| On the right side of the page, there is a directory index, which can jump to the content you want to see according to the title |
|---|
| If not on the right, look for the left |
| Main article link https://blog.csdn.net/grd_java/article/details/115639179 |
|---|
| Chapter I: environmental construction https://blog.csdn.net/grd_java/article/details/115693312 |
If you haven't built the environment yet, please refer to Chapter 1: environment construction. Of course, if you don't build it, you can also learn by looking at the pictures
| Statement: This article is to learn from Hadoop 3 Study notes of 1. X course |
|---|
| Shang Silicon Valley video resource address: https://www.bilibili.com/video/BV1Qp4y1n7EN?p=34&spm_id_from=pageDriver |
1, Overview
1. Background and definition of HDFS
HDFS generation background
- With the increasing amount of data, if there is not enough data in one operating system, it will be allocated to more disks managed by the operating system, but it is inconvenient to manage and maintain. There is an urgent need for a system to manage the files on multiple machines, which is the distributed file management system. HDFS is just one kind of distributed file management system.
HDFS definition
- A file system for storing files and locating files through the directory tree; Secondly, it is distributed, and many servers unite to realize its functions. The servers in the cluster have their own roles.
Applicable scenario
- It is suitable for the scene of writing once and reading many times. After a file is created, written and closed, it does not need to be changed. The only change is to add and delete content, and the stored file cannot be modified
2. Advantages and disadvantages
advantage
- High fault tolerance
- Suitable for handling big data
- Data scale: it can handle data with data scale of GB, TB or even PB
- File size: it can handle a large number of files with a size of more than one million
- It can be built on cheap machines and improve reliability through multi copy mechanism
shortcoming
- It is not suitable for low latency data access, such as millisecond data storage
- Unable to efficiently store a large number of small files
- If a large number of small files are stored, it will occupy a lot of memory of NameNode to store file directory and block information. This is not desirable because NameNode memory is always limited
- The addressing time of small file storage will exceed the reading time, which violates the design goal of HDFS
- Concurrent writing and random file modification are not supported
- A file can only have one write, and multiple threads are not allowed to write at the same time
- Only data append is supported, and random modification of files is not supported
3. Composition
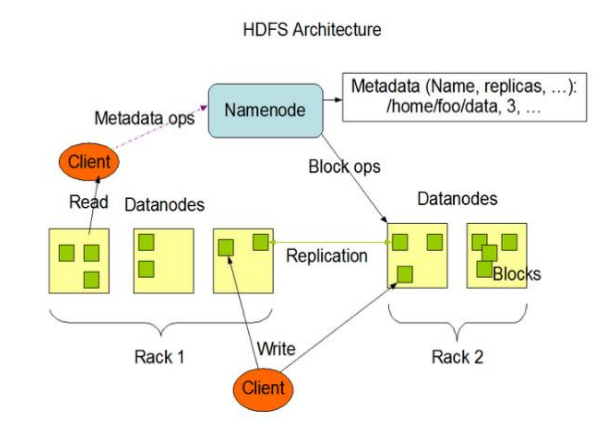
- NameNode (nn): Master, which is a supervisor and manager
- Manage the name space of HDFS, where all file metadata exists (such as file name)
- Configure copy policy (record how many copies each file has)
- Manage data Block mapping information (a large file is usually divided into multiple data blocks, which are uniformly managed by NameNode records, and each data Block has different copies, which are also managed by NameNode)
- Processing client read / write requests
- DataNode: Slave. The NameNode issues a command and the DataNode performs the actual operation
- Store actual data blocks
- Perform read / write operation of data block
- Client: the client
- File segmentation. When uploading files to HDFS, the Client divides the files into blocks one by one, and then uploads them. Generally, the maximum data Block is 128M or 256M
- Interact with NameNode to obtain the location information of the file, that is, NameNode first comes out with a scheme. Where should you save the file
- Interact with DataNode, read or write data, negotiate with corresponding DataNode and store data according to NameNode scheme
- The Client provides some commands to manage HDFS, such as NameNode formatting
- The Client can access HDFS through some commands, such as adding, deleting, checking and modifying HDFS
- Secondary NameNode: not a hot standby of NameNode. When the NameNode hangs, it cannot immediately replace the NameNode and provide services
- Assist NameNode to share its workload, such as regularly merging Fsimage and Edits and pushing them to NameNode
- In case of emergency, the NameNode can be recovered
4. File block size
The files in HDFS are physically stored in blocks. The size of blocks can be specified through the configuration parameter (dfs.blocksize). The default size is Hadoop 2 x/3. X version is 128M, 1 In version x, it is 64M. If there is 1KB of data, 128M blocks will also be allocated, but 128M space will not be directly occupied. Instead, the maximum Block size is 128M, which is actually the size of the data in the Block
- block in cluster
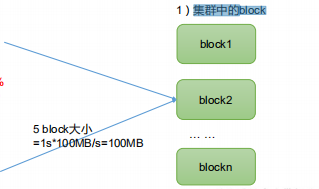
- If the addressing time is about 10ms, that is, the time to find the target block is 10ms
- When the addressing time is 1% of the transmission time, it is the best state. (expert) therefore, transmission time = 10ms/0.01=1000ms=1s
- At present, the transmission rate of disk is generally 100MB/s, so we generally choose the closest 128m as the maximum block space, while the company can use 300M/s data with solid-state disk, and choose 256m as the block space
Why can't the size of the block be set too small or too large
- The block setting of HDFS is too small, which will increase the addressing time. The program has been looking for the starting position of the block. For example, a file of 100m is divided into 100 blocks of 1m, and the optical addressing needs 100 times. After addressing, it starts to obtain data
- If the block is set too large, the time to transfer data from the disk will be significantly greater than the time required to locate the start position of the block. As a result, the program will be very slow in processing this data. We should follow the principle that the addressing time is exactly 1% of the transmission time
- The size setting of HDFS block mainly depends on the disk transmission rate. For ordinary mechanical hard disk, we use 128m to set the block size, and for solid-state hard disk, 256m
2, shell related operations
- Basic grammar
Both commands are OK 1. hadoop fs order of the day 2. hdfs dfs order of the day
- Common command viewing methods
--see hadoop,namely hdfs Related commands [hadoop100@hadoop102 hadoop-3.1.3]$ bin/hadoop fs --use-help View the parameters of the specified command, such as the following query rm Parameters of the command [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -help rm
- Introduction to common commands
- Start hadoop cluster
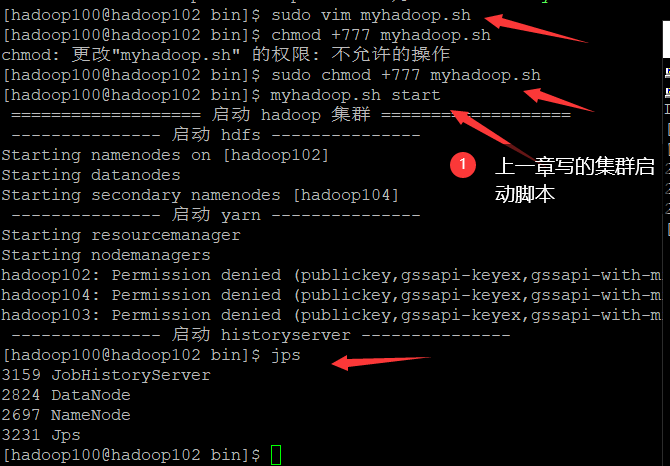
- Create a sanguo folder, - mkdir

[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /sanguo
- Cut from local to HDFS,-moveFormLocal
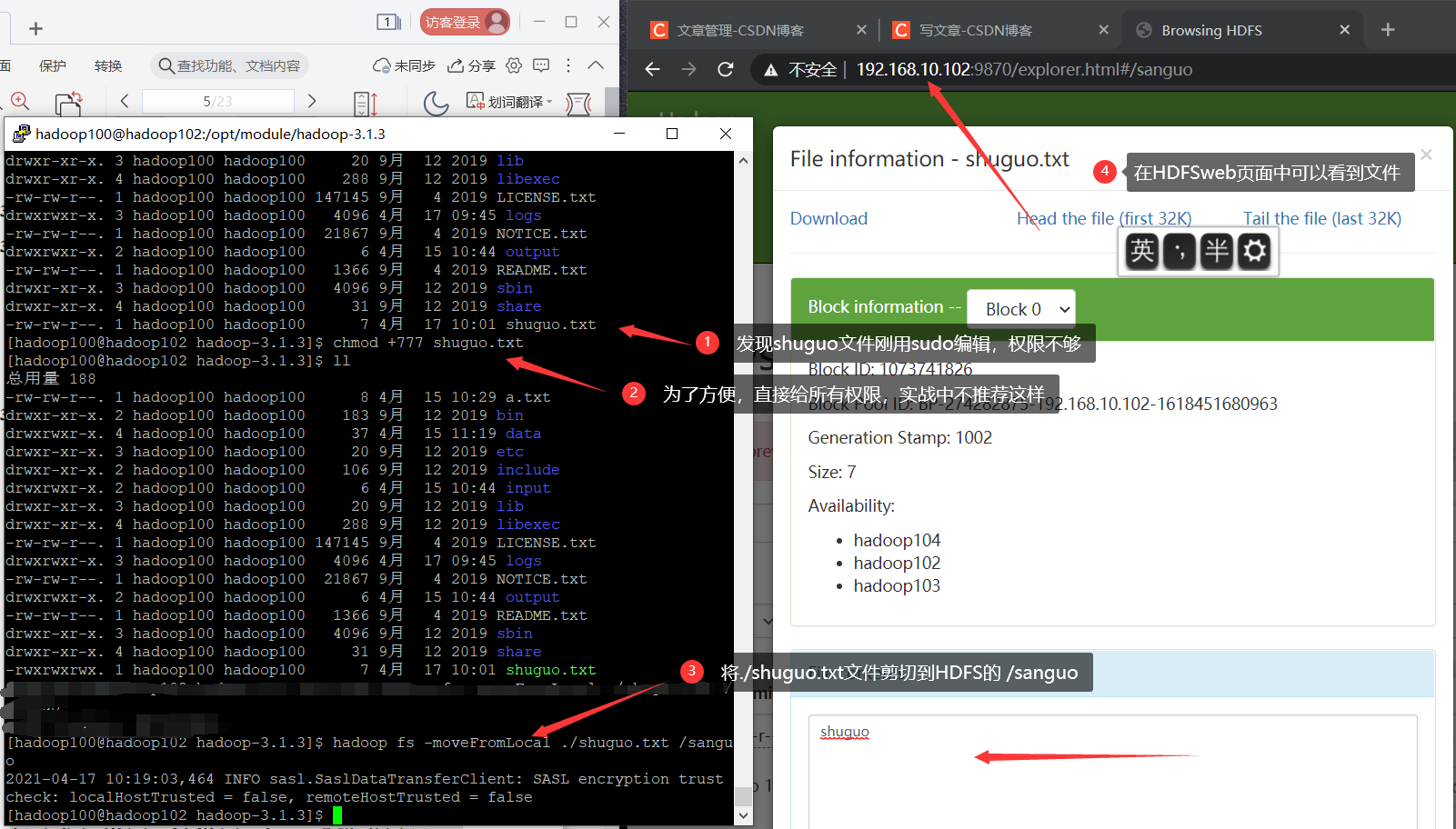
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
- Copy files from the local file system to the HDFS path, - copyFromLocal
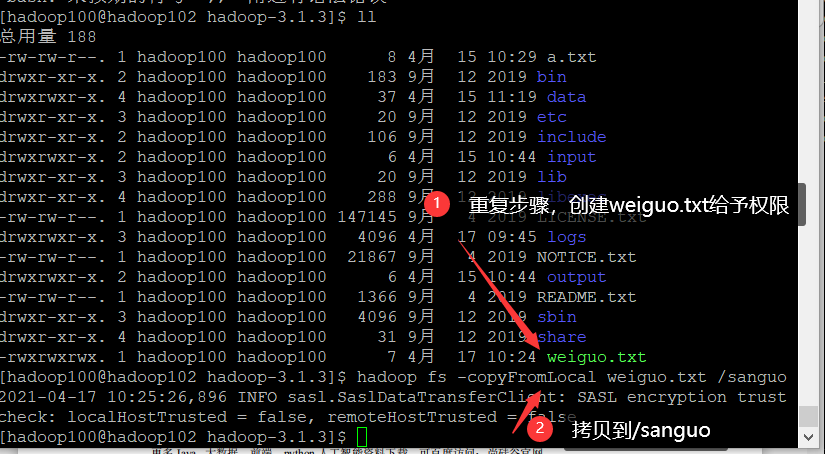
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
- -Put is equivalent to copyFromLocal. The production environment uses more put commands
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
- Append a file to the end of the existing file, - appendToFile
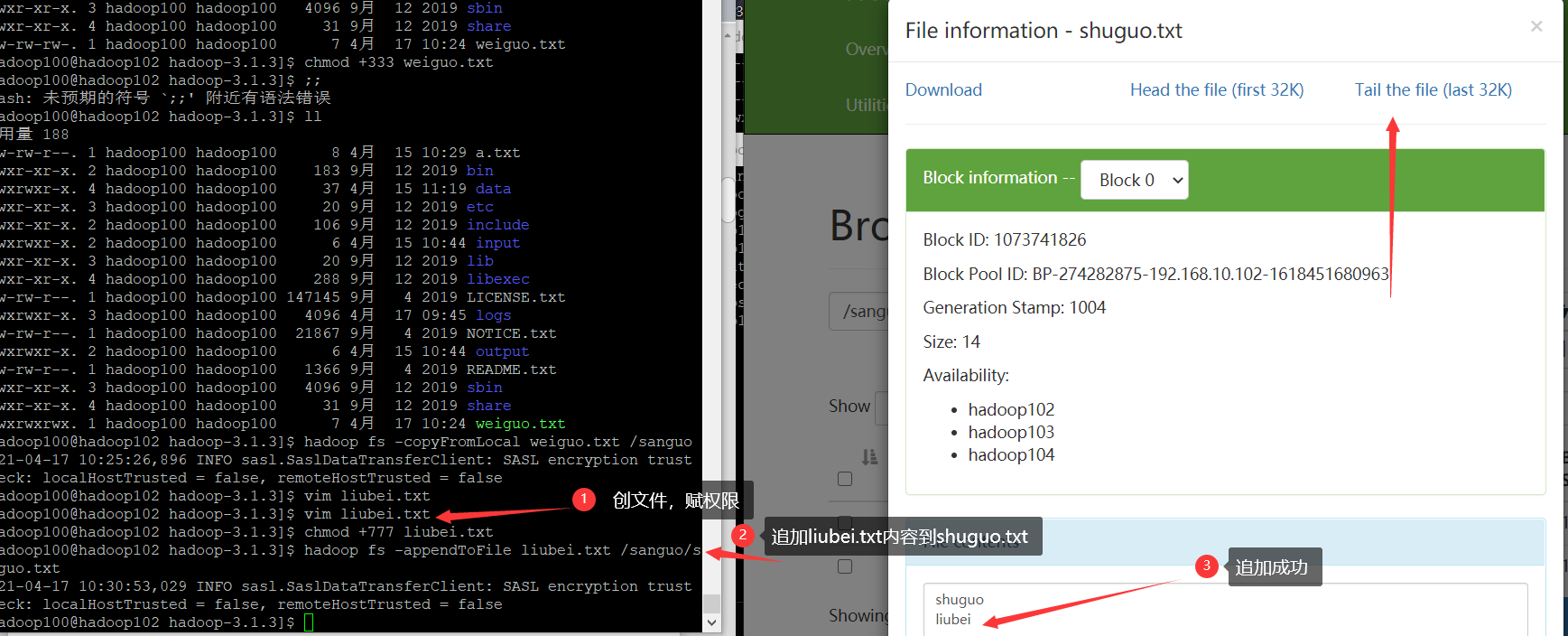
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
- Download, copy from HDFS to local, - copyToLocal,-get
[hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./ [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
- Some commands that directly operate HDFS
1)-ls: Display directory information [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo 2)-cat: Display file contents [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt 3)-chgrp,-chmod,-chown: Linux The same as in the file system, modify the permissions of the file [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -chown hadoop100:hadoop100 /sanguo/shuguo.txt 4)-mkdir: Create path [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo 5)-cp: from HDFS Copy a path to HDFS Another path to [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo 6)-mv: stay HDFS Move files in directory [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt/jinguo [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo 7)-tail: Show the end of a file 1 kb Data [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt 8)-rm: Delete file or folder [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt 9)-rm -r: Recursively delete the directory and its contents [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo 10)-du Statistics folder size information [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo 27 81 /jinguo Note: 27 indicates the file size; 81 means 27*3 Copies;/jinguo Indicates the directory to view [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo 14 42 /jinguo/shuguo.txt 7 21 /jinguo/weiguo.txt 6 18 /jinguo/wuguo.tx 11)-setrep: set up HDFS Number of copies of files in [hadoop100@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt The number of copies set here is 10, which is only recorded in NameNode Whether there will be so many copies in the metadata of has to be determined see DataNode Number of. At present, there are only 3 devices, up to 3 replicas. Only when the number of nodes increases to 10, The number of copies can reach 10
3, Client API for HDFS
1. Build client environment
| Get the compiled hadoop client first |
|---|
| I uploaded the resources here and downloaded them for free |
| https://download.csdn.net/download/grd_java/16728142 |
| Or download it from github https://github.com/cdarlint/winutils |
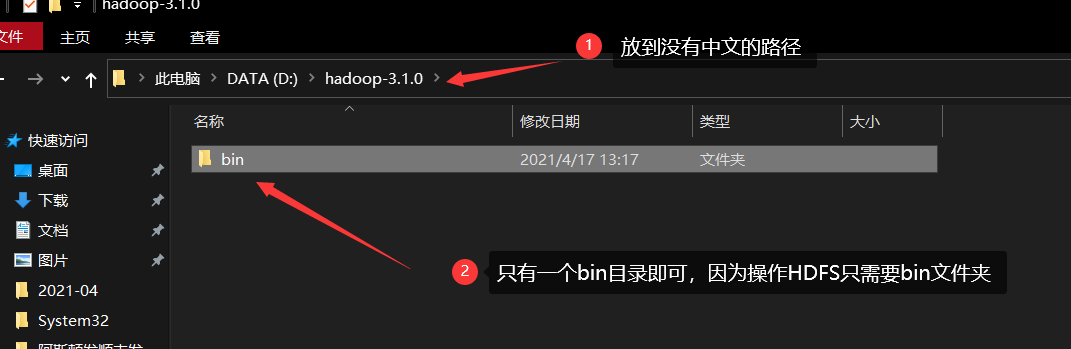
| Configure environment variables |
|---|
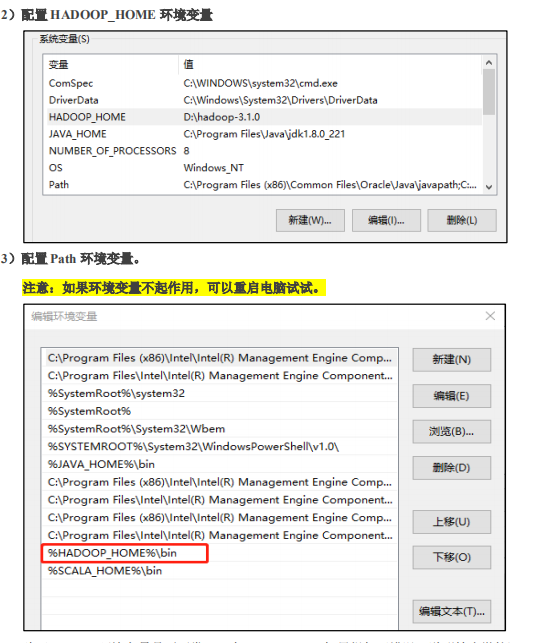
| function |
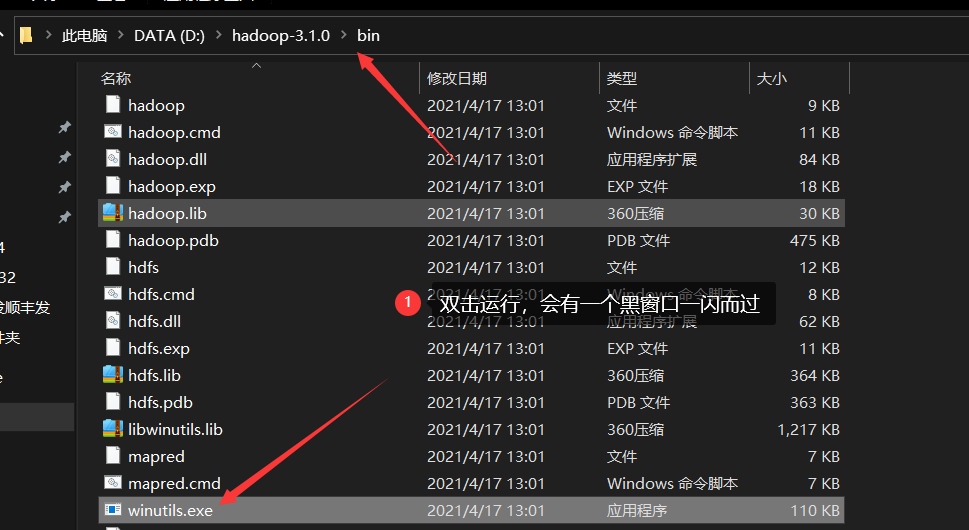
|---|
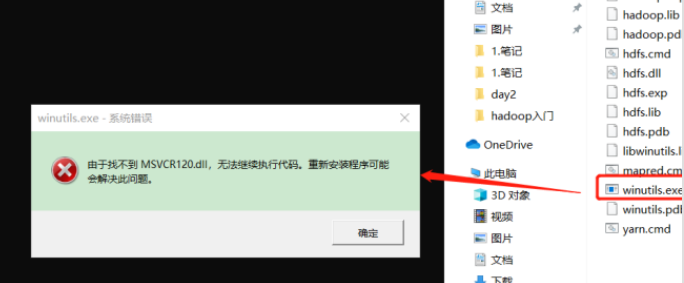
If the following error is reported. It indicates the lack of Microsoft runtime (this problem is often found in genuine systems). Double click the Microsoft runtime installation package corresponding to Baidu to install it
2. Creating MAVEN projects using IDEA
- Create Maven project because of related dependencies
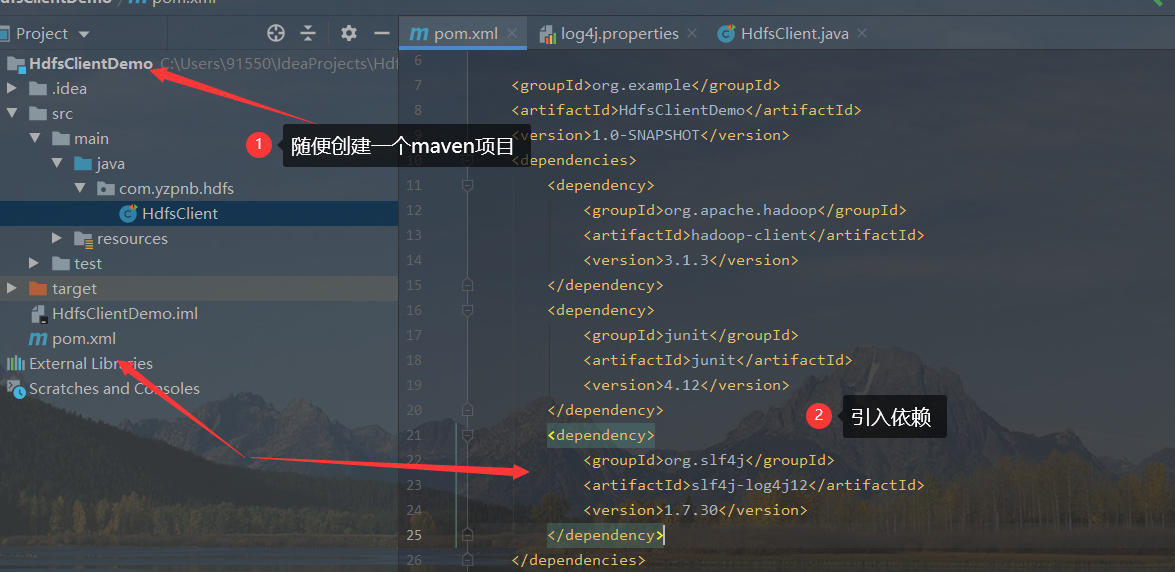
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency> </dependencies>
- In the src/main/resources directory of the project, create a new file named "log4j.properties"
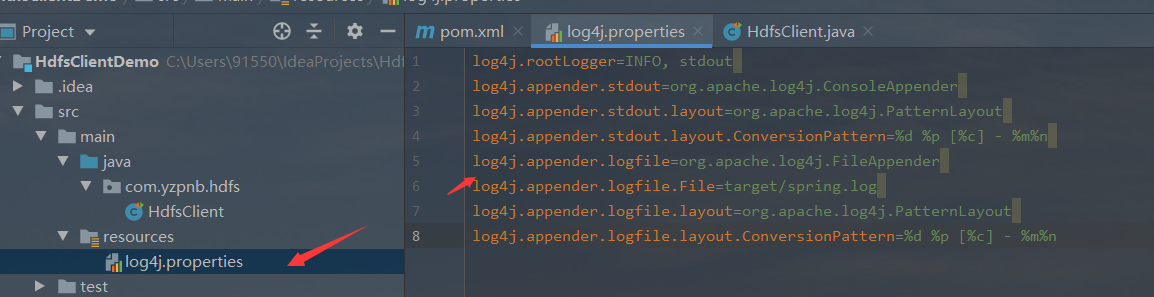
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
3. Create directory remotely
- Write java code
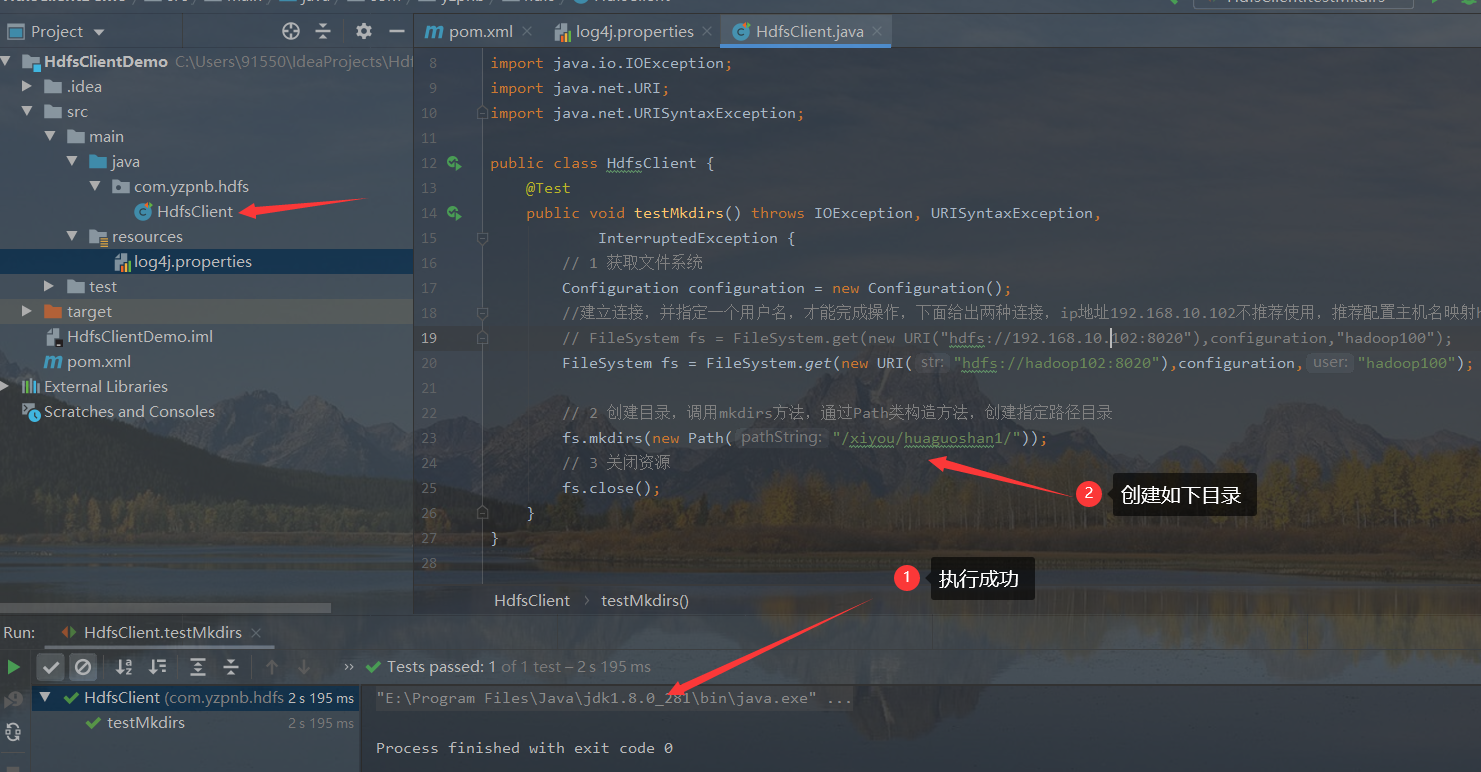
package com.yzpnb.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, URISyntaxException,
InterruptedException {
// 1 get file system
Configuration configuration = new Configuration();
//Establish a connection and specify a user name (the default user of windows is used by default, and an error will be reported if it is inconsistent). The following two connections are given. The ip address 192.168.10.102 is not recommended. It is recommended to configure the host name mapping Hadoop 102
// FileSystem fs = FileSystem.get(new URI("hdfs://192.168.10.102:8020"),configuration,"hadoop100");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),configuration,"hadoop100");
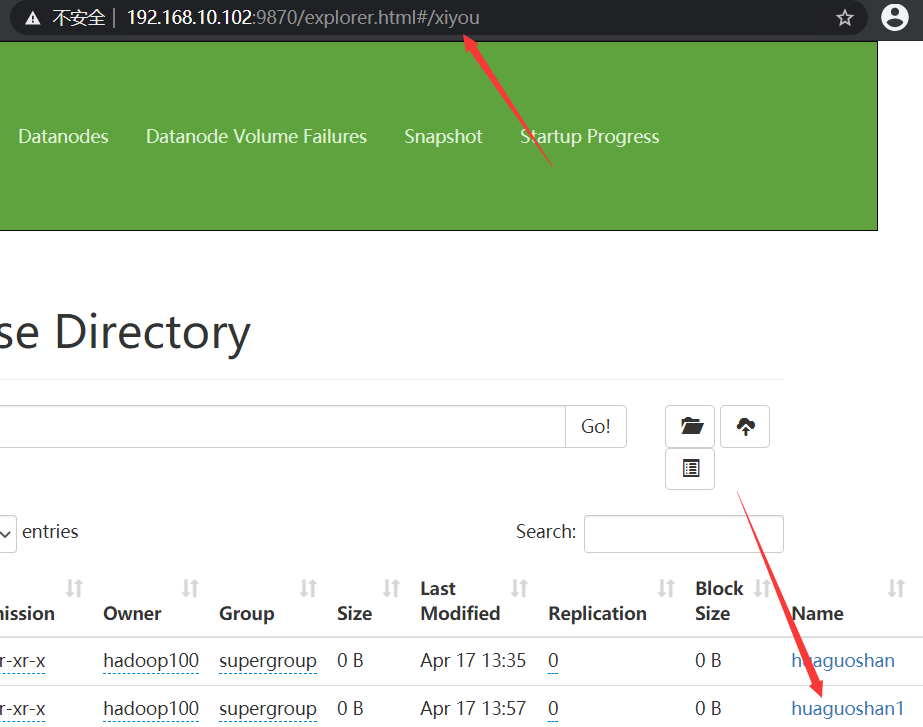
// 2 create a directory, call the mkdirs method, and create the directory with the specified Path through the Path class construction method
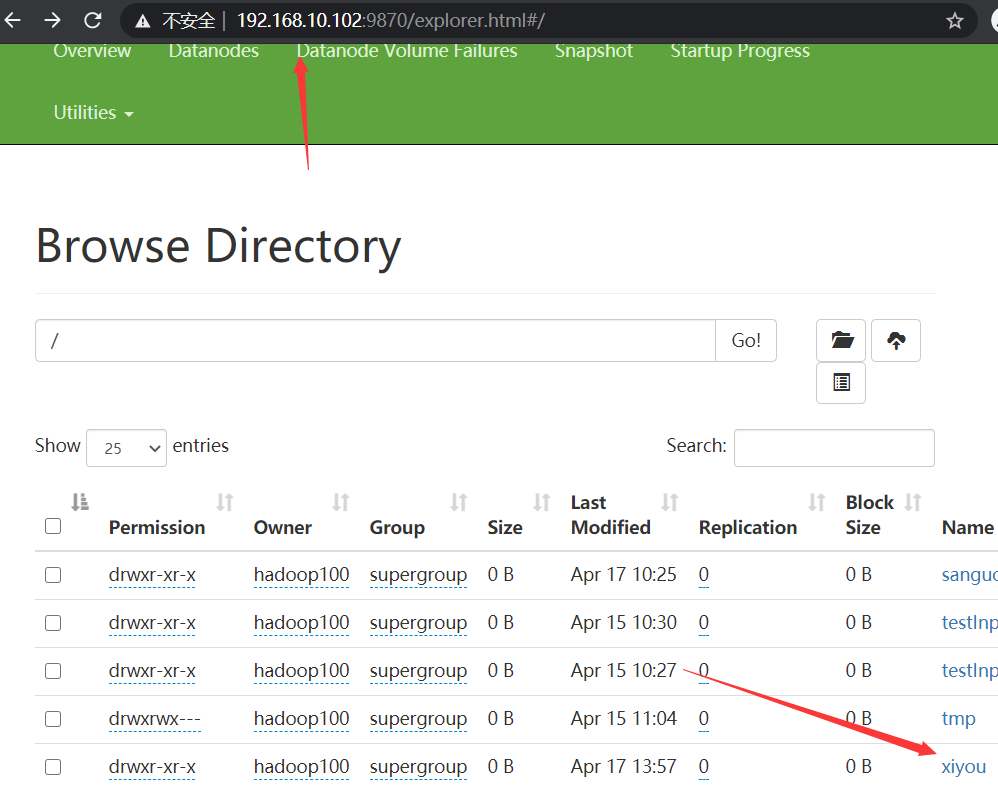
fs.mkdirs(new Path("/xiyou/huaguoshan1/"));
// 3 close resources
fs.close();
}
}
- results of enforcement
4. Downloaded and uploaded data
1. HDFS file upload (test parameter priority)
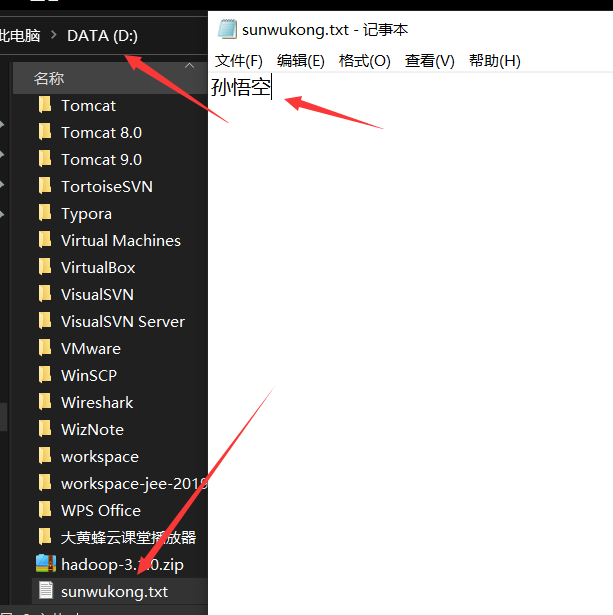
- Create a file to upload
- Write code and execute
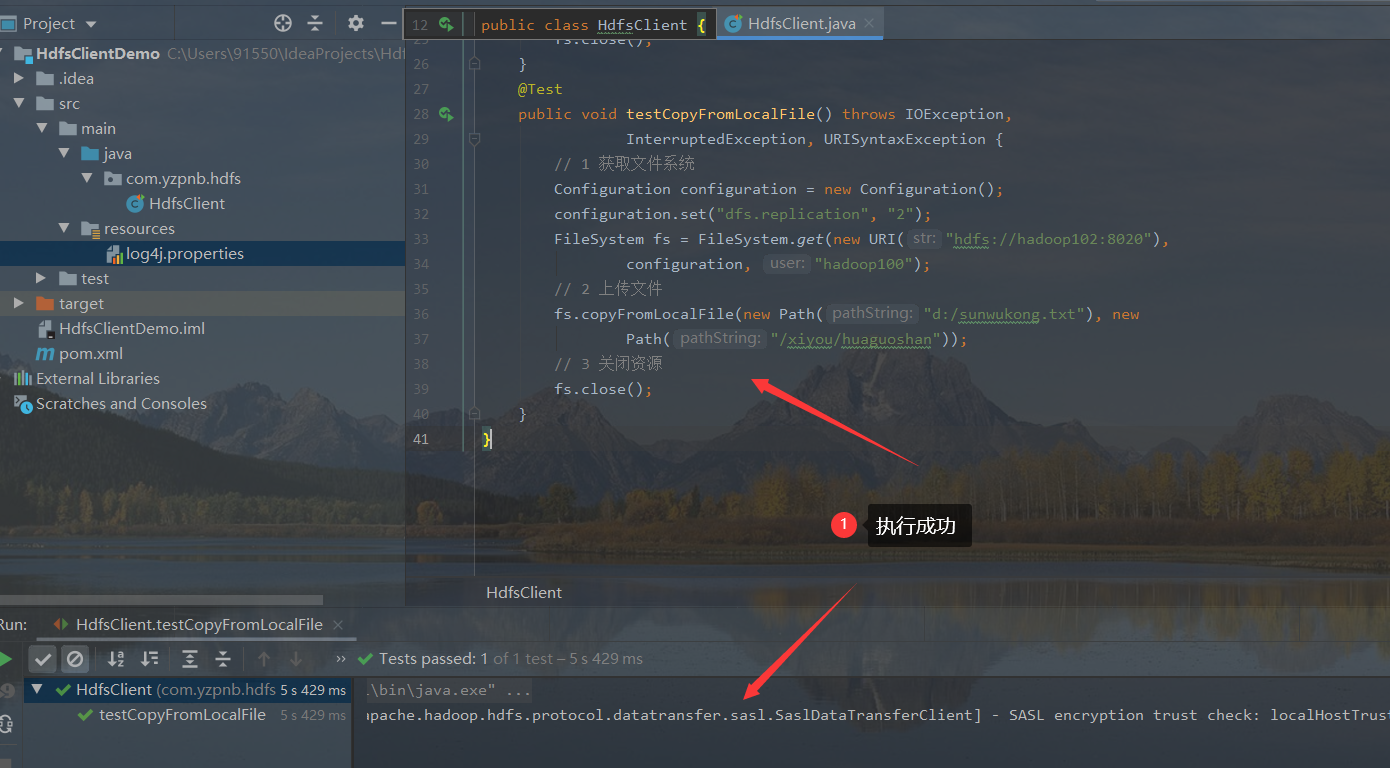
@Test
public void testCopyFromLocalFile() throws IOException,
InterruptedException, URISyntaxException {
// 1 get file system
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2. The following code for uploading files omits parameter 1: delete source data and parameter 2: allow overwrite
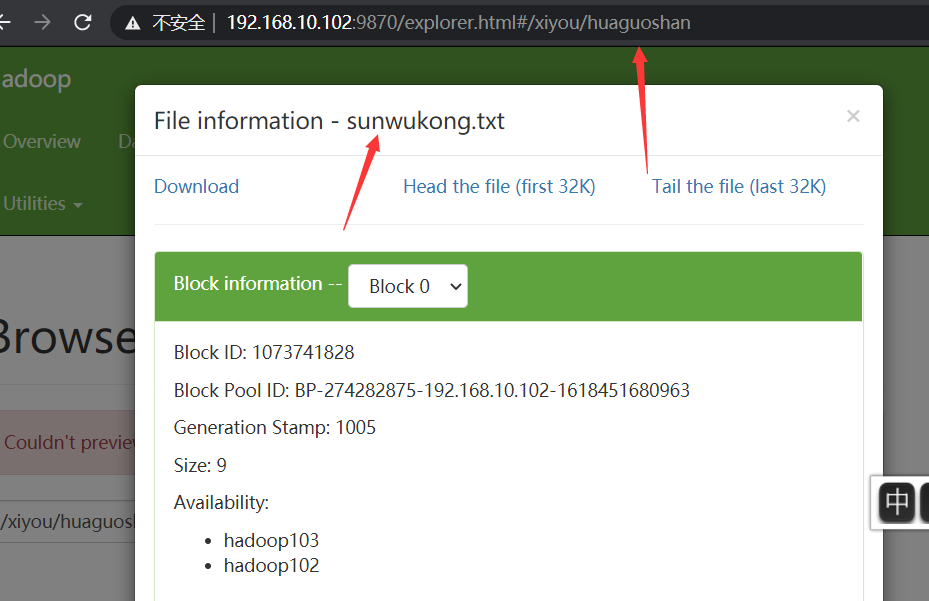
fs.copyFromLocalFile(new Path("d:/sunwukong.txt"), new
Path("/xiyou/huaguoshan"));
// 3 close resources
fs.close();
}
- result
- Parameter priority test (for example, I have an xml configuration file in the client code and the same xml configuration file in the server, so who will prevail in the execution of the client code?)
- Parameter priority
Parameter priority: (1) value set in client code > (2) user defined configuration file under ClassPath > (3) then custom configuration of server (xxx site. XML) > (4) default configuration of server (XXX default. XML)
- HDFS site Copy XML to the resources directory of the project and use DFS The number of replication configuration copies. Check whether 1 of the client configuration is effective or 3 of the server configuration is effective
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
2. File download
- Write test code (if you can't download the file by executing the following code, it may be that there are few Microsoft supported runtime libraries on your computer, so you need to install the Microsoft runtime library. In addition, you may see the file with. crc suffix next to the downloaded file, which verifies whether the file is transmitted incorrectly. When HDFS sends data, encrypt the file, save the result to the crc file, and then save the crc and the source data together After sending, the client will encrypt the file and check whether the result is consistent with the crc file)
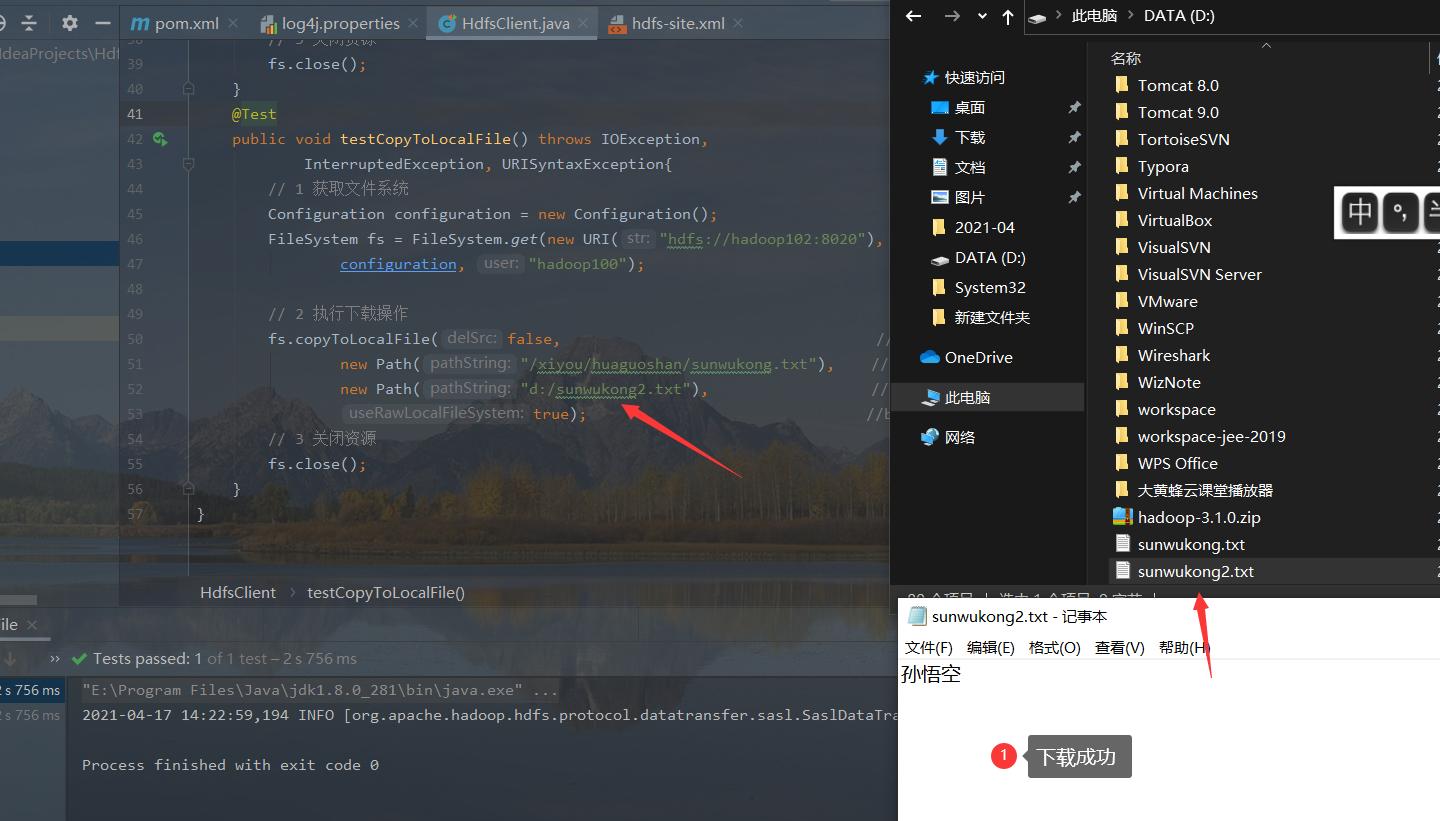
@Test
public void testCopyToLocalFile() throws IOException,
InterruptedException, URISyntaxException{
// 1 get file system
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2. Perform the download operation
fs.copyToLocalFile(false, //boolean delSrc refers to whether to delete the original file
new Path("/xiyou/huaguoshan/sunwukong.txt"), //Path src refers to the path of the file to be downloaded
new Path("d:/sunwukong2.txt"), //Path dst refers to the path to download the file to
true); //boolean useRawLocalFileSystem whether to enable file verification
// 3 close resources
fs.close();
}
3. Renaming and moving files
- Write code and test
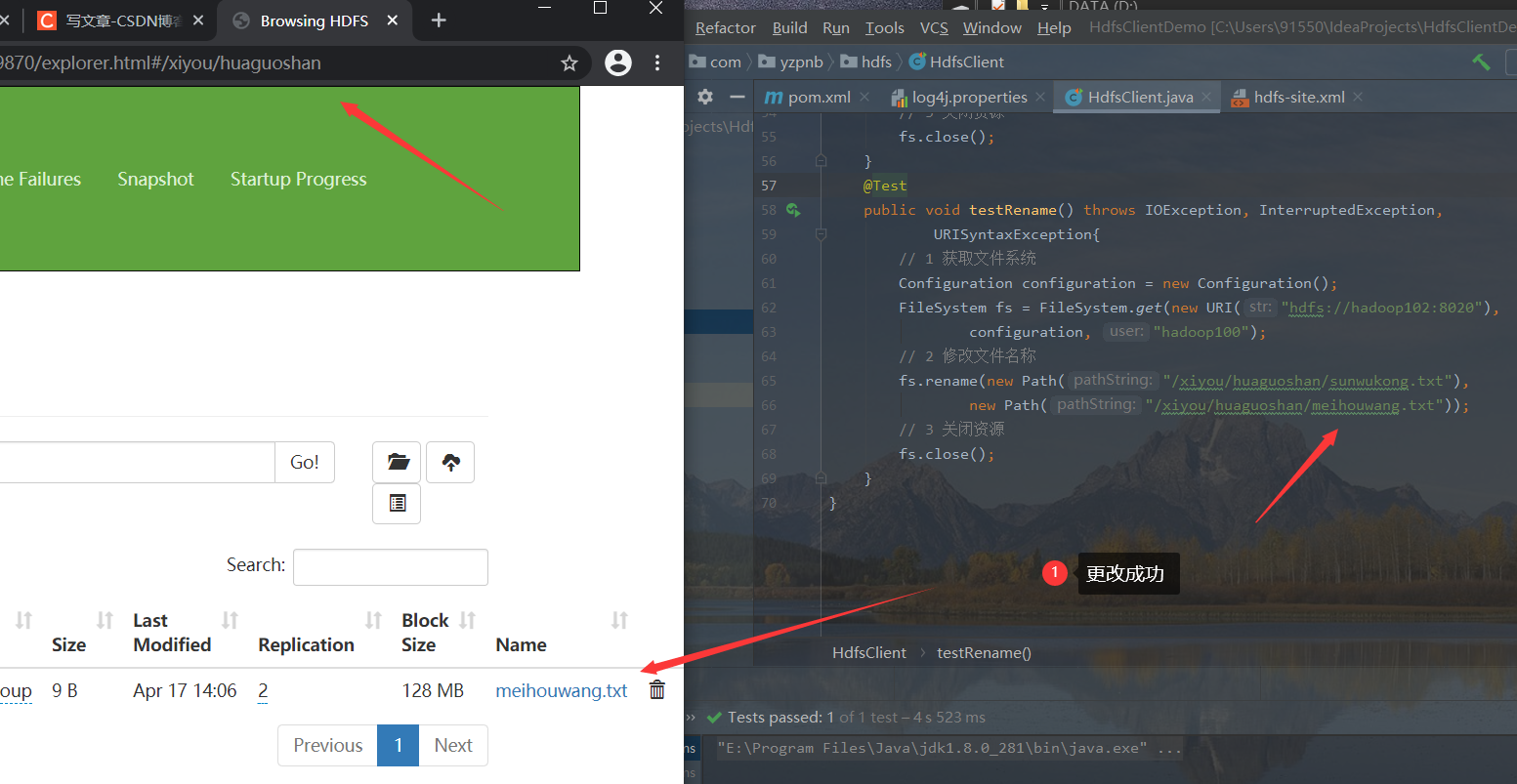
@Test
public void testRename() throws IOException, InterruptedException,
URISyntaxException{
// 1 get file system
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2. Modify the file name
fs.rename(new Path("/xiyou/huaguoshan/sunwukong.txt"),
new Path("/xiyou/huaguoshan/meihouwang.txt"));
// 3 close resources
fs.close();
}
4. Delete files and directories
- Write code to run
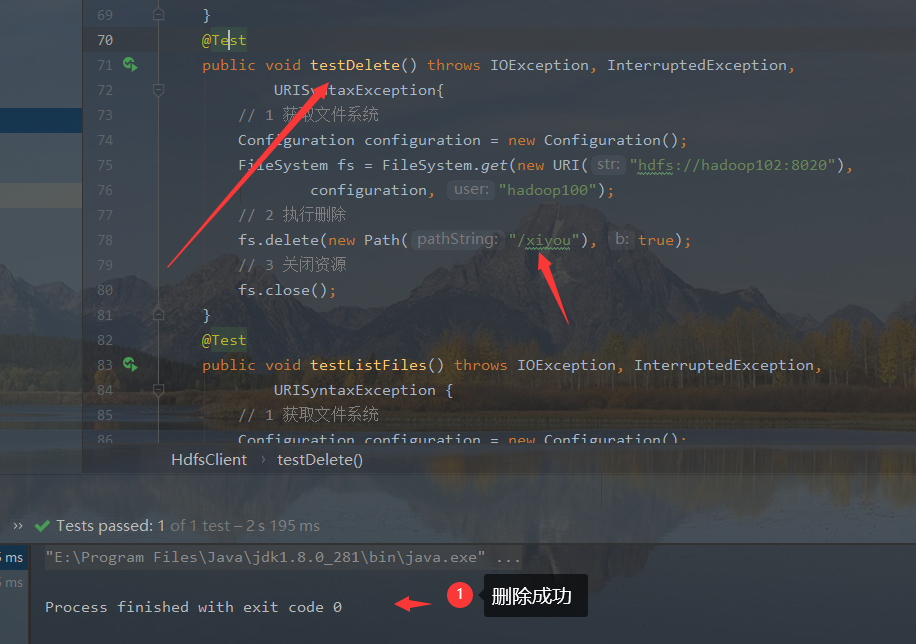
@Test
public void testDelete() throws IOException, InterruptedException,
URISyntaxException{
// 1 get file system
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2. Execute deletion. Parameter 1: delete path. Parameter 2: whether to delete recursively. If not, the files in it cannot be deleted
fs.delete(new Path("/xiyou"), true);
// 3 close resources
fs.close();
}
5. HDFS file details view
- Write code to run
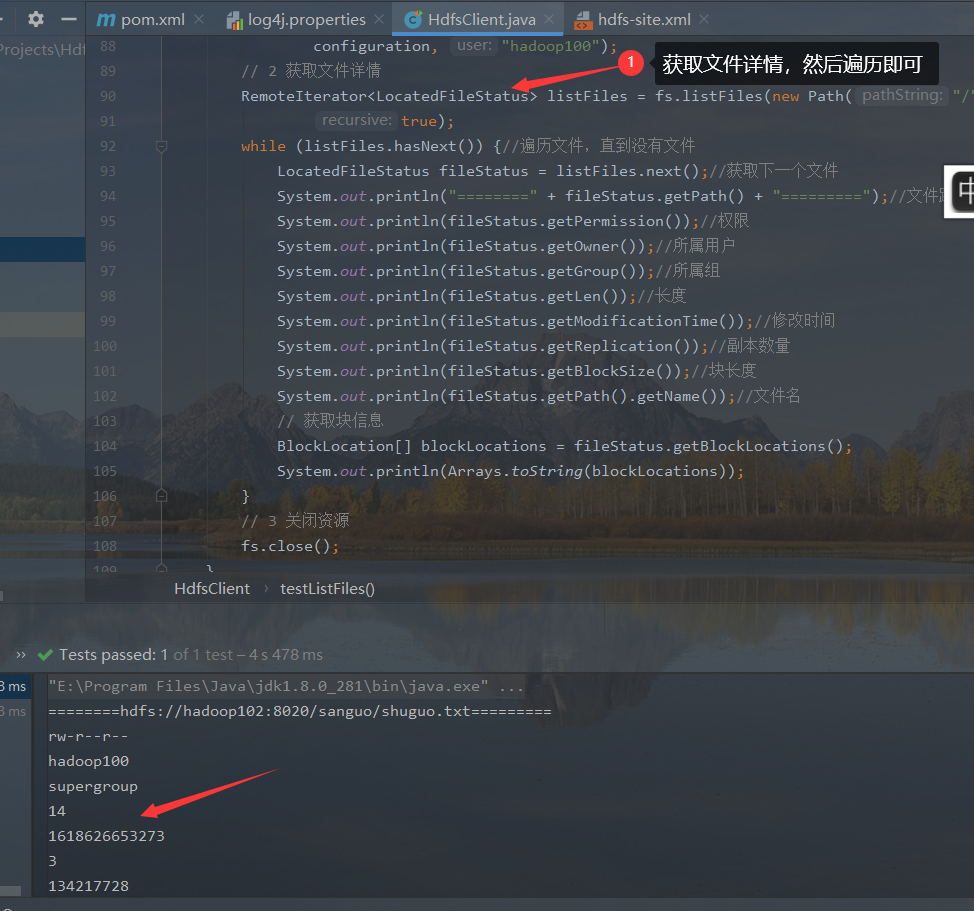
@Test
public void testListFiles() throws IOException, InterruptedException,
URISyntaxException {
// 1 get file system
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2 obtain document details
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"),
true);
while (listFiles.hasNext()) {//Traverse the file until there is no file
LocatedFileStatus fileStatus = listFiles.next();//Get next file
System.out.println("========" + fileStatus.getPath() + "=========");//File path
System.out.println(fileStatus.getPermission());//jurisdiction
System.out.println(fileStatus.getOwner());//User
System.out.println(fileStatus.getGroup());//Group
System.out.println(fileStatus.getLen());//length
System.out.println(fileStatus.getModificationTime());//Modification time
System.out.println(fileStatus.getReplication());//Number of copies
System.out.println(fileStatus.getBlockSize());//Block length
System.out.println(fileStatus.getPath().getName());//file name
// Get block information
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 3 close resources
fs.close();
}
6. HDFS file and folder judgment
- Write code and run
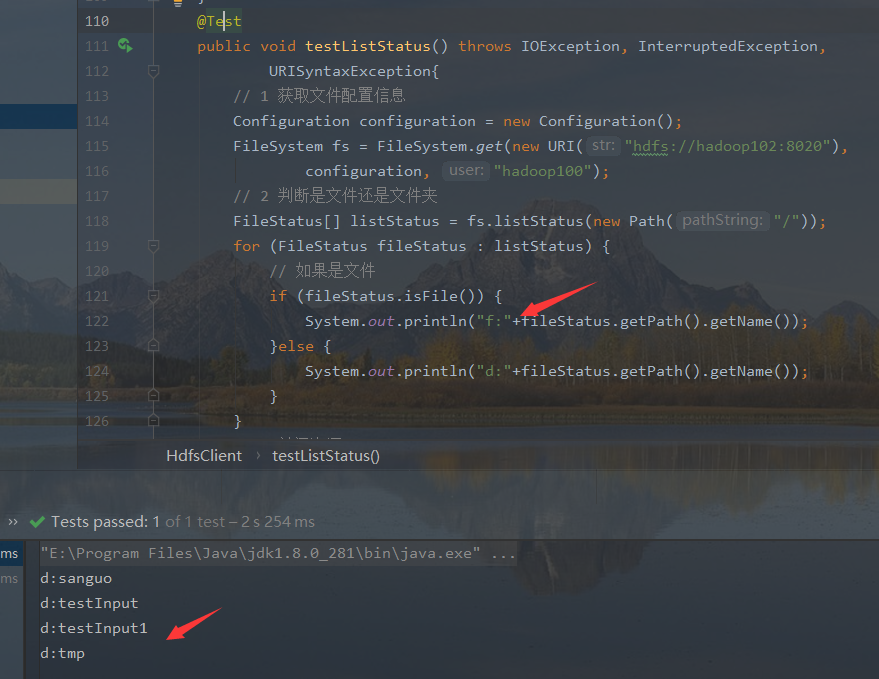
@Test
public void testListStatus() throws IOException, InterruptedException,
URISyntaxException{
// 1 get file configuration information
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration, "hadoop100");
// 2. Judge whether it is a file or a folder
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// If it's a file
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 close resources
fs.close();
}
4, Reading and writing process of HDFS
1. Write process
- File writing analysis
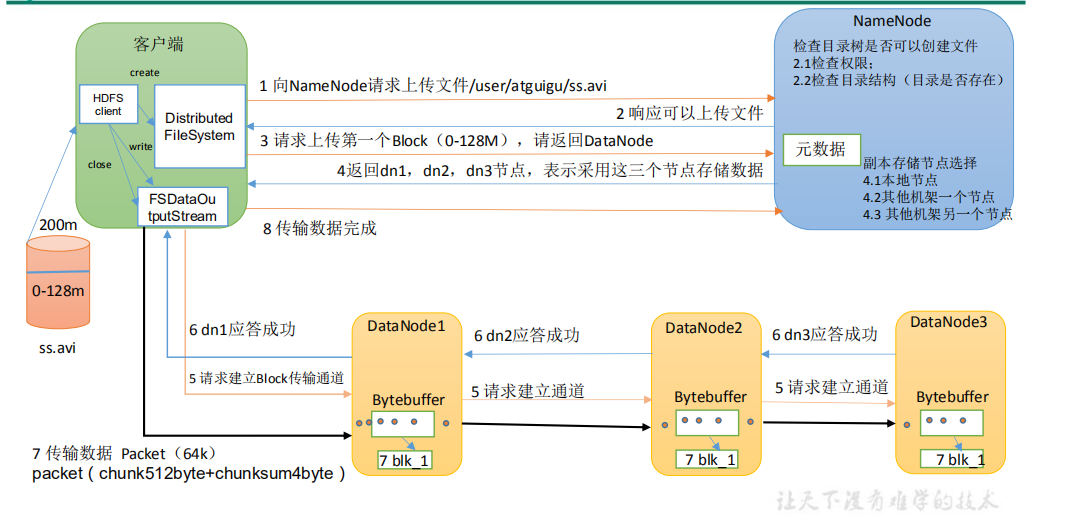
- The client requests the NameNode to upload files through the distributed file system module. The NameNode checks whether the target file exists and whether the parent directory exists
- NameNode returns whether it can be uploaded
- Which DataNode servers does the client request to upload the first Block to
- NameNode returns three DataNode nodes: dn1, dn2 and dn3
- The client requests dn1 to upload data through FSDataOutputStream module. dn1 will continue to call dn2 after receiving the request, and then dn2 will call dn3 to complete the establishment of this communication pipeline
- dn1, dn2, dn3 step-by-step response client
- The client starts to upload the first Block to dn1 (first read the data from the disk and put it into a local memory cache). With packets as the unit, dn1 will send a packet to dn2 and dn2 to dn3; Every packet transmitted by dn1 will be put into a reply queue to wait for a reply.
- After the transmission of a Block is completed, the client again requests the NameNode to upload the server of the second Block. (repeat steps 3-7)
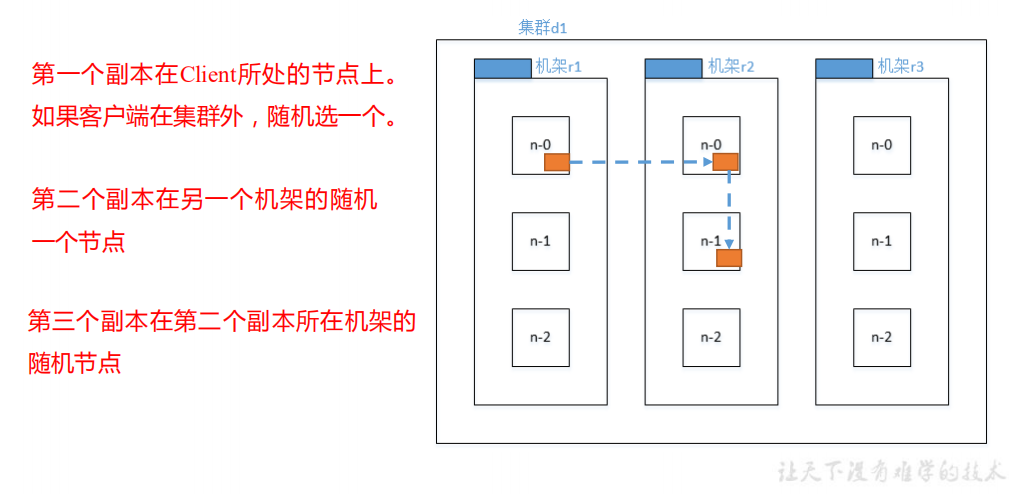
- Network topology node distance calculation
In the process of HDFS writing data, NameNode will select the DataNode closest to the data to be uploaded to receive the data. So how to calculate the nearest distance?
- Node distance: the sum of the distances from two nodes to the nearest common ancestor
- Analyze according to the following figure
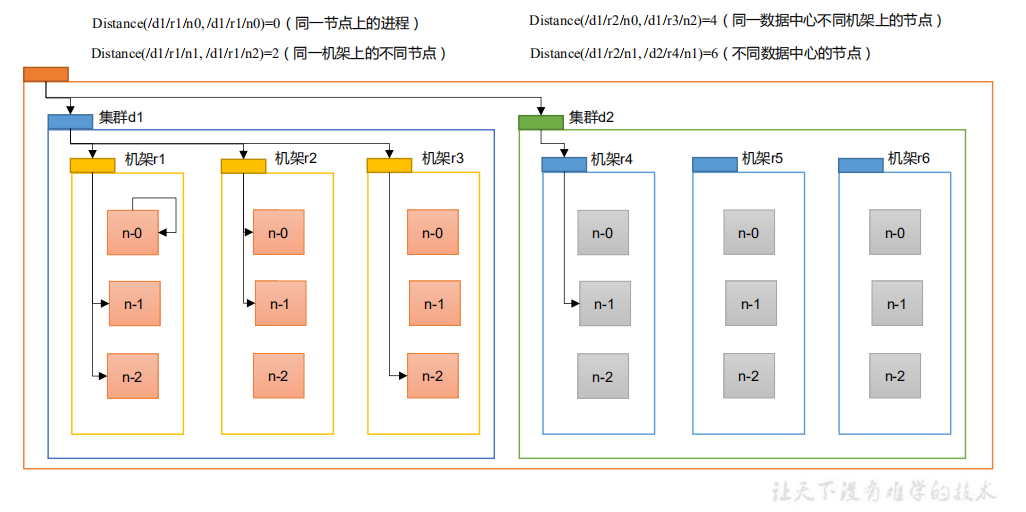
- Suppose there is node n1 in rack r1 of data center d1. This node can be expressed as / d1/r1/n1. Using this q-Mark, four distance descriptions are given here
- Rack aware (replica storage node selection)
- Official documents: http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
- Check according to the source code (Crtl + n find BlockPlacementPolicyDefault, and find the chooseTargetInOrder method in this class)
- Selection of replica nodes
Overall basis, principle of proximity and reliability
2. Read data
- technological process
First read in the principle of proximity. When the processing capacity reaches the upper limit, go to the server where the replica is located to read
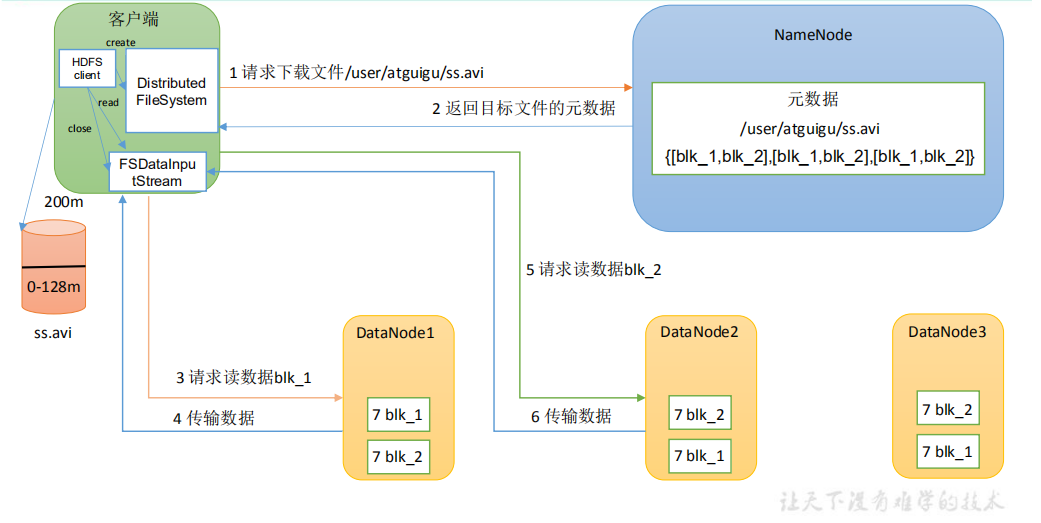
- The client requests the NameNode to download the file through the distributedfile system. The NameNode finds the DataNode address where the file block is located by querying the metadata
- Select a DataNode (proximity principle, then random) server and request to read data
3.DataNode starts transmitting data to the client (read the data input stream from the disk and verify it in Packet)
4. The client receives in packets, caches them locally, and then writes them to the target file
5, NN and 2NN(NameNode and SecondaryNameNode)
1. Working mechanism
- Where is the metadata stored in NameNode
- Stored in memory, but in order not to lose power, FsImage is generated to back up metadata in disk, but the efficiency of updating FsImage at the same time will be low. Therefore, edit files are introduced and only append operations are carried out. When metadata is updated, it will be appended at the same time, but the Edits will become larger and larger. Therefore, a new node, SecondaryNamenod, is introduced, Specifically for FsImage and Edits merging

| NameNode working mechanism |
|---|
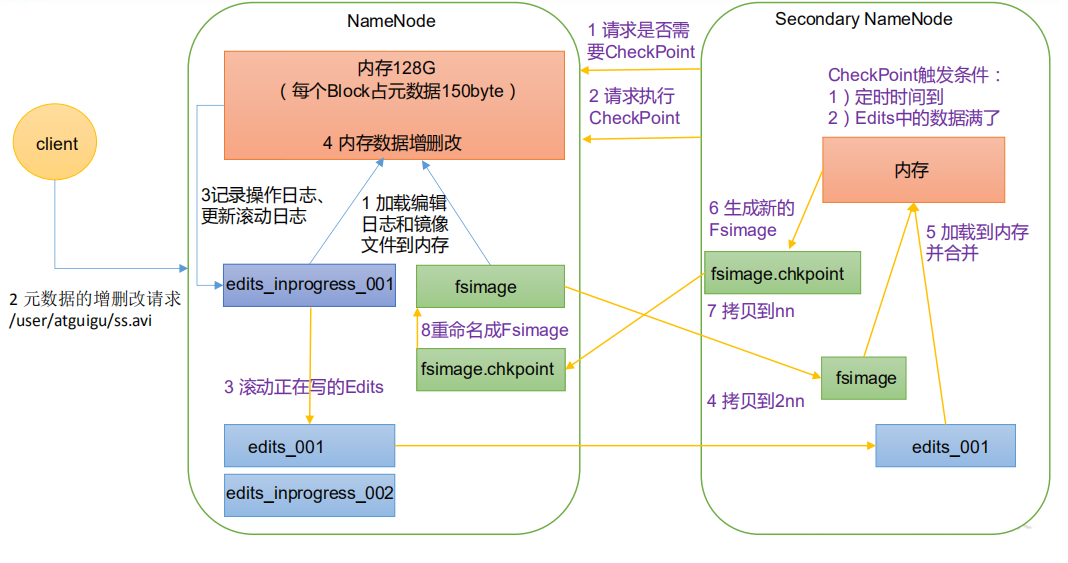
- Phase 1: NameNode startup
- After the NameNode format is started for the first time, the Fsimage and Edits files are created. If it is not the first time to start, directly load the editing log and image file into memory
- Request of the client to add, delete or modify metadata
- NameNode records the operation log and updates the rolling log
- NameNode adds, deletes and modifies metadata in memory
- The second stage: the second namenode works
- The Secondary NameNode asks if the NameNode needs a CheckPoint. Directly bring back the NameNode check result.
- Secondary NameNode requests CheckPoint
- NameNode scrolls the Edits log being written
- Copy the editing log and image files before scrolling to the Secondary NameNode
- The Secondary NameNode loads the editing log and image files into memory and merges them.
- Generate a new image file fsimage chkpoint
- Copy fsimage Chkpoint to NameNode
- NameNode will fsimage Rename chkpoint to fsimage.
2. Fsimage and Edits
- concept

- Fsimage file: a permanent checkpoint of HDFS file system metadata, which contains the serialization information of all directories and file inode s of HDFS file system.
- Edits file: the path to store all update operations of the HDFS file system. All write operations performed by the file system client will first be recorded in the edits file
- seen_ The txid file holds a number, which is the last edit_ Number of
- Each time the NameNode starts, it will read the Fsimage file into the memory and load the update operation in the Edits to ensure that the metadata information in the memory is up-to-date and synchronous. It can be seen that the Fsimage and Edits files are merged when the NameNode starts.
- oiv view Fsimage file

[hadoop100@hadoop102 current]$ hdfs oiv apply the offline fsimage viewer to an fsimage oev apply the offline edits viewer to an edits file The basic syntax is as follows hdfs oiv -p file type -i Mirror file -o Converted file output path Practical operation: [hadoop100@hadoop102 current]$ pwd /opt/module/hadoop-3.1.3/data/dfs/name/current [hadoop100@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml [hadoop100@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/fsimage.xml
- View files


Basic grammar hdfs oev -p file type -i Edit log -o Converted file output path Practical operation: [hadoop100@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml [hadoop100@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/edits.xml
- CheckPoint time settings
- Generally, the SecondaryNameNode is executed every hour (refer to the default configuration of hdfs-default.xml below)
<property> <name>dfs.namenode.checkpoint.period</name> <value>3600s</value> </property>
- Check the number of operations once a minute. When the number of operations reaches 1 million, the SecondaryNameNode executes once
<property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>Operation action times</description> </property> <property> <name>dfs.namenode.checkpoint.check.period</name> <value>60s</value> <description> 1 Number of operations per minute</description> </property
6, Datanode
1. DataNode working mechanism
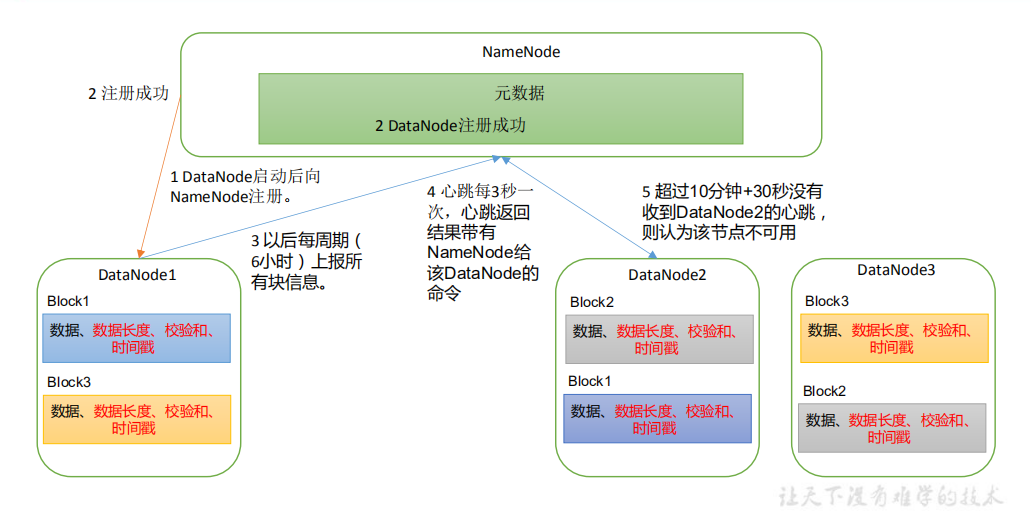
- A data block is stored on the disk in the form of a file on the DataNode, including two files, one is the data itself, and the other is metadata, including the length of the data block, the checksum of the block data, and the timestamp
- After the DataNode starts, it registers with the NameNode. After passing the registration, it periodically (6 hours) reports all block information to the NameNode


- The heartbeat occurs every 3 seconds. The result of the heartbeat is accompanied by the command given by the NameNode to the DataNode, such as copying block data to another machine or deleting a data block. If the heartbeat of a DataNode is not received for more than 10 minutes, the node is considered unavailable
- Some machines can be safely joined and exited during cluster operation
2. Data integrity
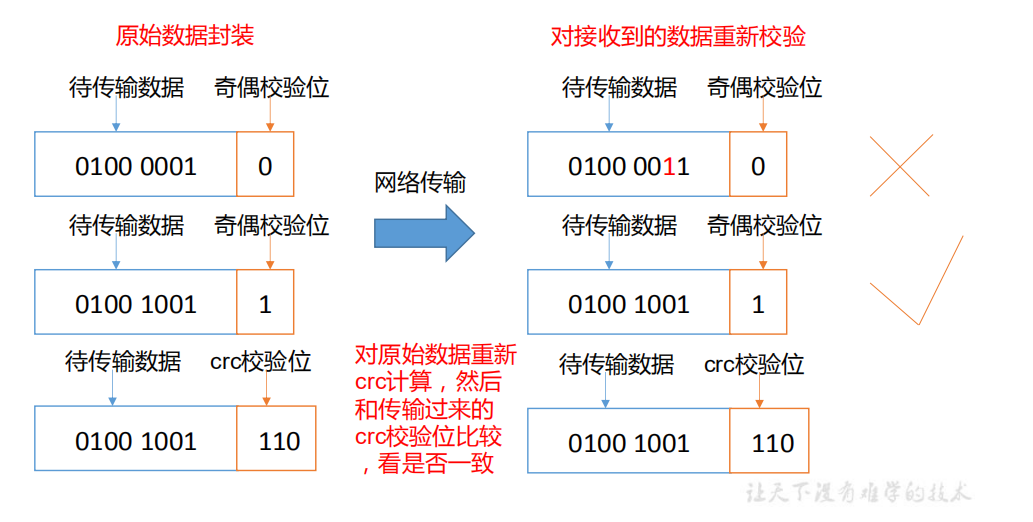
- If the data stored in the computer disk is the red light signal (1) and green light signal (0) controlling the high-speed railway signal, but the disk storing the data is broken and the green light is always displayed, is it very dangerous? Similarly, if the data on the DataNode node is damaged but not found, is it also dangerous? So how to solve it?
- Method of DataNode node to ensure data integrity
- When the DataNode reads the Block, it will calculate the CheckSum
- If the calculated CheckSum is different from the value when the Block was created, it indicates that the Block has been damaged
- Client reads blocks on other datanodes
- Common verification algorithms crc (32), md5 (128), sha1 (160)
- DataNode periodically validates CheckSum after its file is created
3. Parameter setting of disconnection time limit
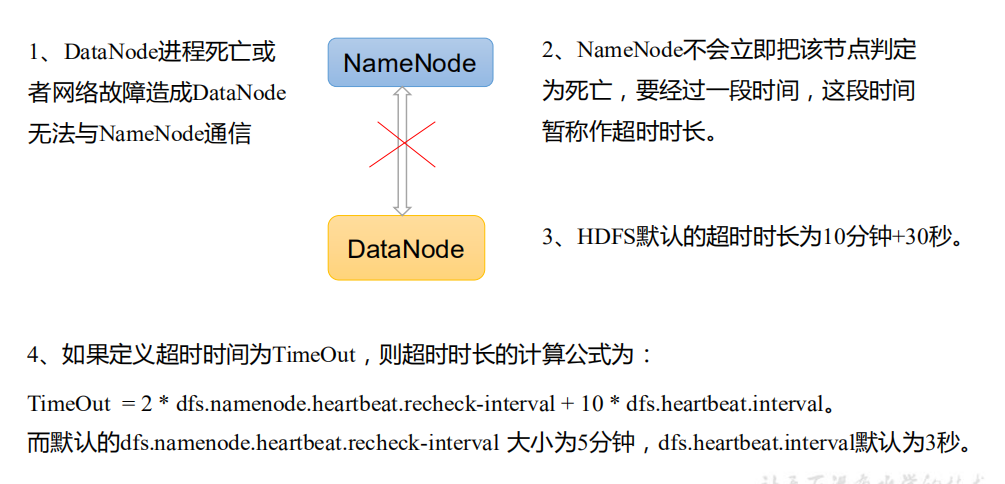
- hdfs-site. Heartbeat. XML configuration file recheck. Interval is in milliseconds, DFS heartbeat. Interval is in seconds
