1. Introduction to multimedia streaming protocol RTSP and MMS
2. Use VLC software to save the captured network stream
First download and install the VLC software

Then, add the network streaming address
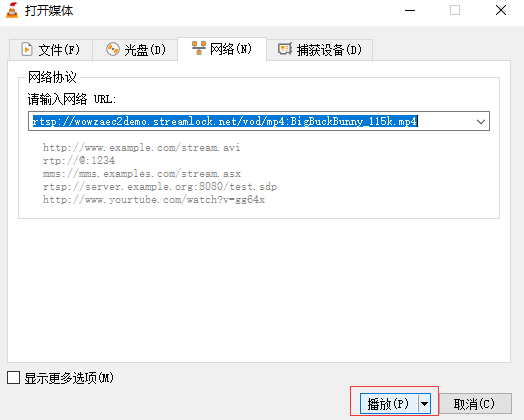
Open VLC, click media - > open network streaming, and add a network streaming media link: rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mp4
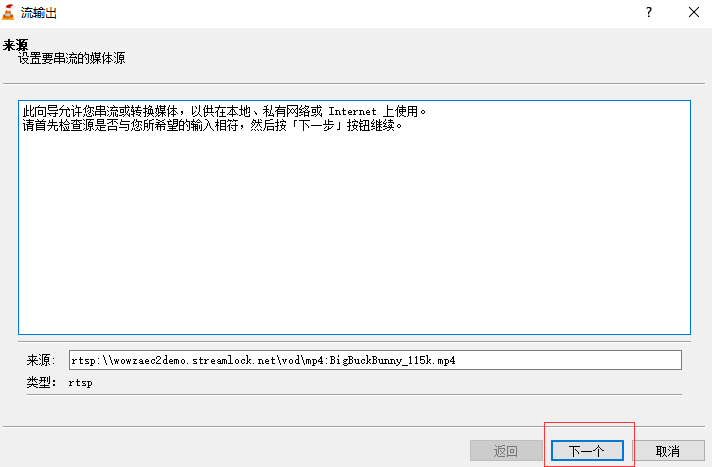
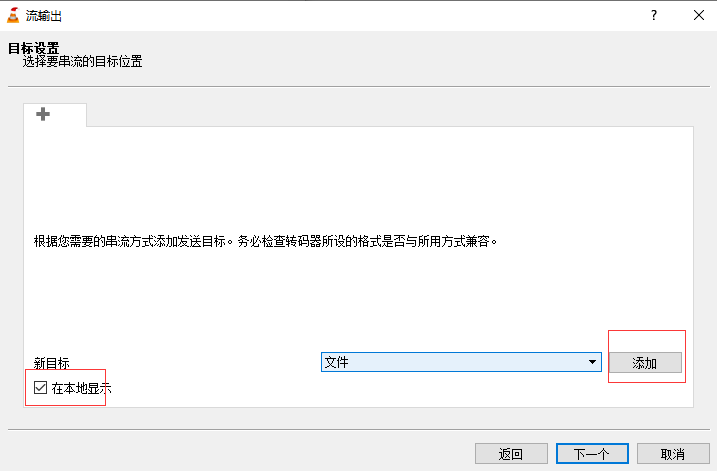
Select Save to file and select display locally:
Select the file storage directory:
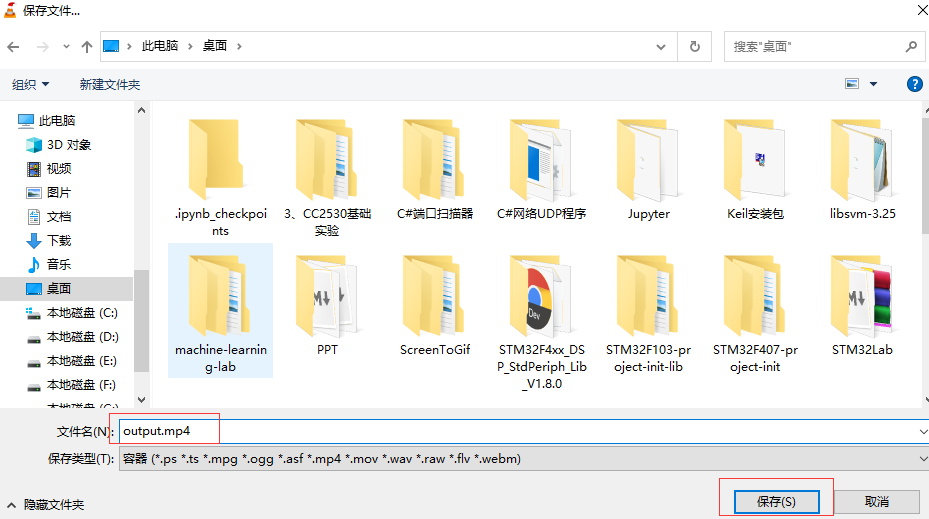
Select the file format, which is selected according to the format of network streaming media. Here is MP4
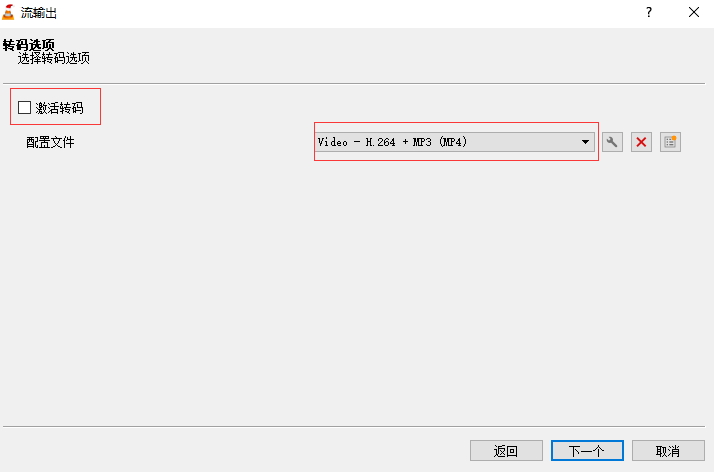
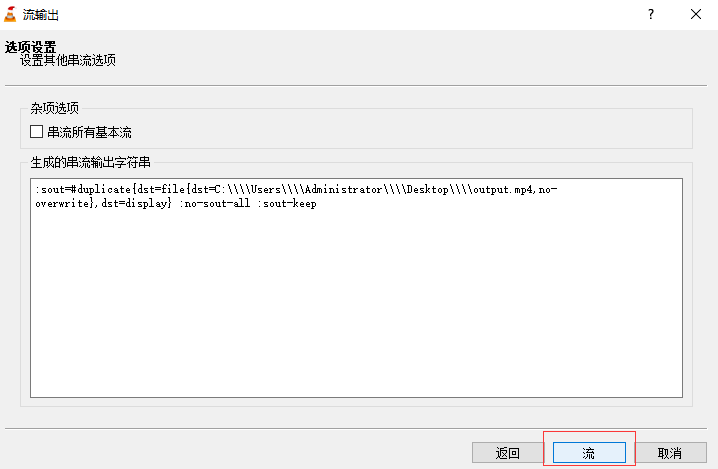
Stream output:
Wait for a period of time. After closing the VLC software, you can open the MP4 file
Saved video files:

2. Capture and save the network video stream of station B
2.1 using Fiddler to analyze the video stream of station B
First open Fiddler, use Ctrl+X to clear the screen, and then play station B video in the browser
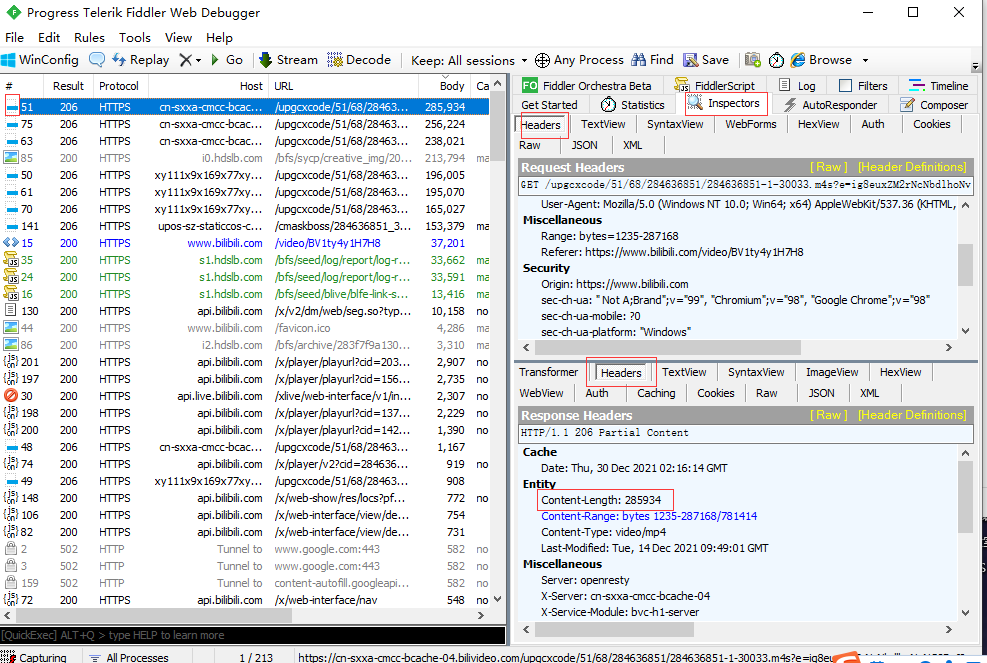
Then view the data packet at Fiddler. The icon on the left represents the video or audio file. Click it to see the length of the content of the data packet in the Headers at the bottom right.
2.2 download complete content with Composer
Open the Composer on the right
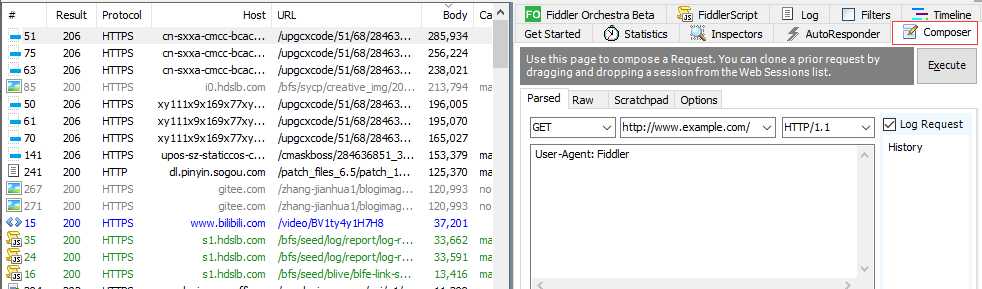
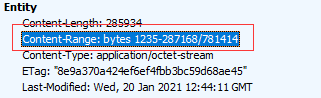
Grab the complete packet content. 781414 in the content range above represents the length of the complete video content, while 1235-287168 is only the video content represented by this data. Therefore, we want to grab the complete video content of 0-781414:
Click the packet on the left and drag it to the right:
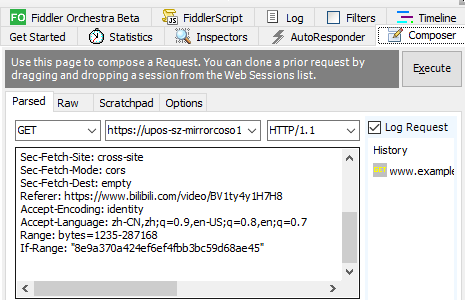
This packet only requests 1235-287168 segments of video data. Modify it to 0-781414:
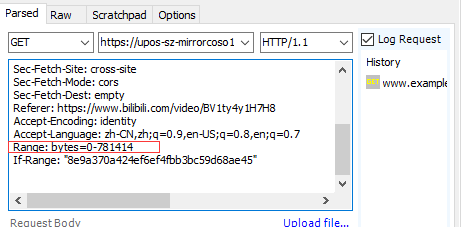
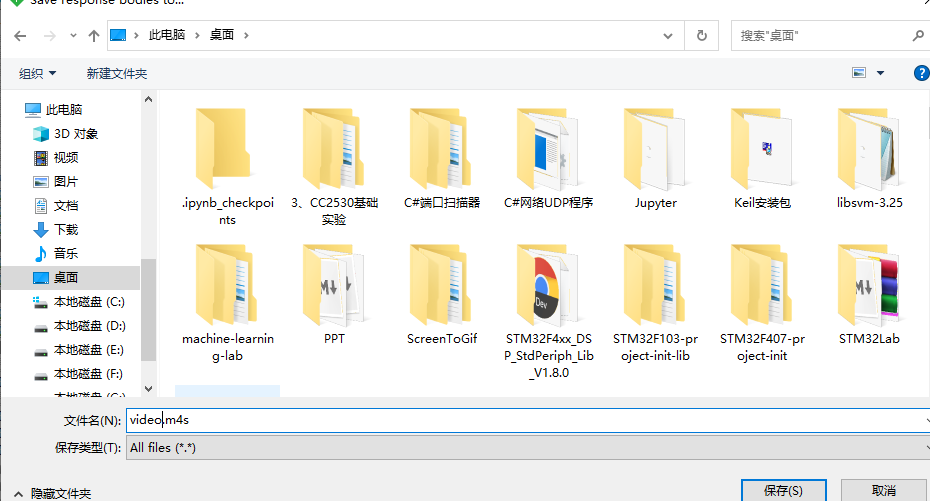
Click Execute to return to the left side and pull it to the bottom. You can see a new video packet. Right click it and click Save → Response → Response Body to Save it:
The default file suffix is M4S Txt, modify the file suffix to mp4:
Next, the second packet is processed in the same way, which is an audio file:
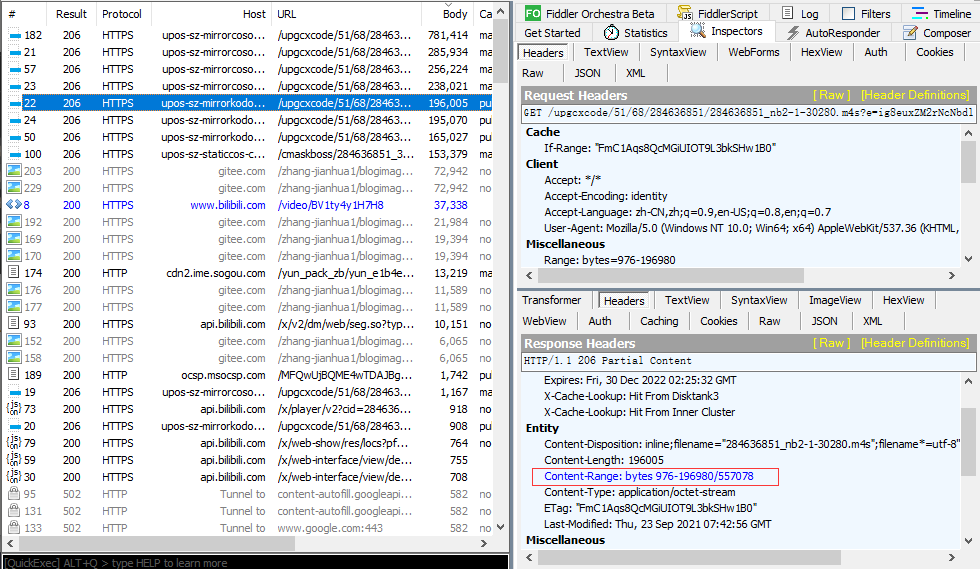
Get audio mp4:

2.3 viewing downloaded video files using VLCPlayer
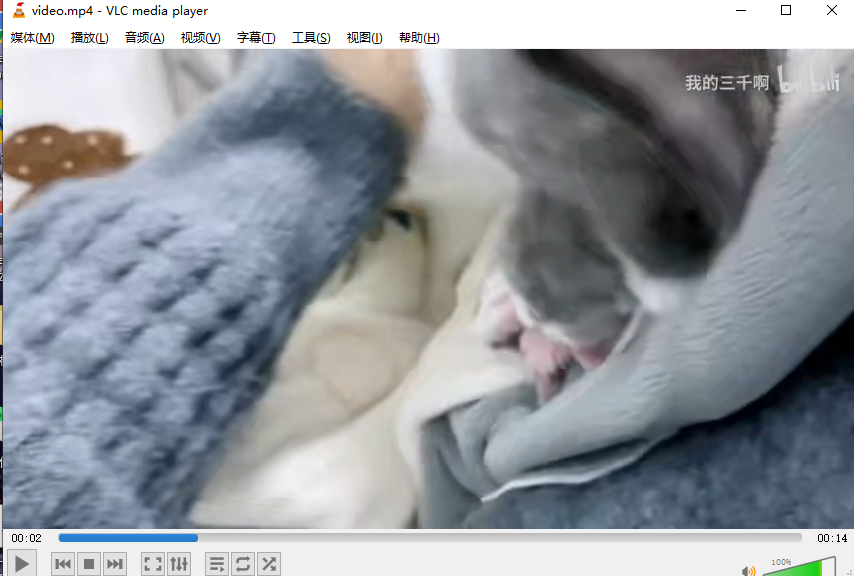
You can play directly, but the audio files are not merged, so there is no sound. You can merge two files with ffmpeg
2.4 climbing station B video
Download using BiliBili's video streaming API
import json
import requests
from fake_useragent import UserAgent
import re
# setting
# Automatic maximum resolution - > 0, 1080p - > 1, 720p - > 2, 480p - > 3, 360p - > 4, 1080 + - > 5
type = 0
# Encoding format AVC - > 0, HEV - > 1
codecs = 0
#cookie
cookie = ''
# Download size (in bytes, None is all)
byte = None
# byte = '0-9999'
url1='https://api.bilibili.com/pgc/player/web/playurl?fnval=80&cid={c}'
url2='https://api.bilibili.com/x/player/playurl?fnval=80&avid={a}&cid={c}'
class VideoList:
headers={
'User-Agent': '',
'referer': '',
'cookie': cookie
}
def __init__(self,url,part=[0]):
self.url=url
self.part=part
def download(self):
self.headers['User-Agent'] = str(UserAgent().random)
try:
self.html = requests.get(self.url,self.headers).text
except Exception:
print('link failure')
return None
if re.findall(r'\.bilibili\.com/video/BV',self.url) != [] or re.findall(r'\.bilibili\.com/video/av',self.url) != []:
return self.video()
elif re.findall(r'\.bilibili\.com/bangumi/play/',self.url) != []:
return self.bangumi()
else:
print('url invalid')
return None
def bangumi(self):
json_ = json.loads('{'+re.search(r'"epList":\[.+?\]',self.html).group()+'}')
self.headers['referer']=self.url
for i in self.part:
try:
cid = json_['epList'][i]['cid']
except Exception:
print('branch p non-existent')
break
self.headers['User-Agent'] = str(UserAgent().random)
js = json.loads(requests.get(url1.format(c=cid),headers=self.headers).text)
js['referer'] = self.url
js['part'] = i
yield js
def video(self):
json_ = json.loads('{'+re.search(r'"aid":\d+',self.html).group()+'}')
aid = json_['aid']
json_ = json.loads('{'+re.search(r'"pages":\[.+?\]',self.html).group()+'}')
self.headers['referer']=self.url
for i in self.part:
try:
cid = json_['pages'][i]['cid']
except Exception:
print('branch p non-existent')
break
self.headers['User-Agent'] = str(UserAgent().random)
js = json.loads(requests.get(url2.format(a=aid,c=cid),headers=self.headers).text)
js['referer'] = self.url
js['part'] = i
yield js
class Download:
headers={
'User-Agent': '',
'referer': '',
'cookie': cookie
}
def __init__(self,js):
self.js=js
def download(self,path,type = 0,codecs = 0,byte = None):
self.headers['User-Agent'] = str(UserAgent().random)
self.headers['referer'] = self.js['referer']
p = str(self.js['part'])
if 'data' in self.js:
self.js=self.js['data']
else:
self.js=self.js['result']
id = self.js['dash']['video'][0]['id']
if type == 1:
id = 80
elif type == 2:
id = 64
elif type == 3:
id = 32
elif type == 4:
id = 16
elif type == 5:
id = 112
elif type != 0:
print('type Parameter error')
return None
code = 'avc'
if codecs == 1:
code = 'hev'
elif codecs != 0:
print('codecs Parameter error')
return None
js_movie = None
for i in self.js['dash']['video']:
if i['id'] == id and re.findall(code,i['codecs']) != []:
js_movie = i
break
js_audio = self.js['dash']['audio'][0]
if js_movie == None:
print('The video related to the specified element does not exist')
return None
if byte!=None:
self.headers['range'] = 'bytes='+byte
vid = self.headers['referer'].split('/')[-1]
with open(path+vid+'_'+p+'.mp4','wb+') as file1, open(path+vid+'_'+p+'.mp3','wb+') as file2:
print('Downloading','website:'+vid+' '+'branch p:'+p)
file1.write(requests.get(js_movie['base_url'],headers=self.headers).content)
file2.write(requests.get(js_audio['base_url'],headers=self.headers).content)
print('Download succeeded')
# Video URL to download
url = 'https://www.bilibili.com/video/BV1ty4y1H7H8'
# List of videos p to be downloaded (episodes for fan dramas)
part = range(0,1)
# Download path
path = 'video/'
# Run this file to download
if __name__ == "__main__":
vl = VideoList(url,part)
for i in vl.download():
dl = Download(i)
dl.download(path,type = type,codecs = codecs,byte = byte)Crawling results:

3. Reference
[1] Analysis of video download interface of b station
[2] Research on crawling live stream of station B - http+flv
[4] [Fiddler] use Fiddler to download and save the videos in Bilibili