1. MySql B + index benefits
(1) B + tree query is more efficient. The B + tree uses a two-way linked list to connect all leaf nodes, which makes the interval query more efficient (because all data are in the leaf nodes of the B + tree, you only need to scan the leaf nodes once to scan the database).
(2) B + tree query efficiency is more stable. The B + tree must query the leaf node every time to find the data, and the data queried by the B + tree may not be in the leaf node or in the leaf node, which will lead to the instability of query efficiency
(3) The disk read and write cost of B + tree is less. The internal node of the B + tree does not point to the specific information of the keyword, so its internal node is smaller than that of the B + tree. Generally, the B + tree is shorter and fatter, and the height is small. The query generates less I/O.
If the depth of the tree is high, the time of data query mainly depends on the number of disk IO. The greater the depth of the binary tree, the more search times, and the worse the performance. The characteristic of B + tree is that it is short and fat enough, which can effectively reduce the number of visits to nodes, so as to improve the performance.
2. MySql isolation level
(1) Read Uncommitted: at this isolation level, all transactions can see the execution results of other uncommitted transactions. This isolation level is rarely used in practical applications because its performance is not much better than other levels. Reading uncommitted data is also called Dirty Read.
(2) Read Committed: This is the default isolation level of most database systems (but not MySQL default). It satisfies the simple definition of isolation: a transaction can only see the changes made by the committed transaction. This isolation level also supports the so-called Nonrepeatable Read. Because other instances of the same transaction may have new commitments during the processing of the instance, the same select may return different results.
(3) Repeatable Read: This is the default transaction isolation level of MySQL. It ensures that multiple instances of the same transaction will see the same data row when reading data concurrently. But in theory, this leads to another thorny problem: Phantom Read. Simply put, phantom reading means that when a user reads a data row in a certain range, another transaction inserts a new row in the range. When the user reads a data row in the range again, it will find a new "phantom" row. InnoDB and Falcon storage engines solve this problem through the multi version concurrency control (MVCC) mechanism.
(4) Serializable: This is the highest isolation level. It solves the unreal reading problem by forcing transaction sequencing to make it impossible to conflict with each other. In short, it adds a shared lock to each read data row. At this level, a large number of timeouts and lock contention may result.
3. Unreal reading and dirty reading
(1) Unreal reading: unreal reading means that a transaction finds that a record does not exist after a query, and then carries out the next operation according to the result. At this time, if another transaction successfully inserts the record, for the first transaction, it is likely to report an error when carrying out the next operation (such as inserting the record). From the perspective of transaction usage, there should be no problem inserting a record after checking that it does not exist, but the exception of primary key conflict is thrown here.
(2) Dirty read: a transaction has updated a copy of data, and another transaction has read the same copy of data at this time. For some reasons, if the previous RollBack operation, the data read by the latter transaction will be incorrect.
(3) Solution to unreal reading:
- a. SERIALIZABLE serialization: when a transaction is read, a table level shared lock is added first, and it is not released until the end of the transaction; During the write operation of a transaction, an exclusive lock at the table level is added first, and it is not released until the end of the transaction
- b. Mvcc + next key lock: next key lock is a combined version of Gap Lock and Record Lock, both of which belong to the locking mechanism of Innodb. For example: select * from TB where id > 100 for update;
<1> The primary key index ID will add a record row lock to the record with id=100
<2> A gap lock will be added to the index id to lock the range of id(100, + infinity)
Other transactions will block the reading and writing of records with ID > 100;
When inserting a record with id=1000, the lock added to the index will be hit, and a transaction exception will be reported;
Next key lock will determine A range, and then lock the range to ensure that the data read by A under the condition of where is consistent, because other transactions in the range of where cannot insert or delete data at all, and are blocked by next key lock.
4. A process of HTTP request
Domain name resolution -- > initiate three handshakes of TCP -- > initiate an http request after establishing a TCP connection -- > the server responds to the http request, and the browser gets the html code -- > the browser parses the html code and requests the resources in the html code (such as js, css, pictures, etc.) -- > the browser renders the page to the user
HTTPS request process
Get the IP address through DNS resolution – > make a TCP connection with the server – > establish an SSL session – > send and receive data – > disconnect the TCP connection
1. The client sends a request for an https connection.
2. The server returns an encrypted public key, usually an SSL certificate.
3. The client parses the public key from the SSL certificate, randomly generates a key, encrypts the key with the public key and sends it to the server (this step is safe because only the server has the private key and can read the key).
4. The server decrypts the key through the private key.
5. The client uses this key to encrypt the data to be transmitted.
6. The server uses the key to parse the data.
5. TCP three handshakes and four waves
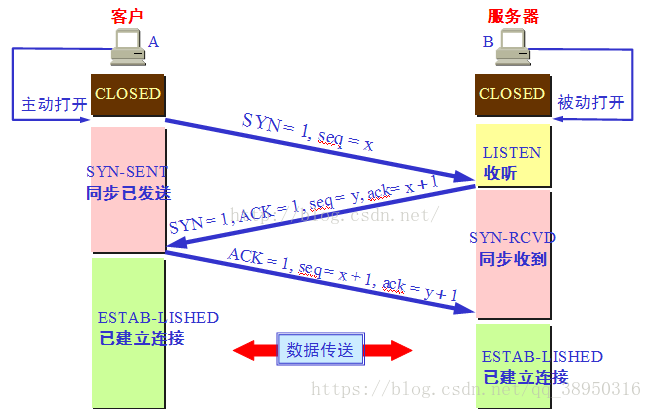
1. TCP third Handshake: the first handshake: when establishing a connection, the client sends a syn packet (syn=x) to the server and enters syn_ Send status, waiting for the server to confirm; SYN: Synchronize Sequence Numbers.
The second handshake: when the server receives the syn packet, it must confirm the syn (ack=x+1) of the customer. At the same time, it also sends a syn packet (syn=y), that is, SYN+ACK packet. At this time, the server enters SYN_RECV status;
The third Handshake: the client receives the SYN+ACK packet from the server and sends a confirmation packet ACK(ack=y+1) to the server. After the packet is sent, the client and the server enter the state of ESTABLISHED (TCP connection succeeded) and complete the three handshakes.
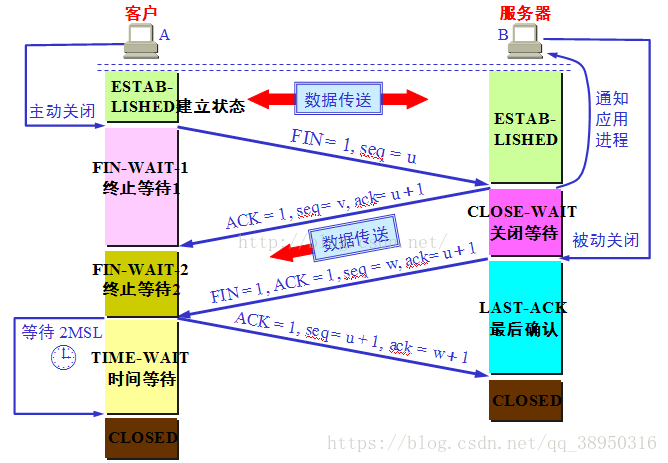
2. Four waves: 1) the client process sends a connection release message and stops sending data. Release the header of the data message, FIN=1, and its serial number is seq=u (equal to the serial number of the last byte of the previously transmitted data plus 1). At this time, the client enters the FIN-WAIT-1 state. TCP stipulates that FIN message segment will consume a serial number even if it does not carry data.
2) The server receives the connection release message, sends a confirmation message, ACK=1, ack=u+1, and takes its own serial number seq=v. at this time, the server enters the CLOSE-WAIT state. The TCP server notifies the high-level application process, and the direction of the client to the server is released. At this time, it is in a semi closed state, that is, the client has no data to send, but if the server sends data, the client still needs to accept it. This state will last for a period of time, that is, the duration of the whole CLOSE-WAIT state.
3) After the client receives the confirmation request from the server, at this time, the client enters the FIN-WAIT-2 state and waits for the server to send the connection release message (before that, it also needs to accept the last data sent by the server).
4) After sending the last data, the server will send the connection release message to the client, FIN=1, ack=u+1. Since it is in the semi closed state, the server is likely to send some data. Assuming that the serial number at this time is seq=w, the server will enter the LAST-ACK state and wait for the confirmation of the client.
5) After receiving the connection release message from the server, the client must send a confirmation, ACK=1, ack=w+1, and its serial number is seq=u+1. At this time, the client enters the TIME-WAIT state. Note that at this time, the TCP connection has not been released. After 2 * MSL (maximum message segment life), the client can enter the CLOSED state only after canceling the corresponding TCB.
6) As long as the server receives the confirmation from the client, it will immediately enter the CLOSED state. Similarly, after canceling the TCB, the TCP connection is ended. It can be seen that the server ends the TCP connection earlier than the client.
[question 1] Why do you shake hands three times when connecting and four times when closing?
A: because when the Server receives the SYN connection request message from the Client, it can directly send SYN+ACK message. Among them, ACK message is used for response and SYN message is used for synchronization. However, when closing the connection, when the Server receives the FIN message, it is likely that the SOCKET will not be closed immediately, so it can only reply to an ACK message and tell the Client, "I received the FIN message you sent". I can only send FIN messages when all messages on my Server are sent, so I can't send them together. Therefore, a four-step handshake is required.
[Q2] why TIME_WAIT status needs 2msl (maximum message segment lifetime) to return to CLOSE status?
A: although it is reasonable that all four messages have been sent and we can directly enter the CLOSE state, we must pretend that the network is unreliable and the last ack can be lost. So TIME_WAIT status is used to retransmit ack messages that may be lost. The Client sends the last ack reply, but the ACK may be lost. If the Server does not receive an ACK, it will repeatedly send FIN fragments. Therefore, the Client cannot CLOSE immediately. It must confirm that the Server has received the ACK. The Client will enter time after sending an ACK_ Wait status. The Client will set a timer to wait for 2MSL. If FIN is received again within this time, the Client will resend the ACK and wait for 2MSL again. The so-called 2MSL is twice the MSL(Maximum Segment Lifetime). MSL refers to the maximum survival time of a segment in the network. 2MSL is the maximum time required for a send and a reply. If the Client does not receive FIN again until 2MSL, the Client concludes that the ACK has been successfully received and ends the TCP connection.
[Q3] why can't you connect with two handshakes?
A: three handshakes complete two important functions. Both parties should make preparations for sending data (both parties know that each other is ready) and allow both parties to negotiate the initial serial number, which is sent and confirmed during the handshake.
Now change three handshakes to only two handshakes, and deadlock is possible. As an example, considering the communication between computers s and C, suppose C sends a connection request packet to s, s receives the packet and sends an acknowledgement response packet. According to the protocol of two handshakes, s considers that the connection has been successfully established and can start sending data packets. However, when the reply packet of S is lost in transmission, C will not know whether s is ready, what serial number s establishes, and C even doubts whether s has received its own connection request packet. In this case, C considers that the connection has not been established successfully, and will ignore any data packets sent by s and only wait for the connection confirmation response packet. S repeatedly sends the same packet after the packet sent times out. This creates a deadlock.
[Q4] what if the connection has been established, but the client suddenly fails?
TCP also has a keep alive timer. Obviously, if the client fails, the server can't wait all the time, wasting resources in vain. Every time the server receives a request from the client, it will reset the timer. The time is usually set to 2 hours. If no data is received from the client within 2 hours, the server will send a detection message segment, and then send it every 75 seconds. If there is still no response after sending 10 detection messages in a row, the server considers that the client has failed, and then closes the connection.
6. Where is the system call overhead
You need to switch from user mode to kernel mode during system call. Since the kernel state stack uses the kernel stack, it is also necessary to switch the stack. SS, ESP, EFLAGS, CS and EIP registers all need to be switched. Moreover, there may be an implicit problem after stack switching, that is, the instructions and data scheduled by the CPU destroy the locality to a certain extent, resulting in a decline in the hit rate of level 1, 2 and 3 data cache and TLB page table cache to a certain extent. In addition to the above environment switching of stack and register, due to the high privilege level of system call, it also needs to carry out a series of permission verification, validity and other related operations. Therefore, the overhead of system call is much larger than that of function call.
7. User mode and kernel mode
Kernel mode: cpu can access all data in memory, including peripheral devices, such as hard disk and network card. cpu can also switch itself from one program to another.
User mode: only limited access to memory and no access to peripheral devices are allowed. The ability to occupy cpu is deprived, and cpu resources can be obtained by other programs.
8. Process thread co process

(1) A process is a program with certain independent functions. It is a running activity on a data set. A process is an independent unit for resource allocation and scheduling. Each process has its own independent memory space, and different processes communicate through inter process communication. Because processes are relatively heavy and occupy independent memory, the switching overhead between context processes (stack, register, virtual memory, file handle, etc.) is relatively large, but relatively stable and safe.
(2) Thread is an entity of a process. It is the basic unit of CPU scheduling and dispatching. It is a smaller basic unit that can run independently than a process The thread itself basically does not own system resources, but only some essential resources in operation (such as program counters, a set of registers and stacks), but it can share all the resources owned by the process with other threads belonging to the same process. The communication between threads is mainly through shared memory. The context switching is fast and the resource overhead is less. However, compared with the process, it is not stable and easy to lose data.
(3) Collaborative process is a kind of lightweight thread in user mode, and the scheduling of collaborative process is completely controlled by users. A coroutine has its own register context and stack. During coprocess scheduling switching, the register context and stack are saved to other places. When switching back, the previously saved register context and stack are restored. Directly operating the stack basically has no cost of kernel switching, and the global variables can be accessed without locking, so the context switching is very fast.
[difference between thread and process]
- Address space: a thread is an execution unit in a process. There is at least one thread in the process. They share the address space of the process, and the process has its own independent address space
- Resource ownership: a process is a unit of resource allocation and ownership. Threads in the same process share the resources of the process
- Thread is the basic unit of processor scheduling, but process is not
- Both can be executed concurrently
- Each independent thread has an entry for program operation, sequential execution sequence and program exit, but the thread cannot execute independently. It must exist in the application, and the application provides multiple thread execution control
[difference between thread and co process]
- A thread can have multiple coroutines, and a process can also have multiple coroutines alone, so that multi-core CPU can be used in python.
- Thread processes are synchronous, while coprocesses are asynchronous
- The coroutine can retain the state of the last call. Each time the procedure re enters, it is equivalent to entering the state of the last call
9. Communication mode between processes and threads
[process]
(1) Pipe: pipe is a half duplex communication mode. Data can only flow in one direction and can only be used between processes with kinship. The kinship of process usually refers to the parent-child process relationship.
(2) Named pipeline FIFO: named pipeline is also a half duplex communication mode, but it allows communication between unrelated processes.
(3) Message queue: message queue is a linked list of messages, stored in the kernel and identified by the message queue identifier. Message queue overcomes the disadvantages of less signal transmission information, the pipeline can only carry unformatted byte stream and the limited buffer size.
(4) Shared memory: shared memory is a memory that can be accessed by other processes. This shared memory is created by one process, but can be accessed by multiple processes. Shared memory is the fastest IPC mode. It is specially designed for the low efficiency of other inter process communication modes. It is often used in conjunction with other communication mechanisms, such as semaphores, to achieve synchronization and communication between processes.
(5) Semaphore semaphore: semaphore is a counter that can be used to control the access of multiple processes to shared resources. It is often used as a locking mechanism to prevent other processes from accessing shared resources when a process is accessing them. Therefore, it is mainly used as a synchronization means between processes and between different threads in the same process.
(6) Socket socket: socket is also an interprocess communication mechanism. Different from other communication mechanisms, it can be used for different and interprocess communication.
(7) Signal: signal is a relatively complex communication method, which is used to inform the receiving process that an event has occurred.
[thread]
(1) volatile keyword mode
volatile has two major features: one is visibility and the other is orderliness. It prohibits instruction reordering. Visibility is to enable communication between threads.
Example:
// An highlighted block
public class VolatileDemo {
private static volatile boolean flag = true;
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
while (true){
if (flag){
System.out.println("trun on");
flag = false;
}
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
while (true){
if (!flag){
System.out.println("trun off");
flag = true;
}
}
}
}).start();
}
}
Result: continuous alternating printing
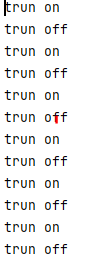
If the volatile keyword is removed, the thread will not be able to perceive the change of flag after switching for a certain number of times. At first, the perception is due to the poor thread startup time.
(2) Waiting / notification mechanism
The wait notification mechanism is implemented based on wait and notify methods. Call the wait method of the thread lock object in a thread, and the thread will enter the wait queue to wait until it is notified or awakened.
public class Main {
private static Object lock = new Object();
private static boolean flag = true;
public static void main(String[] args) throws IOException {
new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
while (flag) {
try {
System.out.println("wait start .......");
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("wait end ....... ");
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
if (flag) {
synchronized (lock) {
if (flag) {
lock.notify();
System.out.println("notify .......");
flag = false;
}
}
}
}
}).start();
}
}

(3) join mode
In fact, join can be understood as thread merging. When one thread calls the join method of another thread, the current thread is blocked and cannot continue to execute until the thread called the join method is executed. Therefore, the benefits of join can ensure the execution order of threads. However, if the join method of calling thread has lost the meaning of parallelism, although there are multiple threads, But it is still serial in nature. The implementation of the final join is actually based on the waiting notification mechanism.
(4) threadLocal mode
threadLocal mode of thread communication is not like the above three modes of communication between multiple threads. It is more like the communication within a thread. It binds the current thread to a map. Data can be accessed arbitrarily in the current thread, reducing the transmission of parameters between method calls.
10. Encryption algorithm
Common symmetric encryption algorithms mainly include DES,3DES,AES Common asymmetric algorithms mainly include RSA,DSA Hash algorithms mainly include SHA-1,MD5 Wait.
Common signature encryption algorithms
(1) MD5 algorithm
- MD5 uses hash function. Its typical application is to generate information summary for a piece of information to prevent tampering. Strictly speaking, MD5 is not an encryption algorithm, but a digest algorithm. No matter how long the input is, MD5 will output a string with a length of 128bits (usually expressed as 32 characters in hexadecimal).
public static final byte[] computeMD5(byte[] content) { try { MessageDigest md5 = MessageDigest.getInstance("MD5"); return md5.digest(content); } catch (NoSuchAlgorithmException e) { throw new RuntimeException(e); } }
(2) SHA1 algorithm
- SHA1 is the same popular message digest algorithm as MD5. However, SHA1 is more secure than MD5. For messages with a length of less than 2 ^ 64 bits, SHA1 will generate a 160 bit message summary. Based on MD5 and SHA1, the information summarization feature and irreversibility (generally speaking) can be applied to the scenarios of checking file integrity and digital signature.
public static byte[] computeSHA1(byte[] content) { try { MessageDigest sha1 = MessageDigest.getInstance("SHA1"); return sha1.digest(content); } catch (NoSuchAlgorithmException e) { throw new RuntimeException(e); } }
(3) HMAC algorithm
- HMAC is a key related hash operation message authentication code. HMAC operation uses hash algorithm (MD5, SHA1, etc.) to generate a message summary as output with a key and a message as input. The HMAC sender and receiver both have keys to calculate, but the third party without this key cannot calculate the correct hash value, so as to prevent the data from being tampered with.
package net.pocrd.util; import net.pocrd.annotation.NotThreadSafe; import net.pocrd.define.ConstField; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import javax.crypto.Mac; import javax.crypto.SecretKey; import javax.crypto.spec.SecretKeySpec; import java.util.Arrays; @NotThreadSafe public class HMacHelper { private static final Logger logger = LoggerFactory.getLogger(HMacHelper.class); private Mac mac; /** * MAC The following algorithms can be selected: * HmacMD5/HmacSHA1/HmacSHA256/HmacSHA384/HmacSHA512 */ private static final String KEY_MAC = "HmacMD5"; public HMacHelper(String key) { try { SecretKey secretKey = new SecretKeySpec(key.getBytes(ConstField.UTF8), KEY_MAC); mac = Mac.getInstance(secretKey.getAlgorithm()); mac.init(secretKey); } catch (Exception e) { logger.error("create hmac helper failed.", e); } } public byte[] sign(byte[] content) { return mac.doFinal(content); } public boolean verify(byte[] signature, byte[] content) { try { byte[] result = mac.doFinal(content); return Arrays.equals(signature, result); } catch (Exception e) { logger.error("verify sig failed.", e); } return false; } }Test conclusion: HMAC Algorithm instances are unsafe in multithreaded environments. However, the auxiliary class that needs to be synchronized during multi-threaded access is used ThreadLocal Caching one instance per thread can avoid locking.
(4) AES/DES/3DES algorithm
AES, DES and 3DES are symmetric block encryption algorithms, and the process of encryption and decryption is reversible. AES128, AES192 and AES256 are commonly used (the JDK installed by default does not support AES256, and the corresponding JCE patches need to be installed to upgrade jce1.7 and jce1.8).
- DES algorithm
DES encryption algorithm is a block cipher, which encrypts data in 64 bits. Its key length is 56 bits. The same algorithm is used for encryption and decryption. DES encryption algorithm is to keep the key secret, while the public algorithm includes encryption and decryption algorithms. In this way, only those who have the same key as the sender can interpret the ciphertext data encrypted by DES encryption algorithm. Therefore, deciphering DES encryption algorithm is actually the coding of search key. For a 56 bit key, if the exhaustive search method is used, the number of operations is 2 ^ 56 times. - 3DES algorithm
It is a symmetric algorithm based on DES, which encrypts a piece of data three times with three different keys, with higher strength. - AES algorithm
AES encryption algorithm is an advanced encryption standard in cryptography. The encryption algorithm adopts symmetrical block cipher system. The minimum support of key length is 128 bits, 192 bits and 256 bits, and the packet length is 128 bits. The algorithm should be easy to implement in various hardware and software. This encryption algorithm is a block encryption standard adopted by the federal government of the United States.
AES itself is to replace DES. AES has better security, efficiency and flexibility.
import net.pocrd.annotation.NotThreadSafe;
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
import java.security.SecureRandom;
@NotThreadSafe
public class AesHelper {
private SecretKeySpec keySpec;
private IvParameterSpec iv;
public AesHelper(byte[] aesKey, byte[] iv) {
if (aesKey == null || aesKey.length < 16 || (iv != null && iv.length < 16)) {
throw new RuntimeException("Bad initial key");
}
if (iv == null) {
iv = Md5Util.compute(aesKey);
}
keySpec = new SecretKeySpec(aesKey, "AES");
this.iv = new IvParameterSpec(iv);
}
public AesHelper(byte[] aesKey) {
if (aesKey == null || aesKey.length < 16) {
throw new RuntimeException("Bad initial key");
}
keySpec = new SecretKeySpec(aesKey, "AES");
this.iv = new IvParameterSpec(Md5Util.compute(aesKey));
}
public byte[] encrypt(byte[] data) {
byte[] result = null;
Cipher cipher = null;
try {
cipher = Cipher.getInstance("AES/CFB/NoPadding");
cipher.init(Cipher.ENCRYPT_MODE, keySpec, iv);
result = cipher.doFinal(data);
} catch (Exception e) {
throw new RuntimeException(e);
}
return result;
}
public byte[] decrypt(byte[] secret) {
byte[] result = null;
Cipher cipher = null;
try {
cipher = Cipher.getInstance("AES/CFB/NoPadding");
cipher.init(Cipher.DECRYPT_MODE, keySpec, iv);
result = cipher.doFinal(secret);
} catch (Exception e) {
throw new RuntimeException(e);
}
return result;
}
public static byte[] randomKey(int size) {
byte[] result = null;
try {
KeyGenerator gen = KeyGenerator.getInstance("AES");
gen.init(size, new SecureRandom());
result = gen.generateKey().getEncoded();
} catch (Exception e) {
throw new RuntimeException(e);
}
return result;
}
}
- RSA algorithm
RSA encryption algorithm is the most influential public key encryption algorithm at present, and is generally considered to be one of the best public key schemes. RSA is the first algorithm that can be used for encryption and digital signature at the same time. It can resist all known cryptographic attacks so far. It has been recommended as the public key data encryption standard by ISO.
RSA encryption algorithm is based on a very simple number theory fact: it is very easy to multiply two large prime numbers, but it is extremely difficult to factorize their product. Therefore, the product can be disclosed as an encryption key.
import net.pocrd.annotation.NotThreadSafe;
import org.bouncycastle.jce.provider.BouncyCastleProvider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.crypto.Cipher;
import java.io.ByteArrayOutputStream;
import java.security.KeyFactory;
import java.security.Security;
import java.security.Signature;
import java.security.interfaces.RSAPrivateCrtKey;
import java.security.interfaces.RSAPublicKey;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
@NotThreadSafe
public class RsaHelper {
private static final Logger logger = LoggerFactory.getLogger(RsaHelper.class);
private RSAPublicKey publicKey;
private RSAPrivateCrtKey privateKey;
static {
Security.addProvider(new BouncyCastleProvider()); //Using bouncy castle as encryption algorithm
}
public RsaHelper(String publicKey, String privateKey) {
this(Base64Util.decode(publicKey), Base64Util.decode(privateKey));
}
public RsaHelper(byte[] publicKey, byte[] privateKey) {
try {
KeyFactory keyFactory = KeyFactory.getInstance("RSA");
if (publicKey != null && publicKey.length > 0) {
this.publicKey = (RSAPublicKey)keyFactory.generatePublic(new X509EncodedKeySpec(publicKey));
}
if (privateKey != null && privateKey.length > 0) {
this.privateKey = (RSAPrivateCrtKey)keyFactory.generatePrivate(new PKCS8EncodedKeySpec(privateKey));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public RsaHelper(String publicKey) {
this(Base64Util.decode(publicKey));
}
public RsaHelper(byte[] publicKey) {
try {
KeyFactory keyFactory = KeyFactory.getInstance("RSA");
if (publicKey != null && publicKey.length > 0) {
this.publicKey = (RSAPublicKey)keyFactory.generatePublic(new X509EncodedKeySpec(publicKey));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public byte[] encrypt(byte[] content) {
if (publicKey == null) {
throw new RuntimeException("public key is null.");
}
if (content == null) {
return null;
}
try {
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding");
cipher.init(Cipher.ENCRYPT_MODE, publicKey);
int size = publicKey.getModulus().bitLength() / 8 - 11;
ByteArrayOutputStream baos = new ByteArrayOutputStream((content.length + size - 1) / size * (size + 11));
int left = 0;
for (int i = 0; i < content.length; ) {
left = content.length - i;
if (left > size) {
cipher.update(content, i, size);
i += size;
} else {
cipher.update(content, i, left);
i += left;
}
baos.write(cipher.doFinal());
}
return baos.toByteArray();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public byte[] decrypt(byte[] secret) {
if (privateKey == null) {
throw new RuntimeException("private key is null.");
}
if (secret == null) {
return null;
}
try {
Cipher cipher = Cipher.getInstance("RSA/ECB/PKCS1Padding");
cipher.init(Cipher.DECRYPT_MODE, privateKey);
int size = privateKey.getModulus().bitLength() / 8;
ByteArrayOutputStream baos = new ByteArrayOutputStream((secret.length + size - 12) / (size - 11) * size);
int left = 0;
for (int i = 0; i < secret.length; ) {
left = secret.length - i;
if (left > size) {
cipher.update(secret, i, size);
i += size;
} else {
cipher.update(secret, i, left);
i += left;
}
baos.write(cipher.doFinal());
}
return baos.toByteArray();
} catch (Exception e) {
logger.error("rsa decrypt failed.", e);
}
return null;
}
public byte[] sign(byte[] content) {
if (privateKey == null) {
throw new RuntimeException("private key is null.");
}
if (content == null) {
return null;
}
try {
Signature signature = Signature.getInstance("SHA1WithRSA");
signature.initSign(privateKey);
signature.update(content);
return signature.sign();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public boolean verify(byte[] sign, byte[] content) {
if (publicKey == null) {
throw new RuntimeException("public key is null.");
}
if (sign == null || content == null) {
return false;
}
try {
Signature signature = Signature.getInstance("SHA1WithRSA");
signature.initVerify(publicKey);
signature.update(content);
return signature.verify(sign);
} catch (Exception e) {
logger.error("rsa verify failed.", e);
}
return false;
}
}
- ECC algorithm
ECC is also an asymmetric encryption algorithm. The main advantage is that in some cases, it uses smaller keys than other methods, such as RSA encryption algorithm, which provides an equivalent or higher level of security. However, one disadvantage is that the implementation of encryption and decryption takes longer than other mechanisms (compared with RSA algorithm, this algorithm consumes a lot of CPU).
import net.pocrd.annotation.NotThreadSafe;
import org.bouncycastle.jcajce.provider.asymmetric.ec.BCECPrivateKey;
import org.bouncycastle.jcajce.provider.asymmetric.ec.BCECPublicKey;
import org.bouncycastle.jce.provider.BouncyCastleProvider;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.crypto.Cipher;
import java.io.ByteArrayOutputStream;
import java.security.KeyFactory;
import java.security.Security;
import java.security.Signature;
import java.security.spec.PKCS8EncodedKeySpec;
import java.security.spec.X509EncodedKeySpec;
@NotThreadSafe
public class EccHelper {
private static final Logger logger = LoggerFactory.getLogger(EccHelper.class);
private static final int SIZE = 4096;
private BCECPublicKey publicKey;
private BCECPrivateKey privateKey;
static {
Security.addProvider(new BouncyCastleProvider());
}
public EccHelper(String publicKey, String privateKey) {
this(Base64Util.decode(publicKey), Base64Util.decode(privateKey));
}
public EccHelper(byte[] publicKey, byte[] privateKey) {
try {
KeyFactory keyFactory = KeyFactory.getInstance("EC", "BC");
if (publicKey != null && publicKey.length > 0) {
this.publicKey = (BCECPublicKey)keyFactory.generatePublic(new X509EncodedKeySpec(publicKey));
}
if (privateKey != null && privateKey.length > 0) {
this.privateKey = (BCECPrivateKey)keyFactory.generatePrivate(new PKCS8EncodedKeySpec(privateKey));
}
} catch (ClassCastException e) {
throw new RuntimeException("", e);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public EccHelper(String publicKey) {
this(Base64Util.decode(publicKey));
}
public EccHelper(byte[] publicKey) {
try {
KeyFactory keyFactory = KeyFactory.getInstance("EC", "BC");
if (publicKey != null && publicKey.length > 0) {
this.publicKey = (BCECPublicKey)keyFactory.generatePublic(new X509EncodedKeySpec(publicKey));
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public byte[] encrypt(byte[] content) {
if (publicKey == null) {
throw new RuntimeException("public key is null.");
}
try {
Cipher cipher = Cipher.getInstance("ECIES", "BC");
cipher.init(Cipher.ENCRYPT_MODE, publicKey);
int size = SIZE;
ByteArrayOutputStream baos = new ByteArrayOutputStream((content.length + size - 1) / size * (size + 45));
int left = 0;
for (int i = 0; i < content.length; ) {
left = content.length - i;
if (left > size) {
cipher.update(content, i, size);
i += size;
} else {
cipher.update(content, i, left);
i += left;
}
baos.write(cipher.doFinal());
}
return baos.toByteArray();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public byte[] decrypt(byte[] secret) {
if (privateKey == null) {
throw new RuntimeException("private key is null.");
}
try {
Cipher cipher = Cipher.getInstance("ECIES", "BC");
cipher.init(Cipher.DECRYPT_MODE, privateKey);
int size = SIZE + 45;
ByteArrayOutputStream baos = new ByteArrayOutputStream((secret.length + size + 44) / (size + 45) * size);
int left = 0;
for (int i = 0; i < secret.length; ) {
left = secret.length - i;
if (left > size) {
cipher.update(secret, i, size);
i += size;
} else {
cipher.update(secret, i, left);
i += left;
}
baos.write(cipher.doFinal());
}
return baos.toByteArray();
} catch (Exception e) {
logger.error("ecc decrypt failed.", e);
}
return null;
}
public byte[] sign(byte[] content) {
if (privateKey == null) {
throw new RuntimeException("private key is null.");
}
try {
Signature signature = Signature.getInstance("SHA1withECDSA", "BC");
signature.initSign(privateKey);
signature.update(content);
return signature.sign();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public boolean verify(byte[] sign, byte[] content) {
if (publicKey == null) {
throw new RuntimeException("public key is null.");
}
try {
Signature signature = Signature.getInstance("SHA1withECDSA", "BC");
signature.initVerify(publicKey);
signature.update(content);
return signature.verify(sign);
} catch (Exception e) {
logger.error("ecc verify failed.", e);
}
return false;
}
}
Comparison of various encryption algorithms
(1) Hash algorithm comparison
| name | Security | speed |
|---|---|---|
| SHA-1 | high | slow |
| MD5 | in | block |
(2) Comparison of symmetric encryption algorithms
| name | Key length | running speed | Security | resource consumption |
|---|---|---|---|---|
| DES | 56 bits | Faster | low | in |
| 3DES | 112 bit or 168 bit | slow | in | high |
| AES | 128, 192, 256 bits | block | high | low |
(3) Comparison of asymmetric encryption algorithms
| name | Maturity | running speed | Security | resource consumption |
|---|---|---|---|---|
| RSA | high | in | high | in |
| ECC | high | slow | high | high |
(4) Symmetric encryption and asymmetric encryption algorithms
Symmetric encryption algorithm
- Key management: it is difficult and not suitable for the Internet. It is generally used for internal systems
- Security: medium
- Encryption speed: several orders of magnitude faster (software encryption and decryption speed is at least 100 times faster, and M bits of data can be encrypted and decrypted per second), which is suitable for encryption and decryption processing of large amount of data
Asymmetric encryption algorithm
- Key management: keys are easy to manage
- Safety: high
- Encryption speed: relatively slow, suitable for small amount of data encryption and decryption or data signature