What is a bloom filter
Bloom Filter was proposed by a young man named bloom in 1970. It has been 50 years since then.
It is actually a very long binary vector and a series of random mapping functions. Everyone should know that the stored data is either 0 or 1, and the default is 0.
It is mainly used to judge whether an element is in a set. 0 means there is no data and 1 means there is data.

Purpose of Bloom filter
-
Solve Redis cache penetration
-
For example: when crawling, filter the crawler website. The website already exists in bloom and will not be crawled.
-
For example: spam filtering, judge whether each email address is in Bloom's blacklist. If it is, it will be judged as spam.
Principle of Bloom filter
Deposit process
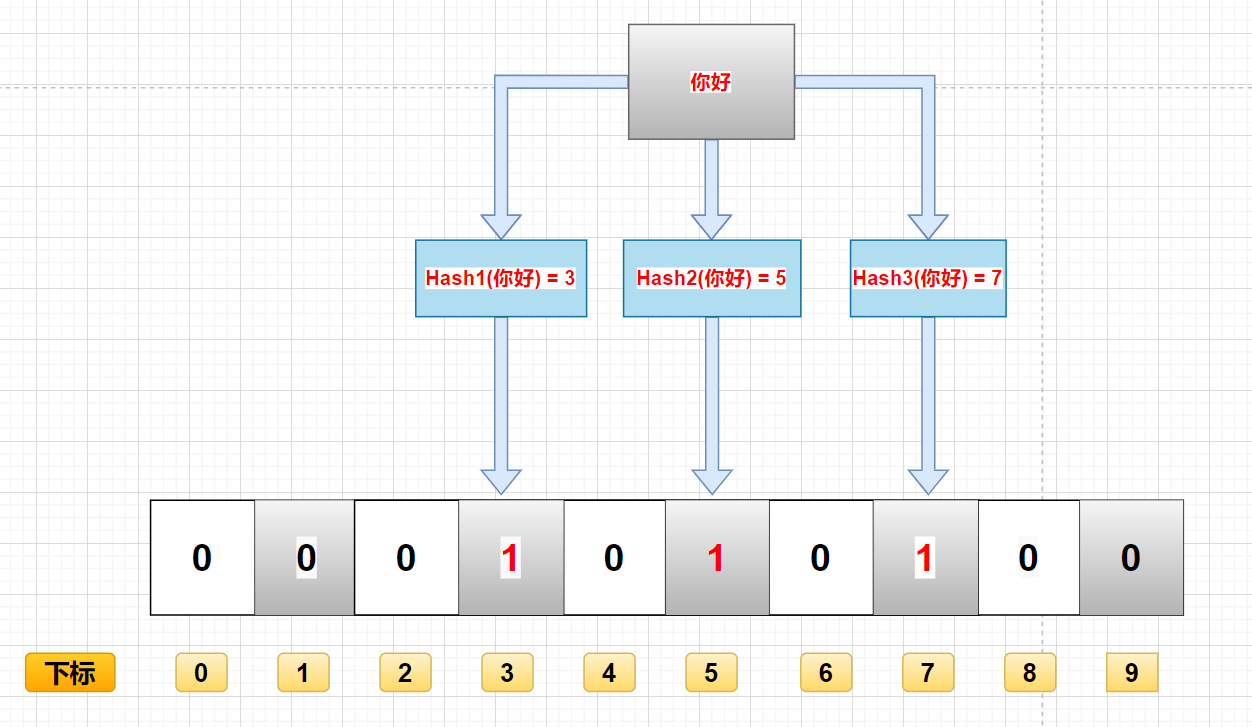
As mentioned above, bloom filter is a collection of binary data. When a data is added to this collection, it experiences the following baptism (there are shortcomings here, which will be discussed below):
- Calculate the data through k hash functions and return K calculated hash values
- These k hash values are mapped to the corresponding K binary array subscripts
- Change the binary data corresponding to K subscripts to 1.
For example, if the first hash function returns X and the second and third hash functions return y and Z, the binary corresponding to x, y and Z will be changed to 1.
Query process
The main function of Bloom filter is to query a data. If it is not in this binary set, the query process is as follows:
-
The data is calculated through K hash functions, corresponding to the calculated K hash values
-
Find the corresponding binary array index through the hash value
-
Judgment: if the binary data of a location is 0, the data does not exist. If they are all 1, the data exists in the set. (here, there will be shortcomings)
Delete process
Generally, the data in bloom filter cannot be deleted, which is one of the disadvantages, which will be analyzed below.
Advantages and disadvantages of Bloom filter
advantage
Because binary data is stored, the space occupied is very small
Its insertion and query speed is very fast, and the time complexity is O (K). You can think of the process of HashMap
Confidentiality is very good, because it does not store any original data, only binary data
shortcoming
This brings us back to the shortcomings we mentioned above.
If you add data by calculating the hash value of the data, it is likely that two different data will get the same hash value.
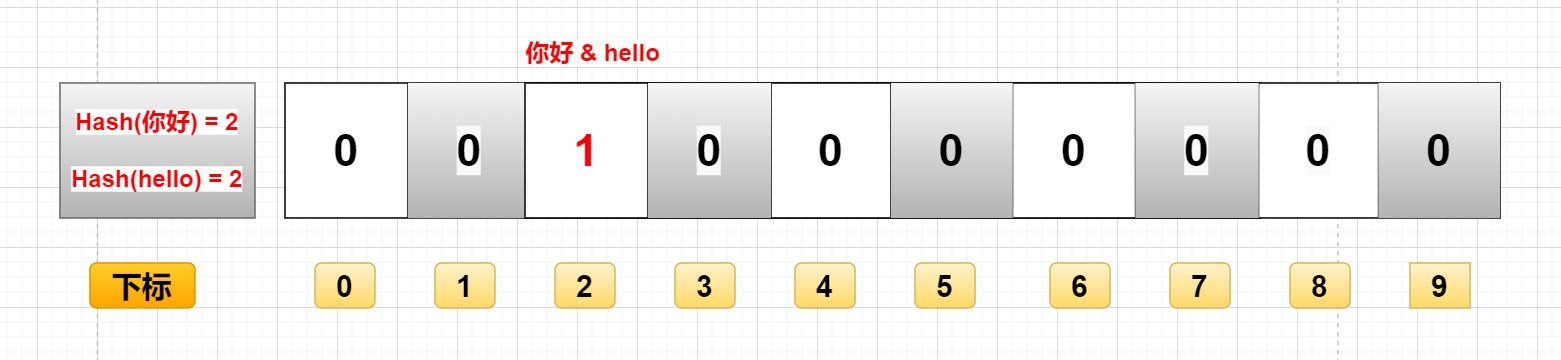
For example, "hello" and "hello" in the figure, if they finally calculate that the hash value is the same, they will change the binary data of the same subscript to 1. At this time, you don't know whether the binary with subscript 2 represents "hello" or "hello".
This leads to the following disadvantages:
-
There is misjudgment
If the above figure does not save "hello", but only "hello", then when you query with "hello", you will judge that "hello" exists in the set.
Because the hash values of "hello" and "hello" are the same. Through the same hash value, the binary data found is the same, which is 1. -
Delete difficulty
Still use the above example, because the hash values of "hello" and "hello" are the same, and the corresponding array subscripts are the same.
At this time, I want to delete "hello", even "hello". (0 means there is this data, 1 means there is no this data)
Realize bloom filter
There are many implementation methods, one of which is the implementation method provided by Guava.
- Introduction of Guava pom configuration
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>29.0-jre</version> </dependency>
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterCase {
/**
* How much data is expected to be inserted
*/
private static int size = 1000000;
/**
* Expected misjudgment rate
*/
private static double fpp = 0.01;
/**
* Bloom filter
*/
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
public static void main(String[] args) {
// Insert 100000 sample data
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
// Test the misjudgment rate with another 100000 test data
int count = 0;
for (int i = size; i < size + 100000; i++) {
if (bloomFilter.mightContain(i)) {
count++;
System.out.println(i + "Misjudged");
}
}
System.out.println("Total misjudgments:" + count);
}
}

Deep analysis of code
@VisibleForTesting
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
. . . .
}
parameter
- funnel: data type (usually in Funnels tool class)
- Expected inserts: the number of values expected to be inserted
- fpp: misjudgment rate (the default value is 0.03)
- strategy: hash algorithm
Adjust fpp misjudgment rate
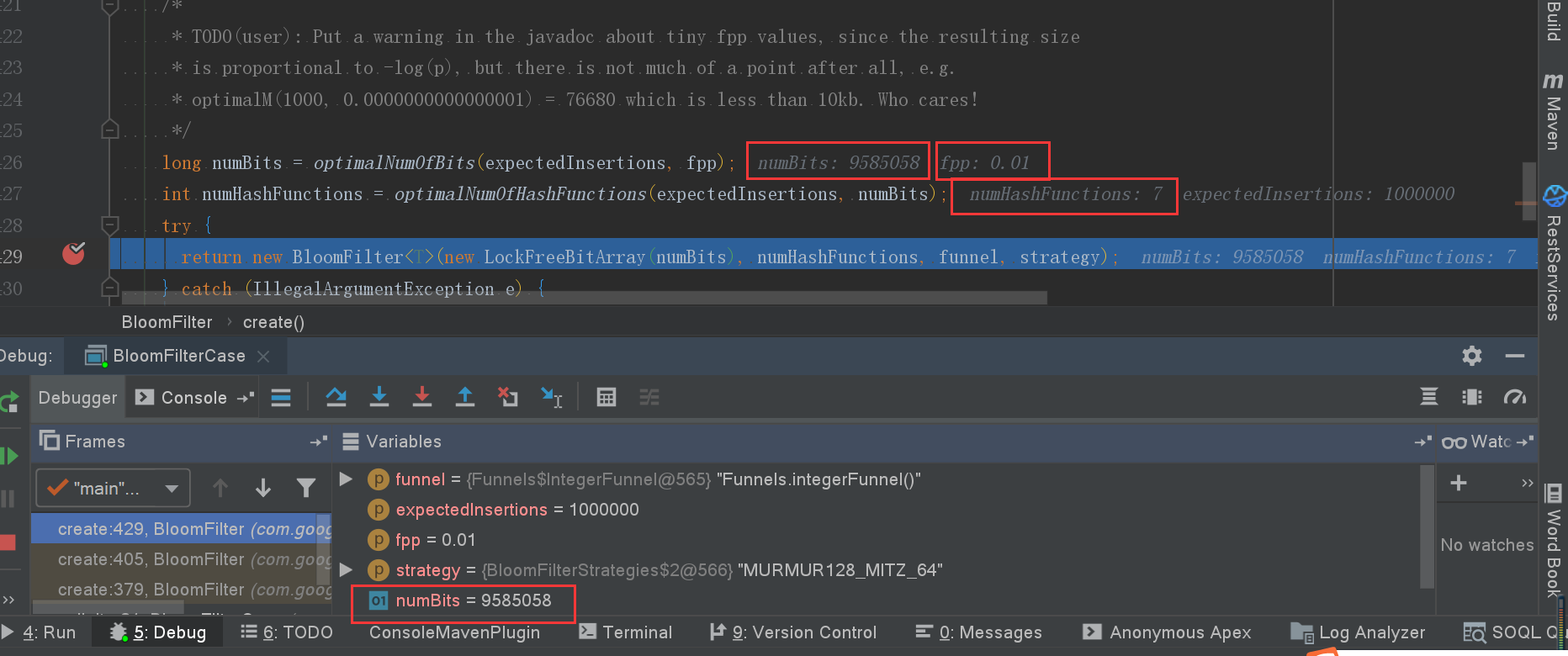
Scenario 1: fpp = 0.01
- Number of misjudgments: 947

- Memory size: 9585058 digits
Scenario summary
- The misjudgment rate can be adjusted by fpp parameters
- The smaller the fpp, the larger the memory space required: 0.01 needs more than 9 million bits, and 0.03 needs more than 7 million bits.
- The smaller the fpp, the more hash functions are needed to calculate more hash values to store in the corresponding array subscript when adding data to the set. (I forgot to look at the process of Bulong filtering and storing data above)
Redis cache penetration solution: bloom filter
Firstly, the hole layout filter is similar to a white list and blacklist. The main element is to judge whether the element exists in a filter. The core is here.
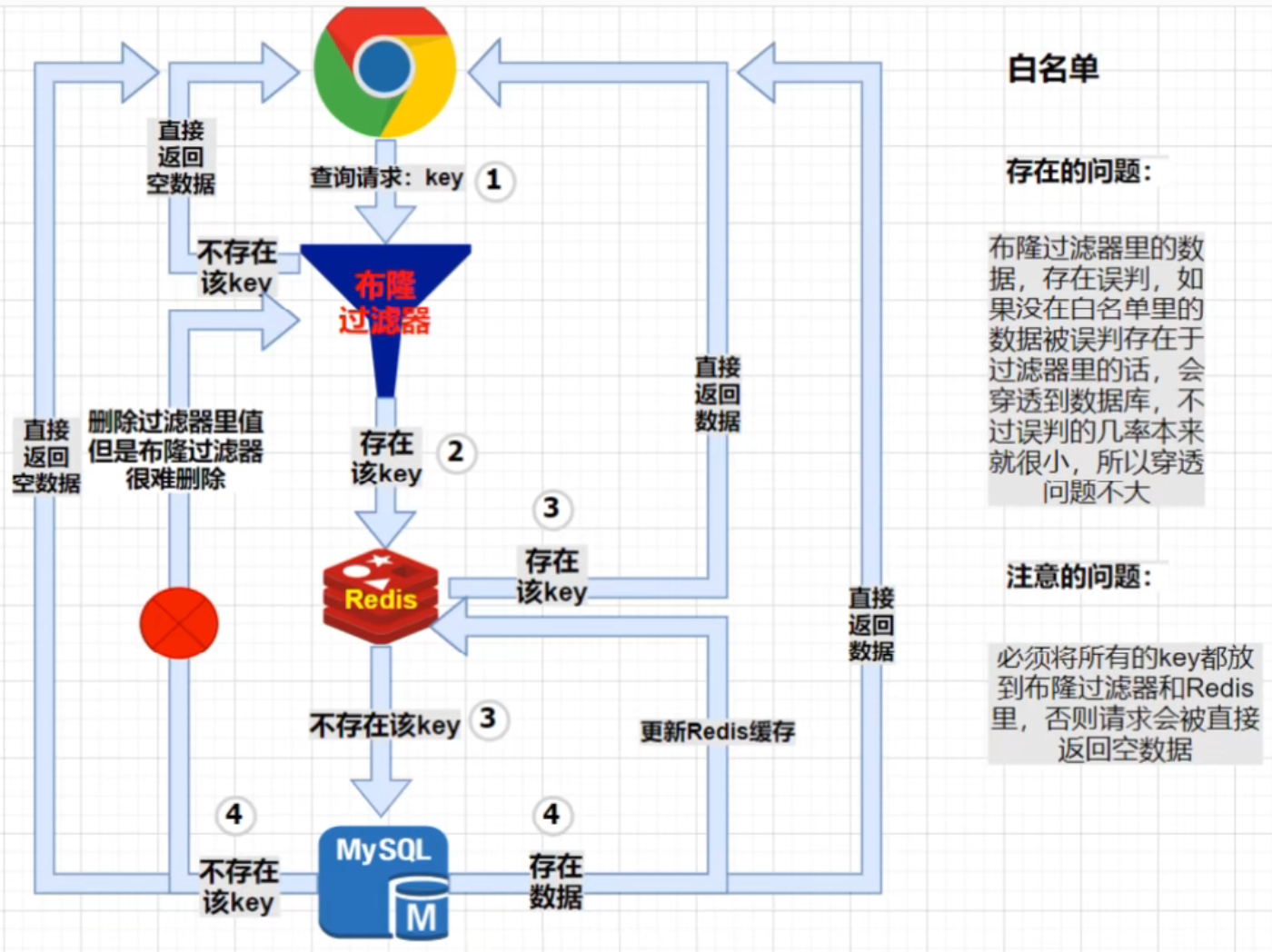
White list
Scenario:
The front end sends a query request through the parameter key, first through the bloom filter. If it does not exist in the filter (white list), it will be intercepted by the filter, and then directly return the empty data to the front end; If the key exists in the filter, the normal Redis and mysql query process will be executed;
Here is a process 4: if the key cannot be queried in mysql, what does it mean? Note that the key is in the white list and cannot be found in the singular mysql, which means that the bloom filter misjudged! Then, this route 4 is intended to delete this misjudgment to prevent the same request from being repeated next time. However, due to the hash collision of Bloom filter, it is difficult to delete (easy to be accidentally injured), so this route 4 is actually impossible!
be careful
- On the whole, as we mentioned earlier, the misjudgment probability of Bloom filter is relatively small, so the probability of directly hitting MySQL is small. Don't worry too much about this situation!
- All legal parameter key s should be put into bloom filter and Redis.
blacklist
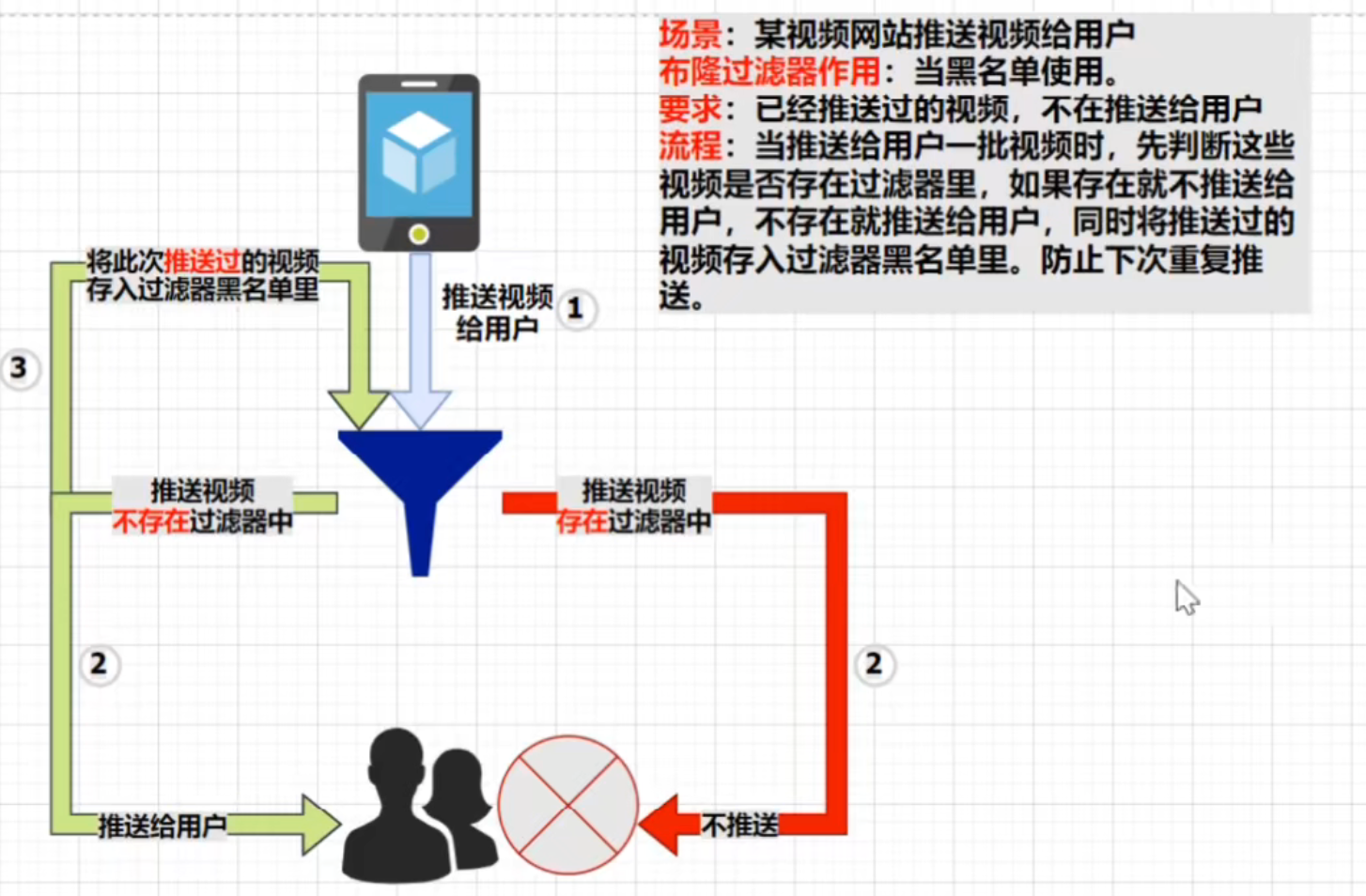
Scenario: a video website pushes videos to users
Bloom filter function: when blacklist is used.
Requirement: videos that have been pushed are no longer pushed to users
Process: when pushing a batch of videos to users, first judge whether these videos exist in the filter. If they exist, they will not be pushed to users. If they do not exist, they will be pushed to users. At the same time, the pushed videos will be stored in the filter blacklist. Prevent the next push.
code:
User entity class:
@Data
public class User implements Serializable {
public static String maYunPhone = "18890019390";
private Long id;
private String userName;
private Integer age;
}
/**
* Resolve cache penetration - white list
*/
public class RedissonBloomFilter {
/**
* Construct Redisson
*/
static RedissonClient redisson = null;
static RBloomFilter<String> bloomFilter = null;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//Redisson structure
redisson = Redisson.create(config);
//Structural bloom filter
bloomFilter = redisson.getBloomFilter("userIdFilter");
// Put the query data into Redis cache and bloom filter
initData(redisson, bloomFilter);
}
public static void main(String[] args) {
User user = getUserById(2L);
System.out.println("user Object is:" + JSON.toJSONString(user));
}
private static void initData(RedissonClient redisson, RBloomFilter<String> bloomFilter) {
//Initialize bloom filter: the expected element is 100000000L, and the error rate is 3%
bloomFilter.tryInit(100000000L,0.01);
//Insert the data with id 1 into the bloom filter
bloomFilter.add("1");
bloomFilter.add("2");
// Insert the user data corresponding to id 1 into the Redis cache
redisson.getBucket("1").set("{id:1, userName:'Zhang San', age:18}");
}
public static User getUserById(Long id) {
if (null == id) {
return null;
}
String idKey = id.toString();
// Start simulating cache penetration
// Front end query request key
if (bloomFilter.contains(idKey)) {
// After passing the filter white list verification, go to Redis to query the real data
RBucket<Object> bucket = redisson.getBucket(idKey);
Object object = bucket.get();
// If Redis has data, the data will be returned directly
if (null != object) {
System.out.println("from Redis Found in it");
String userStr = object.toString();
return JSON.parseObject(userStr, User.class);
}
// If Redis is empty, query the database
User user = selectByDb(idKey);
if (null == user) {
return null;
} else {
// Re flush data into cache
redisson.getBucket(id.toString()).set(JSON.toJSONString(user));
}
return user;
}
return null;
}
private static User selectByDb(String id) {
System.out.println("from MySQL Found in it");
User user = new User();
user.setId(1L);
user.setUserName("Zhang San");
user.setAge(18);
return user;
}
}
Partially reproduced in:
https://www.cnblogs.com/itlaoge/p/14219693.html