Reprinted from Ali Josie-Build Containers From Scratch in Go
On September 17, 2020, the use of containers has increased significantly in the past few years. The concept of container has been around for many years, but due to the easy-to-use command of Docker, container has been popular among developers since 2013 (I think it is mainly reusable image).
In this series, I will try to demonstrate how the underlying container works and how I develop vessel
What is vessel?
Vesel is one of my educational projects. It implements a small version of Docker to manage containers. Instead of using containerd or runc, it uses a list of Linux features to create containers. github warehouse.
Vesel is neither production ready nor well tested software. It is just a simple project for learning containers.
Let's start: reading about Docker!
I found that before I started writing code, I looked at it first Docker document It is useful to have an in-depth understanding of containers.
According to the official Docker documentation, Docker uses several Linux kernel features and packages them into container format. These features include:
- Namespaces
- Control groups
- Union file systems
Now let's take a brief look at each of these features
What is Namespace!?
Linux namespace is the underlying technology behind the most modern container implementation. Namespace is a process level concept that allows isolation of global system resources in a set of processes. For example, network namespace isolates the network stack, which means that processes in the network namespace can have their own independent routes, firewall rules and network devices.
Therefore, if there is no namespace, the process in one container can unmount the file system or set the network interface in another file system.
What kind of resource can isolate using namespaces?
In the current Linux kernel (5.9), there are eight different namespaces, each of which can isolate a global system resource.
-
cgroup: this namespace isolates the Control Groups root directory. I will explain cgroups in the second part, but a brief explanation is that cgroup allows the system to define resource limits for a group of processes. However, it should be noted that cgroup namescape only controls which cgroups in the namespace are visible. Namescape cannot allocate resource constraints, which we will explain in depth soon
-
IPC: this namespace isolates inter process communication mechanisms, such as System V and POSIX message queues
-
Network: this namespace isolates routes, firewall rules, and network devices
-
Mount: this namescape isolates a list of mount points
-
PID: the ID number of the namescape isolation process. It can also enable the ability of the suspending/resuming process
-
Time: this namespace isolates clock_ Mononic and CLOCK_BOOTTIME system clock. These two clocks will affect the API based on time measurement (such as system startup time uptime)
-
User: this namespace isolates user ID, group ID, root directory, keys, and capabilities. The cloud core process is root in the namespace, but not outside the namespace (such as host)
-
UTS: this namespace isolates host names and domain names
An important note about namespaces
Namespace does nothing except isolation, which means that, for example, adding a new network namespace will not give you a group of independent network devices. You must create them yourself. The same thing. For UST namespace, it will not change your hostname. It just isolates the system calls related to hostname
Namespaces lifetime
When the last process in the namespace leaves the namespace, the nameapce will shut down automatically. However, there are many exceptions to this, so that nameapce remains alive when there are no processes. We will learn about one of them in creating a network namespace in vesel
Namespaces system calls
Now that we have a simple understanding of what a namespace is, it's time to see how to interact with them. In Linux, there is a set of system calls that support creating, joining, and discovering namesaces.
-
clone: this system call will create a new process, but with the help of the flags parameter, the new process will create its own new namespace
-
setns: this system call allows a running process to join an existing namespace
-
unshare: this system call is actually the same as clone. The difference is that this call will create a new namespace and move the current process in, while clone will create a process with a new namespace.
Bonus point: fork and vfork are just clone calls with different parameters
Namespace Flags
The system call mentioned above requires a flag to specify the required namespace.
CLONE_NEWCGROUP Cgroup namespaces CLONE_NEWIPC IPC namespaces CLONE_NEWNET Network namespaces CLONE_NEWNS Mount namespaces$$ CLONE_NEWPID PID namespaces CLONE_NEWTIME Time namespaces CLONE_NEWUSER User namespaces CLONE_NEWUTS UTS namespaces
For example, if you want to create a new namespace for the current process, you should call unshare and use CLONE_NEWNET parameter. If you want to create a process with a new User and UTS namespace, you should call clone and use clone_ NEWUSER|CLONE_ The updates parameter.
Namespace file
As mentioned above, we can use setns to move running processes between nameapces, but how do we specify which namespace to move to? In fact, when the namespace is created, the member process will have a symbolic link to the namespace files.
After all, Unix wisdom says, "In Unix, Everything is a file."
For example, in the shell, we can list the / proc/[pid]/ns directory, and you can see the namespace of the process. Here, you can see the namespace of the running shell (self represents the pid of the current shell):
$ ls -l /proc/self/ns | cut -d ' ' -f 10-12 cgroup -> cgroup:[4026531835] ipc -> ipc:[4026531839] mnt -> mnt:[4026531840] net -> net:[4026532008] pid -> pid:[4026531836] pid_for_children -> pid:[4026531836] time -> time:[4026531834] time_for_children -> time:[4026531834] user -> user:[4026531837] uts -> uts:[4026531838]
You can also use the lsns command to view a list of process namespaces:
# lsns
NS TYPE NPROCS PID USER COMMAND
4026531834 time 244 1 root /sbin/init
4026531835 cgroup 244 1 root /sbin/init
4026531836 pid 199 1 root /sbin/init
4026531837 user 198 1 root /sbin/init
4026531838 uts 241 1 root /sbin/init
4026531839 ipc 244 1 root /sbin/init
4026531840 mnt 234 1 root /sbin/init
In fact, what the setns system call does is the file link in the / proc/[pid]/ns directory
Enough talk, LET'S CODE!
Now that we know everything we want to know, it's time to write code that runs on a separate namespace. The first attempt is to see how unshare works. The code is as follows. In line 1, create a new namespace for the current Go program using syscall package and unshare method, then set hostname to "container" in line 5, create a new command line and Run it in line 9, and Run starts the command line and waits for it to complete.
Note: creating a namespace requires a cap_ SYS_ Admin capability, so you need to run the program as root.
err := syscall.Unshare(syscall.CLONE_NEWPID|syscall.CLONE_NEWUTS)
if err != nil {
fmt.Fprintln(os.Stderr, err)
}
err = syscall.Sethostname([]byte("container"))
if err != nil {
fmt.Fprintln(os.Stderr, err)
}
cmd := exec.Command("/bin/sh")
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.Run()
Let's build this program and test it. For the first command in host, I run ps to monitor the running process, and then get the hostname and PID (like self, $$is also the PID of the current process)
$ ps
PID TTY TIME CMD
27973 pts/2 00:00:00 sh
27984 pts/2 00:00:00 ps
$ hostname
host
$ echo $$
27973
Now let's take a look at what happens after running the program. Getting the hostname returns "container", which seems to have taken effect!
$ hostname container
Let's see what the PID is. Yes, it's 1. It also takes effect
$ echo $$ 1
Then use ps to view the running processes in the container
$ ps
PID TTY TIME CMD
27973 pts/2 00:00:00 sh
27998 pts/2 00:00:00 unshare
28003 pts/2 00:00:00 sh
28011 pts/2 00:00:00 ps
What happened, we can see the host process in the container, which is meaningless
We try to kill one of the processes and see what happens?
$ kill 27998 sh: kill: (27998) - No such process
It says, without this process, why?? Explain that the code is actually effective. We are in a new PID namespace and show that the PID is 1. The problem lies in the ps command. The ps bottom layer uses the proc pseudo file system to list the running programs. In order to have our own proc file system, we need a new mount namespace and a new root path to mount proc. We'll dig deeper into this in the next section.
Clone in Go
So far, Go has no clone function. However, a package called goclone packages the clone system calls, but our solution is slightly different. In vesel, I use a package called reexec, which is developed by the Docker team
What is reexec?
Go allows us to run the command line in the new namespace. The idea behind reexec is to re run the program itself in a new namespace. Reexec will return a * exec from the go standard library CMD, which will call / proc/self/exe, which is basically an executable file pointing to the running program.
Now that you know how reexec works, let's write some early code of vesel. This code actually starts a process with a new namespace, which will become our container.
args := []string{"fork"}
...
cmd := reexec.Command(args...)
cmd.Stdin, cmd.Stdout, cmd.Stderr = os.Stdin, os.Stdout, os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS |
syscall.CLONE_NEWIPC |
syscall.CLONE_NEWPID |
syscall.CLONE_NEWNS,
}
SysProcAttr specifies the OS specific attribute, one of which is Cloneflags, indicating that the command line runs in a new namespace. Therefore, our new process has new IPC, UTS, PID and NS (Mount) namespaces, but what about the network namespace?
Dive into the network namespace
As I have already mentioned, namespace only isolates resource and container aware boundaries. Therefore, running the container in the new Network Namespace won't help much. We should also do something to connect the container to the external network, but how is this possible?!
What is a virtual ethernet device?
veth can be used as a channel between Network Namesapce, which means that a connection can be created with a network device in another namespace.
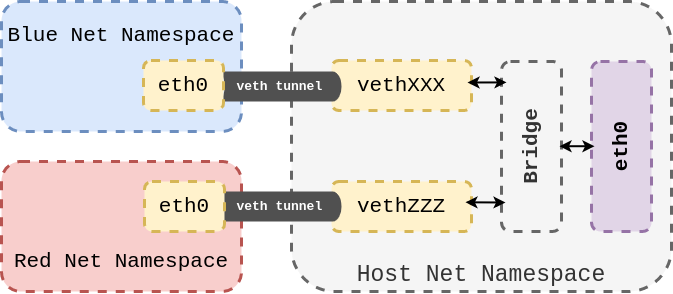
Virtual Ethernet Devices are always created in pairs. All data sent by one party can be received by the other party immediately. When one of them stops, the link stops.
For example, in the figure above, there are two pairs of veth s. In each pair, one is located in the network namespace of the host and the other is located in the network namespace of the container. The device in the host namespace is connected to a Bridge, which is routed to a physical, Internet connected device eth0
Now let's take a look at how vessel created such a network
func (c *Container) SetupNetwork(bridge string) (filesystem.Unmounter, error) {
nsMountTarget := filepath.Join(netnsPath, c.Digest)
vethName := fmt.Sprintf("veth%.7s", c.Digest)
peerName := fmt.Sprintf("P%s", vethName)
if err := network.SetupVirtualEthernet(vethName, peerName); err != nil {
return nil, err
}
if err := network.LinkSetMaster(vethName, bridge); err != nil {
return nil, err
}
unmount, err := network.MountNewNetworkNamespace(nsMountTarget)
if err != nil {
return unmount, err
}
if err := network.LinkSetNsByFile(nsMountTarget, peerName); err != nil {
return unmount, err
}
// Change current network namespace to setup the veth
unset, err := network.SetNetNSByFile(nsMountTarget)
if err != nil {
return unmount, nil
}
defer unset()
ctrEthName := "eth0"
ctrEthIPAddr := c.GetIP()
if err := network.LinkRename(peerName, ctrEthName); err != nil {
return unmount, err
}
if err := network.LinkAddAddr(ctrEthName, ctrEthIPAddr); err != nil {
return unmount, err
}
if err := network.LinkSetup(ctrEthName); err != nil {
return unmount, err
}
if err := network.LinkAddGateway(ctrEthName, "172.30.0.1"); err != nil {
return unmount, err
}
if err := network.LinkSetup("lo"); err != nil {
return unmount, err
}
return unmount, nil
}
The above code describes the SetupNetwork method in vesel's container package, which is responsible for creating the network mentioned above.
Before calling this method, vessel creates a bridge named vessel0, which is actually uploaded to the bridge of SetupNetwork
In lines 3-4, the veth device pair name is defined. Then, on line 6, you create veth with the relevant name. In line 9, veth designates vessel0 as its master for further communication.
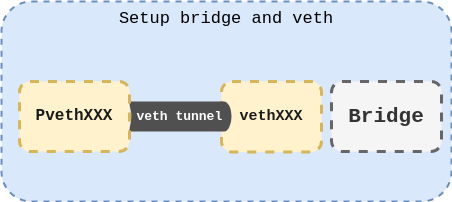
Now you need to create a new network namespace, and then move one of the Veth pairs into. The problem is the life cycle of the container. As we mentioned earlier, if the last process in the namespace exits, the nameapce will be destroyed. We also mentioned some exceptions. One exception is when the namespace is bound mounted, which is why my function is named mountnetworknamespace. This function creates a new namespace and binds it to a file to keep it alive.
func MountNewNetworkNamespace(nsTarget string) (filesystem.Unmounter, error) {
_, err := os.OpenFile(nsTarget, syscall.O_RDONLY|syscall.O_CREAT|syscall.O_EXCL, 0644)
if err != nil {
return nil, errors.Wrap(err, "unable to create target file")
}
// store current network namespace
file, err = os.OpenFile("/proc/self/ns/net", os.O_RDONLY, 0)
if err != nil {
return nil, err
}
defer file.Close()
if err := syscall.Unshare(syscall.CLONE_NEWNET); err != nil {
return nil, errors.Wrap(err, "unshare syscall failed")
}
mountPoint := filesystem.MountOption{
Source: "/proc/self/ns/net",
Target: nsTarget,
Type: "bind",
Flag: syscall.MS_BIND,
}
unmount, err := filesystem.Mount(mountPoint)
if err != nil {
return unmount, err
}
// reset previous network namespace
if err := unix.Setns(int(file.Fd()), syscall.CLONE_NEWNET); err != nil {
return unmount, errors.Wrap(err, "setns syscall failed: ")
}
return unmount, nil
}
In line 2, create a file that is used to bind the new network namespace. Line 8, staging the current namespace for later recovery. Then create a new network namespace and join it with the unshare name. This function binds the file created in line 2 to / proc/self/ns/net. Remember that the contents of / proc/self/ns/net have changed since the unshare system call.
All right, we just need to leave the current network namespace and return to the previous namespace using the setns system call on line 29. This is why we store the network namespace of the process on line 9.
Returning to the SetupNetwork function, let's move one of the devices to the namespace created by MountNewNetworkNamespace. Because the value of nsMountTarget is bound to the network namespace, which represents the namespace itself, we can specify the namespace using the file descriptor.
Well, we already have a pair of virtual Ethernet devices, one of which is in the host network namespace and the other in the new namespace.
Now, the only thing left to do is to configure the device in our new namespace. The problem is that the device is no longer visible in the network namespace of the host. Therefore, we need to add the namespace again with the SetNetNsByFile function (line 21). This function only calls setns on the given file descriptor. Note that we need the defer function unset to leave the container's network namespace at the end of the function.
The rest of the code (lines 22-43) now runs in the container's network namespace. First, rename the device in the container to eth0 (line 29), then associate it with a new IP (line 32), set the device (line 35), add a gateway to the device (line 38), and finally set the loopback (127.0.0.1) network interface. Now our network namespace is completely ready.
It is worth mentioning that setting 172.30.0.1 as the default IP of vessel0 bridge is not the best way, because this IP may have been used. This is just for simplification. Now your task is to do better and submit PR
Conclusion
We have learned that namespace is a feature of Linux. It isolates the global system resources of a group of processes, so it is the basic technology in most containers. In addition, we learned how to interact with namespaces in Go using unshare, clone, and setns system calls.
The article is not finished yet. We will discuss the federated file system in the next section. But now, let's try it and understand it in combination with the source code of vesel.
In addition, don't forget google's "Liz Rice" and watch her speech on containers.