Flume log collection tool is mainly used since it is a tool!
Distributed acquisition processing and aggregation streaming framework
A tool for collecting data by writing a collection scheme, that is, a configuration file. The configuration scheme is in the official document
1. Flume architecture
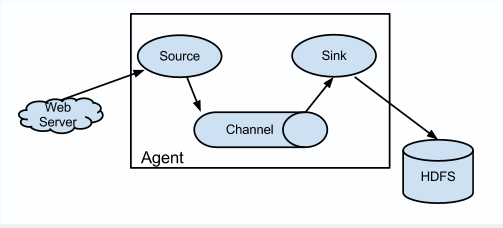
- Agent JVM process
- Source: receive data
- Channel: buffer
- Sink: output data
- Event transmission unit
2. Flume installation
The environment variables of Java and Hadoop are configured in advance. At this time, decompress and use!
3. Flume official example
The official documents of different sink, channel and sink configurations have examples
# example.conf : port -> console # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Start command
bin/flume-ng agent -c conf -f jobs/example.conf -n a1 -Dflume.root.logger=INFO,console
Transmit data
# yum install -y nc nc localhost 44444
4. Flume example
4.1 File New Context -> HDFS
The new content of the collection file is added to HDFS, and cannot be transmitted continuously at a breakpoint
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /data/test.log a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /flume/events/%Y%m%d a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 24 a1.sinks.k1.hdfs.roundUnit = hour a1.sinks.k1.hdfs.fileType = DataStream a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.byteCapacityBufferPercentage = 20 a1.channels.c1.byteCapacity = 800000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
start-up
bin/flume-ng agent -c conf -f jobs/log2hdfs.conf -n a1
4.2 Dir New File -> HDFS
Collect new files in the directory to HDFS and cannot monitor the changes of file contents
a1.sources = src-1 a1.sources.src-1.type = spooldir a1.sources.src-1.channels = c1 a1.sources.src-1.spoolDir = /data/data1 a1.sources.src-1.fileHeader = true a1.channels = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.byteCapacityBufferPercentage = 20 a1.channels.c1.byteCapacity = 800000 a1.sinks = k1 a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = /flume/events/%Y-%m-%d/%H a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.fileType = DataStream
start-up
bin/flume-ng agent -c conf -f jobs/file2hdfs.conf -n a1
4.3 Dir New FIle And Context -> HDFS
It can monitor the changes of files and file contents in multiple directories to HDFS, and can resume transmission at breakpoints. The log under log4j will be renamed, and the file renamed will be uploaded again
a1.sources = r1 a1.sources.r1.type = TAILDIR a1.sources.r1.channels = c1 a1.sources.r1.positionFile = /var/log/flume/taildir_position.json a1.sources.r1.filegroups = f1 f2 a1.sources.r1.filegroups.f1 = /data/data2/.*file.* a1.sources.r1.filegroups.f2 = /data/data3/.*log.* a1.sources.ri.maxBatchCount = 1000 a1.channels = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.byteCapacityBufferPercentage = 20 a1.channels.c1.byteCapacity = 800000 a1.sinks = k1 a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = /flume/events2/%Y-%m-%d/%H a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.fileType = DataStream
start-up
bin/flume-ng agent -c conf -f jobs/dir2hdfs.conf -n a1
[{"inode": 786450, "pos": 1501, "file": "/ data/data2/file1.txt"}] the source code locates a file according to inode and file
If the problem of renaming the file is handled, modify tailfile Java 123 and reliabletaildireventreader Repackage Java 256 and replace the jar package of taildersource under libs
5. Flume affairs
Source pushes events to the Channel and Sink pulls events from the Channel. These are advanced temporary buffers
-
Source - > Channel doput putlist rollback is to directly empty the Channel queue data, which may lose data. If there is a location record, it will not
-
Channel - > sink doTake takelist rollback is to reverse write the pulled data back to the channel queue. There may be duplicate data
6. Flume Agent principle
- Source receive data
- Source - > channel processor processing events
- Channel processor - > interceptor event interception and filtering
- Channel processor - > channel selector: replicating and multiplexing by default
- Channel processor - > channel n: write event to channel
- Channel - > Sink processor: three types: Default [one Sink], LoadBalancing [load balancing], and Failover [Failover]
- Sink processor - > sink: write sink
7. Flume topology
Connect multiple flume agents with Avro
Polling strategy: if Sink fails to pull data, change Sink
- Simple concatenation: sink - > source
- Replication and multiplexing: multi channel - > multi Sink
- Load balancing and failover: Channel - > multi Sink
- Aggregation: multiple sink - > source
8. Flume custom Interceptor
Customize the Interceptor to realize multiplexing:
-
Enter different channels through Header information
-
After collecting the information including Error and Exception, it enters one Channel and others enter another Channel
-
Each Channel Sink is output to the console
- Encoding custom Interceptor
package com.ipinyou.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TypeInterceptor implements Interceptor {
private List<Event> eventList;
@Override
public void initialize() {
eventList = new ArrayList<>();
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String body = new String(event.getBody());
if (body.contains("Error") || body.contains("Exception")) {
headers.put("type", "error");
} else {
headers.put("type", "normal");
}
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
eventList.clear();
for (Event event : list) {
eventList.add(intercept(event));
}
return eventList;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new TypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
- Package and upload to the lib directory of Flume
- Preparation of acquisition scheme
flume-s1-s2.conf
a1.sources = r1 a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop102 a1.sources.r1.port = 6666 a1.sources.r1.channels = c1 c2 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.ipinyou.flume.interceptor.TypeInterceptor$Builder a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = type a1.sources.r1.selector.mapping.error = c1 a1.sources.r1.selector.mapping.normal = c2 a1.channels = c1 c2 a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.byteCapacityBufferPercentage = 20 a1.channels.c1.byteCapacity = 800000 a1.channels.c2.type = memory a1.channels.c2.capacity = 10000 a1.channels.c2.transactionCapacity = 10000 a1.channels.c2.byteCapacityBufferPercentage = 20 a1.channels.c2.byteCapacity = 800000 a1.sinks = k1 k2 a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = hadoop103 a1.sinks.k1.port = 7771 a1.sinks.k2.type = avro a1.sinks.k2.channel = c2 a1.sinks.k2.hostname = hadoop104 a1.sinks.k2.port = 7772
flume-console1.conf
a1.sources = r1 a1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = hadoop103 a1.sources.r1.port = 7771 a1.channels = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.byteCapacityBufferPercentage = 20 a1.channels.c1.byteCapacity = 800000 a1.sinks = k1 a1.sinks.k1.type = logger a1.sinks.k1.channel = c1
flume-console2.conf
a1.sources = r1 a1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = hadoop104 a1.sources.r1.port = 7772 a1.channels = c1 a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.channels.c1.transactionCapacity = 10000 a1.channels.c1.byteCapacityBufferPercentage = 20 a1.channels.c1.byteCapacity = 800000 a1.sinks = k1 a1.sinks.k1.type = logger a1.sinks.k1.channel = c1
start-up
# Start in sequence: Hadoop 103 Hadoop 104 Hadoop 102 bin/flume-ng agent -c conf -f jobs/flume-console1.conf -n a1 -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf -f jobs/flume-console2.conf -n a1 -Dflume.root.logger=INFO,console bin/flume-ng agent -c conf -f jobs/dir2hdfs.conf -n a1
9. Flume custom Source
- Coding implementation
- The custom class inherits AbstractSource and implements configurable and pollablesource
- Implement configure(): read the configuration file
- Implement process (): receive external data, encapsulate events, and write to channels
- Package to lib
- Write configuration file
source type: full class name
- start-up
10. Flume custom Sink
- Coding implementation
-
The custom class inherits AbstractSink and implements Configurable
-
Implement configure(): read the configuration file
-
Implement process (): receive Channel data, open things, and write to the corresponding location
- Follow up is consistent with the above
11. Flume monitoring
With Ganglia third-party open source tools
Ganglia: web presentation data, gmetad storage data, gmod collection data
11.1 Ganglia installation
- install
# 102 103 104 yum install -y epel-release # 102 yum install -y ganglia-gmetad yum install -y ganglia-web yum install -y ganglia-gmod # 103 104 yum install -y ganglia-gmod
- Modify profile
/etc/httpd/conf.d/ganglia.conf
# Configure WindowsIP under Location Require ip 192.168.xxx.xxx
/etc/ganglia/gmetad.conf
data_source "my cluster" hadoop102
/etc/ganglia/gmod. Conf: Hadoop 102 103 104 Distribution
# Modify the following configuration name = "my cluster" host = hadoop102 bind = 0.0.0.0
Close selinux: / etc/selinux/config and restart to take effect or temporarily take effect
SELINUX=disabled
# Provisional entry into force setenforce 0
11.2 Ganlia startup
# If the permission is insufficient, modify the permission chmod -R 777 /var/lib/ganglia # hadoop102 systemctl start gmond systemctl start httpd systemctl start gmetad # hadoop103 hadoop104 systemctl start gmond
Browser open Web UI:
http://hadoop102/ganglia
11.3 Flume start
bin/flume-ng agent -n a1 -c conf -f jobs/xxx -Dflume.root.logger=INFO,console -Dflume.monitoring.type=ganglia -Dflume.monitoring.hosts=hadoop102:8649