Reading guide
In the previous chapters, we introduced how to operate excel and ppt in batches. Today, we talk about the batch operation of word documents
application
Python docx allows you to create new documents and make changes to existing documents. In fact, it only allows you to make changes to existing documents; But if you start with a document without any content, you may feel that you are creating a document from scratch at first.
This feature is a powerful feature. The appearance of a document depends largely on what is left when everything is deleted. Styles, headers and footers are included separately from the main content, allowing you to make a lot of customization in the starting document and then appear in the document you generate.
Let's start with the two steps of creating the document, and let's open it step by step.
Let me make a simple demonstration here
You should first define the merge cell function so that it can be called many times later. Because the code for processing tables in word is different from that in Excel, the function should also be fine tuned. The main change is the merged function expression. For the table in word, the expression is table cell(row1,col1). Merge (table. Cell (row2,col2)), which means to merge the tables from row row1 and column col1 to row row2 and column col2 (row2 and col2 should be greater than or equal to row1 and col1 respectively). It should be noted that cell(0,0) represents the cell in the first row and the first column, and so on. The following functions are modified on the basis of example 28.
#Define functions to merge cells
def Merge_cells(table,target_list,start_row,col):
'''
table: It is a table that needs to be operated
target_list: Is the target list, that is, the list with duplicate data
start_row: Is the starting row, that is, the row in the table that starts comparing data (the title needs to be separated)
col: Is a column that needs to process data
'''
start = 0 #Start line count
end = 0 #End row count
reference = target_list[0] #Sets the baseline, starting with the first string in the list
for i in range(len(target_list)): #Traversal list
if target_list[i] != reference: #Start the comparison. If the contents are different, perform the following steps
reference = target_list[i] #The benchmark becomes the next string in the list
end = i - 1
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))
start = end + 1
if i == len(target_list) - 1: #Traverse to the last line, as follows
end = i
table.cell(start+start_row,col).merge(table.cell(end+start_row,col))
Then you need to read the data in the corresponding table in word and extract it as the basis for judging whether to merge or not. To open a word Document with Document, first check the number of tables in it so that we can lock the tables to be processed. Because there may be hidden tables in word, or a paragraph in a table has the border removed, which makes people look like two tables. It is sometimes unreliable to count the number of tables directly in word. According to len(doc.tables), there are two tables in this Document. Open the word Document and we can see that the first table to be processed is doc tables[0]. If the situation is more complicated, we can print the contents of the cells in the first row of the table to further confirm whether it is the table we need to deal with. After confirming the serial number of the form, you can start reading the content.
from docx import Document
doc = Document("Receiving record.docx")
print("This worksheet has {} A table.\n".format(len(doc.tables))) #Check the number in the table to lock the table we want to work on
print("The contents of the cells in the first row of the first table are as follows:")
for i in doc.tables[0].rows[0].cells: #Reads the contents of the cells in the first row of the first table
print(i.text)
The contents of the cells in the first row of the first table are as follows:
Serial number
Supplier name
Cargo code
Cargo model
description of goods
quantity
date
Form:
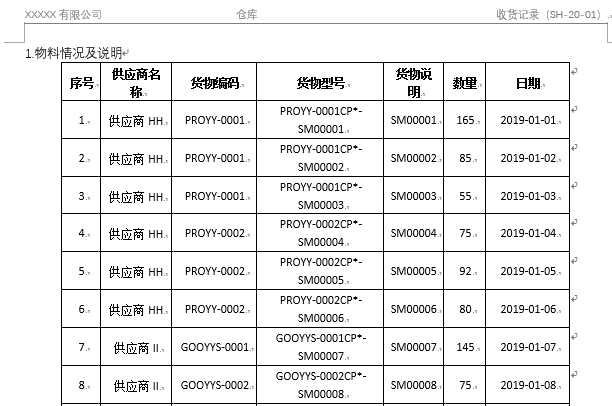
doc.tables[0].rows[0].cells[0].text 'Serial number'
next:
#Read the data of the total number of rows in the second and third columns of the first table in the word document except the header and tail
doc = Document("Receiving record.docx")
table = doc.tables[0] #Determined to be the first table with index 0
supplier = [] #Storage vendor name
pn = [] #Storage material code
max_row = len(table.rows) #Get the largest row
print("Table common{}that 's ok".format(max_row))
#Read the data from the second row to the 29th row and the 2nd and 3rd columns
for i in range(1,max_row-1):
supplier_name = table.rows[i].cells[1].text #cells[1] refers to the second column of the table
supplier.append(supplier_name)
for i in range(1,max_row-1):
material_pn = table.rows[i].cells[2].text #cells[2] refers to the third column of the table
pn.append(material_pn)
print("Get{}Supplier names,{}Item codes.".format(len(supplier),len(pn)))
There are 30 rows in the table
Get 28 supplier names and 28 material codes.
Merge_cells(table,supplier,1,1) #Start merging behavior 2 with index 1; The supplier name is in 2 columns and the index is 1
Merge_cells(table,pn,1,2) #Start merging behavior 2 with index 1; The material code is in 3 columns and the index is 2
doc.save("inspect.docx")
At this step, the merged cells are completed, but the result is as shown in the figure below. The contents of the original cells are all concentrated together, resulting in duplicate contents. We need to rewrite these cells to cover the duplicate content to get the result we want.
result:
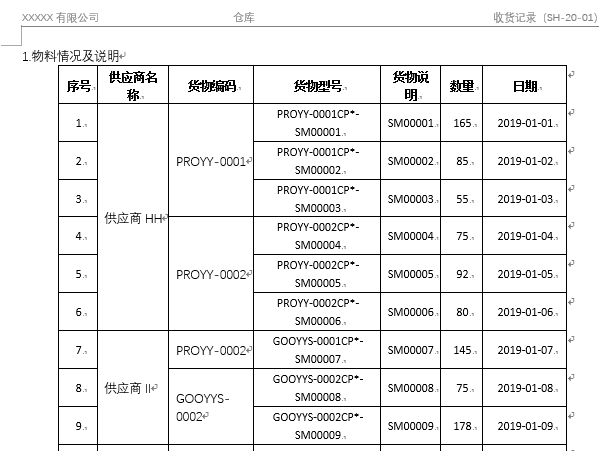
Details
About Python docx Library
Link: Portal
Here is a detailed introduction to the operation
Special introduction
📣 Xiaobai training column is suitable for newcomers who have just started. Welcome to subscribe Programming Xiaobai advanced
📣 The interesting Python hand training project includes interesting articles such as robot awkward chat and spoof program, as well as the introduction of Python automatic office library, which can make you happy to learn python Training project column
📣 In addition, students who want to learn JavaWeb can take a look at this column: Teleporters
📣 This is a sprint factory interview column and algorithm competition practice. Let's cheer together The way ashore
Click to get the data directly
There are python, Java learning materials, interesting programming projects and various resources that are hard to find. It's not a loss to look at it anyway.