This article is shared from Huawei cloud community< Application of C++20 co process in event driven code >Original author: feideli.
The problem of embedded event driven code
Event driven is a common code model. It usually has a main loop that continuously receives events from the queue and then distributes them to the corresponding functions / modules for processing. Common software using event driven model includes graphical user interface (GUI), embedded device software, network server and so on.
This paper takes a highly simplified embedded processing module as an example of event driven code: assuming that the module needs to process user commands, external messages, alarms and other events and distribute them in the main loop, the example code is as follows:
#include <iostream>
#include <vector>
enum class EventType {
COMMAND,
MESSAGE,
ALARM
};
// Used only to simulate the sequence of events received
std::vector<EventType> g_events{EventType::MESSAGE, EventType::COMMAND, EventType::MESSAGE};
void ProcessCmd()
{
std::cout << "Processing Command" << std::endl;
}
void ProcessMsg()
{
std::cout << "Processing Message" << std::endl;
}
void ProcessAlm()
{
std::cout << "Processing Alarm" << std::endl;
}
int main()
{
for (auto event : g_events) {
switch (event) {
case EventType::COMMAND:
ProcessCmd();
break;
case EventType::MESSAGE:
ProcessMsg();
break;
case EventType::ALARM:
ProcessAlm();
break;
}
}
return 0;
}This is only a minimalist model example. The real code is much more complex than it. It may also include: obtaining events from a specific interface, parsing different event types, and using table driven methods for distribution... However, these have little to do with this article and can be ignored for the time being.
This model is represented by a sequence diagram, which is generally as follows:
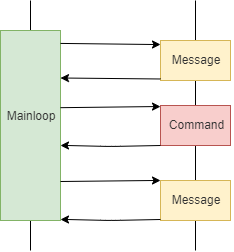
In actual projects, a problem often encountered is that some events take a long time to process. For example, a command may require thousands of hardware operations in batch:
void ProcessCmd()
{
for (int i{0}; i < 1000; ++i) {
// Operating hardware interface
}
}This event handler blocks the main loop for a long time, causing other events to queue up all the time. If all events have no requirements for response speed, it will not cause problems. However, in the actual scenario, there are often some events that need to be responded in time. For example, after some alarm events occur, service switching needs to be performed quickly, otherwise it will cause losses to users. At this time, events that take a long time to deal with will cause problems.
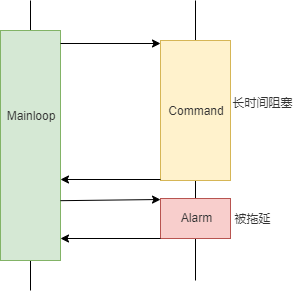
One might think of adding an additional thread dedicated to handling high priority events, which is indeed a common method in practice. However, in embedded systems, event handling functions can read and write many public data structures and operate hardware interfaces. If called concurrently, it is very easy to lead to all kinds of data competition and hardware operation conflict, and these problems are often difficult to locate and solve. What about locking on the basis of multithreading—— Designing which locks and where to add them are also very brain burning and error prone work. If you wait too much for mutual exclusion, it will also affect the performance and even cause troublesome problems such as deadlock.
Another solution is to cut the task with long processing time into many small tasks and rejoin it into the event queue. This will not block the main loop for a long time. How to cut the process into a big headache? When coding, programmers need to analyze all the context information of the function process, design data structures to be stored separately, and establish special events related to these data structures. This often leads to several times the amount of additional code and workload.
This problem exists in almost all event driven software, but it is particularly prominent in embedded software. This is because the CPU, thread and other resources in the embedded environment are limited, while the real-time requirements are high and the concurrent programming is limited.
C++20 language provides a new solution to this problem: collaborative process.
Brief introduction to the collaborative process of C++20
As for what coroutine is, it is well introduced in wikipedia[1] and other materials, which will not be repeated in this article. In C++20, the keyword of the co process is only syntax sugar: the compiler will package the function execution context (including local variables) into an object, and let the unexecuted function return to the caller first. After that, the caller uses this object to enable the function to continue down from the original breakpoint.
When using coprocessing, it is no longer necessary to "cut" the function into multiple small tasks. Only write the internal code of the function according to the customary process, and add co where temporary interruption of execution is allowed_ Yield statement, the compiler can process the function as "piecewise executable".
Coprocessing feels a bit like thread switching, because the stack frame of the function is saved as an object by the compiler, which can be recovered at any time and then run down. However, during actual execution, the coprocessor actually runs in a single thread sequence. There is no physical thread switching. Everything is just the "magic" of the compiler. Therefore, using CO process can completely avoid the performance overhead and resource occupation of multi-threaded switching, and there is no need to worry about data competition.
Unfortunately, the C++20 standard only provides the basic mechanism of collaborative process, and does not provide a really practical collaborative process library (which may be improved in C++23). At present, if you want to write the actual business with collaborative process, you can use the open source library, such as the famous cppcoro[2]. However, for the scenario described in this article, cppcoro does not directly provide the corresponding tools (the generator can solve this problem after proper packaging, but it is not intuitive), so I wrote a collaborative tool class for cutting tasks for examples.
Custom collaboration tools
The following is the code of the SegmentedTask tool class I wrote. This code looks quite complex, but it exists as a reusable tool. There is no need for programmers to understand its internal implementation. Generally, they just need to know how to use it. SegmentedTask is easy to use: it has only three external interfaces: Resume, IsFinished and GetReturnValue. Its functions can be self explained according to the interface name.
#include <optional>
#include <coroutine>
template<typename T>
class SegmentedTask {
public:
struct promise_type {
SegmentedTask<T> get_return_object()
{
return SegmentedTask{Handle::from_promise(*this)};
}
static std::suspend_never initial_suspend() noexcept { return {}; }
static std::suspend_always final_suspend() noexcept { return {}; }
std::suspend_always yield_value(std::nullopt_t) noexcept { return {}; }
std::suspend_never return_value(T value) noexcept
{
returnValue = value;
return {};
}
static void unhandled_exception() { throw; }
std::optional<T> returnValue;
};
using Handle = std::coroutine_handle<promise_type>;
explicit SegmentedTask(const Handle coroutine) : coroutine{coroutine} {}
~SegmentedTask()
{
if (coroutine) {
coroutine.destroy();
}
}
SegmentedTask(const SegmentedTask&) = delete;
SegmentedTask& operator=(const SegmentedTask&) = delete;
SegmentedTask(SegmentedTask&& other) noexcept : coroutine(other.coroutine) { other.coroutine = {}; }
SegmentedTask& operator=(SegmentedTask&& other) noexcept
{
if (this != &other) {
if (coroutine) {
coroutine.destroy();
}
coroutine = other.coroutine;
other.coroutine = {};
}
return *this;
}
void Resume() const { coroutine.resume(); }
bool IsFinished() const { return coroutine.promise().returnValue.has_value(); }
T GetReturnValue() const { return coroutine.promise().returnValue.value(); }
private:
Handle coroutine;
};Tool classes that write their own collaborative processes not only need to have an in-depth understanding of the C + + collaborative process mechanism, but also are prone to undefined behaviors such as dangling references. Therefore, it is strongly recommended that the project team uniformly use the prepared collaboration class. If readers want to learn more about the writing method of collaborative process tools, they can refer to Rainer Grimm's blog post [3].
Next, we use SegmentedTask to transform the previous event handling code. When CO is used in a C + + function_ await,co_yield,co_return, this function becomes a coroutine and its return value becomes the corresponding coroutine tool class. In the example code, when the inner function needs to return in advance, CO is used_ yield. But C++20_ Yield must be followed by an expression. This expression is not necessary in the example scenario, so std::nullopt is used to compile it. Under the actual business environment, co_yield can return a number or object to represent the progress of the current task, which is convenient for external query.
A coroutine cannot use a normal return statement, but must use co_return to return a value, and its return type is not directly equivalent to Co_ Expression type after return.
enum class EventType {
COMMAND,
MESSAGE,
ALARM
};
std::vector<EventType> g_events{EventType::COMMAND, EventType::ALARM};
std::optional<SegmentedTask<int>> suspended; // The unfinished tasks are saved here
SegmentedTask<int> ProcessCmd()
{
for (int i{0}; i < 10; ++i) {
std::cout << "Processing step " << i << std::endl;
co_yield std::nullopt;
}
co_return 0;
}
void ProcessMsg()
{
std::cout << "Processing Message" << std::endl;
}
void ProcessAlm()
{
std::cout << "Processing Alarm" << std::endl;
}
int main()
{
for (auto event : g_events) {
switch (event) {
case EventType::COMMAND:
suspended = ProcessCmd();
break;
case EventType::MESSAGE:
ProcessMsg();
break;
case EventType::ALARM:
ProcessAlm();
break;
}
}
while (suspended.has_value() && !suspended->IsFinished()) {
suspended->Resume();
}
if (suspended.has_value()) {
std::cout << "Final return: " << suspended->GetReturnValue() << endl;
}
return 0;
}For the purpose of making the example simple, only one COMMAND and one ALARM are put into the event queue. The COMMAND is a process that can be executed in segments. After the first segment is executed, the main loop will give priority to the remaining events in the queue, and finally continue to execute the rest of the COMMAND. In the actual scenario, various scheduling strategies can be flexibly selected according to needs. For example, a queue is used to store all unfinished segmented tasks and execute them in turn when they are idle.
The code in this article is compiled and run with GCC version 10.3. Two parameters - std=c++20 and - fcoroutines need to be added at the same time to support the co process. The running results of the code are as follows:
Processing step 0 Processing Alarm Processing step 1 Processing step 2 Processing step 3 Processing step 4 Processing step 5 Processing step 6 Processing step 7 Processing step 8 Processing step 9 Final return: 0
You can see that the for loop statement of ProcessCmd function (coroutine) is not executed at one time, and the execution of ProcessAlm is inserted in the middle. If you analyze the running thread, you will also find that there is no physical thread switching in the whole process, and all code is executed sequentially on the same thread.
The sequence diagram using CO process becomes as follows:
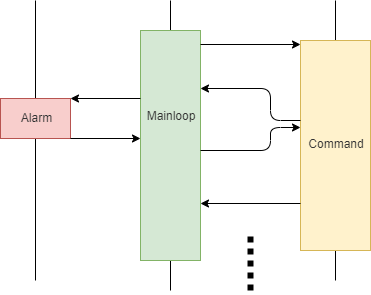
The long execution time of event handling functions is no longer a problem, because other functions can be "inserted" halfway, and then return to the breakpoint to continue running down.
summary
A common misconception is that using multithreading can improve software performance. But in fact, as long as the CPU does not run, when the number of physical threads exceeds the number of CPU cores, the performance will no longer be improved. On the contrary, the performance will be reduced due to the switching overhead of threads. In most development practices, the main benefit of concurrent programming is not to improve performance, but to facilitate coding, because many scene models in reality are concurrent and easy to directly correspond to multi-threaded code.
Coprocessing can be coded as easily and intuitively as multithreading, but at the same time, there is no overhead of physical threads, and there is no design burden in concurrent programming such as mutual exclusion and synchronization. In many scenarios such as embedded applications, coprocessing is often a better choice than physical threads.
It is believed that with the gradual popularization of C++20, collaborative process will be more and more widely used in the future.
Endnote
[1] https://en.wikipedia.org/wiki/Coroutine
[2] https://github.com/lewissbaker/cppcoro
[3] https://www.modernescpp.com/index.php/tag/coroutines
Click follow to learn about Huawei's new cloud technology for the first time~