Cache penetration problem?
Cache penetration: it is specified to use some nonexistent key s for a large number of queries on Redis, resulting in failure to hit. Each request will be sent to the persistence layer for query, resulting in great pressure on the database.
What are the solutions?
- Implement flow restriction on our service interface, user authorization, blacklist and whitelist interception
- If you can't find the results from both the cache and the database, cache the database null results in Redis: set the validity period of 30s to avoid attacking the database with the same id, but if the hacker really wants to mess with you, the id randomly generated by motar must be different
- Bloom filter
This is mainly about bloom filter
Bloom Filter was proposed by bloom in 1970. It is actually a long binary vector and a series of random mapping functions. Bloom Filter can be used to retrieve whether an element is in a set. Its advantage is that its spatial efficiency and query time are much better than general algorithms, but its disadvantage is that it has a certain false recognition rate and deletion difficulty.
The most intuitive function of Bloom filter: it is applicable to efficiently judge whether an element exists in the set, but there may be misjudgment. The misjudgment here refers to that the data that may not exist is judged by Bloom filter to exist in the set, but this situation almost only exists in the probability, that is, it is very low. If you encounter namo, congratulations on winning the prize, The bottom structure of Bloom filter is shown as follows:
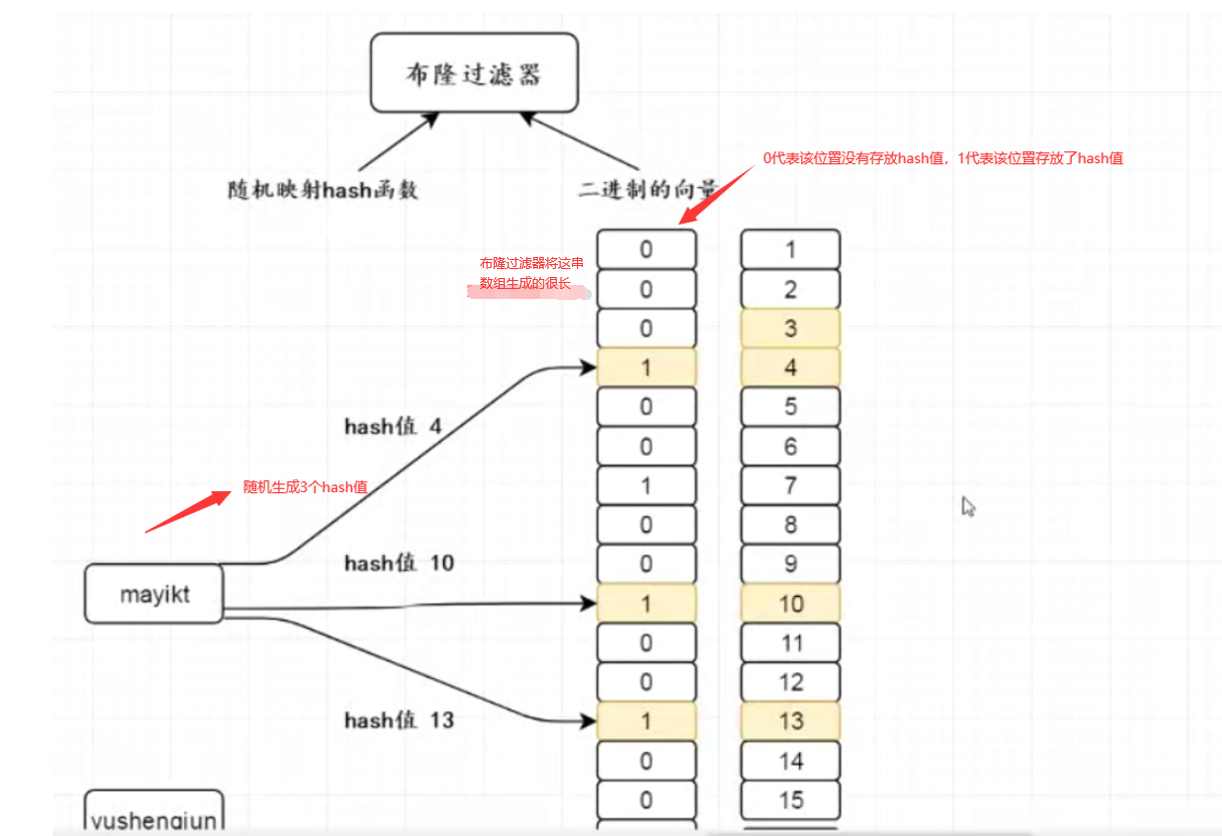
Here is an explanation:
When we store the data in the bloom filter, it will randomly generate three hash values from the key and store them in the vector array, and then change the binary value 0 originally stored in the array to 1. When we query the elements in the bloom filter,, It will calculate the hash value and its corresponding stored binary array position through some algorithm according to the key we passed in. At this time, it will check whether the binary number is 0 or 1 according to the position of the corresponding element in the corresponding binary array, so as to judge whether this element exists in the bloom filter.
Blum filter may be misjudged:
Because the bottom layer of the bloom filter is an array after all, and the length of the array is limited after all, it will calculate its hash value and its corresponding storage location through some algorithm according to the value of the key we pass in. However, the value of this location may be 0 or 1, so it may conflict with the element hash stored in the bloom filter, both of which are 1, This leads to the fact that there is no such element in the original filter, but the hash value calculated by him is 1. He mistakenly thinks that there is such an element
How to solve the hash conflict?
In fact, we only need to lengthen the length of the bottom array of Bloom filter, but everything has advantages and disadvantages, which will obviously lead to more memory occupied, because the array needs a series of continuous memory space in memory.
The following shows how to manipulate the bloom filter using java code
1. In POM Dependency of importing bloom filter in XML file
<!--Inlet bloom filter -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
- Write a test class (the following code is to test the probability of misjudgment of Bloom filter)
public class BlongTest {
/**
* Suppose 1 million pieces of data are stored in the collection
*/
private static Integer size = 1000000;
public static void main(String[] args) {
BloomFilter<Integer> integerBloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
for (int i = 0; i < size; i++) {
// Put 1 million pieces of data into our bloom filter
integerBloomFilter.put(i);
}
ArrayList<Integer> integers = new ArrayList<>();
for (int j = size; j < size + 10000; j++) {
// Use this pai to judge whether the key exists in the bloom filter, and return true. If it exists, false means it does not exist
if (integerBloomFilter.mightContain(j)) {
// Store the misjudgment results of Bloom filter in the collection for later statistics
integers.add(j);
}
}
System.out.println("Misjudgment result of Bloom filter:" + integers.size());
// 0.03 probability debug the underlying source code found that the length of the binary array created is about 7.3 million
// The length of 0.01 probability array is about 9.6 million. Generally, it is ok to use the false judgment probability of 0.01
// If your project cannot be misjudged, the bloom filter is not very good at this time, because you set the misjudgment probability to 0, which will lead to error reporting, because in theory, there must be a probability of misjudgment, which is inevitable
}
}
The following code simply simulates the production environment and stores the data in the database into the bloom filter
@RequestMapping("/dbToBulong")
public String dbToBulong() {
// 1. Preheat id from database to bloom filter
List<Integer> orderIds = orderMapper.getOrderIds();
integerBloomFilter = BloomFilter.create(Funnels.integerFunnel(), orderIds.size(), 0.01);
for (int i = 0; i < orderIds.size(); i++) {
// Add to our bloom filter
integerBloomFilter.put(orderIds.get(i));
}
return "success";
}
Execute normal business processes
@RequestMapping("/getOrder")
public OrderEntity getOrder(Integer orderId) {
// 0. Judge our bloom filter
if (!integerBloomFilter.mightContain(orderId)) {
System.out.println("Query from Bloom filter does not exist");
return null;
}
// 1. First query whether the data in Redis exists
OrderEntity orderRedisEntity = (OrderEntity) redisTemplateUtils.getObject(orderId + "");
if (orderRedisEntity != null) {
System.out.println("Directly from Redis Return data in");
return orderRedisEntity;
}
// 2. Query the contents of the database
System.out.println("from DB Query data");
OrderEntity orderDBEntity = orderMapper.getOrderById(orderId);
if (orderDBEntity != null) {
System.out.println("take Db Put data into Redis in");
redisTemplateUtils.setObject(orderId + "", orderDBEntity);
}
return orderDBEntity;
}