preface
As we all know, Binder is the main interprocess communication suite in the Android system. More specifically, many articles call it Binder driver. Why is it a driver? What is the driver? Let's uncover it step by step from the Binder in the kernel from the bottom up. This article focuses on helping readers have a brief understanding of Binder system, so it is written in a general way. Subsequent articles will analyze it in detail.
What the hell is Binder
The Android system kernel is Linux, and each process has its own virtual address space. Under the 32-bit system, the maximum is 4GB, of which 3GB is the user space and 1GB is the kernel space; The user space of each process is relatively independent, while the kernel space is the same and can be shared, as shown in the following figure
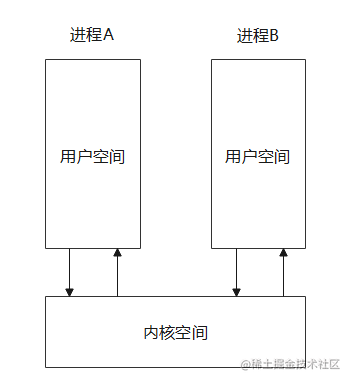
Linux driver runs in kernel space. In a narrow sense, it is an intermediate program used by the system to control hardware, but in the final analysis, it is only a program and a piece of code, so the specific implementation does not have to be related to hardware. Binder registers itself as a misc type driver, does not involve hardware operation, and runs in the kernel, so it can be used as a bridge between different processes to realize IPC functions.
The biggest feature of Linux is that everything is a file, and the driver is no exception. All drivers will be mounted in the File System Dev directory. The corresponding directory of Binder is / dev/binder. When registering the driver, register system calls such as open release mmap with Binder's own functions. In this way, Binder can be used in user space by accessing files through system calls. Let's take a rough look at the relevant code.
device\_ The initcall function is used to register the driver and is called by the system
binder\_ Calling misc\_ in init Register registers a misc driver named binder, and specifies the function mapping to bind the binder\_open is mapped to the system call open, so that the binder can be called through open("/dev/binder")\_ The open function
// Drive function mapping
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
// Register driver parameter structure
static struct miscdevice binder_miscdev = {
.minor = MISC_DYNAMIC_MINOR,
// Drive name
.name = "binder",
.fops = &binder_fops
};
static int binder_open(struct inode *nodp, struct file *filp){......}
static int binder_mmap(struct file *filp, struct vm_area_struct *vma){......}
static int __init binder_init(void)
{
int ret;
// Create a single threaded work queue named binder
binder_deferred_workqueue = create_singlethread_workqueue("binder");
if (!binder_deferred_workqueue)
return -ENOMEM;
......
// Registration driver, misc device is actually a special character device
ret = misc_register(&binder_miscdev);
......
return ret;
}
// Driver registration function
device_initcall(binder_init);Binder's brief communication process
How does a process communicate with another process through a binder? The simplest process is as follows
- The receiving end process starts a special thread, registers the process in the binder driver (kernel) through system call (creates and saves a bidner\_proc), and the driver creates a task queue (binder \ _proc. Todo) for the receiving end process
- The receiving end thread starts an infinite loop and keeps accessing the binder driver through system calls. If there are tasks in the task queue corresponding to the process, it returns to processing. Otherwise, the thread is blocked until new tasks are queued
- The sender also accesses the target process through system call, finds the target process, throws the task into the queue of the target process, and then wakes up the dormant thread in the target process to process the task, that is, to complete communication
Use Binder in Binder driver\_ The proc structure represents a process, the binder\_thread represents a thread, binder\_proc.todo is the task queue from other processes that the process needs to process.
struct binder_proc {
// Store all binders_ Linked list of proc
struct hlist_node proc_node;
// binder_thread red black tree
struct rb_root threads;
// binder_ A red black tree composed of binder entities in the proc process
struct rb_root nodes;
......
}A copy of Binder
As we all know, Binder's advantage lies in its high efficiency of one-time copy. Many blogs have said bad. So what is a copy, how to implement it, and where it happens, let's explain it briefly as much as possible.
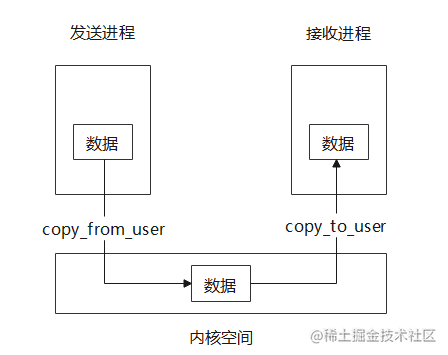
As mentioned above, different processes communicate through Binder drivers in the kernel, but the user space and kernel space are separated and cannot access each other. They need to use copy to transfer data between them\_ from\_ User and copy\_to\_user two system calls to copy the data in the user / kernel space memory to the kernel / user space memory. In this way, if the two processes need one-way communication, they need two copies, as shown in the figure below.
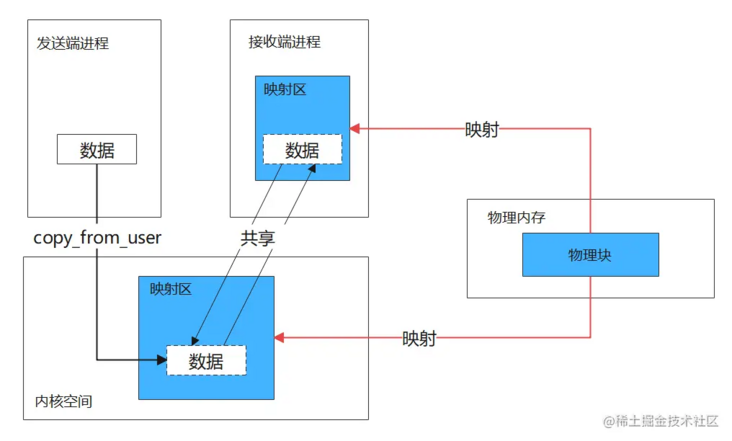
Binder only needs one copy for a single communication, because it uses memory mapping to map a piece of physical memory (several physical pages) to the user space and kernel space at the receiving end respectively, so as to share data in user space and kernel space.
When the sender wants to send data to the receiver, the kernel directly uses copy\_ from\_ The user copies the data to the kernel space mapping area. At this time, due to the shared physical memory, the memory mapping area of the receiving process can get the data, as shown in the following figure.
Code implementation part
The user space calls the Binder in the Binder driver through the mmap system call\_ mmap function for memory mapping. This part of the code is difficult to read. You can take a look at it if you are interested.
binder_mmap create binder\_buffer, record the process memory mapping related information (user space mapping address, kernel space mapping address, etc.), binder_buffer.data is the pointer of the physical memory block shared by the receiving process and the kernel
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
//Kernel virtual space
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
// Every time Binder transfers data, a Binder will be allocated from Binder memory cache first_ Buffer to store transmission data
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
// Ensure that the memory mapping size does not exceed 4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
......
// The IOREMAP method is adopted to allocate a continuous kernel virtual space, which is consistent with the size of the user process virtual space
// vma is a virtual space structure passed from user space
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
// Address to kernel virtual space
proc->buffer = area->addr;
// User virtual space start address - kernel virtual space start address
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
......
// Allocate the pointer array of the physical page. The array size is the number of equivalent pages of vma
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
// Allocate a physical page and map it to kernel space and process space at the same time. Allocate a physical page first
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
// buffer insert linked list
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
// The available size of oneway asynchronous is half of the total space
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
}binder_ update_ page_ The range function allocates a physical page for the mapped address. Here, a physical page (4KB) is allocated first, and then the physical page is mapped to both user space address and memory space address
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
// Start address of kernel mapping area
void *page_addr;
// Starting address of user mapping area
unsigned long user_page_addr;
struct page **page;
// Memory structure
struct mm_struct *mm;
if (end <= start)
return 0;
......
// Circularly allocate all physical pages, and establish the mapping of user space and kernel space to the physical page respectively
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
// Allocate one page of physical memory
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
if (*page == NULL) {
pr_err("%d: binder_alloc_buf failed for page at %p\n",
proc->pid, page_addr);
goto err_alloc_page_failed;
}
// Mapping physical memory to kernel virtual space
ret = map_kernel_range_noflush((unsigned long)page_addr,
PAGE_SIZE, PAGE_KERNEL, page);
flush_cache_vmap((unsigned long)page_addr,
// User space address = kernel address + offset
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
// Mapping physical space to user virtual space
ret = vm_insert_page(vma, user_page_addr, page[0]);
}
}Binder_ Calling Binder_ in MMAP function update_ page_ Range only allocates a physical page space for the mapping area. When Binder starts communication, it will use the Binder again_ alloc_ The buf function allocates more physical pages, which will be discussed later.
Binder suite architecture
The Binder driver in the kernel layer has provided IPC function, but it is also necessary to provide some call encapsulation for the driver layer in the framework native layer to make it easier for framework developers to use, so as to encapsulate the native Binder; At the same time, because the framework native layer is implemented in c/c + + language, application developers need more convenient encapsulation of Java layer to derive Java Binder; Finally, in order to reduce repeated code writing and standardize the interface, AIDL is encapsulated on the basis of Java Binder. After layers of encapsulation, users are basically unaware of Binder when using AIDL.
Here is an architecture diagram.
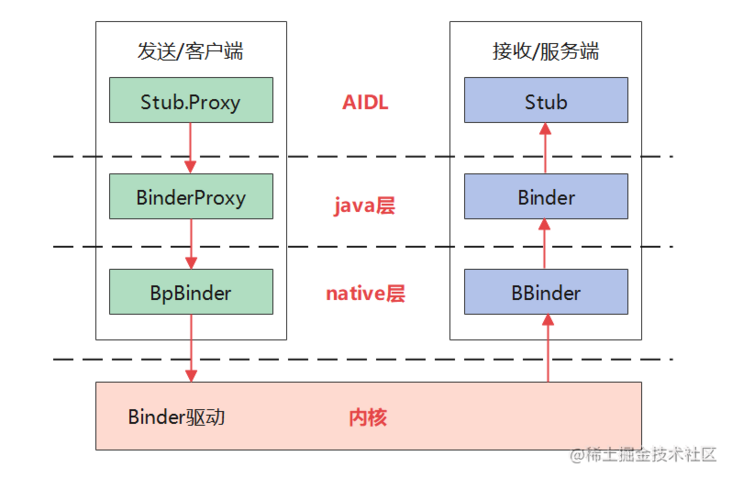
Native layer
BpBinder represents an agent of the server Binder. There is a member mHandle inside, which is the handle of the server Binder in the driver layer. The client passes in the handle by calling BpBinder::transact, generates a session with the server BBinder through the driver layer, and finally the server will call BBinder::onTransact. Here, the agreed code is used to identify the conversation content between the two.
As mentioned earlier, processes that need to communicate with binder need to register the process in the driver first, and a thread is required to read and write the binder driver in an endless loop during each communication. A process in the driver layer corresponds to a binder\_proc, a thread corresponds to a binder\_thread; In the framework native layer, a process corresponds to a ProcessState, a thread corresponds to an IPCThreadState, and BpBinder::transact initiates communication through IPCThreadState Transact calls the driver.
In fact, every application process in Android opens the Binder driver (registered in the driver), and the Zygote process calls the app\_ after the fork application process. main. The onZygoteInit function in CPP is initialized. In this function, the ProcessState instance of the process is created. Open the binder driver and allocate the mapping area. A binder of the process is also created and saved in the driver\_ Proc instance. Let's borrow a picture to describe it. 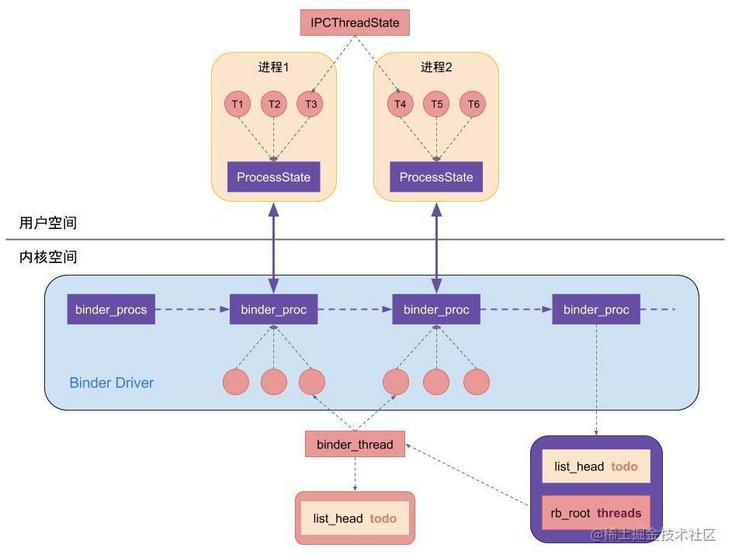
Java layer
The Java layer encapsulates the relevant classes of the native layer. BBinder corresponds to Binder, BpBinder corresponds to BinderProxy, and the Java layer will finally call the corresponding functions of the native layer
AIDL
The code generated by Aidl further encapsulates Binder, < interface > Stub corresponds to server Binder, < interface > Stub. Proxy identifies the client, holds an mRemote instance (BinderProxy) internally, and Aidl generates several transactions according to the defined interface methods_< Function name > code constant, binders at both ends identify and resolve parameters through these codes, and call corresponding interface methods. In other words, Aidl is for BinderProxy Transact and Binder Ontransact is encapsulated, and users do not have to define the code and parameter resolution of each communication.
Postscript
This article mainly provides a general understanding for readers who do not understand Binder system. The next article will start from AIDL remote service and analyze the whole IPC process layer by layer. Therefore, if you want to further understand Binder, this article is also important as a pre knowledge.
Relevant video recommendations:
This article is transferred from https://juejin.cn/post/6987595923543031821 , in case of infringement, please contact to delete.