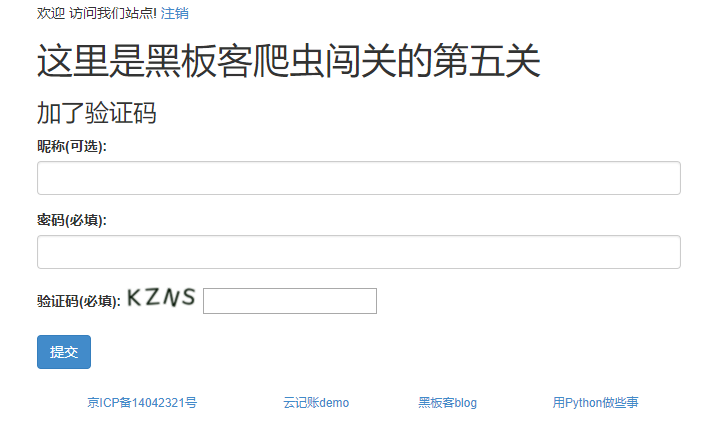
This is the fifth level of reptile in blackboard class
Same need to log in
On the basis of the above, although it is not as complicated as the fourth pass, the verification code link is added here, which is very hard. At that time, it took a lot of effort to install the relevant python package configuration environment, mainly using two kinds of libraries, i.e. pyteseract and Image. I don't know much about them Look here , I don't know much about the verification code, so I simply called the method provided on the Internet, and then the others are almost the same as before
Streamlined process
- Landing verification
- Verification code verification
- Password login attempt
Just repeat the next two steps
Provide several versions for your reference
One.py (in principle, the code logic is OK, but the speed is extremely slow, and the verification code identification is not very clear, so sometimes there is a problem in the final result output. You can try it and help me find the wrong one)
import re import requests from lxml import etree import pytesseract from PIL import Image,ImageEnhance def verification_Code(img_url): #Save verification code imgs = requests.get(img_url).content with open('1.jpg', 'wb') as f: f.write(imgs) image = Image.open('1.jpg') imgry = image.convert('L')#Image enhancement, binarization sharpness = ImageEnhance.Contrast(imgry)#Contrast enhancement sharp_img = sharpness.enhance(2.0) sharp_img.save('1.jpg') text = pytesseract.image_to_string(image) return text def login(): login_url = "http://www.heibanke.com/accounts/login" session = requests.Session() token = session.get(login_url).cookies['csrftoken'] data = { 'username': 'Koelre', 'password': 'lixue961314', 'csrfmiddlewaretoken': token } session.post(login_url, data) print("Login successfully") return session def ex05(a=1,password=1): url = "http://www.heibanke.com/lesson/crawler_ex04/" session = login() html = session.get(url).text etr = etree.HTML(html) token = etr.xpath('/html/body/div/div/div[2]/form/input/@value')[0].strip() img_src = etr.xpath('/html/body/div/div/div[2]/form/div[3]/img/@src')[0].strip() #Verification code connection img_url = 'http://www.heibanke.com' + str(img_src) #Picture code pic_code = etr.xpath('//*[@id="id_captcha_0"]/@value')[0] text = verification_Code(img_url) data = { "csrfmiddlewaretoken": token, "username": "a", "password": password, "captcha_0": pic_code, "captcha_1": text } res = session.post(url, data).text verification_result = re.findall("Verification code input error", res) passwd_result = re.findall('The password you entered is wrong', res) h3 = re.findall('<h3>(.*?)</h3>', res) if verification_result: print(h3) print(text) print("retry") ex05(a+1, password) else: if passwd_result: print(h3) print("Password:%s error" %password) ex05(a, password+1) else: print("The password is:%s" %password) print(h3) if __name__ == '__main__': ex05()
two.py
""" //Blackboard guest, reptile, the fifth hurdle http://www.heibanke.com/lesson/crawler_ex04 //Verification code processing answer is 22 """ import Image from PIL import Image from io import BytesIO import pytesseract import bs4 from bs4 import BeautifulSoup import requests import os import re pytesseract.pytesseract.tesseract_cmd = "D:\\Program Files (x86)\\Tesseract-OCR\\tesseract" url = "http://www.heibanke.com/lesson/crawler_ex04/" login_url = "http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex04/" data={'username': 'medyg', 'password': '19931122bihu', 'csrfmiddlewaretoken': ''} """ Open landing page """ loginr = requests.get(login_url) if loginr.status_code == 200: cookie = loginr.cookies print("get login_url success, csrftoken is :" + cookie['csrftoken']) else: print("get login_url failed") data['csrfmiddlewaretoken'] = cookie['csrftoken'] """ Land """ signinr = requests.post(login_url, data = data, allow_redirects = False, cookies = cookie) if signinr.status_code == 302: cookie2 = signinr.cookies print("post login_url success, csrftoken is :" + cookie2['csrftoken']) else: print("post login_url failed, status_code is " + str(signinr.status_code)) data['csrfmiddlewaretoken'] = cookie2['csrftoken'] """ Obtain and identify the verification code( Using Tesseract-Ocr) """ guesses = 0 guess_success = 0 def get_captcha(): global guesses print("\n Start getting the%d Secondary verification code" % guesses) captchar = requests.get(url, cookies = cookie2) soup = BeautifulSoup(captchar.text, "lxml") img_src = soup.find('img', class_='captcha').get('src') img_url = "http://www.heibanke.com" + img_src captcha_0_value = soup.find('input', id="id_captcha_0").get('value') data['captcha_0'] = captcha_0_value imgr = requests.get(img_url) if imgr.status_code == 200: print("Verification code picture obtained successfully") captcha_img = Image.open(BytesIO(imgr.content)) # content is the type of bytes else: print("Failed to get the captcha picture, get it again") return get_captcha() #captcha_img.show() print("Identifying") captcha_1 = pytesseract.image_to_string(captcha_img) # Using testeract to identify the verification code captcha_1 = captcha_1.strip() captcha_1 = captcha_1.replace(' ', '') guesses += 1 if not re.match('^[A-Z | a-z]{4}$', captcha_1): print("Verification code identification failed:" + captcha_1) return get_captcha() else: print("Verification code identification succeeded:" + captcha_1) return captcha_0_value, captcha_1 """ Guess password """ pw = 0 while True: captcha_0_value, captcha_1 = get_captcha() guess_data = { 'username' : 'medyg', 'password' : pw, 'csrfmiddlewaretoken' : cookie2['csrftoken'], 'captcha_0' : captcha_0_value, 'captcha_1' : captcha_1 } print(guess_data) guessr = requests.post(url, guess_data, cookies = cookie2) if guessr.status_code == 200: soup = BeautifulSoup(guessr.text, 'lxml') h3 = soup.find('h3') if 'Verification code input error' in h3.text: print("If the verification code is wrong, re-enter the verification code. The recognition rate of the verification code is%f" % (float(guess_success) / guesses)) elif 'Password error' in h3.text: guess_success += 1 print("Password error, re-enter the password, the verification code recognition rate is%f" % (float(guess_success) / guesses)) pw += 1 else: guess_success += 1 print(h3.text) print("The password is%d,The verification code identification rate is%f" % (pw, (float(guess_success) / guesses))) break else: print("Request failed, re request%d" % guessr.status_code)
three.py
import requests from bs4 import BeautifulSoup import urllib.request from PIL import Image import pytesseract import re import os URL = 'http://www.heibanke.com/lesson/crawler_ex04/' LOGIN_URL = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex04/' login_page = requests.get(LOGIN_URL) login_data = { 'csrfmiddlewaretoken': login_page.cookies['csrftoken'], 'username': 'fuyufjh', 'password': '142857', } login_res = requests.post(LOGIN_URL, data=login_data, cookies=login_page.cookies, allow_redirects=False) number = 0 while True: prob_res = requests.get(URL, cookies=login_res.cookies) soup = BeautifulSoup(prob_res.text, 'lxml') captcha_id = soup.find(id='id_captcha_0')['value'] captcha_image_url = 'http://www.heibanke.com' + soup.find(alt='captcha')['src'] try: urllib.request.urlretrieve(captcha_image_url, 'captcha.png') vcode_img = Image.open('captcha.png') vcode = pytesseract.image_to_string(vcode_img, lang='eng') finally: os.remove('captcha.png') if not re.match(r'[A-Z]{4}$', vcode): print('recognizing failed') continue data = { 'username': 'fuyufjh', 'password': number, 'captcha_0': captcha_id, 'captcha_1': vcode, 'csrfmiddlewaretoken': prob_res.cookies['csrftoken'] } print(data) guess_res = requests.post(URL, data=data, cookies=login_res.cookies) if 'Verification code input error' in guess_res.text: print('verify code error') continue elif 'Password error' in guess_res.text: print('Password is not %d' % number) number += 1 else: print('Password is %d' % number) break
- Refer to my for more code details Github