1. Index
The first step to do before starting to index data in {elastic search is to create our main data container. The index here is similar to the database concept in SQL. It is a container for types (equivalent to tables in SQL) and documents (equivalent to records in SQL).
The act of storing data is called Indexing. In # elastic search, documents will belong to one type, and these types will exist in the index.
The correspondence between Elasticsearch cluster and core concepts in database is as follows:
| Elasticsearch cluster | Relational database |
|---|---|
| Indexes | database |
| type | surface |
| file | Row data |
| field | Column data |
1.1 index creation
Define a data table structure of blog_info:
| field | type | explain |
|---|---|---|
| blog_id | long | Blog ID |
| blog_name | text | Blog name |
| blog_url | keyword | Blog address |
| blog_points | double | Blog points |
| blog_describe | text | Blog description |
The field type must be mapped to one of the basic types of} Elasticsearch, and you need to add options on how to index the field.
Recommend this blog post: Elasticsearch mapping type
Elasticsearch tutorial: Elasticsearch tutorial
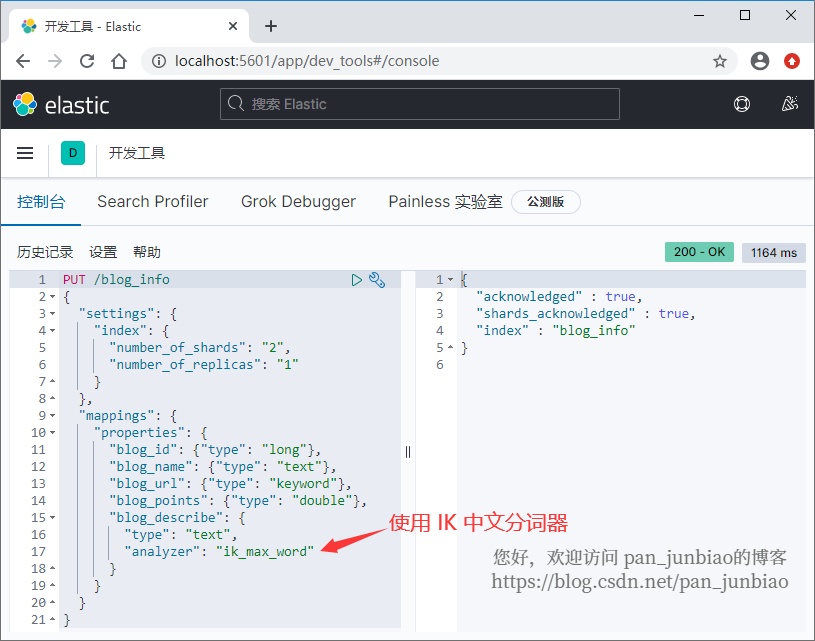
Use the # Elasticsearch command to create an index:
PUT /blog_info
{
"settings": {
"index": {
"number_of_shards": "2",
"number_of_replicas": "1"
}
},
"mappings": {
"properties": {
"blog_id": {"type": "long"},
"blog_name": {"type": "text"},
"blog_url": {"type": "keyword"},
"blog_points": {"type": "double"},
"blog_describe": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}Parameter Description:
number_ of_ Shard s: this parameter controls the number of shards that make up the index.
number_ of_ Replica s: this parameter controls the number of replicas, that is, the number of times data is replicated in the cluster for high availability. It is a good practice to set this value to at least 1.
Execution result:
Note: when creating an index, the index name must be lowercase.
1.2 delete index
The opposite of creating an index is deleting an index. Deleting an index means deleting its shards, mappings, and data.
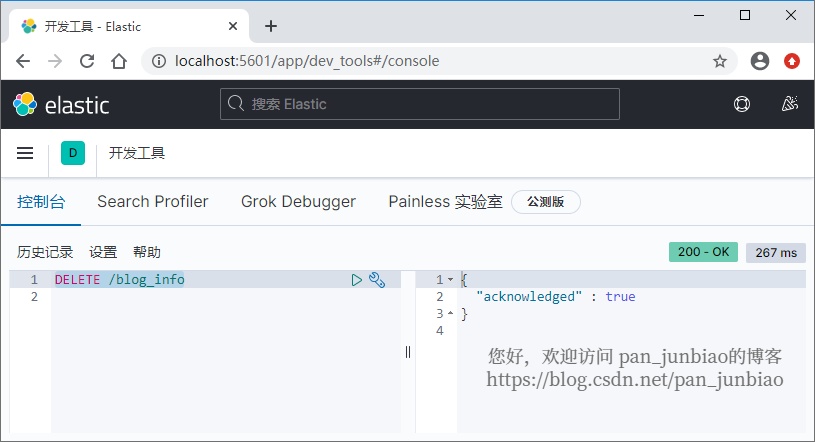
Use the # Elasticsearch command to delete the index:
DELETE /blog_info
Execution result:
1.3 check whether the index exists
A common trap error is to query indexes that do not exist. To avoid this problem, Elasticsearch provides users with the ability to check whether the index exists.
This check is usually used during application startup to create the indexes required for normal operation.
Use the # Elasticsearch command to check whether the index exists:
HEAD /blog_info/
Execution result:
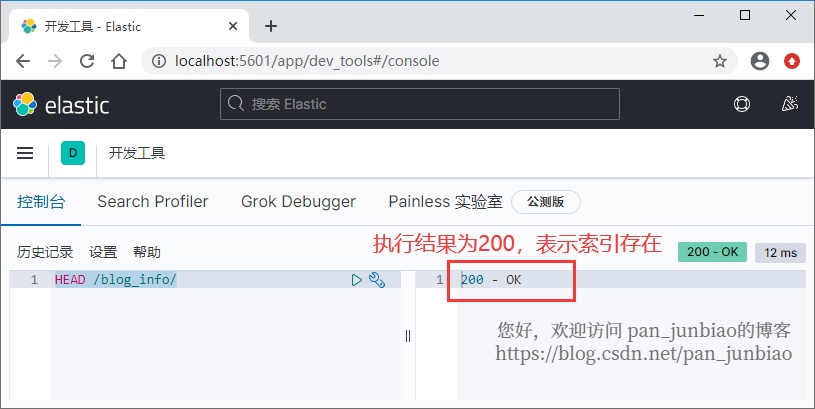
If the index exists, the HTTP status code 200 is returned; If it does not exist, a 404 code is returned.
This is a typical HEAD REST call to check if something exists. It does not return the body response, but only the status code, that is, the result status of the operation.
The most common status codes are as follows:
20X series: everything is normal.
404: indicates that the resource is unavailable.
50X series: indicates that there is a server error.
1.4 turning index on or off
If you want to preserve data and save resources (memory or CPU), a good alternative to deleting an index is to turn it off.
Elasticsearch allows the index to be turned on and off, either online or offline.
Open the index using the # Elasticsearch command:
POST /blog_info/_open
Use the # Elasticsearch command to close the index:
POST /blog_info/_close
1.5 re indexing
There are many common situations involving updating mappings. Due to the limitation of} Elasticsearch mapping, the defined mapping cannot be deleted, so it is usually necessary to re index the index data.
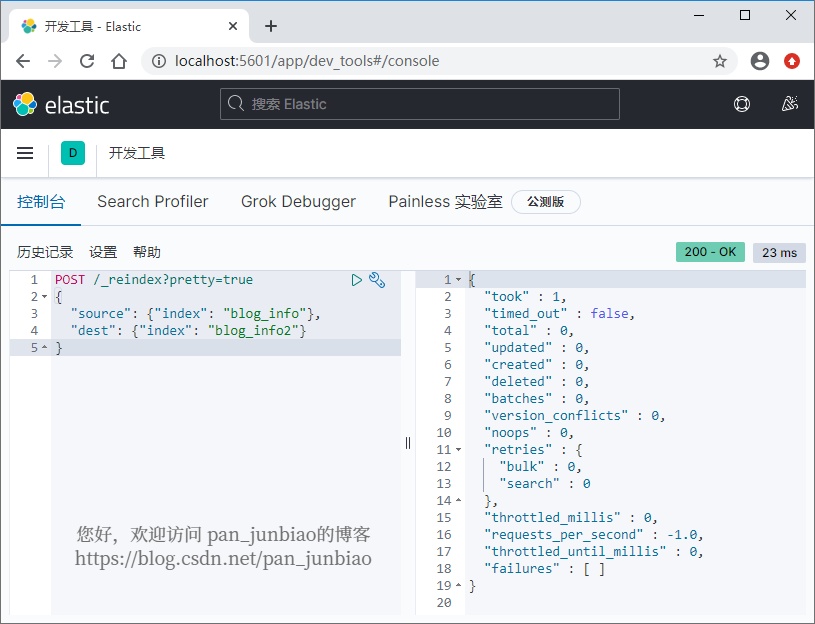
If you want to blog_ The info data is re indexed to} blog_info2 index, rebuild the index using the # Elasticsearch command:
POST /_reindex?pretty=true
{
"source": {"index": "blog_info"},
"dest": {"index": "blog_info2"}
}Execution result:
In addition to the above index operation methods, there are also operations such as refreshing the index, flushing the index, forcibly merging the index, reducing the index, index alias, rolling index, etc. There is no introduction here.
2. Documentation
Creating a document means storing one or more documents in an index, which is similar to the concept of inserting records in a relational database.
In Lucene, the core engine of Elasticsearch, the cost of inserting or updating documents is the same: in Lucene and Elasticsearch, update means replacement.
2.1 adding documents in batch
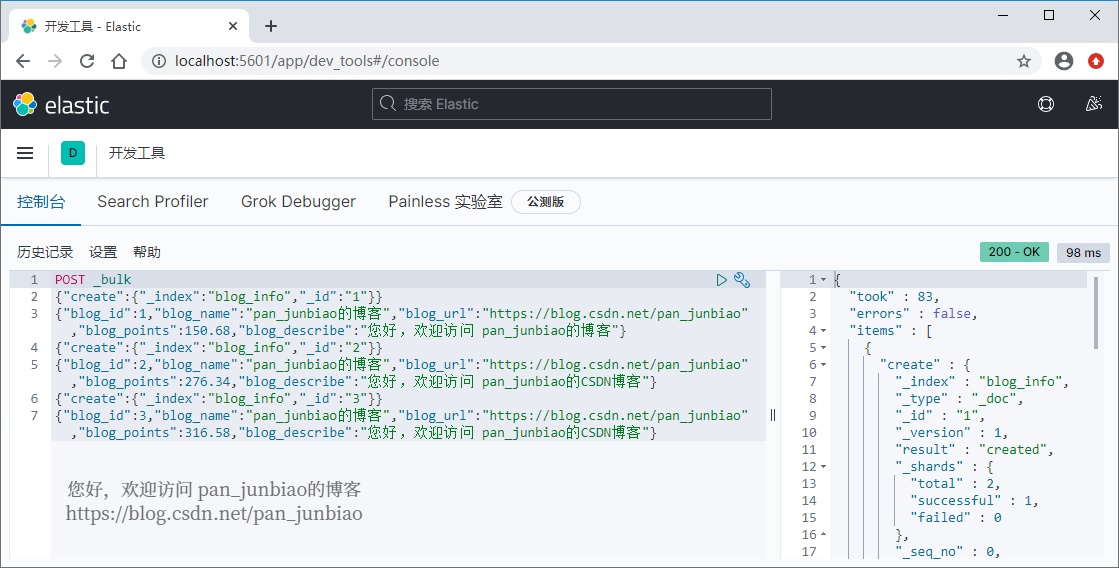
In {Elasticsearch, you can use the batch operation command to batch add documents to the index.
Use the # Elasticsearch command to batch add documents:
POST _bulk
{"create":{"_index":"blog_info","_id":"1"}}
{"blog_id":1,"blog_name":"pan_junbiao Blog","blog_url":"https://blog. csdn. net/pan_junbiao","blog_ points":150.68,"blog_ Hello, welcome to pan_junbiao's blog "}
{"create":{"_index":"blog_info","_id":"2"}}
{"blog_id":2,"blog_name":"pan_junbiao Blog","blog_url":"https://blog. csdn. net/pan_junbiao","blog_ points":276.34,"blog_ Hello, welcome to pan_junbiao's CSDN blog "}
{"create":{"_index":"blog_info","_id":"3"}}
{"blog_id":3,"blog_name":"pan_junbiao Blog","blog_url":"https://blog. csdn. net/pan_junbiao","blog_ points":316.58,"blog_ Hello, welcome to pan_junbiao's CSDN blog "}Execution result:
Use the elasticsearch head plug-in to view the execution results:

2.2 update documents
Documents stored in Elasticsearch can be updated during their lifetime.
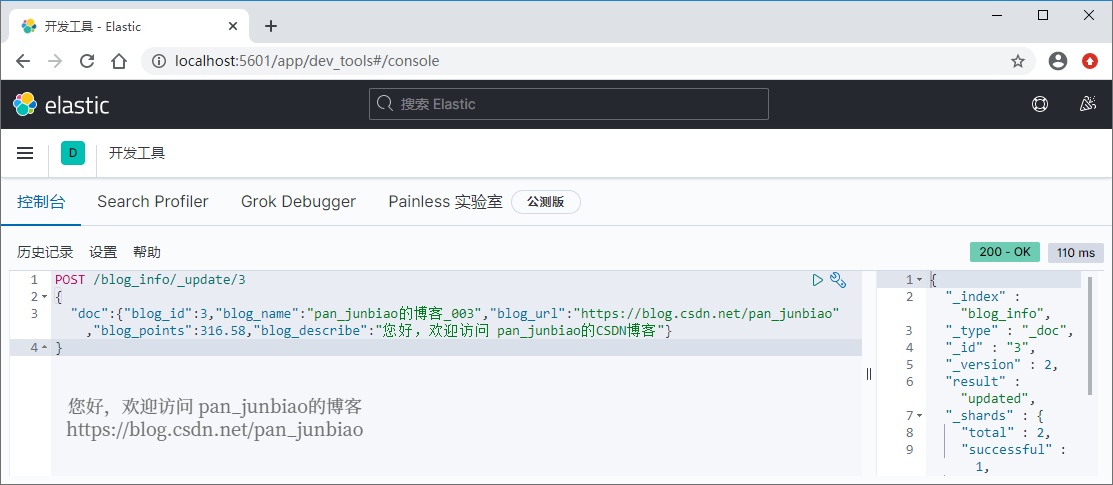
Log the data with document id = 3_ The value of the name field is modified to pan_junbiao's blog_ 003
Use the # Elasticsearch command to update the document:
POST /blog_info/_update/3
{
"doc":{"blog_id":3,"blog_name":"pan_junbiao Blog_003","blog_url":"https://blog. csdn. net/pan_junbiao","blog_ points":316.58,"blog_ Hello, welcome to pan_junbiao's CSDN blog "}
}Execution result:
Use the elasticsearch head plug-in to view the execution results:

2.3 deleting documents
There are two ways to DELETE documents in {Elasticsearch: using DELETE call or delete_by_query call.
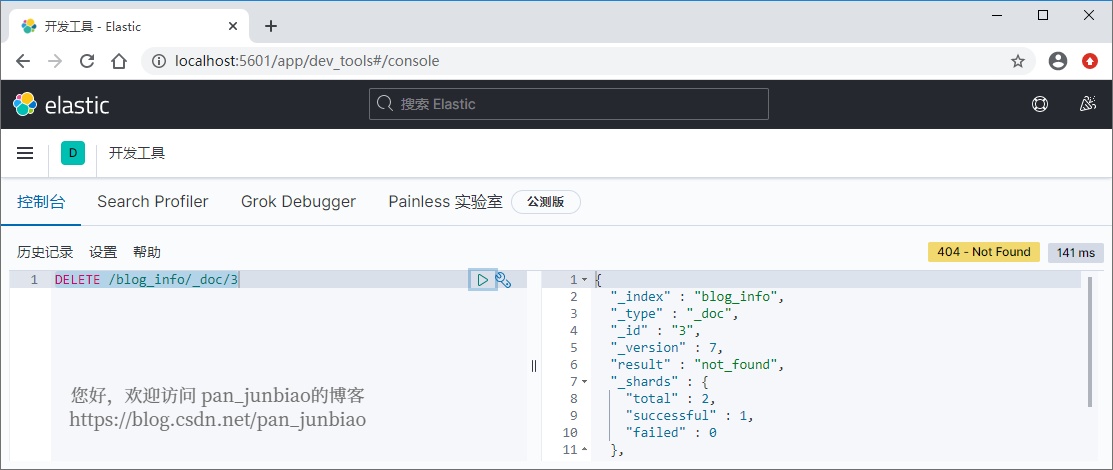
Delete the data with document {id 3.
To delete a document using the # Elasticsearch command:
DELETE /blog_info/_doc/3
Execution result:
Use the elasticsearch head plug-in to view the execution results:

As can be seen from the above figure, the document data with id 3 has been deleted.
2.4 query documents
The standard GET operation is very fast, but if you need to extract multiple documents by document id, Elasticsearch provides multiple GET operations.
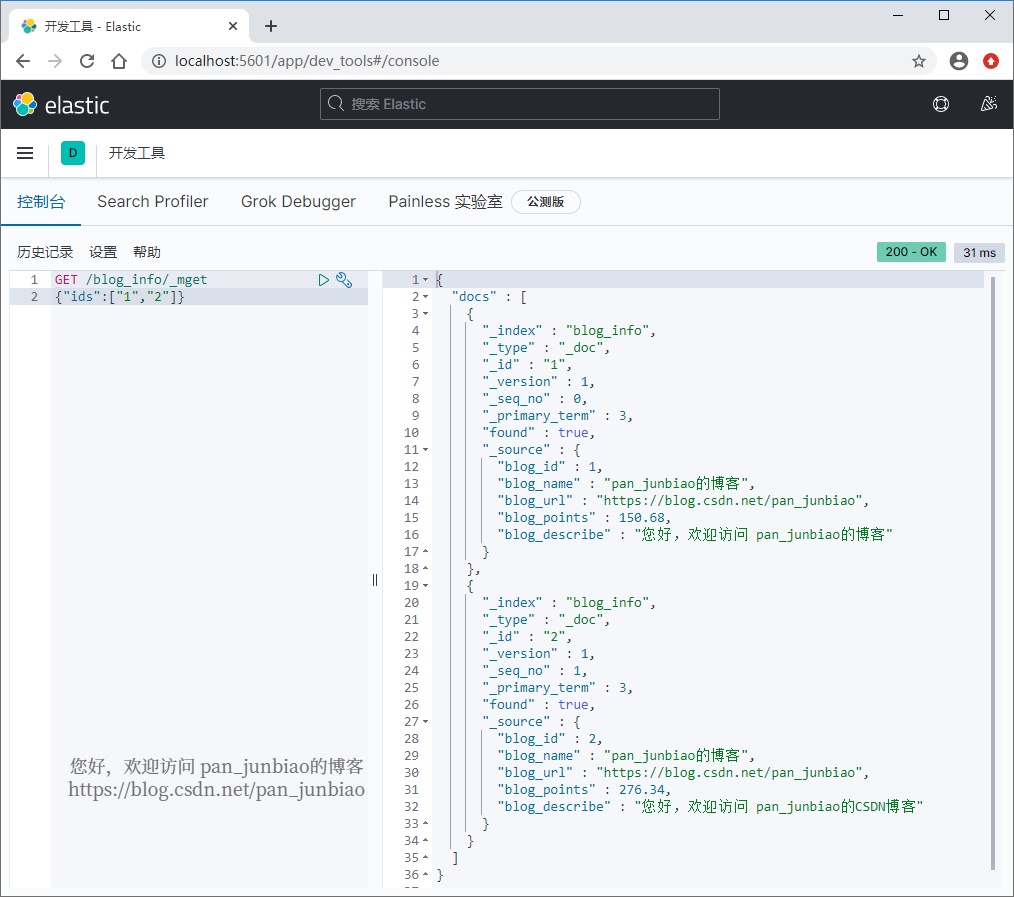
Use the # Elasticsearch command to query documents:
GET /blog_info/_mget
{"ids":["1","2"]}Execution result:
3. Search
Elasticsearch is document oriented and can store the entire document. However, elasticsearch's operation on documents is not limited to storage. Elasticsearch also indexes the content of each document so that it can be searched.
In Elasticsearch, users can index, search, sort and filter document data, which is one of the reasons why Elasticsearch can perform complex full-text search.
3.1 view word segmentation results
In # Elasticsearch, you can set the word splitter and view the word segmentation results.
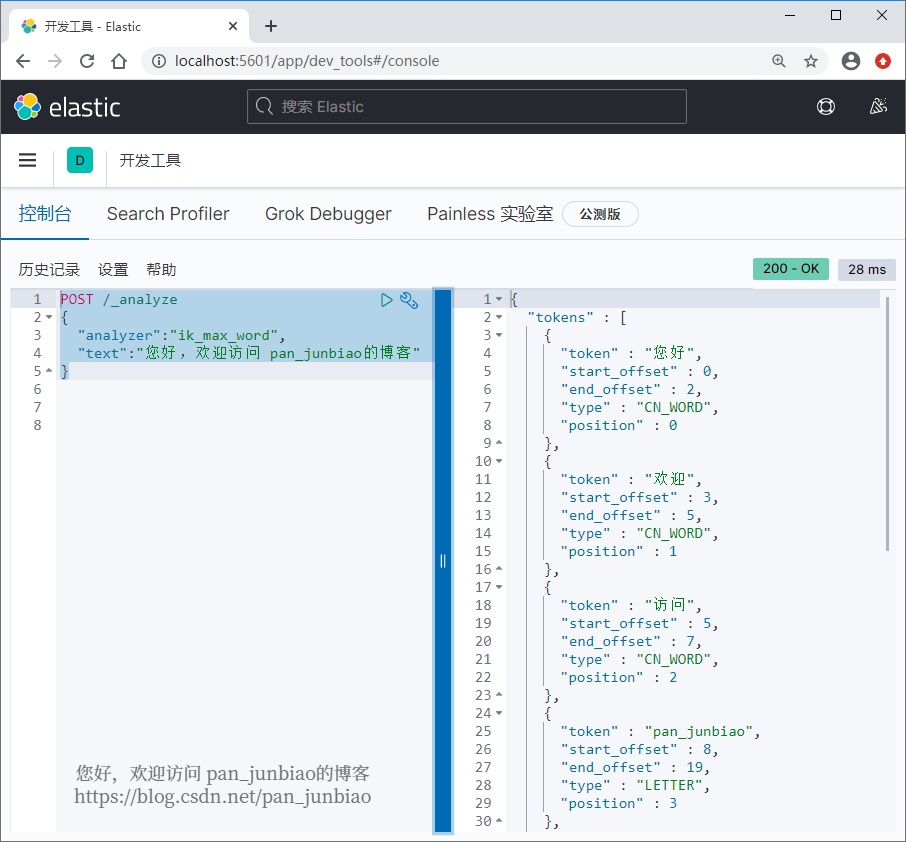
Use the # Elasticsearch command to view the word segmentation results:
POST /_analyze
{
"analyzer":"ik_max_word",
"text":"Hello, welcome to visit pan_junbiao Blog"
}Execution result:
3.2 search and sort
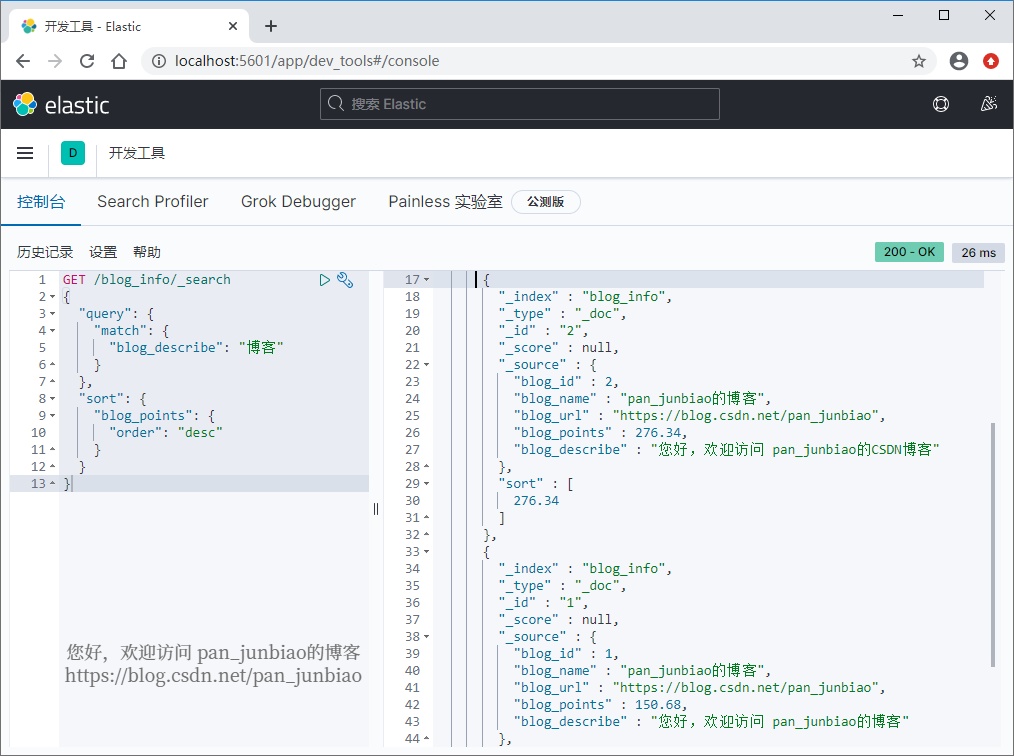
Search blog_ The "blog" data is contained in the "blog description" field and is sorted in reverse order according to blog points.
Search and sort using the # Elasticsearch command:
GET /blog_info/_search
{
"query": {
"match": {
"blog_describe": "Blog"
}
},
"sort": {
"blog_points": {
"order": "desc"
}
}
}Execution result:
3.3 scope of use search
In practical applications, it is very common to search with range values.
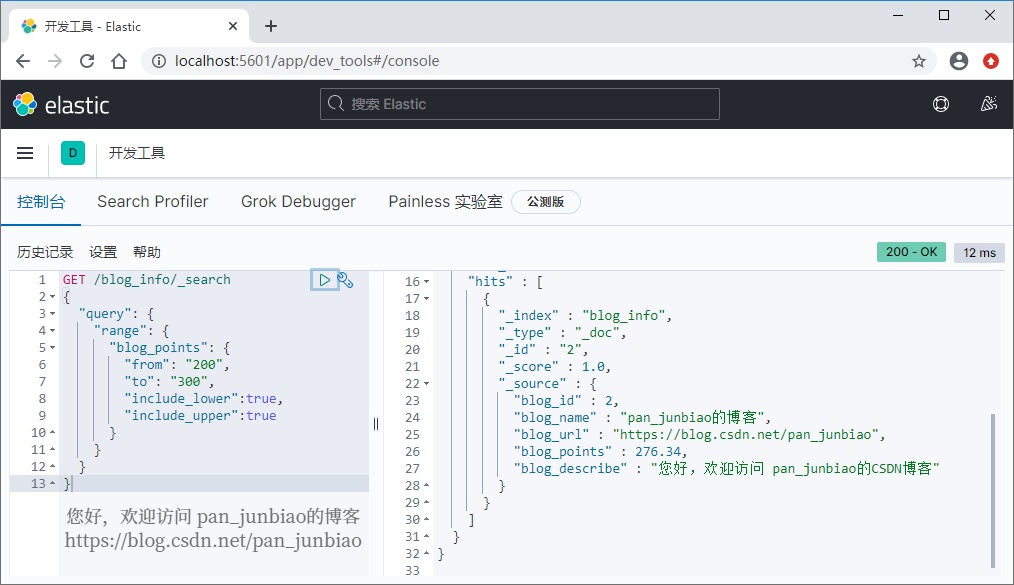
Search for data with blog points in the range of 200 to 300.
GET /blog_info/_search
{
"query": {
"range": {
"blog_points": {
"from": "200",
"to": "300",
"include_lower":true,
"include_upper":true
}
}
}
}Or:
GET /blog_info/_search
{
"query": {
"range": {
"blog_points": {
"gte": "200",
"lte": "300"
}
}
}
}Parameter Description:
from: the starting value of the range (optional).
to: the end value of the range (optional).
include_lower: include the starting value of the range (optional, the default is true).
include_upper: include the end value of the range (optional, the default is true).
gt: greater than.
gte: greater than or equal to.
lt: less than.
lte: less than or equal to.
Execution result: