Theoretical knowledge
Finite state machine
Finite state machine is a tool for object behavior modeling. Its main function is to describe the state sequence experienced by an object in its life cycle and how to respond to various events from the outside world. Understanding finite state machine in simple terms
Memory model
C is divided into four areas: heap, stack, static global variable area and constant area C + + memory is divided into five areas (stack full normal generation): C/C + + memory model.
Light copy and deep copy
Shallow copy only copies a pointer without creating a new address. The copied pointer points to the same address as the original pointer. If the resource pointed to by the original pointer is released, an error will occur in releasing the resource of the shallow copy pointer. Deep copy opens up a new space for storing the copied values. When implementing copy assignment by yourself, if there is a pointer variable, you need to implement deep copy by yourself.
#include <iostream>
#include <string.h>
using namespace std;
class Student
{
private:
int num;
char *name;
public:
Student(){
name = new char(20);
cout << "Student constructor" << endl;
};
~Student(){
cout << "Student destructor " << &name << ", " << (int*)name << endl;
delete name;
name = NULL;
};
Student(const Student &s){//copy constructor
//Shallow copy, when the name of the object and the name of the incoming object point to the same address
// name = s.name;
//Deep copy
name = new char(20);
memcpy(name, s.name, strlen(s.name));
cout << "copy Student" << endl;
};
};
int main()
{
{// Curly braces make s1 and s2 local objects for easy testing
Student s1;
Student s2(s1);// copy object
}
system("pause");
return 0;
}
Shallow copy execution result: (note that name points to the same address and the destructor releases it twice)
Student constructor
copy Student
Student destructor 0x61fdf8, 0xf71750
Student destructor 0x61fe08, 0xf71750
Process returned -1073740940 (0xC0000374)
Execution result of deep copy:
Student constructor
copy Student
Student destructor 0x61fdf8, 0x1d1770
Student destructor 0x61fe08, 0x1d1750
Please press any key to continue
abnormal
The exception handling mechanism in C + + mainly uses three keywords: try, throw and catch. The program first executes the statement block wrapped by try. If no exception occurs during execution, it will not enter any statement block wrapped by catch. Otherwise, the exception can be thrown through throw and caught by catch.
#include <iostream>
using namespace std;
int main()
{
double m = 1, n = 0;
try {
cout << "before dividing." << endl;
if (n == 0)
throw - 1; //Throw int type exception
else if (m == 0)
throw - 1.0; //Throw a double exception
else
cout << m / n << endl;
cout << "after dividing." << endl;
}
catch (double d) {
cout << "catch (double)" << d << endl;
}
catch (...) {
cout << "catch (...)" << endl;
}
cout << "finished" << endl;
return 0;
}
//Operation results
//before dividing.
//catch (...)
//finished
Throw can throw information of various data types. The above code uses numbers, but you can also customize the exception class. Catch accurately captures the data type thrown by throw (without type conversion). If it fails to match, it will directly report an error. You can use catch(...) To catch any exceptions (not recommended). Of course, if an exception is caught in the catch, if the current function does not handle it, or if it has handled it and wants to notify the caller of the upper layer, you can throw the exception in the catch.
- Exception declaration list
When declaring and defining a function, indicate the list of exceptions that can be thrown (that is, indicate the types of exceptions that can be thrown).
int fun() throw(int,double,A,B,C){...};
In this way, the table name function may throw int,double or A, B and C exceptions. If the throw is empty, it indicates that no exception will be thrown. If there is no throw, it may throw any exception.
- exception
Some classes are derived from the exception class, such as:
bad_typeid: using the typeid operator, this exception will be thrown if its operand is a pointer to a polymorphic class and the value of the pointer is NULL.
bad_cast: dynamic in use_ Cast casts a cast from a polymorphic base class object (or reference) to a reference of a derived class, and throws this exception if the cast is unsafe
bad_alloc: this exception will be thrown if there is not enough memory during dynamic memory allocation with the new operator
out_of_range: when using the at member function of vector or string to access an element according to the subscript, this exception will be thrown if the subscript is out of bounds
Some keywords
const constant collapse
The memory allocation area of const constant is a very common stack or global area. In other words, const constant is only checked by the compiler during compilation, and there is no read only area at all. Constant folding in C + + (I) It is also compared with precompiled instructions (#define).
int main()
{
int i0 = 11;
const int i = 0; //Define constant i
int *j = (int *) &i; //See here, you can take value of i and judge the memory space after i is inevitable
*j = 1; //Modify the memory pointed to by j
printf("0x%p\n0x%p\n%d\n%d\n",&i,j,i,*j); //Watch the experimental results
// &i. The address of J is the same; i=0,(*j)=1
const int ck = 9; //This control experiment is to observe the effect of the reference to the constant ck
int ik = ck;
int i1 = 5; //This control experiment is to distinguish what is the difference between references to constants and variables
int i2 = i1;
return 0;
}
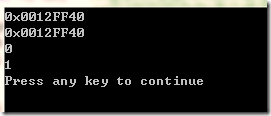
i is a collapsible constant. In the compilation stage, the reference to i has been replaced with the value of i. at the same time, unlike the macro replacement, this i is also stored in the constant table. At the same time, there is also the variable i in the constant table. Otherwise, it is illegal to take the address of i. This is different from macro replacement. Macro replacement will not put the macro name in the constant table and will not be used after precompiling. in other words:
printf("0x%p\n0x%p\n%d\n%d\n",&i,j,i,*j);
i in has been replaced in the preprocessing stage. In fact, it has been changed to:
printf("0x%p\n0x%p\n%d\n%d\n",&i,j,0,*j);
const modifier function (and mutable)
If you don't want a function to modify the value of a member variable, you can also declare this function as a const member function. This function is mainly to protect data members. Function of const in the middle of function
class A
{
public:
void area(int x,int y){length=x;width=y;}
void print(){cout<<"Multiply two numbers to:"<<length*width<<endl;}
private:
int length;
int width;
};
For the print() function, we found that its function is to print the product of length and width on the screen without modifying the values of the private variables length and width in class A. in view of this, we can modify the print() function into const member function, that is
void print()const{cout<<"Multiply two numbers to:"<<length*width<<endl;}
However, mutable is to break through the blockade of const. const member function and mutable keyword Variables modified by mutable will always be in a variable state. Even in a const function, even if the structure variable or class object is const, its mutable members can also be modified, so that some secondary or auxiliary member variables of the class can be changed at any time. The above can also be changed to:
class A
{
public:
void print() const {length *= 100; cout<<"Multiply two numbers to:"<<length*width<<endl;}
private:
mutable int length;
int width;
};
volatile
const constant pointer and pointer constant:
Const is read as a constant and * is read as a pointer. Const in the front * in the back, read along is the constant pointer, const in the back, * in the front is read as the pointer constant
The difference between constant pointer and pointer constant
When using the value of a variable declared by volatile, the system always re reads the data from its memory instead of reading the backup in the register. This is because variables declared with volatile may be changed by factors unknown to the compiler, such as operating system, hardware or other threads. Variables shared by several tasks in multithreading need to be defined as volatile type.
When both threads need to use a variable and the value of the variable will be changed, if the variable is loaded into the register, the two threads may use the variable in memory and the variable in the register, which will cause the wrong execution of the program. At this point, the volatile declaration should be used to prevent the optimization compiler from loading variables from memory into CPU registers. When a variable declared by this keyword is encountered, the compiler will no longer optimize the code accessing the variable, so as to provide stable access to special addresses.
Volatile pointer is similar to const modifier. Const has the expression of constant pointer and pointer constant, and volatile also has the corresponding concept.
The content pointed to by the modifier (object, data):
const char* cpch; volatile char* vpch;
Decorate the pointer itself
char* const pchc; char* volatile pchv;
volatile is similar to the well-known const and is also a type modifier. volatile is an instruction to the compiler that the object it modifies should not be optimized. volatile is used for multithreading programming. In single thread, it can only limit compiler optimization. Explain the role of volatile in C + +,Talk about the volatile keyword of C + + and common misunderstandings
You can assign a non volatile int to a volatile int, but you cannot assign a non volatile object to a volatile object.
In addition to basic types, user-defined types can also be decorated with volatile types.
?? In C + +, a class with volatile identifier can only access a subset of its interfaces, a subset controlled by the implementer of the class. Users can only use const_cast to get full access to the type interface. In addition, volatile, like const, is passed from the class to its members.
explicit keyword
First, the explicit keyword in C + + can only be used to modify a class constructor with only one parameter. Its function is to indicate that the constructor is explicit rather than implicit. Another keyword corresponding to it is implicit, which means hidden. The class constructor is declared implicit by default The explicit keyword is only valid for class constructors with one parameter. If the class constructor parameters are greater than or equal to two, there will be no implicit conversion, so the explicit keyword is invalid
class CxString // Class declarations that do not use the explicit keyword are implicitly declared
{
public:
char *_pstr;
int _size;
CxString(int size)
{
_size = size; // Default size of string
_pstr = malloc(size + 1); // Allocate memory for string
memset(_pstr, 0, size + 1);
}
CxString(const char *p)
{
int size = strlen(p);
_pstr = malloc(size + 1); // Allocate memory for string
strcpy(_pstr, p); // Copy string
_size = strlen(_pstr);
}
// Destructors are not discussed here. Omit
};
// Here is the call:
CxString string1(24); // This is OK. Pre allocate 24 bytes of memory for CxString
CxString string2 = 10; // This is OK. Pre allocate 10 bytes of memory for CxString
CxString string3; // This is not possible because there is no default constructor, and the error is: "CxString": no suitable default constructor is available
CxString string4("aaaa"); // This is OK
CxString string5 = "bbb"; // This is OK. CxString(const char *p) is called
CxString string6 = 'c'; // This is OK. In fact, CxString(int size) is called, and the size is equal to the ascii code of 'c'
string1 = 2; // This is also OK. Pre allocate 2 bytes of memory for CxString
string2 = 3; // This is also OK. Pre allocate 3 bytes of memory for CxString
string3 = string1; // This is OK. At least the compilation is OK, but if the destructor is released with free_ pstr may report an error when the memory pointer is. The complete code must overload the operator "=" and handle the memory release in it
“CxString string2 = 10;” Why is this possible? In c + +, if the constructor has only one parameter, there will be a default conversion operation during compilation: convert the data of the corresponding data type of the constructor to this kind of object That is, "cxstring string2 = 10;" However, in the above code_ Size represents the size of string memory allocation, so the second sentence "cxstring string2 = 10;" And the sixth sentence "CxString string6 = 'c';" It looks nondescript and easy to be confused Is there any way to stop this usage? The answer is to use the explicit keyword Detailed explanation of C++ explicit keyword
explicit CxString(int size)
{
_size = size;
// The code is the same as above, omitting
}
extern
[extern "C"] when using C functions in C + + environment, the compiler often fails to find the C function definition in obj module, resulting in link failure. How should we solve this situation? In order to solve the problem of polymorphism of functions when compiling, C + + language will combine the function name and parameters to generate an intermediate function name, while C language will not. Therefore, the corresponding function cannot be found when linking. At this time, the C function needs to be linked and specified with extern "C", which tells the compiler to keep my name, Don't give me intermediate function names for links. For example: extern "C" void fun(int a, int b); Then tell the compiler to translate the corresponding function name according to the rules of C rather than C + + when compiling the function name of fun. The rules of C + + will change the name of fun beyond recognition when translating the function name, which may be fun@aBc_int_int #%$may be something else. It depends on the "temper" of the compiler (different compilers adopt different methods). Why do you do this? Because C + + supports function overloading! The following is a standard way of writing: Detailed explanation of extern keyword in C/C + +
//Yes h file header
#ifdef __cplusplus
#if __cplusplus
extern "C"{
#endif
#endif /* __cplusplus */
...c Function declaration 1
...c Function declaration 2
//. h where the file ends
#ifdef __cplusplus
#if __cplusplus
}
#endif
#endif /* __cplusplus */
Also refer to Definition of "#ifdef #u cplusplus extern" C "{#endif" : suppose the prototype of a function is: void foo (int x, int y); After the function is compiled by the C compiler, its name in the symbol library may be_ Foo, while the C + + compiler will produce_ foo_int_int (different compilers may generate different names, but they all use the same mechanism, and the generated new name is called "mangled name")_ foo_ int_ The function name and the number of overloaded functions are realized by C + +. The following is an example to illustrate how to use C functions in C + +, or C + + functions in C.
Examples of C + + referencing C functions:
//test.c
#include <stdio.h>
void mytest()
{
printf("mytest in .c file ok\n");
}
//main.cpp
extern "C"
{
void mytest();
}
int main()
{
mytest();
return 0;
}
Reference C + + functions in C: when referring to functions and variables in C + + language in C, C + + functions or variables should be declared in extern "C" {}, but extern "C" cannot be used in C language, otherwise compilation error will occur.
//test.cpp
#include <stdio.h>
extern "C"
{
void mytest()
{
printf("mytest in .cpp file ok\n");
}
}
//main.c
void mytest();
int main()
{
mytest();
return 0;
}
General usage: C + + uses C
#ifdef __cplusplus
extern "C"
{
#endif
//Function declaration
#ifdef __cplusplus
}
#endif
C use C++
//test.h
#ifdef __cplusplus
#include <iostream>
using namespace std;
extern "C"
{
#endif
void mytest();
#ifdef __cplusplus
}
#endif
In this way, you can put the implementation of mytest() in c or Cpp file, you can c or After "test. H" is included in the cpp file, the functions in the header file are used without compilation errors.
[not extern "c"] extern is often used in variable declarations. You are in * c file declares a global variable. If this global variable is to be referenced, it should be placed in * h and declared with extern. Remember that it is a declaration, not a definition!
In the header file test1 H contains the following statement:
#ifndef TEST1H #define TEST1H extern char g_str[]; // Declare global variable g_str void fun1(); #endif
In test1 In CPP
#include "test1.h"
char g_str[] = "123456"; // Define global variable g_str
void fun1() { cout << g_str << endl; }
The above is test1 module, which can be compiled and connected. If we still have test2 module, we also want to use g_str, just reference it in the original file In test2 In CPP
#include "test1.h"
void fun2() { cout << g_str << endl; }
The above test1 and test2 can be compiled and connected at the same time. If you are interested, you can use ultraEdit to open test1 Obj, you can find the string "123456" in it, but you can't find it in test2 Found in obj because g_str is the global variable of the whole project. There is only one copy in memory, test2 There is no need to have another copy of obj compilation unit, otherwise the error of repeated definition will be reported during connection!
Inline: inline function (compare #define)
In c, we often write some short and frequently executed calculations as macros instead of functions. The reason for this is to improve execution efficiency. Macros can avoid the cost of function calls, which are completed by preprocessing. Although the macro looks like a function call, it will hide some hard to find errors (the following two examples). The second problem is unique to c + +. The preprocessor does not allow access to class members, that is, the preprocessor macro cannot be used as a member function of a class. In order to maintain the efficiency of preprocessing macros, increase security, and can be accessed freely in the class like general member functions, c + + introduces inline function In order to inherit the efficiency of macro functions, inline functions have no cost of function call. Then, like ordinary functions, they can check the security of parameters and return value types, and can be used as member functions. C + + inline function.
Some comparisons between preprocessing macros and inline functions are as follows:
#define ADD(x,y) x+y
inline int Add(int x,int y){
return x + y;
}
void test(){
int ret1 = ADD(10, 20) * 10; //The desired result is 300
int ret2 = Add(10, 20) * 10; //I hope the result is 300
cout << "ret1:" << ret1 << endl; //210
cout << "ret2:" << ret2 << endl; //300
}
#define COMPARE(x,y) ((x) < (y) ? (x) : (y))
int Compare(int x,int y){
return x < y ? x : y;
}
void test02(){
int a = 1;
int b = 3;
//cout << "COMPARE(++a, b):" << COMPARE(++a, b) << endl; // 3
cout << "Compare(int x,int y):" << Compare(++a, b) << endl; //2
}
In addition, the predefined macro function has no scope concept and cannot be used as a member function of a class, that is, the predefined macro has no way to represent the scope of a class.
Add the inline keyword in front of the ordinary function (non member function) to make it an inline function. However, it must be noted that the function body and declaration must be combined, otherwise the compiler will treat it as an ordinary function.
inline int func(int a){return ++;}
The compiler will put the function type (including function name, parameter type and return value type) into the symbol table. Similarly, inline functions are placed in the symbol table. When calling an inline function, the compiler first ensures that the incoming parameter types are correctly matched. Or if the types are not exactly matched, but can be converted to the correct type, and the return value matches the correct type in the target expression, or can be converted to the target type, the inline function will directly replace the function call, This eliminates the overhead of function calls. If the inline function is a member function, the object this pointer will also be put in place. Inline functions do take up space, but the advantage of inline functions over ordinary functions is that they save the overhead of stack pressing, jump and return when calling functions. We can understand that inline functions trade space for time.
The inline function itself is also a real function. Inline functions have all the behaviors of ordinary functions. The compiler will check whether the function parameter list is used correctly and return the value (make the necessary conversion). The only difference is that inline functions expand like predefined macros in place, so there is no cost of function calls.
- The inline function can be used wherever a macro is defined
Inline functions inside a class: however, it is not necessary to define inline functions inside a class. Any function defined inside the class automatically becomes an inline function, and there is no need to put an inline keyword in front of the function definition. However, it is meaningless to declare constructors and destructors as inline functions, because the compiler will add additional operations to constructors and destructors (apply for / release memory, construct / destruct objects, etc.), so that constructors / destructors are not as simple as they seem.
Inline is just a suggestion like register. The compiler is not necessarily inline. There are several cases where the compiler does not compile inline:
There cannot be any form of circular statement
There cannot be too many conditional statements
The function body cannot be too large
Function cannot be addressed
Usage of auto,decltype and decltype(auto)
Auto: unlike the original ones that only correspond to a specific type specifier (such as int), auto allows the compiler to deduce the type through the initial value, so as to obtain the type of the defined variable. Therefore, the variables defined by auto must have initial values.
//Ordinary; type int a = 1, b = 3; auto c = a + b;// c is int type //const type const int i = 5; auto j = i; // The variable i is the top const and will be ignored, so the type of j is int auto k = &i; // Variable i is a constant. Addressing a constant is an underlying const, so the type of b is const int* const auto l = i; //If you want to infer that the type is top-level const, you need to add cosnt before auto //Reference and pointer types int x = 2; int& y = x; auto z = y; //z is int type, not int & type auto& p1 = y; //p1 is int & type auto p2 = &x; //p2 is the pointer type int*
Decltype: sometimes we will encounter this situation. We want to infer the type of variable to be defined from the expression, but we don't want to initialize the variable with the value of the expression. It is also possible that the return type of the function is the value type of an expression. At these times, auto seems powerless, so C++11 introduces the second type specifier decltype, which is used to select and return the data type of the operand. In this process, the compiler only analyzes the expression and obtains its type, but does not actually calculate the value of the expression.
int func() {return 0};
//Common type
decltype(func()) sum = 5; // The type of sum is int of the return value of func(), but func() will not be actually called at this time
int a = 0;
decltype(a) b = 4; // The type of a is int, so the type of b is int
//Decltype will be retained regardless of the top-level const or the bottom-level const
const int c = 3;
decltype(c) d = c; // The type of d is the same as that of c, which is the top const
int e = 4;
const int* f = &e; // f is the bottom const
decltype(f) g = f; // g is also the bottom const
//Reference and pointer types
//1. If the expression is a reference type, the type of decltype is also a reference
const int i = 3, &j = i;
decltype(j) k = 5; // The type of k is const int&
//2. If the expression is a reference type, but you want to get the type pointed to by this reference, you need to modify the expression:
int i = 3, &r = i;
decltype(r + 0) t = 5; // This is the int type
//3. Dereference of pointer returns reference type
int i = 3, j = 6, *p = &i;
decltype(*p) c = j; // c is an int & type, and c and j are bound together
//4. If the type of an expression is not a reference, but we need to infer the reference, we can add a pair of parentheses to become a reference type
int i = 3;
decltype((i)) j = i; // At this time, the type of J is int & type, and j and i are bound together
decltype(auto): can be used to declare variables and indicate the return type of functions. When using, the expression to the left of the "=" sign will be replaced with auto, and then the type will be determined according to the syntax rules of decltype.
int e = 4; const int* f = &e; // f is the bottom const decltype(auto) j = f;//The type of j is const int * and points to e
new
- Common new is defined in C + +:
void* operator new(std::size_t) throw(std::bad_alloc); void operator delete(void *) throw();
Therefore, when the space allocation fails, the exception STD:: bad is thrown_ Alloc instead of NULL:
#include <iostream>
#include <string>
using namespace std;
int main()
{
try
{
char *p = new char[10e11];
delete p;
}
catch (const std::bad_alloc &ex)
{
cout << ex.what() << endl;
}
return 0;
}
//Execution result: bad allocation
- nothrow new does not throw an exception when the space allocation fails, but returns NULL:
#include <iostream>
#include <string>
using namespace std;
int main()
{
char *p = new(nothrow) char[10e11];
if (p == NULL)
{
cout << "alloc failed" << endl;
}
delete p;
return 0;
}
//Running result: alloc failed
- placement new reconstructs an object or an array of objects on a piece of memory that has been allocated successfully
It is defined as follows:
void* operator new(size_t,void*); void operator delete(void*,void*);
The constructed object or array should be explicitly destroyed by calling their destructor (the destructor does not release the memory of the object). Never use delete, because the size of the object or array constructed by placement new is not necessarily equal to the originally allocated memory, Using delete can cause memory leaks or run-time errors when freeing memory later.
#include <iostream>
#include <string>
using namespace std;
class ADT{
int i;
int j;
public:
ADT(){
i = 10;
j = 100;
cout << "ADT construct i=" << i << "j="<<j <<endl;
}
~ADT(){
cout << "ADT destruct" << endl;
}
};
int main()
{
char *p = new(nothrow) char[sizeof ADT + 1];
if (p == NULL) {
cout << "alloc failed" << endl;
}
ADT *q = new(p) ADT; //placement new: don't worry about failure, as long as the space of the object p refers to is enough for ADT creation
//delete q;// Wrong! Delete Q cannot be called here;
q->ADT::~ADT();//Show call destructors
delete[] p;
return 0;
}
//Output result:
//ADT construct i=10 j=100
//ADT destruct
Class related
Constructor
The default constructor and initialization constructor complete the initialization of the object by defining the object of the class; Copy constructor is used to copy the object of this class; The conversion constructor is used to implicitly convert other types of variables to this class object.
#include <iostream>
using namespace std;
class Student{
public:
Student(){ //Default constructor, no parameters
this->age = 20;
this->num = 1000;
};
Student(int a, int n):age(a), num(n){}; //Initialize constructor with parameters and parameter list
Student(const Student& s){ //Copy constructor, which is consistent with that generated by the compiler
this->age = s.age;
this->num = s.num;
};
Student(int r){ //Conversion constructor. The formal parameter is a variable of other types, and there is only one formal parameter
this->age = r;
this->num = 1002;
};
~Student(){}
public:
int age;
int num;
};
int main(){
Student s1;
Student s2(18,1001);
int a = 10;
Student s3(a);
Student s4(s3);
printf("s1 age:%d, num:%d\n", s1.age, s1.num);
printf("s2 age:%d, num:%d\n", s2.age, s2.num);
printf("s3 age:%d, num:%d\n", s3.age, s3.num);
printf("s4 age:%d, num:%d\n", s4.age, s4.num);
return 0;
}
//Operation results
//s1 age:20, num:1000
//s2 age:18, num:1001
//s3 age:10, num:1002
//s4 age:10, num:1002
When will the copy constructor be called:
When using one object to initialize another object.
Student s5 = s1;
When the parameter of a function is an object (passed by non reference). The implementation process is to generate a temporary object according to the incoming arguments when calling the function, and then initialize the temporary object with a copy structure, which corresponds to the formal parameters in the function, and destruct the temporary object after the function call.
void useClassS(Student s) {}
useClassS(s5);
When the return value of a function is a local object in the function body, although NRV optimization (Named return Value optimization) occurs at this time, since the return method is value passing (not return reference), the copy constructor will be called at the place of the return value. The theoretical execution process is: generate a temporary object, call the copy constructor to copy the returned object to the temporary object. After the function is executed, first destruct the local variable, then destruct the temporary object, and still call the copy constructor
Student getClassS() // A call to the copy constructor occurred
{
Student s;
return s;
}
Student s6 = getClassS();
Student& getClassS2() // No call to copy constructor occurs
{
Student s;
return s;
}
Student s7 = getClassS();
~Destructor
Why are destructors usually written as virtual functions? Due to the polymorphism of the class, the base class pointer can point to the object of the derived class. If the pointer of the base class is deleted, the derived class destructor pointed to by the pointer will be called, and the destructor of the derived class will automatically call the destructor of the base class, so that the whole object of the derived class will be released. If the destructor is not declared as a virtual function, the compiler implements static binding. When deleting the base class pointer, it will only call the destructor of the base class instead of the destructor of the derived class, which will lead to incomplete destructor of the derived class object and memory leakage. Therefore, it is necessary to declare the destructor as a virtual function. When implementing polymorphism, when the derived class is operated with the base class, the situation that only the base class is destructed but not the derived class is prevented during destruction. The destructor of the base class should be declared as a virtual function.
#include <iostream>
using namespace std;
class Parent{
public:
Parent(){
cout << "Parent construct function" << endl;
};
virtual ~Parent(){
cout << "Parent destructor function" <<endl;
}
};
class Son : public Parent{
public:
Son(){
cout << "Son construct function" << endl;
};
~Son(){
cout << "Son destructor function" <<endl;
}
};
int main()
{
Parent* p = new Son();
delete p;
p = NULL;
return 0;
}
//Operation results:
//Parent construct function
//Son construct function
//Son destructor function
//Parent destructor function
Optimize when creating objects: NRV
reference resources: About NRV optimization . The following is a Vector class, which is used to count the number of constructor calls executed by adding two objects. It has a default constructor and a copy constructor, and adds a static variable count to count the number of constructor calls:
class Vector
{
public:
static int count;
static void init()
{
count = 0;
}
int x,y;
Vector()
{
x = 0;
y = 0;
// For analysis.
count ++;
printf("Default Constructor was called.[0x%08x]\n", this);
}
Vector(const Vector & ref)
{
x = ref.x;
y = ref.y;
// For analysis.
count ++;
printf("Copy Constructor was called.[copy from 0x%08x to 0x%08x].\n", &ref, this);
}
};
int Vector::count = 0;
The function call form is as follows:
Vector a, b;
Vector::init();
printf("\n-- Test add() --\n");
Vector c = add(a, b);
printf("---- Constructors were called %d times. ----\n\n\n", Vector::count);
Operation results:
-- Test add() -- Default Constructor was called.[0x0012fef8] Copy Constructor was called.[copy from 0x0012fef8 to 0x0012ff60]. ---- Constructors were called 2 times. ----
Because there is no optimization at this time, the pseudo code executed is as follows (a total of 4 objects are created):
Vector a, b;
Vector::init();
printf("\n-- Test add() --\n");
Vector __temp0; // Constructor
add(__temp0, a, b);
Vector c(__temp0); // Copy constructor
printf("---- Constructors were called %d times. ----\n\n\n", Vector::count);
If NRV optimization (cl /Ox) is used, the pseudocode executed is as follows (a total of 3 objects are created):
Vector c; add(c, a, b);
In other words, a total of 1 object is created from the function passed in by a and B.
friend function
One rule that matters in any relationship is who can access my private part. Friend functions can. Friends provide a mechanism for data sharing between member functions of different classes and between member functions of classes and general functions. Through friends, a different function or a member function in another class can access private and protected members in the class. The correct use of friends can improve the running efficiency of the program, but it also destroys the encapsulation of classes and the concealment of data, resulting in poor maintainability of the program. Therefore, try to use member functions, unless you have to use friend functions.
- Ordinary functions need to be declared in the class definition. A function can be a friend function of multiple classes, but this function must be declared in each class.
#include <iostream>
using namespace std;
class A
{
public:
friend void set_show(int x, A &a); //This function is a declaration of a friend function
private:
int data;
};
void set_show(int x, A &a) //Friend function definition, in order to access members in class A
{
a.data = x;
cout << a.data << endl;
}
int main(void)
{
class A a;
set_show(1, a);
return 0;
}
- All member functions of a friend class are friend functions of another class, and can access hidden information in another class (including private members and protected members). But another class should also be declared accordingly.
#include <iostream>
using namespace std;
class A
{
public:
friend class C; //This is the declaration of a friend class
private:
int data;
};
class C //Friend class definition, in order to access the members in class A
{
public:
void set_show(int x, A &a) { a.data = x; cout<<a.data<<endl;}
};
int main(void)
{
class A a;
class C c;
c.set_show(1, a);
return 0;
}
Note when using friend classes: (1) friend relationships cannot be inherited. (2) Friend relationship is unidirectional and not exchangeable. If class B is a friend of class A, class A is not necessarily a friend of class B. It depends on whether there is a corresponding declaration in the class. (3) Friend relationships are not transitive. If class B is a friend of class A, class C is a friend of class B, and class C is not necessarily a friend of class A, it also depends on whether there is a corresponding declaration in the class.
When to use friend functions:
1) Friends are required in some cases of operator overloading.
2) When two classes want to share data
Member initialization list
#include<iostream>
#include<string>
using namespace std;
class Weapon
{
private:
string name;
const string type;
const string model;
public:
Weapon(string& name, string& type, string& model) :name(name), type(type), model(model)
{
name = "Cloud";
}
string getProfile()
{
return "name: " + name + "\ntype: " + type + "\nmodel: " + model;
}
};
int main(void)
{
string name = "Comet";
string type = "carbine";
string model = "rifle";
Weapon weapon(name, type, model);
cout << weapon.getProfile() << endl;
cin.get();
return 0;
}
Notice that the name = "Cloud" in the constructor; Overwritten by the value of the initialization list
Both type and model are constants, which can be initialized but cannot be assigned. If you try to do it in the function body of the constructor, such as type = "xxx"; Such assignment will report an error. Conceptually, before entering the function body of the constructor, the object has been created, so the initialization must be completed before the object is created. Therefore, C + + invented the initialization list. This form of assignment is considered as initialization. C + + member initialization list
Distinguish between initialization and assignment
For simple types, initialization and assignment are no different; For classes and complex data types, there is a big difference between the two:
class A{
public:
int num1;
int num2;
public:
A(int a=0, int b=0):num1(a),num2(b){};
A(const A& a){};
//Overload = operator function
A& operator=(const A& a){
num1 = a.num1 + 1;
num2 = a.num2 + 1;
return *this;
};
};
int main(){
A a(1,1);
A a1 = a; //Copy initialization operation, call copy constructor
A b;
b = a;//Assignment operation: in object a, num1 = 1, num2 = 1; In object b, num1 = 2, num2 = 2
return 0;
}
Overload / override (Implementation) / hide
Rewriting is the vertical relationship between parent and child classes, and overloading is the horizontal relationship between different functions
Overloading refers to the (member) functions in the same scope definition. Their function names are the same, but their parameter types and numbers are different. Functions with the same number and types of parameters can not be distinguished only by different return values.
Rewriting refers to overwriting the virtual function with the same name in the base class in the derived class. Rewriting is rewriting the function. The number, type and return value type of the parameters of the two functions are required to be the same.
//Parent class
class A{
public:
virtual int fun(int a){}
}
//Subclass
class B : public A{
public:
//Override, generally add override to ensure that it is a function that overrides the parent class
virtual int fun(int a) override{}
}
Hiding means that in some cases, functions in derived classes mask functions with the same name in the base class
Case 1: the parent-child function names and parameters are the same, but the base class is not a virtual function
//Parent class
class A{
public:
void fun(int a){
cout << "A Medium fun function" << endl;
}
};
//Subclass
class B : public A{
public:
//Hide the fun function of the parent class
void fun(int a){
cout << "B Medium fun function" << endl;
}
};
int main(){
B b;
b.fun(2); //The fun function in B is called
b.A::fun(2); //Call the fun function in A
return 0;
}
Case 2: if the parent and child have the same function name, they will also be hidden
//Parent class
class A{
public:
virtual void fun(int a){
cout << "A Medium fun function" << endl;
}
};
//Subclass
class B : public A{
public:
//Hide the fun function of the parent class
virtual void fun(char* a){
cout << "A Medium fun function" << endl;
}
};
int main(){
B b;
b.fun(2); //An error is reported. The fun function in B is called, and the parameter type is wrong
b.A::fun(2); //Call the fun function in A
return 0;
}
It can be seen from the above that subclass objects can be used even if they are hidden Parent class name: the function (parameter) with the same name as the parent class is called
Polymorphism: overrides the virtual function of the parent class
Functions decorated with virtual are virtual functions. When a class containing virtual functions is instantiated as an object, the compiler will automatically generate a virtual table, and the first four bytes of the object address store the pointer vptr to the virtual table.
#include <iostream>
using namespace std;
class Base{
public:
virtual void fun(){
cout << " Base::func()" <<endl;
}
};
class Son1 : public Base{
public:
virtual void fun() override{
cout << " Son1::func()" <<endl;
}
};
class Son2 : public Base{
};
int main()
{
Base* base = new Son1;
base->fun();
base = new Son2;
base->fun();
delete base;
base = NULL;
return 0;
}
// Operation results
// Son1::func()
// Base::func()
The virtual table is a one-dimensional array that holds the entry address of the virtual function. When constructing a subclass object, the constructor of the parent class will be called first. At this time, the compiler only "sees" the parent class and initializes the virtual table pointer for the parent object to point to the virtual table of the parent class; When calling the constructor of a subclass, initialize the virtual table pointer for the subclass object to point to the virtual table of the subclass. When the derived class does not override the virtual function of the base class, the virtual table pointer of the derived class points to the virtual table of the base class; When the derived class overrides the virtual function of the base class, the virtual table pointer of the derived class points to its own virtual table; When the derived class has its own virtual function, add the address of this virtual function in its own virtual table.
Virtual and pure virtual functions
Defining a function as a virtual function does not mean that the function is not implemented. It is defined as a virtual function to allow the function of a subclass to be called with a pointer to the base class. It lies in the so-called "deferred binding" or "dynamic binding". The call of a class function is not determined at the compile time, but at the run time. When writing code, it is not sure whether the function of the base class or the function of which derived class is called, so it is called "virtual" function. Virtual functions can only achieve polymorphism by means of pointers or references. The difference between C + + virtual function and pure virtual function.
class A
{
public:
virtual void foo()
{
cout<<"A::foo() is called"<<endl;
}
};
class B:public A
{
public:
void foo()
{
cout<<"B::foo() is called"<<endl;
}
};
int main(void)
{
A *a = new B();
a->foo(); // Here, although a is a pointer to a, the called function (foo) is B!
return 0;
}
be careful: Must virtual functions be implemented?
Virtual functions must be implemented; Both parent and child classes have their own versions, which are dynamically bound when called in a polymorphic way.
Pure virtual functions: 1. In order to facilitate the use of polymorphism, we often need to define virtual functions in the base class. 2. In many cases, it is unreasonable for the base class itself to generate objects. For example, as a base class, animals can derive subclasses such as tigers and peacocks, but the objects generated by animals themselves are obviously unreasonable. In order to solve the above problems, the concept of pure virtual function is introduced. A class containing pure virtual functions is called an abstract class, which cannot generate objects. In this way, the above two problems are well solved.
The method of realizing pure virtual function in the base class is to add = 0:
virtual void funtion1()=0;
Abstract classes: classes with pure virtual functions are abstract classes. The main function of abstract class is to organize the relevant operations as the result interface in an inheritance hierarchy, which provides a common root for the derived class, and the derived class will specifically implement the operations as the interface in its base class. Abstract classes can only be used as base classes, and the implementation of pure virtual functions is given by derived classes. If the derived class does not redefine the pure virtual function, but only inherits the pure virtual function of the base class, the derived class is still an abstract class. If the implementation of the pure virtual function of the base class is given in the derived class, the derived class is no longer an abstract class, but a concrete class that can establish an object.
Type safety (caused by polymorphism)
#include<iostream>
using namespace std;
class Parent{};
class Child1 : public Parent
{
public:
int i;
Child1(int e):i(e){}
};
class Child2 : public Parent
{
public:
double d;
Child2(double e):d(e){}
};
int main()
{
Child1 c1(5);
Child2 c2(4.1);
Parent* pp;
Child1* pc1;
pp=&c1;
pc1=(Child1*)pp; // Type down conversion and cast. Since the type is still Child1 *, it will not cause an error
cout<<pc1->i<<endl; //Output: 5
pp=&c2;
pc1=(Child1*)pp; //Cast, and the type changes, will cause an error
cout<<pc1->i<<endl;// Output: 1717986918
return 0;
}
To be solved: template function, special case of template function and template class
le/details/41312111)
Virtual functions must be implemented; Both parent and child classes have their own versions, which are dynamically bound when called in a polymorphic way.
Pure virtual functions: 1. In order to facilitate the use of polymorphism, we often need to define virtual functions in the base class. 2. In many cases, it is unreasonable for the base class itself to generate objects. For example, as a base class, animals can derive subclasses such as tigers and peacocks, but the objects generated by animals themselves are obviously unreasonable. In order to solve the above problems, the concept of pure virtual function is introduced. A class containing pure virtual functions is called an abstract class, which cannot generate objects. In this way, the above two problems are well solved.
The method of realizing pure virtual function in the base class is to add = 0:
virtual void funtion1()=0;
Abstract classes: classes with pure virtual functions are abstract classes. The main function of abstract class is to organize the relevant operations as the result interface in an inheritance hierarchy, which provides a common root for the derived class, and the derived class will specifically implement the operations as the interface in its base class. Abstract classes can only be used as base classes, and the implementation of pure virtual functions is given by derived classes. If the derived class does not redefine the pure virtual function, but only inherits the pure virtual function of the base class, the derived class is still an abstract class. If the implementation of the pure virtual function of the base class is given in the derived class, the derived class is no longer an abstract class, but a concrete class that can establish an object.
Type safety (caused by polymorphism)
#include<iostream>
using namespace std;
class Parent{};
class Child1 : public Parent
{
public:
int i;
Child1(int e):i(e){}
};
class Child2 : public Parent
{
public:
double d;
Child2(double e):d(e){}
};
int main()
{
Child1 c1(5);
Child2 c2(4.1);
Parent* pp;
Child1* pc1;
pp=&c1;
pc1=(Child1*)pp; // Type down conversion and cast. Since the type is still Child1 *, it will not cause an error
cout<<pc1->i<<endl; //Output: 5
pp=&c2;
pc1=(Child1*)pp; //Cast, and the type changes, will cause an error
cout<<pc1->i<<endl;// Output: 1717986918
return 0;
}