1. Operation mechanism of Spark On YARN deployment mode
- After the task is submitted, start the Driver;
- Driver registers the application with the cluster manager;
- The cluster manager allocates the Executor according to the configuration file of this task and starts it;
- The Driver starts to execute the main function. When the action operator is executed, it starts to reverse calculate, and divide the stages according to the wide dependency. Then, each Stage corresponds to a Taskset. There are multiple tasks in the Taskset. Find the available resource Executor for scheduling;
- According to the localization principle, tasks will be distributed to the designated Executor for execution. During Task execution, the Executor will constantly communicate with the Driver to report the Task operation.
1.1,Spark On YARN Cluster
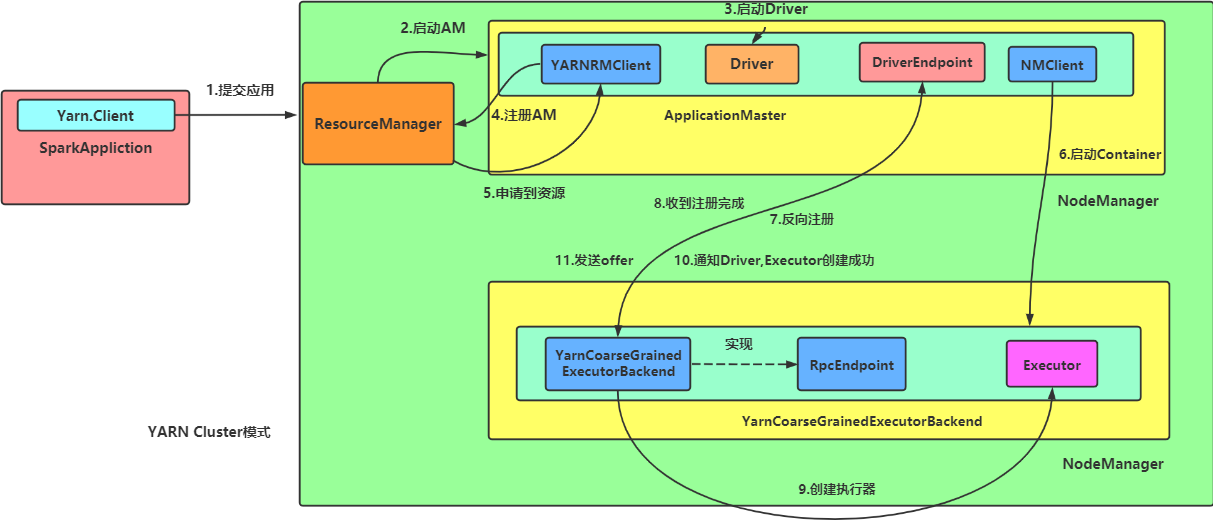
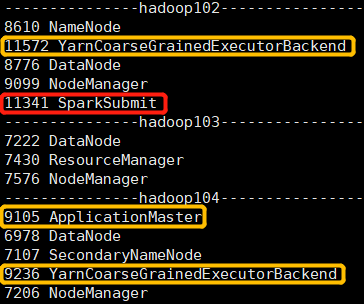
spark-submit \ --master yarn \ --deploy-mode cluster \ --class org.apache.spark.examples.SparkPi \ $SPARK_HOME/examples/jars/spark-examples_2.12-3.0.0.jar \ 999
Submit the Spark task, configure -- master yarn and -- deploy mode cluster, and then view the Java process
1.2,Spark On YARN Client
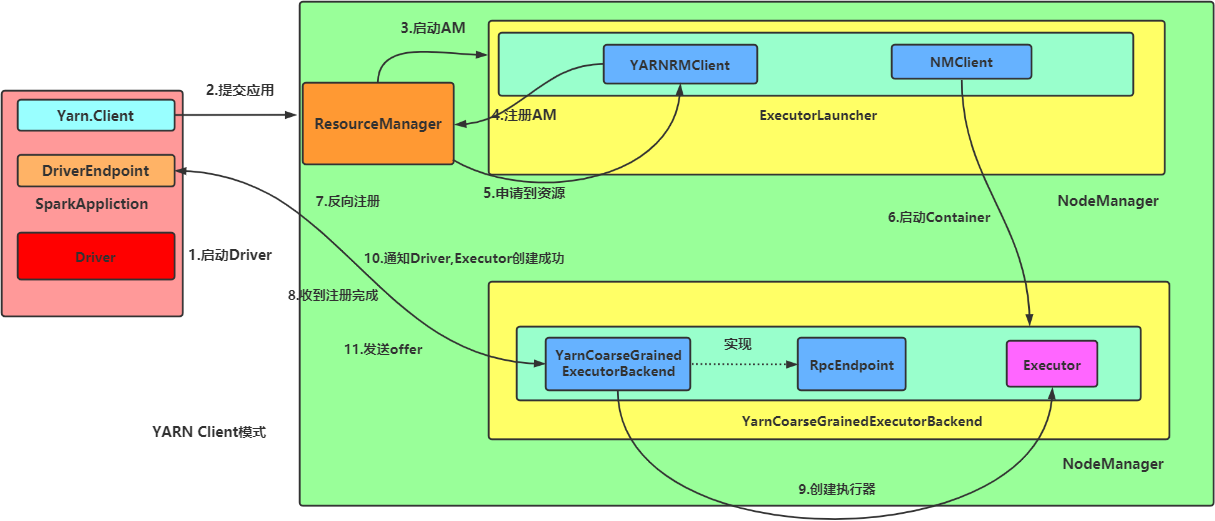
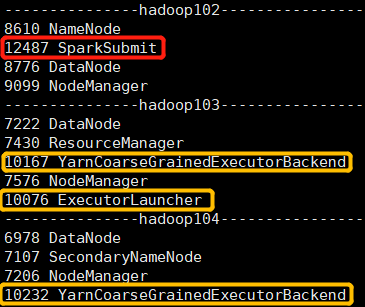
spark-submit \ --master yarn \ --class org.apache.spark.examples.SparkPi \ $SPARK_HOME/examples/jars/spark-examples_2.12-3.0.0.jar \ 999
Submit the Spark task, configure -- master yarn, and then view the Java process
2. Task scheduling mechanism
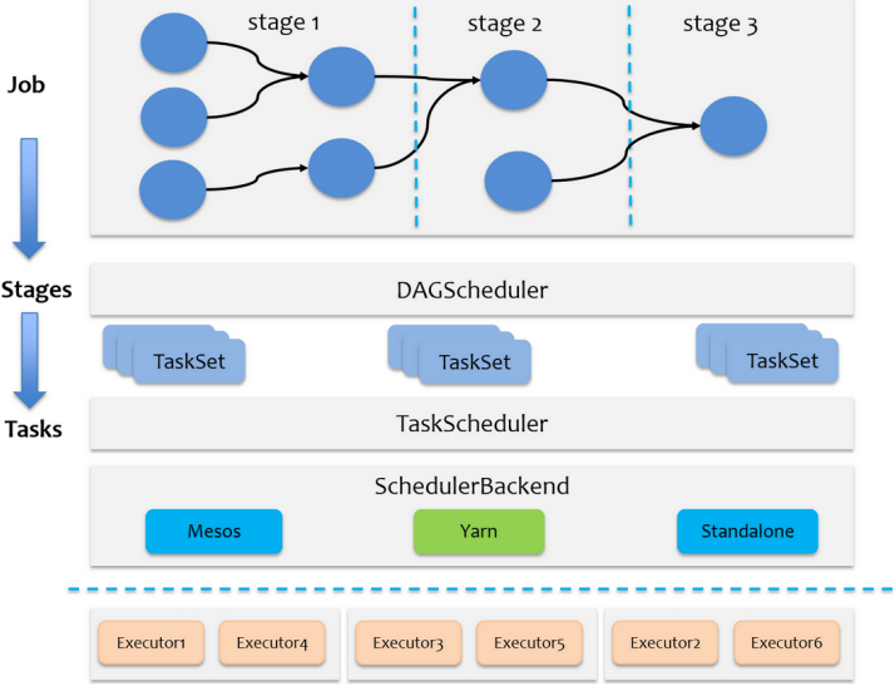
- Job is Action operator Boundary
- Stage is a subset of jobs, bounded by RDD wide dependency
- Task s are a subset of Stage, branch area number = T a s k number amount Number of partitions = number of tasks Number of partitions = number of tasks
-
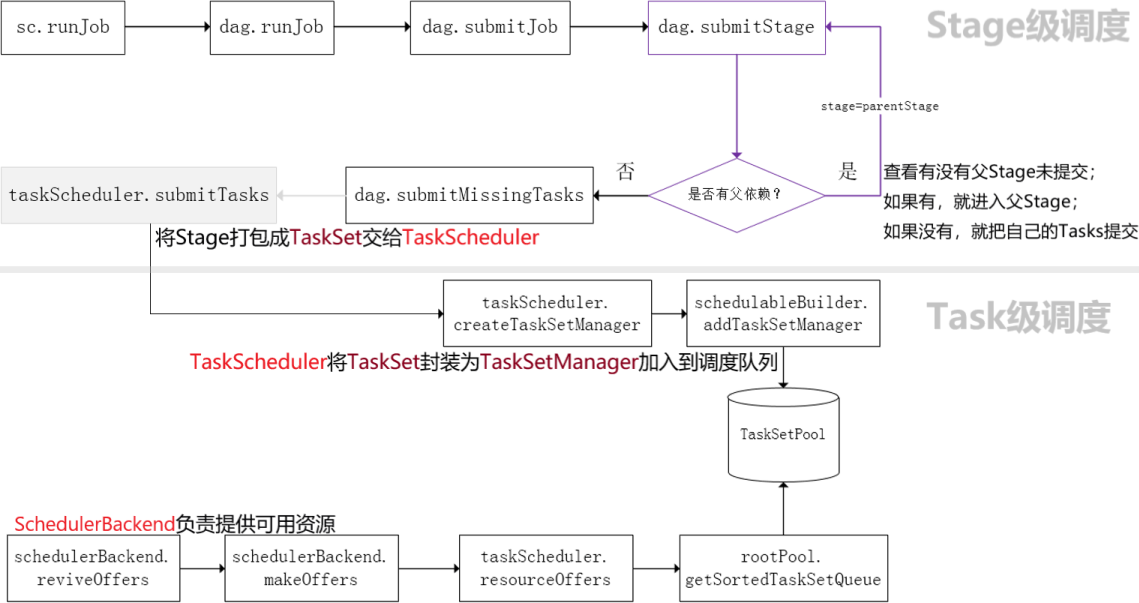
Stage scheduler
DAGScheduler is responsible for scheduling at the Stage level, mainly dividing the Job into several Stages, packaging each Stage into a TaskSet and delivering it to the TaskScheduler for scheduling -
Task scheduler
TaskScheduler is responsible for Task level scheduling and distributes tasksets to the Executor for execution according to the specified scheduling policy
SchedulerBackend is responsible for providing available resources during scheduling
Simplified diagram of source code analysis
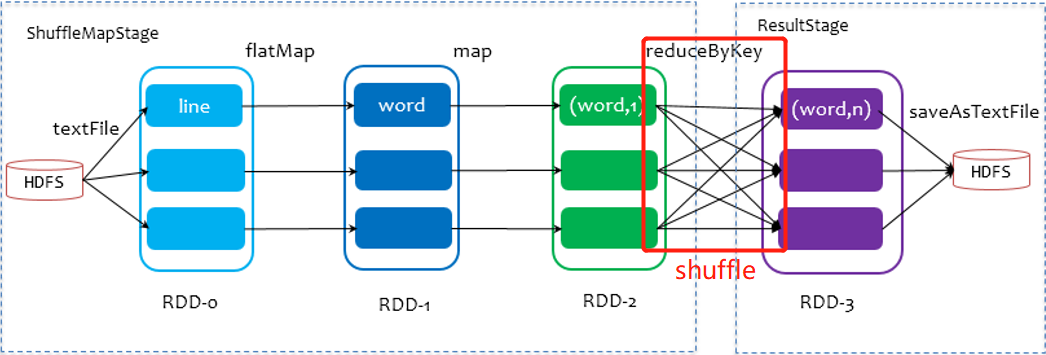
3. Shuffle mechanism
When dividing stage s
The last stage is ResultStage
The previous stage is ShuffleMapStage, and its end is accompanied by shuffle
Simplified sort based shuffle flow chart
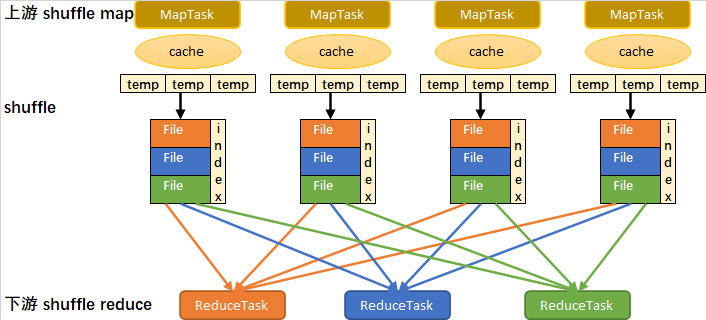
1. Write memory buffer
2. When the buffer is full, it overflows to the temporary file
3. Merge all temporary files into one data file and create an index file
4. A MapTask generates a data file and an index file
5. Total number of sort based shuffle generated files: number of maptasks x 2
6. ReduceTask reads data from the data file according to the index file
4. Memory management
On heap and off heap memory
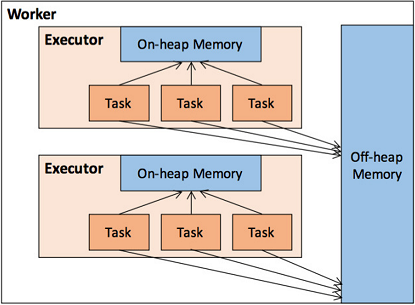
The memory management of the Executor is based on the memory management of the JVM
Spark introduces off heap memory so that it can be used directly in the system memory of the work node
Memory space allocation
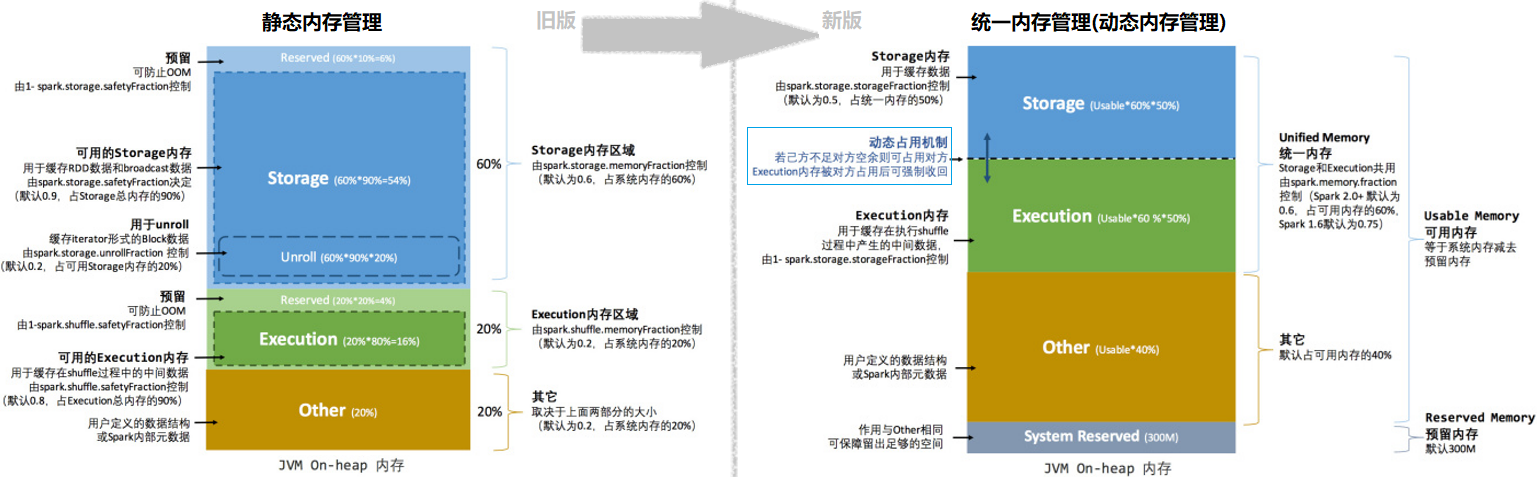
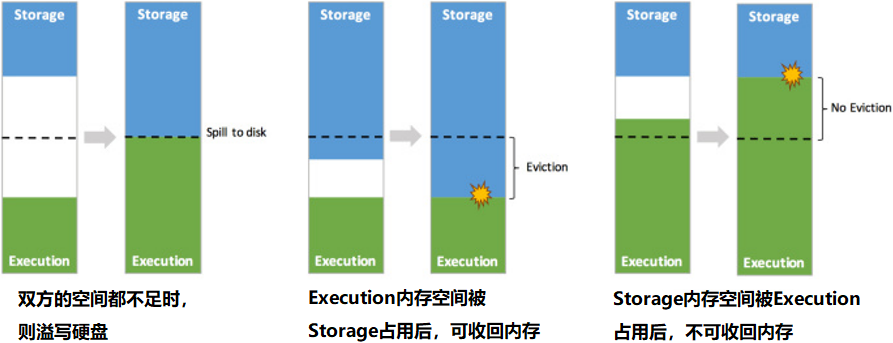
Dynamic occupancy mechanism
5. Appendix
5.1 Related words
| en | 🔉 | cn |
|---|---|---|
| RPC | Remote Procedure Call | remote procedure call |
| spill | spɪl | v. (make) overflow; n. overflow |
| eviction | ɪˈvɪkʃn | n. Eviction; take back |
5.2 source code interception
To view the source code, you need to import the dependency and download the corresponding source code
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
5.2.1,SparkOnYARNCluster
spark-submit --master yarn --deploy-mode cluster ...
-----------------------------------
Part I: client and YARN signal communication
org.apache.spark.deploy.SparkSubmit.main
-- submit.doSubmit(args)
--super.doSubmit(args)
// Parse the parameters passed in after spark submit, and load the default parameters of spark
-- val appArgs = parseArguments(args)
--submit(appArgs, uninitLog)
--doRunMain()
//Run the main method in the main class submitted by spark submit
--runMain(args, uninitLog)
// If deployMode == CLIENT, childMainClass = the full class name submitted by yourself
// If deployMode == CLUSTER, it is the YARN cluster childmainclass = org apache. spark. deploy. YARN. YarnClusterApplication
--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
//Create Class type of childMainClass
--mainClass = Utils.classForName(childMainClass)
--val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
//If it is in cluster mode, run the next line at this time
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
new JavaMainApplication(mainClass)
}
-- app.start(childArgs.toArray, sparkConf)
// YarnClusterApplication. The start () client is a client that can communicate with yarn
--new Client(new ClientArguments(args), conf, null).run()
--this.appId = submitApplication()
// Submit the application to YARN and obtain the return value of YARN
-- val newApp = yarnClient.createApplication()
//Determine the job directory where the app saves temporary data, usually generating a subdirectory in the / tmp directory in hdfs
-- val appStagingBaseDir = sparkConf.get(STAGING_DIR)
//Ensure that YARN has sufficient resources to run the AM of the current app
// If the cluster resource is insufficient, it will be blocked at this time until it times out, and will fail
-- verifyClusterResources(newAppResponse)
-- val containerContext = createContainerLaunchContext(newAppResponse)
// Determine the main class name of AM
// AM is an interface provided by YARN
// If any application wants to submit APP to YARN, it can implement AM interface
// The app written by MR realizes AM
// The App written by spark realizes AM
--val amClass =
if (isClusterMode) {
//The full class name of cluster mode AM is org apache. spark. deploy. yarn. ApplicationMaster
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
-- val appContext = createApplicationSubmissionContext(newApp, containerContext)
//Submit run AM
-- yarnClient.submitApplication(appContext)
----------------------------------------
Part II AM start-up
ApplicationMaster.main
--master.run()
--if (isClusterMode) {
//If it is in Cluster mode, run the Driver in AM
--runDriver()
} else {
runExecutorLauncher()
}
// Start a thread to run the main method of the app application written by the user
--userClassThread = startUserApplication()
//After the main method of the app written by the user runs, obtain the SparkContext created by the user
--val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
// Report to RM that AM has been started successfully
--registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
// Create an object that can request resources from RM and start the Executor
-- createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
//allocator: YarnAllocator is used to apply for a container from RM and decide what to do with the container after obtaining the container
--allocator = client.createAllocator()
--allocator.allocateResources()
//Send request
-- val allocateResponse = amClient.allocate(progressIndicator)
//Get the allocated Container from the response of YARN
--val allocatedContainers = allocateResponse.getAllocatedContainers()
//Processing the requested Container
-- handleAllocatedContainers(allocatedContainers.asScala)
//Running processes in Container
-- runAllocatedContainers(containersToUse)
//Each Container will create an ExecutorRunnable and give it to the thread pool to run
--new ExecutorRunnable.run
-- nmClient = NMClient.createNMClient()
nmClient.init(conf)
nmClient.start()
//Prepare the startup process in the container
startContainer()
--org.apache.spark.executor.YarnCoarseGrainedExecutorBackend Process started in container
--val commands = prepareCommand()
5.2.2,SparkOnYARNClient
spark-submit --master yarn ...
-----------------------------------
Part I: client and YARN signal communication
org.apache.spark.deploy.SparkSubmit.main
-- submit.doSubmit(args)
--super.doSubmit(args)
// Parse the parameters passed in after spark submit, and load the default parameters of spark
-- val appArgs = parseArguments(args)
--submit(appArgs, uninitLog)
--doRunMain()
//Run the main method in the main class submitted by spark submit
--runMain(args, uninitLog)
// If deployMode == CLIENT, childMainClass = the full class name submitted by yourself
// If deployMode == CLUSTER, it is the YARN cluster childmainclass = org apache. spark. deploy. YARN. YarnClusterApplication
--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
//Create Class type of childMainClass
--mainClass = Utils.classForName(childMainClass)
--val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
//If it is client mode, run the next line at this time
new JavaMainApplication(mainClass)
}
//JavaMainApplication.start
-- app.start(childArgs.toArray, sparkConf)
//Get the main of the app class written by the user
-- val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
//Execute the main method and the Driver starts
--mainMethod.invoke(null, args)
------------------------------------------------------------------------
Part II: WordCount.main
SparkContext sc=new SparkContext
SparkContext Important components of:
private var _taskScheduler: TaskScheduler = _ //Responsible for Task scheduling
private var _dagScheduler: DAGScheduler = _ // Segmentation of DAG Stage in Job
private var _env: SparkEnv = _ // Rpcenv (communication environment) blockmanager (data storage)
--------------
_taskScheduler = ts
_taskScheduler.start()
//YarnClientSchedulerBackend.start()
--backend.start()
-- client = new Client(args, conf, sc.env.rpcEnv)
//Submit application to YARN
-- bindToYarn(client.submitApplication(), None)
//Reference cluster mode
--......
--Running in container AM Full class name of: org.apache.spark.deploy.yarn.ExecutorLauncher
-----------------------------
Part II: startup AM
org.apache.spark.deploy.yarn.ExecutorLauncher.main
//ExecutorLauncher encapsulates and implements AM
ApplicationMaster.main(args)
-- --master.run()
if (isClusterMode) {
--runDriver()
} else {
//client mode operation
runExecutorLauncher() //Request Container to start Executor
}
----------------------------------------------------------------------------
// YarnClusterApplication. The start () client is a client that can communicate with yarn
--new Client(new ClientArguments(args), conf, null).run()
--this.appId = submitApplication()
// Submit the application to YARN and obtain the return value of YARN
-- val newApp = yarnClient.createApplication()
//Determine the job directory where the app saves temporary data, usually generating a subdirectory in the / tmp directory in hdfs
-- val appStagingBaseDir = sparkConf.get(STAGING_DIR)
//Ensure that YARN has sufficient resources to run the AM of the current app
// If the cluster resource is insufficient, it will be blocked at this time until it times out, and will fail
-- verifyClusterResources(newAppResponse)
-- val containerContext = createContainerLaunchContext(newAppResponse)
// Determine the main class name of AM
// AM is an interface provided by YARN
// If any application wants to submit APP to YARN, it can implement AM interface
// The app written by MR realizes AM
// The App written by spark realizes AM
--val amClass =
if (isClusterMode) {
//The full class name of cluster mode AM is org apache. spark. deploy. yarn. ApplicationMaster
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
-- val appContext = createApplicationSubmissionContext(newApp, containerContext)
//Submit run AM
-- yarnClient.submitApplication(appContext)
5.2. 3. Reverse registration initiated by Executor
org.apache.spark.executor.YarnCoarseGrainedExecutorBackend Itself is a communication endpoint
//RpcEndpointRef: a reference to a communication endpoint
var driver: Option[RpcEndpointRef] = None
------------------
Part I: YarnCoarseGrainedExecutorBackend Process start
--YarnCoarseGrainedExecutorBackend.main
-- CoarseGrainedExecutorBackend.run(backendArgs, createFn)
//Request the configuration information of spark from the Driver
--val executorConf = new SparkConf
// The current process has a communication alias called Executor in the network
-- env.rpcEnv.setupEndpoint("Executor",
backendCreateFn(env.rpcEnv, arguments, env, cfg.resourceProfile))
//Block and run all the time unless the Driver sends a stop command
--env.rpcEnv.awaitTermination()
constructor -> onStart -> receive* -> onStop
--------------------------------------
Part II: YarnCoarseGrainedExecutorBackend Process direction Driver Send registration request
onStart
// ref:RpcEndpointRef represents the communication endpoint reference (phone number) of the Driver
// Send a registerexecution message to the Driver to reply to a Boolean value
-- ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls,
extractAttributes, _resources, resourceProfile.id))
}(ThreadUtils.sameThread).onComplete {
case Success(_) =>
//If successful, send yourself a RegisteredExecutor message
self.send(RegisteredExecutor)
//If it fails, the process exits
case Failure(e) =>
exitExecutor(1, s"Cannot register with driver: $driverUrl", e, notifyDriver = false)
-------------------------------------
Part III: Driver Processing registration requests
DriverEndPoint.receiveAndReply
--case RegisterExecutor
// Judge whether it has been registered. If it has been registered, the reply fails; Judge whether to pull black, pull black, registration failed
// Otherwise, after registration, reply true
context.reply(true)
----------------------------------------
Part IV: YarnCoarseGrainedExecutorBackend After successful registration
YarnCoarseGrainedExecutorBackend.receive
-- case RegisteredExecutor =>
logInfo("Successfully registered with driver")
try {
// Spark's calculator maintains a thread pool to calculate various tasks
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false,
resources = _resources)
// Send LaunchedExecutor message to Driver
driver.get.send(LaunchedExecutor(executorId))
-----------------------------------------------------
Part V: Driver handle LaunchedExecutor request
DriverEndPoint.receive
-- case LaunchedExecutor(executorId) =>
executorDataMap.get(executorId).foreach { data =>
data.freeCores = data.totalCores
}
//The Driver sends a work Task to the Executor
makeOffers(executorId)
//From the scheduling pool, schedule the tasks according to the priority of the TaskSet.
// According to the principle of sending in turn, the Task is scheduled to all executors to ensure load balance.
//Schedule the tasks that should be sent to the secondary Executor
--scheduler.resourceOffers(workOffers)
-- launchTasks(taskDescs)
-- val serializedTask = TaskDescription.encode(task)
//Say hello to the Executor to be sent and send the Task
--executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
--------------------------------------------------
Part VI: Executor received Task
-- case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
// Deserialize to get the Task description
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
taskResources(taskDesc.taskId) = taskDesc.resources
//Start the operation of the Task
executor.launchTask(this, taskDesc)
//Create a thread for the Task to run
-- val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
// Start thread
threadPool.execute(tr)
--TaskRunner.run()
//Construct a Task object that can be run
--task = ser.deserialize[Task[Any]]
//Run the Task to get the results
-- val res = task.run()
// ShuffleMapTask or ResultTask
--runTask(context)
}
5.2. 4. Task scheduling
--------------
RDD.collect
--val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
//Judge whether there is a closure and whether the closure variable can be serialized
-- val cleanedFunc = clean(func)
-- dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
-- val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// Event handles the loop and puts an event JobSubmitted
// eventProcessLoop = new DAGSchedulerEventProcessLoop
-- eventProcessLoop.post(JobSubmitted())
--EventLoop.onReceive(event)
-- doOnReceive(event)
--case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
----------------------
dagScheduler.handleJobSubmitted
// The last stage of the Job
--var finalStage: ResultStage = null
-- finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
-- Recursion, looking forward from the back, will ResultStage All ancestors of ShuffleMapStage All are created before the last one is created Stage
-- val parents = getOrCreateParentStages(rdd, jobId)
--val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
// The Job will not be generated until the ResultStage is created
-- val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
//Submit ResultStage
--submitStage(finalStage)
//Check whether there are uncommitted parent phases in the current phase, and sort by the ID of the parent phase
--val missing = getMissingParentStages(stage).sortBy(_.id)
//If the parent phase is not submitted, submit it in sequence, and finally submit yourself
--if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
// Create the corresponding Task according to the Stage type. When creating, it is determined according to the number of partitions to be calculated in the current Stage
// How do I know the number of partitions to be calculated for each Stage? Depends on the number of partitions of the last RDD in the Stage
--val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
//Put the task s of each Stage into the scheduling pool and notify the Driver to schedule
//Task set: contains all the Tasks of a Stage, a collection of Tasks
--taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
//Task setmanager: tracks the operation of all tasks in each TaskSet and restarts them when they fail. By delay scheduling
//Handle location sensitive scheduling and schedule each Task
--val manager = createTaskSetManager(taskSet, maxTaskFailures)
//Add TaskSetManager to FIFO | fair. Different scheduling pools will determine the scheduling priority of different tasksets
-- schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
-- backend.reviveOffers()
//Send a message to the Driver to tell the Driver that a new TaskSetManager has entered the pool and can start sending
-- driverEndpoint.send(ReviveOffers)
-- case ReviveOffers =>
makeOffers()