System.IO.Pipelines is a new library designed to make NET makes it easier to perform high-performance io. It is a face NET Standard library, applicable to all NET implementation.
Pipelines was born in NET Core team's work to make Kestrel one of the fastest Web servers in the industry. Originally, as an implementation detail within Kestrel, it developed into a reusable API, which was provided to all as the first type of BCL API (System.IO.Pipelines) in 2.1 NET developer.
What problem does it solve?
Proper parsing of data from streams or sockets is dominated by boilerplate code, and there are many extremes, resulting in complex code that is difficult to maintain. It is difficult to achieve high performance and correctness while dealing with this complexity. Pipelines is designed to address this complexity.
What additional complexities exist today?
Let's start with a simple question. We want to write a TCP server that receives line separated messages (separated by n) from the client.
TCP server with NetworkStream
Disclaimer: as with all performance sensitive work, each scenario should be measured in the context of your application. Depending on the size of your network application, the overhead of each of these technologies may not be necessary.
Use before piping NET is as follows
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
This code may be valid when tested locally, but there are several errors:
The entire message (end of line) ReadAsync may not have been received in a single call to.
It ignores the result of returning the amount of data actually filled into the buffer. stream.ReadAsync()
It does not handle the return of multiple lines in a ReadAsync call.
These are some common pitfalls when reading stream data. To solve this problem, we need to make some changes:
We need to buffer the incoming data until we find a new row.
We need to parse all the rows returned in the buffer
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed, bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset
var lineLength = linePosition - bytesConsumed;
// Process the line
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line we consumed (including \n)
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}```
Again, this may apply to local tests, but the line may be greater than 1 KiB(1024 Bytes). We need to resize the input buffer until we find a new row.
In addition, we allocate buffers on the heap when processing longer rows. When we parse longer rows from the client, we can improve this by using buffer allocation to avoid duplication. ArrayPool<byte>
```csharp
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes
bytesBuffered += bytesRead;
do
{
// Look for a EOL in the buffered data
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed, bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset
var lineLength = linePosition - bytesConsumed;
// Process the line
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line we consumed (including \n)
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
This code works, but now we are resizing the buffer, which will lead to more buffer copies. It also uses more memory because the logic does not shrink the buffer after processing rows. To avoid this, we can store a list of buffers instead of resizing every time the size of the 1KiB buffer is exceeded.
In addition, we will not increase the 1KiB buffer until it is completely empty. This means that we can eventually pass ReadAsync smaller and smaller buffers, which will lead to more operating system calls.
To alleviate this situation, we will allocate a new buffer when less than 512 bytes remain in the existing buffer:
public class BufferSegment
{
public byte[] Buffer { get; set; }
public int Count { get; set; }
public int Remaining => Buffer.Length - Count;
}
async Task ProcessLinesAsync(NetworkStream stream)
{
const int minimumBufferSize = 512;
var segments = new List<BufferSegment>();
var bytesConsumed = 0;
var bytesConsumedBufferIndex = 0;
var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) };
segments.Add(segment);
while (true)
{
// Calculate the amount of bytes remaining in the buffer
if (segment.Remaining < minimumBufferSize)
{
// Allocate a new segment
segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) };
segments.Add(segment);
}
var bytesRead = await stream.ReadAsync(segment.Buffer, segment.Count, segment.Remaining);
if (bytesRead == 0)
{
break;
}
// Keep track of the amount of buffered bytes
segment.Count += bytesRead;
while (true)
{
// Look for a EOL in the list of segments
var (segmentIndex, segmentOffset) = IndexOf(segments, (byte)'\n', bytesConsumedBufferIndex, bytesConsumed);
if (segmentIndex >= 0)
{
// Process the line
ProcessLine(segments, segmentIndex, segmentOffset);
bytesConsumedBufferIndex = segmentOffset;
bytesConsumed = segmentOffset + 1;
}
else
{
break;
}
}
// Drop fully consumed segments from the list so we don't look at them again
for (var i = bytesConsumedBufferIndex; i >= 0; --i)
{
var consumedSegment = segments[i];
// Return all segments unless this is the current segment
if (consumedSegment != segment)
{
ArrayPool<byte>.Shared.Return(consumedSegment.Buffer);
segments.RemoveAt(i);
}
}
}
}
(int segmentIndex, int segmentOffest) IndexOf(List<BufferSegment> segments, byte value, int startBufferIndex, int startSegmentOffset)
{
var first = true;
for (var i = startBufferIndex; i < segments.Count; ++i)
{
var segment = segments[i];
// Start from the correct offset
var offset = first ? startSegmentOffset : 0;
var index = Array.IndexOf(segment.Buffer, value, offset, segment.Count - offset);
if (index >= 0)
{
// Return the buffer index and the index within that segment where EOL was found
return (i, index);
}
first = false;
}
return (-1, -1);
}
This code becomes more complex. When looking for separators, we track the filled buffer. To this end, we use here to represent buffered data when looking for new row delimiters. The result is, and now accepted, not one, and. Our parsing logic now needs to handle one or more buffer segments. ListProcessLineIndexOfListbyte[]offsetcount
Our server now processes some messages. It uses pooled memory to reduce the overall memory consumption, but we still need to make some changes:
We are using only ordinary management arrays. This means that whenever we execute a or, These buffers are fixed during the life cycle of the asynchronous operation (to interoperate with the local IO API on the operating system). This has an impact on the performance of the garbage collector because fixed memory cannot be moved, which can lead to heap fragmentation. Depending on the length of time the asynchronous operation is suspended, the pool implementation may need to be changed. byte[]ArrayPoolReadAsyncWriteAsync
Throughput can be optimized by separating read and processing logic. This produces a batch effect, allowing the parsing logic to consume larger buffer blocks instead of reading more data only after parsing a row. This introduces some additional complexity:
We need two loops that run independently of each other. One reads from the Socket and one parses the buffer.
We need a way to signal parsing logic when data is available.
We need to decide what happens if the loop reads the Socket "too fast". If the parsing logic can't keep up, we need a way to limit the read loop. This is commonly referred to as "flow control" or "back pressure".
We need to make sure things are thread safe. We now share a set of buffers between the read loop and the parse loop, which run independently on different threads.
The memory management logic is now distributed in two different pieces of code. The code rented from the buffer pool is read from the socket, and the code returned from the buffer pool is parsing logic.
After the parsing logic is complete, we need to be very careful how we return the buffer. If we are not careful, we may return a buffer that is still being written by Socket read logic.
Complexity has peaked (we haven't even covered everything). High performance networks usually mean writing very complex code to get higher performance from the system.
The goal is to make writing such code easier. System.IO.Pipelines
With system IO. TCP server for pipelines
Let's see what this example looks like: system IO. Pipelines
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
return Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// Tell the PipeReader that there's no more data coming
writer.Complete();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
SequencePosition? position = null;
do
{
// Look for a EOL in the buffer
position = buffer.PositionOf((byte)'\n');
if (position != null)
{
// Process the line
ProcessLine(buffer.Slice(0, position.Value));
// Skip the line + the \n character (basically position)
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
}
}
while (position != null);
// Tell the PipeReader how much of the buffer we have consumed
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete
reader.Complete();
}
The pipeline version of our line reader has 2 cycles:
FillPipeAsync reads the Socket from it and writes it to PipeWriter
ReadPipeAsync reads the PipeReader and parses the incoming rows.
Unlike the original example, no explicit buffer is allocated anywhere. This is one of the core functions of the pipeline. All buffer management is delegated to the PipeReader/PipeWriter implementation.
This makes it easier to use code to focus on business logic rather than complex buffer management.
In the first loop, we first call to get some memory from the underlying writer; Then we call and tell us the amount of data actually written to the buffer. Then we call to make the data available to PipeWriter.GetMemory(int)PipeWriter.Advance(int)PipeWriterPipeWriter.FlushAsync()PipeReader
In the second loop, we consumed the PipeWriter and finally came from the Socket When the call returns, we get a message containing two important pieces of information, the data read in the form of and a Boolean value to let the reader know whether the author has completed writing (EOF). After finding the end of line (EOL) delimiter and parsing the line, we slice the buffer to skip what we have processed, Then we call to tell us how much data has been consumed. PipeReader.ReadAsync()ReadResultReadOnlySequenceIsCompletedPipeReader.AdvanceToPipeReader
At the end of each cycle, we complete the reader and author. This allows the underlying Pipe to free up all the memory it allocates.
System IO. The Conduit
Partial read
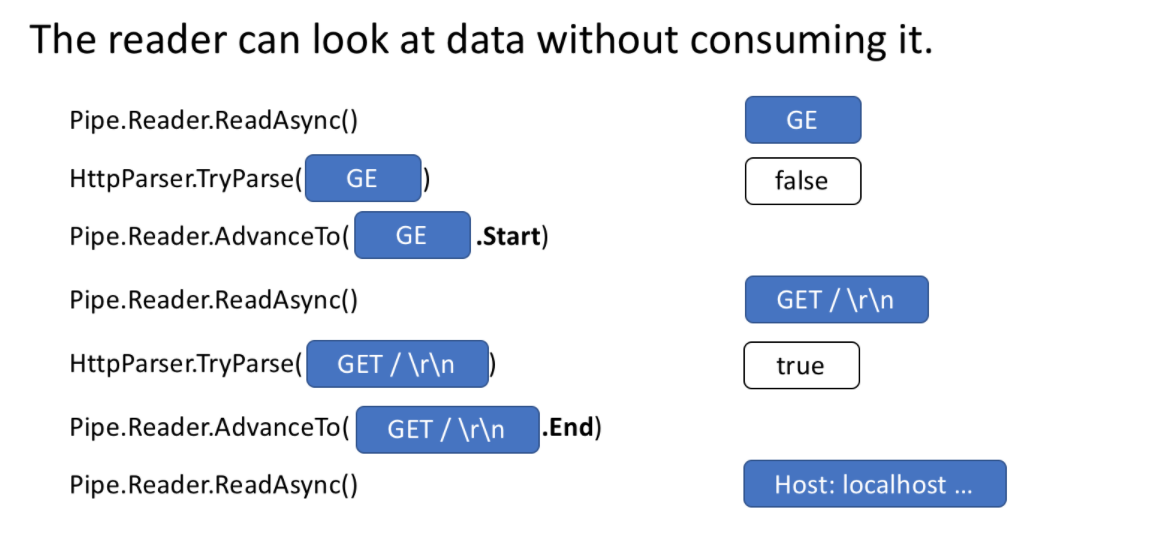
In addition to handling memory management, another core pipeline function is the ability to view data when the Pipe does not actually consume data.
Pipe reader has two core APIReadAsync and AdvanceTo Readasync gets the data pipes in the. AdvanceTo tells the PipeReader that these buffers are no longer needed, so they can be discarded (for example, return to the underlying buffer pool).
The following is an example of an http parser, which reads part of the data and buffers the data until a valid start line is received.
Read-Only Sequences
The Pipe implementation stores a linked list of buffers passed between PipeWriter and pipereader. Expose a, a new BCL type that represents a view of one or more segments of, similar to, and provides a view of arrays and strings. PipeReader.ReadAsyncReadOnlySequenceReadOnlyMemorySpanMemory
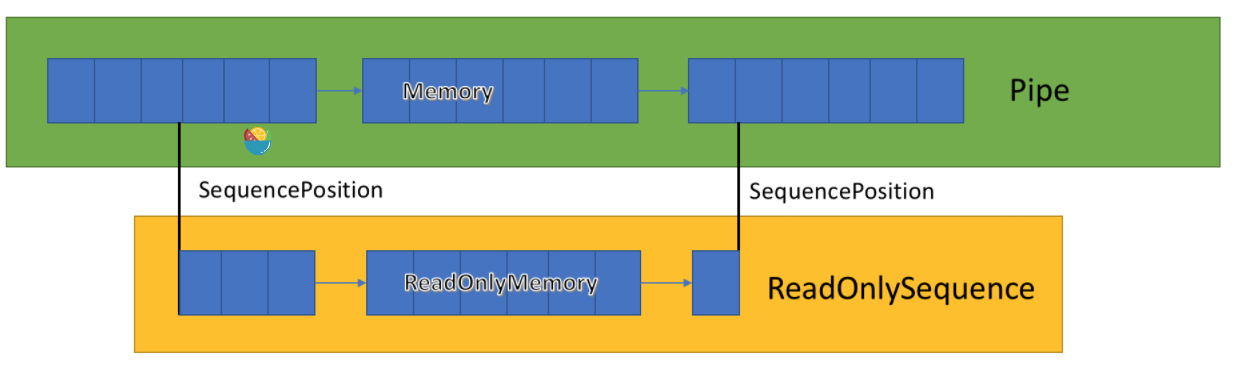
The Pipe internal maintenance points to the place where readers and writers write or read the data assigned by the whole group to update them. The SequencePosition represents a single point in the buffer linked list and can be used to slice effectively. ReadOnlySequence
Since one or more segments can be supported, high-performance processing logic usually splits fast and slow paths based on a single or multiple segments. ReadOnlySequence
For example, the following is an ASCII conversion routine: ReadOnlySequencestring
string GetAsciiString(ReadOnlySequence<byte> buffer)
{
if (buffer.IsSingleSegment)
{
return Encoding.ASCII.GetString(buffer.First.Span);
}
return string.Create((int)buffer.Length, buffer, (span, sequence) =>
{
foreach (var segment in sequence)
{
Encoding.ASCII.GetChars(segment.Span, span);
span = span.Slice(segment.Length);
}
});
}
Back pressure and flow control
In a perfect world, reading and parsing is a team work: the reading thread consumes data from the network and puts it into the buffer, while the parsing thread is responsible for building the appropriate data structure. Typically, parsing takes more time than just copying blocks from the network. Therefore, the read thread can easily overwhelm the parse thread. As a result, the reading thread will have to slow down or allocate more memory to store the data of the parsing thread. For optimal performance, a balance needs to be struck between frequent pauses and allocating more memory.
To solve this problem, the pipeline has two settings to control the data flow, PauseWriterThreshold and ResumeWriterThreshold. The PauseWriterThreshold determines how much data should be buffered before calling. The reader has how much control consumption can be recovered before writing. PipeWriter.FlushAsyncResumeWriterThreshold,
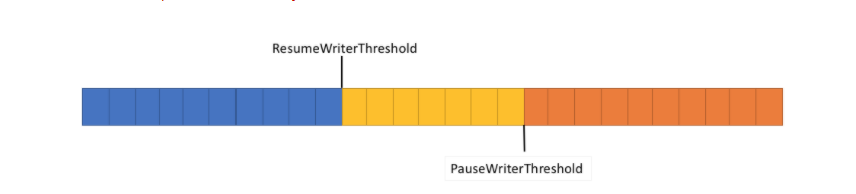
Pipe Writer. Flushasync "blocks" when the data volume pipes cross, and "unblocks" ResumeWriterThreshold when the data volume PauseWriterThreshold is lower than. Two values are used to prevent bumping near the limit.
Scheduling IO
Typically, when async/await is used, the thread pool thread or the current SynchronizationContext
When performing IO, it is very important to fine-grained control the location of IO so that CPU cache can be used more effectively, which is very important for high-performance applications such as Web servers. The pipeline exposes a PipeScheduler that determines where asynchronous callbacks run. This gives the caller precise control over the threads used for Io.
An example in practice is in the Kestrel Libuv transport, where the IO callback runs on a dedicated event loop thread.
Other benefits of PipeReader mode:
Some underlying systems support "no buffer waiting", that is, there is no need to allocate a buffer until there is actually available data in the underlying system. For example, on Linux with epoll, you can wait until the data is ready before actually providing a buffer for reading. This avoids the problem that a large number of threads waiting for data do not immediately need to reserve a large amount of memory.
The default setting Pipe makes it easy to write unit tests for network code. Because the parsing logic is separated from the network code, the unit test only runs the parsing logic for the memory buffer, rather than consuming it directly from the network. It can also easily test difficult patterns that send some data. ASP.NET Core uses it to test all aspects of Kestrel's http parser.
Systems that allow the underlying operating system buffer (such as the registered IO API on Windows) to be exposed to user code are ideal for pipelines, because the buffer is always provided by the PipeReader implementation.
Other related types
As a production system IO. As part of pipelines, we have also added many new original BCL types:
MemoryPool,IMemoryOwner,MemoryManager – . NET Core 1.0 adds ArrayPool and NET Core 2.1, we now have a more general abstract pool, which can be used in any This provides an extensible point that allows you to insert more advanced allocation policies and control how buffers are managed (for example, providing pre fixed buffers rather than purely managed arrays). Memory
IBufferWriter – indicates the receiver used to write synchronous buffer data. (PipeWriter implements this)
IValueTaskSource – ValueTask from NET Core 1.1 has existed since the beginning, but in NET Core 2.1 has some super capabilities that allow no allocation to wait for asynchronous operations. For more details, see https://github.com/dotnet/corefx/issues/27445 .
How do I use pipes?
API exists in system IO. Pipelines nuget package.
This is a NET Core 2.1 server application that uses pipes to process line based messages (our example above) https://github.com/davidfowl/TcpEcho . It should run dotnet run (or by running it in Visual Studio). It listens for sockets on port 8087 and writes received messages to the console. You can use a client like netcat or putty to connect to 8087 and send line-based messages to see if it works properly.
Today, the pipeline supports Kestrel and SignalR, and we want to see it become NET community is the center of many network libraries and components.