Crazy God said MyBatis01: the first program
Introduction to MyBatis

Environmental description:
- jdk 8 +
- MySQL 5.7.19
- maven-3.6.1
- IDEA
Before learning, you need to master:
- JDBC
- MySQL
- Java Foundation
- Maven
- Junit
What is MyBatis
- MyBatis is an excellent persistence layer framework
- MyBatis avoids almost all JDBC code and the process of manually setting parameters and obtaining result sets
- MyBatis can use simple XML or annotations to configure and map native information, and map the interface and Java entity class [Plain Old Java Objects] into records in the database.
- MyBatis was originally an open source project ibatis of apache. In 2010, this project was migrated from apache to google code and renamed MyBatis.
- Moved to Github in November 2013
- Official documents of Mybatis: http://www.mybatis.org/mybatis-3/zh/index.html
- GitHub : https://github.com/mybatis/mybatis-3
Persistence
Persistence is a mechanism to convert program data between persistent state and transient state.
- That is to save data (such as objects in memory) to a permanent storage device (such as disk). The main application of persistence is to store the objects in memory in the database, or in disk files, XML data files and so on.
- JDBC is a persistence mechanism. File IO is also a persistence mechanism.
- In life: refrigerate fresh meat and thaw it when eating. The same is true of canned fruit.
Why do you need persistence services? That is caused by the defect of memory itself
- Data will be lost after memory power failure, but some objects cannot be lost anyway, such as bank accounts. Unfortunately, people can't guarantee that memory will never power down.
- Memory is too expensive. Compared with external memory such as hard disk and optical disc, the price of memory is 2 ~ 3 orders of magnitude higher, and the maintenance cost is also high. At least it needs to be powered all the time. Therefore, even if the object does not need to be permanently saved, it will not stay in memory all the time due to the capacity limit of memory, and it needs to be persisted to cache to external memory.
Persistent layer
What is persistence layer?
- Code block to complete persistence. --- > Dao layer [DAO (Data Access Object)]
- In most cases, especially for enterprise applications, data persistence often means saving the data in memory to disk for solidification, and the implementation process of persistence is mostly completed through various relational databases.
- However, there is a word that needs special emphasis, that is, the so-called "layer". For application systems, data persistence is an essential part. In other words, our system has a natural concept of "persistence layer"? Maybe, but maybe that's not the case. The reason why we want to separate the concept of "persistence layer" instead of "persistence module" and "persistence unit" means that there should be a relatively independent logical level in our system architecture, focusing on the implementation of data persistence logic
- Compared with other parts of the system, this level should have a clear and strict logical boundary[ To put it bluntly, it is used to operate the existence of the database!]
Why do you need Mybatis
-
Mybatis is to help the program store data in the database and get data from the database
-
The traditional jdbc operation has many repeated code blocks, such as the encapsulation of data extraction, the establishment of database connection, etc. through the framework, the repeated code can be reduced and the development efficiency can be improved
-
MyBatis is a semi-automatic ORM framework (object relationship mapping) - > object relationship mapping
-
All things can still be done without Mybatis, but with it, all the implementation will be easier! There is no difference between high and low technology, only the people who use it
-
Advantages of MyBatis
-
- Easy to learn: itself is small and simple. There is no third-party dependency. The simplest installation is just two jar files + several sql mapping files. It is easy to learn and use. Through documents and source code, you can fully master its design idea and implementation.
- Flexibility: mybatis does not impose any impact on the existing design of the application or database. sql is written in xml for unified management and optimization. All requirements for operating the database can be met through sql statements.
- Decouple sql and program code: by providing DAO layer, separate business logic and data access logic, so as to make the system design clearer, easier to maintain and easier to unit test. The separation of sql and code improves maintainability.
- Provide xml tags to support writing dynamic sql.
- ...
-
Most importantly, many people use it! The company needs!
MyBatis first program
Thought process: build environment - > Import Mybatis - > write code - > test
Code demonstration
1. Build experimental database
CREATE DATABASE `mybatis`; USE `mybatis`; DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id` int(20) NOT NULL, `name` varchar(30) DEFAULT NULL, `pwd` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into `user`(`id`,`name`,`pwd`) values (1,'Mad God','123456'),(2,'Zhang San','abcdef'),(3,'Li Si','987654');
2. Import MyBatis related jar package
- Find it on GitHub
<dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.5.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency>
3. Write MyBatis core configuration file
- View help documentation
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=utf8"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/kuang/dao/userMapper.xml"/>
</mappers>
</configuration>
4. Write MyBatis tool class
- View help documentation
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
public class MybatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//Get SqlSession connection
public static SqlSession getSession(){
return sqlSessionFactory.openSession();
}
}
5. Create entity class
public class User {
private int id; //id
private String name; //full name
private String pwd; //password
//Structure, with and without parameters
//set/get
//toString()
}
6. Writing Mapper interface classes
import com.kuang.pojo.User;
import java.util.List;
public interface UserMapper {
List<User> selectUser();
}
7. Write Mapper.xml configuration file
- namespace is very important. You can't write it wrong!
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.dao.UserMapper">
<select id="selectUser" resultType="com.kuang.pojo.User">
select * from user
</select>
</mapper>
8. Writing test classes
- Junit package test
public class MyTest {
@Test
public void selectUser() {
SqlSession session = MybatisUtils.getSession();
//Method 1:
//List<User> users = session.selectList("com.kuang.mapper.UserMapper.selectUser");
//Method 2:
UserMapper mapper = session.getMapper(UserMapper.class);
List<User> users = mapper.selectUser();
for (User user: users){
System.out.println(user);
}
session.close();
}
}
9. Run the test and successfully query our data, ok!
Problem description
Possible problem description: Maven static resource filtering problem
<resources>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
With MyBatis, you don't have to write native JDBC code anymore. It's comfortable!
Crazy God says MyBatis02: CRUD operation and configuration analysis
CRUD operation
Review of Episode 1: Crazy God said MyBatis01: the first program
namespace
- Change the UserMapper interface in the above case to UserDao;
- Change the namespace in UserMapper.xml to the path of UserDao
- Retest
Conclusion:
The name in the namespace in the configuration file is the complete package name of the corresponding Mapper interface or Dao interface, which must be consistent!
select
-
The select tag is one of the most commonly used tags in mybatis
-
The select statement has many properties, and each SQL statement can be configured in detail
-
- Return value type of SQL statement[ Complete class name or alias]
- The parameter type of the passed in SQL statement[ Universal Map, you can try more]
- Unique identifier in namespace
- The method name in the interface corresponds to the SQL statement ID in the mapping file one by one
- id
- parameterType
- resultType
Requirement: query user by id
1. Add corresponding method in UserMapper
public interface UserMapper {
//Query all users
List<User> selectUser();
//Query user by id
User selectUserById(int id);
}
2. Add a Select statement in UserMapper.xml
<select id="selectUserById" resultType="com.kuang.pojo.User">
select * from user where id = #{id}
</select>
3. Test in test class
@Test
public void tsetSelectUserById() {
SqlSession session = MybatisUtils.getSession(); //Get SqlSession connection
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUserById(1);
System.out.println(user);
session.close();
}
Class exercise: query users by password and name
Idea 1: pass parameters directly in the method
1. Add the @ Param attribute before the parameter of the interface method
2. When writing Sql statements, you can directly take the value set in @ Param without setting the parameter type separately
//Query users by password and name
User selectUserByNP(@Param("username") String username,@Param("pwd") String pwd);
/*
<select id="selectUserByNP" resultType="com.kuang.pojo.User">
select * from user where name = #{username} and pwd = #{pwd}
</select>
*/
Idea 2: use universal Map
1. In the interface method, parameters are directly transferred to Map;
User selectUserByNP2(Map<String,Object> map);
2. When writing sql statements, you need to pass the parameter type, which is map
<select id="selectUserByNP2" parameterType="map" resultType="com.kuang.pojo.User">
select * from user where name = #{username} and pwd = #{pwd}
</select>
3. When using the method, the key of the Map can be the value obtained from the sql. There is no order requirement!
Map<String, Object> map = new HashMap<String, Object>();
map.put("username","Xiao Ming");
map.put("pwd","123456");
User user = mapper.selectUserByNP2(map);
Summary: if there are too many parameters, we can consider using Map directly. If there are few parameters, we can pass the parameters directly
insert
We usually use the insert tag for insertion. Its configuration is similar to that of the select tag!
Requirement: add a user to the database
1. Add the corresponding method in the UserMapper interface
//Add a user int addUser(User user);
2. Add an insert statement in UserMapper.xml
<insert id="addUser" parameterType="com.kuang.pojo.User">
insert into user (id,name,pwd) values (#{id},#{name},#{pwd})
</insert>
3. Testing
@Test
public void testAddUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = new User(5,"Wang Wu","zxcvbn");
int i = mapper.addUser(user);
System.out.println(i);
session.commit(); //Commit transaction, focus! If it is not written, it will not be submitted to the database
session.close();
}
Note: add, delete, and modify operations require transaction submission!
**
**
update
We usually use the update tag for update operation. Its configuration is similar to that of the select tag!
Requirement: modify user information
1. Similarly, write interface methods
//Modify a user int updateUser(User user);
2. Write corresponding configuration file SQL
<update id="updateUser" parameterType="com.kuang.pojo.User">
update user set name=#{name},pwd=#{pwd} where id = #{id}
</update>
3. Testing
@Test
public void testUpdateUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUserById(1);
user.setPwd("asdfgh");
int i = mapper.updateUser(user);
System.out.println(i);
session.commit(); //Commit transaction, focus! If it is not written, it will not be submitted to the database
session.close();
}
delete
We usually use the delete tag for deletion. Its configuration is similar to that of the select tag!
Requirement: delete a user according to id
1. Similarly, write interface methods
//Delete user by id int deleteUser(int id);
2. Write corresponding configuration file SQL
<delete id="deleteUser" parameterType="int">
delete from user where id = #{id}
</delete>
3. Testing
@Test
public void testDeleteUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
int i = mapper.deleteUser(5);
System.out.println(i);
session.commit(); //Commit transaction, focus! If it is not written, it will not be submitted to the database
session.close();
}
Summary:
- All addition, deletion and modification operations need to commit transactions!
- For all common parameters of the interface, try to write the @ Param parameter, especially when there are multiple parameters, you must write it!
- Sometimes, according to business requirements, you can consider using map to pass parameters!
- In order to standardize the operation, we try to write the Parameter parameter and resultType in the SQL configuration file!
Thinking questions
How to write a fuzzy query like statement?
Type 1: add sql wildcards in Java code.
string wildcardname = "%smi%";
list<name> names = mapper.selectlike(wildcardname);
<select id="selectlike">
select * from foo where bar like #{value}
</select>
Type 2: splicing wildcards in sql statements will cause sql injection
string wildcardname = "smi";
list<name> names = mapper.selectlike(wildcardname);
<select id="selectlike">
select * from foo where bar like "%"#{value}"%"
</select>
Configuration resolution
Core profile
- mybatis-config.xml system core configuration file
- The MyBatis configuration file contains settings and attribute information that deeply affect MyBatis behavior.
- The configurable contents are as follows:
configuration(Configuration) properties(Properties) settings(Settings) typeAliases(Type alias) typeHandlers(Type (processor) objectFactory(Object factory) plugins(Plug in) environments(Environment configuration) environment(Environment variables) transactionManager(Transaction manager) dataSource((data source) databaseIdProvider(Database (vendor ID) mappers(Mapper) <!-- Pay attention to the order of element nodes! If the sequence is wrong, an error will be reported -->
We can read the dtd header file above mybatis-config.xml!
environments element
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
-
Configure multiple sets of running environments for MyBatis and map SQL to multiple different databases. One of them must be specified as the default running environment (specified by default)
-
Child element node: environment
-
-
The dataSource element uses the standard JDBC data source interface to configure the resources of the JDBC connection object.
-
The data source must be configured.
-
There are three built-in data source types
type="[UNPOOLED|POOLED|JNDI]")
-
unpooled: the implementation of this data source only opens and closes the connection every time it is requested.
-
pooled: the implementation of this data source uses the concept of "pool" to organize JDBC connection objects, which is a popular way to make concurrent Web applications respond to requests quickly.
-
JNDI: this data source is implemented to be used in containers such as Spring or application server. The container can configure the data source centrally or externally, and then place a reference to the JNDI context.
-
Data sources also have many third-party implementations, such as dbcp, c3p0, druid and so on
-
Details: Click to view the official document
-
Neither transaction manager type requires any properties to be set.
-
A specific set of environments can be distinguished by setting the id, and the id is guaranteed to be unique!
-
Child element node: transactionManager - [transaction manager]
<!-- grammar --> <transactionManager type="[ JDBC | MANAGED ]"/>
-
Child element node: dataSource
-
mappers element
mappers
- Mapper: define mapping SQL statement files
- Now that the behavior of MyBatis and other elements have been configured, we are going to define the SQL mapping statement. But first we need to tell MyBatis where to find these statements. Java does not provide a good way to automatically find this, so the best way is to tell MyBatis where to find the mapping file. You can use resource references relative to the classpath, or fully qualified resource locators (including the URL of file: / /), or class and package names. Mapper is one of the core components in MyBatis. Before MyBatis 3, only xml mapper was supported, that is, all SQL statements must be configured in xml files. Starting from MyBatis 3, it also supports interface mapper, which allows the annotation and definition of SQL statements in the form of Java code, which is very concise.
Resource introduction method
<!-- Use resource references relative to Classpaths --> <mappers> <mapper resource="org/mybatis/builder/PostMapper.xml"/> </mappers> <!-- Use fully qualified resource locators( URL) --> <mappers> <mapper url="file:///var/mappers/AuthorMapper.xml"/> </mappers> <!-- Use the mapper interface to implement the fully qualified class name of the class The configuration file name and interface name should be consistent and located in the same directory --> <mappers> <mapper class="org.mybatis.builder.AuthorMapper"/> </mappers> <!-- Register all the mapper interface implementations in the package as mappers However, the configuration file name and interface name should be consistent and located in the same directory --> <mappers> <package name="org.mybatis.builder"/> </mappers>
Mapper file
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.UserMapper">
</mapper>
-
Namespace means namespace in Chinese. Its functions are as follows:
-
- The name of a namespace must have the same name as an interface
- The method in the interface should correspond to the sql statement id in the mapping file one by one
-
- The combination of namespace and child element id ensures uniqueness and distinguishes different mapper s
- Bind DAO interface
- namespace naming rules: package name + class name
The real power of MyBatis lies in its mapping statements, which is its magic. Because of its extraordinary power, the XML file of the mapper is relatively simple. If you compare it with JDBC code with the same function, you will immediately find that nearly 95% of the code is saved. MyBatis is built to focus on SQL to minimize your trouble.
Properties optimization
These database properties are externally configurable and dynamically replaceable. They can be configured in a typical Java property file or passed through the child elements of the properties element. Specific official documents
Let's optimize our profile
The first step; Create a new db.properties in the resource directory
driver=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=utf8 username=root password=123456
Step 2: import the file into the properties configuration file
<configuration>
<!--Import properties file-->
<properties resource="db.properties"/>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>
For more operations, you can view the official documents[ [demonstration leads learning]
- Profile priority issues
- New properties: using placeholders
typeAliases optimization
A type alias is a short name for a Java type. It is only related to XML configuration, and its significance is only to reduce the redundancy of class fully qualified names.
<!--Configure alias,Pay attention to the order--> <typeAliases> <typeAlias type="com.kuang.pojo.User" alias="User"/> </typeAliases>
When configured in this way, User can be used wherever com.kuang.pojo.User is used.
You can also specify a package name. MyBatis will search for the required Java beans under the package name, such as:
<typeAliases> <package name="com.kuang.pojo"/> </typeAliases>
Each Java Bean in the package com.kuang.pojo will use the initial lowercase unqualified class name of the bean as its alias without annotation.
If there is an annotation, the alias is its annotation value. See the following example:
@Alias("user")
public class User {
...
}
Go to the official website to check some of the default type aliases of Mybatis!
Other configuration browsing
set up
-
settings = > View help documentation
-
- Lazy loading
- Log implementation
- Cache on / off
-
An example of a fully configured settings element is as follows:
<settings> <setting name="cacheEnabled" value="true"/> <setting name="lazyLoadingEnabled" value="true"/> <setting name="multipleResultSetsEnabled" value="true"/> <setting name="useColumnLabel" value="true"/> <setting name="useGeneratedKeys" value="false"/> <setting name="autoMappingBehavior" value="PARTIAL"/> <setting name="autoMappingUnknownColumnBehavior" value="WARNING"/> <setting name="defaultExecutorType" value="SIMPLE"/> <setting name="defaultStatementTimeout" value="25"/> <setting name="defaultFetchSize" value="100"/> <setting name="safeRowBoundsEnabled" value="false"/> <setting name="mapUnderscoreToCamelCase" value="false"/> <setting name="localCacheScope" value="SESSION"/> <setting name="jdbcTypeForNull" value="OTHER"/> <setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/> </settings>
Type processor
- Whether MyBatis sets a parameter in the PreparedStatement or takes a value from the result set, it will use the type processor to convert the obtained value into Java type in an appropriate way.
- You can override the type processor or create your own type processor to handle unsupported or nonstandard types[ Understand]
Object factory
- Every time MyBatis creates a new instance of the result object, it uses an object factory instance to complete it.
- The default object factory only needs to instantiate the target class, either through the default constructor or through the parametric constructor when the parameter mapping exists.
- If you want to override the default behavior of an object factory, you can do so by creating your own object factory[ Understand]
Lifecycle and scope
Scope and lifecycle
It is important to understand the different scopes and lifecycle classes we have discussed so far, because incorrect use can lead to very serious concurrency problems.
We can draw a flow chart to analyze the execution process of Mybatis!
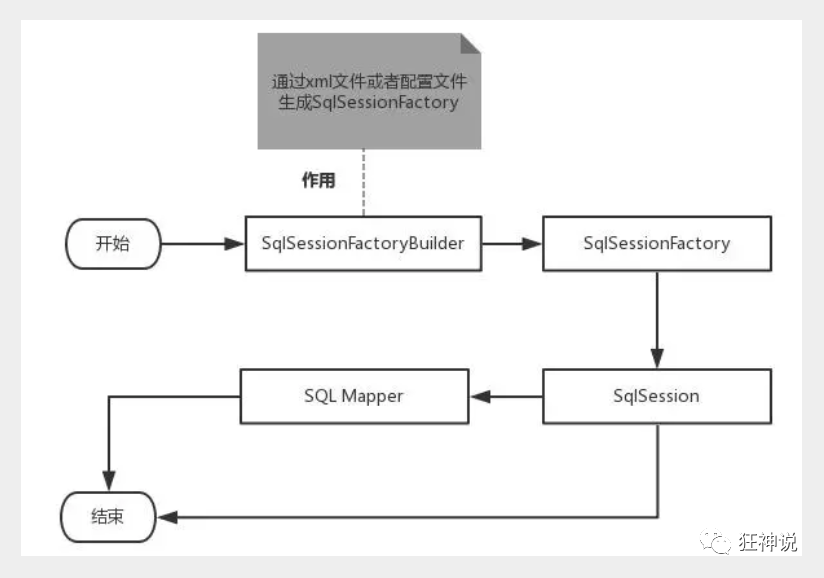
Scope understanding
- The function of SqlSessionFactoryBuilder is to create SqlSessionFactory. After the creation is successful, SqlSessionFactoryBuilder will lose its function, so it can only exist in the method of creating SqlSessionFactory, not for a long time. Therefore, the best scope of the SqlSessionFactoryBuilder instance is the method scope (that is, local method variables).
- SqlSessionFactory can be considered as a database connection pool. Its function is to create SqlSession interface objects. Because the essence of MyBatis is Java's operation on the database, the life cycle of SqlSessionFactory exists in the whole MyBatis application. Therefore, once SqlSessionFactory is created, it must be saved for a long time until MyBatis application is no longer used. Therefore, it can be considered that the life cycle of SqlSessionFactory is equivalent to the application cycle of MyBatis.
- Since SqlSessionFactory is a connection pool to the database, it occupies the connection resources of the database. If multiple sqlsessionfactories are created, there will be multiple database connection pools, which is not conducive to the control of database resources. It will also lead to the depletion of database connection resources and system downtime. Therefore, try to avoid such a situation.
- Therefore, in general applications, we often want SqlSessionFactory as a singleton to be shared in the application. Therefore, the best scope of SqlSessionFactory is the application scope.
- If SqlSessionFactory is equivalent to a database Connection pool, SqlSession is equivalent to a database Connection (Connection object). You can execute multiple SQL in a transaction, and then commit or roll back the transaction through its commit, rollback and other methods. Therefore, it should survive in a business request. After processing a complete request, close the Connection and return it to SqlSessionFactory. Otherwise, the database resources will be consumed quickly and the system will be paralyzed. Therefore, use the try... catch... finally... Statement to ensure that it is closed correctly.
- Therefore, the best scope of SqlSession is the request or method scope.
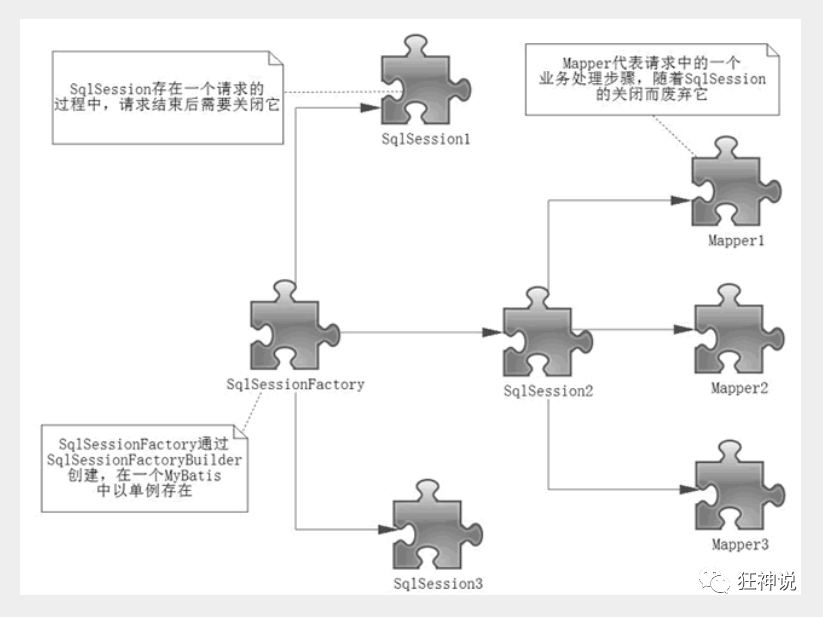
After learning Crud and basic configuration and principles, you can learn some business development
Crazy God says MyBatis03: ResultMap and pagination
ResultMap
Review of Episode 1: Crazy God says MyBatis02: CRUD operation and configuration analysis
The query is null
Problem to be solved: the attribute name and field name are inconsistent
Environment: create a new project and copy the previous project
1. View the field name of the previous database
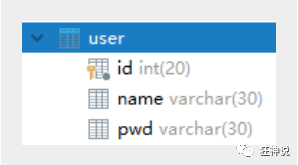
2. Entity class design in Java
public class User {
private int id; //id
private String name; //full name
private String password; //The password is different from the database!
//structure
//set/get
//toString()
}
3. Interface
//Query user by id User selectUserById(int id);
4. mapper mapping file
<select id="selectUserById" resultType="user">
select * from user where id = #{id}
</select>
5. Testing
@Test
public void testSelectUserById() {
SqlSession session = MybatisUtils.getSession(); //Get SqlSession connection
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUserById(1);
System.out.println(user);
session.close();
}
result:
- User{id=1, name ='crazy God ', password ='null'}
- It is found that the password is empty. It indicates that there is a problem!
analysis:
-
select * from user where id = #{id} can be regarded as
select id,name,pwd from user where id = #{id}
-
mybatis will find the set value of the corresponding column name in the corresponding entity class according to the column name of these queries (the column name will be converted to lowercase, and the database is not case sensitive). Because setPwd() cannot be found, the password returns null[ [auto map]
Solution
Scheme 1: specify an alias for the column name, which is consistent with the attribute name of the java entity class
<select id="selectUserById" resultType="User">
select id , name , pwd as password from user where id = #{id}
</select>
Scheme 2: use result set mapping - > resultmap [recommended]
<resultMap id="UserMap" type="User">
<!-- id As primary key -->
<id column="id" property="id"/>
<!-- column Is the column name of the database table , property Is the property name of the corresponding entity class -->
<result column="name" property="name"/>
<result column="pwd" property="password"/>
</resultMap>
<select id="selectUserById" resultMap="UserMap">
select id , name , pwd from user where id = #{id}
</select>
ResultMap
Automatic mapping
- The resultMap element is the most important and powerful element in MyBatis. It frees you from 90% of the JDBC ResultSets data extraction code.
- In fact, when writing mapping code for complex statements such as connections, a resultMap can replace thousands of lines of code that achieve the same function.
- The design idea of ResultMap is that there is no need to configure explicit result mapping for simple statements, but only need to describe their relationship for more complex statements.
You've seen examples of simple mapping statements, but you don't explicitly specify resultMap. For example:
<select id="selectUserById" resultType="map">
select id , name , pwd
from user
where id = #{id}
</select>
The above statement simply maps all columns to the key of the HashMap, which is specified by the resultType attribute. Although it is sufficient in most cases, HashMap is not a good model. Your program is more likely to use JavaBean s or POJO s (Plain Old Java Objects) as models.
The best thing about ResultMap is that although you already know it well, you don't need to explicitly use them at all.
Manual mapping
1. The return value type is resultMap
<select id="selectUserById" resultMap="UserMap">
select id , name , pwd from user where id = #{id}
</select>
2. Write resultMap to realize manual mapping!
<resultMap id="UserMap" type="User"> <!-- id As primary key --> <id column="id" property="id"/> <!-- column Is the column name of the database table , property Is the property name of the corresponding entity class --> <result column="name" property="name"/> <result column="pwd" property="password"/> </resultMap>
If only the world were always so simple. But certainly not. There are many to many and many to one situations in the database. We will use some advanced result set mapping, association and collection later. We will explain later. Today, you need to digest all these knowledge is the most important! Understand the concept of result set mapping!
Several ways of paging
Log factory
Thinking: when we test SQL, if we can output SQL on the console, can we have faster troubleshooting efficiency?
If a database related operation has a problem, we can quickly troubleshoot the problem according to the output SQL statement.
For the previous development process, we often use the debug mode to adjust and track our code execution process. But now using Mybatis is a source code execution process based on interface and configuration file. Therefore, we must choose logging tool as our tool to develop and adjust programs.
The built-in log factory of Mybatis provides log function. The specific log implementation tools are as follows:
- SLF4J
- Apache Commons Logging
- Log4j 2
- Log4j
- JDK logging
The specific log implementation tool selected is determined by MyBatis's built-in log factory. It uses the first found (in the order listed above). If none is found, the logging function is disabled.
Standard log implementation
Specify which logging implementation MyBatis should use. If this setting does not exist, the logging implementation is automatically discovered.
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
Test, you can see that the console has a lot of output! We can use these outputs to determine where the Bug is in the program
Log4j
Introduction:
- Log4j is an open source project of Apache
- By using Log4j, we can control the destination of log information delivery: console, text, GUI components
- We can also control the output format of each log;
- By defining the level of each log information, we can control the log generation process in more detail. The most interesting thing is that these can be flexibly configured through a configuration file without modifying the application code.
Use steps:
1. Import log4j's package
<dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency>
2. Configuration file writing
#Output the log information with the level of DEBUG to the two destinations of console and file. The definitions of console and file are in the following code
log4j.rootLogger=DEBUG,console,file
#Settings related to console output
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[%c]-%m%n
#Settings related to file output
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./log/kuang.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=[%p][%d{yy-MM-dd}][%c]%m%n
#Log output level
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
3. Setting setting log implementation
<settings> <setting name="logImpl" value="LOG4J"/> </settings>
4. Use Log4j for output in the program!
//Note the guide package: org.apache.log4j.Logger
static Logger logger = Logger.getLogger(MyTest.class);
@Test
public void selectUser() {
logger.info("info: get into selectUser method");
logger.debug("debug: get into selectUser method");
logger.error("error: get into selectUser method");
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
List<User> users = mapper.selectUser();
for (User user: users){
System.out.println(user);
}
session.close();
}
5. Test, look at the console output!
- Output logs using Log4j
- You can see that a log file is also generated [the log level of the file needs to be modified]
limit implements paging
Think: why pagination?
When learning persistence layer frameworks such as mybatis, we often add, delete, change and query data. The most used is to query the database. If we query a large amount of data, we often use paging for query, that is, we process a small part of data every time, so the pressure on the database is within a controllable range.
Paging using Limit
#grammar SELECT * FROM table LIMIT stratIndex,pageSize SELECT * FROM table LIMIT 5,10; // Retrieving record lines 6-15 #In order to retrieve all record lines from an offset to the end of the Recordset, the second parameter can be specified as - 1: SELECT * FROM table LIMIT 95,-1; // Retrieve record line 96 last #If only one parameter is given, it indicates that the maximum number of record lines is returned: SELECT * FROM table LIMIT 5; //Retrieve the first 5 record lines #In other words, LIMIT n is equivalent to LIMIT 0,n.
Steps:
1. Modify Mapper file
<select id="selectUser" parameterType="map" resultType="user">
select * from user limit #{startIndex},#{pageSize}
</select>
2. Mapper interface, the parameter is map
//Select all users to implement paging List<User> selectUser(Map<String,Integer> map);
3. Pass in the parameter test in the test class
- Infer: start position = (current page - 1) * page size
//Paging query, two parameters: StartIndex and PageSize
@Test
public void testSelectUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
int currentPage = 1; //What page
int pageSize = 2; //How many are displayed per page
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("startIndex",(currentPage-1)*pageSize);
map.put("pageSize",pageSize);
List<User> users = mapper.selectUser(map);
for (User user: users){
System.out.println(user);
}
session.close();
}
RowBounds paging
In addition to using Limit to realize paging at the SQL level, we can also use RowBounds to realize paging at the Java code level. Of course, this method can be used as an understanding. Let's see how to achieve it!
Steps:
1. mapper interface
//Select all users rowboundaries to implement paging List<User> getUserByRowBounds();
2. mapper file
<select id="getUserByRowBounds" resultType="user"> select * from user </select>
3. Test class
Here, we need to use the RowBounds class
@Test
public void testUserByRowBounds() {
SqlSession session = MybatisUtils.getSession();
int currentPage = 2; //What page
int pageSize = 2; //How many are displayed per page
RowBounds rowBounds = new RowBounds((currentPage-1)*pageSize,pageSize);
//Pass rowboundaries through the session. * * [this method is not recommended now]
List<User> users = session.selectList("com.kuang.mapper.UserMapper.getUserByRowBounds", null, rowBounds);
for (User user: users){
System.out.println(user);
}
session.close();
}
PageHelper
You can understand it and try it yourself
Official documents: https://pagehelper.github.io/
In MyBatisPlus, we also explained the paging implementation, so there are many implementation methods. You can master them according to your understanding and proficiency!
After knowing the simple result set mapping, we can implement one to many and many to one operations

end

Crazy God says MyBatis04: developing with annotations
Using annotation development
Review of Episode 1: Crazy God says MyBatis03: ResultMap and pagination
Interface oriented programming
- Everyone has studied object-oriented programming and interface before, but in real development, we often choose interface oriented programming
- Root cause: decoupling, expandable, improved reuse. In layered development, the upper layer does not care about the specific implementation. Everyone abides by common standards, making the development easier and more standardized
- In an object-oriented system, various functions of the system are completed by many different objects. In this case, how each object implements itself is not so important to system designers;
- The cooperative relationship between various objects has become the key of system design. From the communication between different classes to the interaction between modules, we should focus on it at the beginning of system design, which is also the main work of system design. Interface oriented programming means programming according to this idea.
Understanding of interfaces
-
From a deeper understanding, the interface should be the separation of definition (specification, constraint) and Implementation (the principle of separation of name and reality).
-
The interface itself reflects the system designer's abstract understanding of the system.
-
There shall be two types of interfaces:
-
- The first type is the abstraction of an individual, which can correspond to an abstract class;
- The second is the abstraction of an aspect of an individual, that is, the formation of an abstract interface;
-
An individual may have multiple Abstract faces. Abstract body and abstract surface are different.
Three oriented differences
-
Object - oriented means that when we consider a problem, we take the object as the unit and consider its attributes and methods
-
Process oriented means that when we consider a problem, we consider its implementation in a specific process (transaction process)
-
Interface design and non interface design are aimed at reuse technology, and object-oriented (process) is not a problem. It is more reflected in the overall architecture of the system
Development with annotations
-
The initial configuration information of MyBatis is based on XML, and the mapping statement (SQL) is also defined in XML. MyBatis 3 provides a new annotation based configuration. Unfortunately, the expressiveness and flexibility of Java annotations are very limited. The most powerful MyBatis mapping cannot be built with annotations
-
sql types are mainly divided into:
-
- @select ()
- @update ()
- @Insert ()
- @delete ()
**Note: * * mapper.xml mapping file is not required for annotation development
1. We add annotations to our interface
//Query all users
@Select("select id,name,pwd password from user")
public List<User> getAllUser();
2. Inject in the core configuration file of mybatis
<!--use class Binding interface--> <mappers> <mapper class="com.kuang.mapper.UserMapper"/> </mappers>
3. Let's go and test
@Test
public void testGetAllUser() {
SqlSession session = MybatisUtils.getSession();
//In essence, it makes use of the dynamic proxy mechanism of the jvm
UserMapper mapper = session.getMapper(UserMapper.class);
List<User> users = mapper.getAllUser();
for (User user : users){
System.out.println(user);
}
session.close();
}
4. Use Debug to see the essence
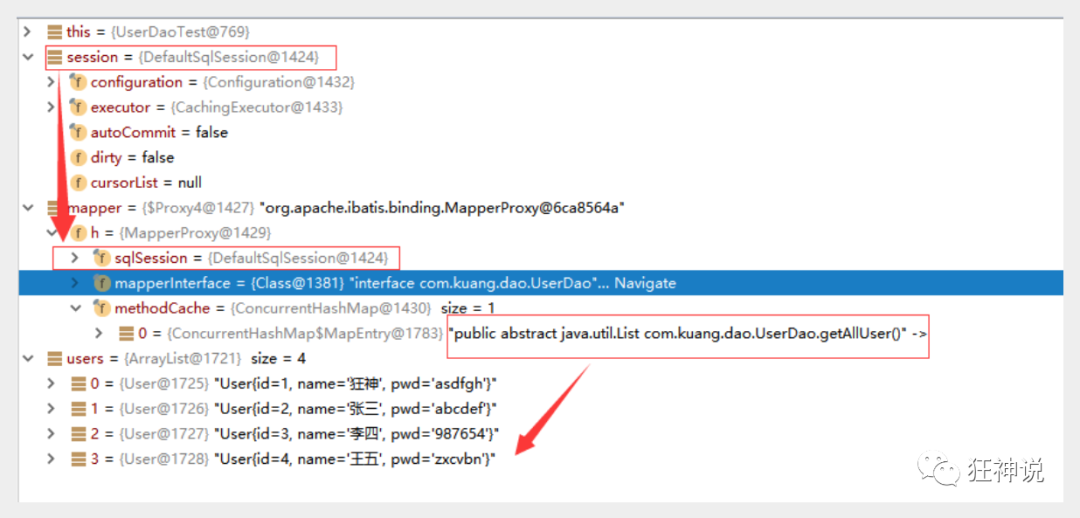
5. In essence, it makes use of the dynamic proxy mechanism of the jvm
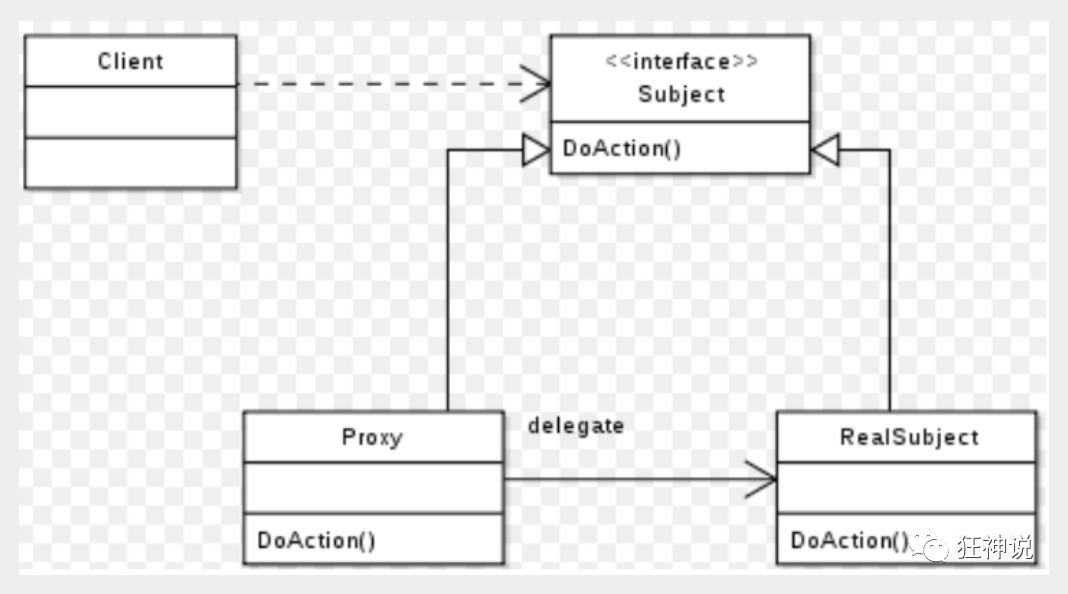
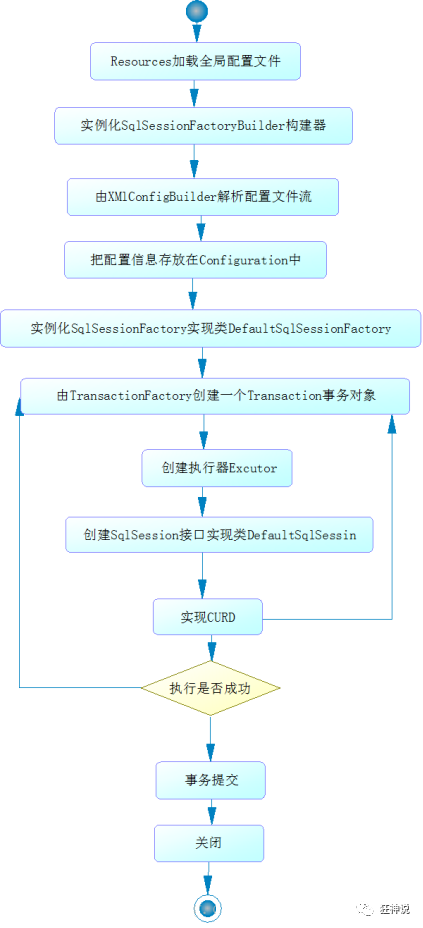
6. Mybatis detailed execution process
Addition, deletion and modification of notes
Transform the getSession() method of MybatisUtils tool class and overload the implementation.
//Get SqlSession connection
public static SqlSession getSession(){
return getSession(true); //Transaction auto commit
}
public static SqlSession getSession(boolean flag){
return sqlSessionFactory.openSession(flag);
}
[note] ensure that the entity class corresponds to the database field
Query:
1. Write interface method annotation
//Query user by id
@Select("select * from user where id = #{id}")
User selectUserById(@Param("id") int id);
2. Testing
@Test
public void testSelectUserById() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.selectUserById(1);
System.out.println(user);
session.close();
}
newly added:
1. Write interface method annotation
//Add a user
@Insert("insert into user (id,name,pwd) values (#{id},#{name},#{pwd})")
int addUser(User user);
2. Testing
@Test
public void testAddUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = new User(6, "Qin Jiang", "123456");
mapper.addUser(user);
session.close();
}
Modification:
1. Write interface method annotation
//Modify a user
@Update("update user set name=#{name},pwd=#{pwd} where id = #{id}")
int updateUser(User user);
2. Testing
@Test
public void testUpdateUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = new User(6, "Qin Jiang", "zxcvbn");
mapper.updateUser(user);
session.close();
}
Delete:
1. Write interface method annotation
//Delete by id
@Delete("delete from user where id = #{id}")
int deleteUser(@Param("id")int id);
2. Testing
@Test
public void testDeleteUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
mapper.deleteUser(6);
session.close();
}
[Note: remember to handle transactions when adding, deleting or modifying]
About @ Param
@The Param annotation is used to give a name to a method parameter. The following are the principles for the use of the summary:
- When the method accepts only one parameter, @ Param may not be used.
- When the method accepts multiple parameters, it is recommended to use the @ Param annotation to name the parameters.
- If the parameter is a JavaBean, @ Param cannot be used.
- When the @ Param annotation is not used, there can only be one parameter and it is a java bean.
#Difference from $
-
#The function of {} is mainly to replace the placeholder in the preparestatement[ [recommended]
INSERT INTO user (name) VALUES (#{name}); INSERT INTO user (name) VALUES (?); -
The function of ${} is to replace strings directly
INSERT INTO user (name) VALUES ('${name}'); INSERT INTO user (name) VALUES ('kuangshen');
Using annotations and configuration files for collaborative development is MyBatis's best practice!
Using annotation development can improve our development efficiency and can be used reasonably!
end
Crazy God says MyBatis05: one to many and many to one processing
Many to one processing
Many to one processing
Many to one understanding:
- Multiple students correspond to one teacher
- For students, it is a many to one phenomenon, that is, a teacher is associated with students!
Database design
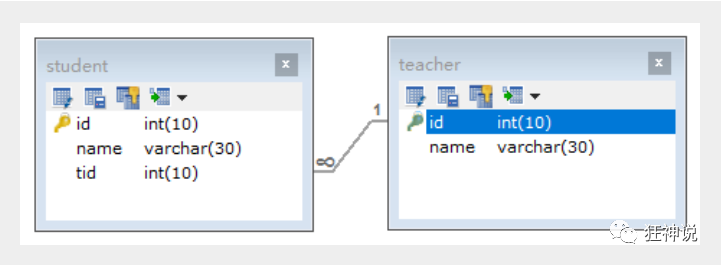
CREATE TABLE `teacher` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO teacher(`id`, `name`) VALUES (1, 'Miss Qin');
CREATE TABLE `student` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
`tid` INT(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fktid` (`tid`),
CONSTRAINT `fktid` FOREIGN KEY (`tid`) REFERENCES `teacher` (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('1', 'Xiao Ming', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('2', 'Xiao Hong', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('3', 'Xiao Zhang', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('4', 'petty thief', '1');
INSERT INTO `student` (`id`, `name`, `tid`) VALUES ('5', 'Xiao Wang', '1');
Build test environment
1. IDEA installing Lombok plug-in
2. Introduce Maven dependency
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.16.10</version> </dependency>
3. Add comments to the code
@Data //GET,SET,ToString, parameterless construction
public class Teacher {
private int id;
private String name;
}
@Data
public class Student {
private int id;
private String name;
//Multiple students can be the same teacher, that is, many to one
private Teacher teacher;
}
4. Write Mapper interfaces corresponding to entity classes [two]
- Whether there is a need or not, it should be written down for later needs!
public interface StudentMapper {
}
public interface TeacherMapper {
}
5. Write mapper.xml configuration files corresponding to Mapper interface [two]
- Whether there is a need or not, it should be written down for later needs!
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.StudentMapper">
</mapper>
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.TeacherMapper">
</mapper>
Nested processing by query
1. Add method to StudentMapper interface
//Get the information of all students and corresponding teachers public List<Student> getStudents();
2. Write the corresponding Mapper file
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.StudentMapper">
<!--
Requirements: obtain the information of all students and corresponding teachers
Idea:
1. Get information about all students
2. Teachers according to the student information obtained ID->Get the teacher's information
3. Think about the problem. In this way, the result set of students should include teachers. How to deal with it? We usually use association query in the database?
1. Make a result set mapping: StudentTeacher
2. StudentTeacher The result set is of type Student
3. The attributes of teachers in students are teacher,The corresponding database is tid.
Multiple [1,...)A student is associated with a teacher=> One to one, one to many
4. Check the official website to find: association – A complex type of Association; Use it to process associative queries
-->
<select id="getStudents" resultMap="StudentTeacher">
select * from student
</select>
<resultMap id="StudentTeacher" type="Student">
<!--association Association properties property Attribute name javaType Attribute type column Column names in tables with more than one side-->
<association property="teacher" column="tid" javaType="Teacher" select="getTeacher"/>
</resultMap>
<!--
From here id,When there is only one attribute, any value can be written below
association in column Multi parameter configuration:
column="{key=value,key=value}"
It's actually in the form of key value pairs, key Pass it on to the next one sql The name of the value, value It's in clip 1 sql The field name of the query.
-->
<select id="getTeacher" resultType="teacher">
select * from teacher where id = #{id}
</select>
</mapper>
3. After writing, go to the Mybatis configuration file and register Mapper!
4. Notes:
<resultMap id="StudentTeacher" type="Student">
<!--association Association properties property Attribute name javaType Attribute type column Column names in tables with more than one side-->
<association property="teacher" column="{id=tid,name=tid}" javaType="Teacher" select="getTeacher"/>
</resultMap>
<!--
From here id,When there is only one attribute, any value can be written below
association in column Multi parameter configuration:
column="{key=value,key=value}"
It's actually in the form of key value pairs, key Pass it on to the next one sql The name of the value, value It's in clip 1 sql The field name of the query.
-->
<select id="getTeacher" resultType="teacher">
select * from teacher where id = #{id} and name = #{name}
</select>
5. Testing
@Test
public void testGetStudents(){
SqlSession session = MybatisUtils.getSession();
StudentMapper mapper = session.getMapper(StudentMapper.class);
List<Student> students = mapper.getStudents();
for (Student student : students){
System.out.println(
"Student name:"+ student.getName()
+"\t teacher:"+student.getTeacher().getName());
}
}
Nested processing by result
In addition to the above way, are there any other ideas?
We can also nest according to the results;
1. Interface method preparation
public List<Student> getStudents2();
2. Write the corresponding mapper file
<!--
Nested processing by query results
Idea:
1. Directly query the results and map the result set
-->
<select id="getStudents2" resultMap="StudentTeacher2" >
select s.id sid, s.name sname , t.name tname
from student s,teacher t
where s.tid = t.id
</select>
<resultMap id="StudentTeacher2" type="Student">
<id property="id" column="sid"/>
<result property="name" column="sname"/>
<!--Associated object property Associated objects in Student Properties in entity classes-->
<association property="teacher" javaType="Teacher">
<result property="name" column="tname"/>
</association>
</resultMap>
3. Go to mybatis config file to inject [it should be handled here]
4. Testing
@Test
public void testGetStudents2(){
SqlSession session = MybatisUtils.getSession();
StudentMapper mapper = session.getMapper(StudentMapper.class);
List<Student> students = mapper.getStudents2();
for (Student student : students){
System.out.println(
"Student name:"+ student.getName()
+"\t teacher:"+student.getTeacher().getName());
}
}
Summary
Nested processing by query is like subquery in SQL
Nested processing according to the results is like a join table query in SQL
One to many processing
One to many processing
One to many understanding:
- A teacher has more than one student
- For teachers, it is a one to many phenomenon, that is, having a group of students (Collection) under a teacher!
Entity class writing
@Data
public class Student {
private int id;
private String name;
private int tid;
}
@Data
public class Teacher {
private int id;
private String name;
//One teacher has more than one student
private List<Student> students;
}
... as before, build a test environment!
Nested processing by result
1. TeacherMapper interface writing method
//Get the designated Teacher and all students under the teacher public Teacher getTeacher(int id);
2. Write Mapper configuration file corresponding to the interface
<mapper namespace="com.kuang.mapper.TeacherMapper">
<!--
thinking:
1. Find out the students from the student list and the teacher list id,Student name, teacher name
2. Map the result set of the queried operations
1. Set, use collection!
JavaType and ofType Are used to specify the object type
JavaType Is used to specify pojo Type of property in
ofType The specified is mapped to list In collection properties pojo Type of.
-->
<select id="getTeacher" resultMap="TeacherStudent">
select s.id sid, s.name sname , t.name tname, t.id tid
from student s,teacher t
where s.tid = t.id and t.id=#{id}
</select>
<resultMap id="TeacherStudent" type="Teacher">
<result property="name" column="tname"/>
<collection property="students" ofType="Student">
<result property="id" column="sid" />
<result property="name" column="sname" />
<result property="tid" column="tid" />
</collection>
</resultMap>
</mapper>
3. Register the Mapper file in the mybatis config file
<mappers> <mapper resource="mapper/TeacherMapper.xml"/> </mappers>
4. Testing
@Test
public void testGetTeacher(){
SqlSession session = MybatisUtils.getSession();
TeacherMapper mapper = session.getMapper(TeacherMapper.class);
Teacher teacher = mapper.getTeacher(1);
System.out.println(teacher.getName());
System.out.println(teacher.getStudents());
}
Nested processing by query
1. TeacherMapper interface writing method
public Teacher getTeacher2(int id);
2. Write Mapper configuration file corresponding to the interface
<select id="getTeacher2" resultMap="TeacherStudent2">
select * from teacher where id = #{id}
</select>
<resultMap id="TeacherStudent2" type="Teacher">
<!--column Is a one to many foreign key , Write the column name of a primary key-->
<collection property="students" javaType="ArrayList" ofType="Student" column="id" select="getStudentByTeacherId"/>
</resultMap>
<select id="getStudentByTeacherId" resultType="Student">
select * from student where tid = #{id}
</select>
3. Register the Mapper file in the mybatis config file
4. Testing
@Test
public void testGetTeacher2(){
SqlSession session = MybatisUtils.getSession();
TeacherMapper mapper = session.getMapper(TeacherMapper.class);
Teacher teacher = mapper.getTeacher2(1);
System.out.println(teacher.getName());
System.out.println(teacher.getStudents());
}
Summary
1. association Association
2. Collection collection
3. Therefore, association is used for one-to-one and many to one, while collection is used for one to many relationships
4. Both JavaType and ofType are used to specify the object type
- JavaType is used to specify the type of property in pojo
- ofType specifies the type mapped to pojo in the list collection property.
Note:
1. Ensure the readability of SQL and make it easy to understand as much as possible
2. According to the actual requirements, try to write SQL statements with higher performance
3. Pay attention to the inconsistency between attribute name and field
4. Note the correspondence between fields and attributes in one to many and many to one
5. Try to use Log4j to view your own errors through the log
One to many and many to one are difficult for many people. We must do a lot of practice and understanding!
end
Crazy God says MyBatis06: dynamic SQL
Dynamic SQL
introduce
What is dynamic SQL: dynamic SQL refers to generating different SQL statements according to different query conditions
Official website description: MyBatis One of its powerful features is its dynamics SQL. If you use JDBC Or other similar framework experience, you can experience splicing according to different conditions SQL The pain of the sentence. For example, when splicing, make sure you don't forget to add the necessary spaces, and pay attention to removing the comma of the last column name in the list. Utilization dynamics SQL This characteristic can completely get rid of this pain. Although dynamic was used before SQL It's not easy, but it is MyBatis Provided can be used in any SQL Powerful dynamic mapping in statements SQL Language can improve this situation. dynamic SQL Element and JSTL Or based on similar XML Similar to the text processor. stay MyBatis In previous versions, there were many elements that needed time to understand. MyBatis 3 The element types are greatly simplified. Now you only need to learn half of the original elements. MyBatis Powerful based OGNL To eliminate most of the other elements. ------------------------------- - if - choose (when, otherwise) - trim (where, set) - foreach -------------------------------
The SQL statements we wrote before are relatively simple. If there are complex businesses, we need to write complex SQL statements, which often need to be spliced. If we don't pay attention to splicing SQL, errors may be caused due to the lack of quotation marks, spaces and so on.
So how to solve this problem? This requires the use of mybatis dynamic SQL. Through tags such as if, choose, when, otherwise, trim, where, set and foreach, it can be combined into very flexible SQL statements, which not only improves the accuracy of SQL statements, but also greatly improves the efficiency of developers.
Build environment
Create a new database table: blog
Fields: id, title, author, create_time,views
CREATE TABLE `blog` ( `id` varchar(50) NOT NULL COMMENT 'Blog id', `title` varchar(100) NOT NULL COMMENT 'Blog title', `author` varchar(30) NOT NULL COMMENT 'Blogger', `create_time` datetime NOT NULL COMMENT 'Creation time', `views` int(30) NOT NULL COMMENT 'Views' ) ENGINE=InnoDB DEFAULT CHARSET=utf8
1. Create Mybatis foundation project
2. IDutil utility class
public class IDUtil {
public static String genId(){
return UUID.randomUUID().toString().replaceAll("-","");
}
}
3. Entity class preparation [pay attention to the function of set method]
import java.util.Date;
public class Blog {
private String id;
private String title;
private String author;
private Date createTime;
private int views;
//set,get....
}
4. Write Mapper interface and xml file
public interface BlogMapper {
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kuang.mapper.BlogMapper">
</mapper>
5. mybatis core configuration file, underline Hump Automatic Conversion
<settings> <setting name="mapUnderscoreToCamelCase" value="true"/> <setting name="logImpl" value="STDOUT_LOGGING"/> </settings> <!--register Mapper.xml--> <mappers> <mapper resource="mapper/BlogMapper.xml"/> </mappers>
6. Insert initial data
Write interface
//Add a new blog int addBlog(Blog blog);
sql configuration file
<insert id="addBlog" parameterType="blog">
insert into blog (id, title, author, create_time, views)
values (#{id},#{title},#{author},#{createTime},#{views});
</insert>
Initialize blog method
@Test
public void addInitBlog(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = new Blog();
blog.setId(IDUtil.genId());
blog.setTitle("Mybatis So simple");
blog.setAuthor("Madness theory");
blog.setCreateTime(new Date());
blog.setViews(9999);
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Java So simple");
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Spring So simple");
mapper.addBlog(blog);
blog.setId(IDUtil.genId());
blog.setTitle("Microservices are so simple");
mapper.addBlog(blog);
session.close();
}
Initialization data completed!
if statement
Demand: query the blog according to the author's name and blog name! If the author's name is empty, query only by the blog name; otherwise, query by the author's name
1. Writing interface classes
//Demand 1 List<Blog> queryBlogIf(Map map);
2. Writing SQL statements
<!--Requirement 1:
According to the author's name and blog name to query the blog!
If the author's name is empty, query only by the blog name; otherwise, query by the author's name
select * from blog where title = #{title} and author = #{author}
-->
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog where
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</select>
3. Testing
@Test
public void testQueryBlogIf(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, String> map = new HashMap<String, String>();
map.put("title","Mybatis So simple");
map.put("author","Madness theory");
List<Blog> blogs = mapper.queryBlogIf(map);
System.out.println(blogs);
session.close();
}
In this way, we can see that if the author is equal to null, the query statement is select * from user where title=#{title}, but what if the title is empty? The query statement is select * from user where and author=#{author}. This is a wrong SQL statement. How to solve it? Look at the following where statement!
Where
Modify the above SQL statement;
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</where>
</select>
The "where" tag will know that if it contains a return value in the tag, it will insert a "where". In addition, if the content returned by the tag starts with AND OR, it will be eliminated.
Set
Similarly, the above query SQL statement contains the where keyword. If the update operation contains the set keyword, how can we deal with it?
1. Writing interface methods
int updateBlog(Map map);
2. sql configuration file
<!--be careful set Are separated by commas-->
<update id="updateBlog" parameterType="map">
update blog
<set>
<if test="title != null">
title = #{title},
</if>
<if test="author != null">
author = #{author}
</if>
</set>
where id = #{id};
</update>
3. Testing
@Test
public void testUpdateBlog(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, String> map = new HashMap<String, String>();
map.put("title","dynamic SQL");
map.put("author","Qin Jiang");
map.put("id","9d6a763f5e1347cebda43e2a32687a77");
mapper.updateBlog(map);
session.close();
}
choose statement
Sometimes, we don't want to use all the query conditions. We just want to select one of them. If one of the query conditions is satisfied, we can use the choose tag to solve such problems, which is similar to the switch statement in Java
1. Writing interface methods
List<Blog> queryBlogChoose(Map map);
2. sql configuration file
<select id="queryBlogChoose" parameterType="map" resultType="blog">
select * from blog
<where>
<choose>
<when test="title != null">
title = #{title}
</when>
<when test="author != null">
and author = #{author}
</when>
<otherwise>
and views = #{views}
</otherwise>
</choose>
</where>
</select>
3. Test class
@Test
public void testQueryBlogChoose(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("title","Java So simple");
map.put("author","Madness theory");
map.put("views",9999);
List<Blog> blogs = mapper.queryBlogChoose(map);
System.out.println(blogs);
session.close();
}
SQL fragment
Sometimes we may use a certain sql statement too much. In order to increase the reusability of the code and simplify the code, we need to extract these codes and call them directly when using them.
Extract SQL fragment:
<sql id="if-title-author">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
Reference SQL fragment:
<select id="queryBlogIf" parameterType="map" resultType="blog">
select * from blog
<where>
<!-- quote sql Clip, if refid If the specified is not in this document, it needs to be preceded by namespace -->
<include refid="if-title-author"></include>
<!-- You can also refer to other sql fragment -->
</where>
</select>
be careful:
① . it is better to define sql fragments based on a single table to improve the reusability of fragments
② . do not include where in the sql fragment
Foreach
Modify the IDs of the first three data in the database to 1,2,3;
Requirement: we need to query the blog information with id 1, 2 and 3 in the blog table
1. Write interface
List<Blog> queryBlogForeach(Map map);
2. Writing SQL statements
<select id="queryBlogForeach" parameterType="map" resultType="blog">
select * from blog
<where>
<!--
collection:Specifies the collection properties in the input object
item:Generated objects per traversal
open:Splice string at the beginning of traversal
close:String spliced at end
separator:Traverse the strings that need to be spliced between objects
select * from blog where 1=1 and (id=1 or id=2 or id=3)
-->
<foreach collection="ids" item="id" open="and (" close=")" separator="or">
id=#{id}
</foreach>
</where>
</select>
3. Testing
@Test
public void testQueryBlogForeach(){
SqlSession session = MybatisUtils.getSession();
BlogMapper mapper = session.getMapper(BlogMapper.class);
HashMap map = new HashMap();
List<Integer> ids = new ArrayList<Integer>();
ids.add(1);
ids.add(2);
ids.add(3);
map.put("ids",ids);
List<Blog> blogs = mapper.queryBlogForeach(map);
System.out.println(blogs);
session.close();
}
Summary: in fact, the compilation of dynamic sql statements is often a problem of splicing. In order to ensure the accuracy of splicing, we'd better first write the original sql statements, and then change them through the dynamic sql of mybatis to prevent errors. It is the skill to master it by using it in practice.
Dynamic SQL is widely used in development. You must master it skillfully!
end
Crazy God says MyBatis07: cache
cache
brief introduction
1. What is Cache?
- There is temporary data in memory.
- Put the data frequently queried by users in the cache (memory), and users do not need to query from the disk (relational database data file) but from the cache to query the data, so as to improve the query efficiency and solve the performance problem of high concurrency system.
2. Why cache?
- Reduce the number of interactions with the database, reduce system overhead and improve system efficiency.
3. What kind of data can be cached?
- Frequently queried and infrequently changed data.
Mybatis cache
-
MyBatis includes a very powerful query caching feature that makes it easy to customize and configure caching. Caching can greatly improve query efficiency.
-
Two levels of cache are defined by default in MyBatis system: L1 cache and L2 cache
-
- By default, only L1 cache is on( SqlSession level cache (also known as local cache)
- L2 cache needs to be manually enabled and configured. It is based on namespace level cache.
- In order to improve scalability, MyBatis defines the Cache interface Cache. We can customize the L2 Cache by implementing the Cache interface
L1 cache
L1 cache is also called local cache:
- The data queried during the same session with the database will be placed in the local cache.
- In the future, if you need to obtain the same data, you can get it directly from the cache. You don't have to query the database again;
test
1. Add logs in mybatis to facilitate test results
2. Writing interface methods
//Query user by id
User queryUserById(@Param("id") int id);
3. Mapper file corresponding to interface
<select id="queryUserById" resultType="user">
select * from user where id = #{id}
</select>
4. Testing
@Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
User user2 = mapper.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session.close();
}
5. Result analysis
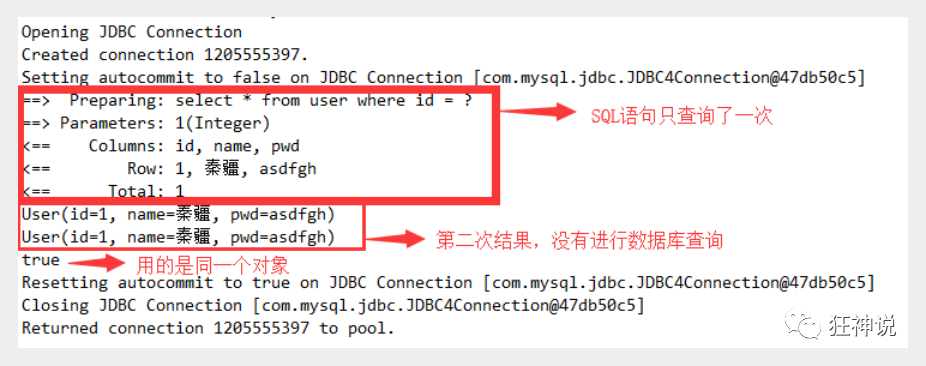
Four situations of L1 cache invalidation
The first level cache is a SqlSession level cache, which is always on, and we can't close it;
L1 cache invalidation: the current L1 cache is not used. The effect is that you need to send another query request to the database!
1. sqlSession is different
@Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
SqlSession session2 = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
UserMapper mapper2 = session2.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
User user2 = mapper2.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session.close();
session2.close();
}
Observation: two SQL statements were sent!
Conclusion: the caches in each sqlSession are independent of each other
2. The sqlSession is the same, but the query criteria are different
@Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
UserMapper mapper2 = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
User user2 = mapper2.queryUserById(2);
System.out.println(user2);
System.out.println(user==user2);
session.close();
}
Observation: two SQL statements were sent! Very normal understanding
Conclusion: this data does not exist in the current cache
3. sqlSession is the same. Add, delete and modify operations are performed between the two queries!
Increase method
//Modify user int updateUser(Map map);
Write SQL
<update id="updateUser" parameterType="map">
update user set name = #{name} where id = #{id}
</update>
test
@Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
HashMap map = new HashMap();
map.put("name","kuangshen");
map.put("id",4);
mapper.updateUser(map);
User user2 = mapper.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session.close();
}
Observation result: the query is re executed after adding, deleting and modifying in the middle
Conclusion: addition, deletion and modification may affect the current data
4. The sqlSession is the same. Manually clear the L1 cache
@Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
session.clearCache();//Manually clear cache
User user2 = mapper.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session.close();
}
The first level cache is a map
L2 cache
-
L2 cache is also called global cache. The scope of L1 cache is too low, so L2 cache was born
-
Based on the namespace level cache, a namespace corresponds to a L2 cache;
-
Working mechanism
-
- When a session queries a piece of data, the data will be placed in the first level cache of the current session;
- If the current session is closed, the L1 cache corresponding to the session is gone; But what we want is that the session is closed and the data in the L1 cache is saved to the L2 cache;
- The new session query information can get the content from the L2 cache;
- The data found by different mapper s will be placed in their corresponding cache (map);
Use steps
1. Open global cache [mybatis config. XML]
<setting name="cacheEnabled" value="true"/>
2. Configure the secondary cache in each mapper.xml. This configuration is very simple[ xxxMapper.xml]
<cache/> Official example=====>View official documents <cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/> This more advanced configuration creates a FIFO The cache is refreshed every 60 seconds. It can store up to 512 references of the result object or list, and the returned objects are considered read-only. Therefore, modifying them may conflict with callers in different threads.
3. Code test
- All entity classes implement the serialization interface first
- Test code
@Test
public void testQueryUserById(){
SqlSession session = MybatisUtils.getSession();
SqlSession session2 = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
UserMapper mapper2 = session2.getMapper(UserMapper.class);
User user = mapper.queryUserById(1);
System.out.println(user);
session.close();
User user2 = mapper2.queryUserById(1);
System.out.println(user2);
System.out.println(user==user2);
session2.close();
}
conclusion
- As long as the L2 cache is enabled, our queries in the same Mapper can get data in the L2 cache
- The detected data will be placed in the L1 cache by default
- Only after the session is committed or closed, the data in the L1 cache will be transferred to the L2 cache
Cache schematic
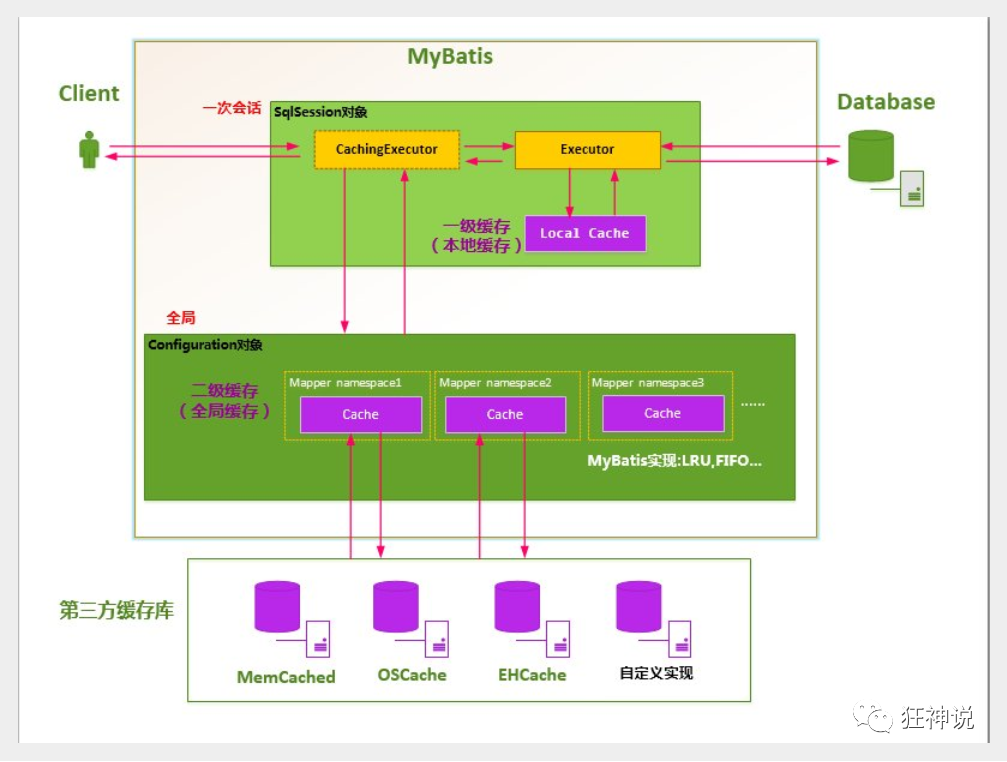
EhCache

Third party cache implementation - EhCache: View Baidu Encyclopedia
Ehcache is a widely used java distributed cache for general cache;
To use Ehcache in your application, you need to introduce dependent jar packages
<!-- https://mvnrepository.com/artifact/org.mybatis.caches/mybatis-ehcache --> <dependency> <groupId>org.mybatis.caches</groupId> <artifactId>mybatis-ehcache</artifactId> <version>1.1.0</version> </dependency>
Use the corresponding cache in mapper.xml
<mapper namespace = "org.acme.FooMapper" > <cache type = "org.mybatis.caches.ehcache.EhcacheCache" /> </mapper>
Write the ehcache.xml file. If the / ehcache.xml resource is not found or there is a problem when loading, the default configuration will be used.
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://ehcache.org/ehcache.xsd"
updateCheck="false">
<!--
diskStore: Is the cache path, ehcache There are two levels: memory and disk. This attribute defines the cache location of the disk. The parameters are explained as follows:
user.home – User home directory
user.dir – User's current working directory
java.io.tmpdir – Default temporary file path
-->
<diskStore path="./tmpdir/Tmp_EhCache"/>
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
<cache
name="cloud_user"
eternal="false"
maxElementsInMemory="5000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="1800"
memoryStoreEvictionPolicy="LRU"/>
<!--
defaultCache: Default cache policy, when ehcache This cache policy is used when the defined cache cannot be found. Only one can be defined.
-->
<!--
name:Cache name.
maxElementsInMemory:Maximum number of caches
maxElementsOnDisk: Maximum number of hard disk caches.
eternal:Whether the object is permanently valid, but once it is set, timeout Will not work.
overflowToDisk:Whether to save to disk when the system crashes
timeToIdleSeconds:Set the allowed idle time (in seconds) of the object before expiration. Only if eternal=false It is used when the object is not permanently valid. It is an optional attribute. The default value is 0, that is, the idle time is infinite.
timeToLiveSeconds:Sets the allowable survival time (in seconds) of an object before it expires. The maximum time is between creation time and expiration time. Only if eternal=false Used when the object is not permanently valid. The default is 0.,That is, the survival time of the object is infinite.
diskPersistent: Cache virtual machine restart data Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB: This parameter setting DiskStore(Cache size for disk cache). The default is 30 MB. each Cache Each should have its own buffer.
diskExpiryThreadIntervalSeconds: The running time interval of disk failure thread is 120 seconds by default.
memoryStoreEvictionPolicy: When reached maxElementsInMemory When restricted, Ehcache The memory will be cleaned according to the specified policy. The default policy is LRU(Least recently used). You can set it to FIFO(First in first out) or LFU(Less used).
clearOnFlush: Whether to clear when the amount of memory is maximum.
memoryStoreEvictionPolicy:Optional strategies are: LRU(Least recently used, default policy) FIFO(First in first out) LFU(Minimum number of visits).
FIFO,first in first out,This is the most familiar, first in, first out.
LFU, Less Frequently Used,This is the strategy used in the above example. To put it bluntly, it has always been the least used. As mentioned above, the cached element has a hit Properties, hit The smallest value will be flushed out of the cache.
LRU,Least Recently Used,The least recently used cache element has a timestamp. When the cache capacity is full and it is necessary to make room for caching new elements, the element with the farthest timestamp from the current time in the existing cache element will be cleared out of the cache.
-->
</ehcache>
Reasonable use of cache can greatly improve the performance of our program!
end
For more Java stack related articles, click the article below
[Full Java stack] summary of learning route and project data of full Java stack [JavaSE+Web foundation + advanced front end + SSM + microservice + Linux+JavaEE]
[Full Java stack] summary of learning route and project data of full Java stack [JavaSE+Web foundation + advanced front end + SSM + microservice + Linux+JavaEE]