buddy algorithm is an old module in the kernel, which solves the problem of adjacent physical memory fragmentation, namely "internal fragmentation problem". At the same time, it takes into account the efficiency of memory application and release. Since the introduction of the algorithm, the kernel has been able to complete good luck on various devices, which proves its good performance and good compatibility.
buddy's core idea
The core idea of buddy algorithm is as follows (note that the following explanation comes from the chapter of full dynamic storage allocation in Volume 1: basic algorithm of computer programming art):
The design idea of this method is for each size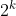 (0
(0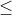 km) The available list is distributed and maintained. The entire allocated memory space pool is composed of
km) The available list is distributed and maintained. The entire allocated memory space pool is composed of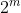 It consists of words. It can be assumed that the addresses of these words are 0 to-1. firstThe entire block of words is available, then, when neededWhen there is no available block of this size, a larger available block is divided into two parts on average; Finally, there will be aWhen a block is divided into two blocks (each half the original size), the two blocks are called buddy. When both partners are available again, they merge into a block. Therefore, this process can be maintained indefinitely until the memory space is exhausted at a certain time.
It consists of words. It can be assumed that the addresses of these words are 0 to-1. firstThe entire block of words is available, then, when neededWhen there is no available block of this size, a larger available block is divided into two parts on average; Finally, there will be aWhen a block is divided into two blocks (each half the original size), the two blocks are called buddy. When both partners are available again, they merge into a block. Therefore, this process can be maintained indefinitely until the memory space is exhausted at a certain time.
The key fact that lays the foundation for the practical value of this method is that if you know the address (the memory location of its first word) and size of a block, you know the address of its partner. For example, if it is known that a block of size 16 starts from binary position 101110010110000, its partner is a block starting from binary position 1011100100000. Why? We first observe that when the algorithm is running, the size isThe block address of isThat is, the binary representation of the address is at least K 0.0 on the right
In linux, the smallest unit of physical memory management is page, and each page is managed through memmap array (note that the memmap array form of different memory models is slightly different). In this way, the address and pfn of each page are fixed. If you know the address (memory location of its first word) and size of a block, you know the address of its partner, So as to improve the distribution and release efficiency. buddy algorithm is perfectly applied to physical memory management, which greatly improves the efficiency of the whole memory.
buddy management architecture
The whole management of buddy in linux kernel is shown in the figure below:
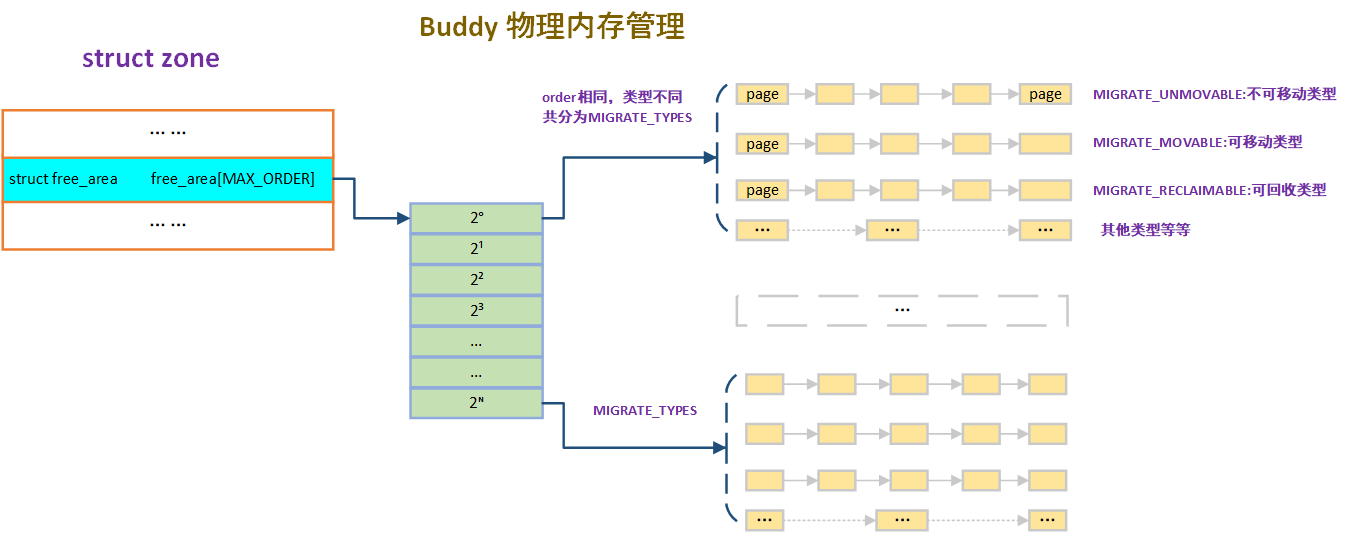
The entire management of buddy is divided by level as follows:
- Zone: the memory managed by buddy belongs to the zone, and the physical memory in each zone belongs to free_ares array.
- struct free_are free_area[] : free_ The area array is responsible for managing all physical memory in the zone according to the buffy algorithm. Where free_ The area array subscript index, as the corresponding order, is responsible for managing page s as a block according to the order power of 2. The maximum order is MAX_ORDER-1. struct free_ The structure is as follows:
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};- struct list_head free_list[MIGRATE_TYPES]: to solve the problem of random memory fragmentation as the system runs for a long time. The kernel divides the memory in the same order according to the memory type_ Types. The memory of the same order has different memory types, mainly divided into MIGRATE_UNMOVABLE,MIGRATE_MOVABLE,MIGRATE_RECLAIMABLE and other types.
- struct list_head free_list: connect the free memory belonging to the same oder and the same type through a linked list to allocate physical memory.
buddy initialization
The whole buddy initialization process is long. The whole process is as follows:
--->start_kernel()
--->setup_arch()
--->mm_init()
--->mem_init()
--->memblock_free_all()
--->memblock_free_all()
--->free_low_memory_core_early()
--->__free_memory_core()
--->__free_pages_memory()
--->memblock_free_pages()
--->__free_pages_core()
--->__free_pages()
--->free_the_page()
--->__free_pages_ok()
--->free_one_pages()
--->__free_one_page
--->add_to_free_list() The overall process is long, but you only need to pay attention to a few main processing functions to have a clear understanding of buddy.
Key processing function
free_low_memory_core_early()
This function can be considered as an entry process of buddy initialization, which is located in mm \ memblock C file, located in the early initialization memory process:
static unsigned long __init free_low_memory_core_early(void)
{
unsigned long count = 0;
phys_addr_t start, end;
u64 i;
memblock_clear_hotplug(0, -1);
for_each_reserved_mem_region(i, &start, &end)
reserve_bootmem_region(start, end);
/*
* We need to use NUMA_NO_NODE instead of NODE_DATA(0)->node_id
* because in some case like Node0 doesn't have RAM installed
* low ram will be on Node1
*/
for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE, &start, &end,
NULL)
count += __free_memory_core(start, end);
return count;
}
This function is located in memblock and initiated by memblock. At the early start stage of the system, it traverses the memory memory information of each node, obtains the start start and end pages, and calls__ free_memory_core() performs a core memory initialization.
__free_pages_memory()
__ free_pages_memory() is an important function. The source code of the function is as follows:
static void __init __free_pages_memory(unsigned long start, unsigned long end)
{
int order;
while (start < end) {
order = min(MAX_ORDER - 1UL, __ffs(start));
while (start + (1UL << order) > end)
order--;
memblock_free_pages(pfn_to_page(start), start, order);
start += (1UL << order);
}
}- This function mainly initializes all physical pages according to the start pfn cycle. A key process is: order = min (max_order - 1ul, _ffs (start)). This process is to calculate the oder corresponding to the current start page
- __ The ffs(start) function calculates the position of the first 0 corresponding to the binary conversion in start. For example, if start is 384=0x180 and the position of the first 1 is 7, the order aligned with 0x180 is 7. If the calculated order is greater than 10, it is finally compared with MAX_ORDER cannot exceed max for comparison_ Order, the real order is the level at which the current start is located.
- In the system process, start may not be max at the beginning_ The order is aligned, and the order corresponding to each start is finally obtained by continuously adjusting the oder
- Next, call memblock_free_pages(), notify the processing [oder power page of start, start + 2] to add it to the corresponding buddy management.
__free_one_page
__ free_one_page() is the key processing function to add page to buddy, which includes merging nearby buffies:
/*
* Freeing function for a buddy system allocator.
*
* The concept of a buddy system is to maintain direct-mapped table
* (containing bit values) for memory blocks of various "orders".
* The bottom level table contains the map for the smallest allocatable
* units of memory (here, pages), and each level above it describes
* pairs of units from the levels below, hence, "buddies".
* At a high level, all that happens here is marking the table entry
* at the bottom level available, and propagating the changes upward
* as necessary, plus some accounting needed to play nicely with other
* parts of the VM system.
* At each level, we keep a list of pages, which are heads of continuous
* free pages of length of (1 << order) and marked with PageBuddy.
* Page's order is recorded in page_private(page) field.
* So when we are allocating or freeing one, we can derive the state of the
* other. That is, if we allocate a small block, and both were
* free, the remainder of the region must be split into blocks.
* If a block is freed, and its buddy is also free, then this
* triggers coalescing into a block of larger size.
*
* -- nyc
*/
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype, bool report)
{
struct capture_control *capc = task_capc(zone);
unsigned long uninitialized_var(buddy_pfn);
unsigned long combined_pfn;
unsigned int max_order;
struct page *buddy;
bool to_tail;
max_order = min_t(unsigned int, MAX_ORDER, pageblock_order + 1);
VM_BUG_ON(!zone_is_initialized(zone));
VM_BUG_ON_PAGE(page->flags & PAGE_FLAGS_CHECK_AT_PREP, page);
VM_BUG_ON(migratetype == -1);
if (likely(!is_migrate_isolate(migratetype)))
__mod_zone_freepage_state(zone, 1 << order, migratetype);
VM_BUG_ON_PAGE(pfn & ((1 << order) - 1), page);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
continue_merging:
while (order < max_order - 1) {
if (compaction_capture(capc, page, order, migratetype)) {
__mod_zone_freepage_state(zone, -(1 << order),
migratetype);
return;
}
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
if (!pfn_valid_within(buddy_pfn))
goto done_merging;
if (!page_is_buddy(page, buddy, order))
goto done_merging;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy))
clear_page_guard(zone, buddy, order, migratetype);
else
del_page_from_free_list(buddy, zone, order);
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn);
pfn = combined_pfn;
order++;
}
if (max_order < MAX_ORDER) {
/* If we are here, it means order is >= pageblock_order.
* We want to prevent merge between freepages on isolate
* pageblock and normal pageblock. Without this, pageblock
* isolation could cause incorrect freepage or CMA accounting.
*
* We don't want to hit this code for the more frequent
* low-order merging.
*/
if (unlikely(has_isolate_pageblock(zone))) {
int buddy_mt;
buddy_pfn = __find_buddy_pfn(pfn, order);
buddy = page + (buddy_pfn - pfn);
buddy_mt = get_pageblock_migratetype(buddy);
if (migratetype != buddy_mt
&& (is_migrate_isolate(migratetype) ||
is_migrate_isolate(buddy_mt)))
goto done_merging;
}
max_order++;
goto continue_merging;
}
done_merging:
set_page_order(page, order);
if (is_shuffle_order(order))
to_tail = shuffle_pick_tail();
else
to_tail = buddy_merge_likely(pfn, buddy_pfn, page, order);
if (to_tail)
add_to_free_list_tail(page, zone, order, migratetype);
else
add_to_free_list(page, zone, order, migratetype);
/* Notify page reporting subsystem of freed page */
if (report)
page_reporting_notify_free(order);
}
The processing of this function is mainly divided into two parts:
- The first part is mainly to find buddy_pfn, find out whether the page to be added has a partner in the corresponding oder. If there is a partner, it indicates that it needs to be merged with the partner to form a higher-level order. Carry out order+1, and continue to find out whether it can still be merged in the higher-level order. In this cycle, as long as it cannot be merged or reaches MAX_ORDER. Note that during the merging process, if it is found that merging can be performed, del needs to be called_ page_ from_ free_ The list function deletes the buddy from the current order so that it can be added to a higher order
- In the second part, through the above continuous merging, finally find the appropriate order to which the current page is added. The current page is called add as the home page in the oder_ to_ free_ List or add_to_free_list_ The tail function is added to the buddy.
add_to_free_list
Add the current free page to the buddy:
static inline void add_to_free_list(struct page *page, struct zone *zone,
unsigned int order, int migratetype)
{
struct free_area *area = &zone->free_area[order];
list_add(&page->lru, &area->free_list[migratetype]);
area->nr_free++;
}- Add the page to the free of the corresponding memory type_ List, where migratetype is taken from the flag of page, and get is called_ pfnblock_ Migratetype (page, PFN) function, specifically for pageblock_flags can be seen pg_data_t and zone structure initialization of linux kernel Explain in detail.
- Another thing to pay special attention to in this function is page - > lru. lru will be mounted in different linked lists for different use states and purposes of page. Therefore, lru is a member of reuse structure. This is the first use of lru in contact. When the page is idle, lru will be mounted to free_list.
- area->nr_ Free + + counts the pages in the corresponding area + 1, the same as add_to_free_list_tail() is handled in the same way
__find_buddy_pfn()
__ find_buddy_pfn() is a commonly used function in buddy algorithm. It mainly calculates the partner of the current page according to the order of the current page.
Take the block of size 32 as an example, it has the shape of XX X0000 address (where x is 0 or 1); If it is split, the newly formed partner block address is XX X00000 and XX Xx10000, in general, order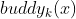 =The address is x and the size isThe partner address of the block, with x+ Or x - Two emotions are
=The address is x and the size isThe partner address of the block, with x+ Or x - Two emotions are
The above two cases can be obtained directly through XOR.
__ find_ buddy_ The source code of PFN is as follows:
static inline unsigned long
__find_buddy_pfn(unsigned long page_pfn, unsigned int order)
{
return page_pfn ^ (1 << order);
}page_is_buddy
page_is_buddy() determines whether it is a buddy:
static inline bool page_is_buddy(struct page *page, struct page *buddy,
unsigned int order)
{
if (!page_is_guard(buddy) && !PageBuddy(buddy))
return false;
if (page_order(buddy) != order)
return false;
/*
* zone check is done late to avoid uselessly calculating
* zone/node ids for pages that could never merge.
*/
if (page_zone_id(page) != page_zone_id(buddy))
return false;
VM_BUG_ON_PAGE(page_count(buddy) != 0, buddy);
return true;
}To check whether page and buddy are real partners, you need to meet the following conditions at the same time:
- buddy cannot be a hole hole, but must be a real physical memory.
- The real physical memory of buddy exists and appears in the buddy system in an idle state
- page and buffy must be in the same order
- Must be in the same zone
Only when all the above conditions are met is the real buddy.
reference material
Art of Computer Programming Volume 1: basic algorithms (3rd Edition)