Azkaban is a batch workflow task scheduler launched by Linkedin company. It is mainly used to run a group of work and processes in a specific order in a workflow. Its configuration is to set dependencies through simple < key, value > pairs and dependencies in the configuration. Azkaban uses job profiles to establish dependencies between tasks and provides an easy-to-use Web user interface to maintain and track your workflow.
Before introducing Azkaban, let's take a look at two existing workflow task scheduling systems. Apache Oozie should be well-known, but its workflow configuration process is to write a large number of XML configurations, and the code complexity is relatively high, which is not easy to secondary development. Another widely used scheduling system is Airflow, but its development language is Python. Because our team uses Java as the mainstream development language, it was eliminated when selecting the model.
The reasons for choosing Azkaban are as follows:
- Provide a clear and easy-to-use Web UI interface
- Provide job configuration files to quickly establish dependencies between tasks
- Provide modular and pluggable plug-in mechanism, and support command, Java, Hive, Pig and Hadoop=
- Based on Java development, the code structure is clear and easy for secondary development
1, Applicable scenario
In practice, there are often these scenarios: there is A big task every day, which can be divided into four small tasks A,B, C and D. there is no dependency between tasks A and B. task C depends on the results of tasks A and B, and task D depends on the results of task C. The general practice is: open two terminals to execute A and B at the same time, execute C after both are executed, and finally execute D. In this way, the whole execution process needs manual participation, and we have to keep an eye on the progress of each task. However, many of our tasks are executed in the middle of the night. We write scripts to set the crontab to execute. In fact, the whole process is similar to A directed acyclic graph (DAG). Each subtask is equivalent to A flow in A large task. The starting point of the task can be executed from the node without degree, and any node without path can be executed at the same time, such as A and B above. To sum up, what we need is A workflow scheduler, and azkaban is A scheduler that can solve the above problems.
2, Structure
Azkaban is implemented on LinkedIn to solve the Hadoop job dependency problem. From ETL work to data analysis products, the work needs to be run in sequence. It was originally a single server solution. With the increase of Hadoop users over the years, Azkaban has developed into a more powerful solution.
Azkaban consists of three key components:
- metadata
- AzkabanWebServer
- AzkabanExecutorServer
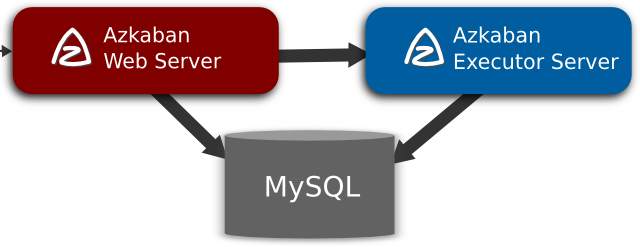
2.1 metadata
Azkaban uses a relational database to store metadata and execution status.
AzkabanWebServer
- Project management: project, project permissions and uploaded files.
- Job status: track the execution process and the process in which the execution program is running.
- Previous processes / jobs: search through previous jobs and process execution and access to their log files.
- Scheduler: keeps the status of scheduled jobs.
- SLA: maintain all SLA rules
AzkabanExecutorServer
- Access project: Retrieves project files from the database.
- Execute process / job: retrieve and update the data of the executing job flow
- Log: store the output logs of jobs and workflows in the database.
- Interdependencies: if a workflow runs on different executors, it will get the status from the database.
2.2 AzkabanWebServer
Azkaban webserver is the main manager of the whole Azkaban Workflow system. It is responsible for a series of tasks, such as Project management, user login authentication, regularly executing Workflow, tracking Workflow execution progress and so on. At the same time, it also provides a Web service operation interface. Using this interface, users can use curl or other Ajax methods to perform Azkaban related operations. The operations include: user login, create Project, upload Workflow, execute Workflow, query Workflow execution progress, kill Workflow and a series of operations, and the return results of these operations are in JSON format. Moreover, Azkaban is easy to use, and Azkaban is easy to use Job is a key value attribute file with suffix name to define each task in the Workflow, and the dependencies attribute is used to define the dependency chain between jobs. These job files and associated code are ultimately expressed in * Upload to the Web server via Azkaban UI in the form of zip.
2.3 AzkabanExecutorServer
Previous versions of Azkaban have Azkaban webserver and Azkaban executorserver functions in a single service. At present, Azkaban has separated Azkaban executorserver into independent servers. The reasons for splitting Azkaban executorserver are as follows:
- After a task flow fails, it is easier to re execute it
- Easy Azkaban upgrade
Azkaban executorserver is mainly responsible for the submission and execution of specific workflows. It can start multiple execution servers, which coordinate the execution of tasks through relational databases.
3, Job flow execution process
- WebServer selects an executor to distribute the job flow according to the resource of each executor cached in memory (a thread of WebServer will traverse each Active Executor to send an Http request to obtain its resource status information and cache it in memory), and according to the selection strategy (including executor resource status, number of recent execution streams, etc.);
- The Executor determines whether to set the job granularity allocation. If the job granularity allocation is not set, all jobs will be executed in the current Executor; If job granularity allocation is set, the current node will become the decision-maker of job allocation, that is, the allocation node;
- The allocation node obtains the resource status information of each Executor from Zookeeper, and then selects an Executor allocation job according to the policy;
- The Executor assigned to the job becomes the execution node, executes the job, and then updates the database.
4, Three operation modes of Azkaban architecture
In version 3.0, Azkaban provides the following three modes:
- solo server mode: the simplest mode. The built-in H2 database, Azkaban webserver and Azkaban executorserver run in the same process. This mode can be adopted for projects with a small amount of tasks.
- two server mode: the database is MySQL. The management server and execution server are in different processes. In this mode, Azkaban webserver and Azkaban executorserver do not affect each other.
- multiple executor mode: in this mode, Azkaban webserver and Azkaban executorserver run on different hosts, and there can be multiple Azkaban executorservers.
At present, we use multiple executor mode to deploy multiple Azkaban executorservers on different hosts to cope with the execution of highly concurrent scheduled tasks, so as to reduce the pressure of a single server. WebServer and ExecutorServer synchronize the solo configuration.
Edit build Gradle add code block
from('../azkaban-solo-server/build/resources/main/conf') {
into 'conf'
}
from('../azkaban-solo-server/src/main/resources/commonprivate.properties') {
into 'plugins/jobtypes'
}
from('../azkaban-solo-server/src/main/resources/log4j.properties') {
into ''
}
from('../azkaban-solo-server/src/main/resources/commonprivate.properties') {
into ''
}
Build and install
./gradlew installDist
5, Use
5.1 create project
After entering Azkaban, you will see the project page. This page displays a list of all items with READ permissions. Only items with group permissions or with READ or ADMIN roles appear.
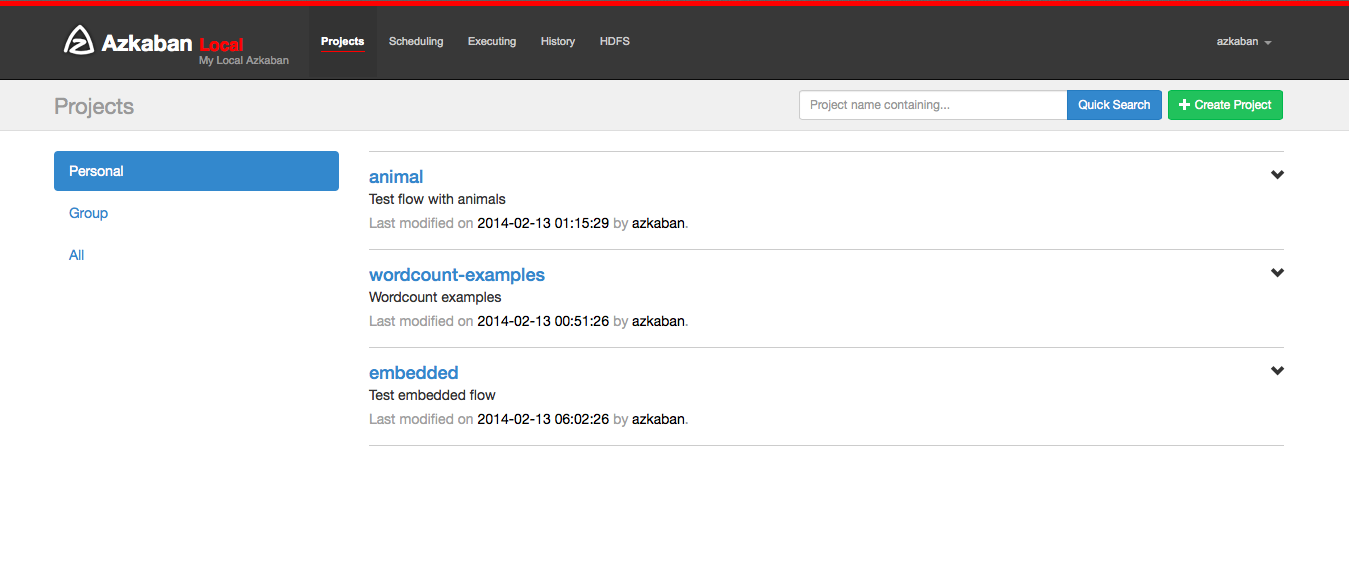
Click create project to pop up a dialog box. Enter the unique project name and description of the project. The project name must start with an English letter and can only contain numbers, English letters, underscores and horizontal lines. You can change the description later, but the project name cannot. If you do not see this button, the possibility of creating a new item is locked except for users with appropriate permissions.
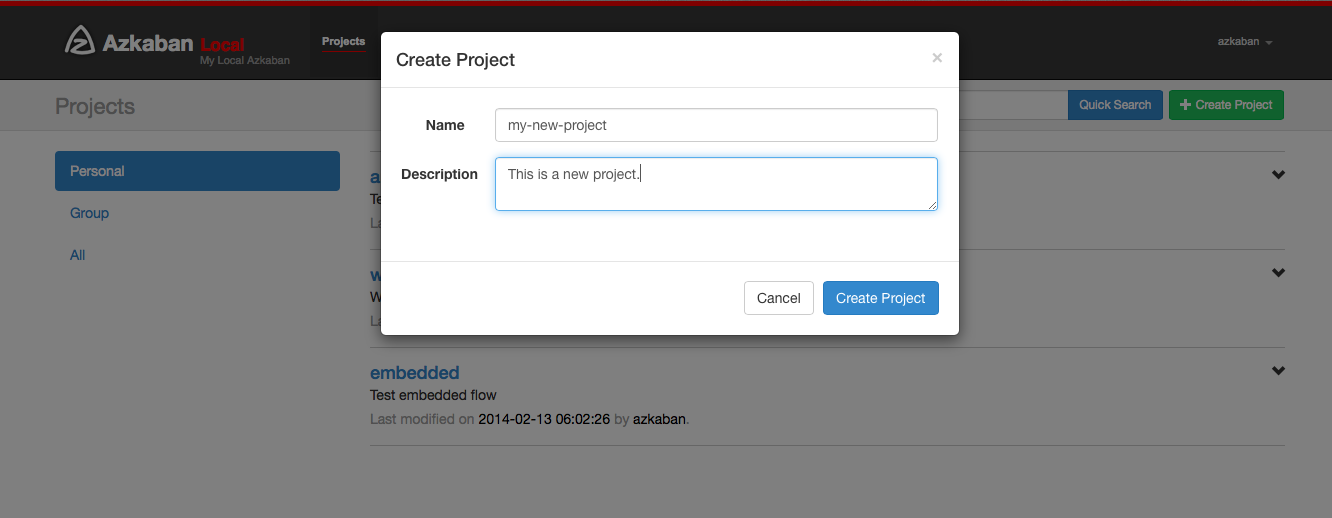
If you have the appropriate permissions (which you should have if you create a project), you can delete the project from the page, update the description, upload files, and view the project log.
5.2 upload items
Click the upload button. You will see the following dialog box.
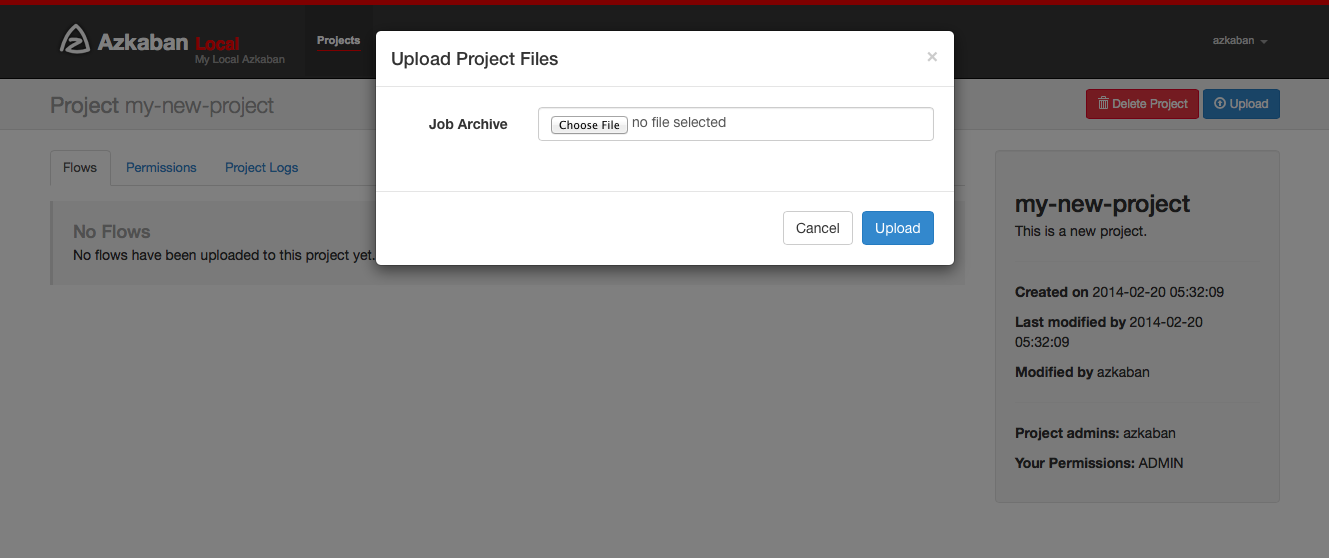
Select the archive file to upload the workflow file. Currently, Azkaban only supports Zip file. The zip should contain The files and any files required by the job to run the job. The job name must be unique in the project. Azkaban will validate the contents of the zip to ensure that the dependencies are met and that no circular dependencies are detected. If any invalid workflow is found, the upload will fail. Upload overwrites all files in the project. After uploading the new zip file, any changes made to the job will be cleared.
5.3 workflow view
You can go to the process view page by clicking the process link. From here, you will see a graphical representation of the process. The left panel contains a list of jobs in the process. Right clicking a job in the right panel or a node in the drawing allows you to open a single job. You can also plan and execute processes from this page.
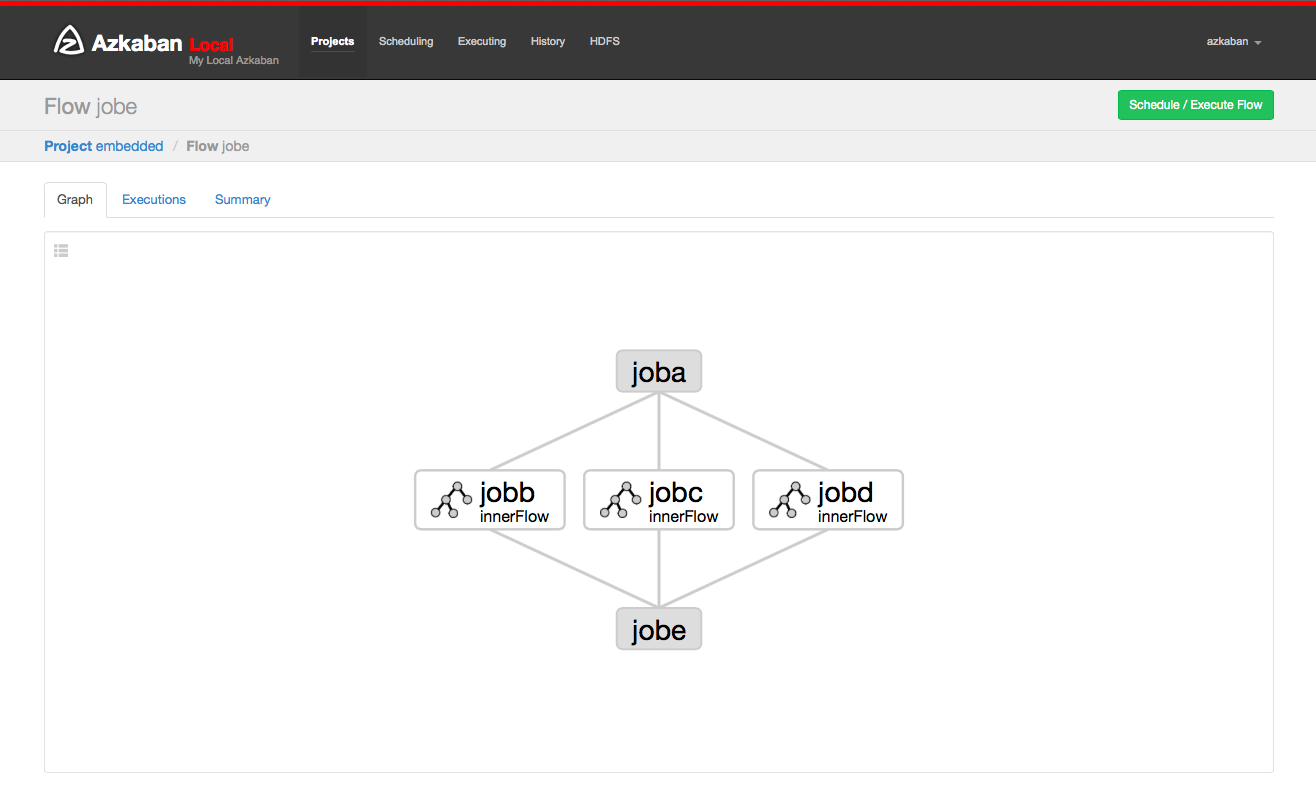
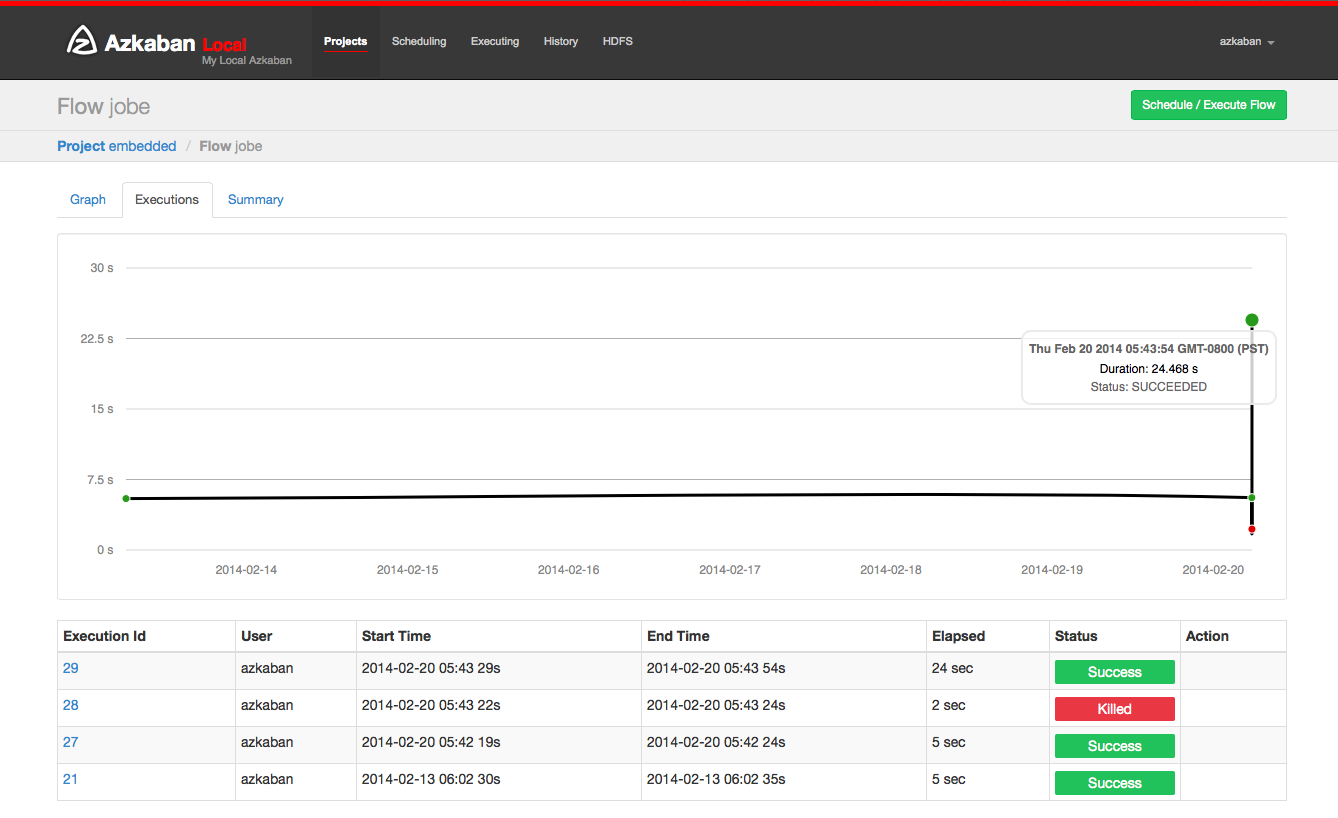
Click the execution tab to display all execution records of this process.
5.4 Project Authority
When a project is created, the creator will automatically give ADMIN status on the project. This allows the creator to view, upload, change jobs, run processes, delete, and add user permissions to the project. Administrators can delete other administrators, but cannot delete themselves. This prevents the project from becoming an administrator unless the administrator is deleted by a user in the management role. The permissions page is accessible from the project page. On the permissions page, administrators can add other users, groups, or proxy users to the project.
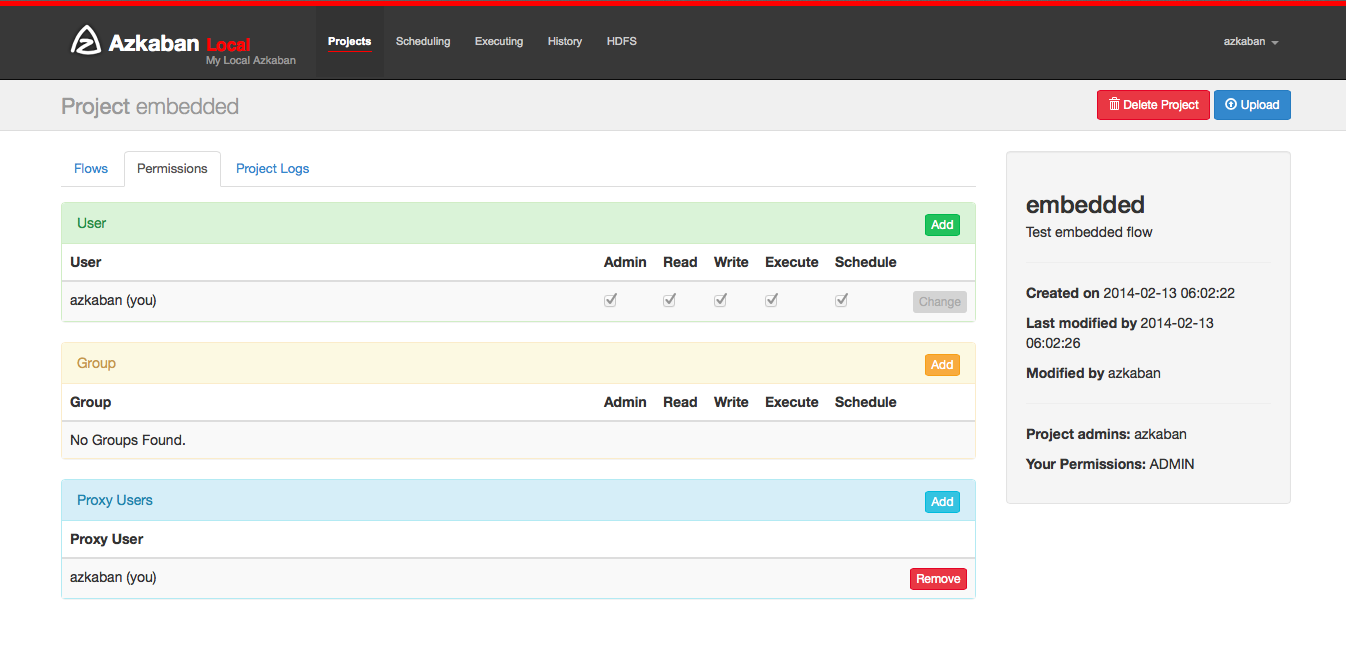
- Add user permissions give these users the permissions specified for the project. Delete user permissions by unchecking all permissions.
- Group permissions allow everyone in a specific group to specify permissions. Delete group permissions by unchecking all group permissions.
- If the proxy user is open, the proxy user allows the project workflow to run as these users. This helps lock out which headless account jobs can be proxied. After adding, click the "delete" button to delete it.
- Each user is authenticated through UserManager to prevent invalid users from being added. Groups and proxy users also check to make sure they are valid and see if administrators are allowed to add them to the project.
You can set the following permissions for users and groups:
| jurisdiction | describe |
|---|---|
| ADMIN | The highest authority, including adding and modifying permissions to other users |
| READ | You can only access the content and log information of each Project |
| WRITE | You can upload and modify task properties in the created Project, and delete any Project |
| EXECUTE | Allow users to perform any workflow |
| SCHEDULE | Allows users to add and delete scheduling information of any workflow |
| CREATEPROJECTS | If the project creation is locked, the user is allowed to create a new project |
5.5 execution process view
From the process view panel, you can right-click the drawing and disable or enable the job. Residual jobs are disabled during execution, just like their dependencies. Residual jobs are displayed translucent.
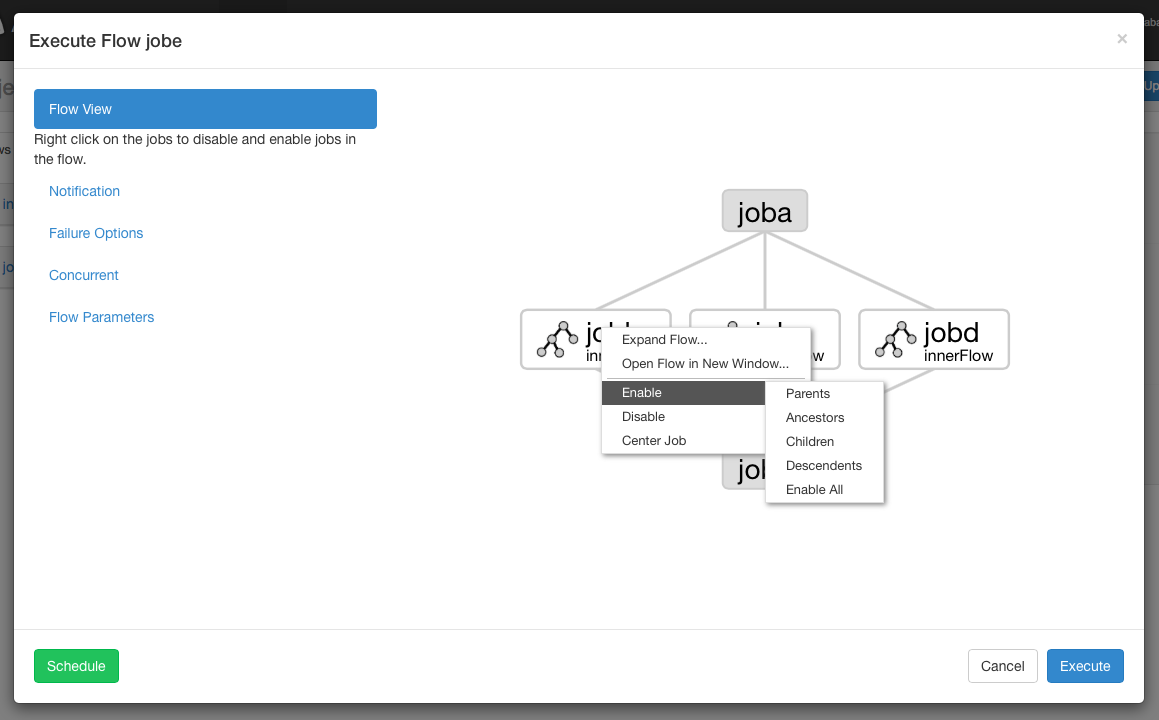
Notification options: notification options allow users to change the success or failure notification behavior of the process.
5.5.1 failure notification
- Fault: Send a fault email when a fault is detected.
- Process completion: if a process's job fails, it will send a failure email after all jobs in the process are completed.
5.5.2 email coverage
Azkaban will use the default notification email set in the final job in the stream. If it is overwritten, the user can change the e-mail address of the e-mail that failed to send or successfully sent. Lists can be separated by commas, spaces, or semicolons.
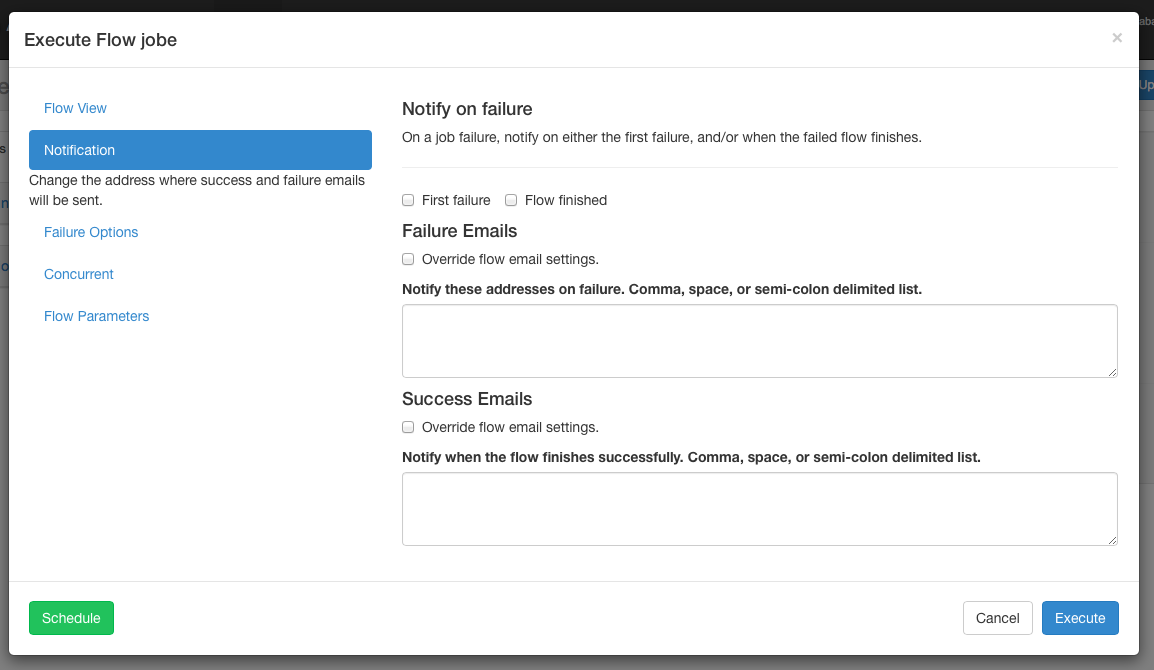
5.5.3 fault options
When a job in a process fails, you can control how the rest of the process succeeds.
- Completing the current run will complete the currently running job, but will not start a new job. Once FAILED FINISHING is completed, the process will be placed in status and set to failed.
- Canceling all will immediately terminate all running jobs and set the status of the execution process to FAILED.
- Complete all jobs that may continue to execute in the process as long as their dependencies are met. Once FAILED FINISHING is completed, the process will be placed in status and set to failed.

5.5.4 concurrency options
If the flow execution is called when the flow executes at the same time, multiple options can be set.
- If the execute option is already running, the flow will not run.
- The run concurrency option runs the process whether it is running or not. Execute different working directories.
- The pipeline runs the process in a new way that does not exceed concurrent execution.
- Level 1: execute the block of job A until job A of the previous process is completed.
- Level 2: execute the block of job A until the child of job A in the previous process has completed. This is useful if you need to run the process after the executed process.
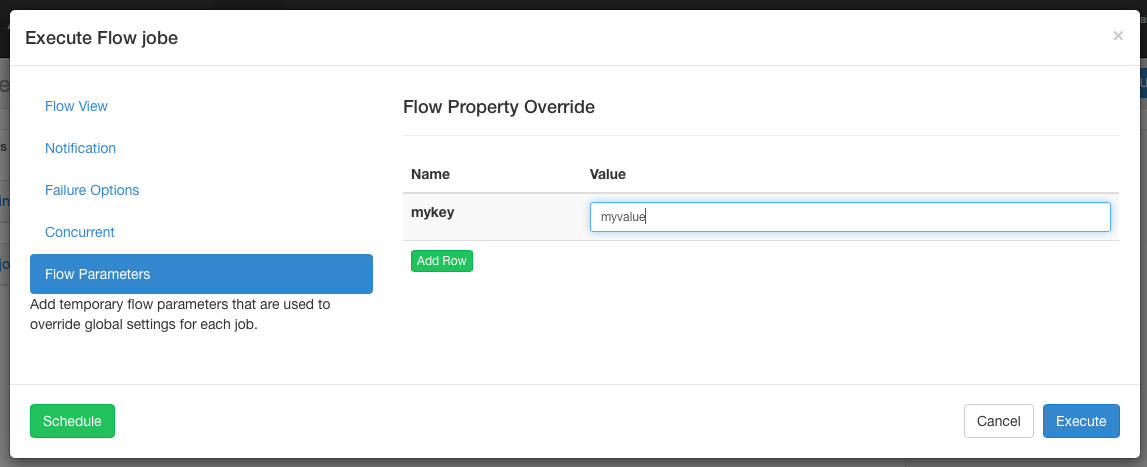
5.5.5 workflow options
Allows users to override workflow parameters. Workflow parameters override the global properties of the job, not the properties of the job itself
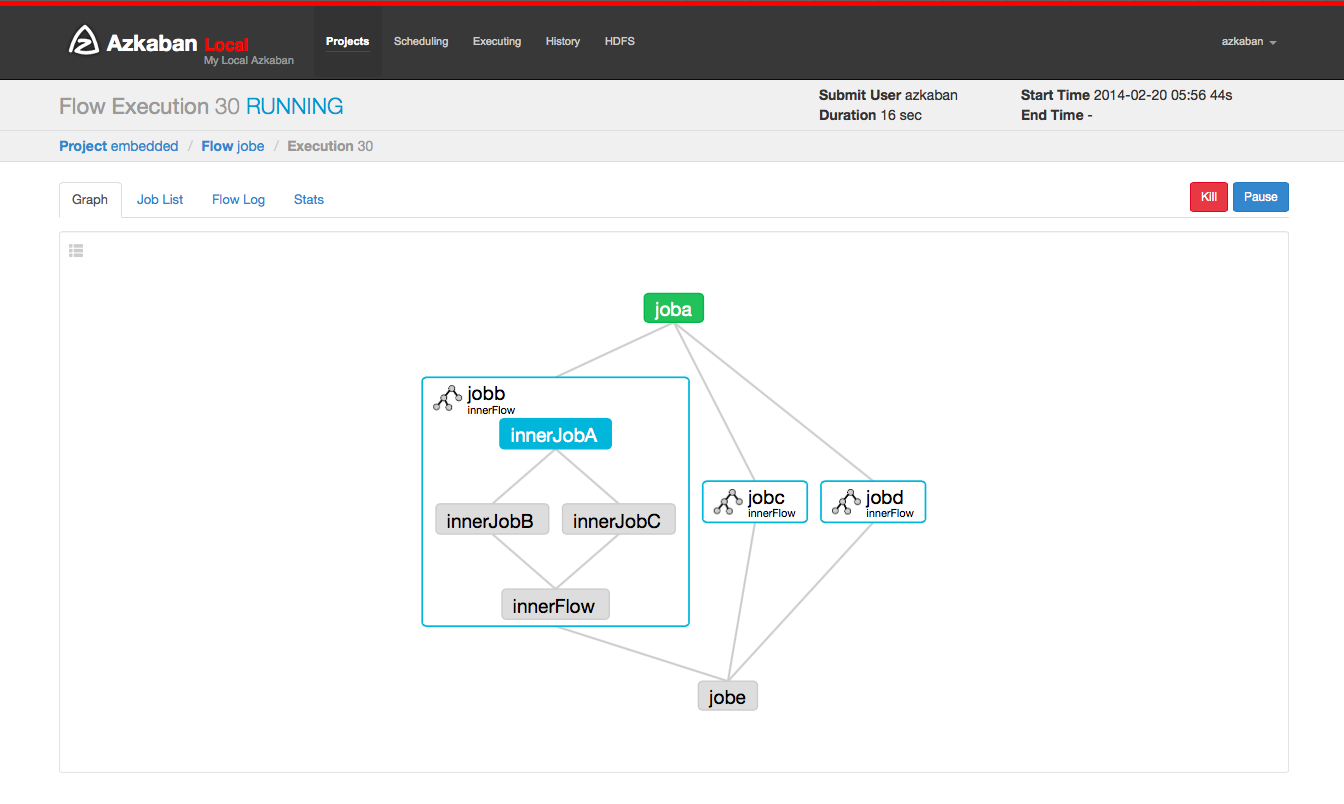
5.6 execution
On the submit execution process page, or select the execution process from the execution tab of the process view page. The history page or the execution page access these process records. This page is similar to the process view page, but displays the status of the running job.
Selecting a work list will give a timetable for performing the work. You can access jobs and job logs directly from this list.
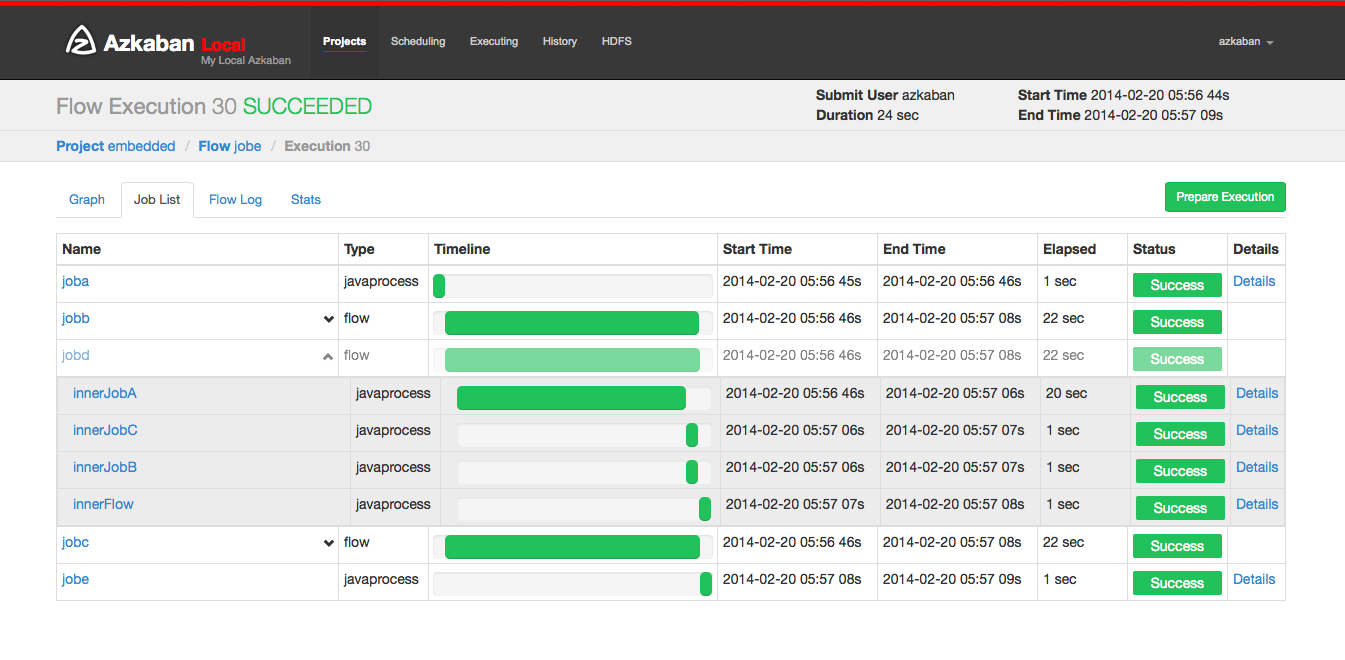
As long as the execution is not completed, the page will be automatically updated.
Some options that can be executed on the execution process include:
- Cancel: kill all running jobs and fail immediately. The flow state will be killed.
- Pause: prevents new jobs from running. The currently running jobs proceed as usual.
- Resume: resume suspended execution.
- Retry FAILED: available only when the process is in FAILED FINISHING state. When the process is still active, retrying will restart all FAILED jobs. Try appears on the job list page.
- Ready for execution: available only in completed processes, whether successful or failed. This will automatically disable jobs that have completed successfully.
5.7 execution page
Click the execute tab in the title to display the * * execute * * page. This page displays the currently running execution and the most recently completed process.
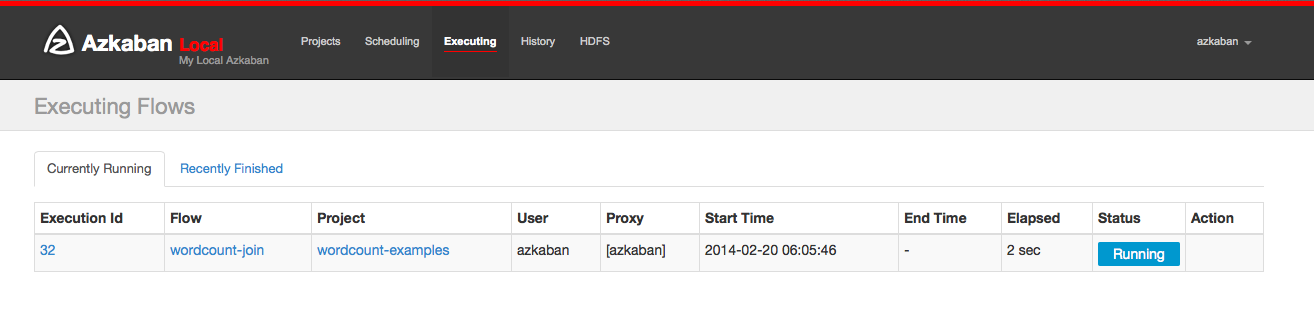
5.8 History page
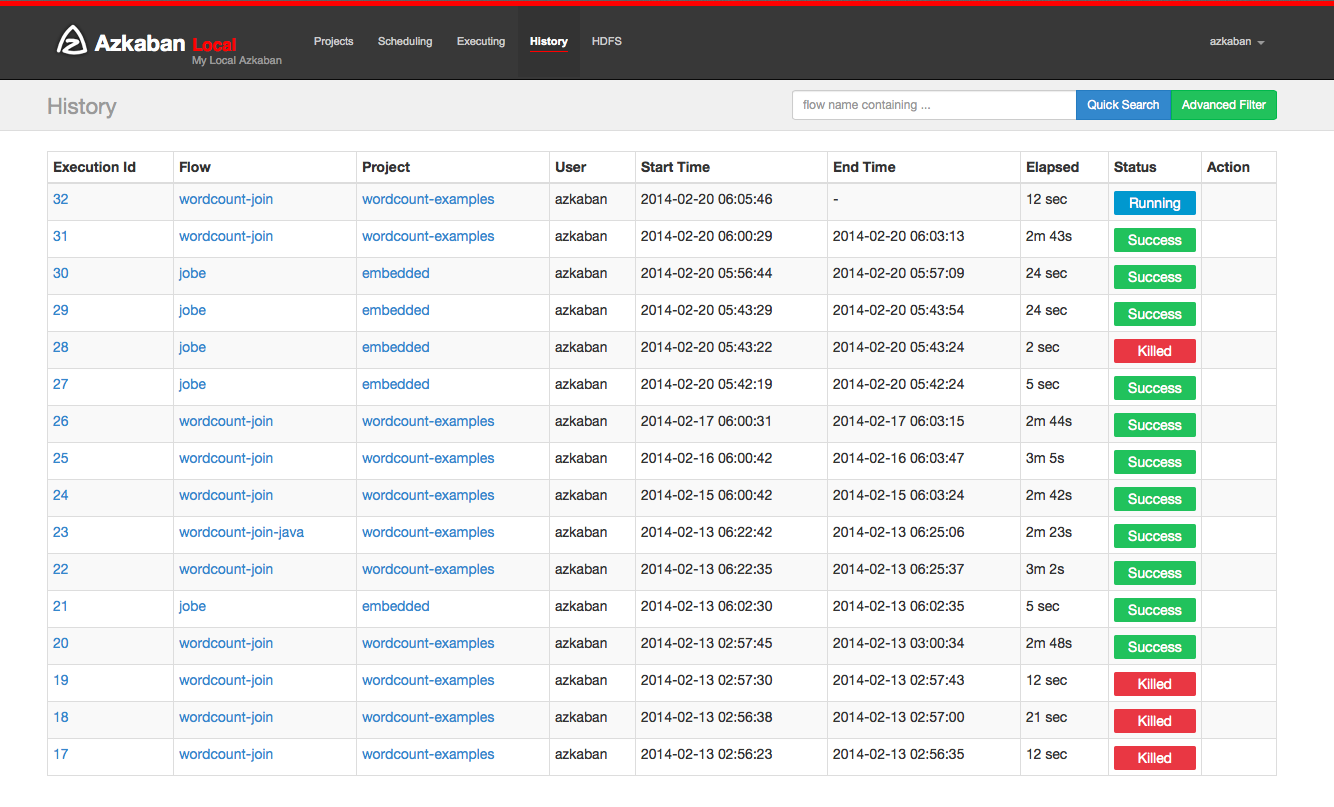
The currently executing process and the completed execution program will be displayed in the history page. Provides search options to find the execution you want to find. Alternatively, you can view previously executed processes on the flow tab.
5.9 planning process
From the same panel used to execute the process, the process can be scheduled by clicking the Schedule button.
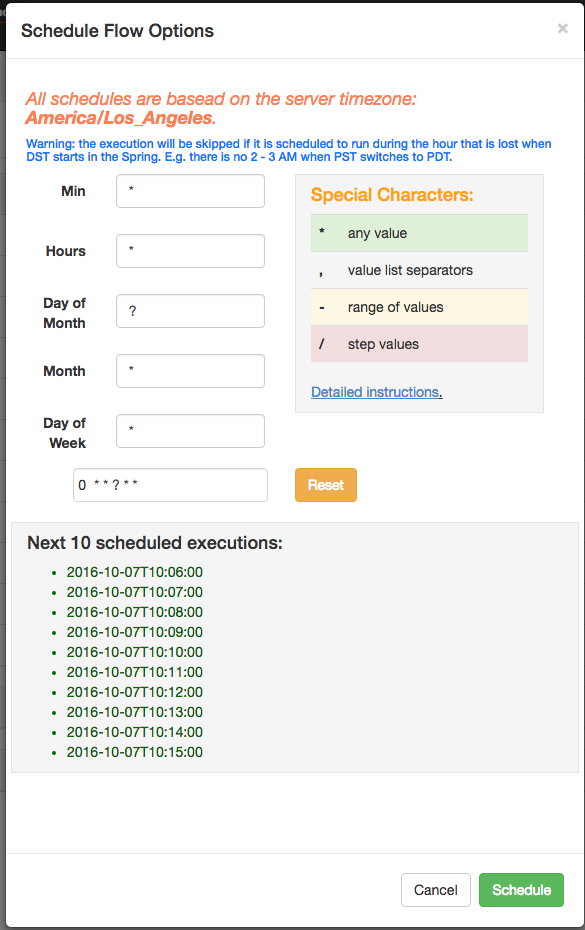
Any set of flow options will be reserved for the scheduled flow. For example, if a job is disabled, the job of the scheduled process will also be disabled.
Using the new flexible scheduling function in Azkaban 3.3, users can define a cron job after the Quartz syntax. An important change from Quartz or cron is that Azkaban operates at most with the smallest granularity. Therefore, the second field in the UI is marked as static "0". The flexible timetable encyclopedia explains how the details are used.
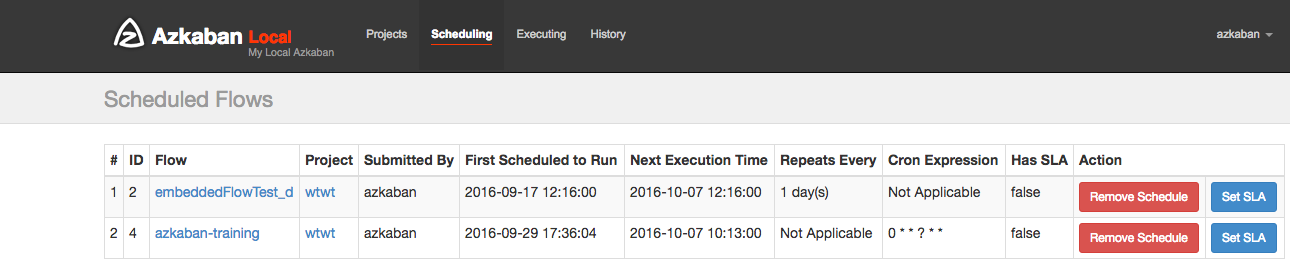
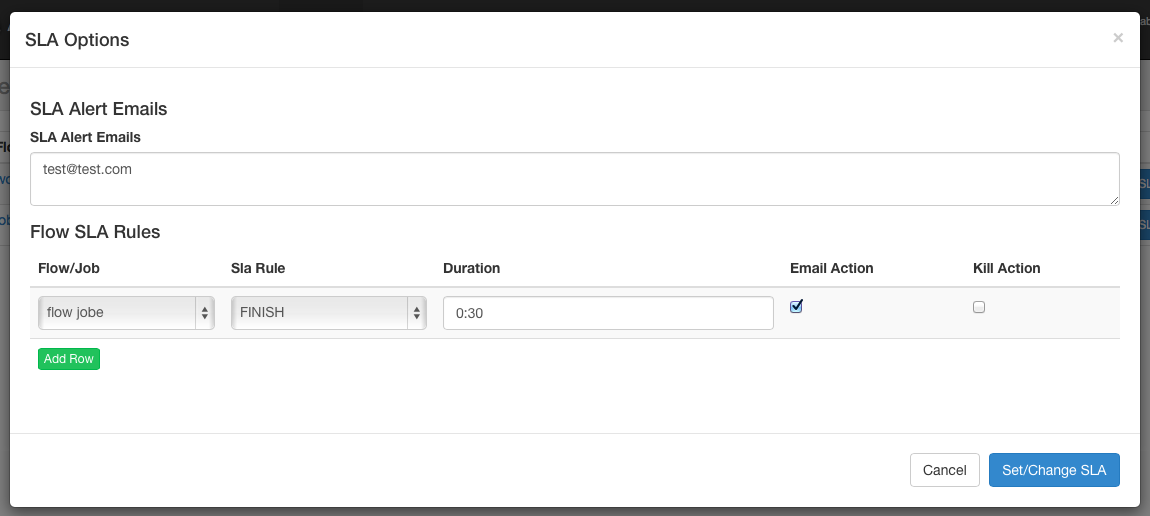
Once scheduled, it should appear on the schedule page where you can delete scheduled jobs or set SLA options.
5.10 SLA
To add an SLA notification or preemption, click the SLA button. From here you can set up SLA alert email. Rules can be added and applied to a single job or process itself. If the duration threshold is exceeded, you can set the alert email, otherwise the process may be killed automatically.
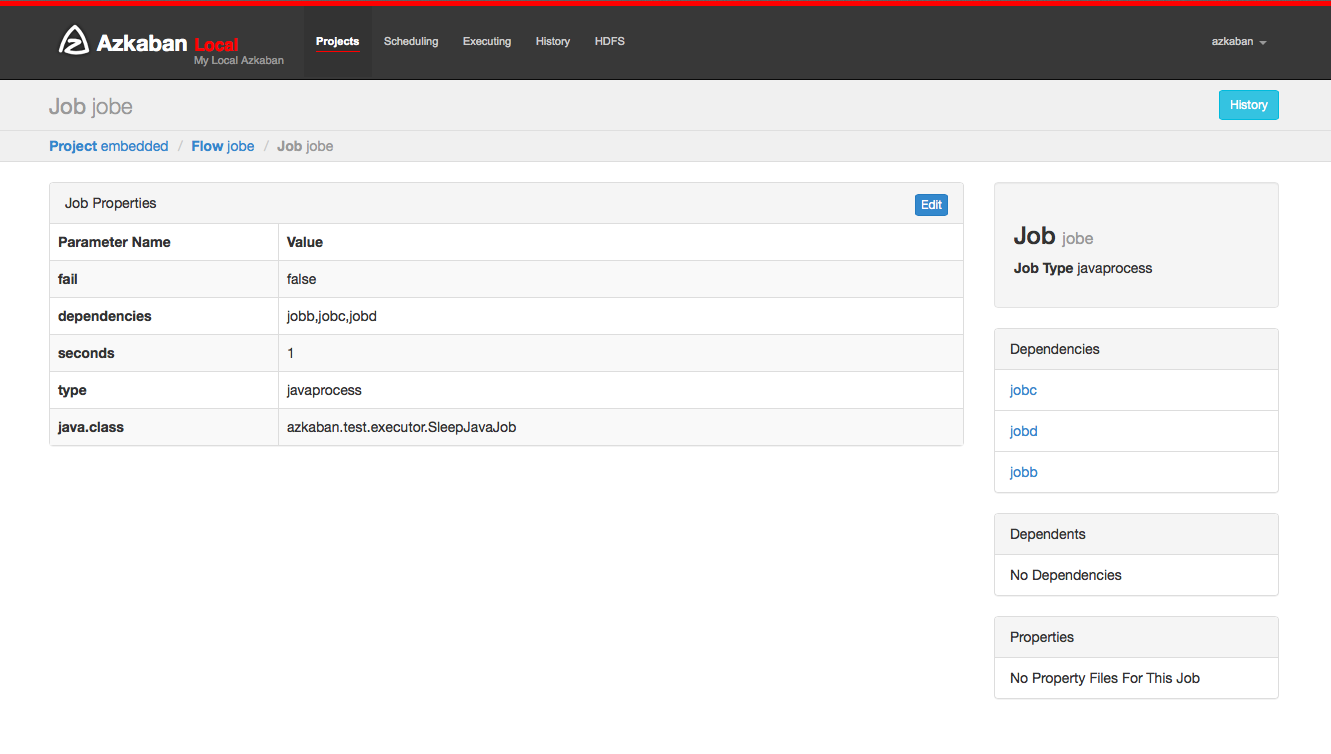
The work page works on the tasks that make up a process. To access the job page, you can right-click the process view to execute the job in the process view or the project page.
5.11 task page
On this page, you can view the dependencies and dependencies of the job and the global properties that the job will use.
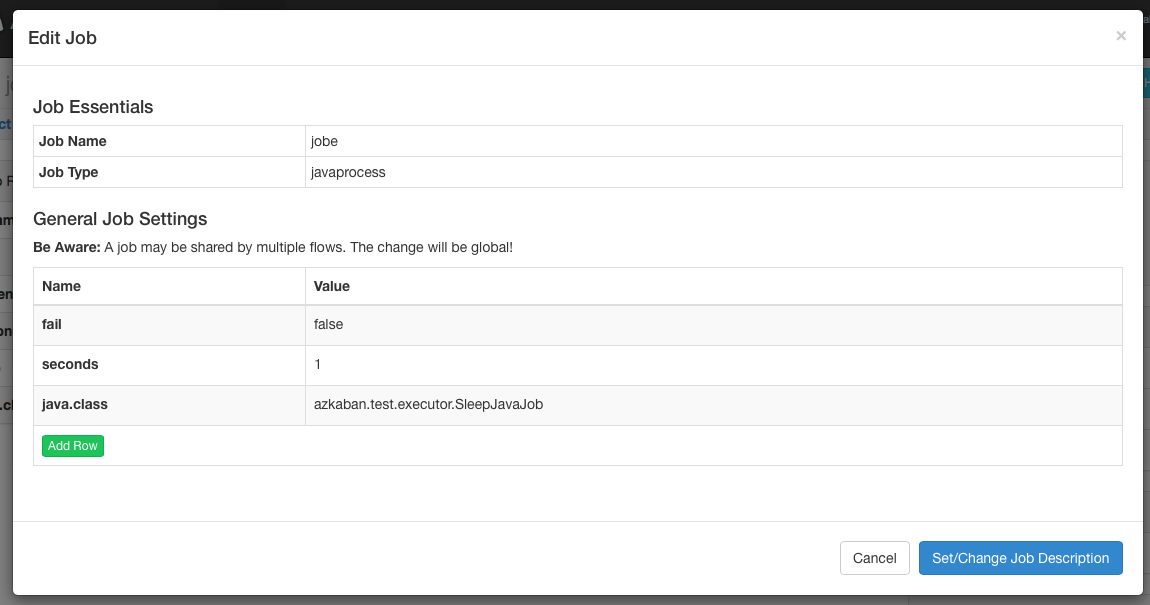
5.12 task editing
Clicking job edit will allow you to edit all job attribute dependencies except for specific retention parameters, such as type. Changes to parameters affect the execution process only when the job has not started running. These overwrite job properties will be overwritten by the next project upload.
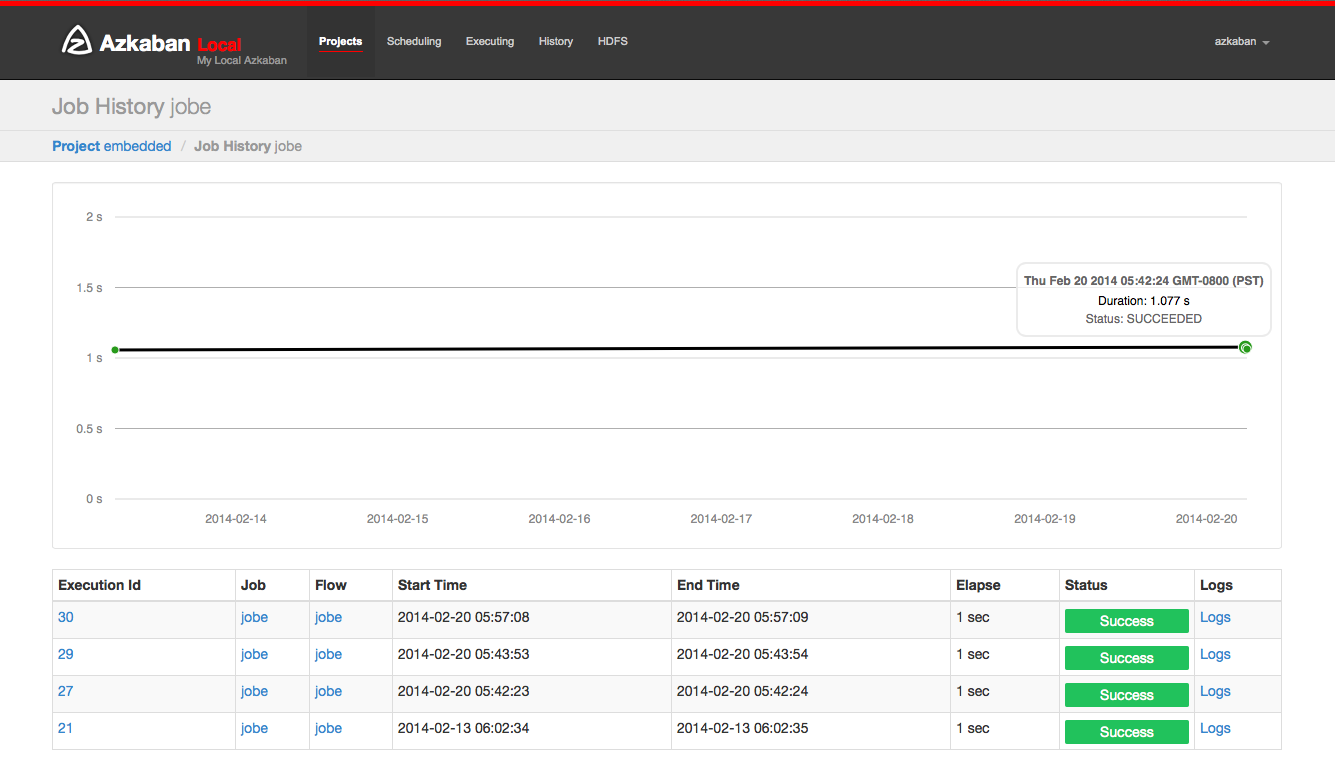
5.13 work history
Any work retries will be displayed as executionid Attemptnumber.
6.14 work log
The job log is stored in the database. They contain the output of all stdout and stderr jobs.
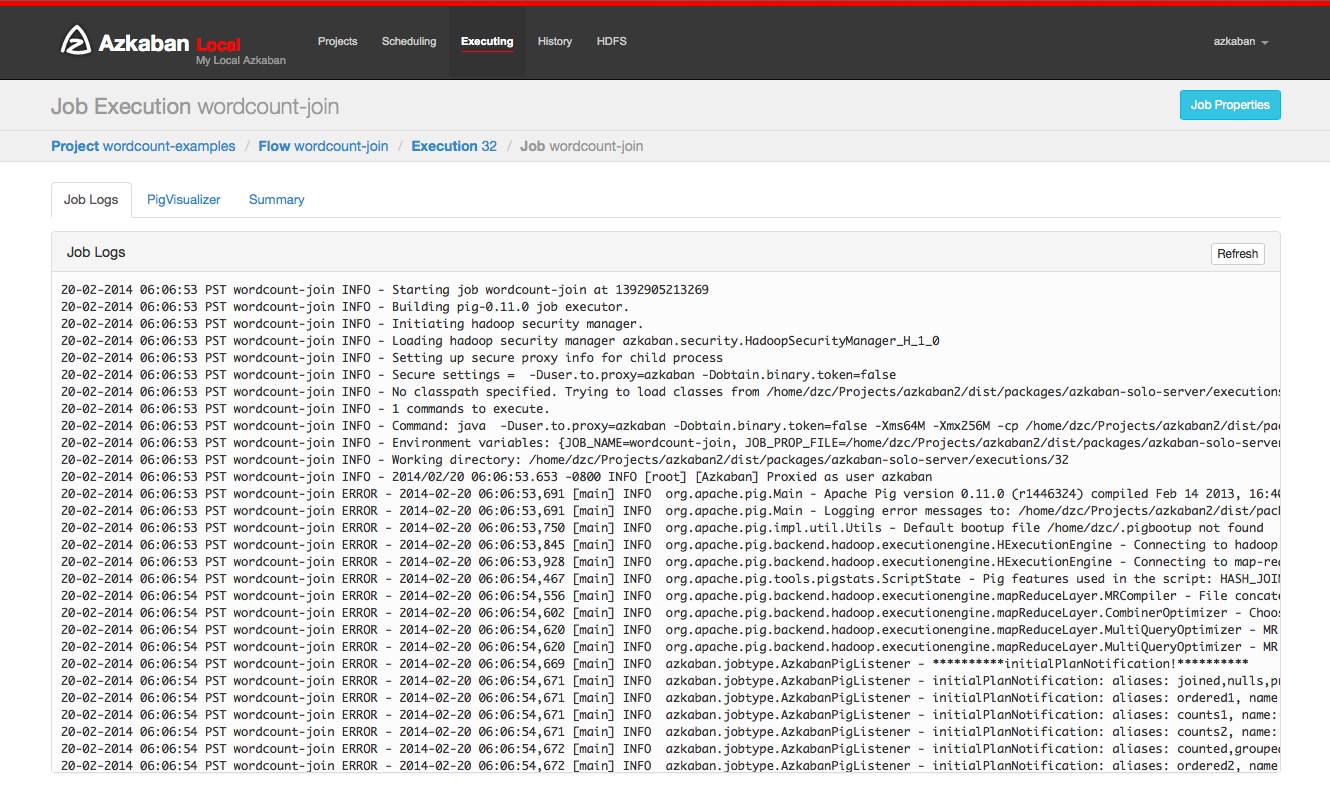
Work summary
The job summary tab is included in the summary of job log information. This includes:
- Job type: the job type of the job
- Command summary: the command to start the job process, as well as the separately displayed fields such as classpath and memory settings
- Pig / Hive job summary: specific customization of pig and Hive jobs
- Map reduction job: link the job ID list of map reduce job with the started job to its job tracking page
Vi Azkaban Job
6.1 serial timed task workflow
zip directory structure
|--start.job |--finish.job
Execute script
# start.job type=command command=echo "this is start.job" # finish.job type=command dependencies=start command=echo "this is finish.job" successEmail=test@example.com failureEmail=test@example.com
6.2 parallel timed task workflow
zip directory structure
|--step1.job |--step2.job |--step3.job
Execute script
# step1.job type=command dependencies=start command=echo "this is step1.job" # step2.job type=command dependencies=start command=echo "this is step2.job" # step3.job type=command dependencies=step1,step2 command=echo "this is step3.job"
6.3 java timed task workflow
zip directory structure
|--AzkabanJob.jar |--azkabanJava.job
Execute script
# azkabanJob.job type=javaprocess java.class=com.example.AzkabanJob classpath=lib/*
6.4 embedded timed task workflow
You can also include a workflow as an embedded flow as a node in another workflow. To create an embedded stream, just create one job file, type=flow, and set it to flow Name is set to the name of the embedded workflow. Moreover, the embedded workflow can be configured with timed tasks separately, for example:
zip directory structure
|--bin | |--flow1.sh | |--flow2.sh | |--flow3.sh | |--start.job |--flow1.job |--flow2.job |--flow3.job |--subflow1.job |--subflow2.job
Execute script
# subflow1.job type=flow flow.name=flow1 dependencies=start # subflow2.job type=flow flow.name=flow2 dependencies=start # flow1.job type=command dependencies=step1 command=sh ./bin/flow1.sh # flow2.job type=command dependencies=step2 command=sh ./bin/flow2.sh # flow3.job type=command dependencies=subflow1,subflow2 command=sh ./bin/flow3.sh
Note: Here's the bin directory and all job is located in the same level directory/ bin/flow.sh one of them Represents the current directory.
6.5 global variables
The postmark name is The properties file will be loaded as a parameter file and shared by each job in the flow. The properties file is inherited through the hierarchical structure of the directory.
zip directory structure
|--common.properties |--bin | |--start.sh | |--finish.sh |--start.job |--finish.job |--flow | |-- flow.properties | |-- step1
configuration file
# common.properties start.nofity.email=start@example.com finish.nofity.email=finish@example.com step.nofity.email=step@example.com
Execute script
# start.job
type=command
command=sh ./bin/start.sh
notify.emails=${start.nofity.email}
# finish.job
type=command
command=sh ./bin/finish.sh
dependencies=start
notify.emails=${finish.nofity.email}
# flow.properties
success.email=success@example.com
# step.job
type=command
command=echo "this is step"
notify.emails=${step.nofity.email}
success.email=${success.email}
common.properties is a global property and will be started job,finish.job and step under flow Job uses, but start Job and finish Job cannot inherit flow Properties, because it is under it, and step A job can inherit flow Properties.
Note: The property name declared in properties cannot contain spaces, such as ${success email}
6.6 Hive Job
type=hive user.to.proxy=Azkaban azk.hive.action=execute.query hive.query.01=drop table words; hive.query.02=create table words (freq int, word string) row format delimited fields terminated by '\t' stored as textfile; hive.query.03=describe words; hive.query.04=load data local inpath "res/input" into table words; hive.query.05=select * from words limit 10; hive.query.06=select freq, count(1) as f2 from words group by freq sort by f2 desc limit 10;
6.7 Hadoop Job
zip directory structure
|--system.properties |--pig.job |--hadoop.job
Execute script
# system.properties
user.to.proxy=Azkaban
HDFSRoot=/tmp
param.inDataLocal=res/rpfarewell
param.inData=${HDFSRoot}/${user.to.proxy}/wordcountjavain
param.outData=${HDFSRoot}/${user.to.proxy}/wordcountjavaout
# pig.job
type=pig
pig.script=src/wordcountpig.pig
user.to.proxy=azkabanHDFS
Root=/tmp
param.inDataLocal=res/rpfarewell
param.inData=${HDFSRoot}/${user.to.proxy}/wordcountpigin
param.outData=${HDFSRoot}/${user.to.proxy}/wordcountpigout
# hadoop.job
type=hadoopJava
job.class=azkaban.jobtype.examples.java.WordCount
classpath=./lib/*,${hadoop.home}/lib/*
main.args=${param.inData} ${param.outData}
force.output.overwrite=true
input.path=${param.inData}
output.path=${param.outData}
dependencies=pig
7, Azkaban Job best practices
Azkaban has been officially used to perform scheduled tasks. The scheduled tasks of talent project team will be explained as the best practice code below.
directory structure
|--conf | |--application.properties | |--bootstrap.yml | |--logback.xml | |--mybatis-config.xml | |--lib | |-- base-0.0.1.jar | |-- meritpay-core-0.0.1.jar | |-- meritpay-job-0.0.1.jar | |-- xxx.jar | |--ComputeTask.job |--DataCheck.job |--ExecutePlan.job
Execute script
# ExecutePlan.job type=command command=java -Xms64m -Xmx1024m -XX:MaxPermSize=64M -Dazkaban.job.id=ExecPlan -jar meritpay-job-0.0.1.jar # ComputeTask.job type=command command=java -Xms64m -Xmx1024m -XX:MaxPermSize=64M -Dazkaban.job.id=ExecTask -jar meritpay-job-0.0.1.jar dependencies=ExecutePlan # DataCheck.job type=command command=java -Xms64m -Xmx1024m -XX:MaxPermSize=64M -Dazkaban.job.id=DataCheck -jar meritpay-job-0.0.1.jar dependencies=ComputeTask
8, Azkaban Ajax API
Azkaban also provides API interfaces for use, so that you can implement your own management mode based on Azkaban. These interfaces communicate with the Web server through HTTPS. Because Azkaban has the concept of user and permission, you need to log in before calling the API. After successful login, a session ID will be returned to the user, After that, all operations need to carry the session ID to judge whether the user has permission. If the session ID is invalid, calling the API will return "error" and "session" information. If it does not carry session ID parameter, the html file content of the login interface will be returned (some session ID accesses will also return such content). The APIs provided by Azkaban include: please refer to the official documents for details: http://azkaban.github.io/azkaban/docs/latest/#ajax-api
8.1 Authenticate
The user login operation needs to carry the user name and password. If the login is successful, a session is returned ID is used for subsequent requests.
Request parameters
| parameter | describe |
|---|---|
| action=login | Login operation (fixed parameters) |
| username | Azkaban user |
| password | Azkaban password |
command
curl -k -X POST --data "action=login&username=azkaban&password=azkaban" https://localhost:8443
{
"status" : "success",
"session.id" : "c001aba5-a90f-4daf-8f11-62330d034c0a"
}
8.2 Create a Project
To create a new project, you need to enter the name of the project as the unique identifier of the project and include the description information of the project. In fact, it is the same as the input of creating a project on the web page.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| action=create | Create project operation (fixed parameters) |
| name | entry name |
| description | Project description |
command
curl -k -X POST --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&name=MyProject&description=test" \
https://localhost:8443/manager?action=create
{
"status":"success",
"path":"manager?project=MyProject",
"action":"redirect"
}
8.3 Delete a Project
Delete an existing project. There is no reply to the request. You need to enter the project ID.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| delete=true | Delete item operation (fixed parameter) |
| project | entry name |
command
curl -k -X POST --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&delete=true&project=azkaban" \ https://localhost:8443/manager
8.4 Upload a Project Zip
Upload a zip file to a project. Generally, after creating a project, the subsequent upload will overwrite the previously uploaded content.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=upload | Upload job flow operation (fixed parameters) |
| project | entry name |
| file | Project zip file. The upload type must be application/zip or application/x-zip-compressed |
command
curl -k -i -H "Content-Type: multipart/mixed" -X POST \
--form 'session.id=c001aba5-a90f-4daf-8f11-62330d034c0a' \
--form 'ajax=upload' --form 'file=@myproject.zip;type=application/zip' \
--form 'project=MyProject;type/plain' \
https://localhost:8443/manager
{
"error" : "Installation Failed.\nError unzipping file.",
"projectId" : "192",
"version" : "1"
}
8.5 Fetch Flows of a Project
Obtain all flow information under a project, input the identification of the project to be specified, there may be multiple flows under a project, and the output flow only contains the flowId identification of each flow.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=fetchprojectflows | Get project job flow operation (fixed parameters) |
| project | entry name |
command
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchprojectflows&project=MyProject" \
https://localhost:8443/manager
{
"project" : "MyProject",
"projectId" : 192,
"flows" : [
{
"flowId" : "test"
}, {
"flowId" : "test2"
}
]
}
8.6 Fetch Jobs of a Flow
Get the information of all jobs under a flow. Because each command is independent on the API side, you need to enter the project id and flow id, and output the information containing each job, including the job id, job type and the job directly from this job.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=fetchflowgraph | Get job operation (fixed parameters) |
| project | entry name |
| flow | Job flow ID |
command
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchflowgraph&project=MyProject&flow=test" \
https://localhost:8443/manager
{
"project" : "MyProject",
"nodes" : [ {
"id" : "test-final",
"type" : "command",
"in" : [ "test-job-3" ]
}, {
"id" : "test-job-start",
"type" : "java"
}, {
"id" : "test-job-3",
"type" : "java",
"in" : [ "test-job-2" ]
}, {
"id" : "test-job-2",
"type" : "java",
"in" : [ "test-job-start" ]
} ],
"flow" : "test",
"projectId" : 192
}
8.7 Fetch Executions of a Flow
To obtain the execution status of a flow, you need to formulate a specific project and flow. This interface can be returned in pages. Therefore, you need to formulate start to specify the index and length to specify the number of returns, because each flow can be executed separately or as a child flow of other flows. Here, the information of each execution in the specified interval of the flow is returned. Each execution information includes the start time, the user who submitted the execution, the execution status, the submission time, the global id of this execution (incremental execid), projectid, end time and flowId.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=fetchFlowExecutions | Get project job flow information operation (fixed parameter) |
| project | entry name |
| flow | Job flow ID |
| start | Gets the start index of the execution |
| length | Gets the number of records executed by the job |
command
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchFlowExecutions\
&project=MyProject&flow=test&start=0&length=1" https://localhost:8443/manager
{
"executions" : [ {
"startTime" : 1407779928865,
"submitUser" : "1",
"status" : "FAILED",
"submitTime" : 1407779928829,
"execId" : 306,
"projectId" : 192,
"endTime" : 1407779950602,
"flowId" : "test"
}],
"total" : 16,
"project" : "MyProject",
"length" : 1,
"from" : 0,
"flow" : "test",
"projectId" : 192
}
8.8 Fetch Running Executions of a Flow
Obtain the execution information of the currently executing flow, enter the identification including project and flow, and return all the execution IDS (Global exec id) of the flow being executed.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=getRunning | Get project executing job flow operation (fixed parameter) |
| project | entry name |
| flow | Job flow ID |
command
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=getRunning&project=MyProject&flow=test" \
https://localhost:8443/executor
{
"execIds": [301, 302]
}
8.9 Execute a Flow
There are many inputs for starting the execution of a flow, because several configurations need to be set every time the flow is started on the web interface. The configuration information other than scheduling can be set on the interface. The input also needs to include the identification of project and flow, and the output is the id of the flow and the exec id of this execution.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=executeFlow | Perform job flow operations (fixed parameters) |
| project | entry name |
| flow | Job flow ID |
| disabled (optional) | List of jobs to be prohibited for this execution ["job_name_1", "job_name_2"] |
| successEmails (optional) | Successfully executed mailing list foo@email.com,bar@email.com |
| failureEmails (optional) | Successfully executed mailing list foo@email.com,bar@email.com |
| Successemailsovride (optional) | Whether to overwrite with the success message configured by the system by default, true or false |
| Failureemailsovride (optional) | Whether to overwrite with the failure message configured by the system by default, true or false |
| notifyFailureFirst (optional) | As long as the first failure occurs, send the execution failure message, true or false |
| notifyFailureLast (optional) | As long as the last failure occurs, send the execution failure message, true or false |
| failureAction (optional) | How to execute if a fault occurs: finishCurrent, cancelImmediately, finishPossible |
| concurrentOption (optional) | Concurrent selection: ignore, pipeline, queue |
| flowOverrideflowProperty (optional) | Overrides the specified job flow property with the specified value: flowOverride[failure.email]=test@gmail.com |
command
curl -k --get --data 'session.id=c001aba5-a90f-4daf-8f11-62330d034c0a' \
--data 'ajax=executeFlow' \
--data 'project=MyProject' \
--data 'flow=test' https://localhost:8443/executor
{
message: "Execution submitted successfully with exec id 295",
project: "foo-demo",
flow: "test",
execid: 295
}
8.10 Cancel a Flow Execution
To cancel the execution of flow once, you need to enter the global exec.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=cancelFlow | Canceling the executing job flow (fixed parameters) |
| execid | ID of the job flow being executed |
command
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=cancelFlow&execid=302" \
https://localhost:8443/executor
{
"error" : "Execution 302 of flow test isn't running."
}
8.11 Flexible scheduling using Cron
Use time expressions to flexibly configure scheduled tasks.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=scheduleCronFlow | Configure job flow scheduled tasks (fixed parameters) using scheduled expressions |
| projectName | entry name |
| flowName | Job flow ID |
| cronExpression | cron time expression. In Azkaban, the Quartz time expression format is used |
command
curl -k -d ajax=scheduleCronFlow -d projectName=wtwt \
-d flow=azkaban-training \
--data-urlencode cronExpression="0 23/30 5,7-10 ? * 6#3" -b "azkaban.browser.session.id=c001aba5-a90f-4daf-8f11-62330d034c0a" \
http://localhost:8081/schedule
{
"message" : "PROJECT_NAME.FLOW_NAME scheduled.",
"status" : "success"
}
8.12 Fetch a Schedule
Obtain the corresponding time scheduled task information according to the project name and job flow ID.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=fetchSchedule | Get scheduled task operation (fixed parameter) |
| projectId | Project ID |
| flowId | Job flow ID |
| cronExpression | cron time expression. In Azkaban, the Quartz time expression format is used |
command
curl -k --get --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchSchedule&projectId=1&flowId=test" \
http://localhost:8081/schedule
{
"schedule" : {
"cronExpression" : "0 * 9 ? * *",
"nextExecTime" : "2017-04-01 09:00:00",
"period" : "null",
"submitUser" : "azkaban",
"executionOptions" : {
"notifyOnFirstFailure" : false,
"notifyOnLastFailure" : false,
"failureEmails" : [ ],
"successEmails" : [ ],
"pipelineLevel" : null,
"queueLevel" : 0,
"concurrentOption" : "skip",
"mailCreator" : "default",
"memoryCheck" : true,
"flowParameters" : {
},
"failureAction" : "FINISH_CURRENTLY_RUNNING",
"failureEmailsOverridden" : false,
"successEmailsOverridden" : false,
"pipelineExecutionId" : null,
"disabledJobs" : [ ]
},
"scheduleId" : "3",
"firstSchedTime" : "2017-03-31 11:45:21"
}
}
8.13 Unschedule a Flow
Cancel the timing configuration of job flow.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=removeSched | Delete job flow timing configuration operation (fixed parameter) |
| scheduleId | Timing configuration ID |
command
curl -d "action=removeSched&scheduleId=3" -b azkaban.browser.session.id=c001aba5-a90f-4daf-8f11-62330d034c0a \
-k https://HOST:PORT/schedule
{
"message" : "flow FLOW_NAME removed from Schedules.",
"status" : "success"
}
8.14 Pause a Flow Execution
Pause execution once, and enter exec id. If the execution is not in the running state, an error message will be returned.
Request parameters
| parameter | describe |
|---|---|
| ession.id | Session returned after successful user login id |
| ajax=removeSched | Delete job flow timing configuration operation (fixed parameter) |
| scheduleId | Timing configuration ID |
command
curl -d "action=removeSched&scheduleId=3" -b azkaban.browser.session.id=c001aba5-a90f-4daf-8f11-62330d034c0a \
-k https://HOST:PORT/schedule
{
"message" : "flow FLOW_NAME removed from Schedules.",
"status" : "success"
}
8.15 Resume a Flow Execution
Restart the execution. Enter exec id. if the execution is already in progress, no error will be returned. If it is no longer running, an error message will be returned.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=pauseFlow | Pauses executing job flow operations (fixed parameters) |
| execid | Execution ID |
command
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=pauseFlow&execid=303" \
https://localhost:8443/executor
{
"error" : "Execution 303 of flow test isn't running."
}
8.16 Resume a Flow Execution
Given an exec id, the API will resume the suspended running process. If the execution has been resumed, it will not return any errors; If the execution does not run, it returns an error message.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=resumeFlow | Pauses executing job flow operations (fixed parameters) |
| execid | Execution ID |
command
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=resumeFlow&execid=303" \
https://localhost:8443/executor
{
"error" : "Execution 303 of flow test isn't running."
}
8.17 Fetch a Flow Execution
Get all the information of one execution, input it as exec id, and output it including the properties of this execution and the execution status of all the job s executed this time.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=fetchexecflow | Get job flow details (fixed parameters) |
| scheduleId | Timing configuration ID |
command
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchexecflow&execid=304" \
https://localhost:8443/executor
{
"attempt" : 0,
"submitUser" : "1",
"updateTime" : 1407779495095,
"status" : "FAILED",
"submitTime" : 1407779473318,
"projectId" : 192,
"flow" : "test",
"endTime" : 1407779495093,
"type" : null,
"nestedId" : "test",
"startTime" : 1407779473354,
"id" : "test",
"project" : "test-azkaban",
"nodes" : [ {
"attempt" : 0,
"startTime" : 1407779495077,
"id" : "test",
"updateTime" : 1407779495077,
"status" : "CANCELLED",
"nestedId" : "test",
"type" : "command",
"endTime" : 1407779495077,
"in" : [ "test-foo" ]
}],
"flowId" : "test",
"execid" : 304
}
8.18 Fetch Execution Job Logs
Get the execution log of a job in one execution. You can use the job execution log as a file. Here, you need to formulate exec
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=fetchExecJobLogs | Get execution job log information (fixed parameters) |
| execid | Row ID |
| jobId | Job ID |
| offset | Log information offset |
| length | Log information length |
command
curl -k --data "session.id=c001aba5-a90f-4daf-8f11-62330d034c0a&ajax=fetchExecJobLogs&execid=297&jobId=test-foobar&offset=0&length=100" \
https://localhost:8443/executor
{
"data" : "05-08-2014 16:53:02 PDT test-foobar INFO - Starting job test-foobar at 140728278",
"length" : 100,
"offset" : 0
}
8.19 Fetch Flow Execution Updates
Returns the information about the execution progress during flow execution.
Request parameters
| parameter | describe |
|---|---|
| session.id | Session returned after successful user login id |
| ajax=fetchexecflowupdate | Delete job flow timing configuration operation (fixed parameter) |
| execid | Execution ID |
| lastUpdateTime | The last update time. If it is only - 1, it means that all job information is required |
command
curl -k --data "execid=301&lastUpdateTime=-1&session.id=c001aba5-a90f-4daf-8f11-62330d034c0a"
\ https://localhost:8443/executor?ajax=fetchexecflowupdate
{
"id" : "test",
"startTime" : 1407778382894,
"attempt" : 0,
"status" : "FAILED",
"updateTime" : 1407778404708,
"nodes" : [ {
"attempt" : 0,
"startTime" : 1407778404683,
"id" : "test",
"updateTime" : 1407778404683,
"status" : "CANCELLED",
"endTime" : 1407778404683
}, {
"attempt" : 0,
"startTime" : 1407778382913,
"id" : "test-job-1",
"updateTime" : 1407778393850,
"status" : "SUCCEEDED",
"endTime" : 1407778393845
}, {
"attempt" : 0,
"startTime" : 1407778393849,
"id" : "test-job-2",
"updateTime" : 1407778404679,
"status" : "FAILED",
"endTime" : 1407778404675
}, {
"attempt" : 0,
"startTime" : 1407778404675,
"id" : "test-job-3",
"updateTime" : 1407778404675,
"status" : "CANCELLED",
"endTime" : 1407778404675
} ],
"flow" : "test",
"endTime" : 1407778404705
}
It can be seen from the interface here that the API provided by azkaban can only be used to simply create project, flow, view project, flow, execute and other operations, and the operation of the web interface is much richer. If we want to develop based on azkaban, I think we can also analyze azkaban's database based on these interfaces, Get the information we want from the database (basic write operations can be implemented through these APIs, so we only need to read from the database). However, there is still a disadvantage compared with using API. After all, the database structure may change with the version update, but this is also a way.
9, Azkaban plugin
9.1 Hadoop Security
Azkaban is most commonly used in big data platforms such as Hadoop. Azkaban's job type plug-in system allows most flexible support for these systems. Azkaban can support all Hadoop versions and Hadoop Security functions; Azkaban can support various versions of ecosystem components, like different versions of pig and hive in an instance.
The most common way to implement Hadoop Security is to rely on Hadoop securitymanager to communicate with Hadoop cluster and ensure Hadoop Security through secure means.
Please refer to Hadoop Security
9.2 Azkaban HDFS browser
Azkaban HDFS browser is a plug-in that allows you to view HDFS FileSystem and decode multiple file types. It was originally created on LinkedIn to view Avro files, LinkedIn's binaryjason format and text files. As the plug-in matures further, we may add decoding of different file types in the future.
Download the HDFS plug-in and unzip it into the plug-in directory of the Web server. The default directory is / Azkaban Web server / plugins / viewer/
Please refer to HDFS Browser
9.3 Jobtype plug-in
The Jobtype plug-in determines the actual operation of a single job on a local or remote cluster. It provides great convenience: you can add or change any type of work without touching the Azkaban core code; Azkaban can be easily extended to run different hadoop versions or distributions; You can keep the old version while adding a new version of the same type. However, it is up to the administrator who manages these plug-ins to ensure that they are installed and configured correctly.
After Azkaban executorserver starts, Azkaban will try to load all the job type plug-ins that can be found. Azkaban will do very simple tests and throw away the bad ones. You should always try to run some test jobs to ensure that the type of work really works as expected.
Please refer to JobType Plugins