Python WeChat Subscription Applet Course Video
https://edu.csdn.net/course/detail/36074
Python Actual Quantitative Transaction Finance System
https://edu.csdn.net/course/detail/35475
In the previous article, we have obtained the output stream of business data, which is the output stream of dim layer dimension data and the output stream of dwd layer fact data. Next, what we need to do is to flow these output streams to the corresponding data media separately. The dim layer flows to hbase, and the dwd layer is still written back to kafka.
1. Dimension of shunts table sink to hbase
As a result of the previous article, the dimension data output stream hbaseDs on the side, and the fact data in the mainstream filterDs is as follows:
//5. Dynamic streaming, fact table writing kafka, dimension table writing hbase
OutputTag<JSONObject> hbaseTag = new OutputTag<JSONObject>(TableProcess.SINK\_TYPE\_HBASE){};
//Create a custom mapFunction function
SingleOutputStreamOperator<JSONObject> kafkaTag = filterDs.process(new TableProcessFunction(hbaseTag));
DataStream<JSONObject> hbaseDs = kafkaTag.getSideOutput(hbaseTag);
filterDs.print("json str --->>");
The process is as follows:
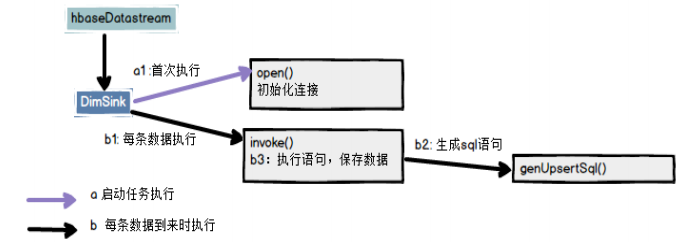
Custom RickSinkFunction class: DimSink.java
- Initialize phoenix connection
- Save data
1.1 Configuration
In the BaseDbTask task, we have obtained the output stream of hbase, and then we can start a series of operations for hbase.
Add phoenix Dependency Package
<dependency> <groupId>org.apache.phoenixgroupId> <artifactId>phoenix-sparkartifactId> <version>5.0.0-HBase-2.0version> <exclusions> <exclusion> <groupId>org.glassfishgroupId> <artifactId>javax.elartifactId> exclusion> exclusions> dependency>
Modify hbase-site.xml, because a separate schema is used, hbase-site is also included in the Idea program. XML
In order to open the schema mapping of namespace and phoenix for hbase, this configuration file needs to be added to the program, as well as hbase-site for HBase and phoenix on the linux service. In the XML configuration file, add the above two configurations and synchronize using xsync.
xml version="1.0"? xml-stylesheet type="text/xsl" href="configuration.xsl"? <configuration> <property> <name>hbase.rootdirname> <value>hdfs://hadoop101:9000/hbasevalue> property> <property> <name>hbase.cluster.distributedname> <value>truevalue> property> <property> <name>hbase.zookeeper.quorumname> <value>hadoop101,hadoop102,hadoop103value> property> <property> <name>hbase.table.sanity.checksname> <value>falsevalue> property> <property> <name>phoenix.schema.isNamespaceMappingEnabledname> <value>truevalue> property> <property> <name>phoenix.schema.mapSystemTablesToNamespacename> <value>truevalue> property> configuration>
1.2 Create Namespace
Execute in phoenix
create schema GMALL_REALTIME;
1.3 DimSink.java
Custom addSink class
package com.zhangbao.gmall.realtime.app.func;
import com.alibaba.fastjson.JSONObject;
import com.google.common.base.Strings;
import com.zhangbao.gmall.realtime.common.GmallConfig;
import lombok.extern.log4j.Log4j2;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* @author: zhangbao
* @date: 2021/9/4 12:23
* @desc: Write dimension tables to hbase
**/
@Log4j2
public class DimSink extends RichSinkFunction {
private Connection conn = null;
@Override
public void open(Configuration parameters) throws Exception {
log.info("establish phoenix Connect...");
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
conn = DriverManager.getConnection(GmallConfig.PHOENIX\_SERVER);
log.info("phoenix Connection successful!");
}
@Override
public void invoke(JSONObject jsonObject, Context context) throws Exception {
String sinkTable = jsonObject.getString("sink\_table");
JSONObject data = jsonObject.getJSONObject("data");
PreparedStatement ps = null;
if(data!=null && data.size()>0){
try {
//Generate an upsert statement for phoenix containing insert and update operations
String sql = generateUpsert(data,sinkTable.toUpperCase());
log.info("Start execution phoenix sql -->{}",sql);
ps = conn.prepareStatement(sql);
ps.executeUpdate();
conn.commit();
log.info("implement phoenix sql Success");
} catch (SQLException throwables) {
throwables.printStackTrace();
throw new RuntimeException("implement phoenix sql Failed!");
}finally {
if(ps!=null){
ps.close();
}
}
}
}
//Generate upsert sql
private String generateUpsert(JSONObject data, String sinkTable) {
StringBuilder sql = new StringBuilder();
//upsert into scheme.table(id,name) values('11','22')
sql.append("upsert into "+GmallConfig.HBASE\_SCHEMA+"."+sinkTable+"(");
//Split Column Name
sql.append(StringUtils.join(data.keySet(),",")).append(")");
//Fill value
sql.append("values('"+ StringUtils.join(data.values(),"','")+"')");
return sql.toString();
}
}
Then join in the main program
//6. Write dimension tables into hbase hbaseDs.addSink(new DimSink());
1.4 Test
- Services that need to be started
hdfs,zk,kafka,Maxwell,hbase,BaseDbTask.java
- Modify configuration data: gmall2021_realtime.table_process
INSERT INTO `gmall2021\_realtime`.`table\_process` (`source\_table`, `operate\_type`, `sink\_type`, `sink\_table`, `sink\_columns`, `sink\_pk`, `sink\_extend`) VALUES ('base\_trademark', 'insert', 'hbase', 'dim\_base\_trademark', 'id,tm\_name', 'id', NULL);
This configuration data represents if the table base_ When trademark inserts data, it synchronizes the data into hbase and automatically creates tables as dimension data.
- Modify table data in business library: gmall2021.base_trademark
INSERT INTO `gmall2021`.`base\_trademark` (`id`, `tm\_name`, `logo\_url`) VALUES ('15', '55', '55');
- View phoenix data: select * from GMALL_REALTIME.BASE_TRADEMARK;
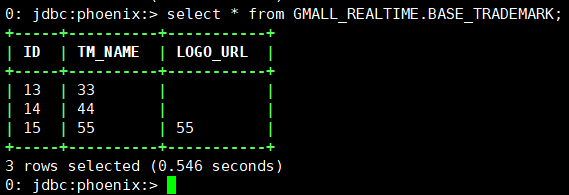
The data has been synchronized to hbase in real time.
2. Shunt fact table sink to kafka
2.1 MyKafkaUtil Definition New Method
Define a new producer method in MyKafkaUtil that dynamically specifies a topic or, if not, produces to the default topic:default_data
/**
* Produce dynamically to a different topic, or automatically to the default topic if no topic is passed
* @param T Serialized data, subject can be specified
*/
public static FlinkKafkaProducer getKafkaBySchema(KafkaSerializationSchema T){
Properties pros = new Properties();
pros.setProperty(ProducerConfig.BOOTSTRAP\_SERVERS\_CONFIG,KAFKA\_HOST);
return new FlinkKafkaProducer(DEFAULT\_TOPIC,T,pros,FlinkKafkaProducer.Semantic.EXACTLY\_ONCE);
}
Use in main task BaseDbTask
//7. Write factual data back to kafka
FlinkKafkaProducer<JSONObject> kafkaBySchema = MyKafkaUtil.getKafkaBySchema(new KafkaSerializationSchema<JSONObject>() {
@Override
public void open(SerializationSchema.InitializationContext context) throws Exception {
System.out.println("kafka serialize open");
}
@Override
public ProducerRecord serialize(JSONObject jsonObject, @Nullable Long aLong) {
String sinkTopic = jsonObject.getString("sink\_table");
return new ProducerRecord<>(sinkTopic, jsonObject.getJSONObject("data").toString().getBytes());
}
});
kafkaTag.addSink(kafkaBySchema);
2.2 Test
- Services that need to be started
hdfs,zk,kafka,Maxwell,hbase,BaseDbTask.java
- Modify configuration information: gmall2021_realtime.table_process
INSERT INTO `gmall2021\_realtime`.`table\_process` (`source\_table`, `operate\_type`, `sink\_type`, `sink\_table`, `sink\_columns`, `sink\_pk`, `sink\_extend`) VALUES ('order\_info', 'insert', 'kafka', 'dwd\_order\_info', 'id,consignee,consignee\_tel,total\_amount,order\_status,user\_id,payment\_way,delivery\_address,order\_comment,out\_trade\_no,trade\_body,create\_time,operate\_time,expire\_time,process\_status,tracking\_no,parent\_order\_id,img\_url,province\_id,activity\_reduce\_amount,coupon\_reduce\_amount,original\_total\_amount,feight\_fee,feight\_fee\_reduce,refundable\_time', 'id', NULL);
Represents table order_ If info has inserted data, it will be synchronized to kafka with topic dwd_order_info.
- Start kafka consumers to see if there is data coming in
[zhangbao@hadoop101 root]$ cd /opt/module/kafka/bin/
[zhangbao@hadoop101 bin]$ ./kafka-console-consumer.sh --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic dwd_order_info
- Finally, start the Business Data Generation Service: mock-db-0.0.1-SNAPSHOT.jar
Remember to modify the profile generation date first: 2021-09-12
Finally, when you look at kafka consumers, you can see data generation, indicating that the process is working.
3. Introduction to Operator Selection
| function | Convertible Structure | Filterable data | Side Output | open | Available Status | Output to |
|---|---|---|---|---|---|---|
| MapFunction | Yes | Downstream Operator | ||||
| FilterFunction | Yes | Downstream Operator | ||||
| RichMapFunction | Yes | Yes | Yes | Downstream Operator | ||
| RichFilterFunction | Yes | Yes | Yes | Downstream Operator | ||
| ProcessFunction | Yes | Yes | Yes | Yes | Yes | Downstream Operator |
| SinkFunction | Yes | Yes | external | |||
| RichSinkFunction | Yes | Yes | Yes | Yes | external |