1.caffeine features
Caffeine uses ConcurrentHashMap internally, provides a variety of cache elimination mechanisms (according to time, weight, quantity, etc.), and supports elimination notification. Moreover, caffeine has high cache performance on the premise of ensuring thread safety, which is known as the king of cache
1.1 official performance comparison
Scenario 1: 8 threads read, 100% read operation

Scenario 2: 6 threads for reading and 2 threads for writing, that is, 75% for reading and 25% for writing
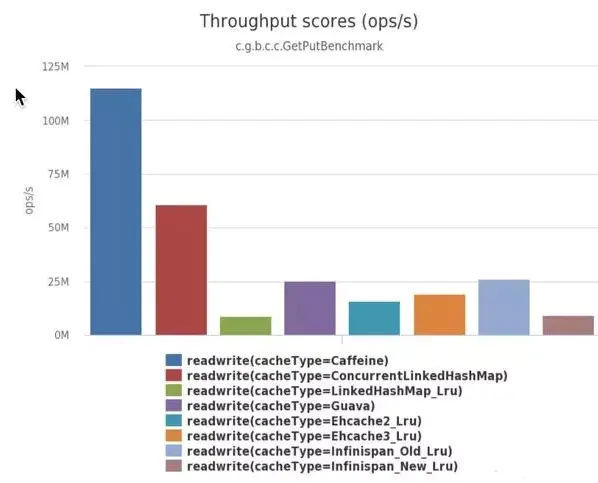
Scenario 3: 8 threads write, 100% write operation
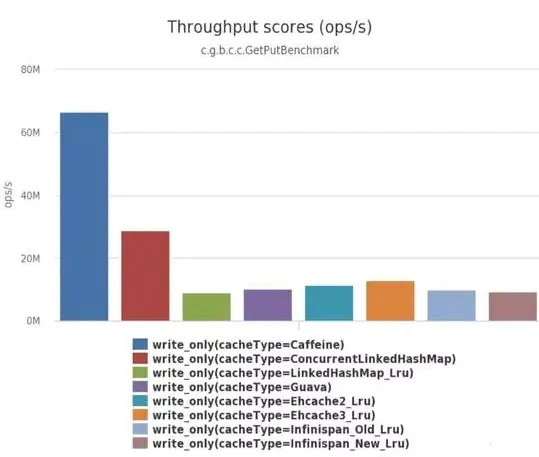
It can be clearly seen that Caffeine is significantly more efficient than other caches.
*1.2 internal structure diagram of caffeine*
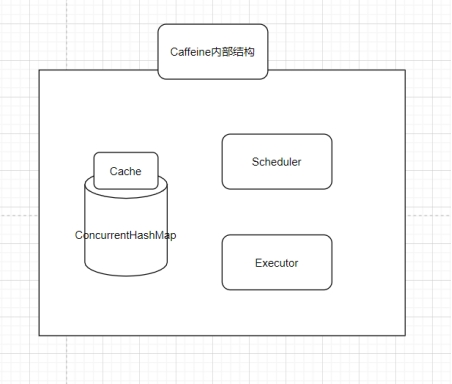
It can be seen that concurrent HashMap is used to cache data inside caffeine, and Scheduler mechanism is provided (regularly clearing and eliminating cache), as well as executor (thread pool for executing asynchronous tasks, which is mainly used to execute asynchronous query tasks and store them in cache in caffeine)
2 how to use Caffeine
*2.1 first introduce maven coordinates*
<dependency> <groupId>com.github.ben-manes.caffeine</groupId> <artifactId>caffeine</artifactId> <version>2.9.1</version> </dependency>
*2.2 several put modes of caffeine*
*The manual loading code is as follows*
//Manual loading
@Test
public void test() throws InterruptedException {
// Initialize the cache and set the maximum number of caches of 100
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.maximumSize(100)
.build();
int key1 = 1;
// Use the getIfPresent method to get the value from the cache. If the specified value does not exist in the cache, the method returns null:
System.out.println(cache.getIfPresent(key1));
// You can also use the get method to get the value, which passes in a Function with a key parameter as a parameter. If the key does not exist in the cache
// Then this function will be used to provide a default value, which will be inserted into the cache after calculation:
System.out.println(cache.get(key1, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer integer) {
return 2;
}
}));
cache.put(key1, 4);
// Verify whether the value corresponding to key1 is inserted into the cache
System.out.println(cache.getIfPresent(key1));
// Remove data and invalidate data
cache.invalidate(key1);
System.out.println(cache.getIfPresent(key1));
}Print results
null
2
4
null
There are two ways to get data mentioned above. One is getIfPercent. If there is no data, Null will be returned. If you get data, you need to provide a Function object. When there is no query key in the cache, this Function will be used to provide the default value and will be inserted into the cache, which can realize the effect that there is no query from other places in the cache!
If multiple threads get at the same time, will this Function object be executed multiple times?
In fact, it won't. as can be seen from the structure diagram, the main data structure inside Caffeine is a ConcurrentHashMap, and the final execution of the get process is ConcurrentHashMap Compute, which will be executed only once.
Practical application: you can use this manual loading mechanism, that is, in the apply Function of the Function object, when you can't get the data from the Caffeine cache, you can read the data from the database, and use this mechanism in combination with the database
Synchronous loading
@Test
public void test() {
// Initialize the cache. The maximum number of caches is 100
LoadingCache<Integer, Integer> cache = Caffeine.newBuilder()
.maximumSize(100)
.build(new CacheLoader<Integer, Integer>() {
@Nullable
@Override
public Integer load(@NonNull Integer key) {
return getInDB(key);
}
});
int key1 = 1;
// get data. If it cannot be obtained, the relevant data will be read from the database, and the value will also be inserted into the cache:
Integer value1 = cache.get(key1);
System.out.println(value1);
//get data. If it cannot be retrieved, execute the apply method of the function object to return
System.out.println(cache.get(2, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer key) {
return 888;
}
}));
// It supports direct get of a set of values and batch search
Map<Integer, Integer> dataMap
= cache.getAll(Arrays.asList(1, 2, 3));
System.out.println(dataMap);
}
/**
* Simulate reading key from database
*
* @param key
* @return
*/
private int getInDB(int key) {
return key + 1;
}Print results
2
888
{1=2, 2=888, 3=4}
The so-called synchronous loading data means that when the data cannot be obtained, the load function in the CacheLoader object provided during build construction will be called finally. If the return value is inserted into the cache and returned, which is a synchronous operation and supports batch search.
And synchronous loading supports manual loading
Practical application: you can use this synchronization mechanism, that is, in the load function in the CacheLoader object, when you can't get data from the cafeine cache, you can read data from the database, and use this mechanism in combination with the database
Asynchronous loading
Asynchronous manual loading
@Test
public void test2() throws ExecutionException, InterruptedException {
// Setting thread pool using executor
AsyncCache<String, Integer> asyncCache = Caffeine.newBuilder()
.maximumSize(100).executor(Executors.newSingleThreadExecutor()).buildAsync();
String key = "1";
// get returns completable future
CompletableFuture<Integer> future = asyncCache.get(key, new Function<String, Integer>() {
@Override
public Integer apply(String key) {
return getValue(key);
}
});
Integer value = future.get();
System.out.println("Current thread:" + Thread.currentThread().getName());
System.out.println(value);
}
private Integer getValue(String key) {
System.out.println("Asynchronous thread:"+Thread.currentThread().getName());
return Integer.valueOf(key)+1;
}The implementation results are as follows
Asynchronous thread: pool-1-thread-1
Current thread: main
2
As mentioned above, when the cache does not exist, the getValue method will be executed asynchronously and the value obtained by getValue will be put into the cache. You can see that getValue is executed in the thread provided by the thread pool (if the default thread pool is not specified), and asynccache Get () returns a completable future, which can be used to realize asynchronous serial parallel implementation.
Practical application: this asynchronous mechanism can be used in combination with the database when the data is obtained from the Caffeine cache for many times, and the version cannot get the data, and it takes a long time to read the data from the data source
Asynchronous Automatic Loading
@Test
public void test2() throws ExecutionException, InterruptedException {
// Setting thread pool using executor
AsyncLoadingCache<String, Integer> asyncCache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.MINUTES).maximumSize(100).executor(Executors.newSingleThreadExecutor()).buildAsync(key -> getValue(key));
String key = "1";
// get returns completable future
CompletableFuture<Integer> future = asyncCache.get(key);
Integer value = future.get();
System.out.println("Current thread:" + Thread.currentThread().getName());
System.out.println(value);
}
private Integer getValue(String key) {
System.out.println("Asynchronous thread:"+Thread.currentThread().getName());
return Integer.valueOf(key)+1;
}Print results
Asynchronous thread: pool-1-thread-1 Current thread: main 2
Like synchronous loading, when no data is obtained from the cache, it is obtained asynchronously from the getValue method specified when building the cache
Elimination mechanism
One of the most practical aspects of caffeine is its sound elimination mechanism. It provides the following elimination mechanisms
-
Based on size
-
Based on weight
-
Time based
-
Reference based
Size based elimination
The first is based on size elimination. The setting method is maximumsize (number), which means that recycling will occur when the cache size exceeds the configured size limit.
@Test
public void test5() throws InterruptedException {
// Initialize the cache, set the write expiration of 1 minute, and the maximum number of 100 caches
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.maximumSize(1)
.build();
int key1 = 1;
cache.get(key1, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer integer) {
return 2;
}
});
int key2 = 2;
cache.put(key2, 4);
Thread.sleep(1000);
System.out.println("Number of caches:"+cache.estimatedSize());
System.out.println("Cache residual value:"+cache.asMap().toString());
}Print results
Number of caches: 1
Cache remaining value: {2 = 4}
It can be seen that the main thread sleeps for one second after put ting in the second element. This is because the Scheduler mechanism mentioned above, that is, eliminating the cache is an asynchronous process. Based on the size elimination, the first in first out principle is followed to eliminate the first in value
Weight based elimination
/**
* Weight based elimination
*/
@Test
public void test6() throws InterruptedException {
// Initialize the cache, and set the value with the maximum weight of 4 as the weight calculation value
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.maximumWeight(4)
.weigher(new Weigher<Integer, Integer>() {
@Override
public int weigh(Integer key, Integer value) {
return value;
}
})
.build();
int key1 = 1;
cache.get(key1, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer integer) {
return 3;
}
});
int key2 = 2;
cache.put(key2,1);
int key3 = 3;
cache.put(key3,2);
Thread.sleep(1000);
System.out.println("Number of caches:"+cache.estimatedSize());
System.out.println("Cache residual value:"+cache.asMap().toString());
}Output results
Number of caches: 2
Cache remaining value: {2 = 1, 3 = 2}
As can be seen from the above, we set the maximum weight sum to 4. The calculation method of each cache weight is value. When putting a 3 and then putting a 1 and a 2, the total weight is 5, so the first 3 is eliminated. At this time, the total weight is 3 less than 4, so the final result is {2 = 1, 3 = 2}. When the total weight is greater than the maximum weight, the weight elimination method also follows the first in, first out elimination method
Then there is the time-based approach and the time-based recovery mechanism. Caffeine provides three types, which can be divided into:
-
Expiration after access, the time node starts from the last read or write, that is, get or put.
-
Expiration after writing. The time node is calculated from the beginning of writing, that is, put.
-
Customize the policy and specific expiration time.
Expire after access
@Test
public void test7() throws InterruptedException {
// Initialize the cache and set a 1-second read expiration
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterAccess(1, TimeUnit.SECONDS)
.build();
int key1 = 1;
// Then this function will be used to provide a default value, which will be inserted into the cache after calculation:
System.out.println(cache.get(key1, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer integer) {
return 2;
}
}));
Thread.sleep(2000);
System.out.println(cache.getIfPresent(key1));
}Print results
2 null
Expire after write
@Test
public void test8() throws InterruptedException {
// Initialize the cache and set a write expiration of 1 second
Cache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.build();
int key1 = 1;
// Then this function will be used to provide a default value, which will be inserted into the cache after calculation:
System.out.println(cache.get(key1, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer integer) {
return 2;
}
}));
Thread.sleep(2000);
System.out.println(cache.getIfPresent(key1));
}Print results
2 null
Custom policy
@Test
public void test9() throws InterruptedException {
Cache<Integer, Integer> cache = Caffeine.newBuilder().expireAfter(new Expiry<Integer, Integer>() {
//It expires one second after creation. It must take nanoseconds
@Override
public long expireAfterCreate(@org.checkerframework.checker.nullness.qual.NonNull Integer k, @org.checkerframework.checker.nullness.qual.NonNull Integer v, long l) {
return TimeUnit.SECONDS.toNanos(1);
}
//It expires two seconds after the update. It must take nanoseconds
@Override
public long expireAfterUpdate(@org.checkerframework.checker.nullness.qual.NonNull Integer k, @org.checkerframework.checker.nullness.qual.NonNull Integer v, long l, @NonNegative long l1) {
return TimeUnit.SECONDS.toNanos(2);
}
//It expires three seconds after access. It must take nanoseconds
@Override
public long expireAfterRead(@org.checkerframework.checker.nullness.qual.NonNull Integer k, @org.checkerframework.checker.nullness.qual.NonNull Integer v, long l, @NonNegative long l1) {
return TimeUnit.SECONDS.toNanos(3);
}
}).scheduler(Scheduler.systemScheduler()).build();
cache.put(1,1);
Thread.sleep(1000);
System.out.println(cache.getIfPresent(1));
cache.put(2,2);
cache.put(2,2);
Thread.sleep(1500);
System.out.println(+cache.getIfPresent(2));
cache.put(3,3);
System.out.println(cache.getIfPresent(3));
Thread.sleep(2000);
System.out.println(cache.getIfPresent(3));
}
}Print results
null 2 3 3
You can see that the Scheduler is set above. If the Scheduler is not set, the obsolete cache will be eliminated only when put or get, that is, the expired data will be cleared asynchronously when we operate the data
In addition, if you use the above scheduler The systemscheduler () timer will take effect only under the environment of java9. If it is java8, even if the scheduler is set Systemscheduler () is eliminated only when put or get. If it is java8, it needs to use the specified scheduler, such as scheduler forScheduledExecutorService(Executors.newScheduledThreadPool(1))
Reference elimination
Before talking about reference elimination, first clarify several types of references
-
Strong reference FinalReference
-
Soft reference
-
Weak reference
-
Phantom reference
These four references are provided for the following purposes:
-
Facilitate Jvm garbage collection
-
It is convenient for developers to use. Developers can flexibly determine the life cycle of some objects
Strong reference
Similar to Object object = new Object(); For such an object, only if the object has variable references, it will not be recycled by the jvm. If the memory is full, it will throw Java Lang.outofmemoryerror exception
@Test
public void test10(){
Car car;
List<Car> carList = new ArrayList<>();
for(int i=0;i<5;i++){
car = new Car("Trolley");
carList.add(car);
}
}
class Car{
public byte[] capacity;
private String name;
public Car(String name){
//Just because this object is big enough
capacity = new byte[1024*1024*500];
this.name = name;
}
}As shown above, the newly created object is always strongly referenced by the array in the list, and the strongly referenced object cannot be recycled, so the heap memory overflow finally throws Java Lang.outofmemoryerror exception
If the strongly referenced object needs to be recycled, it should be set to null. For example, car = new car ("trolley"); car = null;
Soft reference
Objects wrapped in soft references are recycled when the jvm runs out of memory
@Test
public void test11(){
List<SoftReference<Car>> softReferenceList = new ArrayList<>();
Car car;
for(int i=0;i<5;i++){
car = new Car("Trolley");
softReferenceList.add(new SoftReference<Car>(new Car("Trolley"+i)));
}
for(SoftReference<Car> softReference : softReferenceList){
System.out.println(softReference.get());
}
}Print as follows
null
null
Car{name = 'trolley 2'}
Car{name = 'trolley 3'}
Car{name = 'trolley 4'}
It can be seen that when the memory is insufficient, trolley 0 and trolley 1 are recycled
As mentioned above, soft references can be used in some data objects that are used less often. If the memory is insufficient, such objects will be recycled first to avoid memory overflow. When they need to be used, they will be loaded into the heap again
Weak reference
When an object is weakly referenced, it will be recycled by gc regardless of whether the memory is sufficient. The code is as follows
@Test
public void test12() throws InterruptedException {
WeakReference<String> weakReference = new WeakReference<>(new String("Spicy chicken"));
System.out.println("gc front:"+weakReference.get());
System.gc();
Thread.sleep(1000);
System.out.println("gc After:"+weakReference.get());
}Print as follows
Before gc: Spicy Chicken After gc: null
Virtual reference
As the name suggests, a virtual reference is a virtual reference. If an object has only virtual references, it is equivalent to that no references can be recycled by gc at any time
Its main function is to track the garbage collection activity of an object, which needs to be used in combination with ReferenceQueue
ReferenceQueue
ReferenceQueue reference can also be summarized as a member of the reference. It can be used in combination with the above three reference types [soft reference, weak reference and virtual reference].
When the Reference Queue is created by the service collector, it can be used as a garbage collection mechanism. When the Reference Queue is created by the service collector, it can be used as a garbage collection mechanism for other Reference queues.
For example, the following code registers ReferenceQueue with the creation of phantom reference
@Test
public void test12() throws InterruptedException {
WeakReference<String> weakReference = new WeakReference<>(new String("Spicy chicken"));
System.out.println("gc front:"+weakReference.get());
System.gc();
Thread.sleep(1000);
System.out.println("gc After:"+weakReference.get());
}The printing results are as follows
null The object was recycled end
Weak reference elimination mechanism
@Test
public void test14() throws InterruptedException {
Cache<Object, Object> cache = Caffeine.newBuilder()
// Set the Key as weak reference, and the life cycle is the next gc
// Set value as weak reference, and the life cycle is the next gc
.weakKeys().weakValues()
.build(key->key);
cache.put(new Integer(20),1);
cache.put(new Integer(30),1);
cache.put(new Integer(40),1);
cache.put(new Integer(50),1);
System.gc();
Thread.sleep(8000);
System.out.println(cache.estimatedSize());
}Print results
0
In the above example, the value added to the cache is not strongly referenced. The cache will wrap it as a weakly referenced object, which will be recycled during gc. Similarly, if the key is not strongly referenced, it will also be wrapped as a weakly referenced object, which will be recycled during gc
Soft reference elimination
@Test
public void test15() throws InterruptedException {
Cache<Object, Object> cache = Caffeine.newBuilder()
// Set the Key as weak reference, and the life cycle is the next gc
// Set value as weak reference, and the life cycle is the next gc
.softValues()
.build(key->key);
for(int i = 0 ; i<8; i++){
cache.put(1,new Car("Trolley"+i));
}
System.out.println(cache.estimatedSize());
}Print results
1 / / it may be others, depending on the size of your heap memory
There are three things to pay attention to here
-
System.gc() doesn't necessarily trigger GC, but it's just a notification mechanism, but it doesn't necessarily happen. It's uncertain whether the garbage collector will perform GC or not. Therefore, it's possible to see that the system is calling after setting weakKeys There is no loss of cached data during GC ().
-
The asynchronous loading method does not allow the use of reference elimination mechanism, and an error will be reported when starting the program: Java Lang. IllegalStateException: weak or soft values can not be combined with asynccache. It is speculated that the reason is caused by the conflict between the life cycle of asynchronously loaded data and the life cycle of reference elimination mechanism, so Caffeine does not support it.
-
When using the reference elimination mechanism, judge whether two keys or two value s are the same, using = =, rather than equals(), that is, two keys need to point to the same object to be considered consistent, which is likely to lead to unexpected problems in cache hit.
-
weakValues and softValues cannot be used at the same time
Refresh mechanism
If you want the cache to expire x seconds after writing and refresh the data from the data source x seconds after writing, you can use caffeine's refresh mechanism
int i = 1;
//
@Test
public void test4() throws InterruptedException {
// Set the data to expire 3 seconds after writing, and refresh the data if there is data access 2 seconds later
LoadingCache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterWrite(3, TimeUnit.SECONDS)
.refreshAfterWrite(2, TimeUnit.SECONDS)
.build(new CacheLoader<Integer, Integer>() {
@Nullable
@Override
public Integer load(@NonNull Integer key) {
return getInDB();
}
});
cache.put(1, getInDB());
// Sleep for 2.5 seconds, then take value
Thread.sleep(2500);
//Note that the old value is returned at this time, and the refreshed value will not take effect until the next access
System.out.println(cache.getIfPresent(1));
// Sleep for 1.5 seconds, then take value
Thread.sleep(1500);
System.out.println(cache.getIfPresent(1));
}
private int getInDB() {
// Here, in order to reflect that the data is refreshed, index is used++
i++;
return i;
}
Print results
2 3
Obsolescence notification callback
In business, we may encounter some business operations after the cache is eliminated. For example, when the cache is eliminated, it is updated to the database, and caffeine also provides an elimination notification callback
@Test
public void test17() throws InterruptedException {
LoadingCache<Integer, Integer> cache = Caffeine.newBuilder()
.expireAfterAccess(1, TimeUnit.SECONDS)
.scheduler(Scheduler.forScheduledExecutorService(Executors.newScheduledThreadPool(1)))
// Added obsolete monitoring
.removalListener(((key, value, cause) -> {
System.out.println("Elimination notice, key: " + key + ",reason:" + cause);
}))
.build(new CacheLoader<Integer, Integer>() {
@Override
public @Nullable
Integer load(@NonNull Integer key) throws Exception {
return key;
}
});
cache.put(1, 2);
Thread.sleep(3000);
}Print results
Elimination notice, key: 1, reason: EXPIRED
The above reasons, that is, the reasons for elimination, have the following results
-
EXPLICIT: if this is the reason, it means that the data has been remove d manually.
-
REPLACED: it refers to the replacement, that is, the removal caused by the old data being overwritten when the data is put.
-
COLLECTED: this ambiguous point is actually caused by collection, that is, garbage collection. Generally, weak reference or soft reference will lead to this situation.
-
EXPIRED: the reason why the data is EXPIRED without explanation.
-
SIZE: removal caused by exceeding the limit.