preface
HashMap has some differences between JDK7 and JDK8, as shown below:
- The bottom layer of JDK7HashMap is array + linked list, while JDK8 is array + linked list + red black tree
- JDK7 adopts head plug method for capacity expansion, while JDK8 adopts tail plug method
- The rehash of JDK7 is all rehash, while JDK8 is part rehash.
- JDK8 is better than JDK7 for hash value calculation of key.
If you are still interested, you can learn my following articles, which are written in great detail!!
High frequency test questions: handwritten HashMap
Detailed explanation of JDK7 and 8 expansion source code level
Detailed explanation of get() and put() processes of JDK7 and 8HashMap
JDK7 HashMap
JDK7HashMap will have an endless loop problem in a multithreaded environment.
If threads A and B put A HashMap at the same time, and the HashMap just reaches the capacity expansion condition, it needs to be expanded
Then these two threads will expand the capacity of HahsMap (JDK7HashMap calls the resize() method for capacity expansion, and the transfer() method needs to be called in the resize() method to rehash all the old array elements into the new array. Key points: problems will arise in the multi-threaded environment)
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//Traverse rehash for each linked list of the array
for (Entry<K,V> e : table) {
while(null != e) {
//Keep next node
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//Get the corresponding index position in the new array
int i = indexFor(e.hash, newCapacity);
//Tail insertion
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
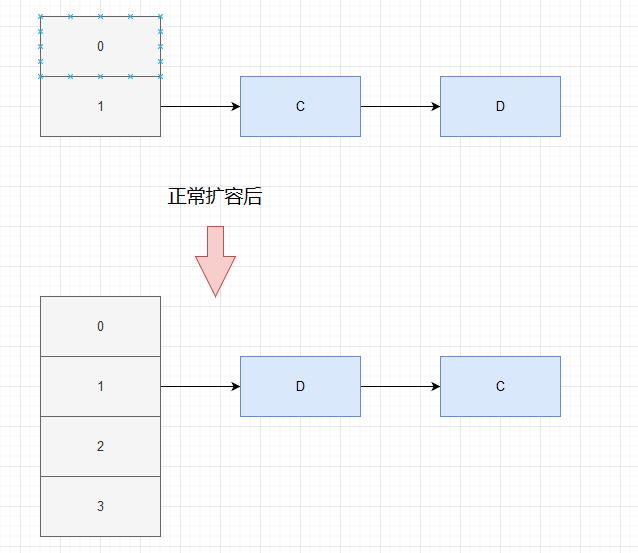
Let's assume that there is a linked list C - > D, and the calculated index positions of C and D remain unchanged after capacity expansion, then they are still in the same linked list
Now thread A enters the transfer method and gets A and its next node B (entry < K, V > next = e.next;) After that, thread A is suspended. At this time, thread B normally goes through the process to add A and Brehash to the new array. Then, according to the header insertion method, it is D - > C in the new array
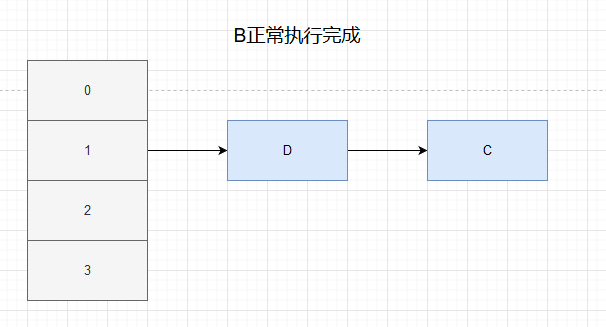
After B executes, thread A continues to execute
Because A obtains e = C and next = D, C can rehash. After C obtains D and finds D.next = C, D can also rehash. At this time, because D - > C, C will be obtained again. It is found that C.next = null, but C is not null, so C can rehash again. At this time, the tail of the linked list C - > D - > C, because e = NULL, so exit the loop, An endless loop appears. C——>D——>C.
You can think about these words or draw a picture on the draft paper and then look at the picture below!
Graphic presentation:
B normal execution completed
A. continue
Because A obtains e = C and next = D, C can rehash
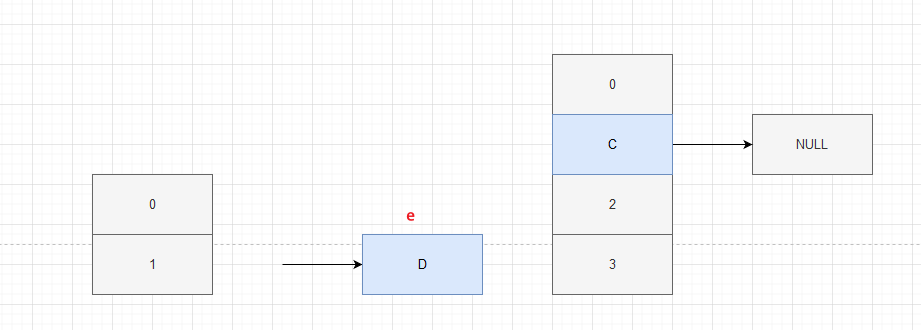
C gets e = D after the process and finds D.next = C, so D can also rehash
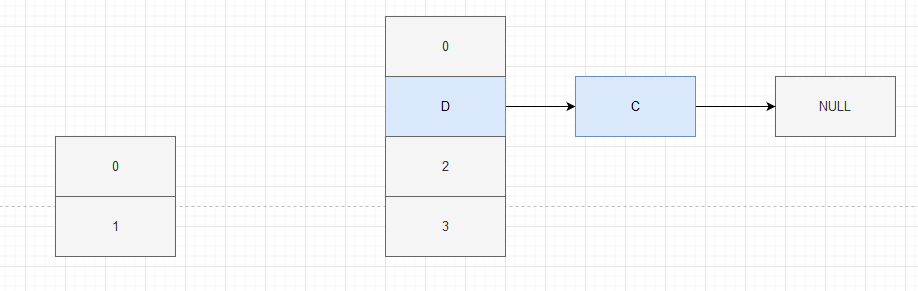
At this time, because D - > C, you will get C again. It is found that C.next = null, but C is not null, so C will rehash again
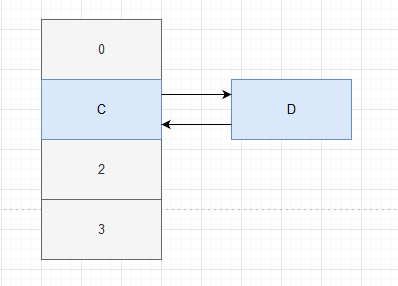
At this time, e = NULL, so exit the loop and an dead loop appears. C——>D——>C.
JDK8 HashMap
JDK1.8. Data coverage will occur
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
-
Line 6 code: assuming that both threads A and B are performing put operation and the hash value calculated according to the key is the same, the index subscript obtained is also the same. When thread A executes the sixth line of code, it is suspended due to the depletion of time slice, while thread B inserts an element at the subscript after obtaining the time slice, completes the normal insertion, and then thread A obtains the time slice, Since the hash collision has been judged before, all users will not judge at this time, but directly insert, which leads to the data inserted by thread B being overwritten by thread A, so the thread is unsafe.
-
Code + + size in line 38 is unsafe. It is still threads A and B. when these two threads perform put operation at the same time, it is assumed that the zise size of the current HashMap is 10. When thread A executes code in line 38, it obtains the size value of 10 from the main memory and is ready for + 1 operation. However, due to the depletion of time slice, it has to give up the CPU, Thread B happily gets the CPU or gets the value of size 10 from the main memory for + 1 operation, completes the put operation and writes size=11 back to the main memory, and then thread A gets the CPU again and continues to execute (at this time, the value of size is still 10). After the put operation is completed, thread A and thread B still write size=11 back to the memory. At this time, both threads A and B perform A put operation, but the value of size is only increased by 1, All this is because data coverage leads to thread insecurity.
last
I am Skin shrimp , a shrimp lover who loves to share knowledge, we will constantly update blog posts that are beneficial to you in the future. We look forward to your attention!!!
It's not easy to create. If this blog is helpful to you, I hope you can click three times!, Thanks for your support. I'll see you next time~~~
Sharing outline
Interview question column of large factory
Directory index of Java learning route from entry to grave
Open source crawler instance tutorial directory index
For more wonderful content sharing, please click Hello World (●'◡'●)