STL: Standard Template Library
GP: Generic Programming
STL is the most successful work of GP!!
1, STL six components
- Allocators
- Containers
- Algorithms
- Iterators (iterators)
- Adapters
- Functors
The relationship between the six components is shown in the figure below:

1. The first contact is Containers, and the container needs data, which needs to occupy memory,
2. Therefore, the problem of memory allocation is also involved. Therefore, Allocator is the Allocator that allocates the memory corresponding to the storage elements to the container.
3. When it is necessary to operate the data elements stored in the container, although the container is a template class and some operations are operated through the functions in the container, most operations are independent into a template function placed outside the container, i.e. Algorithms.
(Note: in the object-oriented (OO) programming technique, when defining a class, you are encouraged to put the data in the class, and the functions that process the data are also placed in the class, so as to form a class; However, in STL, the data is encouraged to be placed in the container and the data processing functions are placed in the algorithm separately, so the design method is different from that of object-oriented.)
4. When the algorithm wants to process the data in containers such as List, it needs to find the data in these containers through the middle bridge of Iterator (i.e. a generalized pointer) Iterator for corresponding operation and processing.
5. Functions are used to handle operations between classes and realize functions similar to functions. In addition, Adapters are used to help containers \ iterators \ functions make some transformations.

First, when using the vector container, < > indicates the template, and the corresponding template parameters need to be specified. The first parameter indicates the element parameter type to be specified (cannot be omitted), and the second parameter allows you to specify the allocator to allocate the corresponding memory to the elements placed in the container (it can be omitted. If not specified, call the default). The assignment form in vector < int, allocator < int > > vi(ia, ia+6) is because in the definition of container class, the assignment is defined in different ways, such as vi(ia, ia+6), that is, the head and tail of the array are assigned to vector as the initial value.
The next step is to operate on the data, count_if() is an algorithm, which operates on the data in the vector and counts when the given conditions are met, and the algorithm needs to find the corresponding data elements stored in the vector through Irerators, so pass in the parameter iterators [generalized pointer] vi.begin() and vi.end(), that is, where the range of data elements to be operated is; The third parameter is the condition of corresponding processing, less < int > (), which is an imitation function, indicating that it is less than a certain object; The condition is to find out the objects less than 40 in these elements, so it is necessary to bind the objects operated by ess < int > (), that is, bind them with the Adapter bind2nd(), and the second incoming parameter is 40; Similarly, notl() is also a function Adapter, which is used to reverse the internal result, that is, obtain a result greater than or equal to 40. So Notl (bind2nd (less < int > (), 40)) corresponds to the if condition. The above is an example of the mixed use of six components.
2, "Front closing and rear opening" section of container
All containers provide begin() and end() functions:
Note here that the end() function points to the next bit of the last element in the container, that is, the iterator (generic pointer) represented by calling the end() function. Its memory address points to the next position of the last element in the container, so it is outside the scope of the container.
So * (c.begin()) is OK, but (c.end()) is incorrect *, because the dereference of the generic pointer obtained is the gray piece of content, which is outside the container rather than part of the container, so * (c.end()) doesn't know what will be obtained outside the container.
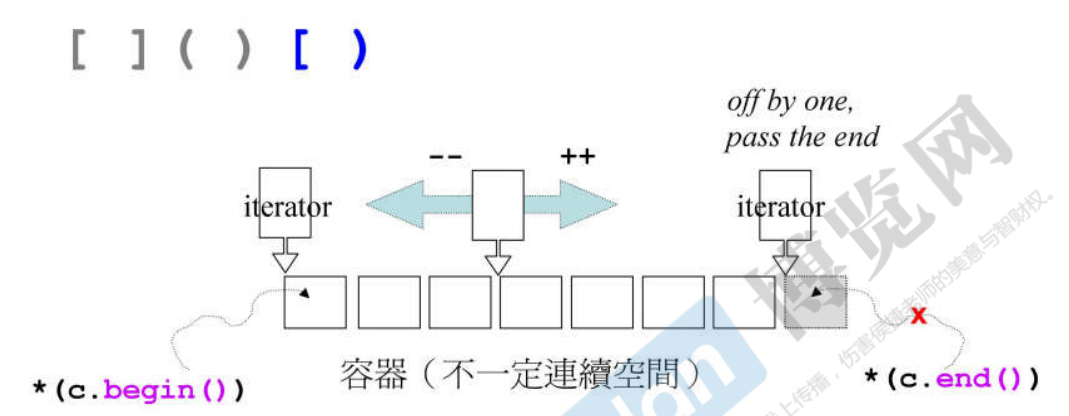 It can be seen from the above that for the emptying of a container, c.begin() = c.end(), which means that the first starting address of the container points to the address outside the container, which is equivalent to the container length of 0, that is, the container is empty.
It can be seen from the above that for the emptying of a container, c.begin() = c.end(), which means that the first starting address of the container points to the address outside the container, which is equivalent to the container length of 0, that is, the container is empty.
list<string> c; ... list<string>::iterator ite; // The general iterator is the declaration of generic pointer (indicating the type of container, i.e. the corresponding container template parameters) ite = ::find(c.begin(), c.end, target); auto ite1 = ::find(c.begin(), c.end, target); // The iterator of the new feature, namely the declaration of generic pointer, uses the auto keyword to let the compiler deduce by itself.
3, Container structure and classification
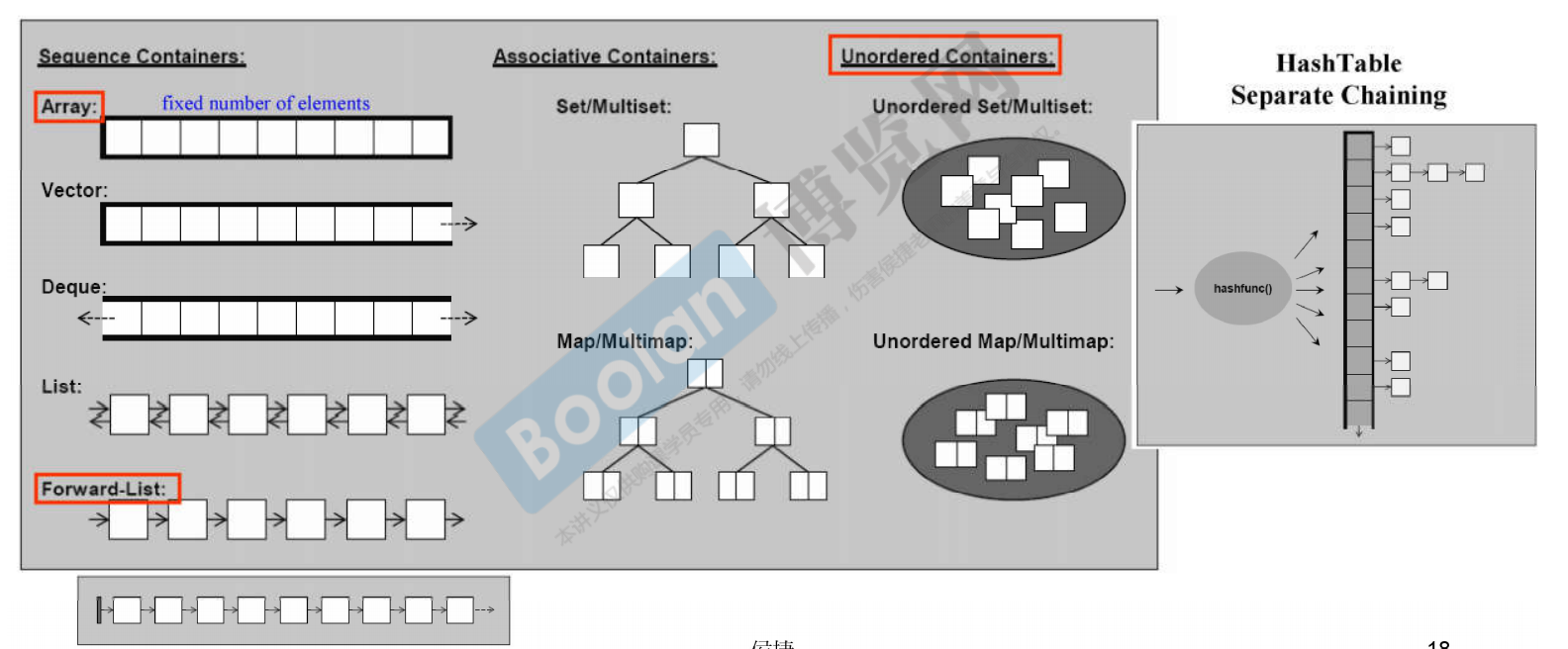
-Sequence containers:
- Array (New): fixed size space
- Vector: the size changes dynamically and is automatically expanded by the allocator in the form of twice the previous memory size
- Deque: two way
- List: bidirectional and not continuous in memory
- Forward List: unidirectional List
-Associative containers:
Features: it is composed of key and value. It is fast to find!
- Set: key and value are the same, and the same element cannot appear
- Multiset: elements inside can be repeated
- Map: key and value are separated, and the same element cannot appear
- Multimap: the elements inside can be repeated
-Unordered containers: its internal position will change dynamically
- Unordered Set: key and value are the same, and the same element cannot appear
- Unordered Multiset: the elements inside can be repeated
- Unordered Map: key and value are separated, and the same element cannot appear
- Unordered Multimap: the elements inside can be repeated
It is realized through Hash Table. There is a separate chaining in each bucket. Elements are stored through some calculations to see which linked list is hung: if the container has 20 spaces, element a is calculated to be placed in the third position, and element B is also calculated to be placed in the third position, then a linked list will be formed in the third position, A - > b... When there are too many elements in a chain, that is, the linked list at a certain position is too long, it will be reassigned (because when looking for elements in the linked list, if the length of the linked list is too long, it will affect the search speed of the linked list), so it is called unordered.
4, Vessel classification and various tests
Auxiliary function of test program
using std::cin;
using std::cout;
using std::string;
long get_a_target_long(){
long target = 0;
cout << "target (0~" << RAND_MAX << "): ";
cin >> target;
return target;
}
string get_a_target_string(){
long target = 0;
char buf[10];
cout << "target (0~" << RAND_MAX <<"):";
cin >> target;
snprintf(buf, 10, "%d", target); // Converts the input long data element to a string data element
return string(buf); // Create a temporary string type variable
}
int compareLongs(const void* a, const void* b){ // The incoming data type can be any type of pointer data
return (*(long*)a - *(long*)b); // Strongly convert any pointer type passed in to a long integer pointer type, and then dereference it to take out the memory address data element
}
int compareStrings(const void* a, const void*b){
if(*(string*)a > *(string*)b)
return 1;
else if(*(string*)a < *(string*)b)
return -1;
else
return 0;
}
-Container array
#include<array>
#include<iostream>
#include<ctime>
#include<cstdlib> // qsort, bsearch, NULL
#define ASIZE 5000000
namespace jj01{
void test_array(){
cout << "\n test_array()...... \n";
array<long, ASIZE> c; // Two template parameters for this container must be specified
clock_t timeStart = clock();
for(long i = 0; i < ASIZE; i++)
c[i] = rand();
cout << "milli-seconds :" << (clock() - timeStart) << endl; // The time it takes to put the generated data into the container
cout << "array.size() = " << c.size() << endl;
cout << "array.front() = " << c.front() << endl; // Take out the first element in the container
cout << "array.back() = " << c.back() << endl;
cout << "array.data() = " << c.data() << endl; // Take out the address of the container at the beginning of memory
long target = get_a_target_long(); // The search target is 20000
timeStart = clock();
qsort(c.data(), ASIZE, sizeof(long), compareLongs); // The incoming starting address, the number of element data placed in the container, the size of each element data (because the element is of long type, the size of each element is sizeof(long)), and the sorting method of comparison size
long* pItem = (long*)bsearch(&target, (c.data()), ASIZE, sizeof(long), compareLongs); // First sort by qsort() and then search by bsearch()
cout << "qsort() + bsearch(), milli-second :" << (clock() - timeStart) << endl;
if(pItem != NULL)
cout << "found," << *pItem << endl;
else
cout << "not found!" << endl;
}
}

It can be seen from the above that in order to find a target element in the array container, the elements are generally sorted by qsort(), and then the binary method is used to find bsearch(), so a considerable part of the time is spent on the early sorting.
-Container vector
#include<vector>
#include<stdexcept>
#include<string>
#include<cstdlib> // absort()
#include<cstdio> // snprintf()
#include<iostream>
#include<ctime>
#include<algorithm> // sort()
namespace jj02{
void test_vector(long& value){
cout << "\n test_vector()...... \n";
vector<string> c;
char buf[10];
clock_t timeStart = clock();
for(long i = 0; i < value; i++){
try{
snprintf(buf, 10, "%d", rand());
c.push_back(string(buf)); // Because the element of vector is put in from the tail, push is used_ Back() instead of pushing_ front()
}
catch(exception& p){
cout << "i = " << i << " " << p.what() << endl;
// Once the highest i = 58389486 then std::bad_alloc
// Every time a new element is added, it is allocated by allocator when space needs to be expanded. When space is not available, it will be bad_alloc
abort(); // When bad happens_ When alloc, you need to terminate it with the abort() command
}
}
cout << "milli-seconds :" << (clock() - timeStart) << endl; // The time it takes to put the generated data into the container
cout << "vector.size() = " << c.size() << endl;
cout << "vector.front() = " << c.front() << endl; // Take out the first element in the container
cout << "vector.back() = " << c.back() << endl;
cout << "vector.data() = " << c.data() << endl; // Take out the address of the container at the beginning of memory
cout << "vector.capacity() = " << c.capacity() << endl;
string target = get_a_target_string();
{
timeStart = clock();
auto pItem = ::find(c.begin(), c.end(), target);
cout << "::find(), milli-seconds : " << (clock() - timeStart) << endl;
// find() returns an iterator, that is, an iterator (generic pointer), so it is pitem when judging= c. End() instead of pitem= NULL
if(pItem != c.end())
cout << "found, " << *pItem << endl;
else
cout << "not found " << endl;
}
{
timeStart = clock();
sort(c.begin(), c.end());
string* pItem = (string*)bsearch(&target, (c.data(), c.size(), sizeof(string));
cout << "sort()+bsearch(), milli-seconds : " << (clock() - timeStart) << endl;
if(pItem != NULL)
cout << "found, " << *pItem << endl;
else
cout << "not found! " << endl;
}
}
}
namespace xx {} its function is to open up a completely new memory space to perform operations, which can ensure that variables with the same name in different namespaces are irrelevant, such as namespace 01{int a = 0;} And namespace 02{int a = 1;} The address of variable a in is different.
The growth of vector container is twice the current space!! But note that instead of growing twice in the original space, find the space twice the size in another place, and then move into the new memory space one by one in the original space!! Because if you expand in the original location, it may conflict with other used memory, so it is to find a new and larger memory space and move the original data.
vector::size() is the total number of elements currently stored, and vector::capacity() is the total size of the current container.

-Container list

The list container has its own sort() function, which is better than using global:: sort() and using its own list::sort(). The global:: find() is significantly faster than list::sort().
-Container forward_list
It also has its own sort() function.
-Non standard library container slist (only for non-standard libraries under gun c, similar to the function of forward_list)

-Container deque
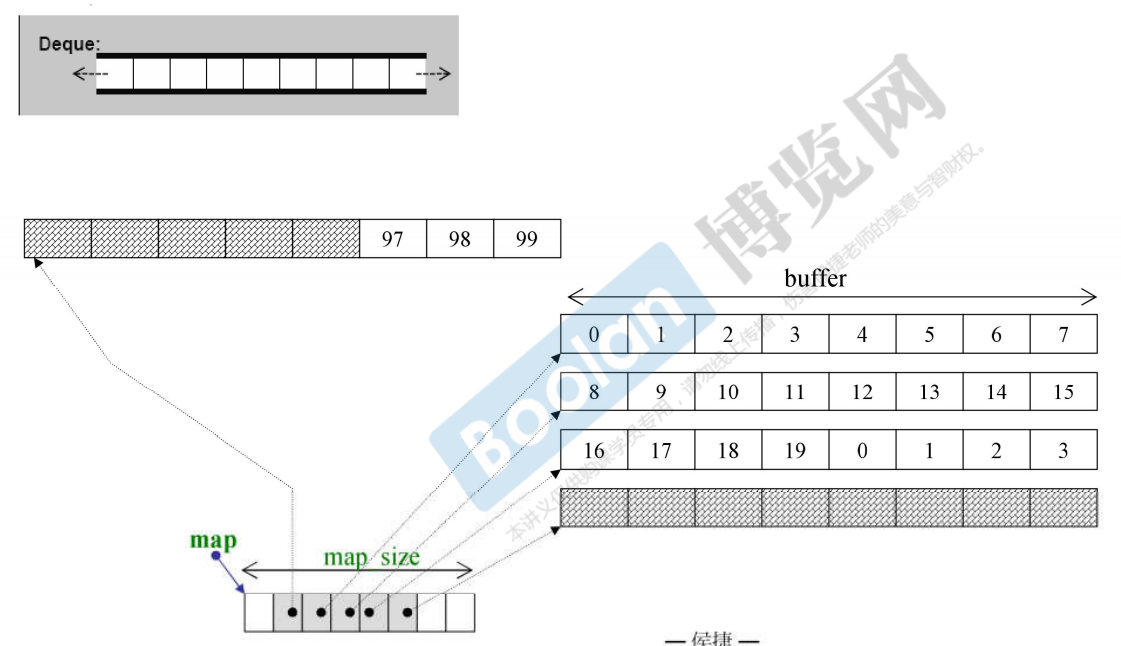
Its structure is that the bottom layer stores pointers, and then each pointer points to a section of buffer. Each buffer is placed with fixed elements, that is, it is piecewise continuous. But push to the right_ When back() is extended to the end of a buffer, it will jump to the beginning of the buffer pointed to by the next pointer; Push left_ When front() is extended to the end, a new buffer will be expanded to add new elements.
 There is no own sort(), so you can only use global:: sort().
There is no own sort(), so you can only use global:: sort().
-stack(deque adapter): the bottom layer is actually implemented by deque
 The placement elements are: push() and pop().
The placement elements are: push() and pop().
-queue(deque adapter): the bottom layer is actually implemented by deque
 The placement elements are: push() and pop().
The placement elements are: push() and pop().
Stack and queue do not provide the operation of iterator. Otherwise, you can use the pointer to add elements to any position in stack and queue at will. In this way, the characteristics of FIFO or LIFO cannot be guaranteed.
-Container multiset
The bottom is realized through the red black tree, and the data in it will be sorted when it is put in! And the elements put in can be repeated.
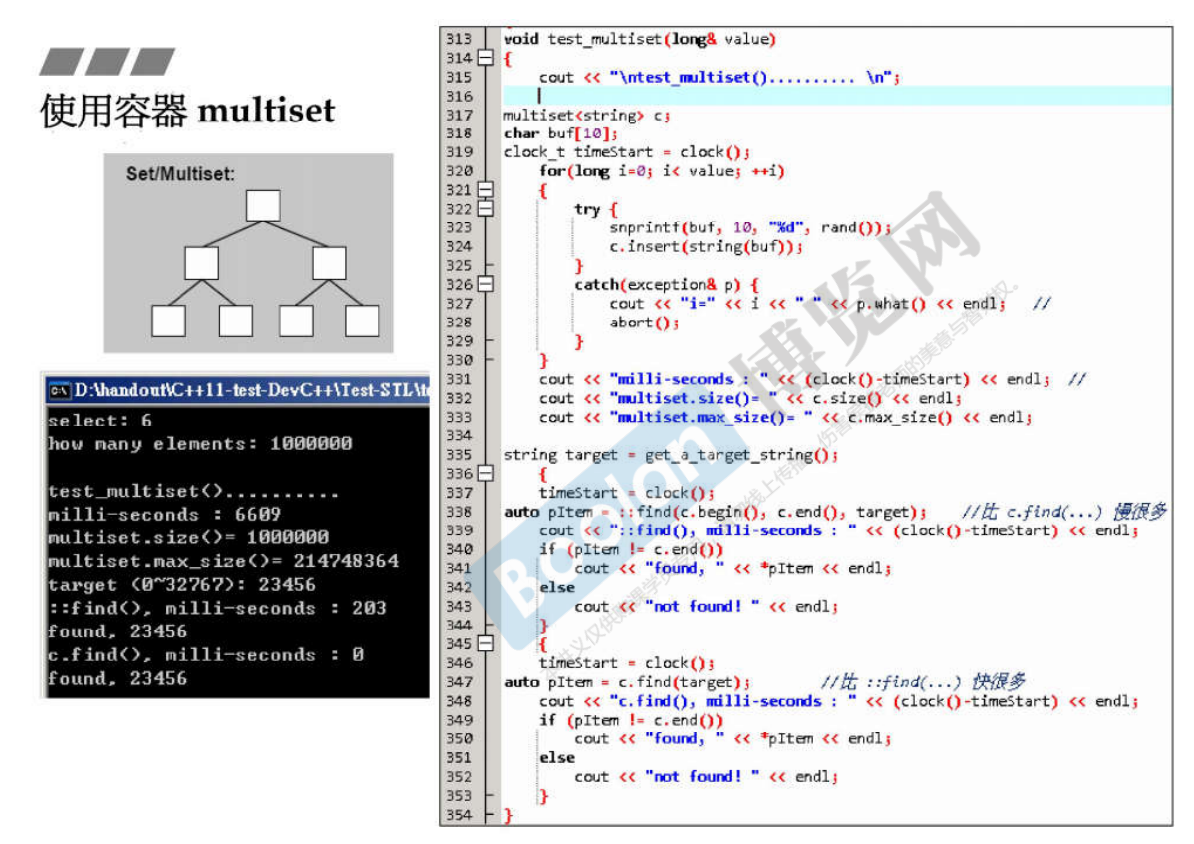 When inserting elements, because the key and value are the same, insert() such as insert (int a) only needs to insert one type of data.
When inserting elements, because the key and value are the same, insert() such as insert (int a) only needs to insert one type of data.
But pay attention to the difference from the insert() of map!!
-Container multimap
The bottom is realized through the red black tree, and the data in it will be sorted when it is put in! The value element can be repeated, but the key must be different!
 When inserting elements, the key and value are different, so insert() needs to insert elements in a pair, that is, insert (pair < long, string > (I, buf)). In addition, the key is used for searching, but [] cannot be used for insertion.
When inserting elements, the key and value are different, so insert() needs to insert elements in a pair, that is, insert (pair < long, string > (I, buf)). In addition, the key is used for searching, but [] cannot be used for insertion.
-Container unordered_multiset (the bottom is implemented by hash table)
 hash table has more buckets than data. Because some buckets are linked with table elements and some buckets are not linked, it is reasonable to have more buckets than data.
hash table has more buckets than data. Because some buckets are linked with table elements and some buckets are not linked, it is reasonable to have more buckets than data.
Rule of thumb: if the number of elements is equal to the number of buckets, the bucket will expand twice, and the elements will be scattered and hung on the bucket again.
-Container unordered_multimap (the bottom is implemented by hash table)

-Container set
 Because the elements put in by set are not repeatable, although 1000000 numbers are put in, there must be a lot of repetition in the selection from 0 to 32767, so actually only 32768 numbers are put in.
Because the elements put in by set are not repeatable, although 1000000 numbers are put in, there must be a lot of repetition in the selection from 0 to 32767, so actually only 32768 numbers are put in.
-Container map
 Note: here, you can put value into the corresponding key in the form of c[i] = string(buf), because the key here is specified that it cannot be repeated, so compared with multimap, it can use [] for insertion. In addition, since the keys here are different, 1000000 keys can be put in, even if the corresponding value behind them will be repeated.
Note: here, you can put value into the corresponding key in the form of c[i] = string(buf), because the key here is specified that it cannot be repeated, so compared with multimap, it can use [] for insertion. In addition, since the keys here are different, 1000000 keys can be put in, even if the corresponding value behind them will be repeated.
5, Distributor and its test

Note: when using additional allocators, you need to #include < ext... >, and it is in__ gnu_cxx:: each allocator called.
 Also note:
Also note:
If you want to bypass the container, you can also use allocator yourself. When telling you to allocate space, you only need to tell the number of allocator elements, such as p = alloca2 Allocate (100), but when you release space again, you need to pass in the corresponding pointer and the number of elements, such as alloc2 Deallocate (p, 100), that is to remember the original pointer p and 100 data behind it.
However, when using new and delete, there is no need to specify the number of specific elements.