1. Core structure and concept
The Validator process provided by calculate is extremely complex, but to sum up, it mainly does one thing: verify whether the semantics of each SqlNode is correct in combination with metadata. These semantics include:
- Verify whether the table name exists;
- Whether the selected column exists in the corresponding table and whether the matched column name is unique. For example, join multiple tables and two tables have fields with the same name. If the selected column does not specify a table name, an error will be reported;
- If it is an insert, you need to insert columns and data sources for verification, such as column number, type, permission, etc;
- ......
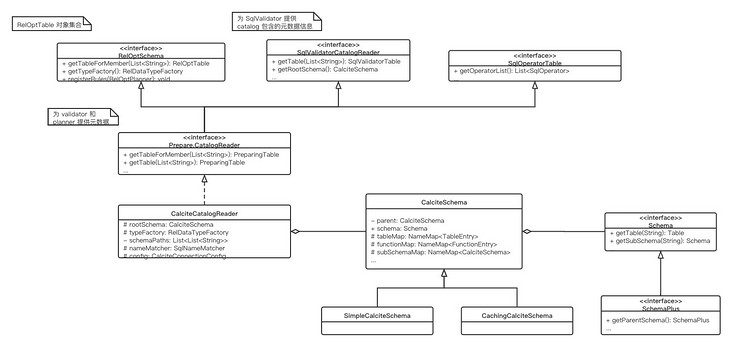
The validator provided by calculate is closely related to the previously mentioned Catalog. Calculate defines a CatalogReader to access metadata (Table schema) during verification, and encapsulates the metadata at runtime. The two core parts are SqlValidatorNamespace and SqlValidatorScope.
- SqlValidatorNamespace: describes the relationship returned by SQL query. An SQL query can be divided into multiple parts, such as query column combination, table name, etc. each part has a corresponding SqlValidatorNamespace.
- SqlValidatorScope: it can be considered as the working context of each SqlNode in the verification process. When the expression is verified, it is resolved through the resolve method of SqlValidatorScope. If it is successful, the corresponding SqlValidatorNamespace description result type will be returned.
On this basis, calculate provides the SqlValidator interface, which provides all the core logic related to verification, and provides the built-in default implementation class SqlValidatorImpl, which is defined as follows:
public class SqlValidatorImpl implements SqlValidatorWithHints {
// ...
final SqlValidatorCatalogReader catalogReader;
/**
* Maps {@link SqlNode query node} objects to the {@link SqlValidatorScope}
* scope created from them.
*/
protected final Map<SqlNode, SqlValidatorScope> scopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its WHERE and HAVING
* clauses.
*/
private final Map<SqlSelect, SqlValidatorScope> whereScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its GROUP BY clause.
*/
private final Map<SqlSelect, SqlValidatorScope> groupByScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its SELECT and HAVING
* clauses.
*/
private final Map<SqlSelect, SqlValidatorScope> selectScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its ORDER BY clause.
*/
private final Map<SqlSelect, SqlValidatorScope> orderScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node that is the argument to a CURSOR
* constructor to the scope of the result of that select node
*/
private final Map<SqlSelect, SqlValidatorScope> cursorScopes =
new IdentityHashMap<>();
/**
* The name-resolution scope of a LATERAL TABLE clause.
*/
private TableScope tableScope = null;
/**
* Maps a {@link SqlNode node} to the
* {@link SqlValidatorNamespace namespace} which describes what columns they
* contain.
*/
protected final Map<SqlNode, SqlValidatorNamespace> namespaces =
new IdentityHashMap<>();
// ...
}You can see that there are many scopes mappings (sqlnode - > SqlValidatorScope) and namespaces (sqlnode - > sqlvalidatorspace) in SqlValidatorImpl. Verification is actually the process of verifying sqlvalidatorspace in each SqlValidatorScope. In addition, SqlValidatorImpl has a member catalogReader, that is, the SqlValidatorCatalogReader mentioned above, SqlValidatorImpl provides an entry to access metadata. (Note: for simplicity, the following articles refer to SqlValidatorScope with scope and SqlValidatorNamespace with namespace).
2. Entry function
In the introduction to SqlNode in Chapter 3, we realize that SqlNode is a nested tree structure. Therefore, it is natural for us to think of using some ideas or algorithms to deal with the tree data structure to deal with the whole SqlNode tree. Based on this idea, calculate traverses each SqlNode recursively and verifies the metadata for each SqlNode.
The verification process is extremely cumbersome. In order to focus on the core logic, we take the SQL in the following code block as an example. The SQL syntax is simple, but it is also a complete ETL process, and the SQL covers the two most common DML statements, INSERT and SELECT.
INSERT INTO sink_table SELECT id FROM source_table WHERE id > -1
The overall entry of SQL verification is the validate(SqlNode topNode) method of SqlValidatorImpl.
public SqlNode validate(SqlNode topNode) {
SqlValidatorScope scope = new EmptyScope(this);
scope = new CatalogScope(scope, ImmutableList.of("CATALOG"));
final SqlNode topNode2 = validateScopedExpression(topNode, scope);
final RelDataType type = getValidatedNodeType(topNode2);
Util.discard(type);
return topNode2;
}First, SqlValidatorImpl will create a CatalogScope as the outermost working context for subsequent verification. This scope is also the parent scope of some later namespace s. After the scope is created, the calculate verification will enter the validatesecopedexpression. (EmptyScope exists to make it easier to deal with the problem of empty judgment, and provides some core parsing logic, which is similar to a root scope)
private SqlNode validateScopedExpression(
SqlNode topNode,
SqlValidatorScope scope) {
// 1. Specify SqlNode
SqlNode outermostNode = performUnconditionalRewrites(topNode, false);
// ...
// 2. Register namespace and scope information
if (outermostNode.isA(SqlKind.TOP_LEVEL)) {
registerQuery(scope, null, outermostNode, outermostNode, null, false);
}
// 3. Check
outermostNode.validate(this, scope);
// ...
return outermostNode;
}The first step of performunconditional rewrites is to standardize our SqlNode to simplify subsequent verification processing. The contents of the specification include but are not limited to the following points:
- If a SELECT clause has an ORDER BY keyword, SQL Parser will parse the entire SELECT clause into SqlOrderBy, and in this step will convert SqlOrderBy into SqlSelect;
- Set sourceSelect for SqlDelete and SqlUpdate (this is a SqlSelect), and their sourceSelect will be verified (i.e. validateSelect) when these two types are verified later;
- ......
In the second step, registerQuery will create the namespace and scope corresponding to the SqlNode, and inject the namespace into the corresponding scope. The following information can be obtained by debugging SQL in this example:
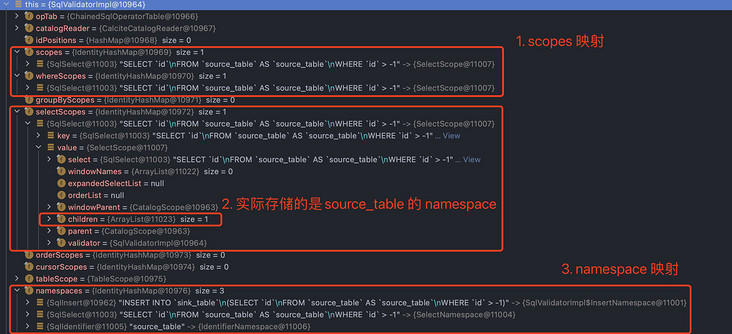
- The first part is the scope mapping, which contains the name resolution space corresponding to each part of the SQL text. Generally, SELECT is a complete space. The scope of sub clauses such as where and groupBy is also the SelectScope of the SELECT clause to which they belong;
- The second part is about injecting namespace into scope. SelectScope inherits ListScope and has a member variable children, which will store the namespace corresponding to the selected data source. For example, source is stored in this example_ Identifier namespace corresponding to table;
- The last part is the namespace mapping. INSERT, SELECT or a specific table and view will have a corresponding namespace to represent the data relationship of their execution results.
The third step checks the validate method of calling SqlNode. In the preceding example, it will take SqlInsert validate and call validateInsert of SqlValidatorImpl.
public void validateInsert(SqlInsert insert) {
// 1. Verify the namespace
final SqlValidatorNamespace targetNamespace = getNamespace(insert);
validateNamespace(targetNamespace, unknownType);
// ...
// Calculate / verify insert columns. Insert statements can be inserted in two forms
// `insert sink_table values(...): insert columns are not specified. All columns are selected by default
// `insert sink_table(idx): Specifies the insertion column
final RelDataType targetRowType = createTargetRowType(table, insert.getTargetColumnList(), false);
// 2. Verify source
final SqlNode source = insert.getSource();
if (source instanceof SqlSelect) {
final SqlSelect sqlSelect = (SqlSelect) source;
validateSelect(sqlSelect, targetRowType);
} else {
final SqlValidatorScope scope = scopes.get(source);
validateQuery(source, scope, targetRowType);
}
// ...
// 3. Verify whether source and sink are compatible
checkFieldCount(insert.getTargetTable(), table, source,
logicalSourceRowType, logicalTargetRowType);
checkTypeAssignment(logicalSourceRowType, logicalTargetRowType, insert);
checkConstraint(table, source, logicalTargetRowType);
validateAccess(insert.getTargetTable(), table, SqlAccessEnum.INSERT);
}The core logic of validateInsert has three blocks:
- Verify the namespace;
- Verify the source of SqlInsert. In this case, the source is a SqlSelect, so it will go to validateSelect;
- Verify that the source and target tables are compatible
3. Verify the namespace
When verifying the metadata of the namespace, calculate adopts the template method design pattern. The main verification process is defined in the validate method of AbstractNamespace, and the real verification logic (validateImpl) is handed over to each specific namespace.
There is a member variable rowType in the AbstarctNamespace. Verifying the namespace is actually parsing the value of the rowType and assigning it to the corresponding namespace.

3.1 SqlValidatorImpl.validateNamespace
The entry to verify the namespace is validateNamespace, which is shown in the following code: verify the namespace, establish the mapping relationship between SqlNode → RelDataType, and put it into nodeToTypeMap..
protected void validateNamespace(final SqlValidatorNamespace namespace,
RelDataType targetRowType) {
// 1. Template method verification namespace
namespace.validate(targetRowType);
if (namespace.getNode() != null) {
// 2. Establish the mapping relationship between sqlnode - > reldatatype
setValidatedNodeType(namespace.getNode(), namespace.getType());
}
}3.2 AbstractNamespace.validate
The main verification procedure of namespace is defined by the validate method
public final void validate(RelDataType targetRowType) {
switch (status) {
// 1. When entering this method for the first time, the status is invalid
case UNVALIDATED:
try {
// 2. Mark status as being processed to avoid repeated processing
status = SqlValidatorImpl.Status.IN_PROGRESS;
Preconditions.checkArgument(rowType == null,
"Namespace.rowType must be null before validate has been called");
// 3. Call the validateImpl of each implementation
RelDataType type = validateImpl(targetRowType);
Preconditions.checkArgument(type != null,
"validateImpl() returned null");
// 4. Record the result type obtained by parsing
setType(type);
} finally {
// 5. Mark status completed
status = SqlValidatorImpl.Status.VALID;
}
break;
case IN_PROGRESS:
throw new AssertionError("Cycle detected during type-checking");
case VALID:
break;
default:
throw Util.unexpected(status);
}
}To remove the status tag update, the actual steps of validate are also two steps:
- Call the validateImpl method implemented by each namespace to obtain the corresponding type (RelDataType);
- Assign the parsed type to the rowType of the namespace.
Taking the above example as an example, SqlInsert will first verify its corresponding InsertNamespace. InsertNamespace does not implement its own validateImpl method, but it inherits the Identifier namespace and will directly call the validateImpl of the Identifier namespace. Therefore, the verification of InsertNamespace is to resolve the rowType of target table (which is an Identifier).
3.3 validateImpl(IdentifierNamespace)
The identifier namespace has a member resolvedNamespace (also a sqlvalidator namespace). When the SqlNode corresponding to the identifier namespace points to a table, the resolvedNamespace is a TableNamespace with real type information.
public RelDataType validateImpl(RelDataType targetRowType) {
// 1. Resolve the namespace corresponding to the identifier, usually TableNamespace
resolvedNamespace = Objects.requireNonNull(resolveImpl(id));
// ...
// 2. Get rowType. It needs to be calculated during the first execution
RelDataType rowType = resolvedNamespace.getRowType();
// ...
return rowType;
}The identifier namespace will call resolveImpl to get the corresponding TableNamespace, and then call resolvedNamespace.getRowType() to get the rowType.
3.3.1 IdentifierNamespace.resolveImpl
In resolveImpl, IdentifierNamespace will create a SqlValidatorScope.ResolvedImpl to store the resolved TableNamespace.
private SqlValidatorNamespace resolveImpl(SqlIdentifier id) {
// ...
parentScope.resolveTable(names, nameMatcher,
SqlValidatorScope.Path.EMPTY, resolved);
// ...
return resolve.namespace;
}The parentScope here is actually the CatalogScope created at the beginning. It is almost an empty implementation. After layers of calls, it will finally be transferred to the resolve of EmptyScope_ method.
3.3.2 EmptyScope.resolve_
Here, the getTable of the CalciteSchema in parentScope (SqlValidatorImpl in parentScope, CalciteCatalogReader in SqlValidatorImpl, and CalciteSchema in CalciteCatalogReader) will be called to get the TableEntryImpl object (as defined below),
public static class TableEntryImpl extends TableEntry {
private final Table table;
// ...
public Table getTable() {
return table;
}
}The whole call chain is shown in the figure:
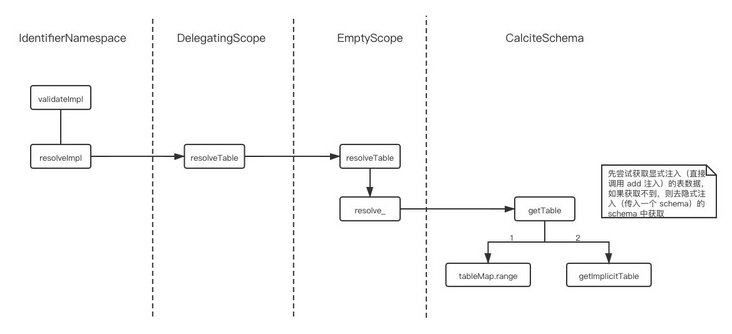
Get the TableEntryImpl object and get the Table data we registered through TableEntryImpl.getTable().
public static class TableEntryImpl extends TableEntry {
private final Table table;
// ...
public Table getTable() {
return table;
}
}After getting the Table, it will try to convert it into a sqlvalidator Table (the actual type is reopttableimpl) and register it in the TableNamespace.
The most important thing is step 3. Here we use the getRowType() method of the Table interface to obtain the rowType. If we have a custom Table that implements the Table interface, we can also customize the returned row type by overriding getRowType(). After getting the rowType, assign the rowType to table2 and create a TableNamespace based on table2.
Until the resolveImpl is executed, we have to get the TableNamespace, which holds a table variable and a rowType of RelDataType inherited from AbstractNamespace. rowType records the row data type corresponding to this namespace. At this time, the TableNamespace has just been created and the rowType is null.
It should be noted that at this time, the rowType is only assigned to the table in the TableNamespace, and the rowType saved by the TableNamespace is still null (this may be an optimization point, which can reduce the subsequent additional steps of verifying the TableNamespace, but it may also be considering that the TableNamespace has just been created and the status is still invalid)
3.4 calculated rowType
Therefore, when the validateNamespace function of identifier namesapce proceeds to the second step: RelDataType rowType = resolvedNamespace.getRowType();, Because the rowType is empty, the verification of TableNamespace will be triggered again.
public RelDataType getRowType() {
if (rowType == null) {
validator.validateNamespace(this, validator.unknownType);
Preconditions.checkArgument(rowType != null, "validate must set rowType");
}
return rowType;
}After verifying the TableNamespace, return to AbstractNamespace.validate (at this time, the real type of the AbstractNamespace is IdentifierNamespace), we get the row type information corresponding to the IdentifierNamespace (that is, the rowType of resolvedNamespace), and inject it into the IdentifierNamespace through setType. At this time, the verification of the IdentifierNamespace is completed.
3.4.1 validateImpl(TableNamespace)
The validateImpl implementation of TableNamespace is as follows:
protected RelDataType validateImpl(RelDataType targetRowType) {
if (extendedFields.isEmpty()) {
return table.getRowType();
}
final RelDataTypeFactory.Builder builder =
validator.getTypeFactory().builder();
builder.addAll(table.getRowType().getFieldList());
builder.addAll(extendedFields);
return builder.build();
}As mentioned earlier, after EmptyScope.resolve_ Method, the table bound in the TableNamespace has injected rowType information, so it can be directly obtained and returned here.
Back to AbstractNamespace.validate (at this time, the real type of the AbstractNamespace is TableNamespace), we get the row type information corresponding to the TableNamespace (that is, the rowType of its TableNamespace), inject it into the TableNamespace through setType, and complete the verification of the TableNamespace.
3.5 summary
The following figure shows the complete process of identifier namespace verification.

4. Verify source
Verifying the source is a process of verifying the select. Continuing with the above example, the statement corresponding to the verified SqlNode (the actual type is SqlSelect) is select id as IDX from source_ Table where id > - 1, SqlSelect has its own bound SelectNamespace and, of course, a part of verifying the namespace (inject rowType attribute into the bound SelectNamespace).
The entry function of validation select is validateSelect. The following figure shows the workflow of the whole validateSelect.

You can see that validateSelect validates each component of the select statement. The most important one is validateSelectList. This method verifies whether the selected column exists (can be retrieved from the data source table) and establishes the corresponding type information (RelDataType) for the columns found in this part, that is, the rowType of the SelectNamespace.
For example, select id from source_ If table where id > - 1, validateSelectList needs to verify whether the column ID is in source_ Exists in table.
5. Verify whether source and target are compatible
The verification of this part includes four parts:
- checkFieldCount: check whether the number of inserted data columns is legal and non empty;
- checkTypeAssignment: check whether the types of the corresponding columns of the source column and the insert table are compatible;
- checkConstraint: constraint check;
- validateAccess: permission verification can be passed by default.
6. References
- Apache compute tutorial - validate validation: https://blog.csdn.net/QXC1281...