Note: the places that need to be installed and configured are in the final reference materials
1, Upload the files to be analyzed (no less than 100000 English words) to HDFS

demo.txt is the file to be analyzed
Start Hadoop

Upload the file to the input folder of hdfs

Ensure successful upload
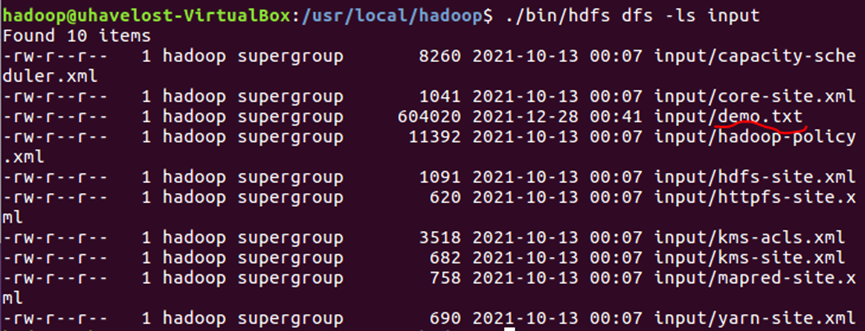
2. Call MapReduce to count the number of occurrences of each word in the file
Open Eclipse and configure MapReduce to see the file
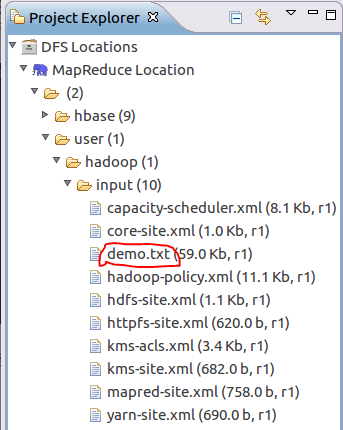
Create MapReduce project
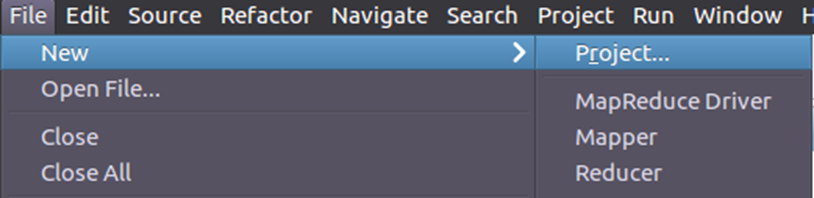
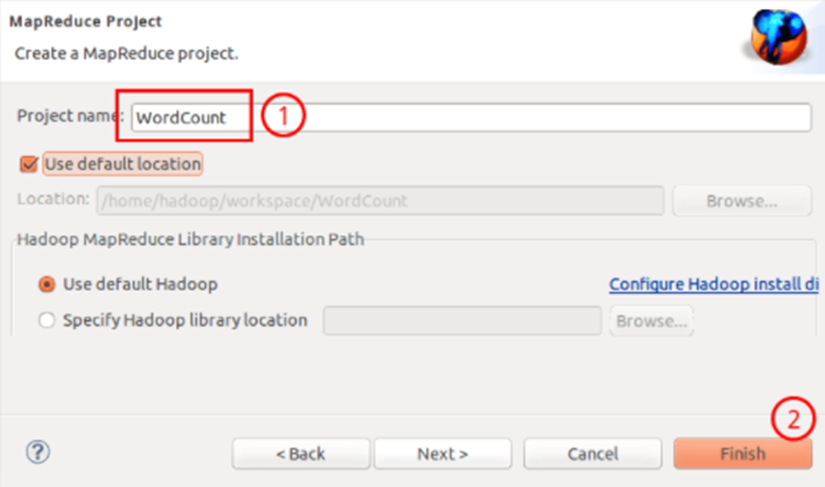
Select Map/Reduce Project and click next
Fill in the Project name as WordCount and click Finish to create the project
Add the required JAR packages for the project
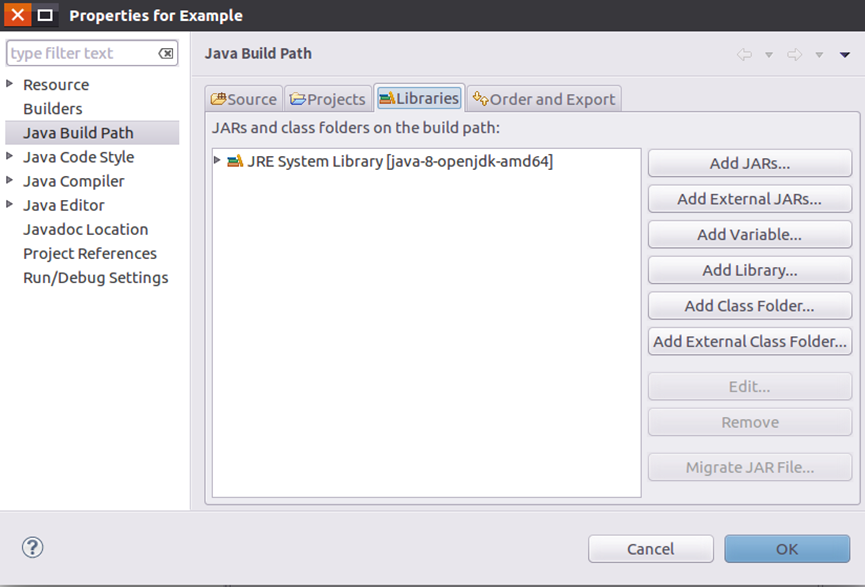
Click the "Add External JARs..." button on the right side of the interface to pop up the interface as shown in the following figure
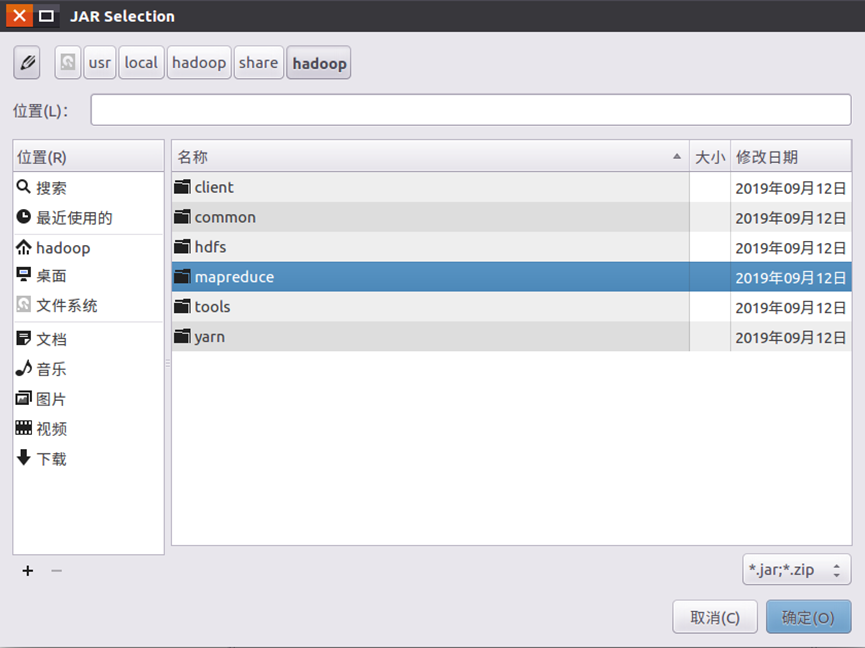
(1) hadoop-common-3.1.3.jar and haoop-nfs-3.1.3.jar under "/ usr/local/hadoop/share/hadoop/common";
(2) All jars in the "/ usr/local/hadoop/share/hadoop/common/lib" directory
(3) All JAR packages under "/ usr/local/hadoop/share/hadoop/mapreduce" directory, but excluding jdiff, lib, lib examples and sources directories.
(4) All JAR packages in the "/ usr/local/hadoop/share/hadoop/mapreduce/lib" directory
Then right-click the newly created WordCount item and select new - > class
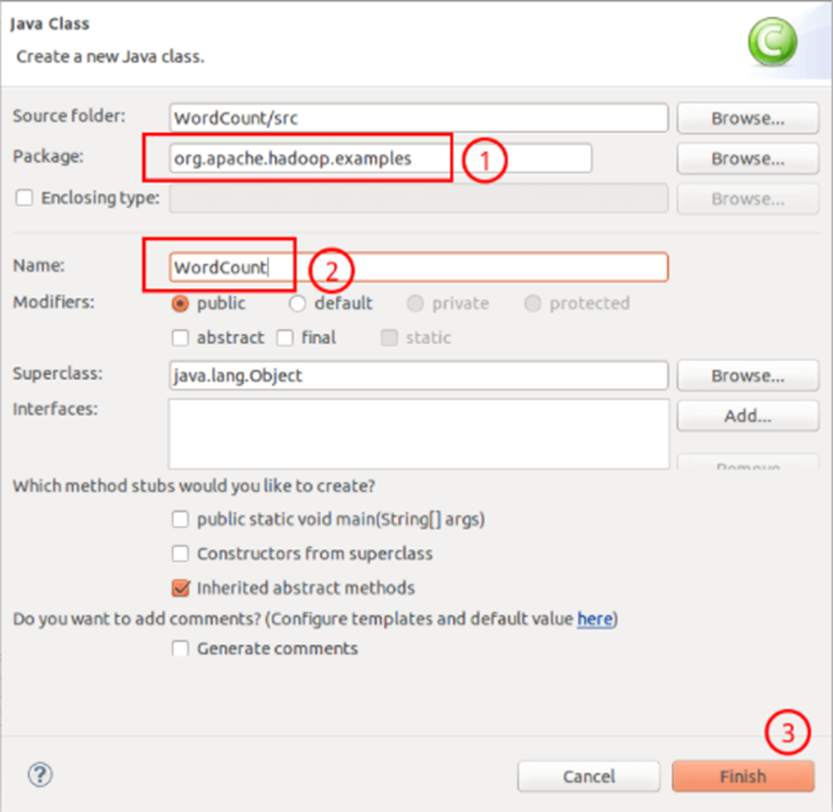
Fill in org. In Package apache. hadoop. examples; Fill in WordCount in the Name field
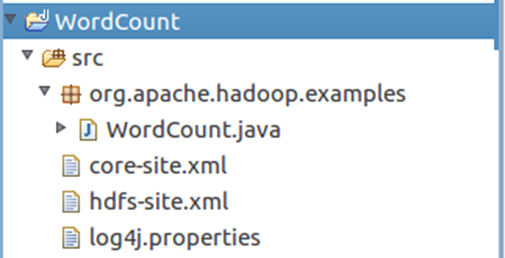
After creating the Class, you can see WordCount in the src of Project Java this file. Copy the following WordCount code into the file
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}Before running the MapReduce program, copy the modified configuration files in / usr/local/hadoop/etc/hadoop (such as core-site.xml and hdfs-site.xml required for pseudo distribution) and log4j.properties to the src folder (~ / workspace/WordCount/src) under the WordCount project:
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src
After copying, right-click WordCount and select refresh to refresh. You can see the file structure as follows:
Set the input parameters in the code. String [] otherargs = new genericoptionsparser (CONF, args) of the code main() function can be getRemainingArgs();
Replace with:
String[] otherArgs=new String[]{"input","output"};
After setting parameters, run the program and you can see the prompt of successful operation. After refreshing DFS Location, you can also see the output folder of output
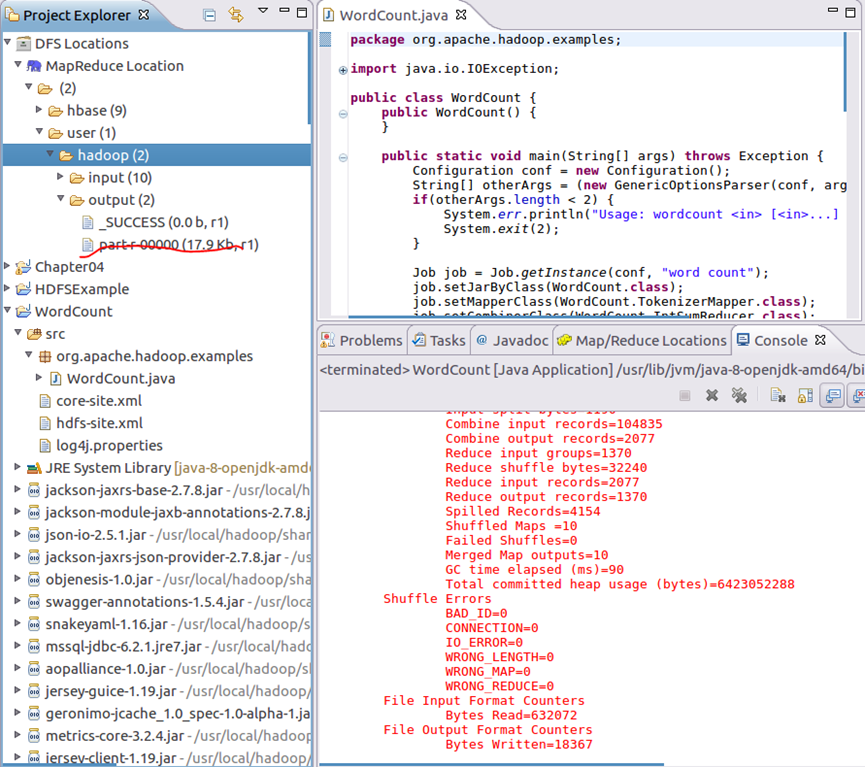
After executing the MapReduce project WordCount, you can see the output result in the file part-r-00000 of output
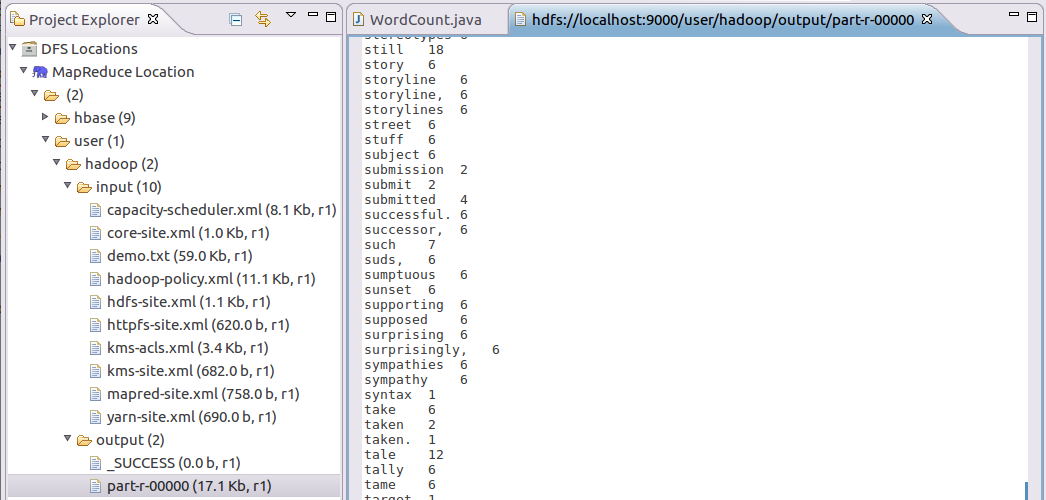
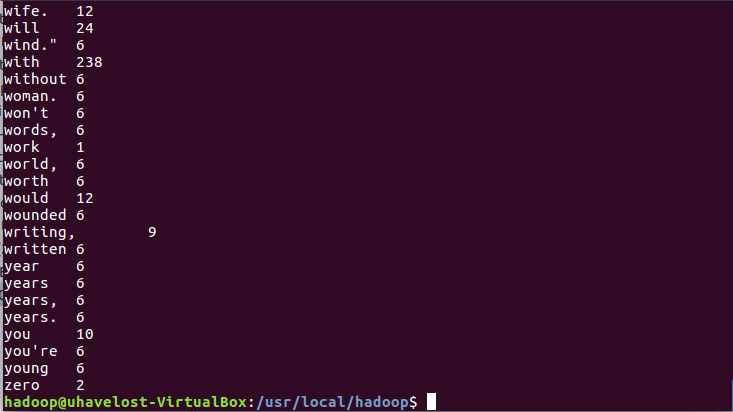
Use the command to view the output results

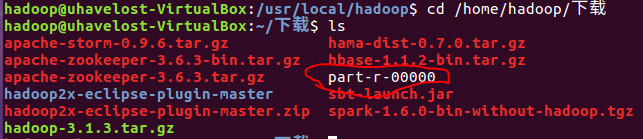
III. download the statistical results to the local

4, Reference materials
Install Ubuntu
http://dblab.xmu.edu.cn/blog/2760-2/
Create Hadoop account and configure SSH; Install Hadoop and java; Hadoop pseudo distributed configuration
http://dblab.xmu.edu.cn/blog/2441-2/
Install Eclipse and configure Hadoop Eclipse plugin
http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/