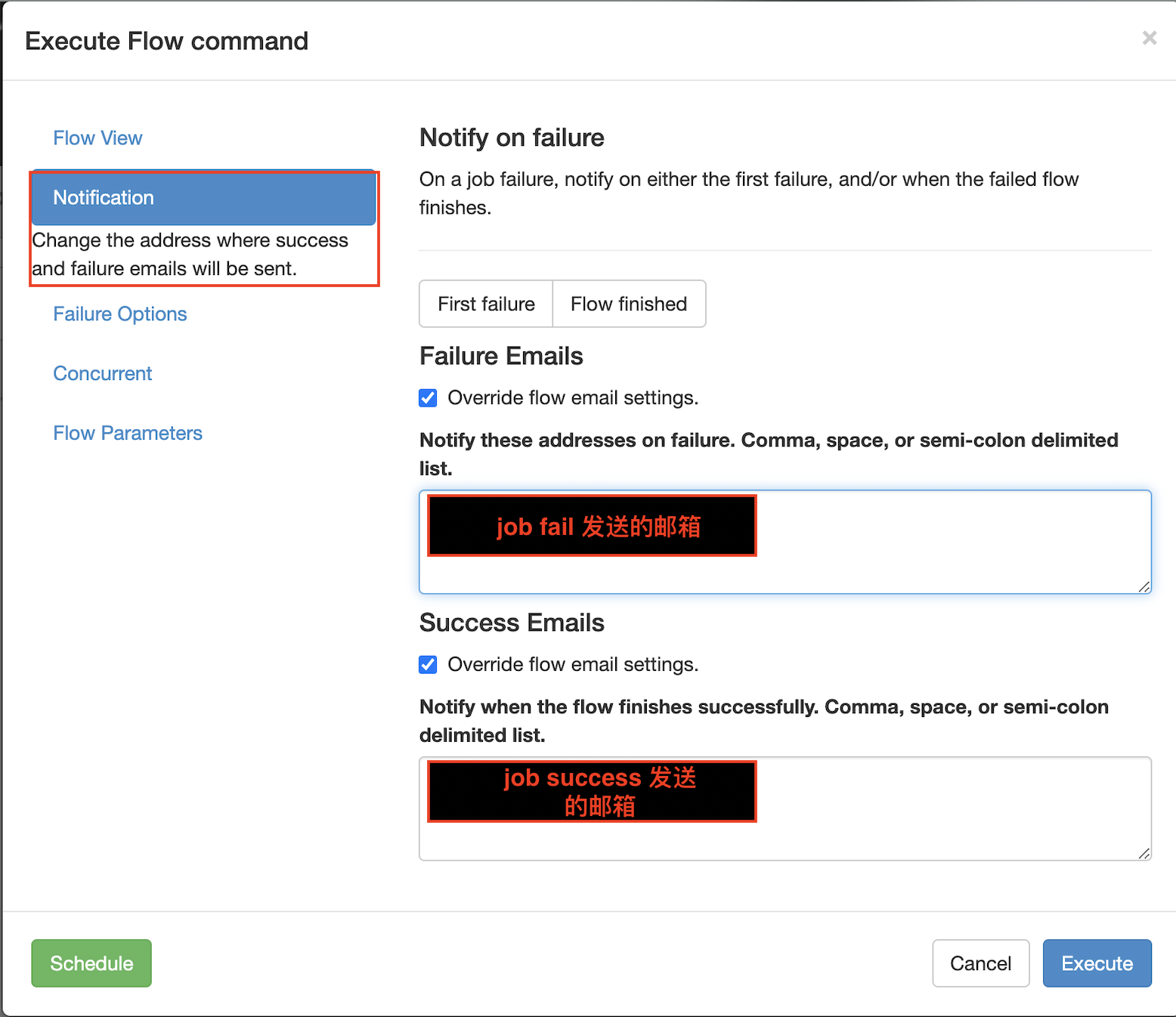
3.5 telephone alarm cases
3.5.1 third party alarm platform integration
Sometimes the email alarm is not received in time after task execution fails, so other alarm methods may be required, such as telephone alarm.
At this time, it can be integrated with a third-party alarm platform, such as Ruixiang cloud.
- Official website address:
https://www.aiops.com/ - Integrated alarm platform, integrated by Email;
- After obtaining the email address, you need to send the alarm information to the email;
- Configurable dispatch policy / notification policy;
notes ⚠️: If you want to use the Ruixiang cloud integration mode, the QQ mailbox is not available, and the email address needs to be modified.
3.5.2 precautions for Azkaban multi Executor mode
Azkaban multi Executor mode means that executors are deployed on multiple nodes in the cluster. In this mode, Azkaban web Server will select one of the executors to perform tasks according to the policy.
In order to ensure that the selected Executor can perform tasks accurately, we must choose one of the following two schemes, and scheme 2 is recommended.
Scheme I:
Specify a specific executor (Hadoop 102) to execute the task.
-
In the azkaban database executors table in MySQL, query the id of the Executor on Hadoop 102;

-
Add useExecutor attribute when executing workflow:
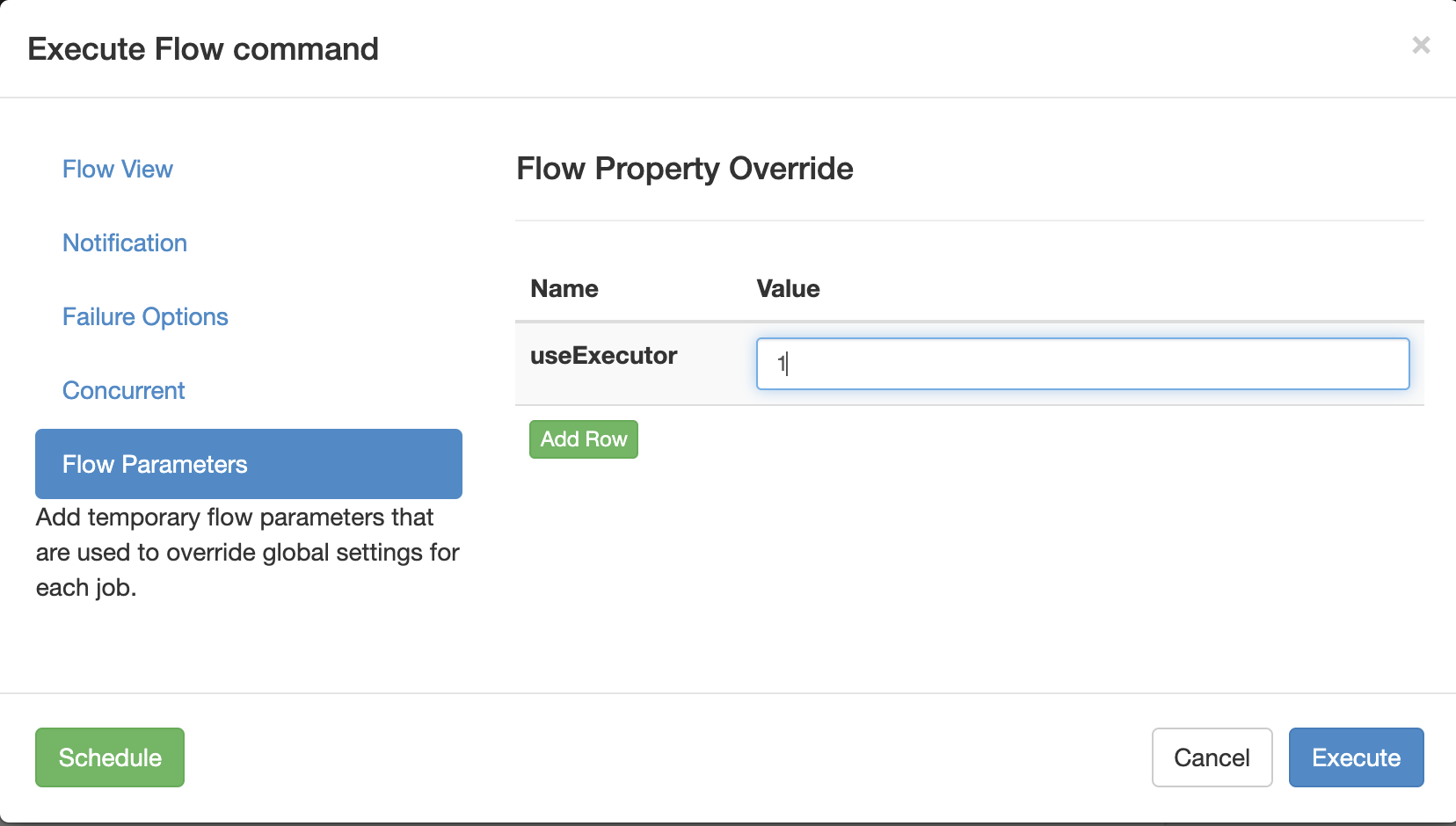
Scheme II ⭐ ️:
Deploy scripts and applications required for tasks on all nodes where the Executor is located.