1 data warehouse concept
Data Warehouse can be abbreviated as DW or DWH. Data Warehouse is a strategic set that provides all system data support for all decision-making processes of enterprises.
The analysis of data in data warehouse can help enterprises improve business processes, control costs and improve product quality.
Data warehouse is not the final destination of data, but preparing for the final destination of data. These preparations include data cleaning, escape, classification, reorganization, merging, splitting, statistics, etc.
2 project requirements
2.1 project demand analysis
1. Real time collection of user behavior data of buried points
2. Realize the hierarchical construction of data warehouse
3. Import business data regularly every day
4. Perform report analysis according to the data in the data warehouse
2.2 project framework
2.2. 1. Technical selection
Data acquisition and transmission: Flume, Kafka, Logstash, DataX, Sqoop
Data storage: Hive, MySql, HDFS, HBase, S3
Data calculation: Spark, Hive, Tez, Flink, Storm
Data query: Presto, Impala, Kylin
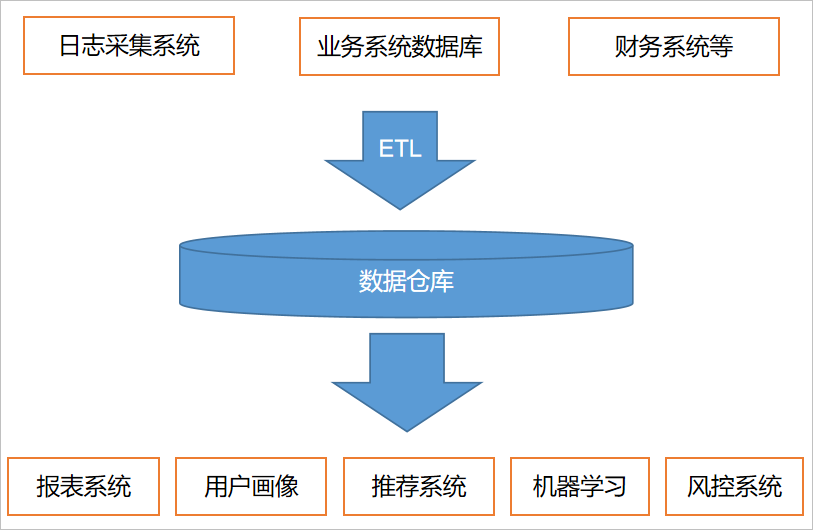
2.2. 2 common system architecture diagram design
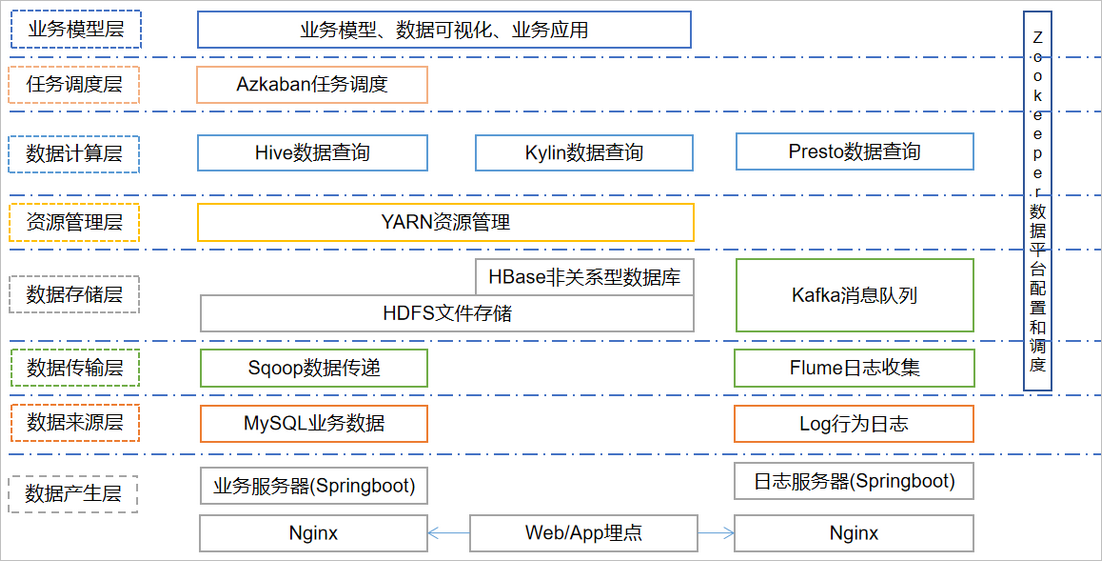
2.2. 3 common system data flow design
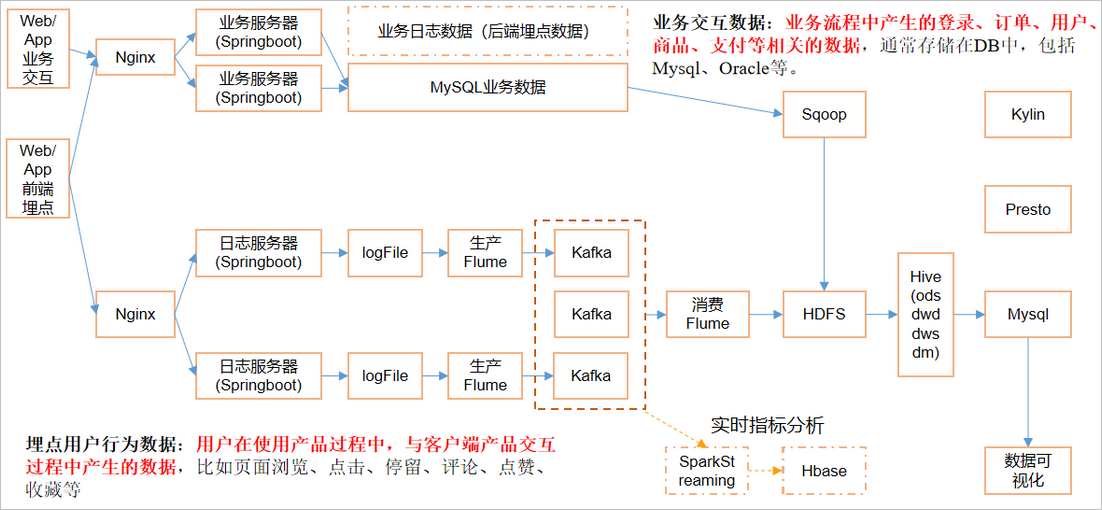
2.2. 4 frame version selection
| software product | edition |
|---|---|
| Hadoop | 2.7.2 |
| Flume | 1.7.0 |
| Kafka | 0.11.0.2 |
| Kafka Manager | 1.3.3.22 |
| Hive | 1.2.1 |
| Sqoop | 1.4.6 |
| Mysql | 5.7 |
| Azkaban | 2.5.0 |
| Java | 1.8 |
| Zookeeper | 3.4.10 |
Note: try not to select the latest frame for frame selection, and choose the stable version of the latest frame about half a year ago.
2.2. 5 cluster resource planning and design
| Server 1 | Server 2 | Server 3 | |
|---|---|---|---|
| HDFS | NameNode,DataNode | DataNode | DataNode |
| Yarn | NodeManager | Resourcemanager,NodeManager | NodeManager |
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
| Flume (collection log) | Flume | Flume | |
| Kafka | Kafka | Kafka | Kafka |
| Flume (consumption Kafka) | Flume | ||
| Hive | Hive | ||
| Mysql | Mysql |
3 data generation module
3.1 bill data field
private String sysId; // Platform coding private String serviceName; // Interface service name private String homeProvinceCode; // Belonging Province private String visitProvinceCode; // Visit Province private String channelCode; // Channel code private String serviceCode; // Business serial number private String cdrGenTime; // start time private String duration; // duration private String recordType; // Bill type private String imsi; // 46000 first 15 bit code private String msisdn; // Usually refers to the mobile phone number private String dataUpLinkVolume; // Uplink traffic private String dataDownLinkVolume; // Downlink traffic private String charge; // cost private String resultCode; // Result coding
3.2 bill data format:
{"cdrGenTime":"20211206165309844","channelCode":"wRFUC","charge":"62.28","dataDownLinkVolume":"2197","dataUpLinkVolume":"467","duration":"1678","homeProvinceCode":"551","imsi":"460007237312954","msisdn":"15636420864","recordType":"gprs","resultCode":"000000","serviceCode":"398814910321850","serviceName":"a9icp8xcNy","sysId":"U1ob6","visitProvinceCode":"451"}
3.3 write project simulation to generate bill data
See project: CDR for details_ gen_ app
Package and deploy the project to Hadoop 101 machine, and execute the command to test data generation
[hadoop@hadoop101 ~]$ head datas/call.log
{"cdrGenTime":"20211206173630762","channelCode":"QEHVc","charge":"78.59","dataDownLinkVolume":"3007","dataUpLinkVolume":"3399","duration":"1545","homeProvinceCode":"571","imsi":"460002441249614","msisdn":"18981080935","recordType":"gprs","resultCode":"000000","serviceCode":"408688053609568","serviceName":"8lr23kV4C2","sysId":"j4FbV","visitProvinceCode":"931"}
{"cdrGenTime":"20211206173630884","channelCode":"TY4On","charge":"31.17","dataDownLinkVolume":"1853","dataUpLinkVolume":"2802","duration":"42","homeProvinceCode":"891","imsi":"460008474876800","msisdn":"15998955319","recordType":"gprs","resultCode":"000000","serviceCode":"739375515156215","serviceName":"6p87h0OHdC","sysId":"UnI9V","visitProvinceCode":"991"}
...
4 data acquisition
4.1 Hadoop environment preparation
| Hadoop101 | Hadoop102 | Hadoop103 | |
|---|---|---|---|
| HDFD | NameNode, DataNode | DataNode | DataNode |
| Yarn | NodeManager | ResourceManager,NodeManager | NodeManager |
4.1. 1 add LZO support package
1) Download lzo's jar project first
<u>https://github.com/twitter/hadoop-lzo/archive/master.zip</u>
2) The downloaded file name is Hadoop LZO master. It is a zip compressed package. Decompress it first, and then compile it with maven. Generate hadoop-lzo-0.4 20.
3) The compiled hadoop-lzo-0.4 20. Jar into hadoop-2.7 2/share/hadoop/common/
[hadoop@hadoop101 common]$ pwd /opt/modules/hadoop-2.7.2/share/hadoop/common [hadoop@hadoop101 common]$ ls hadoop-lzo-0.4.20.jar
4) Synchronize hadoop-lzo-0.4 20. Jar to Hadoop 102 and Hadoop 103
[hadoop@hadoop101 common]$ xsync hadoop-lzo-0.4.20.jar
4.1. 2 add configuration
1)core-site.xml added configuration to support LZO compression
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
2) Synchronize core site XML to Hadoop 102, Hadoop 103
[hadoop@hadoop101 hadoop]$ xsync core-site.xml
4.1. 2 start the cluster
[hadoop@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh [hadoop@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh
4.1. 3 verification
1) web and process viewing
- Web view: http://hadoop101:50070
- Process view: jps view the status of each node.
4.2 Zookeeper environment preparation
| Hadoop101 | Hadoop102 | Hadoop103 | |
|---|---|---|---|
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
4.2.2 ZK cluster start stop script
1) Create a script in the / home/hadoop/bin directory of Hadoop 101
[hadoop@hadoop101 bin]$ vim zk.sh
Write the following in the script
#! /bin/bash
case $1 in
"start"){
for i in hadoop101 hadoop102 hadoop103
do
ssh $i "/opt/modules/zookeeper-3.4.10/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop101 hadoop102 hadoop103
do
ssh $i "/opt/modules/zookeeper-3.4.10/bin/zkServer.sh stop"
done
};;
esac
2) Increase script execution permission
[hadoop@hadoop101 bin]$ chmod +x zk.sh
3) Zookeeper cluster startup script
[hadoop@hadoop101 modules]$ zk.sh start
4) Zookeeper cluster stop script
[hadoop@hadoop101 modules]$ zk.sh stop
4.3 Flume environmental preparation
| Hadoop101 | Hadoop102 | Hadoop103 | |
|---|---|---|---|
| Flume (acquisition) | Flume |
flume configuration analysis
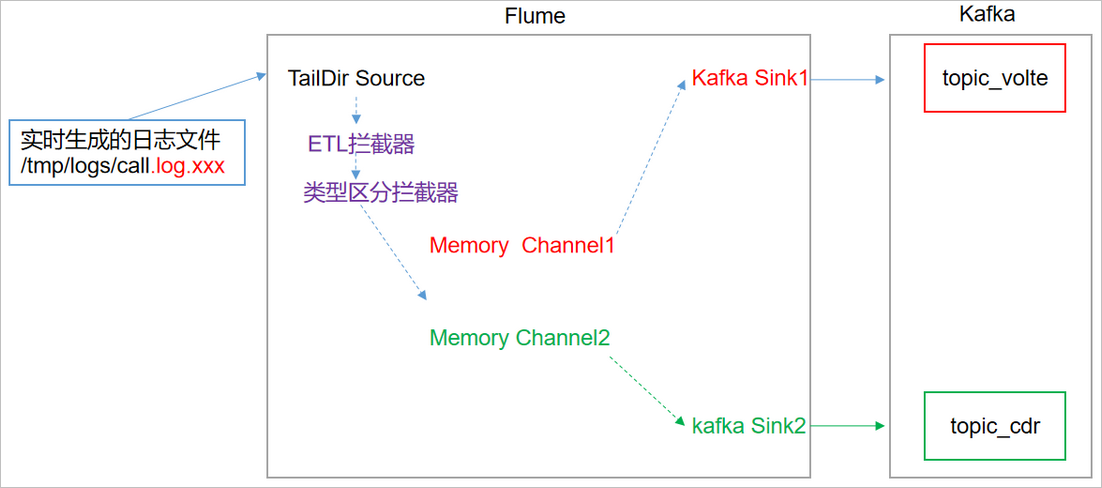
Specific configuration of Flume
(1) Create the flume1.conf file in the / opt / data / callogs / flume1 / directory
[hadoop@hadoop101 conf]$ vim flume1.conf
Configure the following in the file
a1.sources=r1 a1.channels=c1 c2 a1.sinks=k1 k2 # configure source a1.sources.r1.type = TAILDIR a1.sources.r1.positionFile = /opt/datas/calllogs/flume/log_position.json a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/datas/calllogs/records/calllogs.+ a1.sources.r1.fileHeader = true a1.sources.r1.channels = c1 c2 #interceptor a1.sources.r1.interceptors = i1 i2 a1.sources.r1.interceptors.i1.type = com.cmcc.jackyan.flume.interceptor.LogETLInterceptor$Builder a1.sources.r1.interceptors.i2.type = com.cmcc.jackyan.flume.interceptor.LogTypeInterceptor$Builder # selector a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = recordType a1.sources.r1.selector.mapping.volte= c1 a1.sources.r1.selector.mapping.cdr= c2 # configure channel a1.channels.c1.type = memory a1.channels.c1.capacity=10000 a1.channels.c1.byteCapacityBufferPercentage=20 a1.channels.c2.type = memory a1.channels.c2.capacity=10000 a1.channels.c2.byteCapacityBufferPercentage=20 # configure sink # start-sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = topic_volte a1.sinks.k1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092 a1.sinks.k1.kafka.flumeBatchSize = 2000 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.channel = c1 # event-sink a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k2.kafka.topic = topic_cdr a1.sinks.k2.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092 a1.sinks.k2.kafka.flumeBatchSize = 2000 a1.sinks.k2.kafka.producer.acks = 1 a1.sinks.k2.channel = c2
Note: com cmcc. jackyan. flume. interceptor. Logetlinterceptor and com jackyan. flume. interceptor. Logtypeinterceptor is the full class name of a custom interceptor. It needs to be modified according to the user-defined interceptor.
4.3. 3 custom Flume interceptor
Two interceptors are customized here: ETL interceptor and log type discrimination interceptor.
ETL interceptor is mainly used to filter logs with illegal timestamp and incomplete json data
The log type discrimination interceptor is mainly used to distinguish volte bills from other bills to facilitate different topic s sent to kafka.
1) Create maven module flume interceptor
2) Create package name: com cmcc. jackyan. flume. interceptor
3) In POM Add the following configuration to the XML file
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.7.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.cmcc.jackyan.appclient.AppMain</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
4) On COM cmcc. jackyan. flume. Create LogETLInterceptor class name under interceptor package
Flume ETL interceptor LogETLInterceptor
public class LogETLInterceptor implements Interceptor {
//Print log for debugging
private static final Logger logger = LoggerFactory.getLogger(LogETLInterceptor.class);
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
String body = new String(event.getBody(), Charset.forName("UTF-8"));
// logger.info("Before:" + body);
event.setBody(LogUtils.addTimeStamp(body).getBytes());
body = new String(event.getBody(), Charset.forName("UTF-8"));
// logger.info("After:" + body);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> intercepts = new ArrayList<>();
// Traverse all events and filter out illegal events
for (Event event : events) {
Event interceptEvent = intercept(event);
if (interceptEvent != null) {
intercepts.add(event);
}
}
return intercepts;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
4) Flume log processing tool class
public class LogUtils {
private static Logger logger = LoggerFactory.getLogger(LogUtils.class);
/**
* Splice a timestamp for the log
*
* @param log
*/
public static String addTimeStamp(String log) {
//{"cdrGenTime":"20211207091838913","channelCode":"k82Ce","charge":"86.14","dataDownLinkVolume":"3083","dataUpLinkVolume":"2311","duration":"133","homeProvinceCode":"210","imsi":"460004320498004","msisdn":"17268221069","recordType":"mms","resultCode":"000000","serviceCode":"711869363795868","serviceName":"H79cKXuJO4","sysId":"aGIL4","visitProvinceCode":"220"}
long t = System.currentTimeMillis();
return t + "|" + log;
}
}
5) Flume log type distinguishing interceptor LogTypeInterceptor
public class LogTypeInterceptor implements Interceptor {
//Print log for debugging
private static final Logger logger = LoggerFactory.getLogger(LogTypeInterceptor.class);
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 1 get flume receive message header
Map<String, String> headers = event.getHeaders();
// 2 get the json data array received by flume
byte[] json = event.getBody();
// Convert json array to string
String jsonStr = new String(json);
String recordType = "" ;
// volte
if (jsonStr.contains("volte")) {
recordType = "volte";
}
// cdr
else {
recordType = "cdr";
}
// 3 store the log type in the flume header
headers.put("recordType", recordType);
// logger.info("recordType:" + recordType);
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> interceptors = new ArrayList<>();
for (Event event : events) {
Event interceptEvent = intercept(event);
interceptors.add(interceptEvent);
}
return interceptors;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
6) Pack
After the interceptor is packaged, it only needs a separate package, and there is no need to upload the dependent package. After packaging, put it under the lib folder of flume.
7) You need to put the packed package under the / opt/modules/flume/lib folder of Hadoop 101.
[hadoop@hadoop101 lib]$ ls | grep interceptor flume-interceptor-1.0-SNAPSHOT.jar
8) Start flume
[hadoop@hadoop101 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file /opt/datas/calllogs/flume1/flume1.conf &
4.3. 4 log collection Flume start stop script
1) Create the script calllog-flume1.0 in the / home/hadoop/bin directory sh
[hadoop@hadoop101 bin]$ vim calllog-flume1.sh
Fill in the script as follows
#! /bin/bash
case $1 in
"start"){
for i in hadoop101
do
echo " --------start-up $i consumption flume-------"
ssh $i "nohup /opt/modules/flume/bin/flume-ng agent --conf /opt/modules/flume/conf/ --conf-file /opt/datas/calllogs/flume1/flume1.conf &"
done
};;
"stop"){
for i in hadoop101
do
echo " --------stop it $i consumption flume-------"
ssh $i "ps -ef | grep flume1 | grep -v grep | awk '{print \$2}' | xargs kill -9"
done
};;
esac
Note: nohup, this command can continue to run the corresponding process after you exit the account / close the terminal. Nohup means not to hang.
2) Increase script execution permission
[hadoop@hadoop101 bin]$ chmod +x calllog-flume1.sh
3) flume1 cluster startup script
[hadoop@hadoop101 modules]$ calllog-flume1.sh start
4) flume1 cluster stop script
[hadoop@hadoop101 modules]$ calllog-flume1.sh stop
4.4 Kafka environmental preparation
| Hadoop101 | Hadoop102 | Hadoop103 | |
|---|---|---|---|
| Kafka | Kafka | Kafka | Kafka |
4.4.1 Kafka cluster start stop script
1) Create the script kafka.com in the / home/hadoop/bin directory sh
[hadoop@hadoop101 bin]$ vim kafka.sh
Fill in the script as follows
#! /bin/bash
case $1 in
"start"){
for i in hadoop101 hadoop102 hadoop103
do
echo " --------start-up $i kafka-------"
# For KafkaManager monitoring
ssh $i "export JMX_PORT=9988 && /opt/modules/kafka/bin/kafka-server-start.sh -daemon /opt/modules/kafka/config/server.properties "
done
};;
"stop"){
for i in hadoop101 hadoop102 hadoop103
do
echo " --------stop it $i kafka-------"
ssh $i "ps -ef | grep server.properties | grep -v grep| awk '{print $2}' | xargs kill >/dev/null 2>&1 &"
done
};;
esac
Note: when starting Kafka, you should first open the JMX port for subsequent KafkaManager monitoring.
2) Increase script execution permission
[hadoop@hadoop101 bin]$ chmod +x kafka.sh
3) kf cluster startup script
[hadoop@hadoop101 modules]$ kafka.sh start
4) kf cluster stop script
[hadoop@hadoop101 modules]$ kafka.sh stop
4.4. 2 view all Kafka topic s
[hadoop@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181 --list
4.4. 3 Create Kafka topic
Enter the / opt/modules/kafka / directory and create the startup log topic and event log topic respectively.
1) Create a volt theme
[hadoop@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --create --replication-factor 2 --partitions 3 --topic topic-volte
2) Create cdr theme
[hadoop@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --create --replication-factor 2 --partitions 3 --topic topic-cdr
4.4. 4 delete Kafka topic
[hadoop@hadoop101 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --topic topic-volte [hadoop@hadoop101 kafka]$ bin/kafka-topics.sh --delete --zookeeper hadoop101:2181,hadoop102:2181,hadoop103:2181 --topic topic-cdr
4.4. 5 production message
[hadoop@hadoop101 kafka]$ bin/kafka-console-producer.sh \ --bootstrap-server hadoop101:9092 --topic topic-volte >hello world >hadoop hadoop
4.4. 6 consumption news
[hadoop@hadoop102 kafka]$ bin/kafka-console-consumer.sh \ --bootstrap-server hadoop101:9092 --from-beginning --topic topic-volte
--From beginning: all previous data in the first topic will be read out. Select whether to add the configuration according to the business scenario.
4.4. 7 view the details of a Topic
[hadoop@hadoop101 kafka]$ bin/kafka-topics.sh --zookeeper hadoop101:2181 \ --describe --topic topic-volte
4.5 write flume consumption Kafka data to HDFS
| Hadoop101 | Hadoop102 | Hadoop103 | |
|---|---|---|---|
| Flume (consumption kafka) | Flume |
Configuration analysis
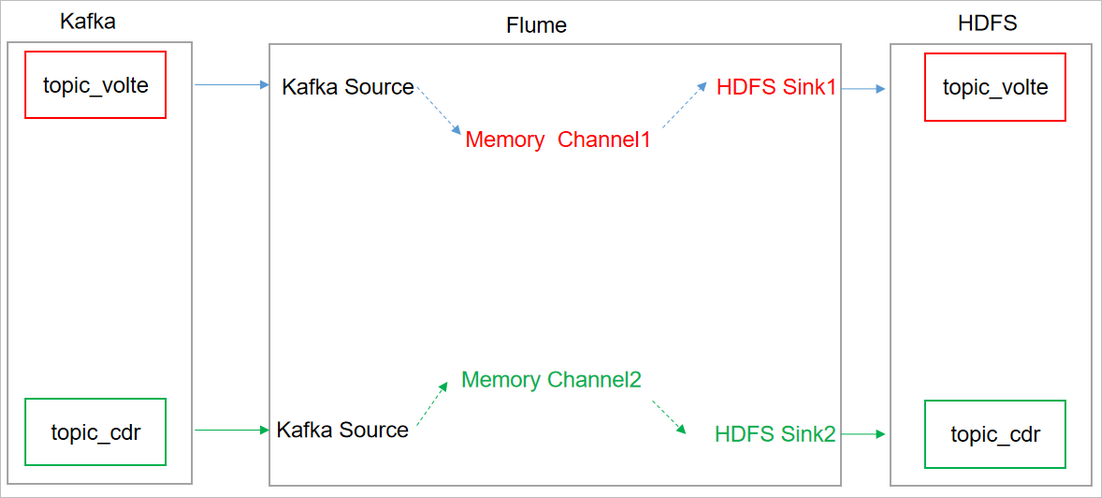
Specific configuration of Flume
(1) Create the flume2.conf file in the / opt / data / callogs / flume2 / directory of Hadoop 103
[hadoop@hadoop101 conf]$ vim flume2.conf
Configure the following in the file
## assembly a1.sources=r1 r2 a1.channels=c1 c2 a1.sinks=k1 k2 ## source1 a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 a1.sources.r1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092 a1.sources.r1.kafka.zookeeperConnect = hadoop101:2181,hadoop102:2181,hadoop103:2181 a1.sources.r1.kafka.topics=topic-volte ## source2 a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r2.batchSize = 5000 a1.sources.r2.batchDurationMillis = 2000 a1.sources.r2.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092 a1.sources.r2.kafka.zookeeperConnect = hadoop101:2181,hadoop102:2181,hadoop103:2181 a1.sources.r2.kafka.topics=topic-cdr ## channel1 a1.channels.c1.type=memory a1.channels.c1.capacity=100000 a1.channels.c1.transactionCapacity=10000 ## channel2 a1.channels.c2.type=memory a1.channels.c2.capacity=100000 a1.channels.c2.transactionCapacity=10000 ## sink1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /origin_data/calllogs/records/topic-volte/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = volte- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 30 a1.sinks.k1.hdfs.roundUnit = second ##sink2 a1.sinks.k2.type = hdfs a1.sinks.k2.hdfs.path = /origin_data/calllogs/records/topic-cdr/%Y-%m-%d a1.sinks.k2.hdfs.filePrefix = cdr- a1.sinks.k2.hdfs.round = true a1.sinks.k2.hdfs.roundValue = 30 a1.sinks.k2.hdfs.roundUnit = second ## Do not generate a large number of small files a1.sinks.k1.hdfs.rollInterval = 30 a1.sinks.k1.hdfs.rollSize = 0 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k2.hdfs.rollInterval = 30 a1.sinks.k2.hdfs.rollSize = 0 a1.sinks.k2.hdfs.rollCount = 0 ## The control output file is a native file. a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k2.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = lzop a1.sinks.k2.hdfs.codeC = lzop ## Assembly a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1 a1.sources.r2.channels = c2 a1.sinks.k2.channel= c2
4.5.2 Flume exception handling
1) Problem Description: if Flume starts consumption, the following exception is thrown
ERROR hdfs.HDFSEventSink: process failed java.lang.OutOfMemoryError: GC overhead limit exceeded
2) Solution steps:
(1) Add the following configuration in / opt / modules / flume / conf / flume env.sh file of Hadoop 101 server
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
(2) Synchronize configuration to Hadoop 102 and Hadoop 103 servers
[hadoop@hadoop101 conf]$ xsync flume-env.sh
4.5. 2 log consumption Flume start stop script
1) Create the script calllog-flume2.0 in the / home/hadoop/bin directory sh
[hadoop@hadoop101 bin]$ vim calllog-flume2.sh
Fill in the script as follows
#! /bin/bash
case $1 in
"start"){
for i in hadoop103
do
echo " --------start-up $i consumption flume-------"
ssh $i "nohup /opt/modules/flume/bin/flume-ng agent --conf /opt/modules/flume/conf/ --conf-file /opt/datas/calllogs/flume2/flume2.conf &"
done
};;
"stop"){
for i in hadoop103
do
echo " --------stop it $i consumption flume-------"
ssh $i "ps -ef | grep flume2 | grep -v grep | awk '{print \$2}' | xargs kill -9"
done
};;
esac
2) Increase script execution permission
[hadoop@hadoop101 bin]$ chmod +x calllog-flume2.sh
3) Cluster startup script
[hadoop@hadoop101 modules]$ calllog-flume2.sh start
4) Cluster stop script
[hadoop@hadoop101 modules]$ calllog-flume2.sh stop
4.6 acquisition channel start / stop script
1) Create the script cluster in the / opt / data / callogs directory sh
[hadoop@hadoop101 calllogs]$ vim cluster.sh
Fill in the script as follows
#! /bin/bash
case $1 in
"start"){
echo " -------- Start cluster -------"
echo " -------- start-up hadoop colony -------"
/opt/modules/hadoop-2.7.2/sbin/start-dfs.sh
ssh hadoop102 "/opt/modules/hadoop-2.7.2/sbin/start-yarn.sh"
#Start Zookeeper cluster
zk.sh start
#Start Flume collection cluster
calllog-flume1.sh start
#Start Kafka collection cluster
kafka.sh start
sleep 4s;
#Start Flume consumption cluster
calllog-flume2.sh start
};;
"stop"){
echo " -------- Stop cluster -------"
#Stop Flume consumption cluster
calllog-flume2.sh stop
#Stop Kafka collection cluster
kafka.sh stop
sleep 4s;
#Stop Flume collection cluster
calllog-flume1.sh stop
#Stop Zookeeper cluster
zk.sh stop
echo " -------- stop it hadoop colony -------"
ssh hadoop102 "/opt/modules/hadoop-2.7.2/sbin/stop-yarn.sh"
/opt/modules/hadoop-2.7.2/sbin/stop-dfs.sh
};;
esac
2) Increase script execution permission
[hadoop@hadoop101 calllogs]$ chmod +x cluster.sh
3) Cluster cluster startup script
[hadoop@hadoop101 calllogs]$ ./cluster.sh start
4) Cluster cluster stop script
[hadoop@hadoop101 calllogs]$ ./cluster.sh stop