Required for every member visit. Only when members check out or find a shopping guide can they be found. Or a person needs to stand at the door and know all the members, so as to better serve the reception of members' visits. Xiaoshuai, in order to avoid these operations. I thought of Baidu AI. Speech synthesis. Combined with the visit and push of third-party face database members. Did a simple member visit voice reminder push small project. Let's take a look at the overall process~
Implementation steps
Step 1: become the developer of Baidu AI open platform
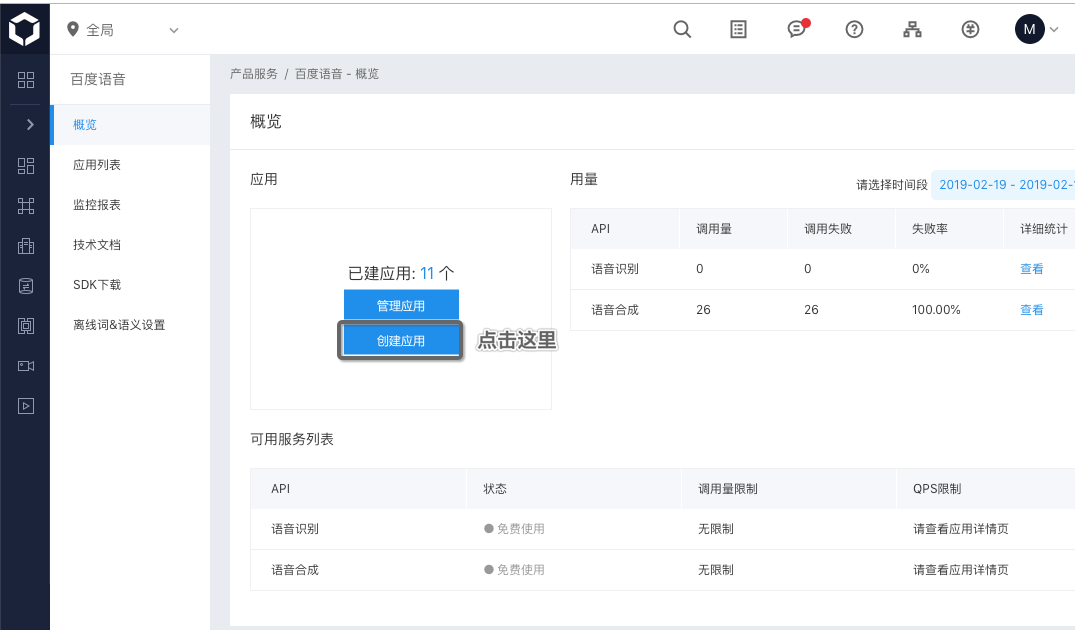
After we have an account, log in and click here (Baidu voice) create an application , as shown below
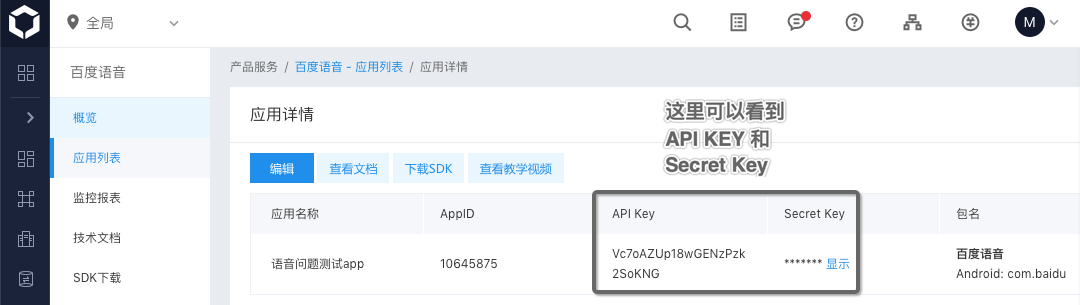
Then you can see the created application and APPID, API KEY and Secret KEY
Step 2: prepare data
Speech synthesis is a service that converts text into audio files that can be played. We find a text of order information from Dayao's order library as follows:
Three minutes ago, from the north of the intersection of Erjing road and Erwei Road, Shunyi District, Beijing, to the T3 terminal of Beijing Capital International Airport, go to Sheraton Hotel (Beijing Jinyu store), No. 36, North Third Ring East Road, Dongcheng District
Step3: write a speech synthesis example program
With the API KEY and Secret KEY in the first step and the data in the second step, we can write an example code to call the character recognition ability of Baidu AI open platform
Prepare development environment
Xiaoshuai chose to use java to quickly build a prototype about how to install Java. You can refer to Baidu experience. Baidu AI has perfect API documents, and more convenient toolkit for encapsulation and call. Next, Xiaoshuai used Maven to build the engineering environment
pom. The XML configuration is as follows:
<!-- https://mvnrepository.com/artifact/com.baidu.aip/java-sdk -->
<dependency>
<groupId>com.baidu.aip</groupId>
<artifactId>java-sdk</artifactId>
<version>4.12.0</version>
</dependency>Write code
Paste the following content and don't forget to replace your appid, apikey, SECRETKEY and picture files
Just run the main method
import com.baidu.aip.speech.AipSpeech;
import com.baidu.aip.speech.TtsResponse;
import com.baidu.aip.util.Util;
import org.json.JSONObject;
import java.util.HashMap;
public class Sample {
//The first step is to create the three values obtained by the application
private static String APPID = "Yours App ID";
private static String APIKEY = "Yours Api Key";
private static String SECRETKEY = "Yours Secret Key";
public static void main(String[] args) {
// Initialize an AipSpeech
AipSpeech client = new AipSpeech(APPID,APIKEY,SECRETKEY);
// Call the picture prepared in the second step of the interface
HashMap<String, Object> options = new HashMap<>();
//Synthetic text content
String text = "Three minutes ago, from the north of the intersection of Erjing road and Erwei Road, Shunyi District, Beijing, Beijing Capital International Airport T3 The terminal goes to Sheraton Hotel, No. 36, North Third Ring East Road, Dongcheng District(Beijing Jinyu store)";
//Speaker selection
/**
* Du Xiaoyu = 1, Du Xiaomei = 0, Du Xiaoyao = 3, Du Yaya = 4
* Du Bowen = 106, Du Xiaotong = 110, Du Xiaomeng = 111, Du miduo = 103, Du Xiaojiao = 5
**/
options.put("per","0");
//Speech speed: the value is 0-9, and the default is 5 medium speech speed
options.put("spd", "3");
TtsResponse res = client.synthesis(text , "zh", 1, options);
byte[] data = res.getData();
JSONObject res1 = res.getResult();
if (data != null) {
try {
Util.writeBytesToFileSystem(data, "F:\\testaudio\\Du Xiaomei Demooutput.mp3");
} catch (IOException e) {
e.printStackTrace();
}
}
if (res1 != null) {
System.out.println(res1.toString());
}
}
}Save the voice byte [] returned by the interface and save it as an MP3 format file. Here's an explanation. The default return is data in MP3 format. If you want another format
//3 is mp3 format (default);
//4 is pcm-16k;
//5 is pcm-8k;
//6 is wav (the same as pcm-16k);
//Note that aue=4 or 6 is the format required by speech recognition, but the audio content is not the natural person pronunciation required by speech recognition, so the recognition effect will be affected.
options.put("aue","3");Click to access the composite sample MP3 file
Speech synthesis singleton loading. The time taken for 10 tests is as follows (unit: ms). AUTH needs to be loaded for the first time. It takes a little more time. The follow-up was basically flat within 710ms
Time consuming to send request to return data:1493 It takes time to send a request to save the file:1495 Time consuming to send request to return data:611 It takes time to send a request to save the file:612 Time consuming to send request to return data:609 It takes time to send a request to save the file:610 Time consuming to send request to return data:473 It takes time to send a request to save the file:474 Time consuming to send request to return data:549 It takes time to send a request to save the file:550 Time consuming to send request to return data:673 It takes time to send a request to save the file:674 Time consuming to send request to return data:754 It takes time to send a request to save the file:755 Time consuming to send request to return data:676 It takes time to send a request to save the file:676 Time consuming to send request to return data:582 It takes time to send a request to save the file:582 Time consuming to send request to return data:662 It takes time to send a request to save the file:663 Average time from sending request to returning data:708.2ms Average time from sending a request to saving a file:709.1ms
for (int i = 0; i < 10; i++) {
// Call interface
String text = "Three minutes ago, from the north of the intersection of Erjing road and Erwei Road, Shunyi District, Beijing, Beijing Capital International Airport T3 The terminal goes to Sheraton Hotel, No. 36, North Third Ring East Road, Dongcheng District(Beijing Jinyu store)";
HashMap<String, Object> options = new HashMap<String, Object>();
options.put("per", "0");
options.put("spd", "3");
long startTime = System.currentTimeMillis();
TtsResponse res = client.synthesis(text, "zh", 1, options);
byte[] data = res.getData();
if (data != null) {
long endTime = System.currentTimeMillis();
System.out.println("Time consuming to send request to return data:"+(endTime - startTime));
try {
Util.writeBytesToFileSystem(data, "F:\\testaudio\\Du Xiaomei Demooutput.mp3");
long saveEndTime = System.currentTimeMillis();
System.out.println("It takes time to send a request to save the file:"+(saveEndTime - startTime));
} catch (IOException e) {
e.printStackTrace();
}
}
JSONObject res1 = res.getResult();
if (res1 != null) {
System.out.println(res1.toString());
}
System.out.println();
}
As can be seen from the above data. The average time is about 0.7s. If the server is configured with thief 6, the bandwidth is also thief wide. It should take less time
next. Let's take the voice synthesis service. To do a small function in combination with the actual business~
Voice reminders of member visits
Take a brief look at the business process diagram. Mainly look at voice synthesis and voice reminder
Face member recognition can see the official solution of Baidu AI https://ai.baidu.com/solution/faceidentify
In this business, face recognition and camera manufacturers do not use Baidu AI for the time being. I am also very helpless. At the request of the company. If you choose again. Absolutely mandatory proposal to choose Baidu AI (I'm afraid it will end up too cheap, you know)
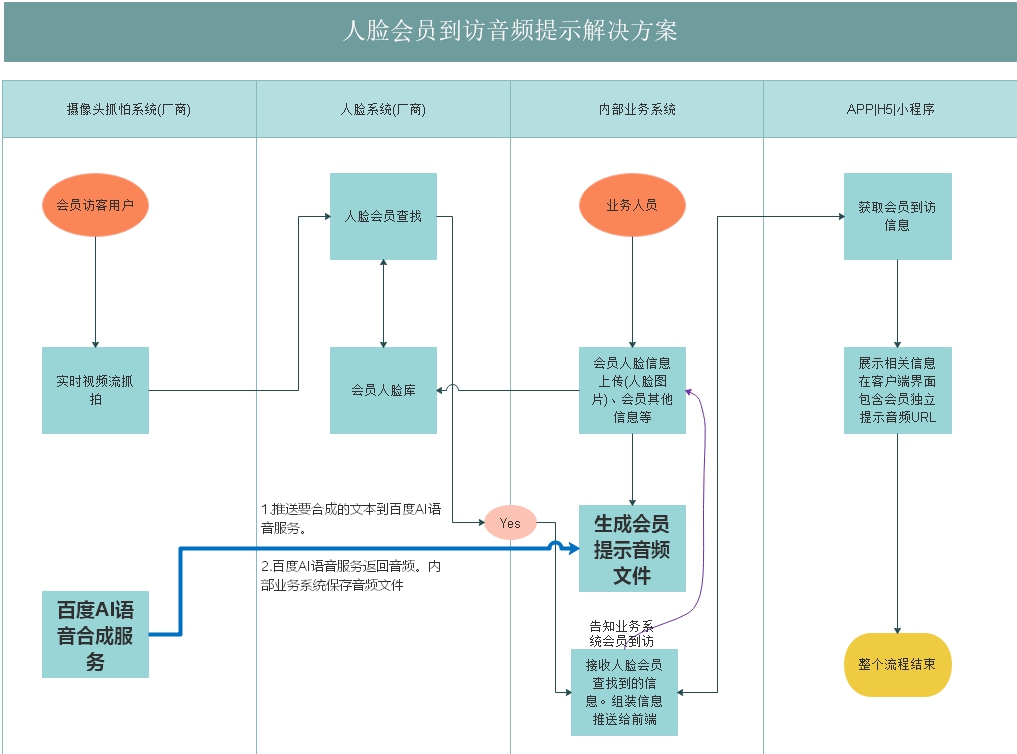
The interface call is encapsulated and conforms to the business system usage
Briefly explain: In the case, the Java back-end part uses the SpringBoot framework jdk1 eight 1. In the step of uploading member's face photo information, Xiaoshuai designed a regular task to execute voice information and synthesize it. Therefore, you need to have a certain understanding of Java scheduled tasks and task scheduling 2. The timing task is to read the face member information and synthesize the member visit voice prompt audio file
Member information collection
The default pronunciation type of member visit prompt sound is more than meters. You can also give different pronunciation types according to different members~
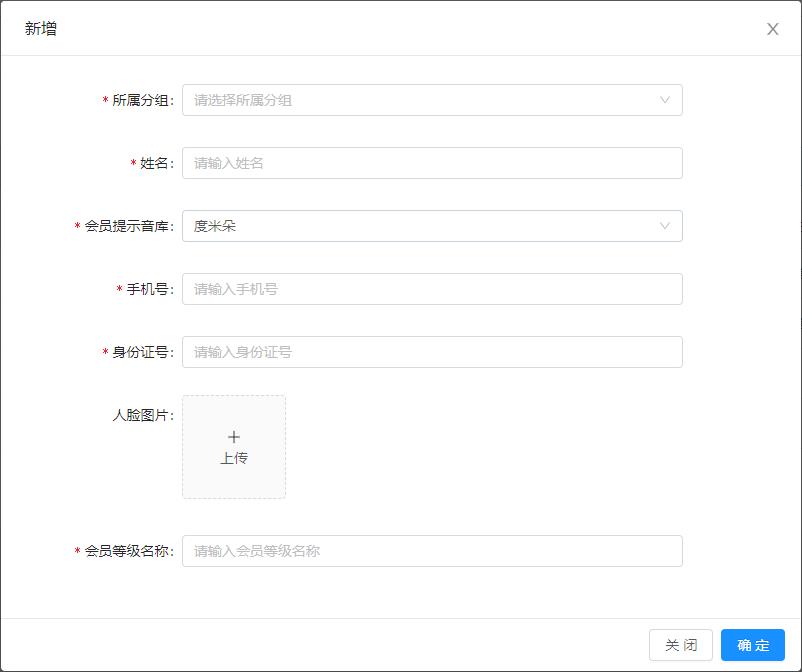


- Back end member face information processing
/**
* Member face information addition
* @param csFace
* @return
*/
@AutoLog(value = "Member face information addition")
@ApiOperation(value="Member face information addition", notes="Member face information addition")
@PostMapping(value = "/add")
public Result<CsFace> add(@RequestBody CsFace csFace) {
Result<CsFace> result = new Result<CsFace>();
csFaceGroup group = new csFaceGroup();
try {
//Save face information to the face database here, and there will be no demonstration. After the face inventory is successfully entered, the business system records it again
csFaceService.save(csFace);
//Submit the member face information to the JOB for subsequent implementation. Facilitate front-end page interaction without waiting
//Face member information only adds a List container to a JobFace class public static List < csface > vipfacemap = new ArrayList < csface > ();
JobFace.vipFaceMap.add(csFace);
result.success("Successfully added!");
} catch (Exception e) {
log.info(e.getMessage());
result.error500("operation failed-Exception in face service");
}
return result;
}- Member visit custom prompt audio synthesis timing task
import cn.hutool.core.date.DatePattern;
import cn.hutool.core.date.DateUtil;
import cn.netand.common.factory.BDFactory;
import cn.netand.modules.csface.entity.CsFace;
import cn.netand.modules.csface.service.ICsFaceService;
import com.baidu.aip.speech.AipSpeech;
import com.baidu.aip.speech.TtsResponse;
import com.baidu.aip.util.Util;
import lombok.extern.slf4j.Slf4j;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import java.io.File;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
/**
* @Description Face member audio generation
* @author Xiaoshuai
* @className VipVoiceJob
* @Date 2019/11/20 22:11
**/
@Slf4j
public class VipVoiceJob implements Job {
@Value(value = "${xiaoshuai.path.upload}")
private String uploadpath;
@Autowired
private GeneralDealBeanUtil generalDealBeanUtil;
@Autowired
private ICsFaceService csFaceService;
//Get the client of audio synthesis
AipSpeech aipSpeech = BDFactory.getAipSpeech();
@Value(value = "${xiaoshuai.domainVoice}")
private String domainVoice;
/**
* Du Xiaoyu = 1, Du Xiaomei = 0, Du Xiaoyao = 3, Du Yaya = 4
* Du Bowen = 106, Du Xiaotong = 110, Du Xiaomeng = 111, Du miduo = 103, Du Xiaojiao = 5
**/
private static final List<String> audioType = Arrays.asList("1","0","3","4","106","110","111","103","5");
private static final String LANGUAGE_ZH = "zh";
private static final Integer CTP = 1;
private static final String AUDIO = ".mp3";
//Task execution details
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("execute VipVoiceJob = " + DateUtil.format(new Date(), DatePattern.NORM_DATETIME_PATTERN));
List<CsFace> vipFaceMap = JobFace.vipFaceMap;
int vipFaceSize = vipFaceMap.size();
if(vipFaceSize>0){
vipFaceMap.forEach(csFace -> {
//Get member information
try {
generalAudio(csFace);
csFace.setVoiceStatus(1);
csFaceService.updateById(csFace);
}catch (Exception e){
System.out.println(e.getMessage());
csFace.setVoiceStatus(2);
csFaceService.updateById(csFace);
}
});
JobFace.vipFaceMap.clear();
}
}
/**
* @Description Generate all sound library audio files
* @Author Xiaoshuai
* @Date 2019/11/20 23:28
* @param face Member face data
* @return void
**/
public void generalAudio(CsFace face){
String ctxPath = uploadpath;
String bizPath = "audios";
File file = new File(ctxPath + File.separator + bizPath + File.separator + face.getId());
if (!file.exists()) {
file.mkdirs();// Create file root
}
long startTime = System.currentTimeMillis();
audioType.forEach(audioTypeStr->{
HashMap<String, Object> options = new HashMap<>();
//Synthetic text content
String text = "XX Store reminder "+face.getName()+" Member visits";
//Speaker selection
options.put("per",audioTypeStr);
//Speech speed: the value is 0-9, and the default is 5 medium speech speed
options.put("spd", "3");
String fileName = audioTypeStr+AUDIO;
TtsResponse response = aipSpeech.synthesis(text,LANGUAGE_ZH,CTP,options);
byte[] data = response.getData();
if (data != null) {
try {
String savePath = file.getPath() + File.separator +fileName;
String filePath = bizPath + File.separator + face.getId() + File.separator + fileName;
if(null!=face.getVoiceType()&&face.getVoiceType().equals(Integer.parseInt(audioTypeStr))){
filePath = filePath.replace("\\", "/");
face.setVoicePath(filePath);
face.setVoiceUrl(domainVoice+filePath);
}
Util.writeBytesToFileSystem(data, savePath);
} catch (Exception e) {
System.out.println(e.getMessage());
}
}
});
long endTime = System.currentTimeMillis();
System.out.println("Total time = " + (endTime - startTime) + "ms");
}
}- Add a scheduled task
This is executed every 5 seconds. In fact, it can be defined according to self needs. The form of scheduled tasks is not necessary.

- Member audio prompt file generation
Numbers represent the type of pronunciation. Every time you add a member. Audio files of all pronunciation types will be generated. It is convenient to give different voice reminders to each visiting member in the follow-up
Member visit APP push
Non Baidu AI face member solution Oh ~ don't ask why you don't use Baidu AI. It has been explained above. 1. Push the camera to the face database system 2. The face database system compares and pushes the results to the internal business system 3. The internal business system | face database system is pushed to app (Xiaoshuai uses the former) The following figure is a gif. It will demonstrate that the app receives a push pop-up window and plays a voice reminder. Access with sound https://mp.weixin.qq.com/s/qL57AxdS4r5zlDzM57z2CQ
