preface
I think the topic of code looping is very interesting. Because as long as developers, they will step through this pit. If you really haven't stepped on it, it only means that you write less code, or you are a real God.
Although many times, we try our best to avoid such problems, many times, the dead cycle comes quietly and pits you invisibly. I'm sure that if you finish reading this article, you will have some new understanding of code looping, learn some very practical experience and avoid detours.
Hazards of dead circulation
Let's take a look at the dangers of code looping?

- The program enters the suspended state. When a request causes an endless loop, the request will not be able to obtain the return of the interface for a long time. The program seems to enter the suspended state.
- cpu utilization soars. After the code has an endless loop, it has been occupying cpu resources because it does not sleep, resulting in the cpu being busy for a long time, which is bound to soar cpu utilization.
- The memory utilization rate soars. If the code has an endless loop, there is a lot of logic to create objects in the loop, and the garbage collector cannot recycle in time, the memory utilization rate will soar. At the same time, if the garbage collector collects objects frequently, it will also cause the cpu utilization to soar.
- StackOverflowError: in some recursive call scenarios, if there is an dead loop, after multiple loops, it will eventually report StackOverflowError stack overflow and the program will hang up directly.
Which scenes produce a life and death cycle?
1. General loop traversal
The general loop traversal here mainly refers to:
- for statement
- foreach statement
- while statement
These three loop statements may be the most commonly used loop statements, but if they are not used well, they are also the most prone to the problem of dead loop. Let's see what happens in a dead circle.
1.1 conditional identity
Many times, we use the for statement to iterate through the loop. If the specified conditions are not met, the program will automatically exit the loop, such as:
for(int i=0; i<10; i++) {
System.out.println(i);
}
However, if you accidentally write the conditions wrong, it becomes like this:
for(int i=0; i>10; i++) {
System.out.println(i);
}
The result is tragic. There must be a dead cycle, because the conditions in the cycle become identical.
Many friends saw this and thought I would never make such a mistake. However, I need to make a special note that the example given here is relatively simple. If I > 10, it is a very complex calculation. I'm not sure there will be no dead cycle.
1.2 incorrect continue
The for statement is more convenient when looping through arrays and list s, while the while statement has more usage scenarios.
Sometimes, when using the while statement to traverse data, if you encounter special conditions, you can use the continue keyword to skip this cycle and directly execute the next cycle.
For example:
int count = 0;
while(count < 10) {
count++;
if(count == 4) {
continue;
}
System.out.println(count);
}
When count equals 4, count is not printed.
However, if continue is not used correctly, strange problems may occur:
int count = 0;
while(count < 10) {
if(count == 4) {
continue;
}
System.out.println(count);
count++;
}
When count equals 4, this cycle is directly launched. Count does not add 1, but directly enters the next cycle. In the next cycle, count still waits for 4, and finally infinite cycle.
This is a scene that we should be careful. Maybe it has entered a dead cycle, and you don't know it yet.
1.3 flag is not visible between threads
Sometimes our code needs to do something until a certain condition is met. When a state tells it to terminate the task, it will exit automatically.
At this time, many people will think of using while(flag) to realize this function:
public class FlagTest {
private boolean flag = true;
public void setFlag(boolean flag) {
this.flag = flag;
}
public void fun() {
while (flag) {
}
System.out.println("done");
}
public static void main(String[] args) throws InterruptedException {
final FlagTest flagTest = new FlagTest();
new Thread(() -> flagTest.fun()).start();
Thread.sleep(200);
flagTest.setFlag(false);
}
}
This code executes an infinite loop in the sub thread. When the main thread sleeps for 200 milliseconds, the flag becomes false, and the sub thread will automatically exit. The idea is good, but in fact, this code enters an endless loop and will not automatically exit because the flag becomes false.
Why is that?
The flag between threads is invisible. At this time, if the volatile keyword is added to the flag, it becomes:
private volatile boolean flag = true;
It will force the value in the shared memory to be refreshed to the main memory, so that it can be seen among multiple threads, and the program can exit normally.
2.Iterator traversal
In addition to the general loop traversal described above, Iterator can also be used to traverse the elements of the collection. Of course, not all collections can be traversed by Iterator. Only collections that implement the Iterator interface or the internal classes of the collection implement the Iterator interface.
For example:
public class IteratorTest {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("123");
list.add("456");
list.add("789");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
But if the procedure changes to this:
public class IteratorTest {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("123");
list.add("456");
list.add("789");
while(list.iterator().hasNext()) {
System.out.println(list.iterator().next());
}
}
}
There will be an endless cycle.
What is this?
If you have seen the source code of ArrayList, you will find that its underlying iterator method is implemented as follows:
public Iterator<E> iterator() {
return new Itr();
}
A new Itr object is created each time. The bottom layer of hasNext method is realized by judging whether the number of cursors and elements are equal:
public boolean hasNext() {
return cursor != size;
}
Every time a new Itr object is created, the cursor value is the default value of 0, which is certainly not equal to the number of elements. Therefore, the conditions in the while statement are always true, so there will be an endless loop.
We all need to pay attention to: use list in the while loop iterator(). Hasnext() is a very big pit. Be careful.
3. Use your own object in the class
Define your own object as a member variable in a class. I don't know if you have done so.
Some may wonder why they did it.
If you need to call another method of @Transactional annotation in one method, if another method is called directly, the other method will fail due to the failure to take the proxy transaction. For example:
@Service
public class ServiceA {
public void save(User user) {
System.out.println("Business processing");
doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
System.out.println("Save data");
}
}
In this scenario, transactions will fail.
At this time, you can effectively avoid this problem by defining the class itself as a member variable and calling the doSave method through this variable.
@Service
public class ServiceA {
@Autowired
private ServiceA serviceA;
public void save(User user) {
System.out.println("Business processing");
serviceA.doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
System.out.println("Save data");
}
}
Of course, there are other ways to solve this problem, but this method is the simplest.
The question is, if the member variables are not injected through @ Autowired, but directly new, is that ok?
After the member variable is changed to:
private ServiceA serviceA = new ServiceA();
When the project is started, the program enters an infinite loop and continues to create ServiceA objects, but it has not been successful. Finally, it will report Java Lang.stackoverflowerror stack overflow. This error occurs when the stack depth exceeds the stack size allocated by the virtual machine to the thread.
Why is this problem?
Because when the program instantiates the ServiceA object, it needs to instantiate its member variable ServiceA first, but its member variable ServiceA needs to instantiate its own member variable ServiceA. In this way, it can't be instantiated in the end.
Why is @ Autowired injection OK?
Because @ Autowired injects the instance into the member variable ServiceA in the dependency injection phase, in addition to the successful instantiation of ServiceA object. Three level cache is used in spring to solve the circular dependency problem by exposing ObjectFactory objects in advance.
If you are interested in spring circular dependency, you can take a look at an article I wrote before.
4. Infinite recursion
In our daily work, we need to often use tree structure to display data, such as classification, region, organization, menu and other functions.
Many times, you need to traverse from the root node to find all leaf nodes, and you also need to trace from the leaf node up to the root node.
Let's take the root node traversal to find all leaf nodes as an example. Because each time you need to traverse the search layer by layer, and the methods you call are basically the same. In order to simplify the code, we usually choose to use recursion to realize this function.
Here we take finding the root node according to the leaf node as an example. The approximate code is as follows:
public Category findRoot(Long categoryId) {
Category category = categoryMapper.findCategoryById(categoryId);
if(null == category) {
throw new BusinessException("Classification does not exist");
}
Long parentId = category.getParentId();
if(null == categoryId || 0 == categoryId) {
return category;
}
return findRoot(parentId);
}
Search up recursively according to the categoryId. If the parentId is found to be null or 0, it is the root node, and then it is returned directly.
This may be the most common recursive call, but if someone makes a bad call, or due to database misoperation, change the parentId of the root node to the categoryId of the secondary classification, for example: 1222. In this way, the recursive call will enter an infinite loop and eventually report Java Lang.stackoverflowerror exception.
In order to avoid such a tragedy, there are actually ways.
You can define a maximum level max for running recursion_ Level, and exit directly when the maximum level is reached. The above codes can be adjusted as follows:
private static final int MAX_LEVEL = 6;
public Category findRoot(Long categoryId, int level) {
if(level >= MAX_LEVEL) {
return null;
}
Category category = categoryMapper.findCategoryById(categoryId);
if(null == category) {
throw new BusinessException("Classification does not exist");
}
Long parentId = category.getParentId();
if(null == categoryId || 0 == categoryId) {
return category;
}
return findRoot(parentId, ++level);
}
Define Max first_ The value of level, and then when the recursive method is called for the first time, the value of the level field is passed to 1. Each recursive time, the value of level is increased by 1. When it is found that the value of level is greater than or equal to MAX_LEVEL indicates that an exception has occurred, and null is returned directly.
When we write recursive methods, we should form a good habit. It is best to define a maximum recursive level MAX_LEVEL to prevent infinite recursion due to code bug s or data exceptions.
5.hashmap
When we write code, in order to improve efficiency, the probability of using sets is very large. Usually, we like to collect data into the collection first, and then batch process the data, such as batch insert or update, to improve the performance of database operations.
We use more collections: ArrayList, HashSet, HashMap, etc. I personally like to use HashMap very much, especially where loops need to be nested in java8. Converting the data of one layer of loops (list or set) into HashMap can reduce one layer of traversal and improve the execution efficiency of code.
However, if HashMap is not used properly, dead loops may occur. What's going on?
5.1 jdk1. HashMap for 7
jdk1. The HashMap of 7 uses the structure of array + linked list to store data. In a multithreaded environment, when put ting data into HaspMap at the same time, the transfer method in the resize method will be triggered to redistribute the data. It is necessary to reorganize the data of the linked list.

Due to the head insertion method, the next of key3 is equal to key7, and the next of key7 is equal to key3, thus forming a dead cycle.
5.2 jdk1. HashMap for 8
With the solution jdk1 7. The problem of dead circulation occurs during capacity expansion, which is in jdk1 HashMap is optimized in 8, and jdk1 The head interpolation method in 7 is changed to tail interpolation method, and the structure of array + linked list + red black tree is used to store data. If there are more than 8 elements in the linked list, the linked list will be transformed into a red black tree to reduce the query complexity and reduce the time complexity to O(logN).
In a multithreaded environment, when put ting data into HaspMap at the same time, it will trigger the root method to reorganize the data in the tree structure.
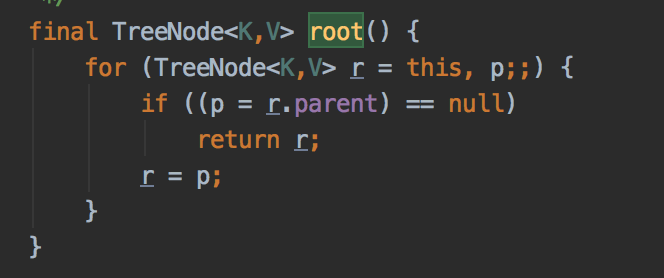
In the for loop, the Parent references of two TreeNode nodes are each other, thus forming an endless loop.
5.3 ConcurrentHashMap
Because in a multithreaded environment, using either jdk1 7, or jdk1 8 HashMap will have the problem of dead circulation. Therefore, many people suggest that instead of using HashMap in a multithreaded environment, you should use concurrent HashMap instead.
ConcurrentHashMap is thread safe. It also uses the structure of array + linked list + red black tree to store data. In addition, it also uses cas + segment lock. The default is 16 segment lock to ensure that data will not produce errors during concurrent writing.
In a multithreaded environment, when computeIfAbsent data is sent to the ConcurrentHashMap at the same time, if there is another computeIfAbsent in it, and the hashCode corresponding to their key is the same, an endless loop will be generated.

Are you surprised?
Fortunately, the bug is in jdk1 9 has been repaired by Doug Lea.
6. Dynamic agent
In our practical work, even if we haven't written dynamic agents by ourselves, we have heard or contacted them, because many excellent development frameworks must use dynamic agents at the bottom to realize some additional functions. Usually, the dynamic agents we use most are JDK dynamic agent and Cglib. spring's AOP is realized through these two dynamic agent technologies.
Here we take JDK dynamic agent as an example:
public interface IUser {
String add();
}
public class User implements IUser {
@Override
public String add() {
System.out.println("===add===");
return "success";
}
}
public class JdkProxy implements InvocationHandler {
private Object target;
public Object getProxy(Object target) {
this.target = target;
return Proxy.newProxyInstance(this.getClass().getClassLoader(),target.getClass().getInterfaces(),this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
before();
Object result = method.invoke(target,args);
after();
return result;
}
private void before() {
System.out.println("===before===");
}
private void after() {
System.out.println("===after===");
}
}
public class Test {
public static void main(String[] args) {
User user = new User();
JdkProxy jdkProxy = new JdkProxy();
IUser proxy = (IUser)jdkProxy.getProxy(user);
proxy.add();
}
}
There are three main steps to achieve:
- Implement a specific business interface
- Implement InvocationHandler interface and create calling relationship
- Use Proxy to create a Proxy class and specify the relevant information of the Proxy class
In this way, when calling the add method of proxy, the before and after methods will be called automatically, which realizes the effect of dynamic proxy. Isn't it cool?
Normally, there is no problem with this writing, but if you call the toString method of the proxy object in the invoke method, add this Code:
proxy.toString();
When the program runs again and loops many times, it will report Java Lang.stackoverflowerror exception.
Many people may look confused when they see here. What happened?
The proxy object itself does not have its own method. All its methods are based on the proxy object. Usually, if you access the method of the proxy object, you will pass through the invoke method of the interceptor. However, if the proxy object's method is called in the invoke method, such as toString method, it will pass through the invoke method of another interceptor, which will be called repeatedly and finally form an endless loop.
Remember not to invoke the method of proxy object in the invoke method, otherwise it will produce a cycle of life and death.
7. We wrote our own dead circle
Many friends may question when they see this title. Will we write a dead cycle ourselves?
Yes, we can really write some scenes.
7.1 scheduled tasks
I don't know if you've ever written a scheduled task by hand. Anyway, I've written it. It's a very simple one (of course, I've also written complex ones, so I won't discuss them here). If there is a requirement to download the latest version of a file remotely every 5 minutes to overwrite the current file.
At this time, if you don't want to use other timed task frameworks, you can implement a simple timed task. The specific code is as follows:
public static void downLoad() {
new Thread(() -> {
while (true) {
try {
System.out.println("download file");
Thread.sleep(1000 * 60 * 5);
} catch (Exception e) {
log.error(e);
}
}
}).start();
}
In fact, many timing tasks in JDK, such as the bottom layer of Timer class, are also implemented with infinite loop (i.e. dead loop) of while(true).
7.2 producers and consumers
I don't know if you have handwritten producers and consumers. Suppose there is a requirement to write user operation logs into the table, but message oriented middleware, such as kafka, has not been introduced into consumption at this time.
The most common way is to synchronously write the log into the table in the interface. The saving logic and business logic may be in the same transaction, but it is generally recommended not to put them in the same transaction in order to avoid large transactions for performance reasons.
Originally, it was very good, but if the interface concurrency increases, in order to optimize the interface performance, the logic of synchronous log writing to the table may be split and processed asynchronously.
At this time, you can manually roll up a producer consumer to solve this problem.
@Data
public class Car {
private Integer id;
private String name;
}
@Slf4j
public class Producer implements Runnable {
private final ArrayBlockingQueue<Car> queue;
public Producer(ArrayBlockingQueue<Car> queue) {
this.queue = queue;
}
@Override
public void run() {
int i = 1;
while (true) {
try {
Car car = new Car();
car.setId(i);
car.setName("automobile" + i);
queue.put(car);
System.out.println("Producer:" + car + ", queueSize:" + queue.size());
} catch (InterruptedException e) {
log.error(e.getMessage(),e);
}
i++;
}
}
}
@Slf4j
public class Consumer implements Runnable {
private final ArrayBlockingQueue<Car> queue;
public Consumer(ArrayBlockingQueue<Car> queue) {
this.queue = queue;
}
@Override
public void run() {
while (true) {
try {
Car car = queue.take();
System.out.println("Consumer:" + car + ",queueSize:" + queue.size());
} catch (InterruptedException e) {
log.error(e.getMessage(), e);
}
}
}
}
public class ClientTest {
public static void main(String[] args) {
ArrayBlockingQueue<Car> queue = new ArrayBlockingQueue<Car>(20);
new Thread(new Producer(queue)).start();
new Thread(new Producer(queue)).start();
new Thread(new Consumer(queue)).start();
}
}
Because the blocking and wake-up mechanism is implemented in the ArrayBlockingQueue blocking queue through notEmpty and notFull conditions, we don't need to do additional control. It's much easier for producers and consumers to use it.
1.3 what should you pay attention to when writing your own dead cycle?
I don't know if smart partners have found that we also wrote a dead cycle in our custom scheduled tasks and examples of producers and consumers, but unlike other examples above, there is no problem with the dead cycle we wrote. Why?
In the scheduled task, we use the sleep method to sleep: thread sleep(300000);.
Producers and consumers use the await and signal methods of Condition class to realize the blocking and wake-up mechanism.
To put it bluntly, these two mechanisms will actively give up the cpu for a period of time to allow other threads to use cpu resources. In this way, the cpu has the process of context switching. It is idle for a period of time and will not be busy all the time like other columns.
Being busy all the time is the real reason for the soaring cpu utilization. We should avoid this situation.
Just as we usually ride a shared bike (cpu resources), we usually return it after riding for 1-2 hours, so that others will have the opportunity to use this shared bike. But if someone has not returned the bike after riding for a day, then the bike has been busy during the day, and others will not have the opportunity to ride the bike.
One last word (please pay attention, don't whore me in vain)
Traditional virtues can't be lost. If you get something after reading this article, remember to praise me 😙. Your support is the only motivation for me to continue writing.
Seek one key three links: like, forward and watch.
Pay attention to the official account: Su three technology, reply in official account: interview, code artifact, development manual, time management have super fans' welfare, and reply: Jia group can communicate with many senior BAT factory's predecessors and learn.