Preface
C++ Concurrency
Reference courses: https://www.bilibili.com/video/BV1Yb411L7ak?p=4&spm_id_from=pageDriver
Reference Notes: https://blog.csdn.net/qq_38231713/category_10001159.html
My previous notes (modern C++ tutorial notes (next)): https://zhuanlan.zhihu.com/p/415910318
1. Processes and Threads
Narrowly, each process (the executable that executes) has a main thread, which is unique, that is, there can only be one main thread in a process.
In fact, when CTRL + F5 runs a simple program, it is actually the main thread of the process that executes (calls) the code in this main function.
Thread: Used to execute code. Understand as a code execution path (road).
In a multithreaded environment, each thread has a stack and a program counter. Stack and program counters are thread-private resources that hold the execution history and state of a thread. Other resources, such as heaps, address spaces, and global variables, are shared by multiple threads within the same process.

2. Thread start and end, create thread multimethod, join, detach

-
The program runs and a process is generated, and the main thread to which the process belongs starts running automatically. When the main thread returns from the main() function, the entire process is executed
-
The main thread executes from main(), so the threads we create ourselves also need to run from a function (the initial function), and once the function is run, the thread ends.
-
The mark of whether the whole process has finished executing is whether the main thread has finished executing or not, if the main thread has finished executing, it will execute on behalf of the whole process, and if other sub-threads have not finished executing, it will also be forcibly terminated by the operating system. [This exception will be explained later]
Create a thread:
- Include header file thread
- Write Initial Function
- Create thread in main
#include <iostream>
#include <thread>
using namespace std;
void myPrint()
{
cout << "My thread started running" << endl;
//-------------
//-------------
cout << "My thread finished running" << endl;
return;
}
int main()
{
//(1) Threads are created and the starting point (entry) for thread execution is myPrint; (2) Execution Threads
thread myThread(myPrint);
//(2) Block the main thread and wait for myPrint to finish executing. When myPrint finishes executing, join() finishes executing and the main thread continues executing down
//Join means join, where child and main threads join
myThread.join();
//Set breakpoints to see how the main thread waits for its child threads
//F11 statement by statement, is to execute one line at a time, if it encounters a function call, it will enter the function
//F10 procedure by procedure, when encountering a function, do not enter the function, the function call as a statement to execute
//(3) In traditional multi-threaded programs, the main thread waits for the sub-thread to finish executing before it can execute itself downward.
//Detach: detach, main thread no longer merges with child thread, no longer waits for child thread
//After detach, the child thread loses its association with the main thread, resides in the background and is taken over by the C++ runtime library
//myThread.detach();
//(4)joinable() determines whether join() or detach() can be used successfully, returning true or false
//If true is returned, it proves that join() or detach() can be called
//If false is returned, it proves that join() or detach(), join() and detach() have been called and can no longer be called
if (myThread.joinable())
{
cout << "Can Call Can Call join()perhaps detach()" << endl;
}
else
{
cout << "Cannot call callable join()perhaps detach()" << endl;
}
cout << "Hello World!" << endl;
return 0;
}
In traditional multithreading, if the main thread finishes executing, but the subthread does not, the program is unstable and may report an exception. (For example, delete myThread.join(); above). Therefore, a well-written program should be the main thread waiting for the child thread to finish execution before it finally exits.
There is detach() method after C++11. Detach: detach, the main thread no longer joins with the child thread, no longer waits for the child thread detach, the child thread loses its association with the main thread, resides in the background, and is taken over by the C++ runtime library. When this subthread finishes execution, the runtime library is responsible for cleaning up the thread-related resources (daemon threads).
However, the teacher suggested that the main thread wait for the end of the sub-threads one by one, which is more stable.
Important additions:
The parameter to the thread class is a callable object.
A set of executable statements is called a callable object. Callable objects in c++ can be functions, function pointers, lambda expressions, objects created by bind, or class objects that overload function call operators.
For example, classes that overload operator():
class Ta
{
public:
void operator()() //Cannot take parameters
{
cout << "My thread started running" << endl;
//-------------
//-------------
cout << "My thread finished running" << endl;
}
};
//In main function:
Ta ta;
thread myThread(ta);
myThread.join();
The lambda expression creates a thread:
//In main function
auto lambdaThread = [] {
cout << "My thread started executing" << endl;
//-------------
//-------------
cout << "My thread started executing" << endl;
};
thread myThread(lambdaThread);
myThread.join();
Use a function in a class as the entry address for a thread:
class Data_
{
public:
void GetMsg(){}
void SaveMsh(){}
};
//In main function
Data_ s;
//The first meaning is address, the second meaning is reference, equivalent to std::ref(s)
//Thread oneobj (&Data_:: SaveMsh, s) is also possible to pass values
//In other constructors &obj does not represent a reference and is treated as an address
//Call method: object member function address, class instance, [member function parameter]
//The second parameter can pass either an object s or a reference std::ref(s) or &s
//Pass s s s, which calls the copy constructor to generate a new object in the child thread
//Delivery &, the original object is still used in the child thread, so detach is not possible because the object will be released when the main thread finishes running
thread oneobj(&Data_::SaveMsh, &s);
thread twoobj(&Data_::GetMsg, &s);
oneobj.join();
twoobj.join();
3. Thread parameter details, detach() pit, member function as thread function

1. Pass Temporary Object as Thread Parameter
1.1 Trap to avoid 1:
#include <iostream>
#include <thread>
using namespace std;
void myPrint(const int &i, char* pmybuf)
{
//If the thread detach s from the main thread
//I is not a real reference to mvar, but actually value passing. Even though the main thread is finished and the child thread is still safe with i, passing references is not recommended
//Recommended change to const int i
cout << i << endl;
//pmybuf still points to the original string, so this is not safe to write
cout << pmybuf << endl;
}
int main()
{
int mvar = 1;
int& mvary = mvar;
char mybuf[] = "this is a test";
thread myThread(myPrint, mvar, mybuf);//The first parameter is the function name, and the last two are the parameters of the function
myThread.join();
//myThread.detach();
cout << "Hello World!" << endl;
}
1.2 Traps to avoid 2:
#include <iostream>
#include <thread>
#include <string>
using namespace std;
void myPrint(const int i, const string& pmybuf)
{
cout << i << endl;
cout << pmybuf << endl;
}
int main()
{
int mvar = 1;
int& mvary = mvar;
char mybuf[] = "this is a test";
//If detach, it's still unsafe
//Mybuf was recycled because there was a main thread running, and the system converted mybuf implicitly to string
//It is recommended that you first create a temporary object thread myThread(myPrint, mvar, string(mybuf)); It's absolutely safe.
thread myThread(myPrint, mvar, mybuf);
myThread.join();
//myThread.detach();
cout << "Hello World!" << endl;
}
1.3 Summary
- If passing int is a simple type, value passing is recommended, not reference
- If you pass class objects instead of implicit type conversions, all you do is create threads, create temporary objects, and then in function parameters, follow by references, otherwise create an object
- Ultimate conclusion: detach is not recommended
2. Thread id concept
- id is a number, and each thread (whether main or child) actually has a number, and each thread has a different number
- Thread IDS can be obtained using functions in the C++ standard library. std::this_thread::get_id() to get
3. Passing Class Objects and Smart Pointer as Thread Parameters
3.1:
#include <iostream>
#include <thread>
using namespace std;
class A {
public:
mutable int m_i; //m_i can be modified even in real const
A(int i) :m_i(i) {}
};
void myPrint(const A& pmybuf)
{
pmybuf.m_i = 199;
cout << "Child Thread myPrint The parameter address is" << &pmybuf << "thread = " << std::this_thread::get_id() << endl;
}
int main()
{
A myObj(10);
//References in myPrint (const A & pmybuf) cannot be removed, if removed an additional object will be created
//const can't be removed, it will make a mistake
//Even though a const reference is passed, a copy constructor is called in the child thread to construct a new object.
//So modify m_i n the child thread The value of I does not affect the main thread
//If you want m_to be modified in a child thread The value of I affects the main thread, you can use thread myThread(myPrint, std::ref(myObj));
//So const is really a reference, const in myPrint definition can be removed, mutable in class A definition can also be removed
thread myThread(myPrint, myObj);
myThread.join();
//myThread.detach();
cout << "Hello World!" << endl;
}
3.2:
#include <iostream>
#include <thread>
#include <memory>
using namespace std;
void myPrint(unique_ptr<int> ptn)
{
cout << "thread = " << std::this_thread::get_id() << endl;
}
int main()
{
unique_ptr<int> up(new int(10));
//Exclusive pointers can only be passed to another pointer through std::move()
//up points to empty after passing, new ptn points to original memory
//So detach is no longer possible because if the main thread finishes executing first, the object ptn points to is released
thread myThread(myPrint, std::move(up));
myThread.join();
//myThread.detach();
return 0;
}
4. Create multiple threads, data sharing problem analysis, case code

1. Create and wait for multiple threads
void TextThread()
{
cout << "I am a thread" << this_thread::get_id() << endl;
/* ... */
cout << "thread" << this_thread::get_id() << "end of execution" << endl;
}
//vector threadagg in main function;
for (int i = 0; i < 10; ++i)
{
threadagg.push_back(thread(TextThread));
}
for (int i = 0; i < 10; ++i)
{
threadagg[i].join();
}
- Managing threads in containers looks like an array of threads, which is good for creating a large number of threads at a time and managing a large number of threads
- The execution order of multiple threads is chaotic, related to the running scheduling mechanism of threads within the operating system
2. Analysis of Data Sharing
2.1 Read-only data
Is secure and stable
2.2 Read and Write
- If left untreated, an error will occur
- The easiest way to prevent crashes is to read without writing and write without reading.
- Writing is a multi-step process, with all sorts of weird things happening (most likely crashing) due to task switching
Example: Game Server, Maintain Command Queue (abstracted by list of chains), a thread reads commands and executes them, then pop_front, a thread plugs in the command; An error (an exception) will occur if unhandled.
5. Mutex concept, usage, deadlock demonstration and resolution details

1. Basic concepts of mutex
- Mutex is a class object, which can be interpreted as a lock. Multiple threads try to lock with the lock() member function. Only one thread can lock successfully. If no lock is successful, the process will get stuck in the lock() and keep trying to lock.
- Be careful when using mutex. Protect not more or less data, less data will not achieve effect, and more data will affect efficiency.
2. Usage of Mutual Exclusion
Include #include <mutex>header file
2.1 lock(),unlock()
- Steps: 1.lock(), 2. operation sharing data, 3.unlock().
- lock() and unlock() are used in pairs
class A Members in: std::mutex my_mutex; Code you want to protect: my_mutex.lock(); // Execute Code ...... my_mutex.unlock(); return ...;
2.2 lock_guard class template
- lock_guard<mutex> sbguard(myMutex); Replace lock() and unlock(); That is, lock_is used After guard, lock () and unlock () can no longer be used
- Lock_ The guard constructor executes mutex::lock(); At the end of the scope, call the destructor and execute mutex::unlock()
std::lock_guard<std::mutex> sbguard(my_mutex); // sbguard is a casual name
You can't use it anymore lock and unlock Yes, lock_guard Automatically Help Take Over
The principle is simple, first of all lock_guard Executed in constructor mutex::lock(),It's time to destruct after the scope has ended mutex::unlock()
So not as good lock and unlock Flexible, but you can also add scopes yourself{}Achieve early end of life
3. Deadlock
3.1 Deadlock Demo
Deadlocks have at least two mutex1, mutex2 mutexs.
- A. When thread A executes, the thread locks mutex1 first, and the lock succeeds, and then unlocks mutex2, a context switch occurs.
- B. Thread B executes. This thread locks mutex2 first because mutex2 is not locked, that is, mutex2 can be successfully locked, and then thread B unlocks mutex1.
- c. A locks mutex1, needs to lock mutex2, B locks mutex2, needs to lock mutex1, and the two threads cannot continue running.
3.2 General solution to deadlocks:
As long as the sequence of locks on multiple mutexes is guaranteed to be the same, no deadlock will occur. (broken deadlock loop wait condition)
Reference resources: https://zhuanlan.zhihu.com/p/373966882
Deadlock refers to the phenomenon that two or more processes wait for each other due to competing for resources during execution. The following four conditions are required to produce a deadlock:
- Mutual exclusion condition: A process does not allow access to the assigned resource by other processes. If other processes access the resource, they can only wait until the process that owns the resource has finished using it and released it.
- Occupancy and wait conditions: When a process has acquired a certain resource, it makes requests to other resources, but the resource may be occupied by other processes. At this time, the request is blocked, but the process will not release the resources it has already occupied.
- Non-preemptive conditions: Resources acquired by a process cannot be deprived until they are fully used, and they can only be released by themselves after use.
- Cyclic wait condition: When a process deadlocks, there must be a loop chain between processes and resources.
How can I solve the deadlock problem?
The solution to deadlock is to destroy one of the four prerequisites for creating a deadlock by:
- The resources are allocated at one time so there are no more requests (breaking the request conditions). As long as one resource is unassigned, no other resources are allocated to the process (breaking possession and waiting conditions).
- Preemptive resources: Release occupied resources when new resources of the process are not met, thereby destroying conditions that are not preemptive.
- Ordered resource allocation: The system assigns a sequence number to each type of resource, and each process incrementally requests the resource, releasing it instead, disrupting the wait conditions in the loop
3.3 std::lock() function template
- std::lock(mutex1,mutex2...); Lock multiple mutexes at once (rarely in this case) to handle multiple mutexes.
- If one of the mutexes is not locked, it waits until all mutexes are locked to continue execution. If one is unlocked, the locked one will be released (either mutually exclusive or unlocked to prevent deadlock).
3.4 std::lock_guard's std::adopt_lock parameter
- std::lock_guard<std::mutex> my_guard(my_mutex, std::adopt_lock);
Add adopt_ After lock, lock_is called lock() is no longer applied when guard's constructor is used; - adopt_guard is a struct object and acts as a marker to indicate that this mutex has been locked () and no longer needs to be locked ().
Simple examples: std::lock(my_mutex1, my_mutex2); // Equivalent to calling.lock() for each mutex; std::lock_guard<std::mutex> sbguard1(my_mutex1, std::adopt_lock); std::lock_guard<std::mutex> sbguard2(my_mutex2, std::adopt_lock); In this way, lock from std::lock The takeover guaranteed, and unlock Then by std::lock_guard Take-over guaranteed
Sample code:
#include <iostream>
#include <thread>
#include <list>
#include <mutex>
using namespace std;
class A {
public:
void inMsgRecvQueue()
{
for (int i = 0; i < 100000; ++i)
{
cout << "Interpolate Interpolate Interpolate Interpolate Interpolate Interpolate Interpolate Insert an element" << i << endl;
{
//lock_guard<mutex> sbguard(myMutex1, adopt_lock);
lock(myMutex1, myMutex2);
//myMutex2.lock();
//myMutex1.lock();
msgRecvQueue.push_back(i);
myMutex1.unlock();
myMutex2.unlock();
}
}
}
bool outMsgLULProc()
{
myMutex1.lock();
myMutex2.lock();
if (!msgRecvQueue.empty())
{
cout << "Delete Delete Delete Delete Delete Delete Delete Delete Delete Delete Delete Delete Delete Elements" << msgRecvQueue.front() << endl;
msgRecvQueue.pop_front();
myMutex2.unlock();
myMutex1.unlock();
return true;
}
myMutex2.unlock();
myMutex1.unlock();
return false;
}
void outMsgRecvQueue()
{
for (int i = 0; i < 100000; ++i)
{
if (outMsgLULProc())
{
}
else
{
cout << "Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Empty Array is empty" << endl;
}
}
}
private:
list<int> msgRecvQueue;
mutex myMutex1;
mutex myMutex2;
};
int main()
{
A myobja;
mutex myMutex;
thread myOutMsgObj(&A::outMsgRecvQueue, &myobja);
thread myInMsgObj(&A::inMsgRecvQueue, &myobja);
myOutMsgObj.join();
myInMsgObj.join();
return 0;
}
Summary: std::lock() locks multiple mutexes at once; Use caution (suggest a lock)
6. unique_lock Details

1.unique_lock instead of lock_guard
- unique_lock is a class template, more than lock_guard is much more flexible (many uses) and less efficient. General lock_in work Guard (recommended)
- unique_lock<mutex> myUniLock(myMutex);
2.unique_ Second parameter of lock
2.1 std::adopt_lock:
- Indicates that the mutex has been locked (), that is, it does not need to lock in the constructor.
- Prerequisite: Mutex must be lock ed in advance
- Lock_ This parameter can also be used in guard:
std::lock_guard<std::mutex> sbguard1(my_mutex1, std::adopt_lock);
2.2 std::try_to_lock:
- Try to lock the mutex with the mutex lock(), but if the lock is not successful, it will return immediately without blocking there;
- Use try_ To_ The reason for lock is to prevent other threads from locking mutex for too long, causing this thread to block at lock
- Prerequisite: cannot lock();
- Owns_ The locks() method determines if a lock has been acquired, and if so returns true
std::unique_lock<std::mutex> sbguard1(my_mutex1, std::try_to_lock);
if (sbguard1.owns_lock())
{
// Lock taken
......
}
else
{
// No Lock Acquired
......
}
2.3 std::defer_lock:
- Lock mutex without a second parameter, plus defer_lock initiated a mutex without a lock
- The purpose of not locking it is to call unique_later Some methods of lock
- Prerequisite: cannot lock in advance
3.unique_ Member functions of lock (the first three used in conjunction with std::defer_lock)
3.1 lock(): Lock.
std::unique_lock<std::mutex> myUniLock(myMutex, std::defer_lock); myUniLock.lock();
Do not use your own unlock();
3.2 unlock(): Unlock.
Although the unlock can be automatically unlocked, the unlock function is provided since there is a lock function, but because it is unique_lock, if it's just a simple lock and then unlock, the program will be very unstable, and it should end up with lock and still let unique_lock to process. Actual uses are as follows:
unique_lock<mutex> myUniLock(myMutex, defer_lock); myUniLock.lock(); //Handle some shared code myUniLock.unlock(); //Handle some unshared code myUniLock.lock(); //Handle some shared code
Because some unshared code needs to be processed, you can temporarily unlock(), process it with another thread, and lock() after processing.
3.3 try_lock(): Attempts to lock mutexes
Return false if the lock is not reached or true otherwise. This function is non-blocking.
std::unique_lock<std::mutex> myUniLock(myMutex, std::defer_lock);
if (myUniLock.try_lock() == true) // Returning true means the lock is taken
{
...
}
else
{
...
}
3.4 release():
- unique_lock<mutex> myUniLock(myMutex);
Equivalent to binding myMutex and myUniLock together, release() unbinds, returns a pointer to the mutex object it manages, and releases ownership - mutex* ptx = myUniLock.release();
Ownership is taken over by ptx, which needs to be unlocked later if the original mutex object handles the locked state. The original pointer (address) is returned.
unique_lock<mutex> myUniLock(myMutex); mutex* ptx = myUniLock.release(); ... ptx.unlock();
The fewer code snippets a lock has, the faster it will execute and the more efficient the entire program will be.
a. Few codes are locked, called fine-grained, and perform efficiently;
b. More code is locked, called coarse-grained and inefficient to execute;
Once the shared data has been processed, unlock it immediately and let the other threads get the lock.
4.unique_ Transfer of lock ownership
Unique_ Lock <mutex> myUniLock (myMutex); Binding myMutex to myUniLock means that myUniLock owns ownership of myMutex (ownership can be transferred, not copied)
- Use move transfer
- MyUniLock owns myMutex, and myUniLock can transfer its ownership of myMutex, but it cannot copy it.
- unique_lock<mutex> myUniLock2(std::move(myUniLock));
myUniLock2 now owns myMutex. - Supplementary, Reference: https://zh.cppreference.com/w/cpp/thread/unique_lock
unique_lock overloads operator=, I think it should be possible to transfer
- return a temporary variable in a function, or transfer
unique_lock<mutex> aFunction()
{
unique_lock<mutex> myUniLock(myMutex);
//Moving a constructor returns a local unique_from the function Lock object is possible
//Returning this local object causes the system to generate a temporary unique_lock object and call unique_lock's Moving Constructor
return myUniLock;
}
// You can then call it outside, where sbguard has ownership of myMutex
In fact, temporary objects generated during program execution are often used only to transfer data (for no other purpose) and are quickly destroyed. Therefore, when initializing a new object with a temporary object, we can transfer the memory resources pointed to by the pointer members it contains directly to the new object without having to make a new copy, which greatly improves the efficiency of initialization.
Reference resources: http://c.biancheng.net/view/7847.html
7. Single Design Mode Shared Data Analysis, Resolution, call_once

1. Design Mode
- The program is flexible and may be easy to maintain. Code written with the concept of design patterns is obscure, but it can be painful for others to take over and read the code.
- When dealing with very large projects, foreigners should summarize and organize the experience of project development and module division into design modes.
- When the design mode of China in the past few years started to fire, I always liked to take a design mode and put it on top. As a result, a small project always needs to add several design modes, which end up upside down
- The design mode has its unique advantages, to learn and use actively, not to be trapped in it, to carry the hard case by hand
2. Singleton design mode:
Throughout the project, there is one or some special class that can only create one object belonging to that class.
Singleton class: Only one object can be generated.
Read-only data (not write) does not require a lock. If the singleton class is created only in the main function, then the other threads are read-only, that's fine.
Problem introduction:
Singleton class:
class Singleton
{
public:
static Singleton * getInstance() {
if (instance == NULL) {
instance = new Singleton;
}
return instance;
}
private:
Singleton() {}
static Singleton *instance;
};
Singleton * Singleton::instance = NULL;
Thread entry function:
void mythread()
{
...
Singleton* singleton = Singleton::getInstance();
...
}
Conflicts arise when multiple threads call the thread entry function at the same time, possibly to execute the single initialization line at the same time:
std::thread mytobj1(mythread);
std::thread mytobj2(mythread);
mytobj1.join();
mytobj1.join();
3. Analysis and Solution of Shared Data for Single Case Design Patterns
Problem: You need to create objects of a singleton class in a thread you create yourself, which may have more than one thread. We may face the need for mutually exclusive member functions like GetInstance().
M_can be determined before locking Whether instances are empty (double locking, or double checking), or if Singleton::getInstance() is locked each time it is called, efficiency is greatly affected. (Because locking is actually a fear that when a single new initialization occurs, multiple threads run here, which simply avoids initialization errors)
#include <iostream>
#include <mutex>
using namespace std;
mutex myMutex;
//Lazy Man Mode
class Singleton
{
public:
static Singleton * getInstance() {
//Double lock for efficiency
if (instance == NULL) {
lock_guard<mutex> myLockGua(myMutex);
if (instance == NULL) {
instance = new Singleton;
}
}
return instance;
}
private:
Singleton() {}
static Singleton *instance;
};
Singleton * Singleton::instance = NULL;
//Hungry Han Mode
class Singleton2 {
public:
static Singleton2* getInstance() {
return instance;
}
private:
Singleton2() {}
static Singleton2 * instance;
};
Singleton2 * Singleton2::instance = new Singleton2;
int main(void)
{
Singleton * singer = Singleton::getInstance();
Singleton * singer2 = Singleton::getInstance();
if (singer == singer2)
cout << "Both are the same instance" << endl;
else
cout << "They are not the same instance" << endl;
cout << "---------- Here is the Hungry Han Style ------------" << endl;
Singleton2 * singer3 = Singleton2::getInstance();
Singleton2 * singer4 = Singleton2::getInstance();
if (singer3 == singer4)
cout << "Both are the same instance" << endl;
else
cout << "They are not the same instance" << endl;
return 0;
}
It is unreasonable to think that an object is new in the singleton mode without deleting it yourself. You can add a class CGarhuishou in a class and create a static CGarhuishou object when a new single class. This will call the destructor of CGarhuishou at the end of the program, releasing the new singleton object.
class Singelton
{
public:
static Singleton * getInstance() {
if (instance == NULL) {
static CGarhuishou huishou;
instance = new Singelton;
}
return instance;
}
class CGarhuishou {
public:
~CGarhuishou()
{
if (Singleton::instance)
{
delete Singleton::instance;
Singleton::instance = NULL;
}
}
};
private:
Singleton() {}
static Singleton *instance;
};
Singleton * Singleton::instance = NULL;
4.std::call_once():
A function template whose first parameter is a tag and the second parameter is a function name (such as a()).
Function: Enables function a() to be called only once. It has the ability to mutex and consumes less resources and is more efficient than mutex.
call_once() needs to be used in conjunction with a tag named std::once_flag; Actually once_flag is a structure, call_once() is a token that determines whether a function is executed or not. Once the call is successful, the token is set to a called state.
When multiple threads execute simultaneously, one thread waits for another thread to execute first.
once_flag g_flag;
class Singleton
{
public:
static void CreateInstance()//call_once guarantees that it is called only once
{
instance = new Singleton;
}
//Two threads are executing here at the same time, one waiting for another to finish executing
static Singleton * getInstance() {
call_once(g_flag, CreateInstance);
return instance;
}
private:
Singleton() {}
static Singleton *instance;
};
Singleton * Singleton::instance = NULL;
Last suggestion:
Or create a singleton object first in the main thread, read-only singletons in the child thread, and avoid creating singletons in the child thread.
8. condition_variable,wait,notify_one,notify_all

1. Conditional variable condition_variable, wait, notify_one, notify_all
std::condition_variable is actually a class, a condition-related class, which simply waits for a condition to be reached.
std::mutex mymutex1;
std::unique_lock<std::mutex> sbguard1(mymutex1);
std::condition_variable condition;
condition.wait(sbguard1, [this] {if (!msgRecvQueue.empty())
return true;
return false;
});
condition.wait(sbguard1);
wait() is used to wait for something
First wait
If the lambda expression for the second parameter returns false, wait() unlocks the mutex and blocks the line
If the lambda expression for the second parameter returns true, wait() returns directly and continues execution.
When will the blockage end? Blocking to another thread to call notify_ Until one() member function;
If there is no second parameter, the effect is the same as if the second parameter lambda expression returned false
wait() unlocks the mutex and blocks it on this line, blocking it from another thread to call notify_ Until one() member function.
When other threads use notify_ Once one () wakes up this thread wait(), the wait is restored:
1. wait() keeps trying to acquire mutex locks. If it cannot, the process gets stuck here waiting for acquisition. If it does, wait() continues to execute and acquires locks (equal to being locked).
2.1. If wait has a second parameter, judge the lambda expression.
- a) If the expression is false, wait unlocks the mutex, then hibernates, waiting to be notify_again One() wake up
- b) If the lambda expression is true, wait returns and the process can continue (at which point the mutex is locked).
2.2. If wait does not have a second parameter, wait returns and the process proceeds.
As soon as the process reaches below wait(), the mutex must be locked.
#include <thread>
#include <iostream>
#include <list>
#include <mutex>
using namespace std;
class A {
public:
void inMsgRecvQueue() {
for (int i = 0; i < 100000; ++i)
{
cout << "inMsgRecvQueue Insert an element" << i << endl;
std::unique_lock<std::mutex> sbguard1(mymutex1);
msgRecvQueue.push_back(i);
//Try waking up the wait() thread and executing the line.
//Then the wait in outMsgRecvQueue() will wake up
//Notfy_only when another thread is executing wait() One() will work, otherwise it will not work
condition.notify_one();
}
}
void outMsgRecvQueue() {
int command = 0;
while (true) {
std::unique_lock<std::mutex> sbguard2(mymutex1);
// wait() is used to wait for something
// If the lambda expression for the second parameter returns false, wait() unlocks the mutex and blocks the line
// When will the blockage end? Blocking to another thread to call notify_ Until one() member function;
//When wait() is notify_ When one() is activated, its condition is executed to determine if the expression is true.
//If true, continue execution
condition.wait(sbguard2, [this] {
if (!msgRecvQueue.empty())
return true;
return false;});
command = msgRecvQueue.front();
msgRecvQueue.pop_front();
//Because unique_lock flexibility, we can unlock at any time to avoid locking for too long
sbguard2.unlock();
cout << "outMsgRecvQueue()Execute, take out the first element" << endl;
}
}
private:
std::list<int> msgRecvQueue;
std::mutex mymutex1;
std::condition_variable condition;
};
int main() {
A myobja;
std::thread myoutobj(&A::outMsgRecvQueue, &myobja);
std::thread myinobj(&A::inMsgRecvQueue, &myobja);
myinobj.join();
myoutobj.join();
}
But one minor problem with the above code is that
2. Deep thinking
There are some problems with the code above:
Question 1: InMsgRecvQueue is a 100,000 cycle, while outMsgRecvQueue is a dead cycle; When the inMsgRecvQueue loop ends, notify_is no longer called One, then outMsgRecvQueue will always be stuck in the wait function. Note in the actual project.
Question 2: Possible, notify_in inMsgRecvQueue One acquires the lock immediately afterwards, so outMsgRecvQueue may acquire the lock hundreds of times. That is, outMsgRecvQueue() and inMsgRecvQueue() are not executed one-to-one, so when a program loop is executed many times, there may already be many messages in msgRecvQueue, but outMsgRecvQueue is still awakened to process only one data at a time. Consider executing outMsgRecvQueue a few more times or limiting inMsgRecvQueue.
Question 3: notify_one may also have no effect, such as code that gets locked after wait and executes after it, or code that is not stuck on the wait line before wait, then notify_of other threads will appear One doesn't work.
3. notify_all()
notify_one(): Notify a thread of wait()
notify_all(): Notify all threads of wait()
9. async,future,packaged_task,promise

This section needs to contain a header file #include <future>
1. std::async, std::future Create background tasks and return values
std::async is a function template used to start an asynchronous task. After starting an asynchronous task, it returns an std::future object, which is a class template.
What is Start an Asynchronous Task? This is to automatically create a thread and start executing the corresponding thread entry function, which returns an std::future object that contains the result returned by the thread entry function (the result returned by the thread), and we can get the result by calling the member function get() of the future object.
In the future, it's also known as std::future provides a mechanism for accessing the results of asynchronous operations, which means you may not get the results right away, but in the near future, when this thread finishes executing, you will get the results, so it's understood that a value is stored in future. This value will be available sometime in the future.
Std:: The get() member function of the future object waits for the thread to execute and return the result. If it doesn't get the result, it waits all the time, feeling a bit like join(). However, it is achievable. (Only one call, multiple calls will result in an exception)
Std:: The wait() member function of the future object, which waits for the thread to return, does not return the result itself, much like the join() of std::thread s.
#include <iostream>
#include <future>
using namespace std;
class A {
public:
int mythread(int mypar) {
cout << mypar << endl;
return mypar;
}
};
int mythread() {
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
return 5;
}
int main() {
A a;
int tmp = 12;
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
std::future<int> result1 = std::async(mythread);
cout << "continue........" << endl;
cout << result1.get() << endl; //Card here waiting for mythread() to finish executing and get results
//Class member function
std::future<int> result2 = std::async(&A::mythread, &a, tmp); //The second parameter is the object reference to ensure that the same object is executed in the thread
cout << result2.get() << endl;
//Or result2.wait();
cout << "good luck" << endl;
return 0;
}
If you use async, it looks like creating threads to pass parameters to a member function of a class is similar to normal threads:
class A,There are member functions: int mythread(int mypar); main Use async Create asynchronous threads: A a; int tmppar = 12; std::future<int> result = std::async(&A::mythread, &a, tmppar); // The second parameter uses & guarantees the same object a
It is recommended that get be used to ensure that thread execution is complete.
We achieve some special purposes by passing a parameter to std::async(), which is the std::launch type (enumeration type):
Reference:
https://zh.cppreference.com/w/cpp/thread/launch
https://zh.cppreference.com/w/cpp/thread/async
1,std::launch::deferred:
(defer defer, defer) means that the call to the thread entry function will be deferred until std:: wait() of the future or get() function is called (called by the main thread); If wait() or get() is not called, it will not execute. There is no new thread created at all.
std::launch::deferred means deferred invocation, does not create a new thread, is a thread entry function called in the main thread.
#include <iostream>
#include <future>
using namespace std;
int mythread() {
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
return 5;
}
int main() {
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
std::future<int> result1 = std::async(std::launch::deferred ,mythread);
cout << "continue........" << endl;
cout << result1.get() << endl; //Card here waiting for mythread() to finish executing and get results
cout << "good luck" << endl;
return 0;
}
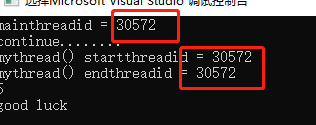
You will always print continue... before printing information such as mythread() start and mythread() end.
2. std::launch::async, start creating a new thread when the async function is called.
int main() {
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
std::future<int> result1 = std::async(std::launch::async ,mythread);
cout << "continue........" << endl;
cout << result1.get() << endl;
cout << "good luck" << endl;
return 0;
}
std::async's default launch policy allows tasks to execute asynchronously and synchronously. That is, the following two are identical:
auto fut1 = std::async(f); // Execute f using default launch policy
auto fut2 = std::async(std::launch::async | // Execute f using async or deferred
std::launch::deferred,
f);
Based on the official documentation for the parameter std::lunch::deferred | std::launch::async is the implementation of the system and library, which strategy to choose is usually optimized for the current concurrent availability in the system.
If you want to ensure that a new thread will be born, you should use std::launch::async
2. std::packaged_task: Package tasks and wrap them up.
Class template whose template parameters are various callable objects via packaged_task wraps various callable objects for future calls as thread entry functions.
#include <thread>
#include <iostream>
#include <future>
using namespace std;
int mythread(int mypar) {
cout << mypar << endl;
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
return 5;
}
int main() {
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
//We pass the function mythread through packaged_ Wrap up task
//The parameter is an int and the return value type is int in the form of a return value (parameter)
std::packaged_task<int(int)> mypt(mythread);
//Thread executes directly, with the second parameter as a parameter to the thread entry function
std::thread t1(std::ref(mypt), 1);
t1.join();
//Std:: The future object contains the result returned by the thread entry function, where result holds the result returned by mythread s.
std::future<int> result = mypt.get_future();
cout << result.get() << endl;
return 0;
}
Callable objects can be replaced by functions with lambda expressions:
int main() {
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
std::packaged_task<int(int)> mypt([](int mypar) {
cout << mypar << endl;
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
return 5;
});
std::thread t1(std::ref(mypt), 1);
t1.join();
std::future<int> result = mypt.get_future();
//Std:: The future object contains the result returned by the thread entry function, where result holds the result returned by mythread s.
cout << result.get() << endl;
cout << "good luck" << endl;
return 0;
}
packaged_task wrapped callable objects can also be called directly, in this sense, packaged_ The task object is also a callable object
Direct calls to lambda:
int main() {
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
std::packaged_task<int(int)> mypt([](int mypar) {
cout << mypar << endl;
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
return 5;
});
mypt(1);
std::future<int> result = mypt.get_future();
cout << result.get() << endl;
}
It can also be packaged in a container:
vector <std::packaged_task<int(int)>> mytasks; mytasks.push_back(std::move(mypt)); // ... std::packaged_task<int(int)> mypt2; auto iter = mytasks.begin(); mypt2 = std::move(*iter); // Moving Semantics mytasks.erase(iter); // Delete the first element, the iterator is no longer valid, so iter is no longer available for subsequent code mypt2(123); std::future<int> result = mypt2.get_future(); cout << result.get() << endl;
3. std::promise
We can assign a value to one thread, and then we can take it out and use it in other threads:
#include <thread>
#include <iostream>
#include <future>
using namespace std;
void mythread(std::promise<int> &tmp, int clac) {
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
int result = clac;
tmp.set_value(result); //The result is saved to the tmp object
return;
}
vector<std::packaged_task<int(int)>> task_vec;
int main() {
std::promise<int> myprom;
std::thread t1(mythread, std::ref(myprom), 180);
t1.join(); //Here the thread has finished executing
std::future<int> fu1 = myprom.get_future(); //promise and future bindings to get thread return values
auto result = fu1.get();
cout << "result = " << result << endl;
}
Summary: Save a value with promise, and at some point in the future we get the bound value by binding a future to this promise
And promise is not replicable, requiring:
std::promise<int> p; std::promise<int> p2 = std::move(p);
Note: When using thread s, you must join() or detach() or the program will report an exception. We used async before to create without joins or detaches
Summary:
The purpose of learning these things is not to use them in actual development.
Conversely, it would be more appreciated if we could write a stable, efficient multithreaded program with the least amount of stuff.
We have to read some handwritten code to grow up in order to accumulate our own code.
Supplement: 7_for C++ Concurrent Programming Future, Promise and async ()
Reference resources: https://www.bilibili.com/video/BV1d54y1Y7fv
Scene, a simple factorial program:
#include <iostream>
#include <thread>
using namespace std;
void factorial(int N)
{
int res = 1;
for (int i = N; i > 1; i--)
{
res *= i;
}
cout << "Result is: " << res << endl;
}
int main()
{
int x;
thread t1(factorial, 4);
t1.join();
return 0;
}
If we want to get results to use, this is probably the case:
#include <iostream>
#include <thread>
using namespace std;
void factorial(int N, int& x)
{
int res = 1;
for (int i = N; i > 1; i--)
{
res *= i;
}
cout << "Result is: " << res << endl;
x = res;
}
int main()
{
int x;
thread t1(factorial, 4, std::ref(x));
t1.join();
return 0;
}
So x is the shared data for the main thread and the child thread t1, and we might use mutex; Or we want to wake up under certain conditions, which in turn introduces condition_variable, followed by wait and notify_for condition Like one, the code becomes very complex.
Here you can use async, future, promise to simplify:
#include <iostream>
#include <future>
using namespace std;
int factorial(int N)
{
int res = 1;
for (int i = N; i > 1; i--)
{
res *= i;
}
cout << "Result is: " << res << endl;
return res;
}
int main()
{
int x;
future<int> fu = async(std::launch::async, factorial, 4);
x = fu.get();
return 0;
}
This implements that child threads pass data to parent threads, and future s can do the opposite, passing data from parent threads to child threads:
#include <iostream>
#include <future>
int factorial(std::future<int>& f)
{
int res = 1;
int N = f.get();
for (int i = N; i > 1; i--)
{
res *= i;
}
std::cout << "Result is: " << res << std::endl;
return res;
}
int main()
{
int x;
std::promise<int> p;
std::future<int> f = p.get_future();
std::future<int> fu = std::async(std::launch::async, factorial, std::ref(f));
// do something else
std::this_thread::sleep_for(std::chrono::milliseconds(20));
p.set_value(4);
x = fu.get();
std::cout << "Get from child: " << x << std::endl;
return 0;
}
By doing so, we are telling the child thread that I will send him a value, but I don't have that value yet, so I will send it to him in the future. This is my promise. Just do whatever you want to do in the child thread.
This is done by p.set_value(4); If you keep your promise and break it if you don't use it, you will get an exception: std::future_errc::broken_promise
If you are sure you want to break your promise, you can use set_exception:
std::promise<int> p;
......
p.set_exception(std::make_exception_ptr(std::runtime_error("To err is human")));
If we want to create multiple async asynchronous threads, and we know that each future can only get once, if we have ten asynchronous threads, if we create ten futures and ten promise, it's ugly, and share_appears Future:
#include <iostream>
#include <future>
int factorial(std::shared_future<int> f)
{
int res = 1;
int N = f.get();
for (int i = N; i > 1; i--)
{
res *= i;
}
std::cout << "Result is: " << res << std::endl;
return res;
}
int main()
{
int x;
std::promise<int> p;
std::future<int> f = p.get_future();
std::shared_future<int> sf = f.share();
std::future<int> fu = std::async(std::launch::async, factorial, sf);
std::future<int> fu2 = std::async(std::launch::async, factorial, sf);
std::future<int> fu3 = std::async(std::launch::async, factorial, sf);
p.set_value(4);
x = fu.get();
std::cout << "Get from child: " << x << std::endl;
return 0;
}
shared_future can be used without reference, as opposed to the previous:
std::future fu = std::async(std::launch::async, factorial, std::ref(f));
std::future fu = std::async(std::launch::async, factorial, sf);
10. future other member functions, shared_future, atomic

1. member functions of std::future
1. std::future_ Status status = result.wait_ For (std:: chrono:: seconds);
Hold the current process and wait for the asynchronous task std::async() to run for some time before returning its status std::future_status. If the parameter of std::async() is std::launch::deferred (delayed execution), the main process will not get stuck.
std::future_status is an enumeration type that represents the execution state of an asynchronous task. Type values are
std::future_status::timeout
std::future_status::ready
std::future_status::deferred
#include <iostream>
#include <future>
using namespace std;
int mythread() {
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
//std::chrono::milliseconds dura(5000);
//std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
return 5;
}
int main() {
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
std::future<int> result = std::async(std::launch::deferred, mythread);
//std::future<int> result = std::async(mythread);
cout << "continue........" << endl;
//Cout << result1.get() << endl; // Card here waiting for mythread() to finish executing and get results
std::future_status status = result.wait_for(std::chrono::seconds(6));
if (status == std::future_status::timeout) {
//Timeout: Indicates that the thread has not finished executing
cout << "Timed out, the thread has not finished executing" << endl;
}
else if (status == std::future_status::ready) {
//Indicates that the thread returned successfully
cout << "Thread executes successfully, returns" << endl;
cout << result.get() << endl;
}
else if (status == std::future_status::deferred) {
//If you set std::future<int> result = std::async (std::launch::deferred, mythread);, Then this condition is true
cout << "Thread Delayed Execution" << endl;
cout << result.get() << endl;
}
cout << "good luck" << endl;
return 0;
}
Get() can only be used once, because the get() function is designed with a mobility semantics, which is equivalent to moving a value from a result to an exception that is reported by get again.
2. std::shared_future: is also a class template
Std:: get() member function of future is to transfer data
Std::shared_ get() member function of future is to copy data
#include <thread>
#include <iostream>
#include <future>
using namespace std;
int mythread() {
cout << "mythread() start" << "threadid = " << std::this_thread::get_id() << endl;
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
cout << "mythread() end" << "threadid = " << std::this_thread::get_id() << endl;
return 5;
}
int main() {
cout << "main" << "threadid = " << std::this_thread::get_id() << endl;
std::packaged_task<int()> mypt(mythread);
std::thread t1(std::ref(mypt));
std::future<int> result = mypt.get_future();
bool ifcanget = result.valid(); //Determine if the value in the future is a valid value
std::shared_future<int> result_s(result.share()); //Result_after execution S has a value, but result is empty
//std::shared_future<int> result_s(std::move(result));
//By get_future return value constructs a shared_directly Future object
//std::shared_future<int> result_s(mypt.get_future());
t1.join();
auto myresult1 = result_s.get();
auto myresult2 = result_s.get();
cout << "good luck" << endl;
return 0;
}
3. std::atomic atomic operation
3.1 The concept of atomic operation leads to examples:
Mutex: Used in multithreaded programming to protect shared data: lock first, operate on shared data, unlock.
There are two threads that operate on a variable, one that reads the value of the variable, and one that writes the value to the variable.
Even if a simple variable is read and written, unlocking can lead to confusion in read and write values (a C statement can be split into 3 or 4 assembly statements to execute, so confusion can still occur).
3.2 Basic std::atomic usage examples
Atomic operations can be understood as a multithreaded concurrent programming method that does not require mutex locking (unlock-free) technology.
Atomic operation: A program execution fragment that is not interrupted in a multithreaded program.
In terms of efficiency, atoms operate more efficiently than mutexes.
Mutex locking is generally for a code snippet, while atomic operations are generally for a variable.
Atomic operations are generally referred to as "indivisible operations"; That is to say, this operation state is either complete or incomplete, and it is impossible to have a semi-complete state.
std::atomic is a class template to represent atomic operations. In fact, std::atomic is used to encapsulate a certain type of value
Need to add #include <atomic>header file
Example 1:
#include <iostream>
#include <thread>
#include <atomic>
using namespace std;
std::atomic<int> g_count = 0; //Encapsulates an object of type int (value)
void mythread1() {
for (int i = 0; i < 1000000; i++) {
g_count++;
}
}
int main() {
std::thread t1(mythread1);
std::thread t2(mythread1);
t1.join();
t2.join();
cout << "Normally the result should be 200,000,000 times. Actually," << g_count << endl;
}
Example 2:
#include <iostream>
#include <thread>
#include <atomic>
using namespace std;
std::atomic<bool> g_ifEnd = false; //Encapsulates an object of type bool (value)
void mythread() {
std::chrono::milliseconds dura(1000);
while (g_ifEnd == false) {
cout << "thread id = " << std::this_thread::get_id() << "Running" << endl;
std::this_thread::sleep_for(dura);
}
cout << "thread id = " << std::this_thread::get_id() << "End of run" << endl;
}
int main() {
std::thread t1(mythread);
std::thread t2(mythread);
std::chrono::milliseconds dura(5000);
std::this_thread::sleep_for(dura);
g_ifEnd = true;
cout << "Program Execution Completed" << endl;
t1.join();
t2.join();
}
Summary:
1. Atomic operations are generally used for counting or statistics (e.g., how many packets are sent and how many packets are received) and are counted together by multiple threads, which can lead to confusion if atomic operations are not used.
2. When writing business code, if you are not sure about the impact of the results, it is best to write a small piece of code debugging yourself first. Or don't use it.
11. std::atomic renewal, std::async in-depth discussion

1. std::atomic renewal
#include <iostream>
#include <thread>
#include <atomic>
using namespace std;
std::atomic<int> g_count = 0; //Encapsulates an object of type int (value)
void mythread1() {
for (int i = 0; i < 1000000; i++) {
//Although g_count uses an atomic operation template, but this writing is both read and written.
//Causes a count error
g_count = g_count + 1;
}
}
int main() {
std::thread t1(mythread1);
std::thread t2(mythread1);
t1.join();
t2.join();
cout << "Normally the result should be 200,000,000 times. Actually," << g_count << endl;
}
atomic operations in general are supported for ++, -, +=, -=, &=, |=, ^=, other operations are not necessarily supported.
2. std:: an in-depth understanding of Async
2.1 std::async parameter details, which async uses to create an asynchronous task
Delayed invocation parameters std::launch::deferred [Delayed invocation], std::launch::async [Force the creation of a thread]
std::async() We don't usually call creating a thread (he can create a thread), we usually call it creating an asynchronous task.
The most obvious difference between std::async and std:: threads is that async sometimes does not create new threads.
(1) If async is called with std::launch::deferred?
Delay until get() or wait() is called, otherwise it will not execute
(2) If you call async with std::launch::async?
Force this asynchronous task to execute on a new thread, which means that the system must create a new thread to run the entry function.
(3) If std::launch::async | std::launch::deferred is also used
This | here means that the behavior of async may be std::launch::async creates a new thread for immediate execution, or std::launch::deferred does not create a new thread and delays execution until get() is called. It is up to the system to decide which scenario to take based on the actual situation
(4) Without additional parameter std::async(mythread), only one entry function name is given to async. At this time, the default value given by the system is std::launch::async | std::launch::deferred and (3) the system decides whether to run asynchronously or synchronously on its own.
2.2 std::async and std::thread() Differences:
std::thread() If system resources are tight, the creation of threads may fail. If the creation of threads fails, the program may crash and it is not easy to get the function return value (not impossible).
std::async() creates an asynchronous task. Threads may or may not be created, and it is easy to get the return value of the thread entry function;
Due to system resource constraints:
(1) If too many threads are created with std::thread s, the creation may fail, the system reports exceptions, and crashes.
(2) If you use std::async, you will not normally report an exception, because if system resources are tight and a new thread cannot be created, the way async is called without additional parameters will not create a new thread. Instead, it executes on the thread where get() is called subsequently to request the result.
If you force async to create a new thread, use the std::launch::async tag. The cost is that the system may crash when resources are tight.
(3) According to experience, the number of threads in a program should not exceed 100-200.
2.3 Solution of Async Uncertainty
async calls with no additional parameters let the system decide whether to create a new thread or not.
std::future<int> result = std::async(mythread);
The question is whether the task has been postponed or not.
By wait_for returns the status to judge:
std::future_status status = result.wait_for(std::chrono::seconds(6));
//std::future_status status = result.wait_for(6s);
if (status == std::future_status::timeout) {
//Timeout: Indicates that the thread has not finished executing
cout << "Timed out, the thread has not finished executing" << endl;
}
else if (status == std::future_status::ready) {
//Indicates that the thread was successfully placed back
cout << "Thread executes successfully, returns" << endl;
cout << result.get() << endl;
}
else if (status == std::future_status::deferred) {
cout << "Thread Delayed Execution" << endl;
cout << result.get() << endl;
}
12. windows critical zone, various other mutex mutex exclusions

1 and 2. windows critical zone
In a Windows critical zone, the same thread can enter repeatedly, but the number of times it enters must be equal to the number of times it leaves.
C++ mutexes do not allow the same thread to repeatedly lock.
The windows critical zone is the content of windows programming. Just know it, the effect is almost equal to the mutex of c++11
Include #include <windows.h>
A critical zone in windows, like mutex, protects a code snippet. However, the critical zone of windows can enter and leave multiple times, but the number of times must be equal to the number of times left, which will not cause the program to report abnormal errors.
#include <iostream>
#include <thread>
#include <list>
#include <mutex>
#include <Windows.h>
#define __WINDOWSJQ_
using namespace std;
class A
{
public:
// Queue incoming messages
void inMsgRecvQueue()
{
for (size_t i = 0; i < 1000; ++i)
{
cout << "Receive the message and queue it " << i << endl;
#ifdef __WINDOWSJQ_
EnterCriticalSection(&my_winsec); // Enter critical zone
//EnterCriticalSection (&my_winsec); // Can enter the critical zone again, program will not error
msgRecvQueue.push_back(i);
LeaveCriticalSection(&my_winsec); // Leave critical zone
//LeaveCriticalSection (&my_winsec); // If you enter twice, you must leave twice without error
#elif
my_mutex.lock();
msgRecvQueue.push_back(i);
my_mutex.unlock();
#endif // __WINDOWSJQ_
}
cout << "Message Entry End" << endl;
}
// Remove message from queue
void outMsgRecvQueue()
{
for (size_t i = 0; i < 1000; ++i)
{
#ifdef __WINDOWSJQ_
EnterCriticalSection(&my_winsec); // Enter critical zone
if (!msgRecvQueue.empty())
{
// Queue is not empty
int num = msgRecvQueue.front();
cout << "Remove from message queue " << num << endl;
msgRecvQueue.pop_front();
}
else
{
// Message queue is empty
cout << "Message queue is empty " << endl;
}
LeaveCriticalSection(&my_winsec); // Leave critical zone
#elif
my_mutex.lock();
if (!msgRecvQueue.empty())
{
// Queue is not empty
int num = msgRecvQueue.front();
cout << "Remove from message queue " << num << endl;
msgRecvQueue.pop_front();
my_mutex.unlock();
}
else
{
// Message queue is empty
cout << "Message queue is empty " << endl;
my_mutex.unlock();
}
#endif // __WINDOWSJQ_
}
cout << "Message Queue End" << endl;
}
A()
{
#ifdef __WINDOWSJQ_
InitializeCriticalSection(&my_winsec); // Initialize before using critical zone
#endif // __WINDOWSJQ_
}
private:
list<int> msgRecvQueue;
mutex my_mutex;
#ifdef __WINDOWSJQ_
CRITICAL_SECTION my_winsec; // The critical zone in windows, very similar to mutex in C++11
#endif // __WINDOWSJQ_
};
int main()
{
A myobj;
thread myInMsgObj(&A::inMsgRecvQueue, &myobj);
thread myOutMsgObj(&A::outMsgRecvQueue, &myobj);
myInMsgObj.join();
myOutMsgObj.join();
getchar();
return 0;
}
Here you enter the critical zone twice and go out twice. Windows is possible. Entering the critical zone is equivalent to locking, leaving the critical zone is equivalent to unlocking. For example, scenarios: when fun1 and fun2 are written, they need to be unlocked. If you call fun2 in fun1 one day, the normal mutex will crash because of two locks. However, recursiv_can be derived Mutex, recursive exclusive mutex, see point 4.
3. Auto-destructive Technology
C++:lock_guard prevents forgetting to release the semaphore and releases it automatically
windows: You can write a class auto-release critical zone:
class CWinLock {
public:
CWinLock(CRITICAL_SECTION *pCritmp)
{
my_winsec =pCritmp;
EnterCriticalSection(my_winsec);
}
~CWinLock()
{
LeaveCriticalSection(my_winsec)
};
private:
CRITICAL_SECTION *my_winsec;
};
The above RAII class (Resource Acquisition is initialization) is resource acquisition and initialization. Containers, smart pointers belong to this class.
4. Recursive Exclusive Mutex std::recursive_mutex
std::mutex exclusive mutex
std::recursive_mutex: Allows the same mutex to be locked () multiple times in the same thread (but the number of recursive locks is limited, too many may report exceptions), which is less efficient than mutex.
If you do use recursive_mutex considers whether there is optimization space in the code and does not call lock() multiple times if it can be called once.
5. Mutex std::timed_with timeout Mutex and std::recursive_timed_mutex
5.1 std::timed_mutex: is the exclusive mutex to be timed out
- try_lock_for():
Wait for a while, and if you get the lock, or if you timed out and don't get the lock, proceed (optionally) as follows:
std::chrono::milliseconds timeout(100);
if (my_mymutex.try_lock_for(timeout)){
//...get the lock and return to ture
}
else{
std::chrono::milliseconds sleeptime(100);
std::this_thread::sleep_for(sleeptime);
}
- try_lock_until():
Parameter is a future point in time, in the time not available in the future, if you get the lock, the process will step down, if the time has not been locked, the process can also step down.
std::chrono::milliseconds timeout(100);
if (my_mymutex.try_lock_until(chrono::steady_clock::now() + timeout)){
//...get the lock and return to ture
}
else{
std::chrono::milliseconds sleeptime(100);
std::this_thread::sleep_for(sleeptime);
}
The difference between the two is that one parameter is time period and the other is time point
5.2 std::recursive_timed_mutex: is a recursive exclusive mutex to be timed out
13. Supplementary knowledge and thread pool

1. Supplement some points of knowledge
1.1 False wake-up:
notify_one or notify_ After all wakes up wait(), some threads may actually not meet the wake-up conditions, causing false wakeups, which can be resolved by judging again in wait.
Solution: A second parameter (lambda) is required in the wait, and the lambda is used to correctly determine if the public data being processed exists.
2.2 atomic:
std::atomic<int> atm = 0; cout << atm << endl;
Here only reading atm is an atomic operation, but the entire line of code cout << atm << endl; It is not an atomic operation, resulting in a "once value" that is ultimately displayed on the screen.
std::atomic<int> atm = 0; auto atm2 = atm; //No, compilation will fail
This copy initialization is not possible and will result in an error.
atomic<int> atm2(atm.load());
load(): Atomically reads the value of an atomic object.
atm2.store(12);
Atomic operations essentially do not allow context switching of the CPU during atomic object operations.
2. Talking about thread pool:
Scenario scenario: Server programs create a new thread to service each client.
Question:
With 120,000 players, it is impossible to create a new thread for each player. This program does not work in this scenario.
2. Program stability issues: When writing code, a thread is created "suddenly from time to time". This way of writing, normally no errors are made, but it is unstable;
Thread pool: Get a bunch of threads together for unified management. This unified way of managing scheduling and recycling is called a thread pool.
How to do this: When the program starts, a certain number of threads are created at once. This is a more reassuring way to feel that the program code is more stable.
3. Talk about the number of threads created:
1. Thread creation limit
Generally speaking, 2000 threads are basically the limit; Create it again and it will crash.
2. Thread creation number recommendation
a. Follow the recommendations and instructions provided by some counting development programs to ensure their efficient execution.
b. Create multithreads to complete business; Considering the number of threads that may be blocked, it is appropriate to create an extra maximum number of blocked threads, such as 110 threads if 100 threads are blocked and refill the business
c. The number of threads created should not exceed 500 and should be kept within 200;