1 description of competition questions
In real social networks, cheating users will affect the social network platform. In the real scene, there will be many constraints. We can only obtain a small number of cheating samples and a part of normal user samples. Now we need to use a small number of labeled samples to mine the remaining cheating samples in a large number of unknown samples.
Samples in a given period of time, including a small number of cheating samples, some normal samples and samples with unknown labels. Participants should use the existing data during this period to propose their own solutions to predict whether the samples with unknown labels are cheating samples.
Data processing methods and algorithms are not limited, but participants need to comprehensively consider the effect and complexity of the algorithm, so as to build a reasonable solution.
2 topic ideas
Based on a given small number of samples, a more direct idea is to mine the relevant black samples through the correlation between samples, and then train a two classifier based on the relevant black samples, so as to get more black samples.
3 topic data
Data range:
- Proportional sampling data under praise and attention events from time T to time T+N
Feature type:
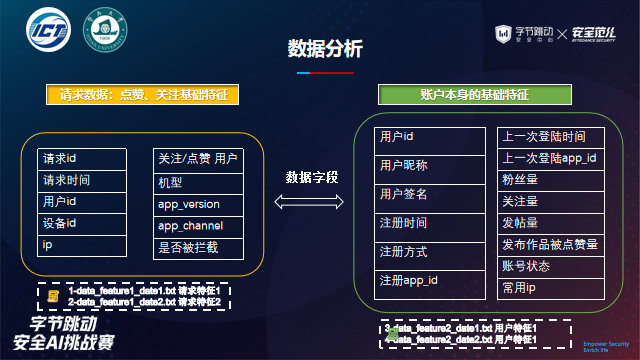
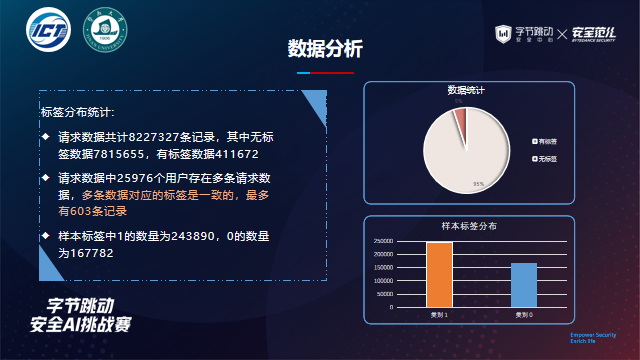
4. Data statistics:
- Total number of accounts: 4579520
- Normal account number with label: 102630
- Number of cheating accounts with labels: 10667
- Total requests: 8227327
- Submitted evaluation data: 151117
Characteristic correlation statistics are as follows:
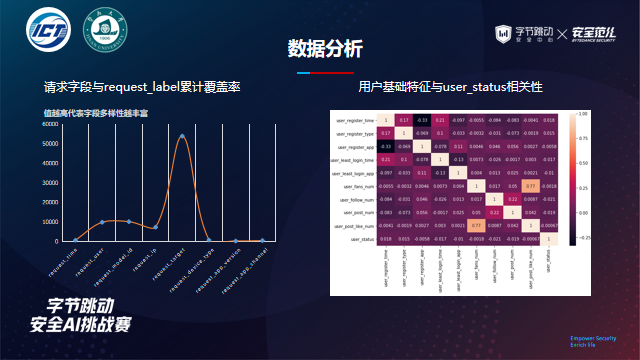
Category variables exist in the request data. You can count the conversion rate under category variables and analyze which features have great potential mining value; For the user's basic data, you can intuitively infer which variables are more important through the correlation coefficient.
For numerical features, we can focus on the difference between the number of users' fans and the number of users' concerns, and the difference between the number of users' published works and the number of users' favorite works. These counter trend features can reflect whether users have real social behavior, rather than "white" black accounts.

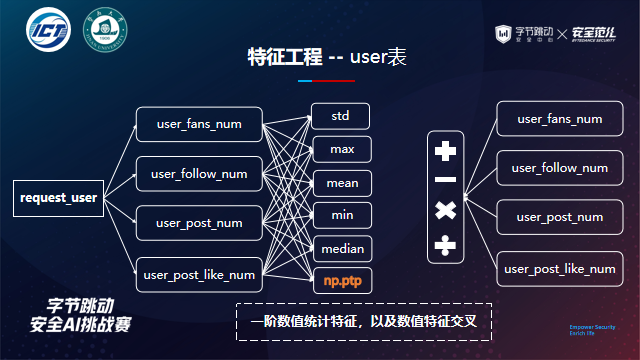
5 characteristic Engineering
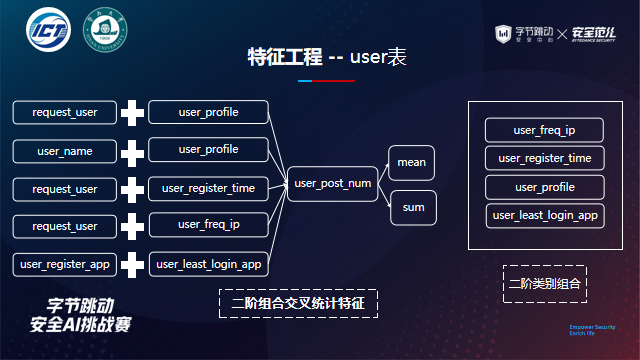
Feature Engineering determines the final effect of the model. After completing the conventional basic features, feature engineering needs to further refine the features around strong features according to the effect of model feedback. Finally, we won the fifth place. Some code references are given below. We have mainly constructed the features of three dimensions in the scheme,
User portrait features: request representation, basic features
- Statistical characteristics of request data


## Time characteristics request_feature['app_channel_nacnt_time_ratio']=request_feature['app_channel_nacnt']/(request_feature['time_gap']+1e-3) request_feature['device_type_nacnt_ratio']=request_feature['device_type_nacnt']/(request_feature['time_gap']+1e-3) request_feature['request_app_channel_count_ratio']=request_feature['group_request_user_request_app_channel_count']/(request_feature['time_gap']+1e-3) request_feature['request_count_time_ratio']=request_feature['request_user_count']/(request_feature['time_gap']+1e-3) request_feature['request_device_type_count_time_ratio']=request_feature['group_request_user_request_device_type_count']/(request_feature['time_gap']+1e-3) request_feature['request_ip_nuinque_ratio']=request_feature['group_request_user_request_ip_nunique']/(request_feature['time_gap']+1e-3) request_feature['request_model_nuinque_ratio']=request_feature['group_request_user_request_model_id_nunique']/(request_feature['time_gap']+1e-3) request_feature['request_target_nuinque_time_ratio']=request_feature['group_request_user_request_target_nunique']/(request_feature['time_gap']+1e-3)

## Strong second-order unique feature
base_cols = [
['request_user', 'request_model_id'],
['request_user', 'request_device_type'],
['request_user', 'request_app_channel'],
['request_user', 'request_app_version'],
]
target_col = ['request_model_id', 'request_ip', 'request_target', 'request_device_type', 'request_app_version',
'request_app_channel']
for base_pair in base_cols:
for col in tqdm(target_col):
if col not in base_pair:
request_feature[col] = request_feature[col].fillna('NAN')
request_feature[f'group_{base_pair[0]}_{base_pair[1]}_{col}_unique'] = \
request_feature[base_pair + [col]].groupby(base_pair)[col].transform('nunique')
- Statistical characteristics of user basic information
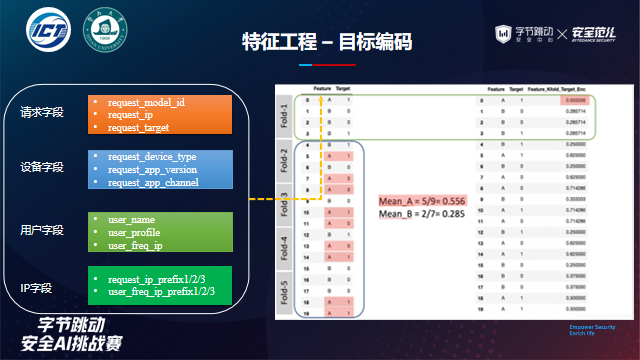
- Target coding
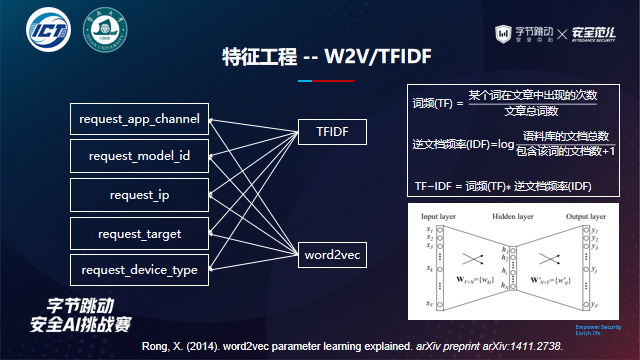
User association features: embedded representation

Behavior characteristics: representation of behavior sequence in time period
model building
Model selection: LGB/XGB/CAT
By training and iterating models with different features in the highly efficient LightGBM, and testing and verifying the feature effect, finally, on the basis of high-quality features, the three models are trained by cross validation, and the optimal results of the last three models are obtained.

Model fusion: additive averaging
During the competition, we tried different fusion schemes for the three models, including voting fusion, weighted fusion and stacking, but the fusion income is relatively small. Finally, the fusion method we selected is to directly integrate the prediction probability results of the three models into a simple average, which can achieve the maximum fusion income.

Feature importance analysis

6 summary and Prospect
In the process of competition, the tree model we tried is highly interpretable, gives the construction direction of derived features, and has fast training iteration speed. In addition, user behavior features, time series features and user portrait features are more important. At the same time, the network features between users and devices, users and networks have potential mining value. The lack of attempt is that there is no effective prediction of unlabeled data sets through supervised model, followed by pseudo label learning, and there is no experimental effect of neural network model or graph neural network