Article catalogue
catalogue
2.1 definition of default parameters
2.2 classification of default parameters
2.3 precautions for default functions
3.1 definition of function overload
3.2 principle of function overloading
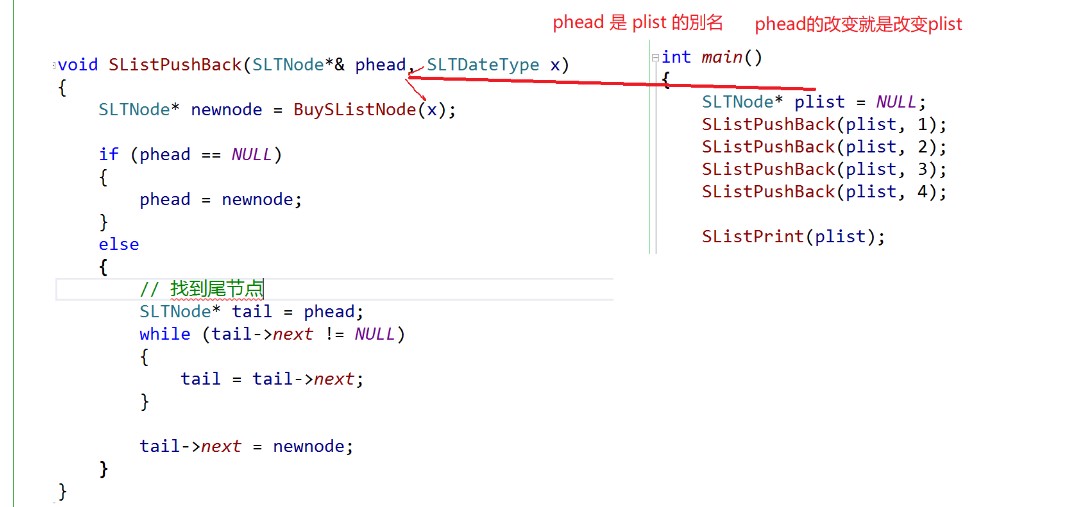
4.3.3 reference as return value
4.5 difference between reference and pointer
5.2 concept of associative function
5.3 characteristics of associative functions
6.2.1. auto is used in conjunction with pointers and references
6.2.2. Define multiple variables on the same line
6.2.3auto scenarios that cannot be deduced
preface
Finally made this decision to write a blog well. There may be many deficiencies in it. I hope you can correct it in the comment area. If you have comments, you must pay a return visit..
1. Input and output of C + +
1.1.C + + header file
To understand the input and output of C + +, you must first know the header file of C + +.
#include<iostream> using namespace std;
The header file in c + + library, and #include < stdio h> The input / output stream is the same. The second sentence? This sentence is found in many reference books. After learning the namespace, you will probably know what it means. This is the standard namespace std. after writing this sentence, you can directly write cout or cin. But it's not good to write this sentence, because the implementation of c + + library is defined in a namespace called std. if it is written in this way, all the contents in std library will be expanded, which will lead to invalidation. But it doesn't matter to practice writing like this.
1.2.C + + I / O
cout << "hello world" << endl;
cout << "hello world\n" ;
printf("hello world\n");cout is the output, and then < < is the stream insertion, and then the endl is equivalent to line feed. There is a second way to write this line feed, which is the second line.
int i = 1; double d = 1.11; cout << i << d << endl;
Here we find that there is no need to specify the type of variable in C + + syntax. Just write the variable directly.
struct Student
{
char name[20];
int age;
// ...
};
int main()
{
struct Student s = { "Travis", 18 };
// cpp
cout <<"full name:" <<s.name << endl;
cout << "Age:" << s.age << endl << endl;
// c
printf("full name:%s\n Age:%d\n", s.name, s.age);
}It can be seen here that C + + is not necessarily more convenient than C, so consider it yourself when using it.
cin >> s.name >> s.age;
cout << "full name:" << s.name << endl;
cout << "Age:" << s.age << endl << endl;
scanf("%s%d", s.name, &s.age);
printf("full name:%s\n Age:%d\n", s.name, s.age);cin is the input and > > is the stream extraction operator. The input here does not need to specify the variable type. Write the variable directly after the stream extraction operator. You're welcome endl to pay attention here.
2. Default parameters
2.1 definition of default parameters
The default parameter is to specify a default value for the parameter of the function when the function is declared or defined. When calling this function, if no argument is specified, the default value is adopted; otherwise, the specified argument is used.
2.2 classification of default parameters
Default parameters are divided into two categories: full default parameters and semi default parameters
**All default parameters
void Func(int a = 10,int b = 20, int c = 30)
{
cout << "a =" << a << endl;
cout << "b =" << b << endl;
cout << "c =" << c << endl;
}
int main()
{
Func();
Func(1);
Func(1, 2);
Func(1, 2, 3);
}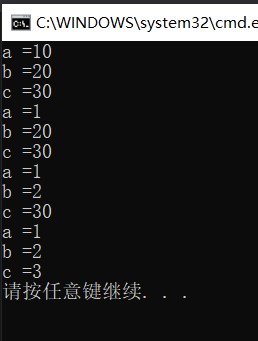
You can see the results of the above pictures. It should be noted that the value is passed from left to right when calling the function.
You can't just pass it to B, like Func (, 2,);, That won't work.
**Semi default parameter
void TestFunc(int a, int b = 10, int c = 20)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl<<endl;
}
int main()
{
TestFunc(1);
TestFunc(1,2);
TestFunc(1,2,3);
}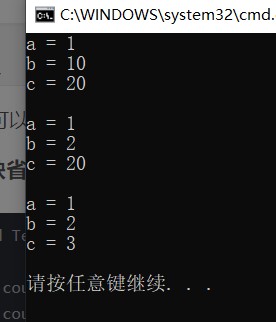
This is the call of semi default parameters. Many students will ask whether it can be called in this way.
TestFunc(1, ,2);
This is not possible because it is a grammatical error. Let me show you the results of the compiler.
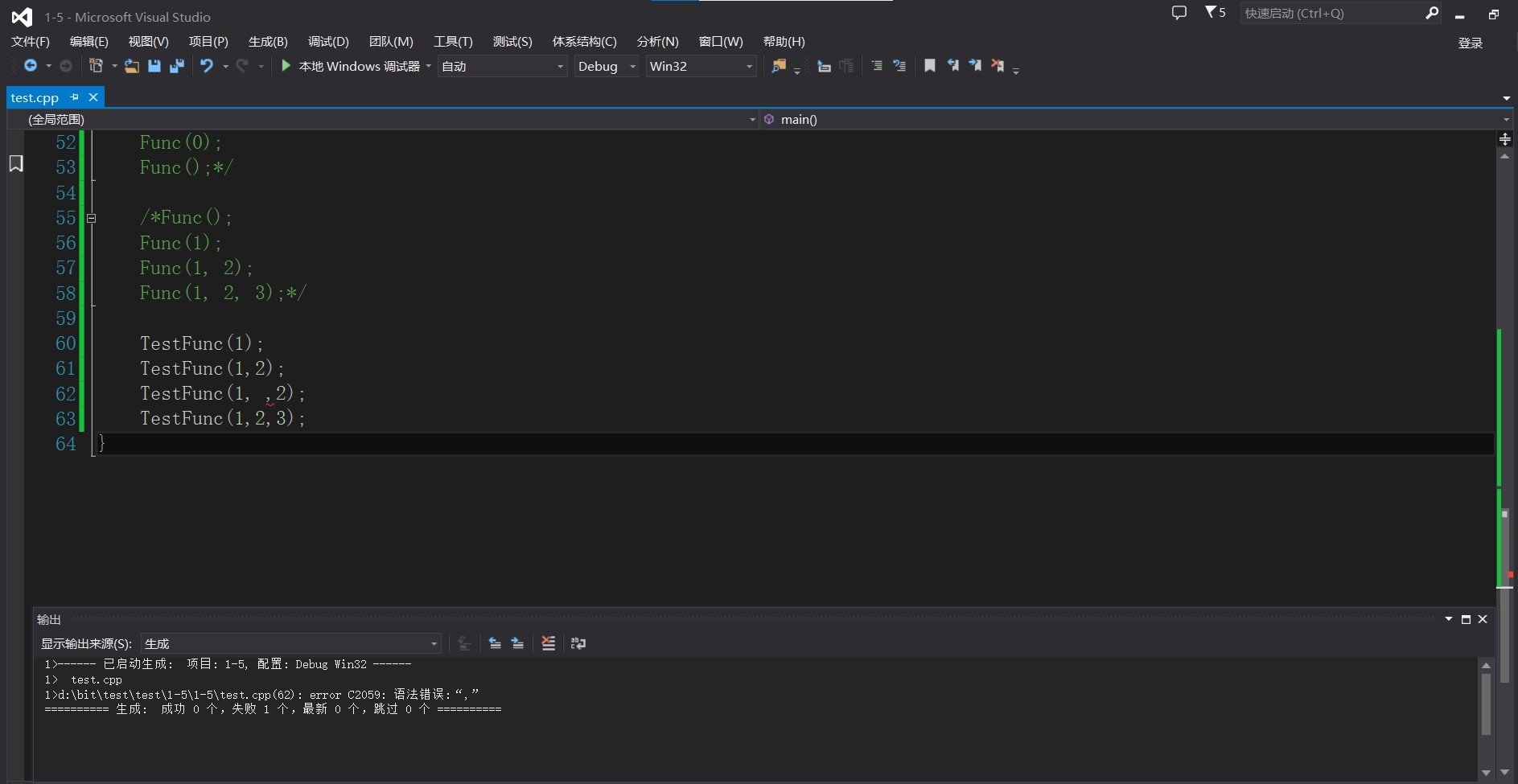
Then some students will ask, can we define semi default functions in this way.
void TestFunc1(int a, int b = 10, int c )
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl<<endl;
}
void TestFunc2(int a = 10, int b , int c)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}This is not possible, because the default function must start from left to right. If the compiler like the above code will report an error.
2.3 precautions for default functions
Semi default parameters must be given from right to left, and cannot be given at intervals
Default parameters cannot appear in function declarations and definitions at the same time
The default value must be a constant or a global variable
C language cannot implement default functions
3. Function overloading
3.1 definition of function overload
Function overloading: it is a special case of functions. C + + allows to declare several functions with the same name with similar functions in the same scope. The formal parameter list (number or type or order of parameters) of these functions with the same name must be different. It is commonly used to deal with the problems of similar functions and different data types. Then let's try it according to these situations.
**Number of parameters
int Add(int left, int right)
{
cout << left + right << endl;
return 0;
}
int Add(int left,int mid,int right)
{
cout << left + mid + right << endl;
return 0;
}
int main()
{
Add(1,9);
Add(1,5,7);
}**Type
int Add(int left, int right)
{
cout << left + right << endl;
return 0;
}
int Add(double left, double right)
{
cout << left + right << endl;
return 0;
}
int main()
{
Add(1,8);
Add(1.6,1.9);
}**Order
int Add(int left, double right)
{
cout << left - right << endl;
return 0;
}
int Add(double right, int left)
{
cout << left - right << endl;
return 0;
}
int main()
{
Add(1,1.9);
Add(1.9,1);
}**Special circumstances * *
The return value is different and cannot constitute an overload
short Add(short left, short right)
{
return left+right;
}
int Add(short left, short right)
{
return left+right;
}
The default value is different and cannot constitute an overload
void f(int a)
{
cout << "f()" << endl;
}
void f(int a = 0)
{
cout << "f(int a)" << endl;
}Constitute an overload, but there will be problems when using: f(); Ambiguous call
void f()
{
cout << "f()" << endl;
}
void f(int a = 0)
{
cout << "f(int a)" << endl;
}
int main()
{
// f(); // Ambiguous call
f(1);
return 0;
}3.2 principle of function overloading
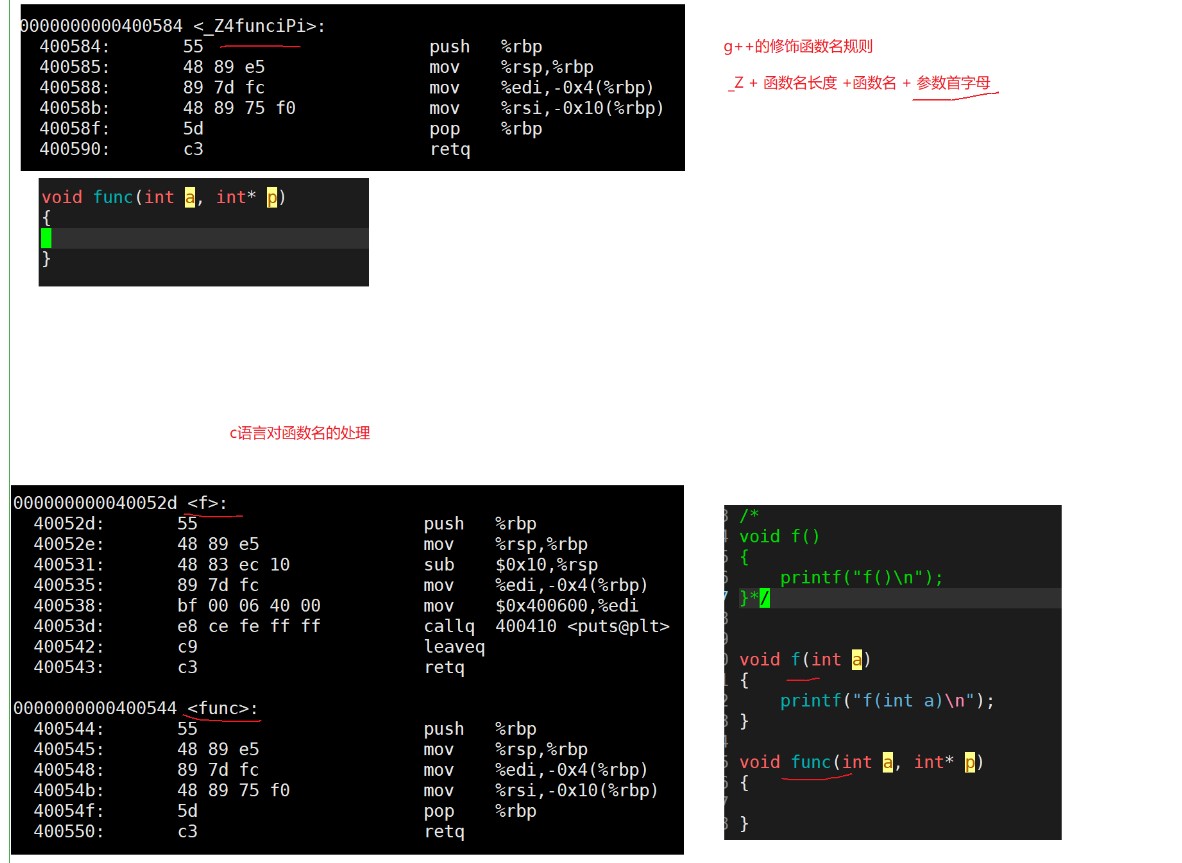
We should know that C language does not support function overloading, but why?
At this time, we should know the principle of the compiler, which is divided into: preprocessing (header file expansion, macro replacement, conditional compilation, removing comments) - > compilation (checking syntax, generating assembly code) - > assembly (converting assembly code into binary code) - > links. Now let's look at a program.
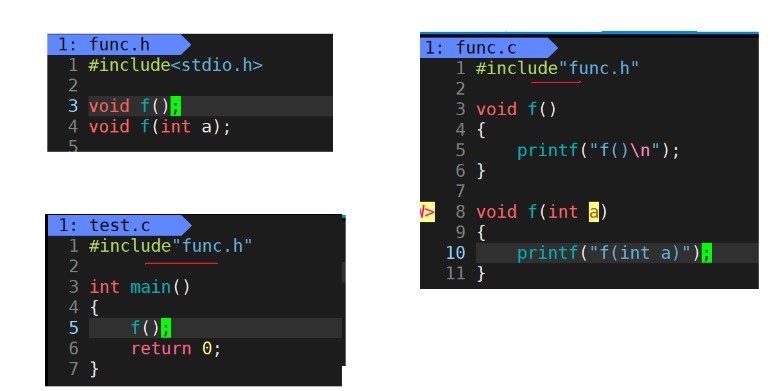
Now let's analyze why C language does not support function overloading.
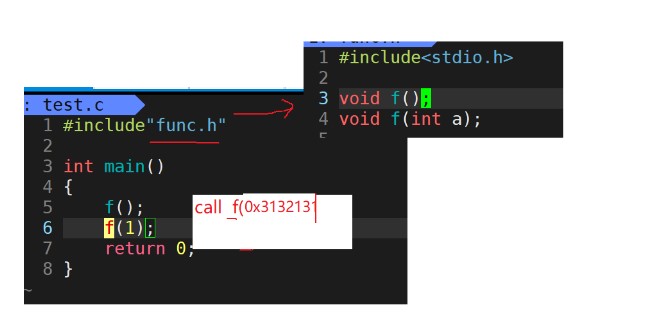
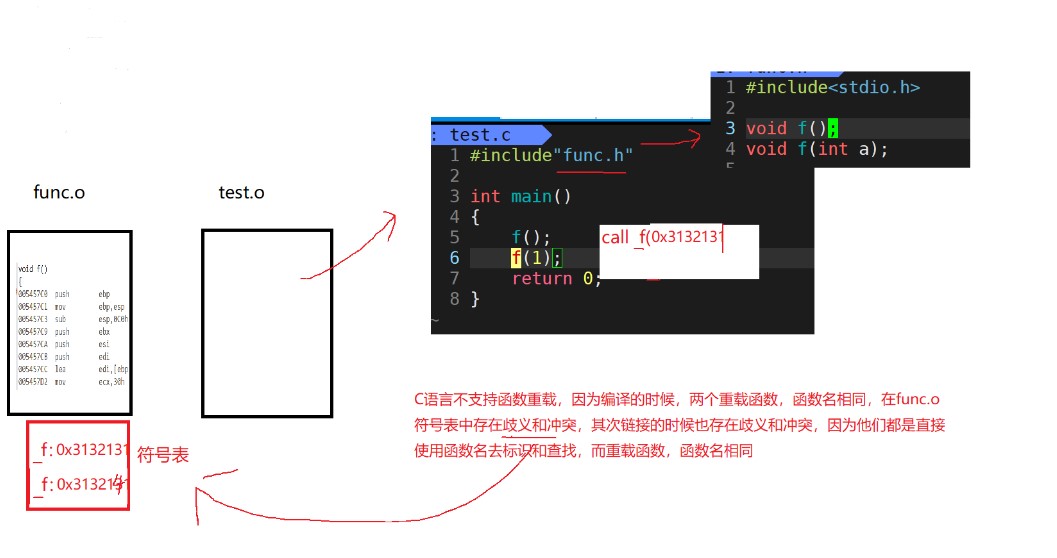
First, in func C is the function definition, test C is the main function to call the function. The address can be generated only when the function is defined. In test In C, there is #include "func.h" at the top. This is a function declaration. Calling the function during compilation will generate a call_f(?) , You might ask why_ f(), because the syntax of C language stipulates to use the function name when there is a function declaration during compilation. And the following (?), It is used to find the address when linking. If the function definition is also in test C inside, that's no good, test Symbol table will also be generated in C, because the naming rules of C language lead to ambiguity in the symbol table generated by him. For details, refer to func c.
Next comes func C, there is also a function definition here, so I won't talk more about it, and then the content in the function definition.

At this time, a symbol table will be generated in the function definition.

Let's make a summary at this time.
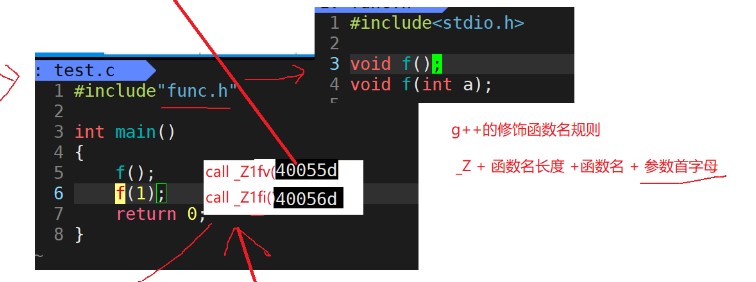
Now let's discuss why C + + supports function overloading. It introduces a function name naming rule.
First, test c. The difference is that it is not the same when compiling_ f(?), But_ Z1fi(?), Why this? Because the naming rules of C language and C + + are different, C language is based on the function name, while C + + is based on_ Z + function name length + function name + parameter initials. In this way, there will be no ambiguity when linking_ Z1fi(?) The question mark here is the address you get when you link.
Then func c. The generated symbol tables are also different. Here we can clearly see the difference between the two symbol tables.
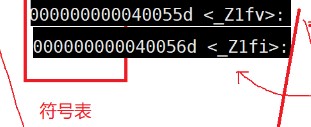
So here's another look at func C and test C compiled content.
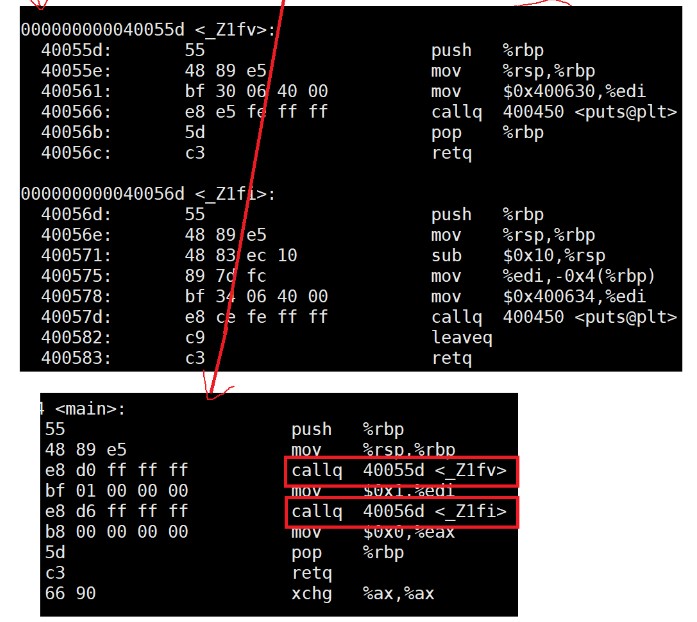
So let's summarize.
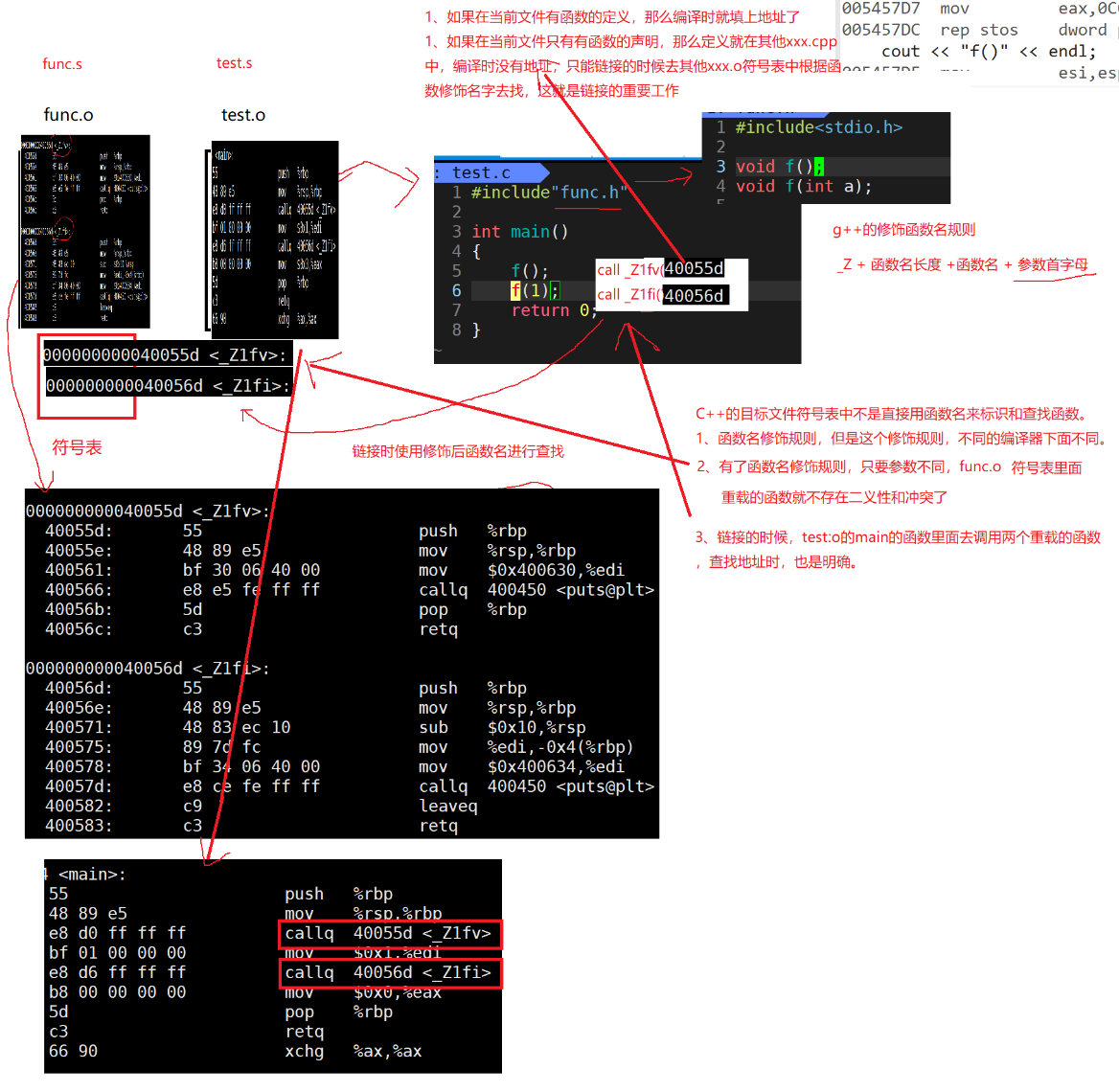
Now get familiar with the difference between C language and C + + naming.
4. Reference
4.1 referenced concepts
Instead of defining a new variable, a reference gives an alias to an existing variable. The compiler will not open up memory space for the referenced variable. It shares the same memory space with the variable it references.
int main()
{
int a = 10;
int &b = a;
cout << a << endl;
cout << b << endl;
}
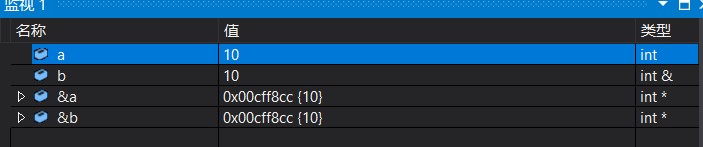
Quoting is equivalent to a a taking another name b. they share a space.
Note: the referenced variable must be of the same data type as the original variable.
4.2 reference characteristics
1. Reference must be initialized when defining
int main()
{
int a = 10;
int &b;
}
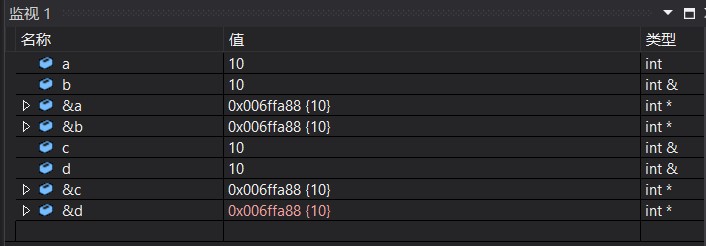
2. A variable can have multiple references
int main()
{
int a = 10;
int &b = a;
int &c = a;
int &d = b;
}
3. Reference once an entity is referenced, other entities cannot be referenced
int main()
{
int a = 10;
int& b = a;
int c = 20;
b = c;
}Is this an alias for c? Or give the value of c to b?
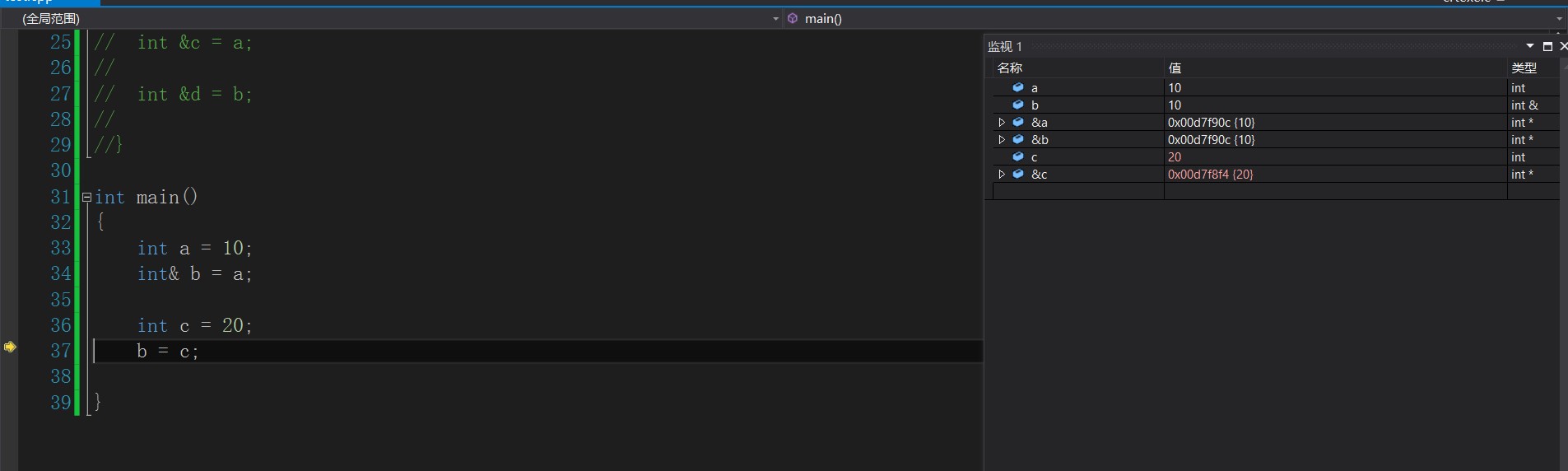
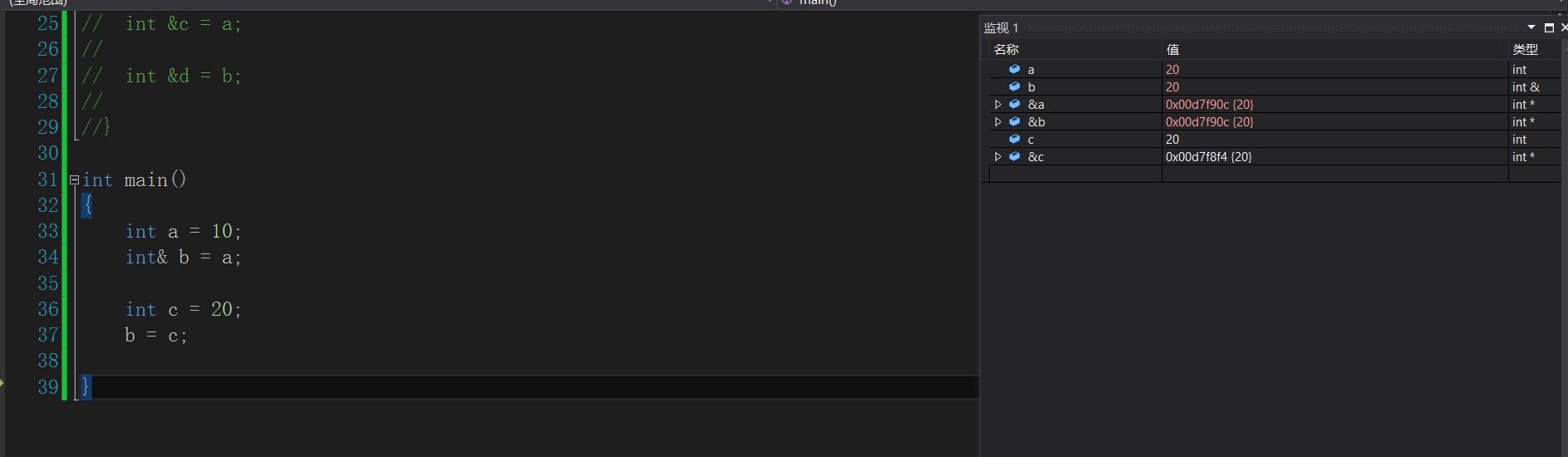
You can see here that the value of the space where b is located is changed to c, so there is no alias for c.
4.3 application of references
4.3.1 reference of pointer
The first is the previous secondary pointer. The previous secondary pointer may not be well understood. This can be replaced by a reference. Let's take a look at a piece of code. Any type can be referenced, and pointers are no exception. Here they are called pointer references.
int main()
{
int a = 10;
int *p1 = &a;
int** p2 = &p1;
int*& p3 = p1;
}
Here, there is a space called a, the value stored in it is 10, and there is a pointer variable called p1, which stores the address of a, and then gives this p1 an alias called p2.

Here's how to replace the secondary pointer with a reference.
4.3.2 reference as parameter
void Swap(int *px, int *py)//Address transfer call
{
int a;
a = *px;
*px = *py;
*py = a;
}
void Swap(int&rx, int& ry)//Pass reference
{
int a;
a = rx;
rx = ry;
ry = a;
}
void Swap(int x, int y)//Value transmission
{
int a;
a = x;
x = y;
y = a;
}
int main()
{
int x = 10, y = 20;
cout << x <<" "<< y << endl;
Swap(&x,&y);
cout << x << " " << y << endl;
Swap(x,y);//There is ambiguity between value passing and reference passing, although they constitute overloaded functions.
cout << x << " " << y << endl;
}4.3.3 reference as return value
To learn this content, we must first understand one thing, that is, value passing and return.
//Pass value return value
int Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int ret = Add(1, 2);
cout << ret << endl;
return 0;
}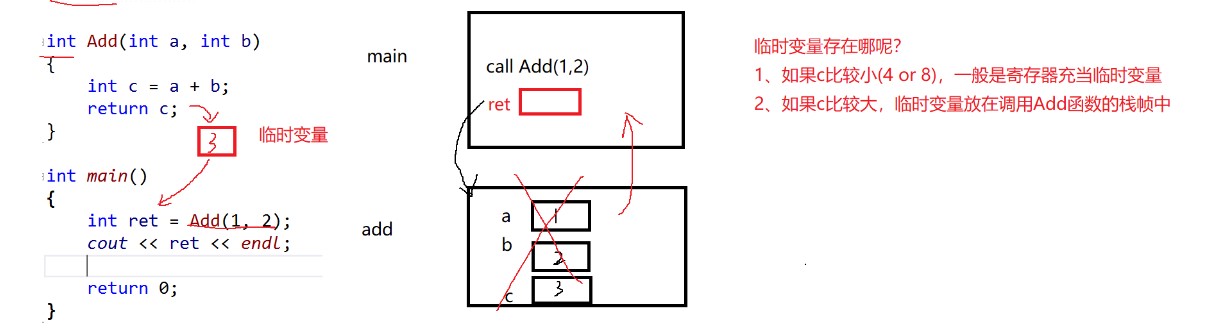
Let's look at this figure to analyze. First, the main and Add functions will generate a space. Where the main function calls the Add function to enter the Add function, three small spaces will be generated in the space generated by the Add function to store variables a, B and c. then, after a+b, return returns the value of c. at this time, the value of c will be stored in a temporary variable, The space generated by the Add function will be returned to memory. After the function is called, the value of ret is a temporary variable, not c.
Let's look at the reference return value again.
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
cout << ret << endl;
}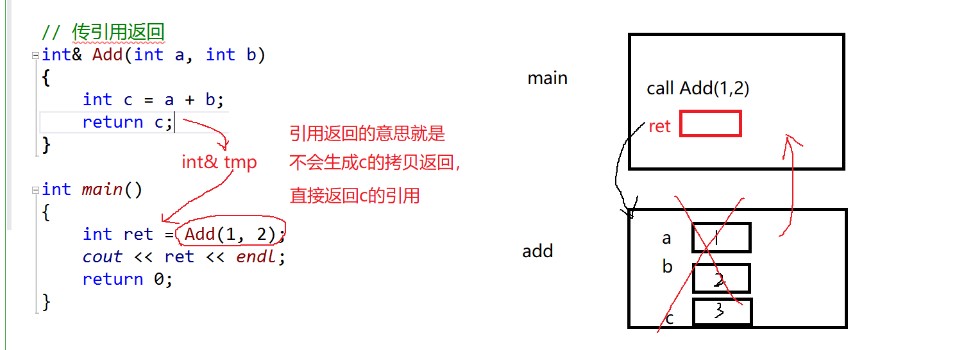
Most of them are the same as those above. I'll just say something different now. When the add function is completed, the returned value is the reference (alias) of c, and then a reference is also required to accept it. It is wrong in the figure. It should be int & ret. at this time, many people will ask, shouldn't the add function reclaim its own space when it is over, The reference RET of c is useless. This has a lot to do with the compiler. Some compilers will clear the data when the function returns space, while others won't. I won't use vs2013, which will cause problems. The problem in the figure below is that after the add function is called again, the data in the original space is overwritten, and the space pointed to by RET is still that one, so it becomes 30.
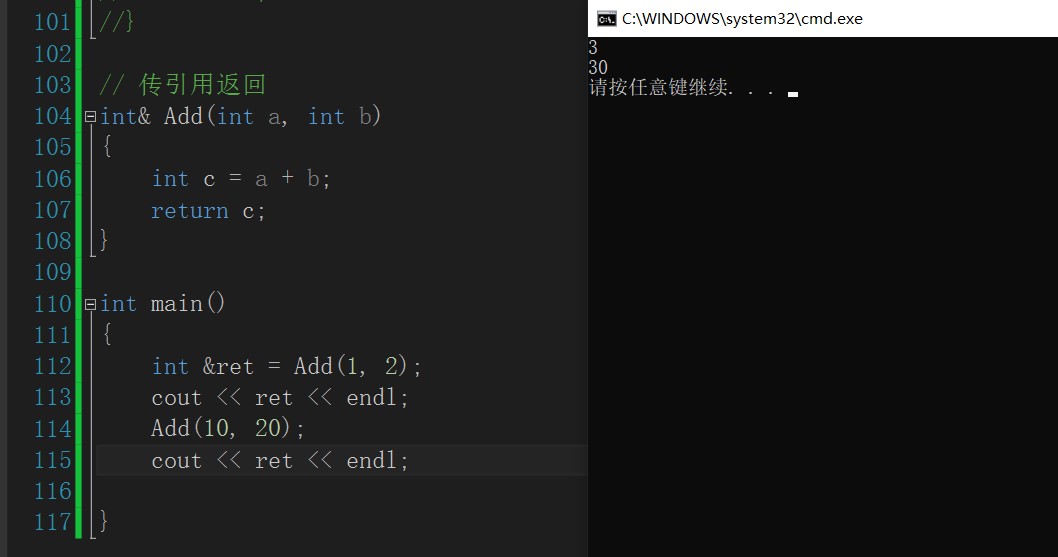

Then I also want to say that as long as the function is called, it will consume a piece of space. The same is true for printf and cout. If there is a value after the function is called, the space will be overwritten.
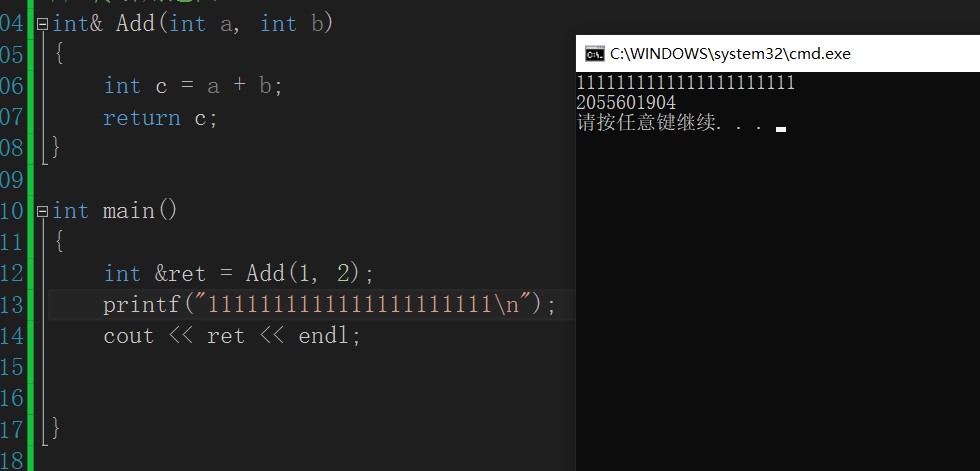
So how can this be avoided? For example, using static can be effective when the scope of the function is given.

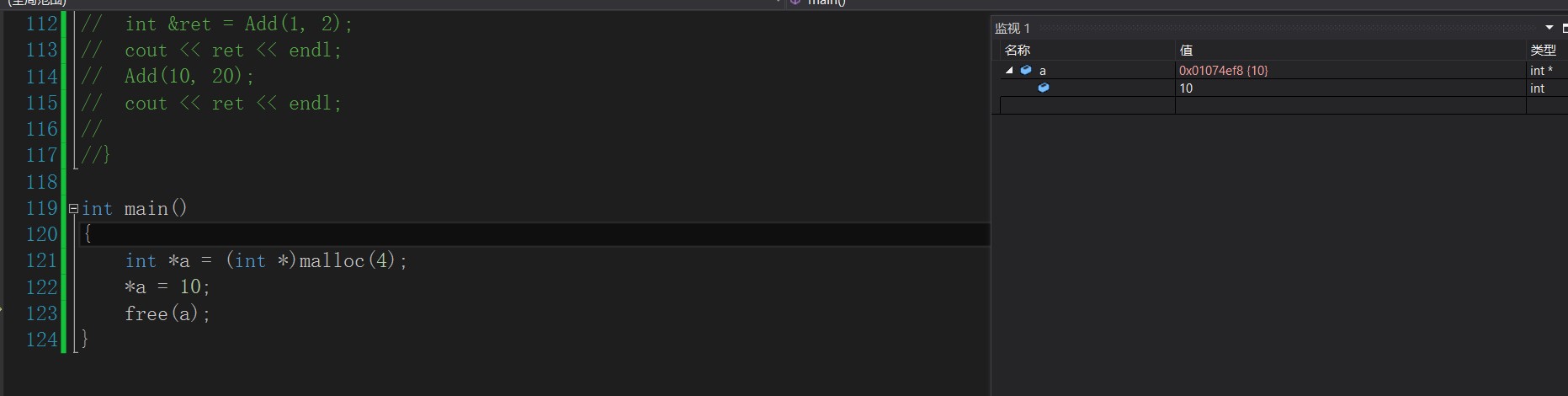
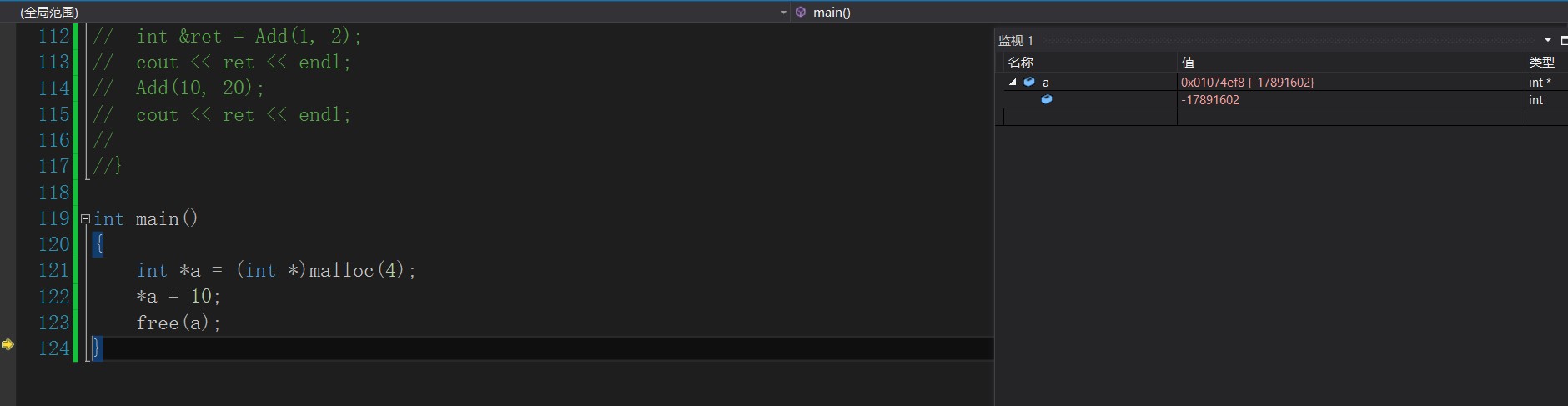
It should be noted that for the space generated by malloc, free will clear the data.
Many people ask and learn what the use of this reference is. When passing values, they feel that they have no advantage. When the data is very large, it is a waste of time and space to pass the value, because the value must be copied every time the function is called, and it is not necessary to pass the reference. Now let's take a look at an example.
#include <time.h>
struct A{ int a[10000]; };
A a;
// Return value -- 40000 bytes per copy
A TestFunc1() { return a; }
// Reference return -- no copy
A& TestFunc2(){ return a; }
void TestReturnByRefOrValue()
{
// Takes the value as the return value type of the function
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// Take reference as the return value type of the function
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// Calculate the time after the operation of two functions is completed
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{
A a;
// Take value as function parameter
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// Take reference as function parameter
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// Calculate the time after the two functions run respectively
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
//TestRefAndValue();
return 0;
}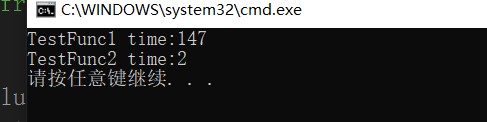
Here you can see the advantages of passing references over passing values.
| 1. Referring to pass parameter and return value can improve performance in some scenarios. (large object + deep copy object -) | ||
| 2. Reference pass parameter and return value, output type parameter and output type return value. Generally speaking, in some scenarios, the parameters can be changed by changing the formal parameters. | ||
| In some scenarios, the return object can be changed by referring to the return-- Find out |
4.4 frequently cited
// Permission amplification is not allowed //const int a = 10; //int& b = a; // Permission unchanged const int a = 10; const int& b = a; // Permission can be reduced int c = 10; const int& d = c;
This code is easy to understand, needless to say.
int main()
{
double d = 1.11;
int i1 = d;
//int &i2 = d;
const int &i3 = d;
}
Where int = i1=d; This code is the shaping promotion of c language. It is equivalent to that the value of d exists in a temporary variable and it is constant (immutable), and then give the value in the temporary variable to i1. At this time, the value of i1 will become shaping. Only type conversion can generate temporary variables!!!

Int & I2 = d, why can't this code work? Because the value of d exists in the temporary variable, that is, the temporary variable is constant, and its permission will become larger, so it cannot be referenced., Therefore, the const sentence will be added to reduce its permission. At this time, i3 is the alias of the temporary variable.

4.5 difference between reference and pointer
1. The reference must be initialized during definition, and the pointer is not required
2. After a reference references an entity during initialization, it can no longer reference other entities, and the pointer can point to any entity of the same type at any time
3. There is no NULL reference, but there is a NULL pointer
4. Different meanings in sizeof: the reference result is the size of the reference type, but the pointer is always the number of bytes in the address space (4 bytes in 32-bit platform)
5. Reference self addition means that the referenced entity is increased by 1, and pointer self addition means that the pointer is shifted backward by one type
6. There are multi-level pointers, but there are no multi-level references
7. There are different ways to access entities. The pointer needs to be explicitly dereferenced, and the reference compiler handles it by itself
8. References are relatively safer to use than pointers
5. Associative function
5.1 simple macros
To learn about associative functions, we need to know macros, so let's write a piece of macro code. When writing the macro of this function, many people may write the first sentence as #define Add(x,y) x+y. there is no problem with simply calling this sentence, but when calling, change it to 10 * Add(1, 9), then it won't work. When we write its expression, it becomes 10 * 1 + 9. It is obvious that the answer is 19, which is different from our expected result, At this time, our macro is changed to #define Add(x,y) (x+y). This is still a problem. If the parameters passed when calling the function are (A & B, a | b), we write the expression, that is, a & B + a | B. through the learning of c language, we know that + has higher priority than & and | so we operate on + first, so there is still a problem with the macro written in this way, At this time, we changed it to #define Add(x,y) ((x)+(y)).
int Add(int &x, int &y)
{
int ret = x + y;
return ret;
}
//#define Add(x,y) x+y
//#define Add(x,y) (x+y)
#define Add(x,y) ((x)+(y))
int main()
{
cout << Add(1, 9) << endl;//cout<<1+9<<endl;
cout << 10 * Add(1, 9) << endl;//cout<<10*1+9<<endl;
int a = 0, b = 1;
cout << Add(a&b, a | b) << endl;//cout<<a& b+a|b<<endl;
}5.2 concept of associative function
By writing the macro of the Add function, we find that the macro is still relatively complex. Therefore, in order to make up for the shortcomings of C language, C + + has a class associative function. Why learn macros and associative functions?
Because the function stack frame will be consumed when calling the function, and some registers will be saved in the stack frame and restored after the end. We see that it is consumed.
inline int Add(int &x, int &y)
{
int ret = x + y;
return ret;
}
int main()
{
int a = 1, b = 2;
int ret = Add(a, b);
cout << ret << endl;
}//int Add(int &x, int &y)
//{
// int ret = x + y;
// return ret;
//}
int main()
{
int a = 1, b = 2;
int ret = Add(a, b);
cout << ret << endl;
}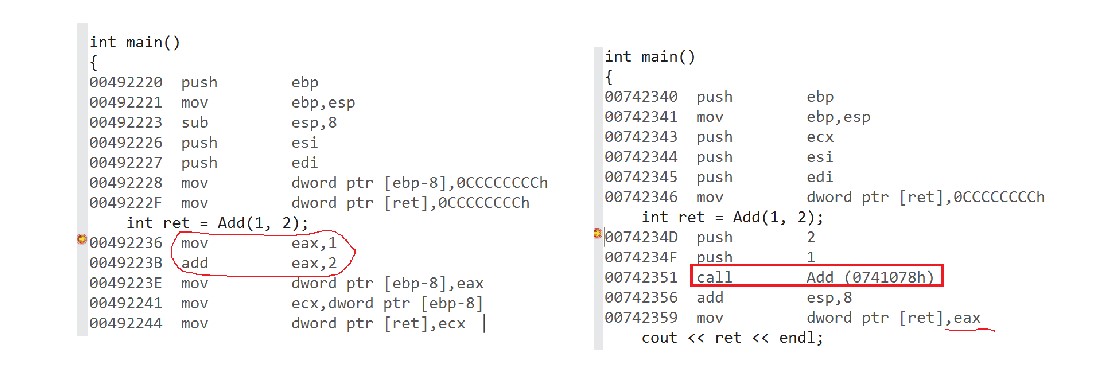
In the Debug environment, turn the above two pieces of code into assembly language, and illine will expand the function directly, instead of calling the function without inline.
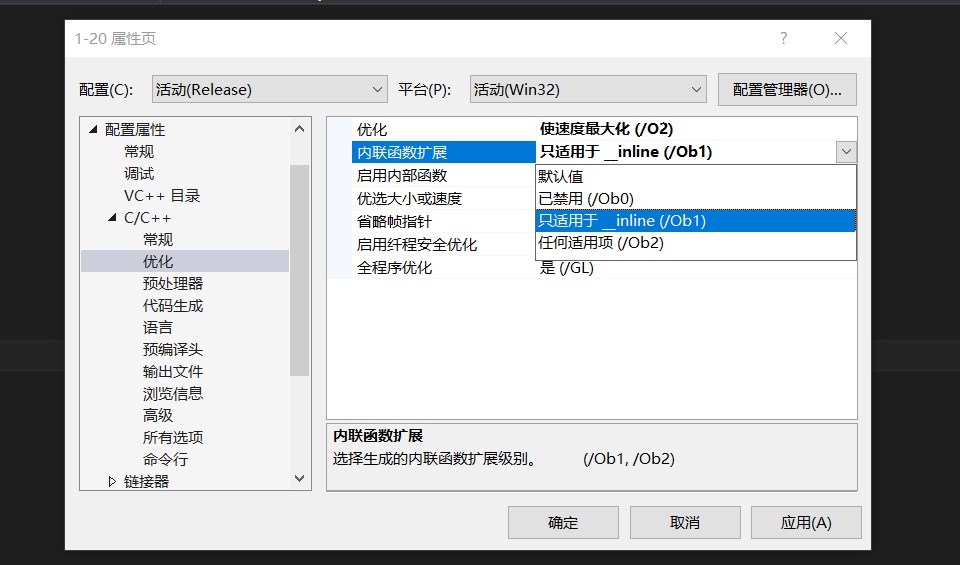
There are also some things that need to be changed under Debug to make inline work.
5.3 characteristics of associative functions
1. inline is a method of exchanging space for time, which saves the cost of calling functions. Therefore, functions with long code or loop / recursion are not suitable for inline functions.
2. inline is only a suggestion for the compiler. The compiler will optimize automatically. If there are loops / recursions in the function defined as inline, the compiler will ignore the inline during optimization.
3. inline does not recommend the separation of declaration and definition, which will lead to link errors. Because the inline is expanded, there will be no function address, and the link will not be found.
4. inline can be used when the code is short and trivial.
6.auto keyword
6.1 introduction to uto
In the early C/C + +, the meaning of auto is: the variable modified by auto is a local variable with automatic memory, but unfortunately, no one has used it. You can think about why? In C++11, the standards committee gives a new meaning to auto, that is, auto is no longer a storage type indicator, but as a new type indicator to indicate the compiler. The variables declared by auto must be derived by the compiler at compile time
int main()
{
//const int a = 10;
//auto b = a;
auto d = 20;
auto e = 1.6;
auto f = 'a';
auto g = "asda";
//cout << typeid(a).name() << endl;
cout << typeid(d).name() << endl;
cout << typeid(e).name() << endl;
cout << typeid(f).name() << endl;
cout << typeid(g).name() << endl;
}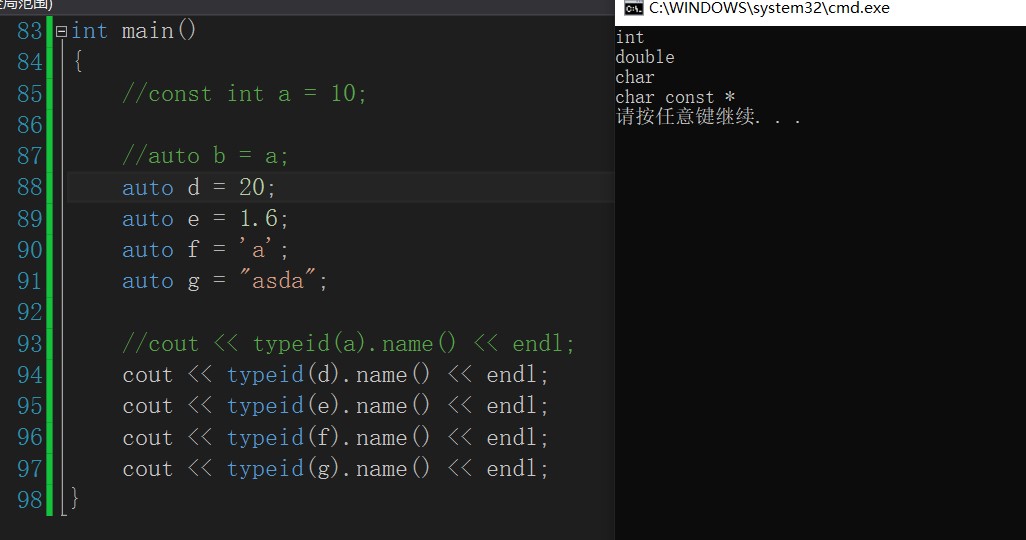
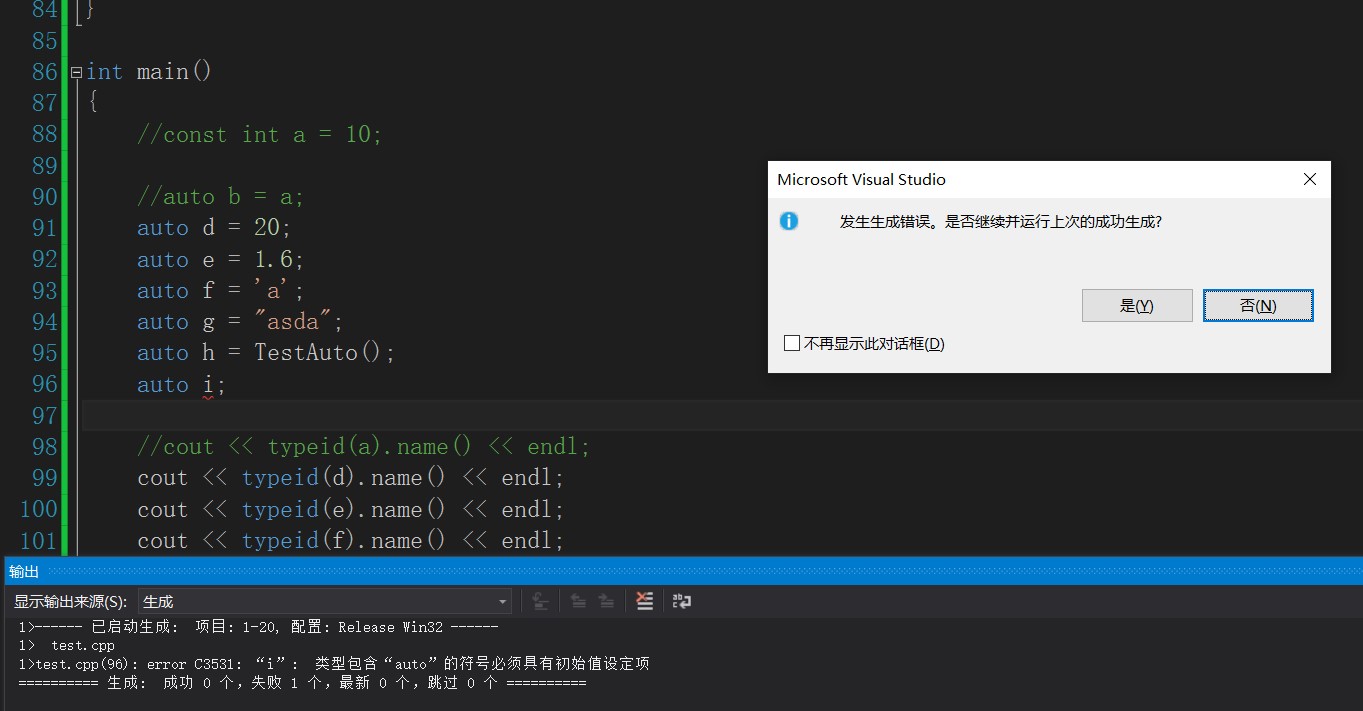
You can see the results of the compiler. Auto is the type of data that can be deduced. Cout < < typeID (b) name() << endl; It is the type of test variable. There is no need to study it here. Just understand it. Also, note that the variables from auto must be initialized.
auto can also be used to end the return value of a function. If the return value is of type char and double, it will be converted to int.
6.2auto usage rules
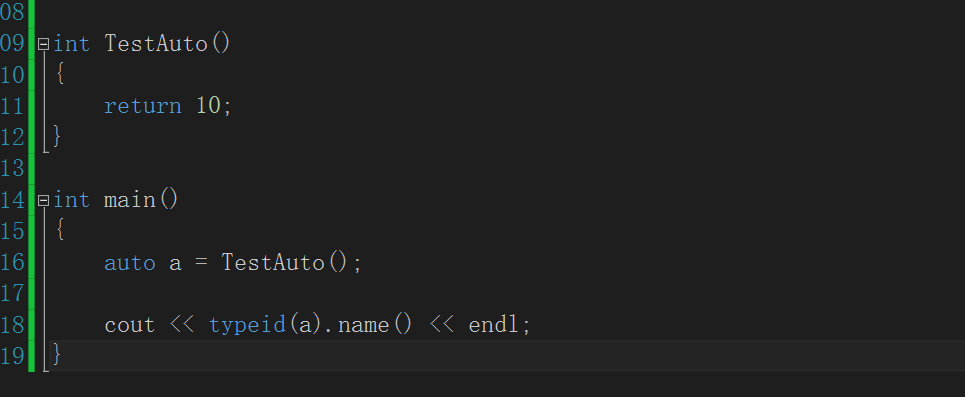
6.2.1. auto is used in conjunction with pointers and references
int main()
{
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 100;
*b = 200;
c = 300;
cout << *a << endl;
cout << *b << endl;
cout << c << endl;
}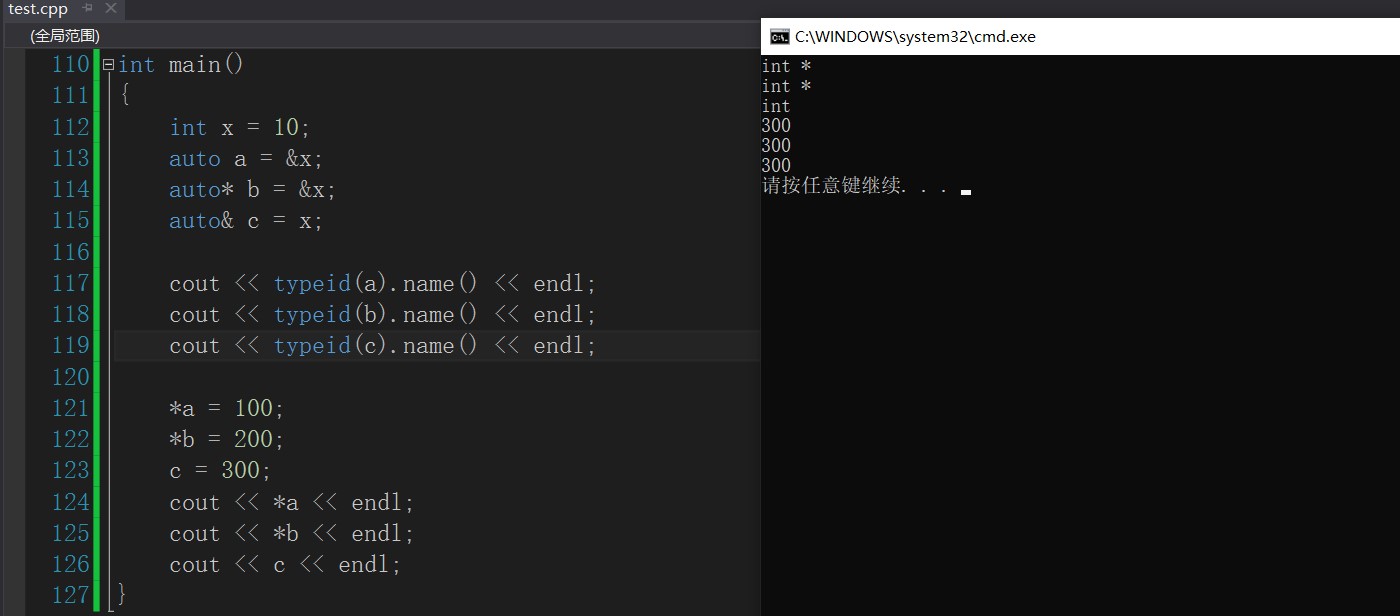
Here Auto a = & X; And auto * b = & X; In fact, it means that they are all converted to pointers, and the c variable is a reference.
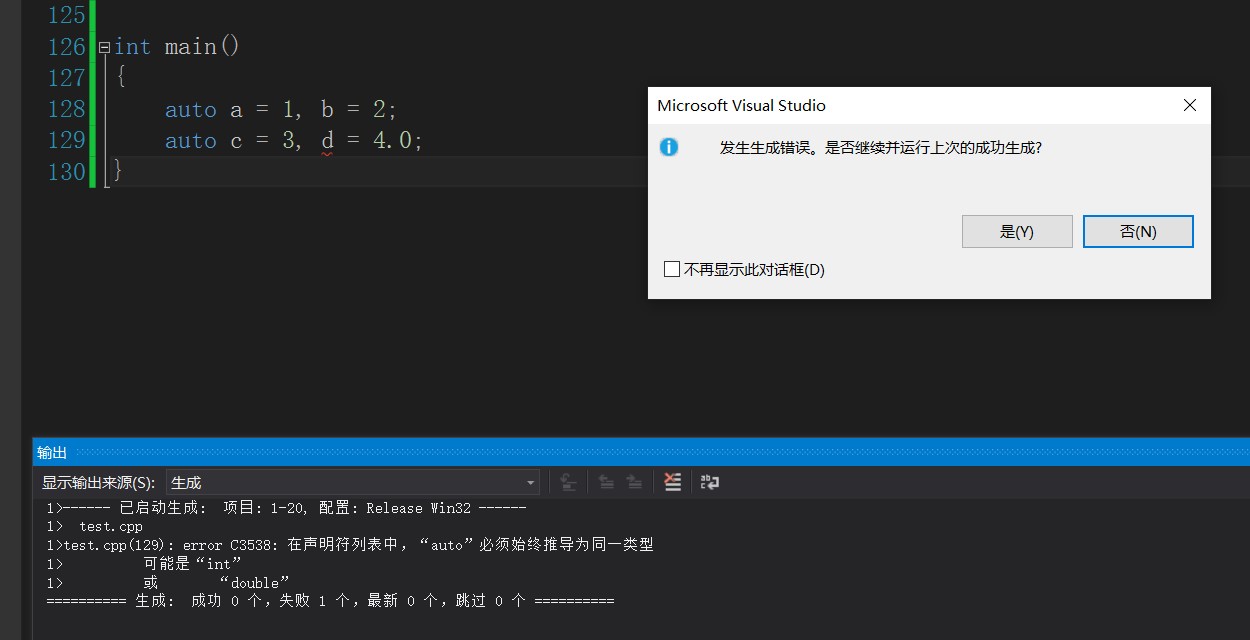
6.2.2. Define multiple variables on the same line
int main()
{
auto a = 1, b = 2;
auto c = 3, d = 4.0;
}The first line is OK, but the second line is not, because the auto definition must be the same type, otherwise the compiler will report an error.
6.2.3auto scenarios that cannot be deduced
1. auto cannot be used as a parameter of a function
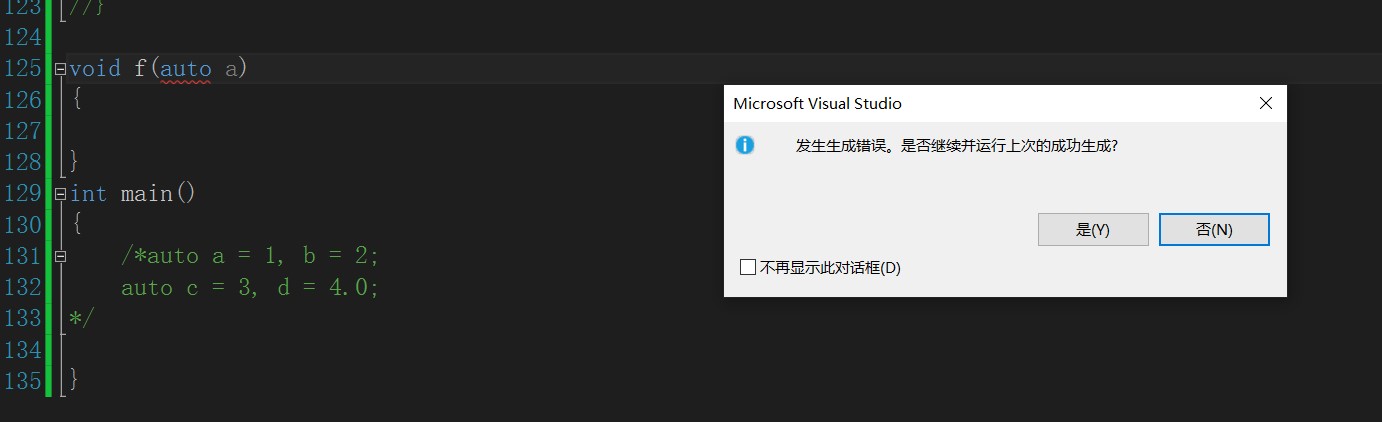
2. auto cannot be directly used to declare arrays
3. In order to avoid confusion with auto in C++98, C++11 only retains the use of auto as a type indicator
4. The most common advantage usage of auto in practice is the new for loop and lambda expression provided by C++11, which will be mentioned later
7.. Range based for loop
7.1 basic use
In the past, the for loop was used
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array) / sizeof(array[0]); ++p)
cout << *p << " ";
cout<<endl;
}
Now c + + introduces a new for loop.
int main()
{
int arr[] = { 1, 2, 3, 4, 5 };
for (auto&e : arr)
e *= 2;
for (auto&e : arr)
cout << e << " ";
}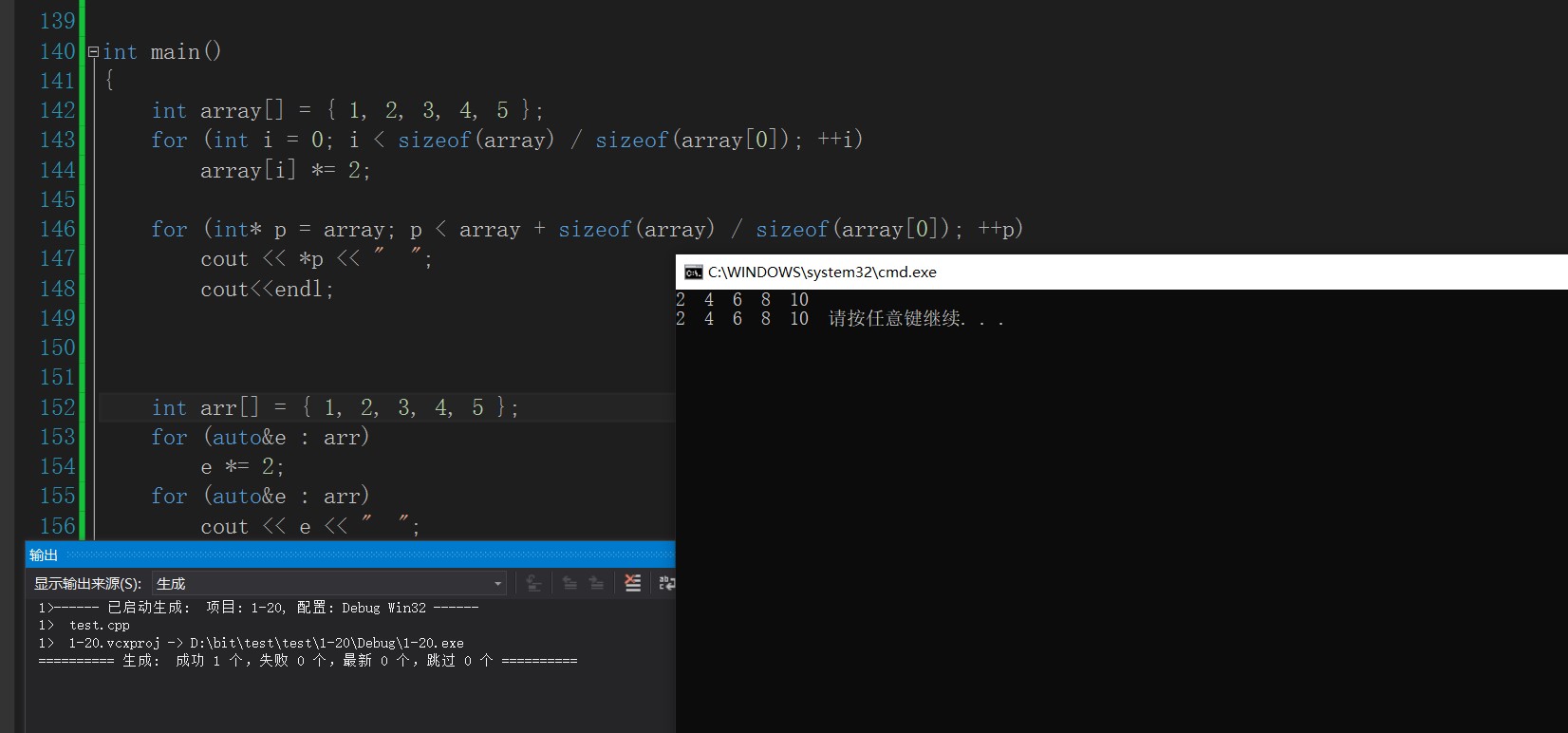
You can see that the results are the same. The parentheses after the for loop are divided into two parts by the colon ":": the first part is the variables used for iteration in the range, and the second part represents the range to be iterated.
7.2 precautions
void TestFor(int a[])
{
// The range must be an array name
for (auto& e : a)
cout << e << endl;
}
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
TestFor(array);
}This code is problematic because the for loop must have a range, and the conditions of this range are a little harsh. It must be a function name, but not in a function.
8. Null pointer nullptr
Let's look at a piece of code
void f(int a1)
{
cout <<"int" << endl;
}
void f(int* a2)
{
cout << "int*" << endl;
}
int main()
{
f(0);
f(NULL);
f(nullptr);
}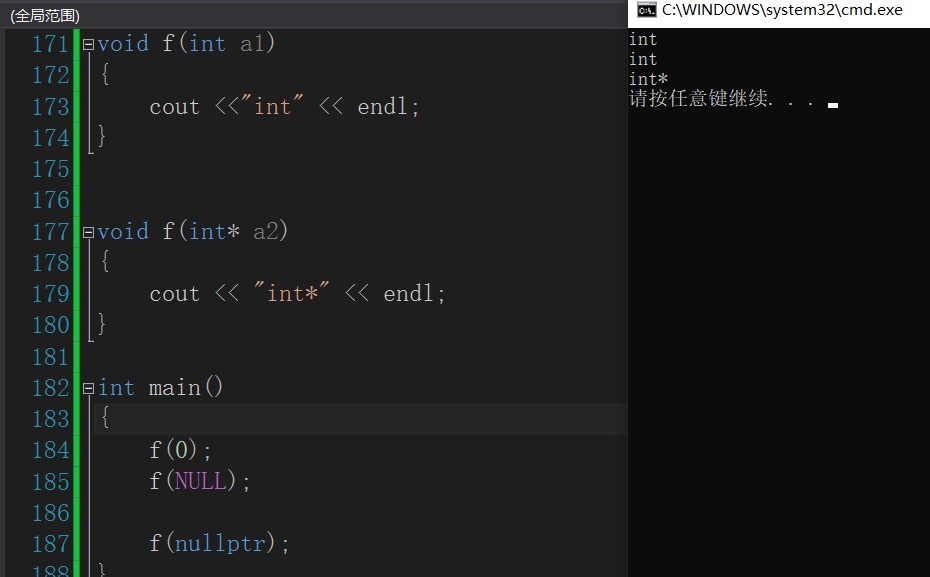
Why does NULL call the above function? Because NULL is a macro and its macro is NULL as 0, the wrong function will be called when calling the function. Therefore, in some scenarios, NULL will cause some errors. nullptr won't.
1. When nullptr is used to represent pointer null value, it is not necessary to include header file, because nullptr is introduced by C++11 as a new keyword.
2. In C++11, sizeof(nullptr) and sizeof((void*)0) occupy the same number of bytes.
3. In order to improve the robustness of the code, it is recommended to use nullptr when representing pointer null values later.
summary
After several days of hard work, the blogger finally got this blog out. It may be a little simple, but I will actively learn how to write a high-quality blog. Thank you for your support!!!