1, Characteristics of hash function
- Input ∞, output S (limited range)
- Same in - > same out not random
- Different in - > same out hash collision. The probability is very small
- Different inputs can be almost uniformly dispersed to the S region
- Input, the number obtained through the hash function is in a limited range S, modulus m, and the results are also evenly distributed in the range of 0~M-1
2, Returns the maximum number of occurrences
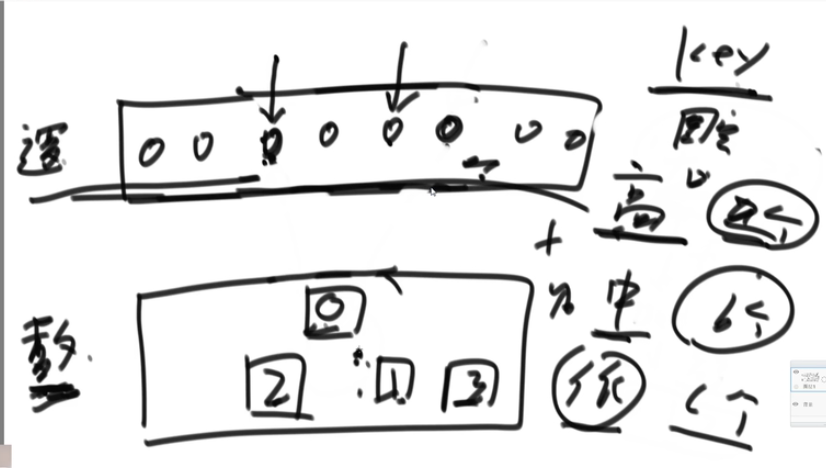
Title: unsigned integer 0 ~ 2 ^ 32-1, about 4 billion numbers. The value of each number is 0 ~ 4.2 billion. First, there is 1G memory. What is the number with the most occurrences?
- Hash table: 4B for key(int) and 4B for value(int). Ignoring the index space, 4 billion * 8b = 32 billion B=32G does not meet the requirements
The space occupied by the hash table is only related to the number of different numbers - Hash function: call the hash function for each number to get a value, and then modulo 100. The result is in the range of 0 ~ 99. After it is divided into 100 small files, each small file is used with a hash table.
Space used by hash table: 32G/100
After each small file is counted, the occupied space is released to count the next small file.
Find the number with the largest number of occurrences in each file, a total of 100, and then find the number with the largest number of occurrences in these 100 numbers.
3, Implementation of hash table
Method: one way linked list
In order to avoid the chain length being too long, the capacity can be expanded
Time complexity of hash function: O(1)
After the hash value is obtained, a value: O(1)
Add, check and change a record: O(1)
If N strings have been added, it has experienced logN expansion times: O(logN)
Cost of each expansion: O(N)
Total capacity expansion cost: O(NlogN)
Average and single expansion: O(NlogN)/N=O(logN)
-
Technology I
Set a longer chain length, O(NlogN)/N approximates O(1)
n is the bottom and n is the multiple of expansion -
Technology 2 - > offline capacity expansion technology (JVM and other virtual machine languages)
Use offline technology and do not occupy users' Online -
When the hash table is used, it can be considered that the addition, deletion, modification and query are O(1), which is O(logN) in theory
4, Design RandomPool structure
[title]
Design a structure with the following three functions:
insert (key): add a key to the structure without adding it repeatedly
delete (key): removes a key that was originally in the structure
getRandom(): random return of any key in the structure with equal probability
[requirements]
The time complexity of insert, delete and getRandom is O(1)
package com.zuogod.java;
import java.util.HashMap;
//Use two hash tables
public class RandomPool {
public static class Pool<K>{
private HashMap<K, Integer> keyIndexMap;
private HashMap<Integer, K> indexKeyMap;
private int size;
public Pool(){
this.keyIndexMap = new HashMap<K, Integer>();
this.indexKeyMap = new HashMap<Integer, K>();
this.size = 0;
}
public void insert(K key){
if (!this.keyIndexMap.containsKey(key)){ //If not, join; Yes, skip
this.keyIndexMap.put(key,this.size); //key is the first to come in
this.indexKeyMap.put(this.size++,key); //The first size comes in key, size++
}
}
public void delete(K key){
if(this.keyIndexMap.containsKey(key)){
int deleteIndex = keyIndexMap.get(key);
int lastIndex = --size;
K lastKey = this.indexKeyMap.get(lastIndex);
this.keyIndexMap.put(lastKey,deleteIndex);
this.indexKeyMap.put(deleteIndex,lastKey);
this.keyIndexMap.remove(key);
this.indexKeyMap.remove(lastIndex);
}
}
public K getRandom(){
if (this.size == 0){
return null;
}
int index = (int)(Math.random() * this.size); //0 ~ size-1
return this.indexKeyMap.get(index);
}
}
public static void main(String[] args) {
Pool<String> pool = new Pool<String>();
pool.insert("zuo");
pool.insert("cheng");
pool.insert("yun");
pool.remove("zuo");
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
}
}
5, Bitmap
- How to use a smaller memory unit to mark a number, and in the program, we use the bit bit of the smallest access unit, so how to mark (map) these data into a bitmap.
- How to make an array of bit type?
Spell with foundation type
int a = 0; //a 32bit int[] arr = new int[10]; //32bit*10 -> 320bits // arr[0] int 0~31 // arr[1] int 32~63 // arr[2] int 64~95 int i = 178; //Want to get 178 bit status int numIndex = 178 / 32; //Look at that number int bitIndex = 178 % 32; //In which number //Get the status of 178 int s = ( (arr[numIndex]) >> (bitIndex) & 1); //Shift right to find this bit, and 1 //Change the status of bit 178 to 1 arr[numIndex] = arr[numIndex] | (1 << (bitIndex)); //The number of original status bits or bits shifted left by 1 //Change the status of bit 178 to 0 arr[numIndex] = arr[numIndex] & (~ (1 << (bitIndex)); //The number of original status bits or bits shifted left by 1
6, Bloom filter
-
Bloom filter is a compact and ingenious probabilistic data structure. It is characterized by efficient insertion and query to judge whether something exists. It uses multiple hash functions to map a data into a bitmap structure, which can not only improve the query efficiency. It can also save a lot of memory space.
-
Solve similar blacklist query model
-
Only adding and querying, not deleting
-
Save memory space and speed up query time
-
If there is a mistake rate, you will not judge the right one wrong, but you may judge the wrong one right
(1) Black - > white × This is impossible
(2) White - > black √ -
operation
(1) Add: call k hash functions for each url to get the hash value out1, then modulo m = > get k numbers, and mark the corresponding K numbers black
(2) Query: urlx calls K same hash functions to get the hash value out, then modulus m = > to get k numbers, and query the status of the corresponding position of the corresponding K numbers
If all are 1, the url is in the blacklist set; If not all are 1, the url is not in the blacklist
-Determine the appropriate number of hash functions according to m and the specific sample size (the number of hash functions is equivalent to the number of feature points, but not too many, and the error rate will increase if there are too many)
(1) Bloom filter is only related to n = sample size and p = error rate, and has nothing to do with the size of a single sample (that is, a url of 64 bytes is useless, as long as the called hash function can receive 64 bytes of parameters)
The size of a single sample is independent of the size of the bloom filter and the number of hash functions
(2) Array size: m = - (n * lnp) / (ln2)^2
Where, M is the required bit number, n is the sample size, and p is the expected error rate; The number of bytes is m/8
(3) Number of hash functions: K = ln2 * m/n = 0.7 * m/n
(4) The size of the array and the number of hash functions are rounded up, and the real error rate is: (1 - e ^ (- n*K/m))^K
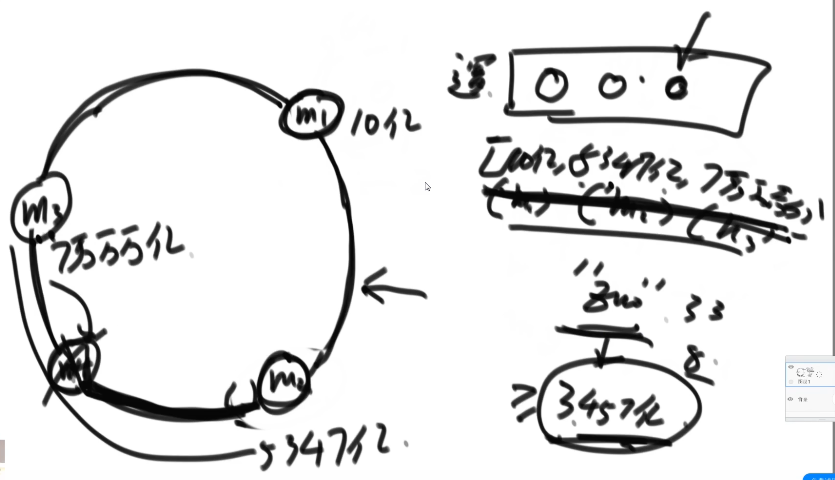
7, Consistency hash
- For the hash table with K keywords and n slots (nodes in the distributed system), only K/n keywords need to be remapped on average after increasing or decreasing slots.
- Hash index
To evaluate the advantages and disadvantages of a hash algorithm, there are the following indicators, and all consistent hashes meet the following requirements:
(1) balance: the hash addresses of keywords are evenly distributed in the address space to make full use of the address space, which is a basic feature of hash design.
(2) monotonicity: monotonicity refers to a new address space in which the hash address of the keyword obtained by the hash function can also be mapped when the address space increases, rather than being limited to the original address space. Or when the address space is reduced, it can only be mapped to a valid address space. Simple hash functions often cannot meet this property.
(3) spread: hash is often used in distributed environment. End users store their contents in different buffers through hash function. At this time, the terminal may not see all buffers, but only some of them. When the terminal wants to map the content to the buffer through the hash process, the buffer range seen by different terminals may be different, resulting in inconsistent hash results. The final result is that the same content is mapped to different buffers by different terminals. This situation should obviously be avoided, because it causes the same content to be stored in different buffers, reducing the efficiency of system storage. Dispersion is defined as the severity of the above situation. A good hash algorithm should be able to avoid inconsistency as much as possible, that is, to reduce the dispersion as much as possible.
(4) load: the load problem is actually a decentralized problem from another perspective. Since different terminals may map the same content to different buffers, a specific buffer may also be mapped to different content by different users. Like decentralization, this situation should be avoided, so a good hash algorithm should be able to minimize the load of buffer. - How does the data select the machine?
Find the nearest one through the hash ring. (dichotomy) - Selection of hash Key:
There are many kinds of choices, so that there are a number of keys in high frequency, intermediate frequency and low frequency for data division (average).
-
Advantages: it can reduce the cost of data migration and balance the load at the same time
-
Question 1:
How to ensure load balancing for a small number of machines? -
Question 2:
Even at the beginning of load balancing, if a machine is suddenly added, how to ensure load balancing? -
Solution: virtual node technology (in proportion) = > advantages: manage load