The most detailed big data ELK article series in the whole network. It is strongly recommended to collect and pay attention!
The new articles have listed the historical article directory to help you review the previous knowledge focus.
catalogue
3. Create an index to save position information
5. View all indexes in Elasticsearch
7. Specifies to use the IK word breaker
3. Add position information request
2. Perform the update operation
7, Retrieve the specified position data according to the ID
1. Use from and size for paging
Job search case of liepin.com
1, Demand
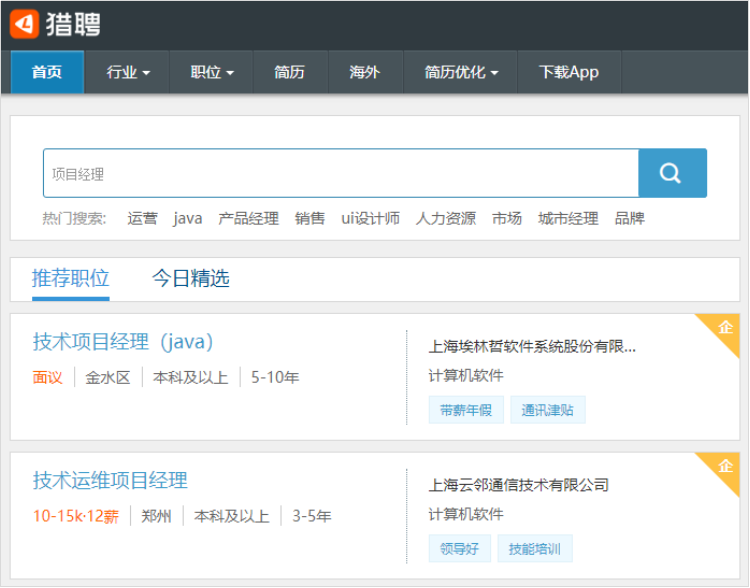
In this case, to realize a case similar to liepin.com, users can search relevant jobs by searching relevant job keywords. We have prepared some data in advance. These data are crawled by crawlers and stored in CSV text files. We need to build an index based on these data for users to search and query.
Data set introduction
| Field name | explain | data |
| doc_id | Unique identification (as document ID) | 29097 |
| area | Position area | Working area: Shenzhen Nanshan District |
| exp | Required working experience | 1 year experience |
| edu | Educational requirements | College degree or above |
| salary | salary range | ¥ 6-8000 / month |
| job_type | Position type (full-time / Part-time) | internship |
| cmp | Company name | Happy home |
| pv | Views | 616000 people have browsed it / 14 person evaluation / 113 people are watching |
| title | Post name | Taoyuan Shenda sales internship pre job training |
| jd | Job description | [salary] 7500 undergraduate salaries, 6800 junior college salaries, no performance requirements, and 55% ~ 80% of the performance accounting proportion, with a per capita monthly income of more than 13000 [Job Responsibilities] 1. Love to learn and be patient: be familiar with the basic real estate business and relevant legal and financial knowledge through the company's systematic training, and serve customers without utility, Patiently solve all kinds of problems encountered by customers in real estate transactions; 2. Be able to listen and ask questions: understand customers' core demands in detail, accurately match appropriate product information, have good communication skills with users, and have a sense of teamwork and service; 3. Love thinking, |
2, Create index
In order to search position data, we need to create an index in Elasticsearch in advance, and then we can retrieve keywords. Let's first review the process of creating tables in MySQL. In mysql, if we want to create a table, we need to specify the name of the table, the columns in the table and the type of columns. Similarly, in elastic search, indexes can be defined in a similar way.
1. Create index with mapping
In elastic search, we can use the RESTful API (http request) to perform various indexing operations. When creating a MySQL table, we use DDL to describe the table structure, fields, field types, constraints, etc. In Elasticsearch, we use the DSL of Elasticsearch to define -- using JSON to describe. For example:
PUT /my-index
{
"mapping": {
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
} 
2. Type of field
In elastic search, each field has a type. The following are the types that can be used in Elasticsearch:
| classification | Type name | explain |
| Simple type | text | The fields requiring full-text retrieval usually use text type to correspond to unstructured text data such as mail body, product description or short text. The word splitter will first segment the text and convert it into an entry list. In the future, it can be retrieved based on entries. Text fields cannot be sorted or aggregated by users. |
| keyword | Use keywords to correspond to structured data, such as ID, e-mail address, host name, status code, zip code, or label. You can use keyword to sort or aggregate calculations. Note: keyword cannot be segmented. | |
| date | Save formatted date data, such as 2015-01-01 or 2015 / 01 / 01 12:10:30. In elastic search, dates are displayed as strings. You can specify the format for date: "format": "yyyy MM DD HH: mm: SS" | |
| long/integer/short/byte | 64 bit integer / 32-bit integer / 16 bit integer / 8-bit integer | |
| double/float/half_float | 64 bit double precision floating point / 32-bit single precision floating point / 16 bit half progress floating point | |
| boolean | "true"/"false" | |
| ip | IPV4(192.168.1.110)/IPV6(192.168.0.0/16) | |
| JSON hierarchical nested types | object | Used to save JSON objects |
| nested | Used to save JSON arrays | |
| Special type | geo_point | Used to save latitude and longitude coordinates |
| geo_shape | Used to save polygon coordinates on the map |
3. Create an index to save position information
- Send PUT request using PUT
- The index name is / job_idx
- Whether to use text or keyword mainly depends on whether word segmentation is required
| field | type |
| area | text |
| exp | text |
| edu | keyword |
| salary | keyword |
| job_type | keyword |
| cmp | text |
| pv | keyword |
| title | text |
| jd | text |
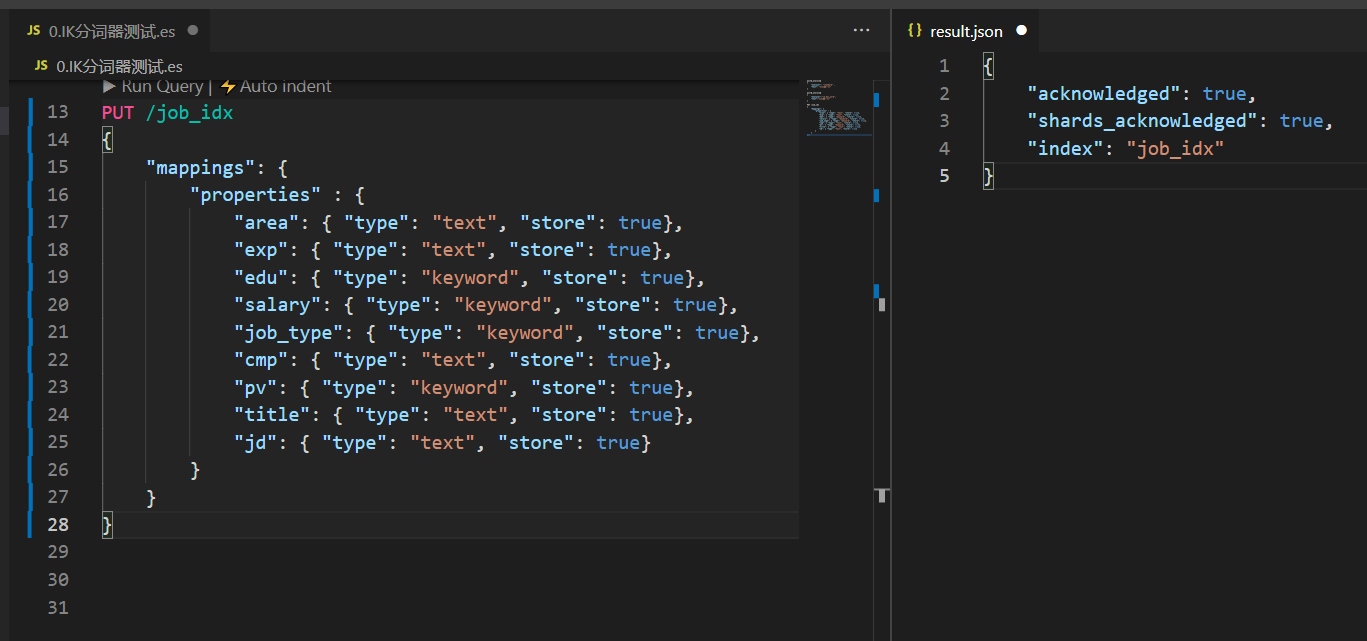
Create index:
PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true},
"exp": { "type": "text", "store": true},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true},
"jd": { "type": "text", "store": true}
}
}
}
4. View index mapping
View index mappings using GET requests
// View index mapping GET /job_idx/_mapping
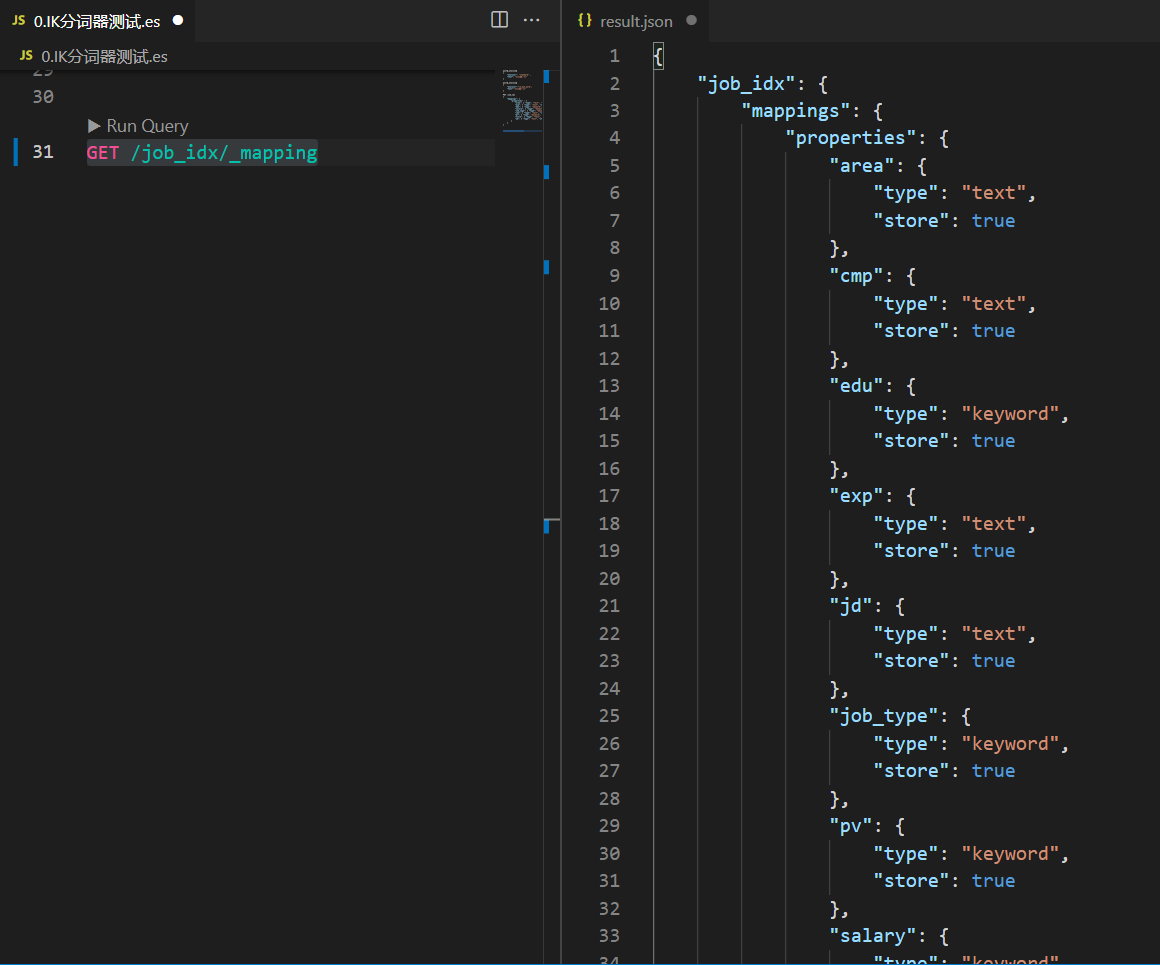
You can also view the index mapping information using the head plug-in
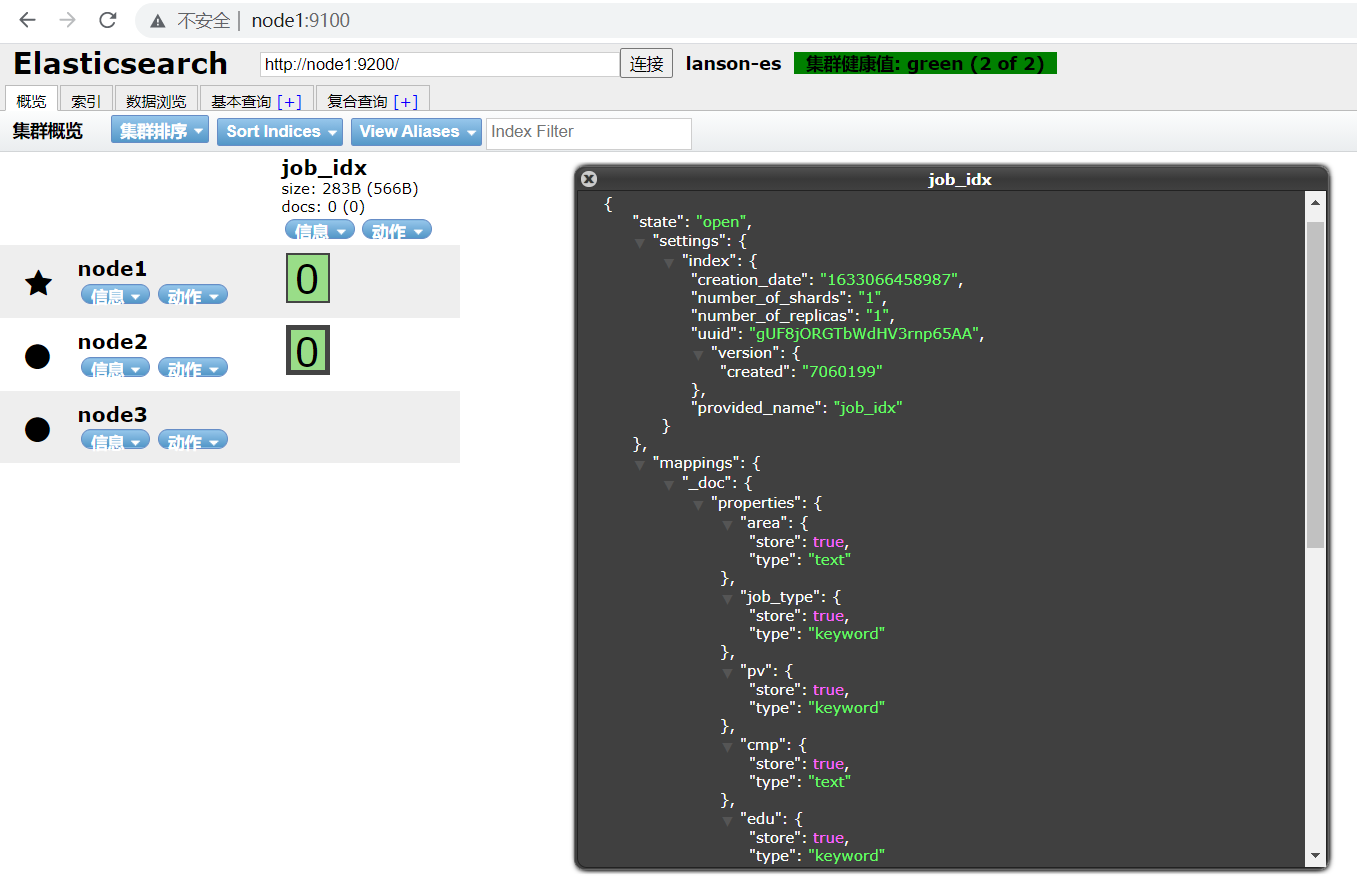
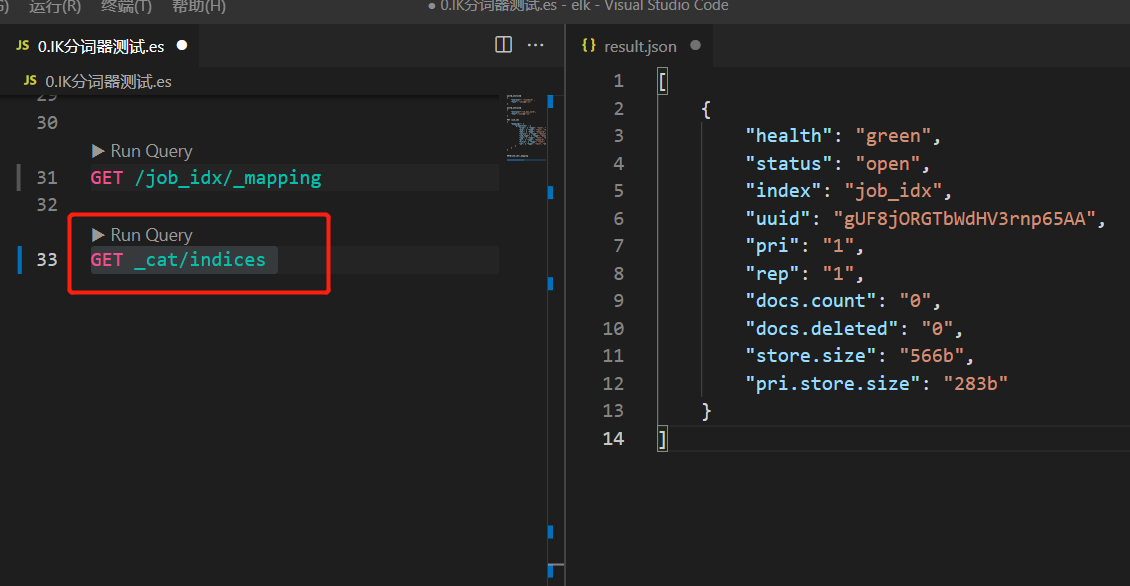
5. View all indexes in Elasticsearch
GET _cat/indices
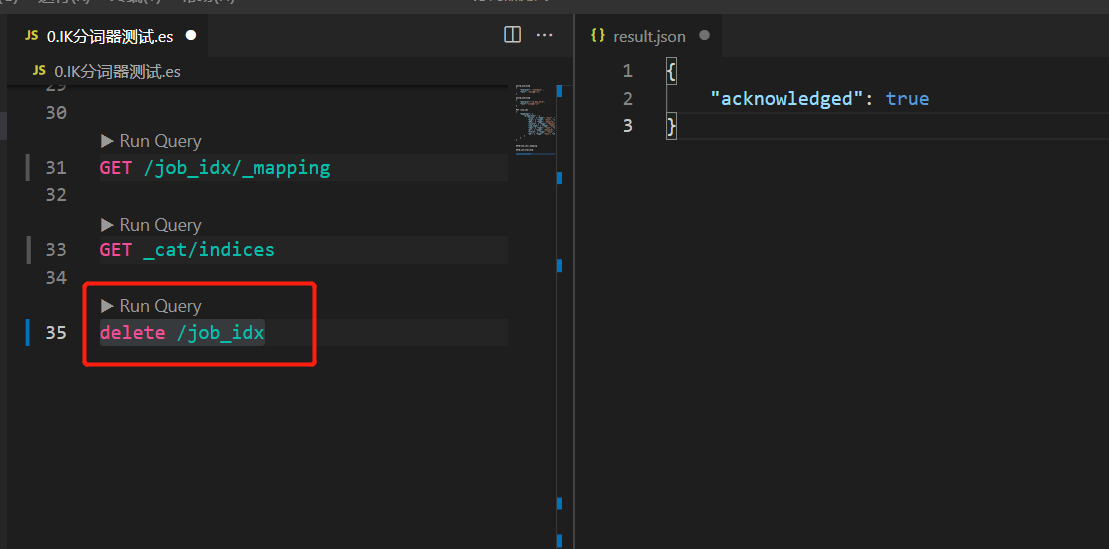
6. Delete index
delete /job_idx
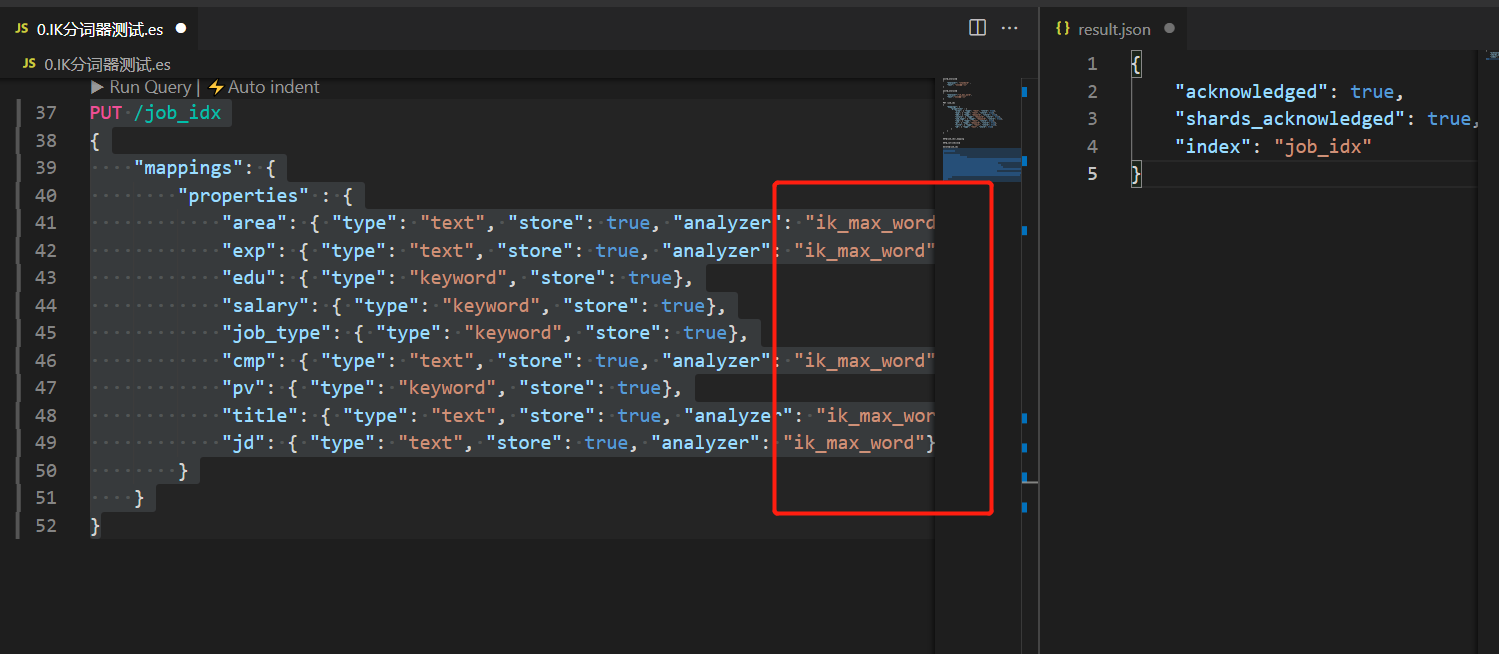
7. Specify to use IK word breaker
Because the data stored in the index database is stored in Chinese. Therefore, in order to have a better word segmentation effect, we need to use IK word splitter for word segmentation. In this way, the search will be more accurate in the future.
PUT /job_idx
{
"mappings": {
"properties" : {
"area": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"exp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"edu": { "type": "keyword", "store": true},
"salary": { "type": "keyword", "store": true},
"job_type": { "type": "keyword", "store": true},
"cmp": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"pv": { "type": "keyword", "store": true},
"title": { "type": "text", "store": true, "analyzer": "ik_max_word"},
"jd": { "type": "text", "store": true, "analyzer": "ik_max_word"}
}
}
}
III. add a position data
1. Demand
We now have a piece of position data that needs to be added to Elasticsearch, and we need to be able to search these data in Elasticsearch later.
| 29097, Working area: Shenzhen Nanshan District, 1 year experience, College degree or above, ¥ 6-8000 / month, internship, Happy home, 616000 people have browsed it / 14 person evaluation / 113 people are watching, Taoyuan Shenda sales internship pre job training, [salary] 7500 undergraduate salaries, 6800 junior college salaries, no performance requirements, and 55% ~ 80% of the performance accounting proportion, with a per capita monthly income of more than 13000 [Job Responsibilities] 1. Love to learn and be patient: be familiar with the basic real estate business and relevant legal and financial knowledge through the company's systematic training, and serve customers without utility, Patiently solve all kinds of problems encountered by customers in real estate transactions; 2. Be able to listen and ask questions: understand customers' core demands in detail, accurately match appropriate product information, have good communication skills with users, and have a sense of teamwork and service; 3. Pondering and Thinking: keen on user psychological research, good at refining user needs from user data, and using personalized and refined operation means to improve user experience. [job requirements] 1.18-26 years old, college degree or above; 2. Have good affinity, understanding, logical coordination and communication skills; 3. Be positive, optimistic and cheerful, be honest and trustworthy, work actively and pay attention to teamwork; 4. Willing to serve high-end customers, and willing to improve their comprehensive ability through face-to-face communication with high-end customers; 5. Willing to participate in public welfare activities, with love and gratitude. [training path] 1. Thousands of courses; Real estate knowledge, marketing knowledge, transaction knowledge, laws and regulations, customer maintenance, target management, negotiation skills, psychology and economics; 2. Growth companionship: one-to-one mentoring 3. Online self-learning platform: leyoujia college, produced by professional teams and shared by big coffee every week 4. Reserve and management classes: cadre training camp, monthly / quarterly management training [promotion and development] marketing [elite] development planning: A1 Property Consultant - A6 senior property expert marketing [management] development planning: (you can compete after the next month of employment) real estate consultant - Real Estate Manager - Store Manager - deputy general manager of marketing - vice president of marketing - President of marketing internal [competitive] company functional positions: such as market, channel development center, legal department, mortgage manager, etc. are all internal competitive [contact] Xiao Ming, who is in charge of 15888888888 (the same number of wechat) |
2. PUT request
We have created the index earlier. Next, we can add some documents to the index library. This operation can be completed directly through the PUT request. In Elasticsearch, each document has a unique ID. the data is also described in JSON format. For example:
PUT /customer/_doc/1
{
"name": "John Doe"
}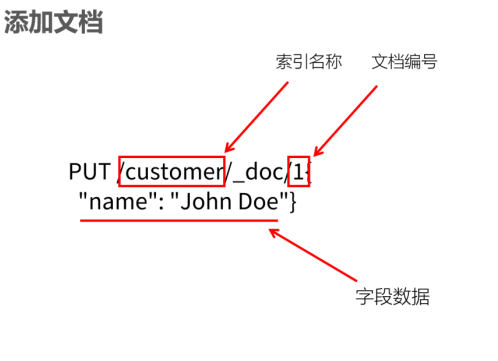
If there is no document with ID 1 in customer, Elasticsearch will automatically create it
3. Add position information request
PUT /job_idx/_doc/29097
{
"area": "Shenzhen-Nanshan District",
"exp": "1 Years of experience",
"edu": "College degree or above",
"salary": "6-8 thousand/month",
"job_type": "internship",
"cmp": "Happy home",
"pv": "61.6 Ten thousand people have browsed it / 14 Human evaluation / 113 People are paying attention",
"title": "Taoyuan Shenda sales internship pre job training",
"jd": "Salary] 7500 undergraduate salaries, 6800 junior college salaries, no performance requirements, and 55% of performance accounting%~80% Per capita monthly income exceeds 1.3 [Job Responsibilities] 1.Love to learn and be patient: be familiar with the basic business of real estate and relevant legal and financial knowledge through systematic training of the company, do not serve customers utilitarian, and be patient with various problems encountered by customers in real estate transactions; 2.Be able to listen and ask questions: understand customers' core demands in detail, accurately match appropriate product information, have good communication skills with users, and have a sense of teamwork and service; 3.Love thinking, good at thinking: Keen on user psychology research, good at refining user needs from user data, and using personalized and refined operation means to improve user experience. [job requirements] 1.18-26 One year old, college degree or above; 2.Have good affinity, understanding, logical coordination and communication skills; 3.Positive, optimistic and cheerful, honest and trustworthy, proactive, and pay attention to teamwork; 4.Willing to serve high-end customers, and willing to improve their comprehensive ability through face-to-face communication with high-end customers; 5.Willing to participate in public welfare activities, with love and gratitude. [training path] 1.Thousands of courses;Real estate knowledge, marketing knowledge, transaction knowledge, laws and regulations, customer maintenance, target management, negotiation skills, psychology and economics; 2.Growth companionship: one-on-one mentoring 3.Online independent learning platform: leyoujia college, produced by professional teams, and shared by big coffee 4 times a week.Reserve and management class: cadre training camp, monthly/Quarterly management training meeting [promotion and development] marketing [elite] development plan: A1 Property consultant -A6 Senior real estate expert marketing [management] development planning: (you can compete for employment after the next month) real estate consultant-Real estate manager-shopowner-Deputy general manager of marketing-Vice president of marketing-Marketing president internal [competition] company functional posts: such as market, channel development center, legal department, mortgage manager, etc. are internal competition for [contact] director Xiao Ming 15888888888 (same number on wechat)"
}Elasticsearch response result:
{
"_index": "job_idx",
"_type": "_doc",
"_id": "29097",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
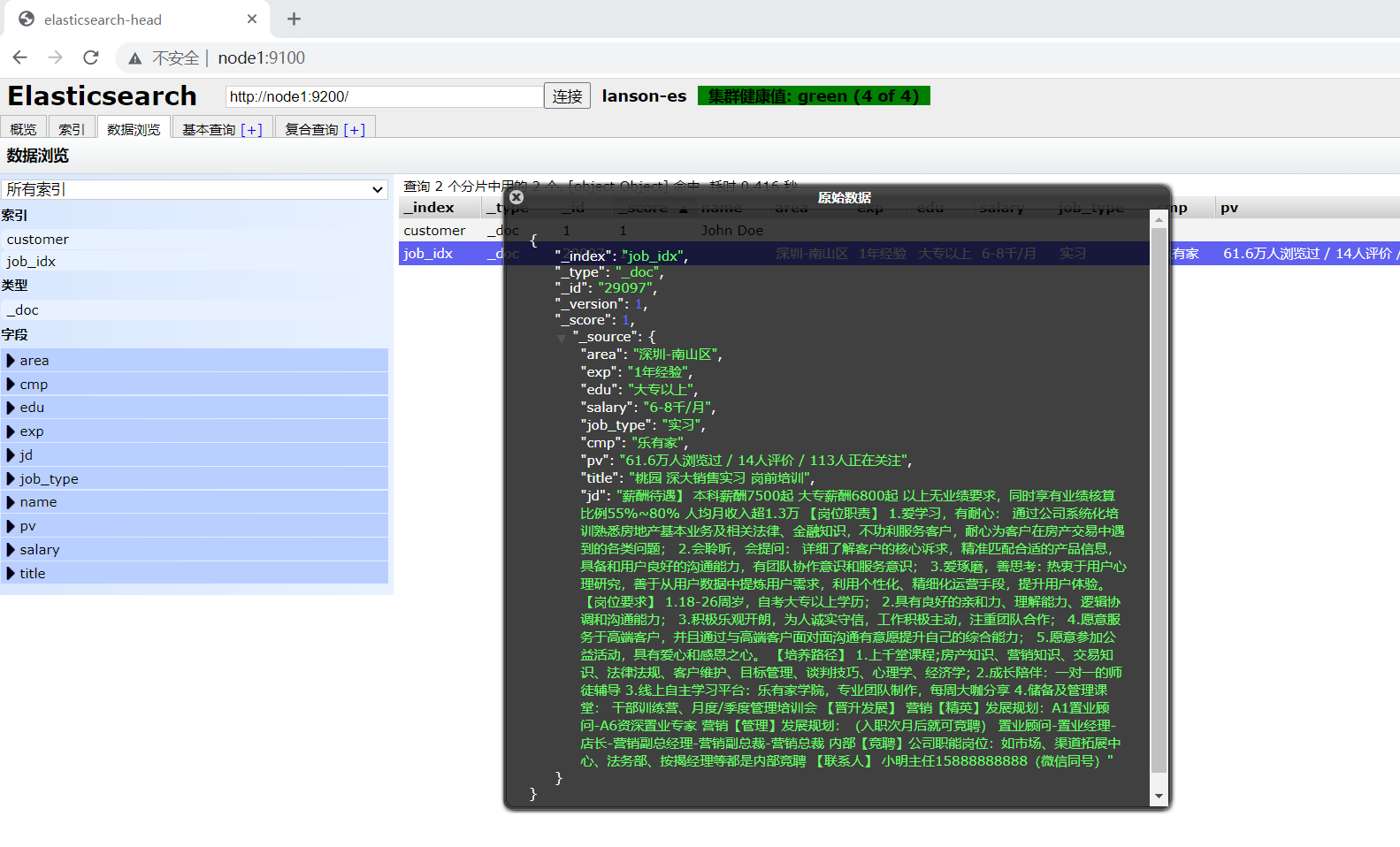
To browse data using the ES head plug-in:
4, Modify position salary
1. Demand
Because the company can't recruit people, the original salary of 6000-8000 / month needs to be changed to 15000-20000 / month
2. Perform the update operation
POST /job_idx/_update/29097
{
"doc": {
"salary": "15-20k/month"
}
}5, Delete a position data
1. Demand
The position with ID 29097 has been cancelled. Therefore, we need to delete the position in the index library.
2. DELETE operation
DELETE /job_idx/_doc/29097
6, Batch import JSON data
1. bulk import
In order to facilitate the following tests, we need to import some test data into ES in advance. There is a job_info.json data file in the data folder. We can use the bulk interface in Elasticsearch to import data.
- Upload JSON data files to Linux
- Execute Import command
curl -H "Content-Type: application/json" -XPOST "node1:9200/job_idx/_bulk?pretty&refresh" --data-binary "@job_info.json"
2. View index status
GET _cat/indices?index=job_idx
By executing the above request, Elasticsearch returns the following data:
[
{
"health": "green",
"status": "open",
"index": "job_idx",
"uuid": "LS0fkOS3SWGlOCp5u28yIA",
"pri": "1",
"rep": "1",
"docs.count": "6764",
"docs.deleted": "0",
"store.size": "23.2mb",
"pri.store.size": "11.6mb"
}
]
7, Retrieve the specified position data according to the ID
1. Demand
The user submits a document ID, and Elasticsearch returns the document corresponding to the ID directly to the user.
2. Realize
In elastic search, you can query documents by sending GET requests.

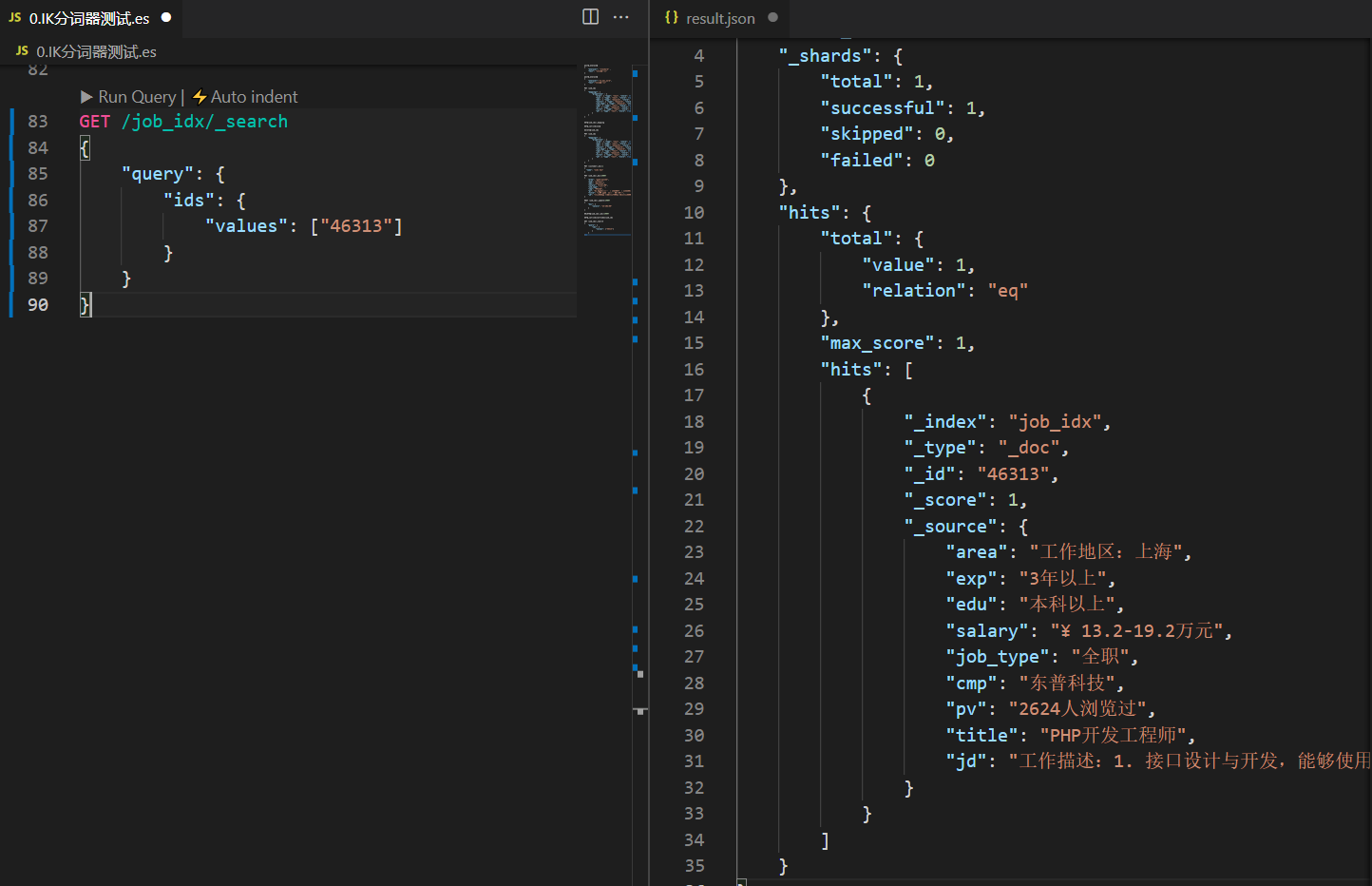
GET /job_idx/_search
{
"query": {
"ids": {
"values": ["46313"]
}
}
}
8, Search data by keyword
1. Demand
Search for positions with "sales" keyword in positions
2. Realize
Search jd for sales related positions
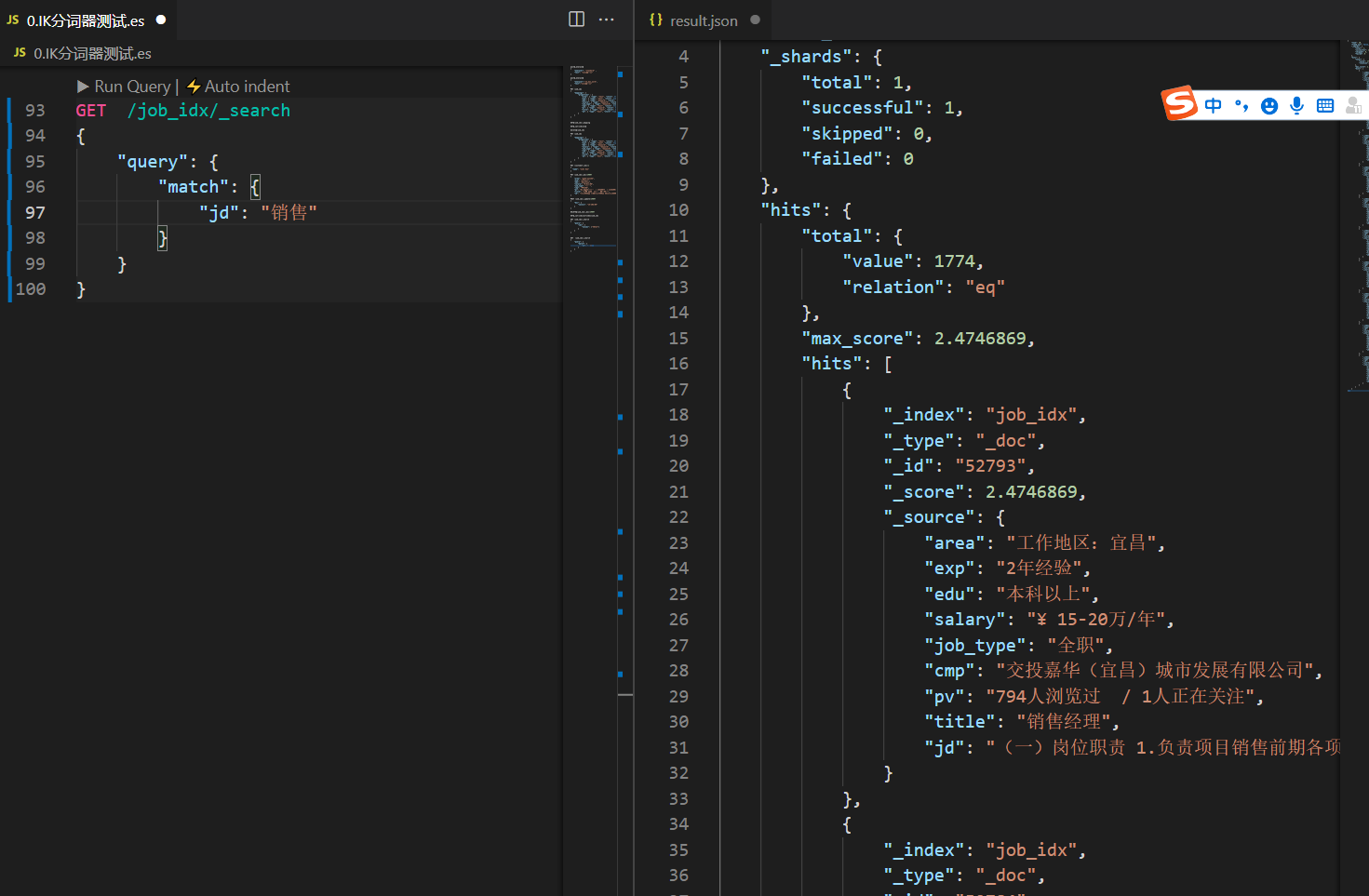
GET /job_idx/_search
{
"query": {
"match": {
"jd": "sale"
}
}
}
In addition to retrieving the position description field, we also need to retrieve the positions related to sales contained in the title. Therefore, we need to perform a combined query of multiple fields.
GET /job_idx/_search
{
"query": {
"multi_match": {
"query": "Overall planning of various materials in the early stage of sales",
"fields": [
"title",
"jd"
]
}
}
}More queries:
Official address: Start using elastic search | elastic videos
IX. pagination search according to keywords
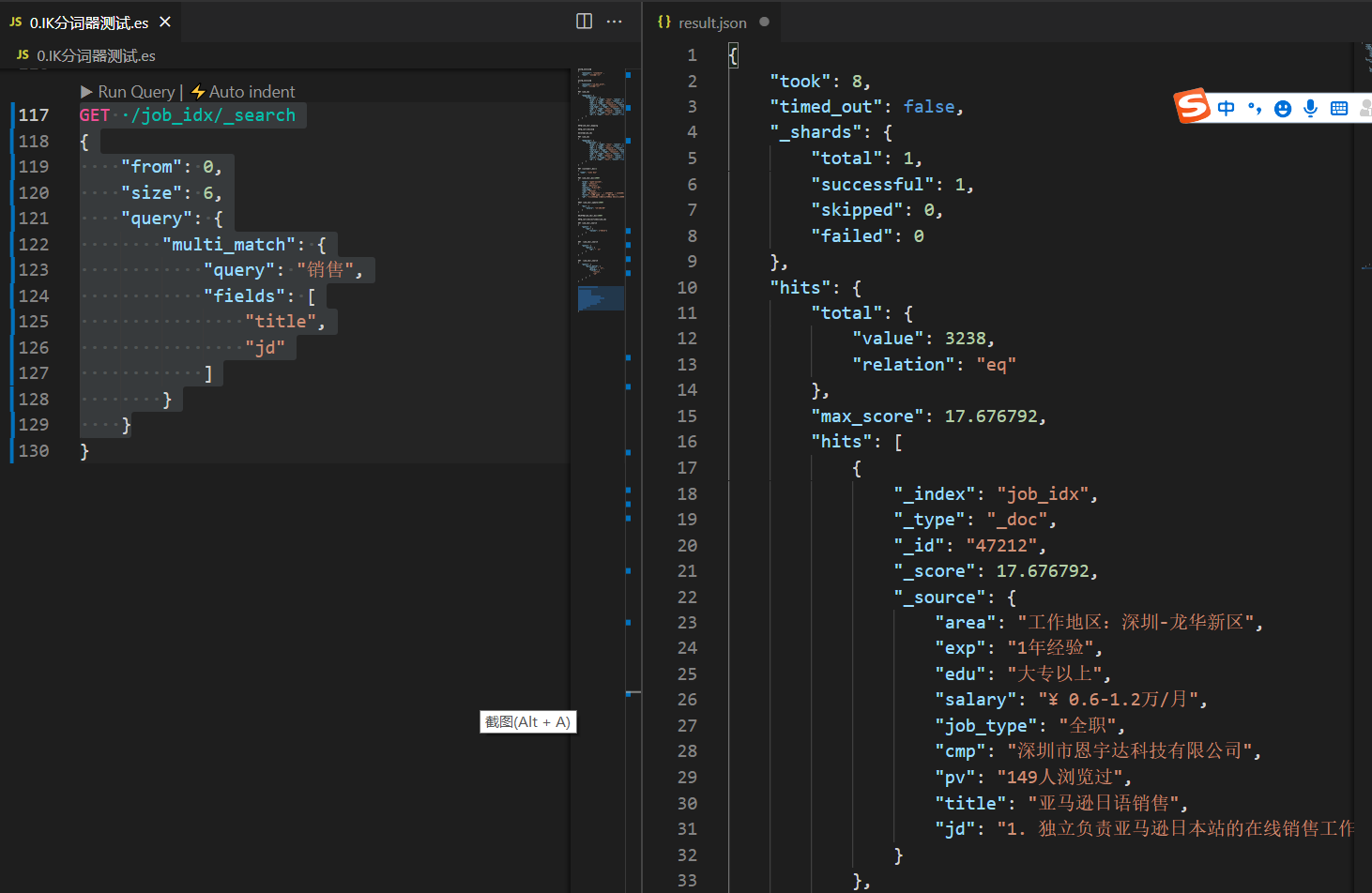
1. Use from and size for paging
When executing a query, you can specify from (from which data to start) and size (how many data to return per page) data to easily complete paging.
from = (page – 1) * size
GET /job_idx/_search
{
"from": 0,
"size": 6,
"query": {
"multi_match": {
"query": "sale",
"fields": [
"title",
"jd"
]
}
}
2. Paging using scroll mode
Using the from and size methods, it is OK to query within 1W-5W data. However, if there is a large amount of data, there will be performance problems. Elasticsearch makes a restriction that it is not allowed to query data after 10000 items. If you want to query data after 1W items, you need to use the scroll cursor provided in elasticsearch to query.
When a large number of pages are paged, each page needs to reorder the data to be queried, which is a waste of performance. Using scroll is to sort the data to be used at one time, and then take it out in batches. Performance is much better than from + size. After using the scroll query, the sorted data will remain for a certain period of time, and subsequent paging queries can take data from the snapshot.
1) use scroll paging query for the first time
Here, we keep the sorted data for 1 minute, so set the scroll to 1m
GET /job_idx/_search?scroll=1m
{
"query": {
"multi_match": {
"query": "sale",
"fields": ["title", "jd"]
}
},
"size": 100
}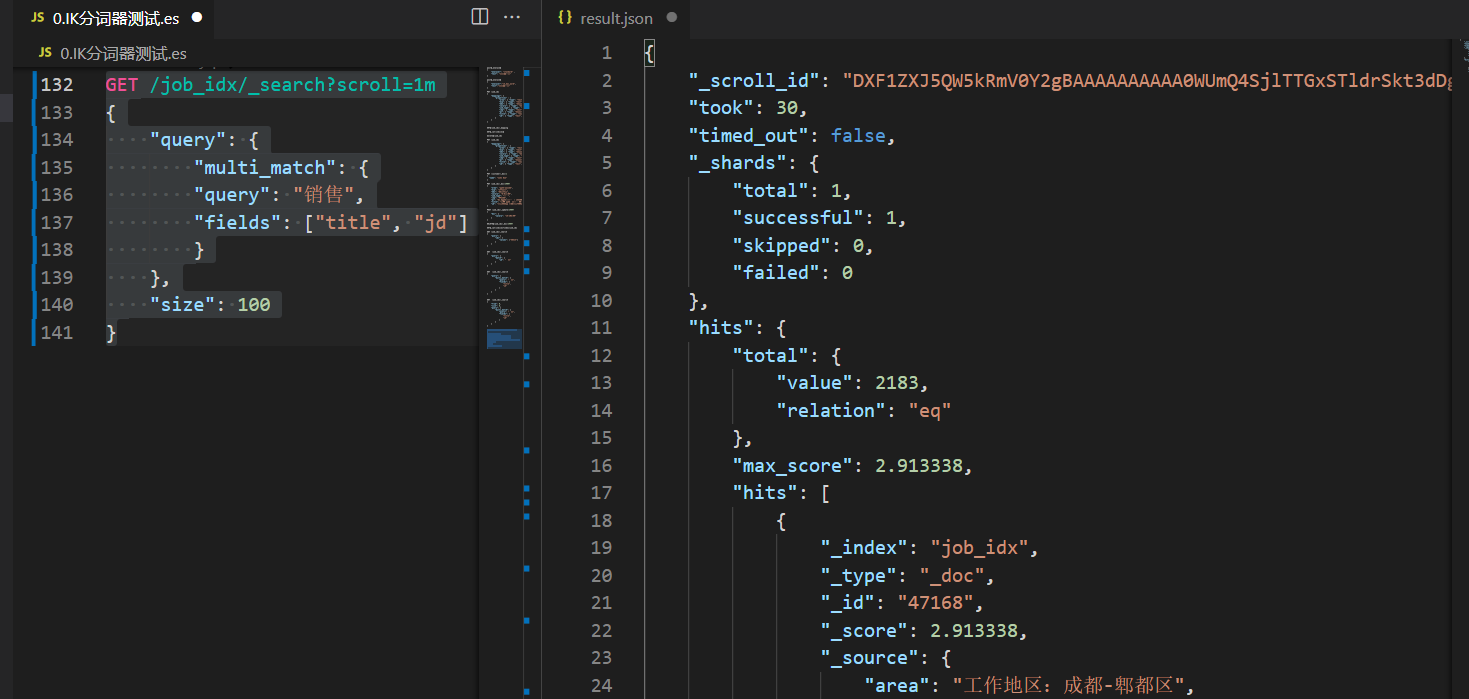
After execution, we noticed that there was one item in the response result:
"_scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAA0WUmQ4SjlTTGxSTldrSkt3dDg1eHRuQQ=="
In the follow-up, we need to according to this_ scroll_id to query
2) for the second time, directly use scroll id for query
GET _search/scroll?scroll=1m
{
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAA4WUmQ4SjlTTGxSTldrSkt3dDg1eHRuQQ=="
}
- 📢 Blog home page: https://lansonli.blog.csdn.net
- 📢 Welcome to praise 👍 Collection ⭐ Leaving a message. 📝 Please correct any errors!
- 📢 This article was originally written by Lansonli and started on CSDN blog 🙉
- 📢 Big data series articles will be updated every day. When you stop to rest, don't forget that others are still running. I hope you will seize the time to study and make every effort to go to a better life ✨