Tell me about this website
Auto home is the ancestor website of anti climbing. The development team of this website must be good at the front end. Starting to write this blog on April 19, 2019, it is not guaranteed that this code will survive until the end of the month. I hope that the crawler coder will continue to fight against cars later.
There are thousands of anti climbing articles about car home on CSDN, but the crawler is interesting. I don't know if it can be used in the next moment after writing it at this moment, so someone can write it all the time. I hope today's blog can help you learn an anti climbing skill.
Page to climb today

car.autohome.com.cn/config/seri... All we have to do is climb the car parameter configuration
The specific data are as follows
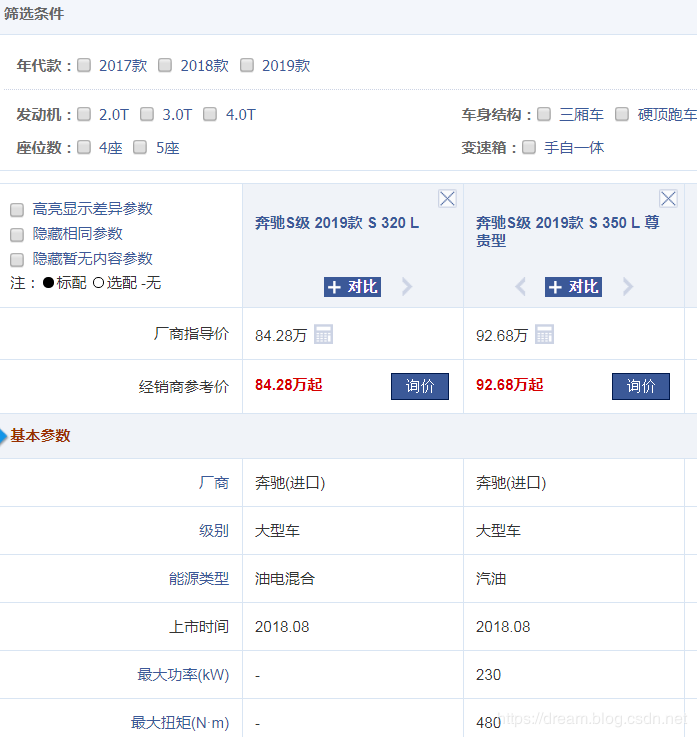
Looking at the page source code, I found that a lot of CSS3 syntax is used in the source code. As shown in the figure below, the part I marked is some key data, about 600 lines later.
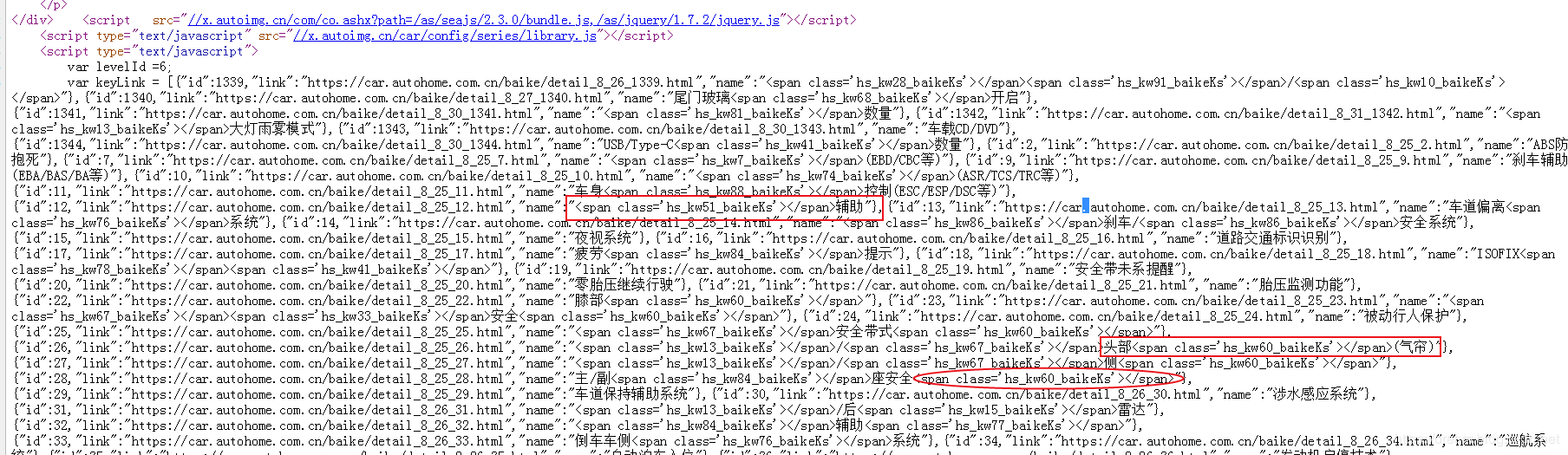
Display of anti climbing measures
Source file data
brake/<span class='hs_kw86_baikeIl'></span>safety system Copy code
Page display data
Some key data have been processed.
Crawl key information
We need to get the key information in the source code first, even if the data is anti crawling. Getting data is very simple. Through the request module
def get_html():
url = "https://car.autohome.com.cn/config/series/59.html#pvareaid=3454437"
headers = {
"User-agent": "Your browser UA"
}
with requests.get(url=url, headers=headers, timeout=3) as res:
html = res.content.decode("utf-8")
return html
Copy codeFind key factors
Find the key points in the html page:
- var config
- var levelId
- var keyLink
- var bag
- var color
- var innerColor
- var option
After you find these contents, you start with the key points. What are they? The data can be obtained through a simple regular expression
def get_detail(html):
config = re.search("var config = (.*?)};", html, re.S)
option = re.search("var option = (.*?)};", html, re.S)
print(config,option)
Copy codeOutput results
>python e:/python/demo.py
<re.Match object; span=(167291, 233943), match='var config = {"message":"<span class=\'hs_kw50_co>
>python e:/python/demo.py
<re.Match object; span=(167291, 233943), match='var config = {"message":"<span class=\'hs_kw50_co> <re.Match object; span=(233952, 442342), match='var option = {"message":"<span class=\'hs_kw16_op>
Copy codeProcessing vehicle parameters
Through the regular expression search method, matching data, and then calling group(0) to get the relevant data.
def get_detail(html):
config = re.search("var config = (.*?)};", html, re.S)
option = re.search("var option = (.*?)};", html, re.S)
# Processing vehicle parameters
car_info = ""
if config and option :
car_info = car_info + config.group(0) + option.group(0)
print(car_info)
Copy codeAfter getting the data, there is no end. This is the data after confusion. It needs to be parsed back. Continue to pay attention to the web page source code and find a strange JS. Don't worry about this JS, just leave an impression~

Keyword cracking
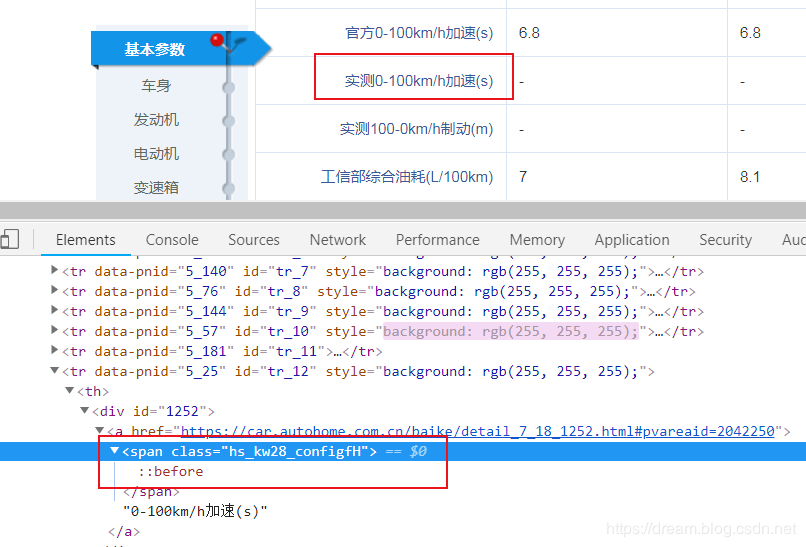
be aware
<span class="hs_kw28_configfH"></span> Copy code
hs_kw digital_ configfH is a span class
After I select span:: before
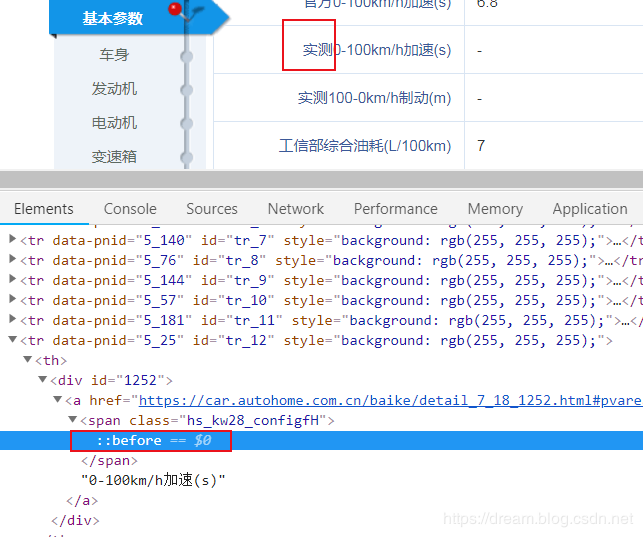
The corresponding css is
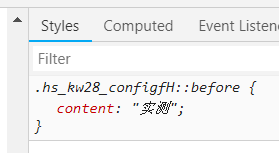
It is found that the word "actual measurement" appears. Please remember the corresponding class
.hs_kw28_configfH::before Copy code
Global search
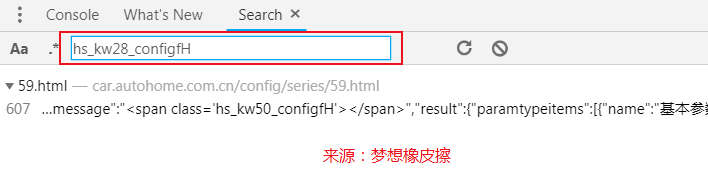
Double click to find the source
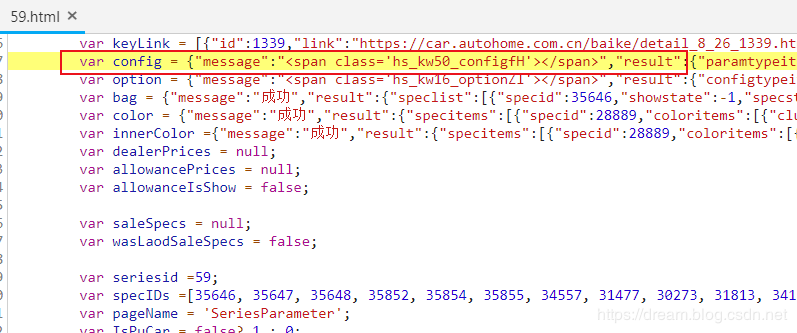
Make sure the data is in the html source code.
Format html source code and search HS internally_ KW, find the key function
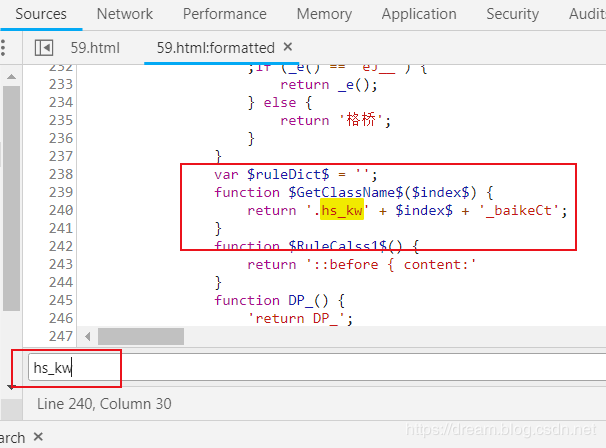
function $GetClassName$($index$) {
return '.hs_kw' + $index$ + '_baikeCt';
}
Copy codeThe source of this JS is the JS code segment we just retained. Copy all JS source codes, create a snippet in the source, and then let's run it.
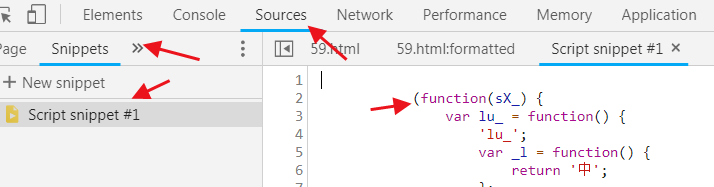
Add a breakpoint at the end of the code and run ctrl+enter

When you run to the breakpoint, you can see some parameters on the right

- :
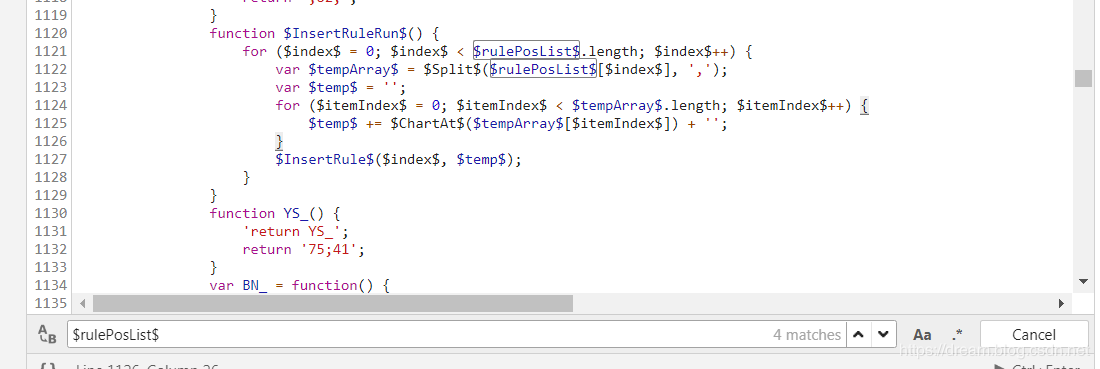 Find the core replacement method through parameters
Find the core replacement method through parameters
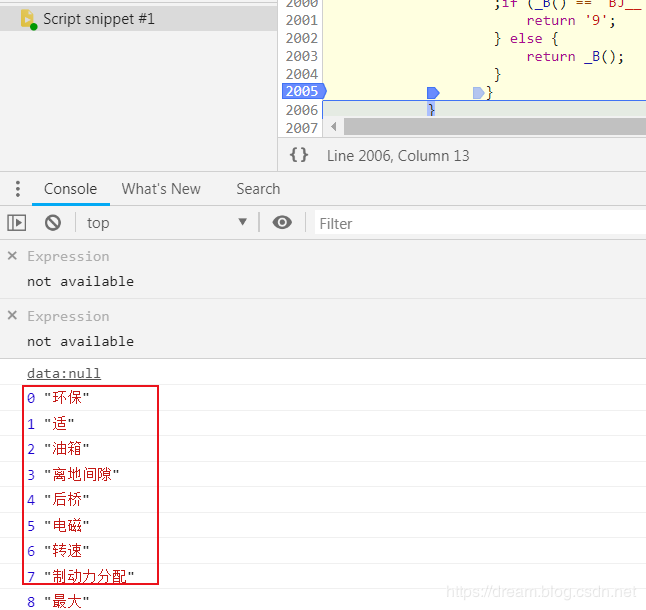
Next, we perform the replacement operation. This process requires selenium to replace
The core code is as follows. The main comments are written inside the code. I hope they can help you understand
def write_html(js_list,car_info):
# DOM running JS -- this crack is the most troublesome and time-consuming ~ refer to the great God code on the Internet
DOM = ("var rules = '2';"
"var document = {};"
"function getRules(){return rules}"
"document.createElement = function() {"
" return {"
" sheet: {"
" insertRule: function(rule, i) {"
" if (rules.length == 0) {"
" rules = rule;"
" } else {"
" rules = rules + '#' + rule;"
" }"
" }"
" }"
" }"
"};"
"document.querySelectorAll = function() {"
" return {};"
"};"
"document.head = {};"
"document.head.appendChild = function() {};"
"var window = {};"
"window.decodeURIComponent = decodeURIComponent;")
# Write the JS file into the file
for item in js_list:
DOM = DOM + item
html_type = "<html><meta http-equiv='Content-Type' content='text/html; charset=utf-8' /><head></head><body> <script type='text/javascript'>"
# Spliced into a running web page
js = html_type + DOM + " document.write(rules)</script></body></html>"
# When running again, please delete the file, otherwise you cannot create a file with the same name, or you can verify it yourself
with open("./demo.html", "w", encoding="utf-8") as f:
f.write(js)
# Read out the data through selenium and replace it
driver = webdriver.PhantomJS()
driver.get("./demo.html")
# Read the body part
text = driver.find_element_by_tag_name('body').text
# Match all span labels in vehicle parameters
span_list = re.findall("<span(.*?)></span>", car_info) # car_info is the string I spliced above
# Replace with the keyword in the span tag and text
for span in span_list:
# This place matches the name of class, for example < span class ='hs_kw7_optionZl '> < / span > match hs_kw7_optionZl come out
info = re.search("'(.*?)'", span)
if info:
class_info = str(info.group(1)) + "::before { content:(.*?)}" # Splice as hs_kw7_optionZl::before { content:(.*?)}
content = re.search(class_info, text).group(1) # Match the text content, and the returned results are "measured", "fuel consumption" and "warranty"
car_info = car_info.replace(str("<span class='" + info.group(1) + "'></span>"),
re.search("\"(.*?)\"", content).group(1))
print(car_info)
Copy codeOperation results
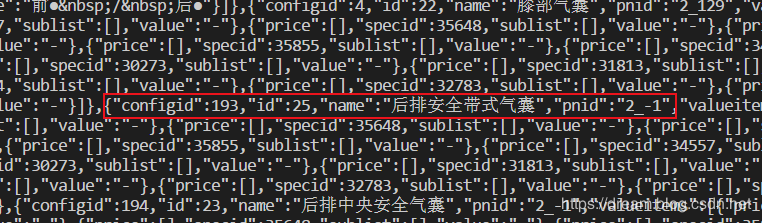
Compare the original data and find that the problem is not big. Complete the task.
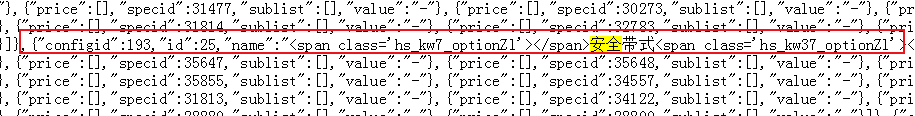
Warehousing operation
The remaining steps are data persistence. After the data is obtained, the rest are relatively simple. I hope you can do it directly.
Small extension: formatting JS
When you encounter this JS, you can directly find the formatting tool to handle it
tool.oschina.net/codeformat/...
After the format is completed, the code has a certain reading ability
Summary of ideas
Auto Home CSS hides some real fonts. In the process of solving the problem, you need to find the class first. When you find the location of JS, you must deal with its encryption rules. After following the rules, you only need to complete the basic key and value replacement to get the real data.
exchange of learning:
① Python ebooks have
② Python development environment installation tutorial
③ Python video has
④ Common vocabulary of software development
⑤ Python learning Roadmap
⑥ Project source code case sharing, if you can use it, you can take it directly in my QQ technology exchange Q group
Group No.: 200160592