Basic operation of SparkStreaming in PySpark
preface
Stream data has the following characteristics:
• data arrives quickly and continuously, and the potential size may be endless
• numerous data sources and complex formats
• large amount of data, but do not pay much attention to storage. Once processed, it will either be discarded or archived for storage
• focus on the overall value of data, but focus on individual data
• the order of the data to be processed is not complete, or the data to be processed cannot reach the system
Stream computing (the value of data decreases with the flow of time):
Obtain massive data from different data sources in real time, and obtain valuable information through real-time analysis and processing
Flow calculation processing flow (emphasizing real-time):
Real time data collection - > real-time data calculation - > real-time query service
- Real time data acquisition: in the real-time data acquisition stage, massive data from multiple data sources are usually collected, which needs to ensure real-time, low delay, stability and reliability
- Data real-time calculation: in the data real-time calculation stage, analyze and calculate the collected data in real time, and feed back the real-time results
- Real time query service: the results obtained through the stream computing framework can be queried, displayed or stored by users in real time
The stream processing system is different from the traditional data processing system as follows:
- Stream processing system deals with real-time data, while traditional data processing system deals with pre stored static data
- Users get real-time results through the stream processing system, while through the traditional data processing system, they get the results of a certain time in the past
- Stream processing system does not need users to actively send queries, and real-time query service can actively push real-time results to users
SparkStreaming operation:
Spark Streaming can integrate multiple input data sources, such as Kafka, Flume, HDFS, and even ordinary TCP sockets. The processed data can be stored in the file system, database or displayed in the dashboard.

Basic principle of Spark Streaming:
It is to split the real-time input data stream in time slice (second level), and then process each time slice data (pseudo real-time, second level response) in a similar batch manner by Spark engine

The main abstraction of Spark Streaming:
Dstream (discrete stream) refers to continuous data stream. In terms of internal implementation, the input data of Spark Streaming is divided into segments according to the time slice (such as 1 second). Each segment of data is converted into RDD in Spark. These segments are dstreams, and the operation of dstream is finally converted into the operation of corresponding RDD
basic operation
The basic steps of writing Spark Streaming program are:
- Define the input source by creating an input DStream
- Flow calculations are defined by applying transformation and output operations to dstreams
- Use streamingcontext Start() to start receiving data and processing
- Through streamingcontext Awaittermination () method to wait for the end of processing (either manually or due to an error)
- You can use streamingcontext Stop() to manually end the flow calculation process
RDD queue flow
Knowledge points:
Differences among foreachRDD, foreachPartition and foreach in Spark:
First, the scope of action is different. foreachRDD acts on the RDD of each time interval in DStream, foreachPartition acts on each partition in the RDD of each time interval, and foreach acts on each element in the RDD of each time interval.
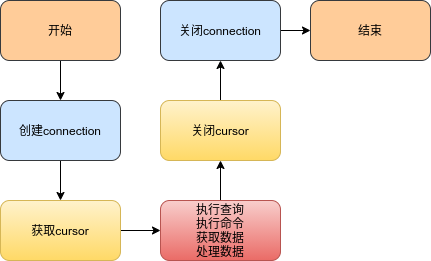
Output mysql process:
%%writefile rdd_queue.py
import findspark
findspark.init()
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
from pyspark.sql.session import SparkSession
import time
import os
import pymysql
# Environment configuration
conf = SparkConf().setAppName("RDD Queue").setMaster("local")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 2)
# Create RDD data stream
rddQueue = []
for i in range(5):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(100 + i)], 10)]
time.sleep(1)
inputStream = ssc.queueStream(rddQueue)
reduceedStream = inputStream.map(lambda x: (x%10, 1)).reduceByKey(lambda x, y: x + y)
# Method 1: save the value to the specified text file
# reduceedStream.saveAsTextFiles("file://" + os.getcwd() + "/process/")
# Method 2: save data to mysql database
def db_func(records):
# Connect database
# Connect to mysql database
print("Connecting to database!")
db = pymysql.connect(host='localhost',user='root',passwd='123456',db='spark')
cursor = db.cursor()
def do_insert():
# sql statement
print("Inserting data!")
sql = " insert into wordcount(word, count) values ('%s','%s')" % (str(p[0]), str(p[1]))
try:
cursor.ececute(sql)
db.commit()
except:
# RollBACK
db.rollback()
for item in recorders:
do_insert(item)
def func(rdd):
repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(db_func)
reduceedStream.pprint()
reduceedStream.foreachRDD(func)
ssc.start()
ssc.stop(stopSparkContext=True, stopGraceFully=True)
%run rdd_queue.py
------------------------------------------- Time: 2021-05-11 15:01:30 ------------------------------------------- (0, 10) (1, 10) (2, 10) (3, 10) (4, 10) (5, 10) (6, 10) (7, 10) (8, 10) (9, 10) ------------------------------------------- Time: 2021-05-11 15:01:32 ------------------------------------------- (0, 11) (1, 10) (2, 10) (3, 10) (4, 10) (5, 10) (6, 10) (7, 10) (8, 10) (9, 10)
Word frequency statistics (stateless operation)
Note: for stateless transition, each statistics only counts the word frequency of the words arrived in the current batch, which has nothing to do with the previous batch and will not be accumulated.
The output result shows:

%%writefile sscrun.py
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create environment
sc = SparkContext(master="local[2]", appName="NetworkWordCount")
ssc = StreamingContext(sc, 1) # Monitor data every second
# Listen for port data (socket data source)
lines = ssc.socketTextStream("localhost", 9999)
#Split words
words = lines.flatMap(lambda line: line.split(" "))
# Statistical word frequency
pairs = words.map(lambda word:(word, 1))
wordCounts = pairs.reduceByKey(lambda x, y:x+y)
# print data
wordCounts.pprint()
# Turn on streaming
ssc.start()
ssc.awaitTermination(timeout=10)
%run sscrun.py
-------------------------------------------
Time: 2021-05-11 14:46:11
-------------------------------------------
('', 1)
('1', 1)
('\x1b[F', 1)
('\x1b[F1', 1)
Word frequency statistics (stateful operation)
Note: for the stateful assembly and replacement operation, the word frequency statistics of this batch will be continuously accumulated on the basis of the word frequency statistics results of previous batches. Therefore, the word frequency obtained in the final statistics is the statistical result of the word frequency of all batches.
Update function: words.updateStateByKey(updateFunc, numPartitions=None, initialRDD=None)
%%writefile calcultor.py
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import os
# Create environment
sc = SparkContext(master="local[2]", appName="NetworkWordCounts")
ssc = StreamingContext(sc, 3) # Monitor data every second
# Monitor port data
lines = ssc.socketTextStream("localhost", 9999)
#Split words
words = lines.flatMap(lambda line: line.split(" "))
# Set checkpoint (write to current file system)
ssc.checkpoint("file://" + os.getcwd() + "checkpoint")
# Status update function
def updatefun(new_values,last_sum):
# The value value of the key state of the current state is added to the forward state
# Eg (initial state):
# new_values = [1, 1, 1], last_sum = 0
return sum(new_values) + (last_sum or 0) # Initial transition to zero
# Monitor port data
lines = ssc.socketTextStream("localhost", 9999)
#Split words
words = lines.flatMap(lambda line: line.split(" "))
# Statistical word frequency
pairs = words.map(lambda word:(word, 1))
wordCounts = pairs.updateStateByKey(updateFunc=updatefun)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
%run calcultor.py
-------------------------------------------
Time: 2021-05-10 15:09:45
-------------------------------------------
('1', 5)
('12', 3)
('54', 1)
('4', 1)
('11', 1)
('6', 1)
('5', 1)
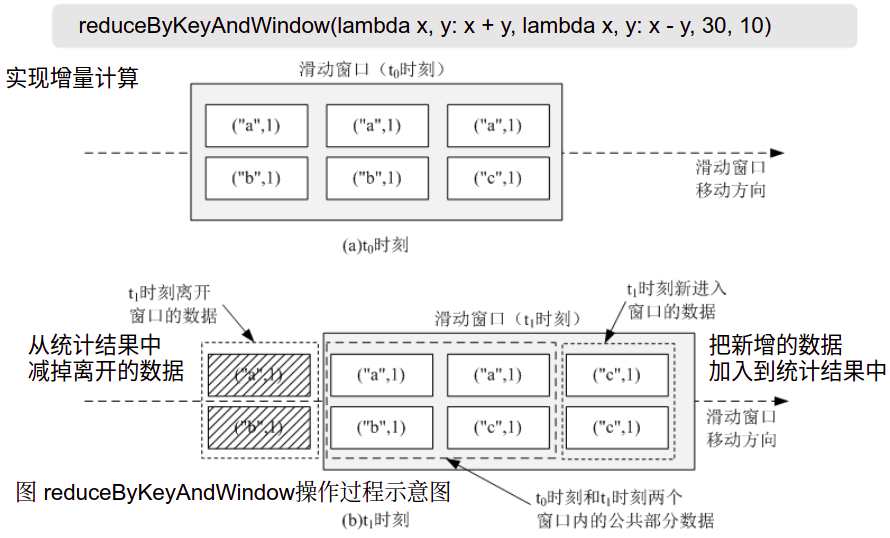
Windows (with transition operation)
Update function:
lines.reduceByKeyAndWindow(
func, # Statistical function
invFunc, # Inverse statistical function
windowDuration, # Window size
slideDuration=None, # Window update frequency
numPartitions=None,
filterFunc=None,
)
Calculation diagram:
%%writefile top.py
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.sql.session import SparkSession
def get_countryname(line):
country_name = line.strip() # Eliminate spaces
if country_name == 'usa':
output = 'USA'
elif country_name == 'ind':
output = 'India'
elif country_name == 'aus':
output = 'Australia'
else:
output = 'Unknown'
return (output, 1)
# Set parameters
batch_interval = 1
window_length = 6*batch_interval # Window size
frquency = 3*batch_interval # Sliding frequency
sc = sc = SparkContext(master="local[2]", appName="NetworkWordCount")
ssc = StreamingContext(sc, batch_interval)
ssc.checkpoint("checkpoint")
# Monitor port data
lines = ssc.socketTextStream("localhost", 9999)
addFunc = lambda x, y: x+y
invAddFunc = lambda x, y: x-y
word_counts = lines.map(get_countryname).reduceByKeyAndWindow(addFunc, invAddFunc, window_length, frquency)
word_counts.pprint()
ssc.start()
ssc.awaitTermination()
%run top.py
reference resources
Interpretation of foreachRDD, foreachPartition and foreach in Spark
Interaction between Python and MySQL