summary
For a long time, the software industry has been hoping to establish a reusable thing and a method to create "reusable things", from functions, classes, function libraries, class libraries, various components, from modular design to object-oriented, in order to improve reusability.
Reusability must be based on some standard. However, in many environments, even the most basic data structures and algorithms in software development fail to have a set of standards. A large number of programmers are forced to do a lot of repetitive work in order to complete the program code that has been completed by predecessors but they do not have in their hands. This is not only a waste of human resources, but also a source of frustration and pain.
In order to establish a set of standards for data structures and algorithms, and reduce the coupling relationship between them, so as to improve their independence, flexibility and interoperability (mutual cooperation, interoperability), STL was born.
STL(Standard Template Library) is a general term for a series of software developed by HP Labs. Now it mainly appears in c + +, but this technology has existed for a long time before the introduction of c + +.
STL is broadly divided into: container algorithm and iterator.
Containers and algorithms are seamlessly connected through iterators. Almost all STL codes adopt template classes or template functions, which provides better code reuse opportunities than the traditional library composed of functions and classes.
STL(Standard Template Library) standard template library accounts for more than 80% of our c + + standard library.
Introduction to STL six components
STL provides six components that can be combined and applied to each other. These six components are: container, algorithm, iterator, functor, adapter (adapter) and space configurator.
Container: various data structures, such as vector, list, deque, set and map, are used to store data. From the implementation point of view, STL container is a class template.
Algorithm: various commonly used algorithms, such as sort, find, copy and for_each. From the perspective of implementation, STL algorithm is a function temporary
Iterator: it acts as the glue between container and algorithm. There are five types. From the implementation point of view, iterator is a class template that overloads pointer related operations such as operator *, operator - >, operator + +, operator - All STL containers come with their own iterators. Only the designer of the container knows how to traverse its own elements. A native pointer is also an iterator.
Imitation function: it behaves like a function and can be used as a strategy of the algorithm. From an implementation point of view, a functor is a class or class template that overloads operator()
Adapter: something used to decorate a container or an interface to an emulator or iterator.
Space configurator: responsible for space configuration and management. From the implementation point of view, the configurator is a class temporary that implements dynamic space configuration, space management and space release
The interaction between the six components of STL. The container obtains the data storage space through the space configurator. The algorithm stores the contents of the container through the iterator. The imitation function can assist the algorithm to complete the changes of different strategies, and the adapter can modify the imitation function.
The advantages of STL are obvious:
STL is part of C + +, so there is no need to install anything else. It is built into your compiler.
An important feature of STL is the separation of data and operation. Data is managed by container categories, and operations are defined by customizable algorithms. Iterators act as "glue" between the two so that the algorithm can interact with the container
Programmers can not think about the specific implementation process of STL, as long as they can skillfully use STL. So they can focus on other aspects of program development.
STL has the advantages of high reusability, high performance, high portability and cross platform.
High reusability: almost all code in STL is implemented by template classes and template functions, which provides better code reuse opportunities than the traditional library composed of functions and classes.
High performance: for example, map can efficiently find the specified records from 100000 records, because map is implemented with a variant of red black tree.
High portability: for example, modules written in STL on project A can be directly transplanted to project B.
Introduction to three components
1. Container
Almost any specific data structure is to implement a specific algorithm. STL container is to implement some of the most widely used data structures.
Common data structures: array, list, tree, stack, queue, set and map. According to the arrangement characteristics of data in containers, these data are divided into sequential containers and associative containers.
- Sequential containers emphasize the sorting of values. Each element in a sequential container has a fixed position, unless it is changed by deleting or inserting. Vector container, Deque container, List container, etc.
- Relational container is a nonlinear tree structure, more accurately, a binary tree structure. There is no strict physical order relationship between elements, that is, the logical order of elements when they are placed in the container is not saved in the container. Another notable feature of associative containers is to select a value from the values as the keyword key, which acts as an index to the values for easy search. Set/multiset container Map/multimap container
2. Algorithm
Algorithm, the solution of a problem, with limited steps to solve a logical or mathematical problem.
Every program we write is an algorithm, and every function in it is also an algorithm. After all, they are used to solve large or small logical or mathematical problems. The algorithms included in STL have been mathematically analyzed and proved to be of great reuse value, including common sorting, search and so on. Specific algorithms often match specific data structures, and algorithms and data structures complement each other.
Algorithms are divided into: qualitative algorithm and non qualitative algorithm.
- Qualitative change algorithm: refers to the content of elements in the interval will be changed during operation. For example, copy, replace, delete, etc
- Non qualitative algorithm: it means that the element content in the interval will not be changed during the operation, such as finding, counting, traversing, finding extreme values, etc
3. Iterator
Iterator is an abstract design concept. There is no real object directly corresponding to this concept in real programming language. The book < < Design Patterns > > provides a complete description of 23 design patterns, of which the iterator pattern is defined as follows: it provides a method to search the elements contained in a container in order without exposing the internal representation of the container.
Iterator design thinking - the key to STL is that the central idea of STL is to separate containers and algorithms, design them independently of each other, and finally glue them together.
From a technical point of view, the generalization of containers and algorithms is not difficult. The class template and function template of c + + can achieve their goals respectively. If a good adhesive is designed between the two, it is a big problem.
Types of iterators:
| iterator | function | describe |
|---|---|---|
| Input Iterator | Provides read-only access to data | Read only, support + +, = == |
| output iterators | Provide write only access to data | Write only, support++ |
| forward iterators | Provides read and write operations and can push the iterator forward | Read and write, support + +, = == |
| Bidirectional Iterator | Provide read and write operations, and can operate forward and backward | Read and write, support + +, –, |
| random access iterators | It provides read and write operations and can access any data of the container in a jumping way. It is the most powerful iterator | Read and write, support + +, –, [n], - N, <, < =, >, >= |
demonstration
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
//Container algorithm iterator in STL
void test01(){
vector<int> v; //One of the standard containers in STL: dynamic arrays
v.push_back(1); //The method of inserting data provided by the vector container
v.push_back(5);
v.push_back(3);
v.push_back(7);
//iterator
vector<int>::iterator pStart = v.begin(); //The vector container provides a begin() method that returns an iterator pointing to the first element
vector<int>::iterator pEnd = v.end(); //The vector container provides an end() method that returns an iterator pointing to the next position of the last element
//Traversal through iterators
while (pStart != pEnd){
cout << *pStart << " ";
pStart++;
}
cout << endl;
//Algorithm count algorithm is used to count the number of elements
int n = count(pStart, pEnd, 5);
cout << "n:" << n << endl;
}
//STL containers can store not only basic data types, but also class objects
class Teacher
{
public:
Teacher(int age) :age(age){};
~Teacher(){};
public:
int age;
};
void test02(){
vector<Teacher> v; //A container that stores data of type Teacher
Teacher t1(10), t2(20), t3(30);
v.push_back(t1);
v.push_back(t2);
v.push_back(t3);
vector<Teacher>::iterator pStart = v.begin();
vector<Teacher>::iterator pEnd = v.end();
//Traversal through iterators
while (pStart != pEnd){
cout << pStart->age << " ";
pStart++;
}
cout << endl;
}
//Store pointer to Teacher type
void test03(){
vector<Teacher*> v; //Store pointer to Teacher type
Teacher* t1 = new Teacher(10);
Teacher* t2 = new Teacher(20);
Teacher* t3 = new Teacher(30);
v.push_back(t1);
v.push_back(t2);
v.push_back(t3);
//Get container iterator
vector<Teacher*>::iterator pStart = v.begin();
vector<Teacher*>::iterator pEnd = v.end();
//Traversal through iterators
while (pStart != pEnd){
cout << (*pStart)->age << " ";
pStart++;
}
cout << endl;
}
//Container nesting container difficulties
void test04()
{
vector< vector<int> > v;
vector<int>v1;
vector<int>v2;
vector<int>v3;
for (int i = 0; i < 5;i++)
{
v1.push_back(i);
v2.push_back(i * 10);
v3.push_back(i * 100);
}
v.push_back(v1);
v.push_back(v2);
v.push_back(v3);
for (vector< vector<int> >::iterator it = v.begin(); it != v.end();it++)
{
for (vector<int>::iterator subIt = (*it).begin(); subIt != (*it).end(); subIt ++)
{
cout << *subIt << " ";
}
cout << endl;
}
}
int main(){
//test01();
//test02();
//test03();
test04();
system("pause");
return EXIT_SUCCESS;
}
Common containers
1. string container
Basic concepts of string container
C-style strings (character arrays ending with null characters) are too complex to master and are not suitable for the development of large programs. Therefore, the C + + standard library defines a string class, which is defined in the header file < string >.
Comparison between String and c-style String:
- Char * is a pointer and String is a class
String encapsulates char *, manages this string, and is a char * container. - String encapsulates many practical member methods
find, copy, delete, replace, insert - Memory release and out of bounds are not considered
String manages the memory allocated by char *. Every time a string is copied, the value is maintained by the string class. You don't have to worry about copying out of bounds and value out of bounds.
string container common operations
string constructor
string();//Create an empty string, for example: string str; string(const string& str);//Initializes another string object with one string object string(const char* s);//Initialize with string s string(int n, char c);//Initialize with n characters c
string basic assignment operation
string& operator=(const char* s);//char * type string is assigned to the current string string& operator=(const string &s);//Assign the string s to the current string string& operator=(char c);//The character is assigned to the current string string& assign(const char *s);//Assign the string s to the current string string& assign(const char *s, int n);//Assign the first n characters of string s to the current string string& assign(const string &s);//Assign the string s to the current string string& assign(int n, char c);//Assign n characters c to the current string string& assign(const string &s, int start, int n);//Assign s n characters from start to the string
string access character operation
char& operator[](int n);//Take characters by [] char& at(int n);//Get characters through at method
string splicing operation
string& operator+=(const string& str);//Overload + = operator string& operator+=(const char* str);//Overload + = operator string& operator+=(const char c);//Overload + = operator string& append(const char *s);//Connects the string s to the end of the current string string& append(const char *s, int n);//Connect the first n characters of string s to the end of the current string string& append(const string &s);//Same as operator + = () string& append(const string &s, int pos, int n);//Connect the n characters from pos in the string s to the end of the current string string& append(int n, char c);//Adds n characters to the end of the current string c
string find and replace
int find(const string& str, int pos = 0) const; //Find the location where str first appears, starting from pos int find(const char* s, int pos = 0) const; //Find the location where s first appears, starting from pos int find(const char* s, int pos, int n) const; //Find the first position of the first n characters of s from the pos position int find(const char c, int pos = 0) const; //Find where the character c first appears int rfind(const string& str, int pos = npos) const;//Find the last position of str, starting from pos int rfind(const char* s, int pos = npos) const;//Find the location of the last occurrence of s, starting from pos int rfind(const char* s, int pos, int n) const;//Find the last position of the first n characters of s from pos int rfind(const char c, int pos = 0) const; //Find where the character c last appeared string& replace(int pos, int n, const string& str); //Replace n characters starting from pos with string str string& replace(int pos, int n, const char* s); //Replace the n characters starting from pos with the string s
string compare operation
/* compare The function returns 1 when >, - 1 when < and 0 when = =. The comparison is case sensitive. When comparing, refer to the order of the dictionary. The smaller the front row is. Capital a is smaller than lowercase a. */ int compare(const string &s) const;//Compare with string s int compare(const char *s) const;//Compare with string s
string substring
string substr(int pos = 0, int n = npos) const;//Returns a string of n characters starting with pos
string insert and delete operations
string& insert(int pos, const char* s); //Insert string string& insert(int pos, const string& str); //Insert string string& insert(int pos, int n, char c);//Inserts n characters c at the specified position string& erase(int pos, int n = npos);//Delete n characters starting from Pos
String and c-style string conversion
//string to char* string str = "it"; const char* cstr = str.c_str(); //char * to string char* s = "it"; string str(s);
In c + +, there is an implicit type conversion from const char * to string, but there is no conversion from a string object to c_ Automatic type conversion of string. For strings of type string, you can use c_ The str() function returns the c corresponding to the string object_ string.
Generally, programmers should insist on using string class objects throughout the program, and do not convert them to C until they must convert the content to char *_ string.
To modify the contents of a string, both the subscript operators [] and at return a reference to the character. However, when the memory of the string is reallocated, an error may occur
string s = "abcdefg"; char& a = s[2]; char& b = s[3]; a = '1'; b = '2'; cout << s << endl; cout << (int*)s.c_str() << endl; s = "pppppppppppppppppppppppp"; //a = '1'; //b = '2'; cout << s << endl; cout << (int*)s.c_str() << endl;
2. vector container
Basic concepts of vector container
The data arrangement and operation mode of vector are very similar to array. The only difference between them is the flexibility of space application.
Array is a static space. Once configured, it cannot be changed. You need to change a larger or smaller space. You can do everything by yourself. First configure a new space, then move the data of the old space to the new space, and then release the original space.
Vector is a dynamic space. With the addition of elements, its internal mechanism will automatically expand the space to accommodate new elements. Therefore, the use of vector is very helpful for the rational utilization and flexibility of memory. We don't have to be afraid of insufficient space and ask for a large array from the beginning.
The key to the implementation technology of vector lies in its size control and data movement efficiency during reconfiguration. Once the old space of vector is full, it is unwise to expand the space of one element inside vector every time the customer adds an element, because the so-called expanded space (no matter how large) is, as just said, It is a big project of "configuring new space - data movement - releasing old space". The time cost is very high. We should consider taking precautions. We can see the space configuration strategy of vector later.
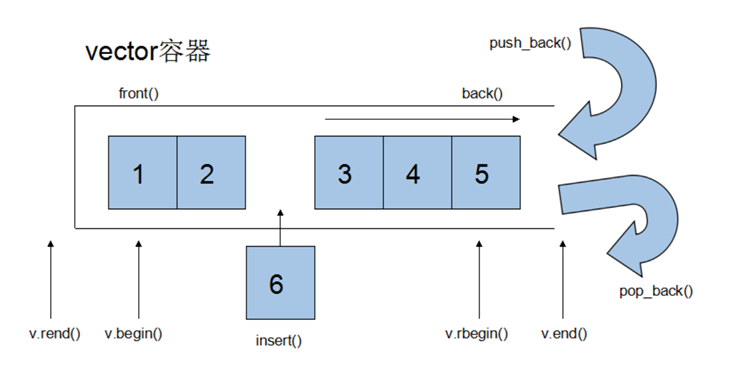
vector iterator
Vector maintains a linear space, so no matter what the type of element, the ordinary pointer can be used as the iterator of vector, because the operation behavior required by the vector iterator, such as operator *, operator - >, operator + +, operator –, operator +, operator -, operator -, operator + =, operator - =, is inherent in the ordinary pointer.
Vector supports random access, which is what ordinary pointers do. Therefore, vector provides random access iterators
According to the above description, if we write the following code:
Vector<int>::iterator it1; Vector<Teacher>::iterator it2;
The type of it1 is int *, and the type of it2 is Teacher *
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<vector>
using namespace std;
int main(){
vector<int> v;
for (int i = 0; i < 10;i ++){
v.push_back(i);
cout << v.capacity() << endl; // v.capacity() the capacity of the container
}
system("pause");
return EXIT_SUCCESS;
}
Data structure of vector
The data structure used by Vector is very simple, linear continuous space, which uses two iterators_ Myfirst and_ Mylast points to the currently used range in the configured continuous space, and uses iterators_ Myend points to the end of the entire contiguous memory space.
In order to reduce the speed cost of space configuration, the actual configuration size of vector may be larger than that of the client for possible expansion in the future. Here is the concept of capacity. In other words, the capacity of a vector is always greater than or equal to its size. Once the capacity is equal to its size, it is full. The next time there are new elements, the whole vector container will have to find another place to live.
The so-called dynamic size increase is not to connect a new space after the original space (because there is no configurable space after the original space), but a larger memory space, then copy the original data to the new space and release the original space. Therefore, once any operation on the vector causes a space reconfiguration, all iterators pointing to the original vector will fail. This is a mistake that programmers are easy to make. Be careful.
vector common API operations
vector constructor
vector<T> v; //Using template implementation class implementation, default constructor vector(v.begin(), v.end());//Copy the elements in the v[begin(), end()) interval to itself. vector(n, elem);//The constructor copies n elem s to itself. vector(const vector &vec);//Copy constructor.
//Using the second constructor, we can
int arr[] = {2,3,4,1,9};
vector<int> v1(arr, arr + sizeof(arr) / sizeof(int));
vector common assignment operations
assign(beg, end);//Assign the data copy in the [beg, end) interval to itself. assign(n, elem);//Assign n elem copies to itself. vector& operator=(const vector &vec);//Overloaded equal sign operator swap(vec);// Swap vec with its own elements.
vector size operation
size();//Returns the number of elements in the container empty();//Determine whether the container is empty resize(int num);//Reassign the length of the container to num. if the container becomes longer, fill the new location with the default value. If the container becomes shorter, the element whose end exceeds the length of the container is deleted. resize(int num, elem);//Reassign the length of the container to num. if the container becomes longer, fill the new position with elem value. If the container becomes shorter, the element whose end exceeds the container length > degrees is deleted. capacity();//Capacity of container reserve(int len);//The container reserves len element lengths. The reserved positions are not initialized and the elements are inaccessible.
vector data access operation
at(int idx); //Returns the data indicated by the index idx. If the IDX is out of bounds, an out is thrown_ of_ Range exception. operator[];//Returns the data indicated by the index idx. If it exceeds the limit, the operation will directly report an error front();//Returns the first data element in the container back();//Returns the last data element in the container
vector insert and delete operations
insert(const_iterator pos, int count,ele);//The iterator points to the position pos and inserts count elements ele push_back(ele); //Tail insert element ele pop_back();//Delete last element erase(const_iterator start, const_iterator end);//Delete the elements of the iterator from start to end erase(const_iterator pos);//Delete the element pointed to by the iterator clear();//Delete all elements in the container
vector demo: use swap skillfully to shrink memory space
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<vector>
using namespace std;
int main(){
vector<int> v;
for (int i = 0; i < 100000;i ++){
v.push_back(i);
}
cout << "capacity:" << v.capacity() << endl;
cout << "size:" << v.size() << endl;
//At this point, change the container size by resize
v.resize(10);
cout << "capacity:" << v.capacity() << endl;
cout << "size:" << v.size() << endl;
//The capacity has not changed
vector<int>(v).swap(v);
cout << "capacity:" << v.capacity() << endl;
cout << "size:" << v.size() << endl;
system("pause");
return EXIT_SUCCESS;
}
reserve reserved space
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<vector>
using namespace std;
int main(){
vector<int> v;
//Open up space in advance
v.reserve(100000);
int* pStart = NULL;
int count = 0;
for (int i = 0; i < 100000;i ++){
v.push_back(i);
if (pStart != &v[0]){
pStart = &v[0];
count++;
}
}
cout << "count:" << count << endl;
system("pause");
return EXIT_SUCCESS;
}
3. deque container
deque container basic concepts
Vector container is a continuous memory space with one-way opening, and deque is a continuous linear space with two-way opening.
The so-called two-way opening means that elements can be inserted and deleted at both ends of the head and tail. Of course, the vector container can also insert elements at both ends of the head and tail, but the operation efficiency at its head is extremely poor and cannot be accepted
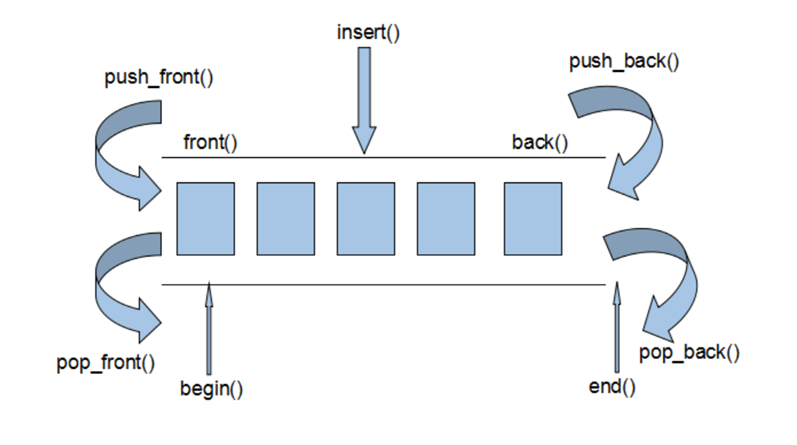
The biggest difference between deque container and vector container is that deque allows the insertion and deletion of elements at the head end using constant term time. Second, deque does not have the concept of capacity, because it is a dynamic combination of segmented continuous spaces, which can add a new space and link it at any time. In other words, like vector, "if the old space is insufficient, reconfigure a larger space, then copy the elements and release the old space" will not happen to deque. Therefore, deque does not have to provide the so-called space reserve function
Although the deque container also provides Random Access Iterator, its iterator is not an ordinary pointer, and its complexity and vector are not of the same order of magnitude, which of course affects the level of each operation. Therefore, unless necessary, we should use vector instead of deque as much as possible. For the sorting operation of deque, in order to maximize efficiency, deque can be completely copied into a vector, the vector container can be sorted, and then copied back to deque
deque container implementation principle
Deque container is a continuous space, at least logically. The continuous current space always reminds us of array and vector. Array cannot grow. Although vector can grow, it can only grow to the end, and its growth is actually an illusion. In fact, (1) apply for a larger space, (2) copy the original data into a new space, (3) release the original space, If the vector does not leave enough space every time it configures a new space, the cost of its growth illusion is very expensive.
Deque is composed of quantitative continuous spaces section by section. Once it is necessary to add new space at the front end or tail end of deque, a continuous quantitative space will be configured and connected in series at the head end or tail end of deque. Deque's biggest job is to maintain the illusion of the integrity of these segmented and continuous memory spaces, and provide a random access interface to avoid the cycle of space reconfiguration, replication and release, at the cost of complex iterator architecture.
Since deque is a piecewise continuous memory space, it must have central control to maintain the illusion of overall continuity. The design of data structure and the forward and backward operation of iterator are quite cumbersome. Deque code has far more implementations than vector or list.
Deque takes a so-called map (note that it is not an STL map container) as the master control. The so-called map here is a small piece of continuous memory space, in which each element (here it becomes a node) is a pointer to another continuous memory space, which is called a buffer area. The buffer is the main body of deque's storage space.
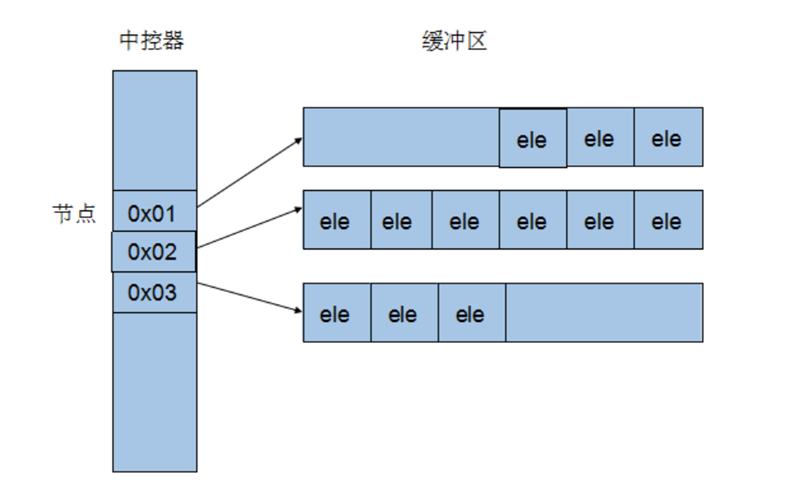
deque common API
deque constructor
deque<T> deqT;//Default construction form deque(beg, end);//The constructor copies the elements in the [beg, end) interval to itself. deque(n, elem);//The constructor copies n elem s to itself. deque(const deque &deq);//Copy constructor.
deque assignment operation
assign(beg, end);//Assign the data copy in the [beg, end) interval to itself. assign(n, elem);//Assign n elem copies to itself. deque& operator=(const deque &deq); //Overloaded equal sign operator swap(deq);// Exchange deq with its own elements
deque size operation
deque.size();//Returns the number of elements in the container deque.empty();//Determine whether the container is empty deque.resize(num);//Reassign the length of the container to num. if the container becomes longer, fill the new location with the default value. If the container becomes shorter, the element whose end exceeds the length of the container is deleted. deque.resize(num, elem); //Reassign the length of the container to num. if the container becomes longer, fill the new position with the elem value. If the container becomes shorter, the elements beyond the length of the container at the end will be deleted.
deque double ended insert and delete operations
push_back(elem);//Add a data at the end of the container push_front(elem);//Insert a data in the head of the container pop_back();//Delete the last data in the container pop_front();//Delete container first data
deque data access
at(idx);//Returns the data indicated by the index idx. If the IDX is out of bounds, an out is thrown_ of_ range. operator[];//Returns the data indicated by the index idx. If the IDX is out of bounds, no exception will be thrown and an error will be made directly. front();//Returns the first data. back();//Returns the last data
deque insert operation
insert(pos,elem);//Insert a copy of the elem ent in the pos position and return the location of the new data. insert(pos,n,elem);//Insert n elem data in pos position, no return value. insert(pos,beg,end);//Insert the data in the [beg,end) interval at the pos position, and there is no return value.
deque delete operation
clear();//Remove all data from the container erase(beg,end);//Delete the data in the [beg,end) interval and return the position of the next data. erase(pos);//Delete the data in pos position and return the position of the next data.
4. stack container
Basic concepts of stack container
Stack is a first in last out (Filo) data structure. It has only one exit, as shown in the figure. The stack container allows you to add elements, remove elements and get the top elements of the stack, but there is no other way to access other elements of the stack except the top. In other words, stack does not allow traversal behavior.
The operation of pushing elements into the stack is called push, and the operation of pushing elements out of the stack is called pop
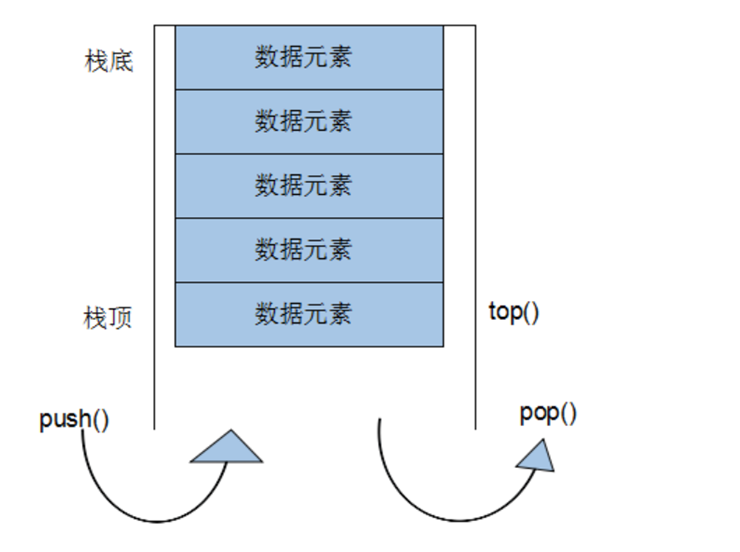
stack has no iterators
All elements in and out of the stack must meet the conditions of "first in and last out". Only the elements at the top of the stack can be used by the outside world. Stack does not provide traversal or iterators.
stack common API s
stack constructor
stack<T> stkT;//Stack is implemented by template class. The default construction form of stack object is: stack(const stack &stk);//copy constructor
stack assignment operation
stack& operator=(const stack &stk);//Overloaded equal sign operator
stack data access operation
push(elem);//Add an element to the top of the stack pop();//Remove the first element from the top of the stack top();//Return stack top element
stack size operation
empty();//Determine whether the stack is empty size();//Returns the size of the stack
5. queue container
Basic concepts of queue container
Queue is a first in first out (FIFO) data structure. It has two exits. The queue container allows adding elements from one end and removing elements from the other end.
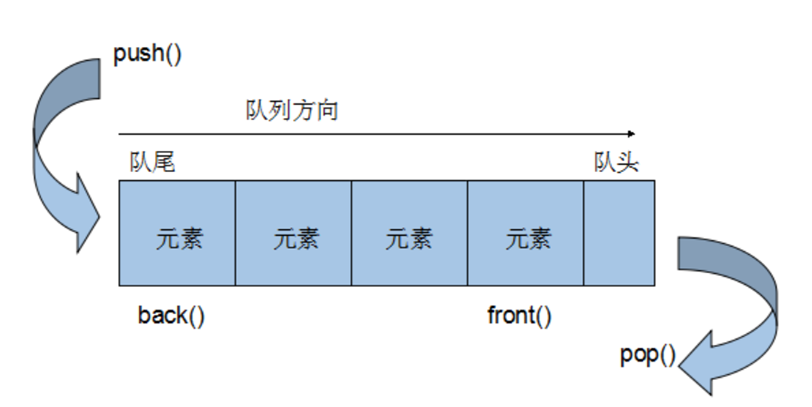
queue has no iterator
All elements in and out of the queue must meet the "first in, first out" condition. Only the top element of the queue can be accessed by the outside world. Queue does not provide traversal or iterators.
queue common API s
queue constructor
queue<T> queT;//Queue is implemented by template class. The default construction form of queue object is: queue(const queue &que);//copy constructor
queue access, insert, and delete operations
push(elem);//Add elements to the end of the queue pop();//Remove the first element from the team head back();//Returns the last element front();//Returns the first element
queue assignment operation
queue& operator=(const queue &que);//Overloaded equal sign operator
queue size operation
empty();//Determine whether the queue is empty size();//Returns the size of the queue
6. list container
Basic concepts of list container
Linked list is a non continuous and non sequential storage structure on the physical storage unit. The logical order of data elements is realized through the pointer link order in the linked list.
The linked list consists of a series of nodes (each element in the linked list is called a node), which can be generated dynamically at runtime. Each node includes two parts: one is the data field for storing the data element, and the other is the pointer field for storing the address of the next node.
Compared with the continuous linear space of vector, list is more responsible. Its advantage is that each time an element is inserted or deleted, it is to configure or release the space of an element. Therefore, the list is absolutely accurate in the use of space and is not wasted at all. Moreover, for element insertion or element removal at any position, list is always a constant time.
List and vector are the two most commonly used containers.
The List container is a two-way linked List.
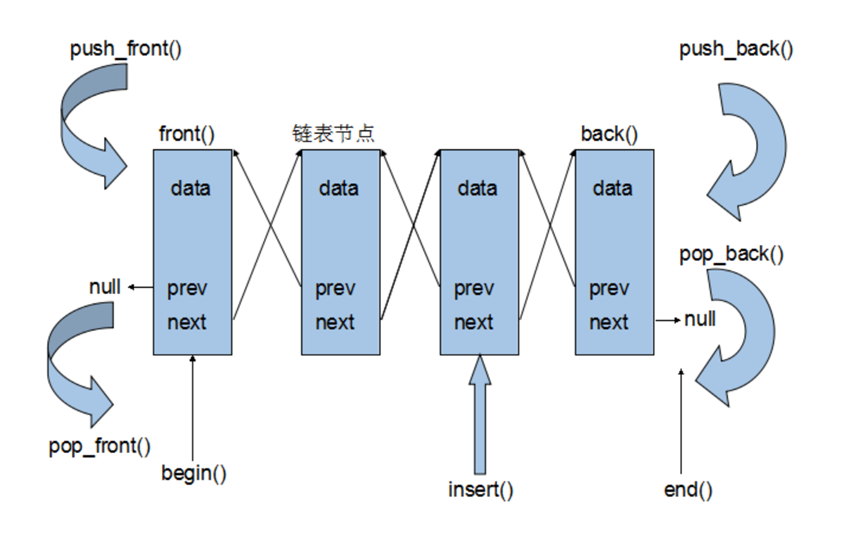
- Dynamic storage allocation will not cause memory waste and overflow
- It is very convenient to insert and delete the linked list. You can modify the pointer without moving a large number of elements
- The linked list is flexible, but it consumes more space and time
Iterator for list container
A List container cannot use a normal pointer as an iterator like a vector because its nodes cannot be guaranteed to be in the same contiguous memory space.
The list iterator must have the ability to point to the node of the list, and have the ability to correctly increment, decrement, value and member access operations. The so-called "list is correctly incremented, decremented, value taken and member taken" means that when incrementing, it points to the next node, when decrementing, it points to the previous node, when taking value, it takes the data value of the node, and when taking members, it takes the members of the node.
Because list is a two-way linked list, iterators must be able to move forward and backward, so the list container provides Bidirectional Iterators
List has an important property. Neither insert nor delete will invalidate the original list iterator. This is not true in vector, because the insertion operation of vector may cause memory reconfiguration, resulting in the invalidation of all the original iterators. Even when the list element is deleted, only the iterator of the deleted element will be invalid, and other iterators will not be affected.
Data structure of list container
The list container is not only a two-way linked list, but also a circular two-way linked list.
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<list>
using namespace std;
int main(){
list<int> myList;
for (int i = 0; i < 10; i ++){
myList.push_back(i);
}
list<int>::_Nodeptr node = myList._Myhead->_Next;
for (int i = 0; i < myList._Mysize * 2;i++){
cout << "Node:" << node->_Myval << endl;
node = node->_Next;
if (node == myList._Myhead){
node = node->_Next;
}
}
system("pause");
return EXIT_SUCCESS;
}
list common API s
list constructor
list<T> lstT;//list is implemented by template class, and the default construction form of object is: list(beg,end);//The constructor copies the elements in the [beg, end) interval to itself. list(n,elem);//The constructor copies n elem s to itself. list(const list &lst);//Copy constructor.
list data element insertion and deletion operations
push_back(elem);//Add an element at the end of the container pop_back();//Delete the last element in the container push_front(elem);//Insert an element at the beginning of the container pop_front();//Remove the first element from the beginning of the container insert(pos,elem);//Insert a copy of the elem element in the pos position to return the location of the new data. insert(pos,n,elem);//Insert n elem data in pos position, no return value. insert(pos,beg,end);//Insert the data in the [beg,end) interval at the pos position, and there is no return value. clear();//Remove all data from the container erase(beg,end);//Delete the data in the [beg,end) interval and return the position of the next data. erase(pos);//Delete the data in pos position and return the position of the next data. remove(elem);//Delete all elements in the container that match the elem value.
list size operation
size();//Returns the number of elements in the container empty();//Determine whether the container is empty resize(num);//Reassign the length of the container to num, If the container becomes longer, the new location is populated with the default value. If the container becomes shorter, the element whose end exceeds the length of the container is deleted. resize(num, elem);//Reassign the length of the container to num, If the container becomes longer, use elem Value populates the new location. If the container becomes shorter, the element whose end exceeds the length of the container is deleted.
list assignment operation
assign(beg, end);//Assign the data copy in the [beg, end) interval to itself. assign(n, elem);//Assign n elem copies to itself. list& operator=(const list &lst);//Overloaded equal sign operator swap(lst);//Swap lst with its own elements.
Access of list data
front();//Returns the first element. back();//Returns the last element.
list reverse sort
reverse();//Reverse the linked list. For example, lst contains 1,3,5 elements. After running this method, lst contains 5,3,1 elements. sort(); //list sort
7. set/multiset container
Basic concepts of set container
The characteristics of set are. All elements are automatically sorted according to the key value of the element. Unlike map, the element of set can have both real value and key value. The element of set is both key value and real value. Set does not allow two elements to have the same key value.
We can't change the value of the set element through the set iterator, because the value of the set element is its key value, which is related to the sorting rules of the set element. If you arbitrarily change the value of the set element, the set organization will be seriously damaged. In other words, the iterator of set is a const_iterator.
set has some of the same properties as list. When an element in a container is inserted or deleted, all iterators before the operation are still valid after the operation is completed. The iterator of the deleted element must be an exception.
Basic concepts of multiset container
Multiset has the same characteristics and usage as set. The only difference is that it allows key values to be repeated. The underlying implementation of set and multiset is red black tree
set common API s
set constructor
set<T> st;//set default constructor: mulitset<T> mst; //multiset default constructor: set(const set &st);//copy constructor
set assignment operation
set& operator=(const set &st);//Overloaded equal sign operator swap(st);//Swap two collection containers
set size operation
size();//Returns the number of elements in the container empty();//Determine whether the container is empty
set insert and delete operations
insert(elem);//Inserts an element into the container. clear();//Clear all elements erase(pos);//Delete the element referred to by the pos iterator and return the iterator of the next element. erase(beg, end);//Delete all elements of the interval [beg, end], and return the iterator of the next element. erase(elem);//Delete the element with element in the container.
set lookup operation
find(key);//Find out whether the key exists. If so, return the iterator of the element of the key; If it does not exist, return set end(); count(key);//Number of elements to find key lower_bound(keyElem);//Returns the iterator of the first key > = keyelem element. upper_bound(keyElem);//Returns the iterator of the first key > keyelem element. equal_range(keyElem);//Returns two iterators with upper and lower bounds equal to key and keyElem in the container.
The return value of set specifies the set collation example:
//Insert operation return value
void test01(){
set<int> s;
pair<set<int>::iterator,bool> ret = s.insert(10);
if (ret.second){
cout << "Insert successful:" << *ret.first << endl;
}
else{
cout << "Insert failed:" << *ret.first << endl;
}
ret = s.insert(10);
if(ret.second){
cout << "Insert successful:" << *ret.first << endl;
}
else{
cout << "Insert failed:" << *ret.first << endl;
}
}
struct MyCompare02{
bool operator()(int v1,int v2){
return v1 > v2;
}
};
//set from large to small
void test02(){
srand((unsigned int)time(NULL));
//We found that the second template parameter of the set container can set the sorting rule, and the default rule is less<_ Kty>
set<int, MyCompare02> s;
for (int i = 0; i < 10;i++){
s.insert(rand() % 100);
}
for (set<int, MyCompare02>::iterator it = s.begin(); it != s.end(); it ++){
cout << *it << " ";
}
cout << endl;
}
//Store objects in the set container
class Person{
public:
Person(string name,int age){
this->mName = name;
this->mAge = age;
}
public:
string mName;
int mAge;
};
struct MyCompare03{
bool operator()(const Person& p1,const Person& p2){
return p1.mAge > p2.mAge;
}
};
void test03(){
set<Person, MyCompare03> s;
Person p1("aaa", 20);
Person p2("bbb", 30);
Person p3("ccc", 40);
Person p4("ddd", 50);
s.insert(p1);
s.insert(p2);
s.insert(p3);
s.insert(p4);
for (set<Person, MyCompare03>::iterator it = s.begin(); it != s.end(); it++){
cout << "Name:" << it->mName << " Age:" << it->mAge << endl;
}
}
Pair
Pair combines a pair of values into a value. The pair of values can have different data types. The two values can be accessed by the two public attributes of pair, first and second, respectively.
Class template: template < class T1, class T2 > struct pair
Create a pair of groups:
//The first method creates a pair group
pair<string, int> pair1(string("name"), 20);
cout << pair1.first << endl; //Access the first value of pair
cout << pair1.second << endl;//Access the second value of pair
//Second
pair<string, int> pair2 = make_pair("name", 30);
cout << pair2.first << endl;
cout << pair2.second << endl;
//pair = assignment
pair<string, int> pair3 = pair2;
cout << pair3.first << endl;
cout << pair3.second << endl;
8. map/multimap container
Basic concepts of map/multimap
The feature of Map is that all elements are automatically sorted according to the key value of the element.
All the elements in the map are pair and have both real values and key values. The first element of pair is regarded as a key value and the second element is regarded as a real value. Map does not allow two elements to have the same key value.
We can't change the key value of map through the iterator of map, because the key value of map is related to the arrangement rules of map elements. Arbitrarily changing the key value of map will seriously damage the map organization. If you want to modify the real value of the element, you can.
Map and list have some of the same properties. When adding or deleting its container element, all iterators before the operation are still valid after the operation is completed. Of course, the iterator of the deleted element must be an exception.
The operation of Multimap is similar to that of map. The only difference is that the key value of Multimap can be repeated.
Both Map and multimap take red black tree as the underlying implementation mechanism.
map/multimap common API s
map constructor
map<T1, T2> mapTT;//map default constructor: map(const map &mp);//copy constructor
map assignment operation
map& operator=(const map &mp);//Overloaded equal sign operator swap(mp);//Swap two collection containers
map size operation
size();//Returns the number of elements in the container empty();//Determine whether the container is empty
map insert data element operation
map.insert(...); //Insert elements into the container and return pair < iterator, bool > map<int, string> mapStu; // The first method is to insert objects through pair mapStu.insert(pair<int, string>(3, "Xiao Zhang")); // The second method is to insert objects through pair mapStu.inset(make_pair(-1, "principal")); // The third pass value_type to insert objects mapStu.insert(map<int, string>::value_type(1, "petty thief")); // The fourth way is to insert values through arrays mapStu[3] = "Xiao Liu"; mapStu[5] = "Xiao Wang";
map delete operation
clear();//Delete all elements erase(pos);//Delete the element referred to by the pos iterator and return the iterator of the next element. erase(beg,end);//Delete all elements of the interval [beg, end], and return the iterator of the next element. erase(keyElem);//Delete the pair group whose key is keyElem in the container.
map lookup operation
find(key);//Find out whether the key exists. If so, return the iterator of the element of the key/ If it does not exist, return map end(); count(keyElem);//Returns the number of pairs in the container whose key is keyElem. For a map, either 0 or 1. For multimap, the value may be greater than 1. lower_bound(keyElem);//Returns the iterator of the first key > = keyelem element. upper_bound(keyElem);//Returns the iterator of the first key > keyelem element. equal_range(keyElem);//Returns two iterators with upper and lower bounds equal to key and keyElem in the container.
multimap case
//The company has recruited five employees today. After five employees enter the company, they need to assign employees to work in that department
//Personnel information includes: name, age, telephone, salary, etc
//Insert, save and display information through Multimap
//Display employee information by division display all employee information
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
#include<map>
#include<string>
#include<vector>
using namespace std;
//multimap case
//The company has recruited five employees today. After five employees enter the company, they need to assign employees to work in that department
//Personnel information includes: name, age, telephone, salary, etc
//Insert, save and display information through Multimap
//Display employee information by division display all employee information
#define SALE_ Dispatch 1 / / Sales Department
#define DEVELOP_ Development 2 / / R & D department
#define FINACIAL_ Dispatch 3 / / Finance Department
#define ALL_ Dispatch 4 / / all departments
//Employee category
class person{
public:
string name; //Employee name
int age; //Employee age
double salary; //Employee salary
string tele; //Employee telephone
};
//Create 5 employees
void CreatePerson(vector<person>& vlist){
string seed = "ABCDE";
for (int i = 0; i < 5; i++){
person p;
p.name = "staff";
p.name += seed[i];
p.age = rand() % 30 + 20;
p.salary = rand() % 20000 + 10000;
p.tele = "010-8888888";
vlist.push_back(p);
}
}
//5 employees assigned to different departments
void PersonByGroup(vector<person>& vlist, multimap<int, person>& plist){
int operate = -1; //User actions
for (vector<person>::iterator it = vlist.begin(); it != vlist.end(); it++){
cout << "Current employee information:" << endl;
cout << "full name:" << it->name << " Age:" << it->age << " wages:" << it->salary << " Telephone:" << it->tele << endl;
cout << "Please assign a department to this employee(1 Sales Department, 2 R & D department, 3 Finance Department):" << endl;
scanf("%d", &operate);
while (true){
if (operate == SALE_DEPATMENT){ //Add the employee to the sales department
plist.insert(make_pair(SALE_DEPATMENT, *it));
break;
}
else if (operate == DEVELOP_DEPATMENT){
plist.insert(make_pair(DEVELOP_DEPATMENT, *it));
break;
}
else if (operate == FINACIAL_DEPATMENT){
plist.insert(make_pair(FINACIAL_DEPATMENT, *it));
break;
}
else{
cout << "Your input is incorrect, please re-enter(1 Sales Department, 2 R & D department, 3 Finance Department):" << endl;
scanf("%d", &operate);
}
}
}
cout << "Employee Department assignment completed!" << endl;
cout << "***********************************************************" << endl;
}
//Print employee information
void printList(multimap<int, person>& plist, int myoperate){
if (myoperate == ALL_DEPATMENT){
for (multimap<int, person>::iterator it = plist.begin(); it != plist.end(); it++){
cout << "full name:" << it->second.name << " Age:" << it->second.age << " wages:" << it->second.salary << " Telephone:" << it->second.tele << endl;
}
return;
}
multimap<int, person>::iterator it = plist.find(myoperate);
int depatCount = plist.count(myoperate);
int num = 0;
if (it != plist.end()){
while (it != plist.end() && num < depatCount){
cout << "full name:" << it->second.name << " Age:" << it->second.age << " wages:" << it->second.salary << " Telephone:" << it->second.tele << endl;
it++;
num++;
}
}
}
//The personnel list of different departments is displayed according to user operations
void ShowPersonList(multimap<int, person>& plist, int myoperate){
switch (myoperate)
{
case SALE_DEPATMENT:
printList(plist, SALE_DEPATMENT);
break;
case DEVELOP_DEPATMENT:
printList(plist, DEVELOP_DEPATMENT);
break;
case FINACIAL_DEPATMENT:
printList(plist, FINACIAL_DEPATMENT);
break;
case ALL_DEPATMENT:
printList(plist, ALL_DEPATMENT);
break;
}
}
//User action menu
void PersonMenue(multimap<int, person>& plist){
int flag = -1;
int isexit = 0;
while (true){
cout << "Please enter your action((1 Sales Department, 2 R & D department, 3 Finance Department, 4 All departments, 0 sign out): " << endl;
scanf("%d", &flag);
switch (flag)
{
case SALE_DEPATMENT:
ShowPersonList(plist, SALE_DEPATMENT);
break;
case DEVELOP_DEPATMENT:
ShowPersonList(plist, DEVELOP_DEPATMENT);
break;
case FINACIAL_DEPATMENT:
ShowPersonList(plist, FINACIAL_DEPATMENT);
break;
case ALL_DEPATMENT:
ShowPersonList(plist, ALL_DEPATMENT);
break;
case 0:
isexit = 1;
break;
default:
cout << "Your input is incorrect, please re-enter!" << endl;
break;
}
if (isexit == 1){
break;
}
}
}
int main(){
vector<person> vlist; //The 5 employees created are not grouped
multimap<int, person> plist; //Save employee information after grouping
//Create 5 employees
CreatePerson(vlist);
//5 employees assigned to different departments
PersonByGroup(vlist, plist);
//Display the employee information list of different departments or the information list of all employees according to user input
PersonMenue(plist);
system("pause");
return EXIT_SUCCESS;
}
STL container usage timing
| . | vector | deque | list | set | multiset | map | multimap |
|---|---|---|---|---|---|---|---|
| Typical memory structure | Single ended array | Double ended array | Bidirectional linked list | Binary tree | Binary tree | Binary tree | Binary tree |
| Random access | yes | yes | no | no | no | For key: No | no |
| Element search speed | slow | slow | Very slow | fast | fast | For key: fast | For key: fast |
| Element placement and removal | Tail end | Head and tail ends | Any location | - | - | - | - |
Usage scenario of vector: for example, in the storage of software history operation records, we often check the history records, such as the last record and the last record, but we will not delete the records, because the records are descriptions of facts.
Use scenario of deque: for example, in the queuing ticket system, deque can be used for the storage of queuers, supporting the rapid removal of the head end and the rapid addition of the tail end. If vector is used, a large amount of data will be moved when the head end is removed, and the speed is slow.
Comparison between vector and deque:
1: Vector At () is better than deque At () is efficient, such as vector At (0) is fixed, but the starting position of deque is not fixed.
2: If there are a large number of release operations, the vector takes less time, which is related to the internal implementation of the two.
3: Deque supports rapid insertion and removal of the head, which is the advantage of deque.
Use scenario of list: for example, the storage of bus passengers, passengers may get off at any time, and frequent removal and insertion of uncertain location elements are supported.
Usage scenario of set: for example, the storage of personal score records of mobile games requires the order from high score to low score.
Usage scenario of map: for example, 100000 users are stored by ID number. If you want to quickly find the corresponding user through ID. The search efficiency of binary tree is reflected at this time. If it is a vector container, in the worst case, you may have to traverse the entire container to find the user.
Common algorithms
1. Function object
The objects of classes that overload function call operators are often called function object s, that is, they are objects that behave like functions, also known as functors. In fact, they overload the "()" operator so that class objects can be called like functions.
be careful:
- A function object (functor) is a class, not a function.
- The function object (functor) overloads the "()" operator so that it can be called like a function.
Classification: assuming that a class has an overloaded operator() and the overloaded operator() requires to obtain a parameter, we call this class "unary function"; on the contrary, if the overloaded operator() requires to obtain two parameters, we call this class "binary function".
Functions of function objects:
The algorithms provided by STL often have two versions, one of which shows the most commonly used operation, and the other allows users to specify the policy to be adopted in the form of template parameter.
//A function object is a class that overloads the function call symbol
class MyPrint
{
public:
MyPrint()
{
m_Num = 0;
}
int m_Num;
public:
void operator() (int num)
{
cout << num << endl;
m_Num++;
}
};
//Function object
//The instantiated object of a class that overloads the () operator can be called like an ordinary function. It can have parameters and return values
void test01()
{
MyPrint myPrint;
myPrint(20);
}
// Function objects go beyond the concept of ordinary functions and can save the call state of functions
void test02()
{
MyPrint myPrint;
myPrint(20);
myPrint(20);
myPrint(20);
cout << myPrint.m_Num << endl;
}
void doBusiness(MyPrint print,int num)
{
print(num);
}
//Function object as argument
void test03()
{
//Parameter 1: anonymous function object
doBusiness(MyPrint(),30);
}
Summary:
1. Function objects usually do not define constructors and destructors, so there will be no problems during construction and destructor, avoiding the runtime problems of function calls.
2. Function objects go beyond the concept of ordinary functions. Function objects can have their own states
3. Function objects can be compiled inline with good performance. It is almost impossible to use function pointers
4. Template function objects make function objects universal, which is one of its advantages
2. Predicate
Predicates refer to ordinary functions or overloaded operator() whose return value is a bool type function object (imitation function). If the operator accepts one parameter, it is called a unary predicate. If it accepts two parameters, it is called a binary predicate. The predicate can be used as a judgment.
class GreaterThenFive
{
public:
bool operator()(int num)
{
return num > 5;
}
};
//one-element predicate
void test01()
{
vector<int> v;
for (int i = 0; i < 10;i ++)
{
v.push_back(i);
}
vector<int>::iterator it = find_if(v.begin(), v.end(), GreaterThenFive());
if (it == v.end())
{
cout << "Can't find" << endl;
}
else
{
cout << "eureka: " << *it << endl;
}
}
//two-place predicate
class MyCompare
{
public:
bool operator()(int num1, int num2)
{
return num1 > num2;
}
};
void test02()
{
vector<int> v;
v.push_back(10);
v.push_back(40);
v.push_back(20);
v.push_back(90);
v.push_back(60);
//Default from small to large
sort(v.begin(), v.end());
for (vector<int>::iterator it = v.begin(); it != v.end();it++)
{
cout << *it << " ";
}
cout << endl;
cout << "----------------------------" << endl;
//Use the function object to change the algorithm strategy and sort from large to small
sort(v.begin(), v.end(),MyCompare());
for (vector<int>::iterator it = v.begin(); it != v.end(); it++)
{
cout << *it << " ";
}
cout << endl;
}
3. Built in function object
STL has built-in function objects. It is divided into: arithmetic function object, relational operation function object, logical operation and imitation function. The usage of the objects generated by these imitation functions is exactly the same as that of general functions. Of course, we can also generate nameless temporary objects to perform function functions. When using built-in function objects, you need to import header files
#include<functional>.
The six arithmetic function objects are binary operations except that negate is a unary operation.
template<class T> T plus<T>//Additive affine function template<class T> T minus<T>//Subtractive imitation function template<class T> T multiplies<T>//Multiplicative affine function template<class T> T divides<T>//Division imitation function template<class T> T modulus<T>//Take imitation function template<class T> T negate<T>//Take inverse affine function
Six relational operation class function objects, each of which is a binary operation.
template<class T> bool equal_to<T>//be equal to template<class T> bool not_equal_to<T>//Not equal to template<class T> bool greater<T>//greater than template<class T> bool greater_equal<T>//Greater than or equal to template<class T> bool less<T>//less than template<class T> bool less_equal<T>//Less than or equal to
Logic operation class operation function, not is unary operation, and the rest are binary operation.
template<class T> bool logical_and<T>//Logic and template<class T> bool logical_or<T>//Logical or template<class T> bool logical_not<T>//Logical non
Examples of built-in function objects:
//Take inverse affine function
void test01()
{
negate<int> n;
cout << n(50) << endl;
}
//Additive affine function
void test02()
{
plus<int> p;
cout << p(10, 20) << endl;
}
//Greater than affine function
void test03()
{
vector<int> v;
srand((unsigned int)time(NULL));
for (int i = 0; i < 10; i++){
v.push_back(rand() % 100);
}
for (vector<int>::iterator it = v.begin(); it != v.end(); it++){
cout << *it << " ";
}
cout << endl;
sort(v.begin(), v.end(), greater<int>());
for (vector<int>::iterator it = v.begin(); it != v.end(); it++){
cout << *it << " ";
}
cout << endl;
}
4. Function object adapter
//Function adapter bind1st bind2nd
//Now I have this requirement. When traversing the container, I want to display all the values in the container after adding 100. What should I do?
//If we bind parameters directly to the function object, an error will be reported at the compilation stage
//for_each(v.begin(), v.end(), bind2nd(myprint(),100));
//If we want to use the binding adapter, we need our own function object to inherit binary_function or unary_function
//According to whether our function object is a unary function object or a binary function object
class MyPrint :public binary_function<int,int,void>
{
public:
void operator()(int v1,int v2) const
{
cout << "v1 = : " << v1 << " v2 = :" <<v2 << " v1+v2 = :" << (v1 + v2) << endl;
}
};
//1. Function adapter
void test01()
{
vector<int>v;
for (int i = 0; i < 10; i++)
{
v.push_back(i);
}
cout << "Please enter a starting value:" << endl;
int x;
cin >> x;
for_each(v.begin(), v.end(), bind1st(MyPrint(), x));
//for_each(v.begin(), v.end(), bind2nd( MyPrint(),x ));
}
//Summary: what is the difference between bind1st and bind2nd?
//bind1st: bind the parameter to the first parameter of the function object
//bind2nd: bind the parameter to the second parameter of the function object
//bind1st bind2nd converts a binary function object to a unary function object
class GreaterThenFive:public unary_function<int,bool>
{
public:
bool operator ()(int v) const
{
return v > 5;
}
};
//2. Reverse Adapter
void test02()
{
vector <int> v;
for (int i = 0; i < 10;i++)
{
v.push_back(i);
}
// vector<int>::iterator it = find_ if(v.begin(), v.end(), GreaterThenFive()); // Returns the first iterator greater than 5
// vector<int>::iterator it = find_ if(v.begin(), v.end(), not1(GreaterThenFive())); // Returns the first iterator less than 5
//Custom input
vector<int>::iterator it = find_if(v.begin(), v.end(), not1 ( bind2nd(greater<int>(),5)));
if (it == v.end())
{
cout << "Can't find" << endl;
}
else
{
cout << "find" << *it << endl;
}
//Sort binary function objects
sort(v.begin(), v.end(), not2(less<int>()));
for_each(v.begin(), v.end(), [](int val){cout << val << " "; });
}
//not1 negates a unary function object
//not2 negates a binary function object
void MyPrint03(int v,int v2)
{
cout << v + v2<< " ";
}
//3. Function pointer adapter ptr_fun
void test03()
{
vector <int> v;
for (int i = 0; i < 10; i++)
{
v.push_back(i);
}
// ptr_fun() adapts an ordinary function pointer to a function object
for_each(v.begin(), v.end(), bind2nd( ptr_fun( MyPrint03 ), 100));
}
//4. Member function adapter
class Person
{
public:
Person(string name, int age)
{
m_Name = name;
m_Age = age;
}
//Print function
void ShowPerson(){
cout << "Member function:" << "Name:" << m_Name << " Age:" << m_Age << endl;
}
void Plus100()
{
m_Age += 100;
}
public:
string m_Name;
int m_Age;
};
void MyPrint04(Person &p)
{
cout << "full name:" << p.m_Name << " Age:" << p.m_Age << endl;
};
void test04()
{
vector <Person>v;
Person p1("aaa", 10);
Person p2("bbb", 20);
Person p3("ccc", 30);
Person p4("ddd", 40);
v.push_back(p1);
v.push_back(p2);
v.push_back(p3);
v.push_back(p4);
//for_each(v.begin(), v.end(), MyPrint04);
//Using mem_fun_ref adapts the Person internal member function
for_each(v.begin(), v.end(), mem_fun_ref(&Person::ShowPerson));
// for_each(v.begin(), v.end(), mem_fun_ref(&Person::Plus100));
// for_each(v.begin(), v.end(), mem_fun_ref(&Person::ShowPerson));
}
void test05(){
vector<Person*> v1;
//Create data
Person p1("aaa", 10);
Person p2("bbb", 20);
Person p3("ccc", 30);
Person p4("ddd", 40);
v1.push_back(&p1);
v1.push_back(&p2);
v1.push_back(&p3);
v1.push_back(&p4);
for_each(v1.begin(), v1.end(), mem_fun(&Person::ShowPerson));
}
//If the container holds object pointers, use mem_fun
//If the object entity is stored in the container, MEM is used_ fun_ ref
Algorithm overview
The algorithm is mainly composed of header files < algorithm > < functional > < numeric >.
< algorithm > is the largest of all STL header files. The commonly used functions involve comparison, exchange, search, traversal, copy, modify, reverse, sort, merge, etc
< numeric > is very small and only includes template functions for simple operations on several sequence containers
< functional > defines some template classes to declare function objects.
1. Common traversal algorithms
/*
The traversal algorithm traverses the container elements
@param beg Start iterator
@param end End iterator
@param _callback Function callback or function object
@return Function object
*/
for_each(iterator beg, iterator end, _callback);
/*
transform The algorithm moves the specified container interval element to another container
Note: transform will not allocate memory to the target container, so we need to allocate memory in advance
@param beg1 Source container start iterator
@param end1 Source container end iterator
@param beg2 Destination container start iterator
@param _cakkback Callback function or function object
@return Returns the destination container iterator
*/
transform(iterator beg1, iterator end1, iterator beg2, _callbakc)
for_each:
/*
template<class _InIt,class _Fn1> inline
void for_each(_InIt _First, _InIt _Last, _Fn1 _Func)
{
for (; _First != _Last; ++_First)
_Func(*_First);
}
*/
//Ordinary function
void print01(int val){
cout << val << " ";
}
//Function object
struct print001{
void operator()(int val){
cout << val << " ";
}
};
//for_ Basic usage of each algorithm
void test01(){
vector<int> v;
for (int i = 0; i < 10;i++){
v.push_back(i);
}
//inorder traversal
for_each(v.begin(), v.end(), print01);
cout << endl;
for_each(v.begin(), v.end(), print001());
cout << endl;
}
struct print02{
print02(){
mCount = 0;
}
void operator()(int val){
cout << val << " ";
mCount++;
}
int mCount;
};
//for_each return value
void test02(){
vector<int> v;
for (int i = 0; i < 10; i++){
v.push_back(i);
}
print02 p = for_each(v.begin(), v.end(), print02());
cout << endl;
cout << p.mCount << endl;
}
struct print03 : public binary_function<int, int, void>{
void operator()(int val,int bindParam) const{
cout << val + bindParam << " ";
}
};
//for_each binding parameter output
void test03(){
vector<int> v;
for (int i = 0; i < 10; i++){
v.push_back(i);
}
for_each(v.begin(), v.end(), bind2nd(print03(),100));
}
transform:
//transform moves values from one container to another
/*
template<class _InIt, class _OutIt, class _Fn1> inline
_OutIt _Transform(_InIt _First, _InIt _Last,_OutIt _Dest, _Fn1 _Func)
{
for (; _First != _Last; ++_First, ++_Dest)
*_Dest = _Func(*_First);
return (_Dest);
}
template<class _InIt1,class _InIt2,class _OutIt,class _Fn2> inline
_OutIt _Transform(_InIt1 _First1, _InIt1 _Last1,_InIt2 _First2, _OutIt _Dest, _Fn2 _Func)
{
for (; _First1 != _Last1; ++_First1, ++_First2, ++_Dest)
*_Dest = _Func(*_First1, *_First2);
return (_Dest);
}
*/
struct transformTest01{
int operator()(int val){
return val + 100;
}
};
struct print01{
void operator()(int val){
cout << val << " ";
}
};
void test01(){
vector<int> vSource;
for (int i = 0; i < 10;i ++){
vSource.push_back(i + 1);
}
//Target container
vector<int> vTarget;
//Make room for vTarget
vTarget.resize(vSource.size());
//Move elements from vSource to vTarget
vector<int>::iterator it = transform(vSource.begin(), vSource.end(), vTarget.begin(), transformTest01());
//Print
for_each(vTarget.begin(), vTarget.end(), print01()); cout << endl;
}
//Add the elements in container 1 and container 2 into the third container
struct transformTest02{
int operator()(int v1,int v2){
return v1 + v2;
}
};
void test02(){
vector<int> vSource1;
vector<int> vSource2;
for (int i = 0; i < 10; i++){
vSource1.push_back(i + 1);
}
//Target container
vector<int> vTarget;
//Make room for vTarget
vTarget.resize(vSource1.size());
transform(vSource1.begin(), vSource1.end(), vSource2.begin(),vTarget.begin(), transformTest02());
//Print
for_each(vTarget.begin(), vTarget.end(), print01()); cout << endl;
}
2. Common search algorithms
/* find Algorithm lookup element @param beg Container start iterator @param end Container end iterator @param value Elements to find @return Returns the location of the lookup element */ find(iterator beg, iterator end, value) /* find_if Algorithm condition search @param beg Container start iterator @param end Container end iterator @param callback Callback function or predicate (return bool type function object) @return bool Search returns true, otherwise false */ find_if(iterator beg, iterator end, _callback); /* adjacent_find Algorithm to find adjacent duplicate elements @param beg Container start iterator @param end Container end iterator @param _callback Callback function or predicate (return bool type function object) @return An iterator that returns the first position of an adjacent element */ adjacent_find(iterator beg, iterator end, _callback); /* binary_search Algorithm binary search method Note: not available in unordered sequences @param beg Container start iterator @param end Container end iterator @param value Elements to find @return bool Search returns true, otherwise false */ bool binary_search(iterator beg, iterator end, value); /* count The algorithm counts the number of occurrences of elements @param beg Container start iterator @param end Container end iterator @param value Callback function or predicate (return bool type function object) @return int Returns the number of elements */ count(iterator beg, iterator end, value); /* count The algorithm counts the number of occurrences of elements @param beg Container start iterator @param end Container end iterator @param callback Callback function or predicate (return bool type function object) @return int Returns the number of elements */ count_if(iterator beg, iterator end, _callback);
3. Common sorting algorithms
/* merge Algorithm container elements are merged and stored in another container @param beg1 Container 1 start iterator @param end1 Container 1 end iterator @param beg2 Container 2 starts the iterator @param end2 Container 2 end iterator @param dest Destination container start iterator */ merge(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest) /* sort Algorithm container element sorting Note: the two containers must be ordered @param beg Container 1 start iterator @param end Container 1 end iterator @param _callback Callback function or predicate (return bool type function object) */ sort(iterator beg, iterator end, _callback) /* sort The algorithm randomly adjusts the order of elements within the specified range @param beg Container start iterator @param end Container end iterator */ random_shuffle(iterator beg, iterator end) /* reverse The algorithm inverts the elements of the specified range @param beg Container start iterator @param end Container end iterator */ reverse(iterator beg, iterator end)
4. Common copy and replacement algorithms
/* copy The algorithm copies the specified range of elements in the container to another container @param beg Container start iterator @param end Container end iterator @param dest Target start iterator */ copy(iterator beg, iterator end, iterator dest) /* replace The algorithm modifies the old element of the specified range in the container to a new element @param beg Container start iterator @param end Container end iterator @param oldvalue Old element @param oldvalue New element */ replace(iterator beg, iterator end, oldvalue, newvalue) /* replace_if The algorithm replaces the elements that meet the conditions in the specified range in the container with new elements @param beg Container start iterator @param end Container end iterator @param callback Function callback or predicate (return Bool type function object) @param oldvalue New element */ replace_if(iterator beg, iterator end, _callback, newvalue) /* swap The algorithm swaps the elements of two containers @param c1 Container 1 @param c2 Container 2 */ swap(container c1, container c2)
5. Common arithmetic generation algorithms
/* accumulate The algorithm calculates the cumulative sum of container elements @param beg Container start iterator @param end Container end iterator @param value Cumulative value */ accumulate(iterator beg, iterator end, value) /* fill The algorithm adds elements to the container @param beg Container start iterator @param end Container end iterator @param value t Fill element */ fill(iterator beg, iterator end, value)
6. Common set algorithms
/* set_intersection Algorithm for finding the intersection of two set s Note: the two sets must be an ordered sequence @param beg1 Container 1 start iterator @param end1 Container 1 end iterator @param beg2 Container 2 starts the iterator @param end2 Container 2 end iterator @param dest Destination container start iterator @return Iterator address of the last element of the target container */ set_intersection(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest) /* set_union An algorithm for finding the union of two set s Note: the two sets must be an ordered sequence @param beg1 Container 1 start iterator @param end1 Container 1 end iterator @param beg2 Container 2 starts the iterator @param end2 Container 2 end iterator @param dest Destination container start iterator @return Iterator address of the last element of the target container */ set_union(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest) /* set_difference Algorithm for the difference set of two sets Note: the two sets must be an ordered sequence @param beg1 Container 1 start iterator @param end1 Container 1 end iterator @param beg2 Container 2 starts the iterator @param end2 Container 2 end iterator @param dest Destination container start iterator @return Iterator address of the last element of the target container */ set_difference(iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)