

Amazon Redshift ML simplifies the operation of machine learning (ML) by using simple SQL statements to create and train machine learning (ML) models using the data in Amazon Redshift ML. You can use Amazon Redshift ML to solve binary classification, multi classification and regression problems, and you can directly use technologies such as AutoML or XGBoost.
- Amazon Redshift ML
https://aws.amazon.com/redshi... - Amazon Redshift
http://aws.amazon.com/redshift
📢 To learn more about the latest technology release and practical innovation of Amazon cloud technology, please pay attention to the 2021 Amazon cloud technology China summit! Click the picture to sign up ~
This article is part of the Amazon Redshift ML series. For more information about building regression using Amazon Redshift ML, see building regression models using Amazon Redshift ML.
- Building regression models using Amazon Redshift ML
https://aws.amazon.com/blogs/...
You can use Amazon Redshift ML to automate data preparation, preprocessing, and problem type selection, as described in this blog post. We assume that you have a good understanding of your data and the types of questions that best apply to your use case. This article will focus on creating a model in Amazon Redshift using the multi category problem type, which includes at least three categories. For example, you can predict whether the transaction is fraudulent, failed, or successful, whether the customer will remain active for 3, 6, 9, or 12 months, or whether the news will be marked as sports, world news, or business content.
- Blog post
https://aws.amazon.com/blogs/...
precondition
As a prerequisite for implementing this solution, you need to set up an Amazon Redshift cluster with machine learning (ML) enabled. For these preparation steps, see creating, training and deploying machine learning models in Amazon Redshift using SQL and Amazon Redshift ML:
https://aws.amazon.com/blogs/...
Use case
In our use case, we want to find the most active customers for a special customer loyalty program. We use Amazon Redshift ML and multi category model to predict how many months customers will be active in 13 months. This will translate into up to 13 possible classifications, so it is more suitable to adopt multiple classifications. Customers who are expected to remain active for 7 months or more will become the target group of the special customer loyalty program.
Input raw data
In order to prepare the original data of the model, we use the public data set e-commerce sales forecast (including the sales data of UK online retailers) to populate the ecommerce_sales table in Amazon Redshift.
- E-commerce sales forecast
https://www.kaggle.com/alluni...
Enter the following statement to load data into Amazon Redshift:
CREATE TABLE IF NOT EXISTS ecommerce_sales ( invoiceno VARCHAR(30) ,stockcode VARCHAR(30) ,description VARCHAR(60) ,quantity DOUBLE PRECISION ,invoicedate VARCHAR(30) ,unitprice DOUBLE PRECISION ,customerid BIGINT ,country VARCHAR(25) ) ; Copy ecommerce_sales From 's3://redshift-ml-multiclass/ecommerce_data.txt' iam_role '<<your-amazon-redshift-sagemaker-iam-role-arn>>' delimiter '\t' IGNOREHEADER 1 region 'us-east-1' maxerror 100;
To reproduce this script in your environment
your-amazon-redshift-sagemaker-iam-role-arn
Replace with Amazon Identity and Access Management (Amazon IAM) ARN for your Amazon Redshift cluster.
- Amazon Identity and Access Management
http://aws.amazon.com/iam
Data preparation of machine learning (ML) model
Now that our data set has been loaded, we can choose to split the data into three groups for training (80%), verification (10%) and prediction (10%). Please note that Amazon Redshift ML Autopilot will automatically split the data into training and verification, but if you split it here, you will be able to well verify the accuracy of the model. In addition, we will calculate the number of months our customers remain active because we want the model to predict this value based on new data. We use random functions in SQL statements to split data. Refer to the following codes:
create table ecommerce_sales_data as ( select t1.stockcode, t1.description, t1.invoicedate, t1.customerid, t1.country, t1.sales_amt, cast(random() * 100 as int) as data_group_id from ( select stockcode, description, invoicedate, customerid, country, sum(quantity * unitprice) as sales_amt from ecommerce_sales group by 1, 2, 3, 4, 5 ) t1 );
Training set
create table ecommerce_sales_training as ( select a.customerid, a.country, a.stockcode, a.description, a.invoicedate, a.sales_amt, (b.nbr_months_active) as nbr_months_active from ecommerce_sales_data a inner join ( select customerid, count( distinct( DATE_PART(y, cast(invoicedate as date)) || '-' || LPAD( DATE_PART(mon, cast(invoicedate as date)), 2, '00' ) ) ) as nbr_months_active from ecommerce_sales_data group by 1 ) b on a.customerid = b.customerid where a.data_group_id < 80 );
Validation set
create table ecommerce_sales_validation as ( select a.customerid, a.country, a.stockcode, a.description, a.invoicedate, a.sales_amt, (b.nbr_months_active) as nbr_months_active from ecommerce_sales_data a inner join ( select customerid, count( distinct( DATE_PART(y, cast(invoicedate as date)) || '-' || LPAD( DATE_PART(mon, cast(invoicedate as date)), 2, '00' ) ) ) as nbr_months_active from ecommerce_sales_data group by 1 ) b on a.customerid = b.customerid where a.data_group_id between 80 and 90 );
Prediction set
create table ecommerce_sales_prediction as ( select customerid, country, stockcode, description, invoicedate, sales_amt from ecommerce_sales_data where data_group_id > 90);
Create a model in Amazon Redshift
Now that we have created the training and validation dataset, we can use the create model statement in Amazon Redshift to use Multiclass_Classification creates our machine learning model. We specify the problem type and then let AutoML handle everything else. In this model, the goal we want to predict is nbr_months_active. Amazon SageMaker} created a function predict_customer_activity, which we will use to infer in Amazon Redshift. Refer to the following codes:
create model ecommerce_customer_activity from ( select customerid, country, stockcode, description, invoicedate, sales_amt, nbr_months_active from ecommerce_sales_training) TARGET nbr_months_active FUNCTION predict_customer_activity IAM_ROLE '<<your-amazon-redshift-sagemaker-iam-role-arn>>' problem_type MULTICLASS_CLASSIFICATION SETTINGS ( S3_BUCKET '<<your-amazon-s3-bucket-name>>', S3_GARBAGE_COLLECT OFF );
To reproduce this script in the environment, set
your-amazon-redshift-sagemaker-iam-role-arn
Replace with the Amazon IAM role ARN for the cluster.
- create model
https://docs.aws.amazon.com/r... - Amazon SageMaker
https://aws.amazon.com/sagema...
Validation prediction
In this step, we will evaluate the accuracy of the machine learning (ML) model against the validation data.
When creating a model, Amazon SageMaker Autopilot will automatically split the input data into training and verification sets, and select the model with the best objective index, which is deployed in Amazon Redshift cluster. You can use the show model statement in the cluster to view various indicators, including accuracy scores. If not explicitly specified, Amazon SageMaker automatically uses the accuracy of the target type. Refer to the following codes:
Show model ecommerce_customer_activity;
- Amazon SageMaker Autopilot
https://aws.amazon.com/sagema...
As shown in the following output, the accuracy of our model is 0.996580.
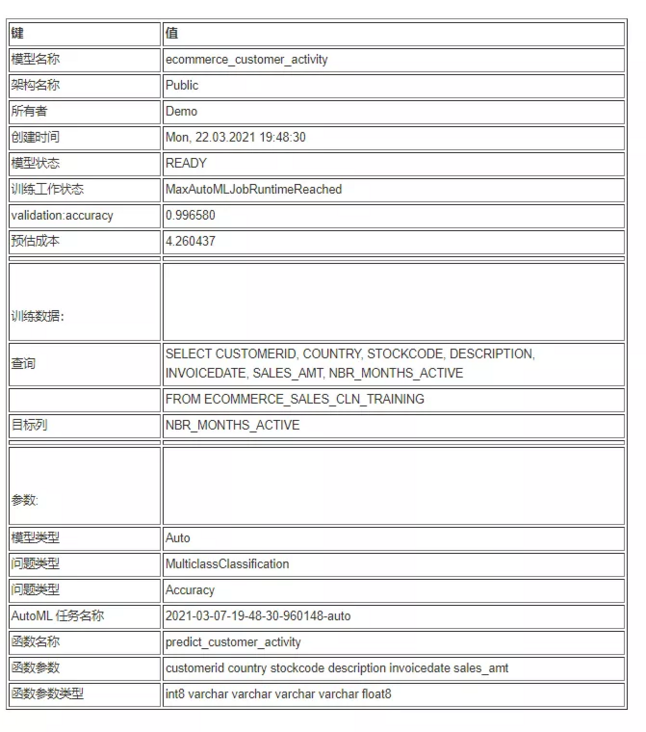
Let's use the following SQL code on the validation data to run an inference query on the validation data:
select cast(sum(t1.match)as decimal(7,2)) as predicted_matches ,cast(sum(t1.nonmatch) as decimal(7,2)) as predicted_non_matches ,cast(sum(t1.match + t1.nonmatch) as decimal(7,2)) as total_predictions ,predicted_matches / total_predictions as pct_accuracy from (select customerid, country, stockcode, description, invoicedate, sales_amt, nbr_months_active, predict_customer_activity(customerid, country, stockcode, description, invoicedate, sales_amt) as predicted_months_active, case when nbr_months_active = predicted_months_active then 1 else 0 end as match, case when nbr_months_active <> predicted_months_active then 1 else 0 end as nonmatch from ecommerce_sales_validation )t1;
It can be seen that the accuracy of prediction on our data set is 99.74%, which is consistent with the accuracy in show model.

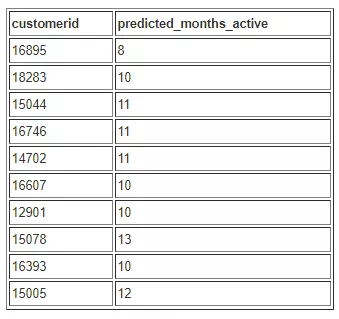
Now let's run a query to see which customers are eligible to participate in our customer loyalty program based on at least 7 months of activity:
select customerid, predict_customer_activity(customerid, country, stockcode, description, invoicedate, sales_amt) as predicted_months_active from ecommerce_sales_prediction where predicted_months_active >=7 group by 1,2 limit 10;
The following table shows our output results.
Troubleshooting
Although the Create Model statement in Amazon Redshift is automatically responsible for starting the Amazon SageMaker Autopilot process to build, train and adjust the best machine learning model and deploy the model in Amazon Redshift, you can view the intermediate steps performed in this process, which can also help you troubleshoot if problems occur. You can also retrieve the AutoML Job Name from the output of the show model command.
When creating a model, you need to set an Amazon Simple Storage Service (Amazon S3) bucket name as parameter S3_ The value of bucket. You can use this bucket to share training data and artifacts between Amazon Redshift and Amazon SageMaker. Amazon Redshift will create a subfolder in this bucket to save training data. After training, unless parameter S3_ garbage_ Set collect to off (available for troubleshooting), otherwise it will delete subfolders and their contents. For more information, see CREATE MODEL.
- Amazon Simple Storage Service
http://aws.amazon.com/s3 - CREATE MODEL
https://docs.aws.amazon.com/r...
For information about using the Amazon SageMaker console and Amazon SageMaker Studio, see building regression models using Amazon Redshift ML.
- Amazon SageMaker Studio
https://docs.aws.amazon.com/s... - Amazon Redshift ML builds regression model
https://aws.amazon.com/blogs/...
conclusion
Amazon Redshift ML provides a suitable platform for database users to create, train and adjust models using SQL interface. In this article, we will show you how to create a multi class classification model. We hope you can use Amazon Redshift ML to help gain valuable insights.
For more information about building different models using Amazon Redshift ML, see building regression models using Amazon Redshift ML and reading the Amazon Redshift ML documentation.
- Building regression models using Amazon Redshift ML
https://aws.amazon.com/blogs/... - Amazon Redshift
http://ocs.aws.amazon.com/red...
Acknowledge
According to the UCI machine learning (ML) repository, these data were provided by Dr. Chen Daqing, director of the public analysis group.
Email: chend@lsbu.ac.uk
School of Engineering, London South Bank University, London SE1 0AA, UK
Dua, D. and Graff, C.(2019). UCI machine learning (ML) repository[ http://archive.ics.uci.edu/ml].
Irvine, California: School of information and computer science, University of California.
Author of this article

Phil Bates
Amazon cloud technology
Senior data analysis expert solution architect
More than 25 years of data warehouse experience.

Debu Panda
Amazon cloud technology
Chief product manager
Industry leader in data analysis, application platform and database technology, with more than 25 years of experience in IT.

Nikos Koulouris
Amazon cloud technology
Software Development Engineer
Work in the field of database and data analysis.

Enrico Sartorello
Amazon cloud technology
Senior Software Development Engineer
Help customers adopt machine learning solutions that suit their needs by developing new features for Amazon SageMaker