First, Stream#reduce has three overload methods as follows:
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
The first method has two input parameters:
- T identity: it means the starting point of accumulator
- BinaryOperator accumulator: accumulator
This method is easy to understand. For the incoming identity, each element in the Stream stream is given the identity after performing the operation in the incoming accumulator accumulator.
The second method has only one input parameter, which is similar to the above. The difference is that the built-in identity is initially null, and the value after processing by the accumulator accumulator may still be null, so the return value is wrapped in Optional.
This paper focuses on the three parameters of the third method:
- U identity: it means the starting point of accumulator
- BiFunction<U, ? Super T, u > accumulator: accumulator
- Binaryoperator < U > combiner: combiner
Let's take a look first Official documents Interpretation of:
accumulator - an associative, non-interfering, stateless function for incorporating an additional element into a result.
Accumulator - an associated, undisturbed, stateless function used to incorporate additional elements into the result
combiner - an associative, non-interfering, stateless function for combining two values, which must be compatible with the accumulator function
Combiner - an associated, interference free, stateless function used to combine two values. It must be compatible with the accumulator function
The emphasis is on the yellow font above, and the official also gives a specific explanation:
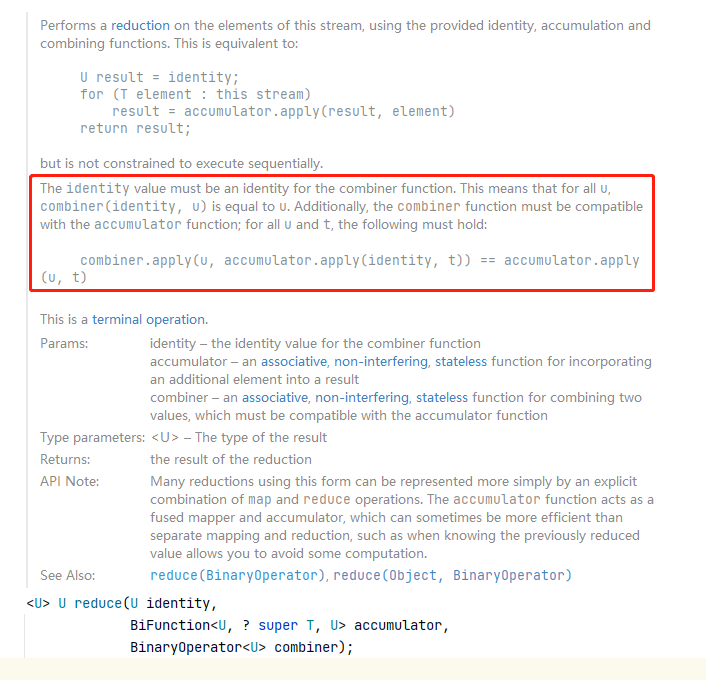
The framed description roughly means:
The identity value must be the identity of the combiner function. This means that for all u, the value type after combiner(identity, u) is equal to u. In addition, the combiner function must be compatible with the accumulator function; For all u and t, the following must be true:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
At first glance, I'm still confused. Since the above equation needs to be established, why should we design the accumulator and combiner separately?
Let's look at a set of codes:
private static void testForReduce() {
ArrayList<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Integer reduce = list.stream().reduce(
1,
(x, y) -> {
System.out.println("------accumulator--------"
+ "\nvalue:" + (x + y + 2)
);
return x + y + 2;
},
(x, y) -> {
System.out.println("------combiner--------"
+ "\nvalue:" + (x * y)
);
return x * y;
}
);
System.out.println("result:"+reduce);
}
You can boldly guess the result. If the result is 23, it is recommended to jump to the end of the article to see the conclusion.
The following is the above code execution process:

Careful people in the above processes may find that why is there no combiner implementation process?
Note: in the above code, combiner does not participate in the calculation of the whole process of reduce
So what is the significance of designing combiner?
Let's modify the code:
private static void testForReduce() {
ArrayList<Integer> list = new ArrayList<>();
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Integer reduce = list.parallelStream().reduce(1,
(x, y) -> {
System.out.println("------accumulator--------\n"
+ "ThreadName: " + Thread.currentThread().getName()
+ "\nvalue:" + (x + y + 2) + "\n"
);
return x + y + 2;
},
(x, y) -> {
System.out.println("------combiner--------\n"
+ "ThreadName: " + Thread.currentThread().getName()
+ "\nvalue:" + (x * y)
);
return x * y;
}
);
System.out.println("result:"+reduce);
}
Compared with the code executed for the first time, the above code changes stream() to parallelStream(), and prints the name of the current Thread every time. Let's take a look at the log for analysis:
------accumulator-------- ThreadName: ForkJoinPool.commonPool-worker-2 value:8 ------accumulator-------- ThreadName: ForkJoinPool.commonPool-worker-11 value:5 ------accumulator-------- ThreadName: ForkJoinPool.commonPool-worker-9 value:6 ------accumulator-------- ThreadName: main value:7 ------combiner-------- ThreadName: ForkJoinPool.commonPool-worker-9 value:30 ------combiner-------- ThreadName: main value:56 ------combiner-------- ThreadName: main value:1680 result:1680
Combined with the above logs, the code execution process is as follows:
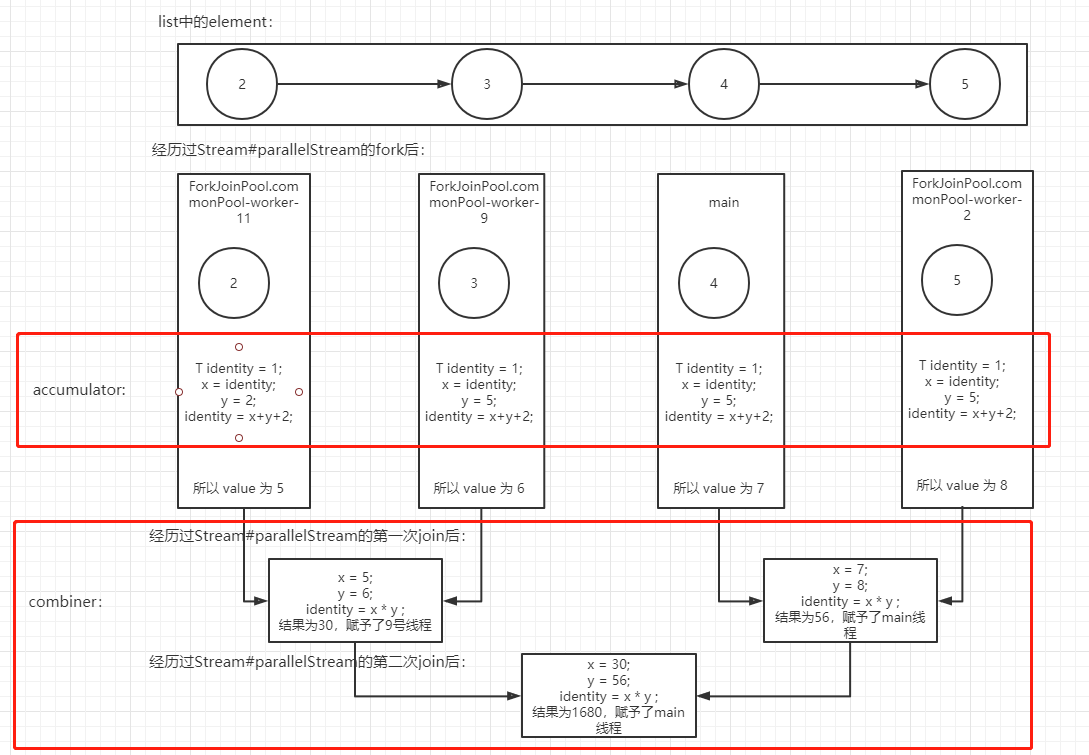
Combined with the above picture, it can be clearly seen that the execution process of combiner is the combined data flow before multiple threads, so combiner does not take effect in the previous single thread processing.
Conclusion: the combiner of the Stream#reduce method does not take effect when a single thread works, and the combiner takes effect when multiple threads are merged. Therefore, in order to ensure the consistency between the results of serial flow and parallel flow, the principles mentioned above are designed:
combiner.apply(u, accumulator.apply(identity, t)) == accumulator.apply(u, t)
If the above principles are not met, the two results in this paper will be inconsistent.
Extended thinking:
- The problem of data synchronization between multithreads needs to be considered and preprocessed in advance.
- According to the ThreadName in this article's log, it is confirmed that the bottom layer of parallel stream is actually ForkJoinPool. Multiple task s are divided into multiple threads and then joined again.