canal source code analysis series - sink module analysis
introduction
The parser module is used to subscribe to binlog events and post them to the store through sink. What the sink stage does is to filter binlog data according to certain rules. In addition, some data distribution will be done. Its core interface is CanalEventSink, and its core method sink is used to submit data.
text
The CanalEventSink interface has two core implementation classes, EntryEventSink and GroupEventSink. The latter is mainly used in multi database scenarios, such as sub database and sub table. The class diagram structure is as follows:
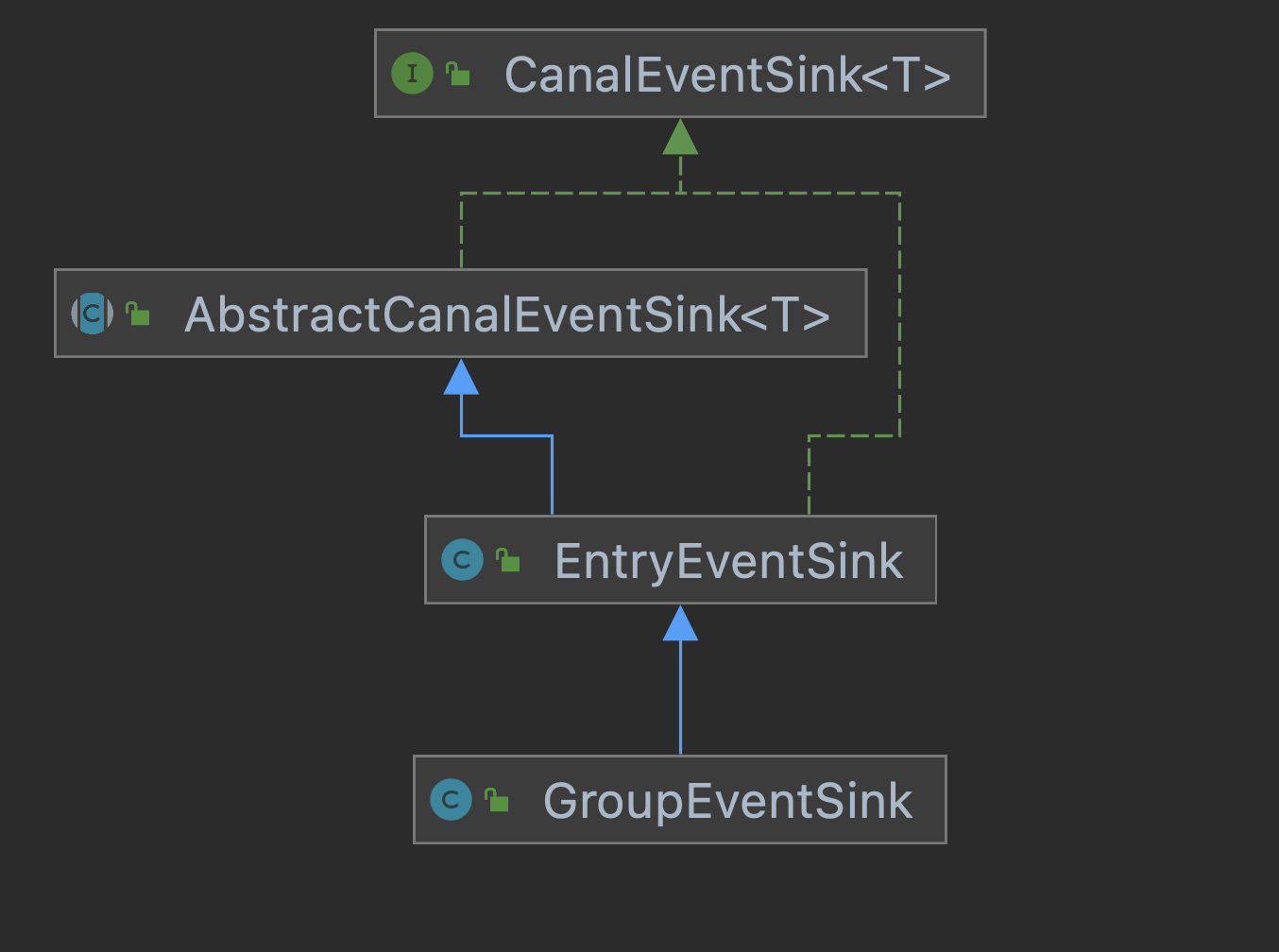
The two implementation classes are created in the com.alibaba.otter.canal.instance.manager.CanalInstanceWithManager#initEventSink method.
protected void initEventSink() {
logger.info("init eventSink begin...");
int groupSize = getGroupSize();
if (groupSize <= 1) {
eventSink = new EntryEventSink();
} else {
eventSink = new GroupEventSink(groupSize);
}
...
In the previous article, we talked about the parser module. After parsing, the parse module will put the data (CanalEntry.Entry) into a ring queue TransactionBuffer. The method is as follows:
com.alibaba.otter.canal.parse.inbound.EventTransactionBuffer#add(com.alibaba.otter.canal.protocol.CanalEntry.Entry)
public void add(CanalEntry.Entry entry) throws InterruptedException {
switch (entry.getEntryType()) {
case TRANSACTIONBEGIN:
flush();// Refresh last data
put(entry);
break;
case TRANSACTIONEND:
put(entry);
flush();
break;
case ROWDATA:
put(entry);
// For non DML data, it is output directly without buffer control
EventType eventType = entry.getHeader().getEventType();
if (eventType != null && !isDml(eventType)) {
flush();
}
break;
case HEARTBEAT:
// heartbeat from the master indicates that the binlog has been read and is in the idle state
put(entry);
flush();
break;
default:
break;
}
}
Here, different processing is performed according to different types of events. For example, if things start, first refresh the last data to the store, and then put in new data.
I'll post the codes of put and flush first,
private void put(CanalEntry.Entry data) throws InterruptedException {
// First, check whether there is a vacant seat
if (checkFreeSlotAt(putSequence.get() + 1)) {
long current = putSequence.get();
long next = current + 1;
// Write the data first, and then update the corresponding cursor. In case of high concurrency, the putSequence will be visible by the get request, taking out the old Entry value in the ringbuffer
entries[getIndex(next)] = data;
putSequence.set(next);
} else {
flush();// The buffer area is full. Refresh it
put(data);// Continue to add new data
}
}
private void flush() throws InterruptedException {
long start = this.flushSequence.get() + 1;
long end = this.putSequence.get();
if (start <= end) {
List<CanalEntry.Entry> transaction = new ArrayList<>();
for (long next = start; next <= end; next++) {
transaction.add(this.entries[getIndex(next)]);
}
flushCallback.flush(transaction);//Refresh (sink)
flushSequence.set(end);// After the flush is successful, update the flush location
}
}
First, when you see put, you will update a pointer, putSequence, and flush also has a pointer: flushSequence. So we can see that in the flush method, start is the pointer to flush and end is the pointer to put. The action of flush is to refresh all the data from the current flush to put to the next stage. The code passed to the next stage is in the flushCallback.flush method. The logic of this method is:
//The consumption logic of consumetheeventandprofiling ifnecessary is to call sink to drop data
boolean successed = consumeTheEventAndProfilingIfNecessary(transaction);
if (!running) {
return;
}
if (!successed) {
throw new CanalParseException("consume failed!");
}
//Update binlog location after sink
LogPosition position = buildLastTransactionPosition(transaction);
if (position != null) { // position may be empty
logPositionManager.persistLogPosition(AbstractEventParser.this.destination, position);
}
Consumetheeventandprofileingifnecessary calls the sink method of the CanalEventSink interface,
protected boolean consumeTheEventAndProfilingIfNecessary(List<CanalEntry.Entry> entrys) throws CanalSinkException,
InterruptedException {
...
boolean result = eventSink.sink(entrys, (runningInfo == null) ? null : runningInfo.getAddress(), destination);
...
return result;
}
Then look at the sink method,
public boolean sink(List<CanalEntry.Entry> entrys, InetSocketAddress remoteAddress, String destination)
throws CanalSinkException,
InterruptedException {
return sinkData(entrys, remoteAddress);
}
private boolean sinkData(List<CanalEntry.Entry> entrys, InetSocketAddress remoteAddress)
throws InterruptedException {
boolean hasRowData = false;
boolean hasHeartBeat = false;
List<Event> events = new ArrayList<>();
for (CanalEntry.Entry entry : entrys) {
if (!doFilter(entry)) {//Data filtering, filtering table names, fields, etc
continue;
}
if (filterTransactionEntry
&& (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND)) {
long currentTimestamp = entry.getHeader().getExecuteTime();
// Based on certain policy control, the empty transaction header and tail are allowed to update the database sites in time, indicating that the work is normal
if (lastTransactionCount.incrementAndGet() <= emptyTransctionThresold
&& Math.abs(currentTimestamp - lastTransactionTimestamp) <= emptyTransactionInterval) {
continue;
} else {
// fixed issue https://github.com/alibaba/canal/issues/2616
// The main reason is that empty transactions only send begin and do not send commit information synchronously. Here, it is modified to only update the count of commit events to ensure that begin/commit appear in pairs
if (entry.getEntryType() == EntryType.TRANSACTIONEND) {
lastTransactionCount.set(0L);
lastTransactionTimestamp = currentTimestamp;
}
}
}
hasRowData |= (entry.getEntryType() == EntryType.ROWDATA);
hasHeartBeat |= (entry.getEntryType() == EntryType.HEARTBEAT);
Event event = new Event(new LogIdentity(remoteAddress, -1L), entry, raw);
events.add(event);
}
if (hasRowData || hasHeartBeat) {
// If there are row records or heartbeat records, skip to subsequent processing directly
return doSink(events);
} else {
// Data to be filtered
if (filterEmtryTransactionEntry && !CollectionUtils.isEmpty(events)) {
long currentTimestamp = events.get(0).getExecuteTime();
// Based on certain policy control, the empty transaction header and tail are allowed to update the database sites in time, indicating that the work is normal
if (Math.abs(currentTimestamp - lastEmptyTransactionTimestamp) > emptyTransactionInterval
|| lastEmptyTransactionCount.incrementAndGet() > emptyTransctionThresold) {
lastEmptyTransactionCount.set(0L);
lastEmptyTransactionTimestamp = currentTimestamp;
return doSink(events);
}
}
// Directly return true, ignoring the empty transaction header and tail
return true;
}
}
The notes are quite clear. Here are some additional points.
First, filter the data. Only the EntryType.ROWDATA type can be filtered. The filtering principle uses the filter module of canal, which is mainly used to filter the table and field data from binlog. When using canal, it can be configured on the server or client. Filter is matched based on aviator. There are several implementation classes:
- Aviaterelfilter matches the El expression
- AviaterRegexFilter regular matching
- AviaterSimpleFilter simple match
This part is not expanded in depth here. Those who are interested can see it.
The next part seems difficult to understand. The filterTransactionEntry is used to control whether to filter the transaction header (transactionbin) and transaction end. If it is not filtered, it is equivalent to seeing these two entries in the message received by the client. Transaction headers and tails are mainly used to distinguish transaction boundaries, and the data itself is meaningless. The default value of filterTransactionEntry is false, that is, it is not filtered in most cases. You don't need to pay attention to this.
The core call in the sinkData method is to send the doSink method to the downstream (EventStore). Let's look at its logic,
protected boolean doSink(List<Event> events) {
//HeartBeatEntryEventHandler
for (CanalEventDownStreamHandler<List<Event>> handler : getHandlers()) {
events = handler.before(events);//doSink pre operation to filter heartbeat data
}
long blockingStart = 0L;
int fullTimes = 0;
do {
if (eventStore.tryPut(events)) {//Send to the next step store
if (fullTimes > 0) {
eventsSinkBlockingTime.addAndGet(System.nanoTime() - blockingStart);
}
for (CanalEventDownStreamHandler<List<Event>> handler : getHandlers()) {
events = handler.after(events);//after is an empty method
}
return true;
} else {
//retry
if (fullTimes == 0) {
blockingStart = System.nanoTime();
}
applyWait(++fullTimes);//Prevent unlimited waiting
if (fullTimes % 100 == 0) {
long nextStart = System.nanoTime();
eventsSinkBlockingTime.addAndGet(nextStart - blockingStart);
blockingStart = nextStart;
}
}
for (CanalEventDownStreamHandler<List<Event>> handler : getHandlers()) {
events = handler.retry(events);//retry is an empty method
}
} while (running && !Thread.interrupted());
return false;
}
This logic is relatively simple. Canaleveventdownstreamhandler actually has only one implementation of HeartBeatEntryEventHandler, which removes the heartbeat event from events in the before method. Then call the tryPut() method and send it to the next step store.
Next, look at GroupEventSink.
When the data scale of a business reaches a certain level, it will inevitably involve horizontal splitting and vertical splitting. When the split data needs to be processed, it needs to link multiple store s for processing, the consumption sites will become multiple copies, and the progress of data consumption cannot be guaranteed as orderly as possible.
Therefore, in certain business scenarios, it is necessary to merge the split incremental data, such as sorting and merging according to timestamp / global id. after merging, it is uniformly output by the client to ES, hbase and other storage devices.
Let's take a look at its doSink method,
protected boolean doSink(List<Event> events) {
int size = events.size();
for (int i = 0; i < events.size(); i++) {
Event event = events.get(i);
try {
barrier.await(event);// Merge and schedule the timeline
if (filterTransactionEntry) {
super.doSink(Arrays.asList(event));
} else if (i == size - 1) {
// For transaction data, the sink operation is performed only after the last data passes to ensure atomicity
// At the same time, batch sink should also ensure that the data is written out before the last data release state, otherwise there will be concurrency problems
return super.doSink(events);
}
} catch (InterruptedException e) {
return false;
} finally {
barrier.clear(event);
}
}
return false;
}
The core of merging is the barrier, which is defined as follows:
private GroupBarrier barrier; // Merging and sorting requires knowing the size of the group in advance to judge whether all sink s in the group have started to fetch data normally
It has two implementation classes: TimelineBarrier and TimelineTransactionBarrier. How do you choose to use that? The logic is as follows:
public void start() {
super.start();
if (filterTransactionEntry) {
barrier = new TimelineBarrier(groupSize);
} else {
barrier = new TimelineTransactionBarrier(groupSize);// Support transaction retention
}
}
Combined with the above doSink method, the basic process is clear. When filterTransactionEntry is true, use TimelineBarrier for scheduling; otherwise, use TimelineTransactionBarrier. The latter is batch call support transactions. (using transaction headers and transaction tails)
Let's continue to look at the await method of TimelineBarrier and see what the scheduling principle is?
/**
* Judge whether your timestamp can pass
*
* @throws InterruptedException
*/
public void await(Event event) throws InterruptedException {
long timestamp = getTimestamp(event);//Extraction time
try {
lock.lockInterruptibly();
single(timestamp);//The current time enters the priority queue and notifies the next minTimestamp data to exit the queue
//If the current time timestamp is greater than the threshold, it indicates that there is still less time to process
while (isPermit(event, timestamp) == false) {
condition.await();
}
} finally {
lock.unlock();
}
}
Then look at the single method,
/**
* Notify the next minTimestamp data out of the queue
*
* @throws InterruptedException
*/
private void single(long timestamp) throws InterruptedException {
lastTimestamps.add(timestamp);
if (timestamp < state()) {//The current event time is actually less than a small event that has been processed before
// Time hopping occurs in mysql transactions
// example:
// 2012-08-08 16:24:26 transaction header
// 2012-08-08 16:24:24 change record
// 2012-08-08 16:24:25 change record
// 2012-08-08 16:24:26 end of transaction
// For this case, once the timestamp fallback is found, the threshold is directly updated, other operations are forcibly blocked, and the minimum data priority processing is completed
threshold = timestamp; // Update to minimum
}
if (lastTimestamps.size() >= groupSize) {// Determine whether the queue needs to be triggered
// Data triggering the next outgoing queue
Long minTimestamp = this.lastTimestamps.peek();//Out of queue, minimum time
if (minTimestamp != null) {
threshold = minTimestamp;
notify(minTimestamp);
}
} else {
threshold = Long.MIN_VALUE;// If the queue length is not met, it needs to block and wait
}
}
Combined with the notes, the principle of scheduling is actually very clear. To put it bluntly, the event with the smallest timestamp is executed first (distributed to the store). The so-called minimum timestamp does not mean that the events that arrive first are processed first, but are sorted according to the time when the events themselves occur. Sorting uses the priority queue PriorityBlockingQueue.
Timelinetransaction barrier is limited to space, so I won't say more. The code is relatively simple and can be read by yourself.
Based on the above analysis, we can summarize the design idea of EventSink with a picture:
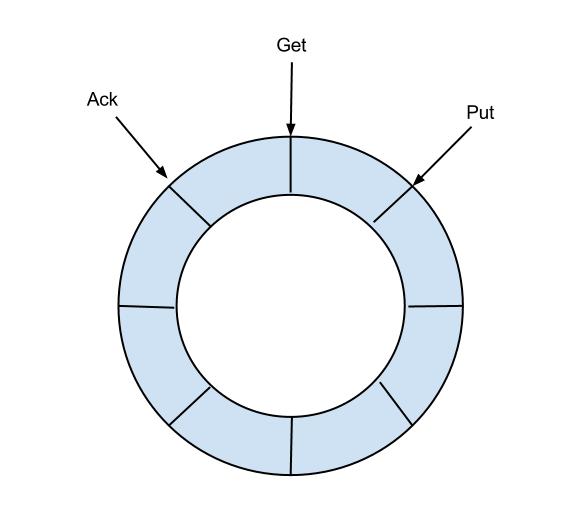
explain:
- Data filtering: support wildcard filtering mode, table name, field content, etc
- Data routing / distribution: solve 1: n (one parser corresponds to multiple store s)
- Data merging: solve n:1 (multiple parser s correspond to one store)
- Data processing: perform additional processing before entering the store, such as join
reference resources:
- https://www.bookstack.cn/read/canal-v1.1.4/34357b71c7c1f182.md#%E6%9E%B6%E6%9E%84
- https://zhuanlan.zhihu.com/p/345736518
- https://github.com/alibaba/canal/issues/132