1, Common web Cluster scheduler
1. At present, the common web Cluster scheduler is divided into software and hardware
2. The software usually uses open source LVS, Haproxy and Nginx
3. F5 is the most commonly used hardware, and many people use some domestic products, such as shuttle fish, green alliance, etc
2, Haproxy application analysis
1.LVS has strong anti load ability in enterprise application, but it has shortcomings
• LVS does not support regular processing and cannot realize dynamic and static separation
• for large websites, the implementation configuration of LVS is complex and the maintenance cost is relatively high
2.Haproxy is a proxy software that can provide high availability, load balancing and TCP and HTTP based applications
• suitable for web sites with heavy load
• connection requests running on hardware that can support tens of thousands of concurrent connections
3, Principle of Haproxy scheduling algorithm
Haproxy supports a variety of scheduling algorithms, three of which are most commonly used
① RR(Round Robin)
RR algorithm is the simplest and most commonly used algorithm, namely polling scheduling
For example:
• there are three nodes A, B and C
• the first user access is assigned to node A
• the first user access is assigned to node B
• the first user access is assigned to node C
• the fourth user access will be assigned to node A, polling and distributing access requests to achieve load balancing
② LC(Least Connections)
The minimum number of connections algorithm dynamically allocates the front-end requests according to the number of connections of the back-end nodes
For example:
• there are three nodes A, B and C, and the connection numbers of each node are A:4, B:5 and C:6 respectively
• the first user connection request will be assigned to A, and the number of connections will change to A:5, B:5 and C:6
• the second user request will continue to be allocated to A, and the number of connections will change to A:6, B:5 and C:6; New requests will be assigned to B, and new requests will be assigned to the client with the smallest number of connections each time
• because the number of connections of A, B and C will be released dynamically in practice, it is difficult to have the same number of connections
• compared with rr algorithm, this algorithm is greatly improved and is a - kind of algorithm used more at present
③ SH(Source Hashing)
Source based access scheduling algorithm is used in some scenarios where sessions will be recorded on the server. Cluster scheduling can be done based on source IP, cookies, etc
For example:
• there are three nodes A, B and C. The first user is assigned to A for the first access and the second user is assigned to B for the first access
• the first user will continue to be assigned to A during the second access, and the second user will still be assigned to B during the second access. As long as the load balancing scheduler does not restart, the first user access will be assigned to A and the second user access will be assigned to B to realize the scheduling of the cluster
• the advantage of this scheduling algorithm is to maintain the session, but when some IP accesses are very large, the load will be unbalanced, and the traffic of some nodes is too large, which will affect the service use
4, Haproxy features
HAProxy is a proxy that can provide high availability, load balancing and TCP and HTTP based applications. It is a free, fast and reliable solution. HAProxy is very suitable for large concurrent (and more than 1w developed) web sites, which usually need session persistence or seven layer processing. The running mode of HAProxy makes it easy and safe to integrate into the current architecture, and can protect the web server from being exposed to the network.
Main features of Haproxy
● very good reliability and stability, comparable to F5 load balancing equipment at hardware level;
● up to 40000-50000 concurrent connections can be maintained at the same time, the maximum number of requests processed per unit time is 20000, and the maximum processing capacity can reach 10Git/s;
● support up to 8 load balancing algorithms and session maintenance;
● support the function of virtual machine host, so as to realize more flexible web load balancing;
● support unique functions such as connection rejection and fully transparent proxy;
● strong ACL support for access control;
● its unique elastic binary tree data structure increases the complexity of the data structure to 0 (1), that is, the search speed of data will not decrease with the increase of data entries;
● support the keepalive function of the client, reduce the waste of resources caused by multiple handshakes between the client and haproxy, and allow multiple requests to be completed in one tcp connection;
● support TCP acceleration and zero replication function, similar to mmap mechanism;
● support response buffering;
● support RDP protocol;
● source based stickiness, similar to nginx's ip_hash function, which always schedules requests from the same client to the same upstream server within a certain period of time;
● better statistical data interface, whose web interface displays the statistical information of data received, sent, rejected, error and other data of each server in the back-end cluster;
● detailed health status detection. The web interface has the health detection status of the upstream server, and provides certain management functions;
● flow based health assessment mechanism;
● http based authentication;
● management interface based on command line;
● log analyzer, which can analyze logs.
There are many HAProxy load balancing strategies, including the following 8 common ones
● roundrobin: indicates simple polling.
● static RR: indicates the weight.
● leastconn: indicates that the least connected person will handle it first.
● source: indicates the source IP according to the request, which is similar to the IP of Nginx_ Hash mechanism.
● ri: indicates the URI according to the request.
● rl_param: it means to lock every HTTP request according to the HTTP request header.
● RDP cookie(name): it means that each TCP request is locked and hashed according to the cookie(name).
Differences among LVS, Nginx and HAproxy
● LVS realizes soft load balancing based on Linux operating system, while HAProxy and Nginx realize soft load balancing based on third-party applications;
● LVS is a 4-layer IP load balancing technology, which can not realize forwarding based on directory and URL. Both HAProxy and Nginx can implement layer 4 and layer 7 technologies. HAProxy can provide a comprehensive load balancing solution for TCP and HTTP applications;
● LVS works in the fourth layer of ISO model, so its status monitoring function is single, while HAProxy has richer and more powerful functions in status monitoring, and can support port, URL, script and other status detection methods;
● HAProxy is powerful, but its overall performance is lower than LVS load balancing in layer 4 mode.
● Nginx is mainly used for Web server or cache server.
5, Building Web cluster with Haproxy
Haproxy server: 192.168.110.10
Nginx server 1: 192.168.110.20
Nginx server 2: 192.168.110.60
Client: 192.168.110.123
1.haproxy server deployment
Compressed package link: link
Password: yt973d
1. Close the firewall and transfer the software package required to install Haproxy to the / opt directory
systemctl stop firewalld setenforce 0 cd /opt haproxy-1.5.19.tar.gz
2. Compile and install Haproxy
yum install -y pcre-devel bzip2-devel gcc gcc-c++ make tar zxvf haproxy-1.5.19.tar.gz cd haproxy-1.5.19/ make TARGET=linux2628 ARCH=x86_64 make install
Parameter description
Target = Linux 26 # kernel version,
#Use uname -r to view the kernel, such as 2.6.18-371 El5, in this case, TARGET=linux26 is used for this parameter; TARGET=linux2628 for kernel greater than 2.6.28
ARCH=x86_64 # system bits
3.Haproxy server configuration
mkdir /etc/haproxy cp /opt/haproxy-1.5.19/examples/haproxy.cfg /etc/haproxy/

cd /etc/haproxy/
vim haproxy.cfg
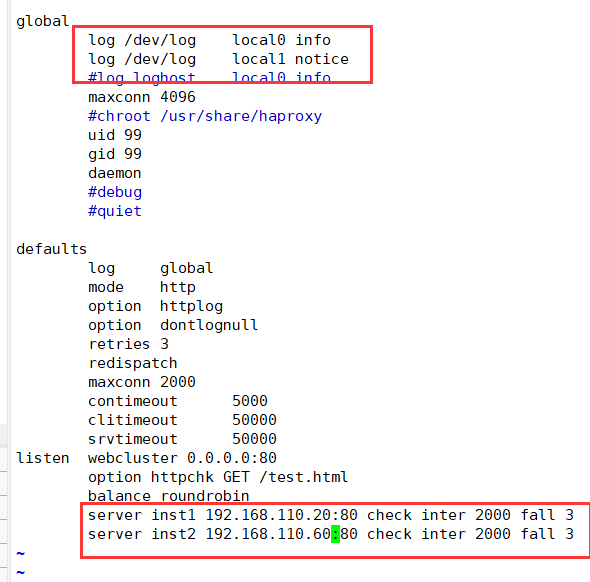
global
--4~5 that 's ok--Modify, configure logging, local0 It is a log device and is stored in the system log by default
log /dev/log local0 info
log /dev/log local0 notice
#log loghost local0 info
maxconn 4096 #For the maximum number of connections, consider the ulimit -n limit
--8 that 's ok--notes, chroot The running path is the root directory set by the service itself. Generally, this line needs to be commented out
#chroot /usr/share/haproxy
uid 99 #User UID
gid 99 #User GID
daemon #Daemon mode
defaults
log global #Define log is the log definition in global configuration
mode http #The mode is http
option httplog #Log in http log format
option dontlognull #Do not record health check log information
retries 3 #Check the number of failures of the node server. If there are three consecutive failures, the node is considered unavailable
redispatch #When the server load is very high, it will automatically end the connection that has been queued for a long time
maxconn 2000 #maximum connection
contimeout 5000 #Connection timeout
clitimeout 50000 #Client timeout
srvtimeout 50000 #Server timeout
--Delete all below listen term--,add to
listen webcluster 0.0.0.0:80 #Define an application called webcuster
option httpchk GET /test.html #Check the test of the server HTML file
balance roundrobin #The load balancing scheduling algorithm uses the polling algorithm roundrobin
server inst1 192.168.110.20:80 check inter 2000 fall 3 #Define online nodes
server inst2 192.168.110.60:80 check inter 2000 fall 3
Parameter description
balance roundrobin # load balancing scheduling algorithm
#Polling algorithm: roundrobin; Minimum connection number algorithm: leastconn; Source access scheduling algorithm: source, which is similar to the IP address of nginx_ hash
check inter 2000 # indicates a heartbeat rate between the haproxy server and the node
fall 3 # indicates that the node fails if the heartbeat frequency is not detected for three consecutive times
If the node is configured with "backup", it means that the node is only a backup node, and the node will not be connected until the primary node fails. If "backup" is not carried, it means the master node and provides services together with other master nodes.
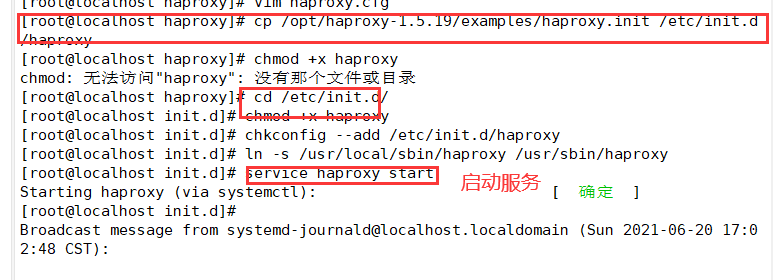
4. Add haproxy system service
cp /opt/haproxy-1.5.19/examples/haproxy.init /etc/init.d/haproxy chmod +x haproxy chkconfig --add /etc/init.d/haproxy ln -s /usr/local/sbin/haproxy /usr/sbin/haproxy service haproxy start or /etc/init.d/haproxy start
2. Node server deployment (192.168.110.20; 192.168.110.60)
1. Turn off the firewall
systemctl stop firewalld setenforce 0
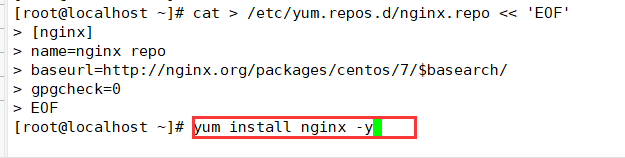
2. Install nginx using yum or up2date
cat > /etc/yum.repos.d/nginx.repo << 'EOF' [nginx] name=nginx repo baseurl=http://nginx.org/packages/centos/7/$basearch/ gpgcheck=0 EOF yum install nginx -y
3. Edit web files
--------------192.168.110.20-------------- cd /usr/share/nginx/html/ #The path to the Nginx site directory where yum is installed mv index.html index.html.bak #Rename the original home page file echo 'This is WEB1' > /usr/share/nginx/html/index.html #Recreate a home page file

--------------192.168.110.60-------------- cd /usr/share/nginx/html/ #The path to the Nginx site directory where yum is installed mv index.html index.html.bak #Rename the original home page file echo 'This is WEB2' > /usr/share/nginx/html/index.html #Recreate a home page file

4. Restart the service
systemctl restart nginx Start failed netstat -ntlp kill process
3. Test Web Cluster
Open using browser on client http://192.168.110.10/index.html , constantly refresh the browser to test the effect of load balancing
6, Log definition
#By default, the log of haproxy is output to the syslog of the system, which is not very convenient to view. In order to better manage the log of haproxy, we generally define it separately in the production environment. The info and notice logs of haproxy need to be recorded in different log files. vim /etc/haproxy/haproxy.cfg global log /dev/log local0 info log /dev/log local0 notice service haproxy restart
#The rsyslog configuration needs to be modified to facilitate management. Define the configuration related to haproxy independently to haproxy Conf and put it in / etc / rsyslog D /, all configuration files in this directory will be loaded automatically when rsyslog is started. vim /etc/rsyslog.d/haproxy.conf if ($programname == 'haproxy' and $syslogseverity-text == 'info') then -/var/log/haproxy/haproxy-info.log &~ if ($programname == 'haproxy' and $syslogseverity-text == 'notice') then -/var/log/haproxy/haproxy-notice.log &~
explain:
This part of the configuration is to record the info log of haproxy to / var / log / haproxy / haproxy info Log, record the notice log to / var / log / haproxy / haproxy notice Log. "&~" means that rsyslog stops processing this information after the log is written to the log file.
systemctl restart rsyslog.service tail -f /var/log/haproxy/haproxy-info.log #View the access request log information of haproxy
7, Haproxy parameter optimization
With the increasing load of enterprise websites, the optimization of haproxy parameters is very important
• maxconn: the maximum number of connections, which can be adjusted according to the actual situation of the application. It is recommended to use 10 240
• daemon: daemon mode. Haproxy can be started in non daemon mode. It is recommended to start in daemon mode
• nbproc: the number of concurrent processes for load balancing. It is recommended to be equal to or twice the number of CPU cores of the current server
◆ retries: the number of retries, which is mainly used to check the cluster nodes. If there are many nodes and a large amount of concurrency, set it to 2 or 3 times
• option http server close: actively turn off the http request option,
This option is recommended for production environments
• timeout HTTP keep alive: long connection timeout, set long connection timeout
The time can be set to 10s
• timeout HTTP request: the timeout time of the HTTP request, which is recommended to be
Set it to 5~ 10s to increase the release speed of http connection
• timeout client: the timeout time of the client. If the number of accesses is too large, the node
The response is slow. You can set this time to be shorter. It is recommended to set it to about 1min
That's it