What is Expression?
In sql statements, except for the keywords select and from, most other elements can be understood as expression, such as:
select a,b from testdata2 where a>2
A, B, >, 2 here are all expression s
canonicalized operation of Expression
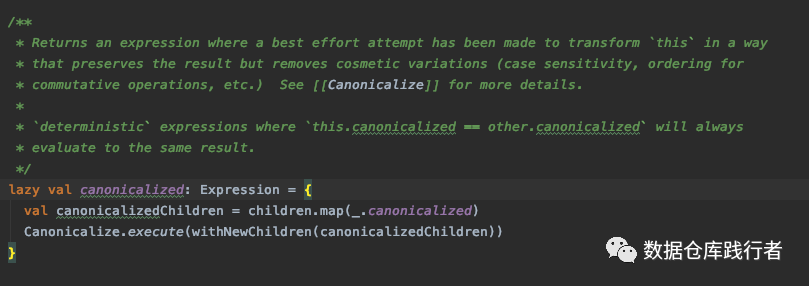
This operation returns the normalized expression
Normalization will rewrite the expression through some rules on the premise of ensuring the same output results
What is the use of this standardization?
for instance:
select b,B,sum(A+b) as ab,sum(B+a) as ba from testdata2 where b>3 group by b
In the above code, although B and B,sum(A+b) and sum(B+a) are different in appearance, the actual calculation results are exactly the same. The normalization operation will unify the appearance of B, B and sum(A+b) and sum(B+a), so that they can reference the same actual calculation result and avoid multiple calculations.
How does this standardization work?
With the help of the tool class: Canonicalize
Core method execute
Rewrite the expression according to some rules to eliminate the appearance difference
def execute(e: Expression): Expression = {
expressionReorder(ignoreNamesTypes(e))
}Normalize the naming of the result set
Two cases:
- For the expression of AttributeReference reference reference class, the main method is to eliminate the differences caused by name and nullability
- GetStructField is an expression of complex type to eliminate the difference caused by name
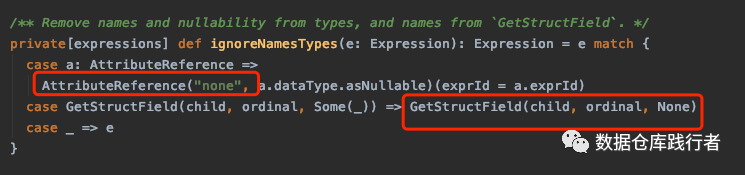
For expressions of reference types, it is ok to judge whether they are the same, only if the referenced id(exprId) is the same. Therefore, the processing method here is to uniformly set the name to none to eliminate the difference, for example:
select b,B,sum(A+b) as ab,sum(B+a) as ba from testdata2 where b>3 group by b //name#exprId Expression(b) ---> b#3 ignoreNamesTypes(b)----none#3 Expression(B) ---> B#3 ignoreNamesTypes(B)----none#3 After the above transformation, b and B All for none#3
Calculation class expression
- For the sub operations of switching and combining operations (Add and Multiply), the left and right sub nodes are sorted by "hashCode"
- For the sub operations of exchange And combination operations (Or And), the left And right sub nodes are sorted by "hashCode", but the expression must be deterministic
- EqualTo and equallnullsafe sort the left and right child nodes through "hashCode".
- Other comparisons (greater than, less than) are reversed by "hashCode".
- The elements in in are reordered by ` hashCode '
private def expressionReorder(e: Expression): Expression = e match {
// Addition and multiplication can exchange order, convert to Seq, and sort with sortBy of Seq
case a: Add => orderCommutative(a, { case Add(l, r) => Seq(l, r) }).reduce(Add)
case m: Multiply => orderCommutative(m, { case Multiply(l, r) => Seq(l, r) }).reduce(Multiply)
// or and can exchange the order, convert it to Seq, and sort it with sortBy of Seq, but it must be deterministic
case o: Or =>
orderCommutative(o, { case Or(l, r) if l.deterministic && r.deterministic => Seq(l, r) })
.reduce(Or)
case a: And =>
orderCommutative(a, { case And(l, r) if l.deterministic && r.deterministic => Seq(l, r)})
.reduce(And)
// EqualTo and equallnullsafe sort the left and right child nodes through "hashCode"
case EqualTo(l, r) if l.hashCode() > r.hashCode() => EqualTo(r, l)
case EqualNullSafe(l, r) if l.hashCode() > r.hashCode() => EqualNullSafe(r, l)
// For other comparisons, LessThan is reversed from "hashCode". For example, when > is selected, if l.hashCode() > r.hashCode(), it is changed to LessThan(r, l)
case GreaterThan(l, r) if l.hashCode() > r.hashCode() => LessThan(r, l)
case LessThan(l, r) if l.hashCode() > r.hashCode() => GreaterThan(r, l)
case GreaterThanOrEqual(l, r) if l.hashCode() > r.hashCode() => LessThanOrEqual(r, l)
case LessThanOrEqual(l, r) if l.hashCode() > r.hashCode() => GreaterThanOrEqual(r, l)
// Note in the following `NOT` cases, `l.hashCode() <= r.hashCode()` holds. The reason is that
// canonicalization is conducted bottom-up -- see [[Expression.canonicalized]].
case Not(GreaterThan(l, r)) => LessThanOrEqual(l, r)
case Not(LessThan(l, r)) => GreaterThanOrEqual(l, r)
case Not(GreaterThanOrEqual(l, r)) => LessThan(l, r)
case Not(LessThanOrEqual(l, r)) => GreaterThan(l, r)
// in reorder by ` hashCode '
case In(value, list) if list.length > 1 => In(value, list.sortBy(_.hashCode()))
case _ => e
}
}Extension operation semanticEquals
// When two expressions calculate the same result, they return true. The judgment basis is that both expressions are deterministic,
// And the two expressions are the same after normalization
def semanticEquals(other: Expression): Boolean =
deterministic && other.deterministic && canonicalized == other.canonicalizedHey!
I'm a radish operator