Big data engineering practice reference manual
vmtools installation still cannot copy and paste, and drag and drop files
Restart the virtual machine after executing the following commands in sequence
sudo apt-get autoremove open-vm-tools sudo apt-get install open-vm-tools sudo apt-get install open-vm-tools-desktop
ssh password free login
reference resources How to configure SSH secret free login for Ubuntu - unassigned microservices - blog Park (cnblogs.com)
First, check whether ssh is installed
sudo ps -e |grep ssh
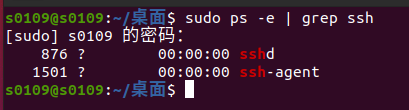
If there are two, ssh is installed. Otherwise, execute the following command to install ssh
sudo apt-get install openssh-server
It is recommended to delete the ssh directory first and reconfigure it
rm -r ~/.ssh
Execute the following command to generate the public key and private key, and then press enter
ssh-keygen -t rsa -P "" #Parameter Description: - t is the selected encryption algorithm, - P is the set password, and setting to "" indicates that no password is required
Add public key to authorize_keys file
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Finally, ssh connects to the local machine for testing. For the first connection, enter yes
ssh localhost perhaps ssh 127.0.0.1
Unable to init server: unable to connect
reference resources (97 messages) [error handling] Unable to init server: unable to connect: refuse to connect to _gloriiaaablog - CSDN blog
Use the following instructions
$ xhost local:gedit
If the following error is reported
xhost: unable to open display ""
Available instructions
$ export DISPLAY=:0
Then enter again
$ xhost local:gedit
If present
non-network local connections being added to access control list
This indicates that the modification was successful
hadoop installation
reference resources Hadoop3.1.3 installation tutorial_ Stand alone / pseudo distributed configuration_ Hadoop3.1.3/Ubuntu18.04(16.04)_ Xiamen University database lab blog (xmu.edu.cn) You can not create hadoop users
In addition to the pseudo distributed configuration in the above blog, please configure Hadoop env SH file
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
add to
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
Error Prevention
HBase installation
reference resources HBase2.2.2 installation and programming practice guide_ Xiamen University database lab blog (xmu.edu.cn)
python script
Modify the pabu to your user name, and create a data folder in advance. The script is saved in the data folder, such as / home / s0109 / data / click log
import random
import time
url_paths = ["class/112.html",
"class/128.html",
"class/145.html",
"class/146.html",
"class/500.html",
"class/250.html",
"class/131.html",
"class/130.html",
"class/271.html",
"class/127.html",
"learn/821",
"learn/823",
"learn/987",
"learn/500",
"course/list"]
ip_slices = [132, 156, 124, 10, 29, 167, 143, 187, 30, 46,
55, 63, 72, 87, 98, 168, 192, 134, 111, 54, 64, 110, 43]
http_referers = ["http://www.baidu.com/s?wd={query}", "https://www.sogou.com/web?query={query}",
"http://cn.bing.com/search?q={query}", "https://search.yahoo.com/search?p={query}", ]
search_keyword = ["Spark SQL actual combat", "Hadoop Basics", "Storm actual combat",
"Spark Streaming actual combat", "10 Hour entry big data", "SpringBoot actual combat", "Linux Advanced ", "Vue.js"]
status_codes = ["200", "404", "500", "403"]
def sample_url():
return random.sample(url_paths, 1)[0]
def sample_ip():
slice = random.sample(ip_slices, 4)
return ".".join([str(item) for item in slice])
def sample_referer():
if random.uniform(0, 1) > 0.5:
return "-"
refer_str = random.sample(http_referers, 1)
query_str = random.sample(search_keyword, 1)
return refer_str[0].format(query=query_str[0])
def sample_status_code():
return random.sample(status_codes, 1)[0]
def generate_log(count=10):
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
f = open("/home/s0109/data/click.log", "w+")
while count >= 1:
query_log = "{ip}\t{local_time}\t\"GET /{url} HTTP/1.1\"\t{status_code}\t{referer}".format(url=sample_url(
), ip=sample_ip(), referer=sample_referer(), status_code=sample_status_code(), local_time=time_str)
f.write(query_log + "\n")
count = count - 1
if __name__ == '__main__':
generate_log(100)
Set Ubuntu timer
crontab -e after creating a new task, it is recommended to select 2. If you have installed vim, select 1 and use the nano editor: ctrl+o to save and ctrl+x to exit. If you want to modify after selection, use the select editor command to select again
The path in the timer also needs to be changed to the corresponding path
Log data collection using Flume and Kafka
Pay attention to modifying the location of the log file for the configuration file
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-HAbucEfR-1640857591193)(E: \ file \ course \ junior college \ big data \ big data. assets\image-20211226150043176.png)]
exec-memory-kafka.sources = exec-source exec-memory-kafka.sinks = kafka-sink exec-memory-kafka.channels = memory-channel exec-memory-kafka.sources.exec-source.type = exec exec-memory-kafka.sources.exec-source.command = tail -F /home/s0109/data/click.log exec-memory-kafka.sources.exec-source.shell = /bin/sh -c exec-memory-kafka.channels.memory-channel.type = memory exec-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink exec-memory-kafka.sinks.kafka-sink.brokerList = localhost:9092 exec-memory-kafka.sinks.kafka-sink.topic = streamtopic exec-memory-kafka.sinks.kafka-sink.batchSize = 10 exec-memory-kafka.sinks.kafka-sink.requiredAcks = 1 exec-memory-kafka.sources.exec-source.channels = memory-channel exec-memory-kafka.sinks.kafka-sink.channel = memory-channel
When you start zookeeper and Kafka, you can add & after the command to make it run in the background
consumer failed to receive data
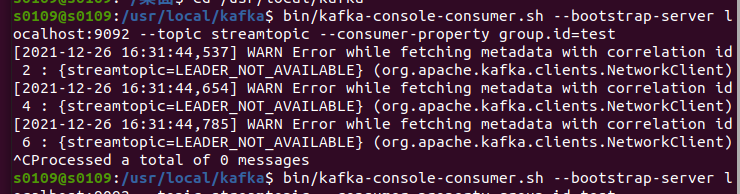
Check the Flume configuration file for errors
An error occurred while creating the Hbase table
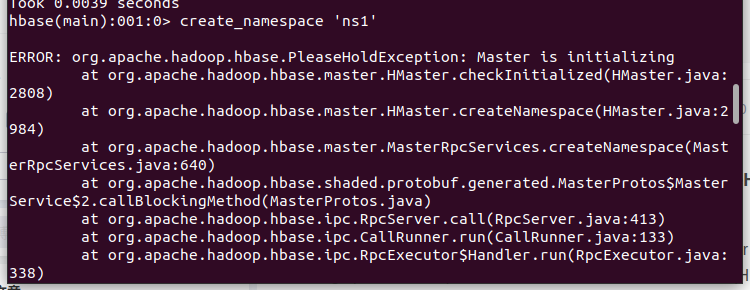
Restart hbase
stop-hbase.sh start-hbase.sh
After the restart, for example, execute the list command after the hbase shell command. It will not be created when it is stuck. Otherwise, continue to try to restart
Building back-end projects
Note: before executing all the codes for HBase operations from this step, please save the virtual machine snapshot. After executing the error code, the HBase environment will crash!!!
Installing Intellij
reference resources (98 messages) Ubuntu 20 04 install idea2020 2 ide detailed tutorial_ liutao43 blog - CSDN blog_ Ubuntu 20 installation idea Modify the corresponding command to the version you downloaded
Simply put, it is 2 steps, decompressing and running
sudo tar -zxvf ideaIU-2020.2.3.tar.gz -C /opt #/opt can be changed to the location you want to unzip. The compressed package can be changed to the version you downloaded. Before unzipping, you need to enter the location where the compressed package is downloaded /opt/ideaIU-2020.2.3/bin/idea.sh
After installation, select Plugin and search for scala installation plug-ins. The download speed is slow and wait patiently
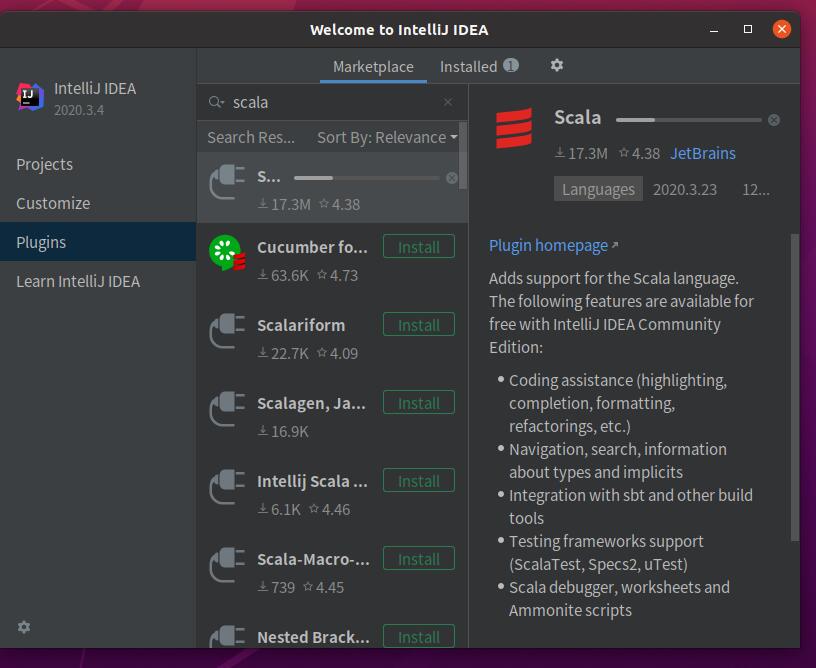
The reference of the old version
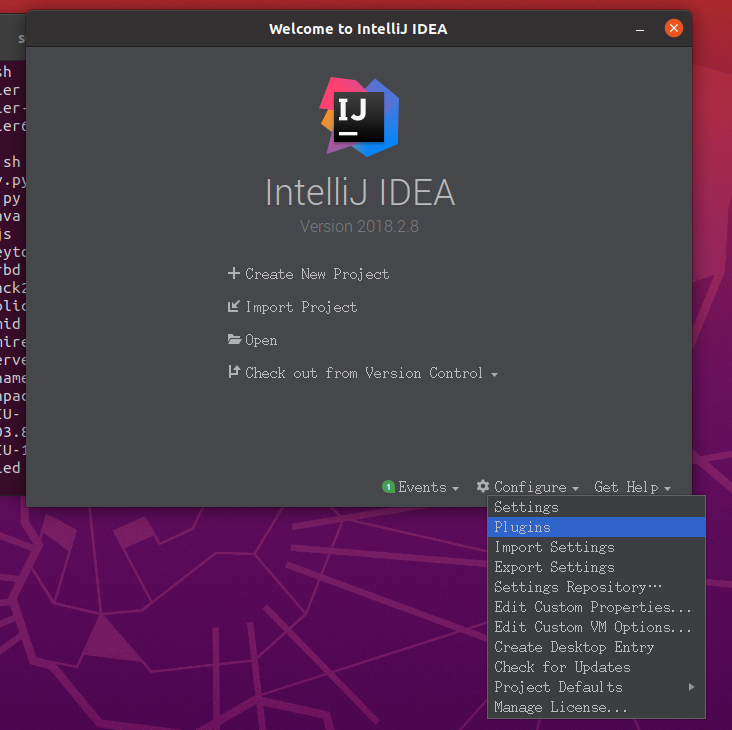
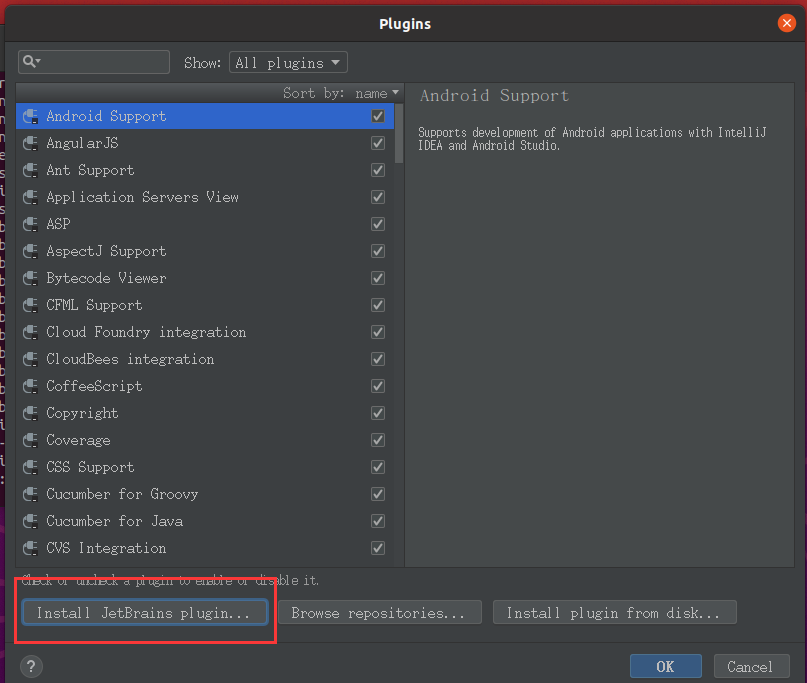
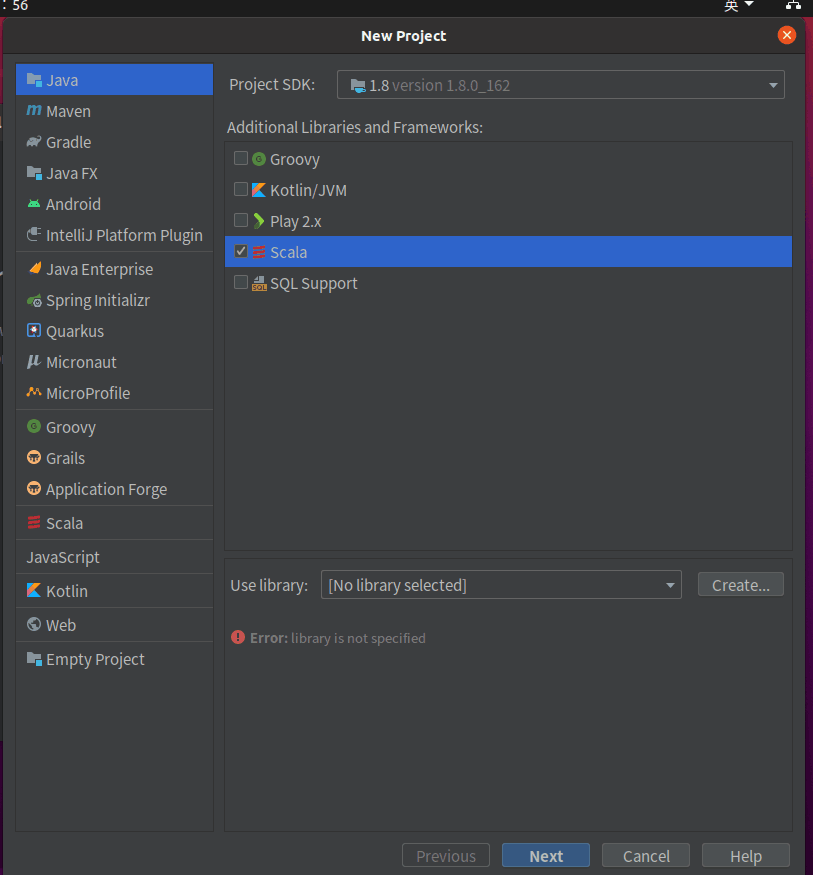
Then Create the project, select Scala and click Create
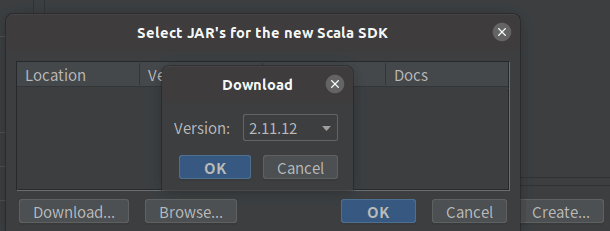
Select 2.11 12. Download. Wait patiently. The download is extremely slow, but it is only 40 mb files. If it is too slow, find an offline installation method yourself
When setting up the maven environment, the repository does not exist and is created by itself
code
rely on
<repositories>
<repository>
<id>alimaven</id>
<name>Maven Aliyun Mirror</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>
<releases> <enabled>true</enabled> </releases>
<snapshots> <enabled>false</enabled> </snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version> </dependency>
<dependency> <groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.5.1</version>
</dependency>
<dependency> <groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.2</version>
</dependency>
<dependency> <groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-scala_2.11</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>net.jpountz.lz4</groupId>
<artifactId>lz4</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.6</version>
</dependency>
</dependencies>
After filling in the old version, click Enable Auto Import to update it
HBaseUtils
Note that zk service parameters should be modified to replace the contents in s0109 below with your account
package com.spark.streaming.project.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HTable;
public class HBaseUtils {
private Configuration configuration = null;
private Connection connection = null;
private static HBaseUtils instance = null;
private HBaseUtils(){
try {
configuration = new Configuration();
//Specify the zk server to access
configuration.set("hbase.zookeeper.quorum", "s0109:2181");
// Get Hbase connection
connection = ConnectionFactory.createConnection(configuration);
}catch(Exception e){
e.printStackTrace();
}
}
/**
* Get HBase connection instance
*/
public static synchronized HBaseUtils getInstance(){
if(instance == null){
instance = new HBaseUtils();
}
return instance;
}
/**
*Get an instance of a table from the table name
* @param tableName
* @return
*/
public HTable getTable(String tableName) {
HTable hTable = null;
try {
hTable = (HTable)connection.getTable(TableName.valueOf(tableName));
}catch (Exception e){
e.printStackTrace();
}
return hTable;
}
}
DateUtils
package com.spark.streaming.project.utils
import org.apache.commons.lang3.time.FastDateFormat
/**
* Format date tool class
*/
object DateUtils {
//Specifies the date format to enter
val YYYYMMDDHMMSS_FORMAT = FastDateFormat.getInstance("yyyy-MM-dd hh:mm:ss");
//Specify output format
val TARGET_FORMAT = FastDateFormat.getInstance("yyyyMMddhhmmss")
// Enter String to return the result converted to log in this format
def getTime(time: String) = {
YYYYMMDDHMMSS_FORMAT.parse(time).getTime
}
def parseToMinute(time: String) = {
//Call getTime
TARGET_FORMAT.format(getTime(time))
}
}
CourseClickCountDao
package com.spark.streaming.project.dao
import com.spark.streaming.project.domain.CourseClickCount
import com.spark.streaming.project.utils.HBaseUtils
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
object CourseClickCountDao {
val tableName = "ns1:courses_clickcount" //Table name
val cf = "info" //Column family
val qualifer = "click_count" //column
/**
* Save data to Hbase
* @param list (day_course:String,click_count:Int) //Count the total hits of each course on the same day
*/
def save(list: ListBuffer[CourseClickCount]): Unit = {
//Call the method of HBaseUtils to obtain the HBase table instance
val table = HBaseUtils.getInstance().getTable(tableName)
for (item <- list) {
//Call a self increasing method of Hbase
table.incrementColumnValue(Bytes.toBytes(item.day_course),
Bytes.toBytes(cf), Bytes.toBytes(qualifer),
item.click_count) //If the value is Long, it will be automatically converted
}
}
}
CourseSearchClickCountDao
package com.spark.streaming.project.dao
import com.spark.streaming.project.domain.CourseSearchClickCount
import com.spark.streaming.project.utils.HBaseUtils
import org.apache.hadoop.hbase.util.Bytes
import scala.collection.mutable.ListBuffer
object CourseSearchClickCountDao {
val tableName = "ns1:courses_search_clickcount"
val cf = "info"
val qualifer = "click_count"
/**
* Save data to Hbase
* @param list (day_course:String,click_count:Int) //Count the total hits of each course on the same day
*/
def save(list: ListBuffer[CourseSearchClickCount]): Unit = {
val table = HBaseUtils.getInstance().getTable(tableName)
for (item <- list) {
table.incrementColumnValue(Bytes.toBytes(item.day_serach_course),
Bytes.toBytes(cf), Bytes.toBytes(qualifer),
item.click_count
) //If the value is Long, it will be automatically converted
}
}
}
CountByStreaming
package com.spark.streaming.project.application
import com.spark.streaming.project.domain.ClickLog
import com.spark.streaming.project.domain.CourseClickCount
import com.spark.streaming.project.domain.CourseSearchClickCount
import com.spark.streaming.project.utils.DateUtils
import com.spark.streaming.project.dao.CourseClickCountDao
import com.spark.streaming.project.dao.CourseSearchClickCountDao
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.ListBuffer
object CountByStreaming {
def main(args: Array[String]): Unit = {
/**
* Finally, the program will be packaged and run on the cluster,
* Several parameters need to be received: the ip address of the zookeeper server, the kafka consumption group,
* Topic, and number of threads
*/
if (args.length != 4) {
System.err.println("Error:you need to input:<zookeeper> <group> <toplics> <threadNum>")
System.exit(1)
}
//Receive the parameters of the main function and pass the parameters outside
val Array(zkAdderss, group, toplics, threadNum) = args
/**
* When creating Spark context, you need to set AppName for local operation
* Master And other attributes, which need to be deleted before packaging on the cluster
*/
val sparkConf = new SparkConf()
.setAppName("CountByStreaming")
.setMaster("local[4]")
//Create a Spark discrete stream and receive data every 60 seconds
val ssc = new StreamingContext(sparkConf, Seconds(60))
//Using kafka as the data source
val topicsMap = toplics.split(",").map((_, threadNum.toInt)).toMap
//Create a kafka discrete stream and consume the data of the kafka cluster every 60 seconds
val kafkaInputDS = KafkaUtils.createStream(ssc, zkAdderss, group, topicsMap)
//Get the original log data
val logResourcesDS = kafkaInputDS.map(_._2)
/**
* (1)Clean the data and package it into ClickLog
* (2)Filter out illegal data
*/
val cleanDataRDD = logResourcesDS.map(line => {
val splits = line.split("\t")
if (splits.length != 5) {
//Illegal data is directly encapsulated and given an error value by default, and the filter will filter it
ClickLog("", "", 0, 0, "")
}
else {
val ip = splits(0) //Get the ip address of the user in the log
val time = DateUtils.parseToMinute(splits(1)) //Obtain the access time of the user in the log and call DateUtils to format the time
val status = splits(3).toInt //Get access status code
val referer = splits(4)
val url = splits(2).split(" ")(1) //Get search url
var courseId = 0
if (url.startsWith("/class")) {
val courseIdHtml = url.split("/")(2)
courseId = courseIdHtml.substring(0, courseIdHtml.lastIndexOf(".")).toInt
}
ClickLog(ip, time, courseId, status, referer) //Encapsulate the cleaned log into ClickLog
}
}).filter(x => x.courseId != 0) //Filter out non practical courses
/**
* (1)statistical data
* (2)Write the calculation results into HBase
*/
cleanDataRDD.map(line => {
//This is equivalent to defining the RowKey of the HBase table "ns1:courses_clickcount",
// Set 'date'_ Course 'as a RowKey means the number of visits to a course on a certain day
(line.time.substring(0, 8) + "_" + line.courseId, 1) //Map to tuple
}).reduceByKey(_ + _) //polymerization
.foreachRDD(rdd => { //There are multiple RDD S in a DStream
rdd.foreachPartition(partition => { //There are multiple partitions in an RDD
val list = new ListBuffer[CourseClickCount]
partition.foreach(item => { //There are multiple records in a Partition
list.append(CourseClickCount(item._1, item._2))
})
CourseClickCountDao.save(list) //Save to HBase
})
})
/**
* Count the total hits of practical courses from various search engines so far
* (1)statistical data
* (2)Write the statistical results into HBase
*/
cleanDataRDD.map(line => {
val referer = line.referer
val time = line.time.substring(0, 8)
var url = ""
if (referer == "-") { //Filter illegal URLs
(url, time)
}
else {
//Take out the name of the search engine
url = referer.replaceAll("//", "/").split("/")(1)
(url, time)
}
}).filter(x => x._1 != "").map(line => {
//This is equivalent to defining the RowKey of the HBase table "ns1:courses_search_clickcount",
// Will 'date_ Search engine name 'as RowKey means the number of times a course is accessed through a search engine on a certain day
(line._2 + "_" + line._1, 1) //Map to tuple
}).reduceByKey(_ + _) //polymerization
.foreachRDD(rdd => {
rdd.foreachPartition(partition => {
val list = new ListBuffer[CourseSearchClickCount]
partition.foreach(item => {
list.append(CourseSearchClickCount(item._1, item._2))
})
CourseSearchClickCountDao.save(list)
})
})
ssc.start()
ssc.awaitTermination()
}
}
Running environment configuration
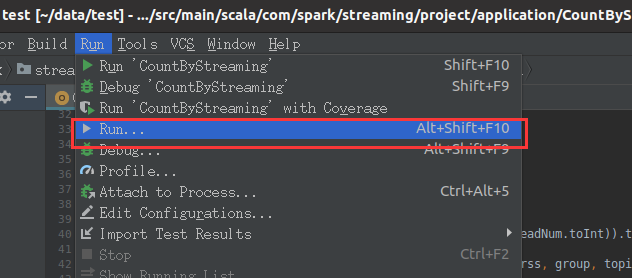
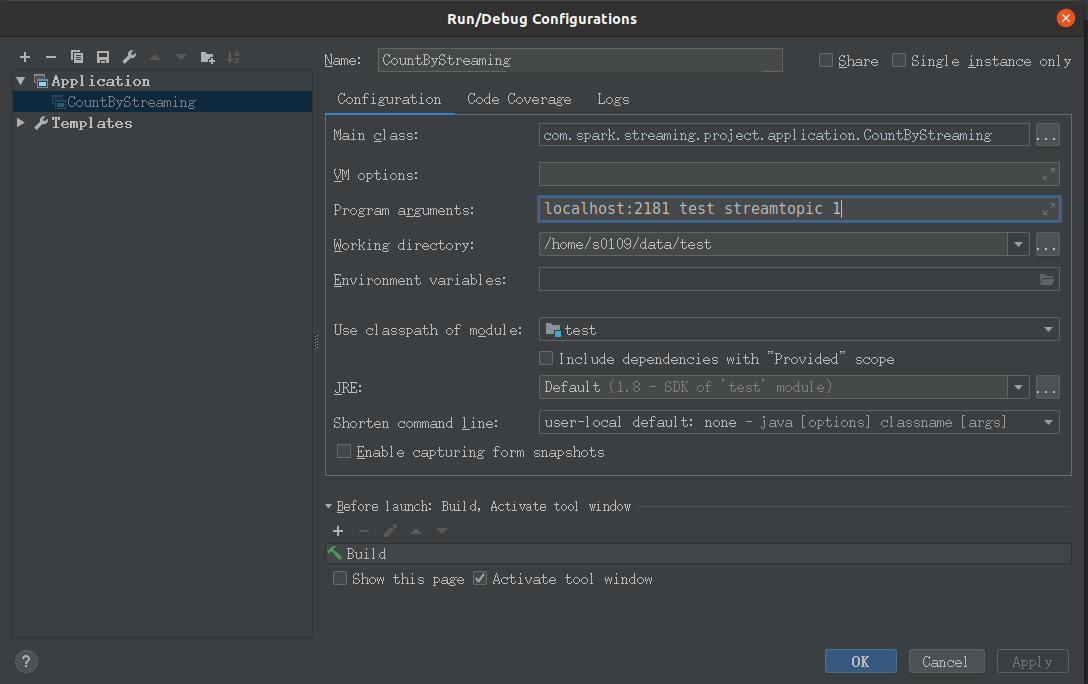
First click run, a pop-up box will pop up, select CountByStreaming, select the one without $, then refer to the environment configuration in pdf, and fill in the parameters in Program arguments
Build front end projects
to configure
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency> <dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<classifier>jdk15</classifier>
<version>2.4</version> </dependency>
<dependency> <groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.78</version>
</dependency> <dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version> </dependency>
</dependencies>
Unable to connect to mysql
First of all, make sure that you have the database spark in your mysql
ERROR: 1
Similar errors may be reported in different versions

Reason: mysql was not started on port 3306
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf take skip-grant-tables notes
ERROR: 2

jdbc version incompatible
If mysql executes the command on pdf without specifying the version, go to the official website to download the latest version of jdbc for reference( MySQL_ JDBC_ Download and use of jar package (Windows) - desolate and warm - blog Garden (cnblogs.com))
code
testSQL
**Note: * * modify the time in the testHbase() code to the time when you execute the back-end code. For example, 20211001 is changed to 20211229. Before execution, please take a snapshot of the virtual machine and check whether the zookeeper server address in the HBaseUtils file is correct
import com.test.utils.HBaseUtils;
import com.test.utils.JdbcUtils;
import org.junit.Test;
import java.sql.*;
import java.util.Map;
public class testSQL {
@Test
public void testjdbc() throws ClassNotFoundException {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/spark";
String username = "root";
String password = "root";
try {
Connection conn = DriverManager.getConnection(url, username,
password);
Statement stmt = conn.createStatement();
ResultSet res = stmt.executeQuery("select * from course");
while (res.next())
System.out.println(res.getString(1)+" "+res.getString(2));
conn.close();
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
@Test
public void testJdbcUtils() throws ClassNotFoundException {
System.out.println(JdbcUtils.getInstance().getCourseName("128"));
System.out.println(JdbcUtils.getInstance().getCourseName("112"));
}
@Test
public void testHbase() {
Map<String,Long>clickCount=HBaseUtils.getInstance().getClickCount("ns1:courses_clickcount", "20211001");
for (String x : clickCount.keySet())
System.out.println(x + " " +clickCount.get(x));
}
}
JdbcUtils
package com.test.utils;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashMap;
import java.util.Map;
public class JdbcUtils {
private Connection connection = null;
private static JdbcUtils jdbcUtils = null;
Statement stmt = null;
private JdbcUtils() throws ClassNotFoundException {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/spark?useSSL=false";
String username = "root";
String password = "root";
try {
connection = DriverManager.getConnection(url, username, password);
stmt = connection.createStatement();
}catch (Exception e){
e.printStackTrace();
}
}
/**
* Get JdbcUtil instance
* @return
*/
public static synchronized JdbcUtils getInstance() throws
ClassNotFoundException {
if(jdbcUtils == null){
jdbcUtils = new JdbcUtils();
}
return jdbcUtils;
}
/**
* Get the course name according to the course id
*/
public String getCourseName(String id){
try {
ResultSet res = stmt.executeQuery("select * from course where id =\'" + id + "\'");
while (res.next())
return res.getString(2);
}catch (Exception e){
e.printStackTrace();
}
return null;
}
/**
* Query statistics results by date
*/
public Map<String,Long> getClickCount(String tableName, String date){
Map<String,Long> map = new HashMap<String, Long>();
try {
}catch (Exception e){
e.printStackTrace();
return null;
}
return map;
}
}
HBaseUtils
Note that change the locahost in the zookeeper server address to your user name
package com.test.utils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.PrefixFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.util.HashMap;
import java.util.Map;
public class HBaseUtils {
private Configuration configuration = null;
private Connection connection = null;
private static HBaseUtils hBaseUtil = null;
private HBaseUtils(){
try {
configuration = new Configuration();
//The address of the zookeeper server
configuration.set("hbase.zookeeper.quorum","localhost:2181");
connection = ConnectionFactory.createConnection(configuration);
}catch (Exception e){
e.printStackTrace();
}
}
/**
* Get HBaseUtil instance
* @return
*/
public static synchronized HBaseUtils getInstance(){
if(hBaseUtil == null){
hBaseUtil = new HBaseUtils();
}
return hBaseUtil;
}
/**
* Get table objects from table names
*/
public HTable getTable(String tableName){
try {
HTable table = null;
table = (HTable)connection.getTable(TableName.valueOf(tableName));
return table;
}catch (Exception e){
e.printStackTrace();
}
return null;
}
/**
* Query statistics results by date
*/
public Map<String,Long> getClickCount(String tableName, String date){
Map<String,Long> map = new HashMap<String, Long>();
try {
//Get table instance
HTable table = getInstance().getTable(tableName);
//Column family
String cf = "info";
//column
String qualifier = "click_count";
//Define a scanner prefix filter to scan only row s of a given date
Filter filter = new PrefixFilter(Bytes.toBytes(date));
//Define scanner
Scan scan = new Scan();
scan.setFilter(filter);
ResultScanner results = table.getScanner(scan);
for(Result result:results){
//Remove rowKey
String rowKey = Bytes.toString(result.getRow());
//Take out hits
Long clickCount =
Bytes.toLong(result.getValue(cf.getBytes(),qualifier.getBytes()));
map.put(rowKey,clickCount);
}
}catch (Exception e){
e.printStackTrace();
return null;
}
return map;
}
}
Mysql data
Use the shell command to log in to mysql and execute
use spark; DROP TABLE IF EXISTS `course`; CREATE TABLE `course` ( `id` int NOT NULL, `course` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; INSERT INTO `course` VALUES (112, 'Spark'); INSERT INTO `course` VALUES (127, 'HBase'); INSERT INTO `course` VALUES (128, 'Flink'); INSERT INTO `course` VALUES (130, 'Hadoop'); INSERT INTO `course` VALUES (145, 'Linux'); INSERT INTO `course` VALUES (146, 'Python');
The later tutorial is gone. Do it yourself
t.getValue(cf.getBytes(),qualifier.getBytes()));
map.put(rowKey,clickCount);
}
}catch (Exception e){
e.printStackTrace();
return null;
}
return map;
}
}
### Mysql data use shell Command login mysql Post execution ```sql use spark; DROP TABLE IF EXISTS `course`; CREATE TABLE `course` ( `id` int NOT NULL, `course` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; INSERT INTO `course` VALUES (112, 'Spark'); INSERT INTO `course` VALUES (127, 'HBase'); INSERT INTO `course` VALUES (128, 'Flink'); INSERT INTO `course` VALUES (130, 'Hadoop'); INSERT INTO `course` VALUES (145, 'Linux'); INSERT INTO `course` VALUES (146, 'Python');
The later tutorial is gone. Do it yourself