catalogue
2.3 CBAM integrated with a ResBlock in ResNet
1. Attention mechanism
Generally speaking, the attention mechanism is to hope that the network can automatically learn what needs attention in the picture or text sequence. For example, when observing a painting, the human eye will not evenly distribute its attention to each pixel in the painting, but pay more attention to the places people pay attention to.
From the perspective of implementation: the attention mechanism generates a mask mask through the operation of neural network, and the value on the mask is scored to evaluate the score of current points of concern.
Attention mechanisms can be divided into:
- Channel attention mechanism: a mask mask is generated for the channel and scored, representing senet and Channel Attention Map
- Spatial attention mechanism: generate and score the spatial mask, which represents the Spatial Attention Map
- Mixed domain attention mechanism: scoring channel attention and spatial attention at the same time, representing bam and CBAM
2. Thesis interpretation
This paper proposes a Convolutional Block Attention Module (CBAM), which is a simple and effective Attention Module designed for convolutional neural network (Attention Module). For the feature map generated by convolutional neural network, CBAM calculates the attention map of feature map from the two dimensions of channel and space, and then multiplies the feature map and attention map for adaptive feature learning. CBAM is a lightweight general module, which is suitable for various convolutional neural networks
The implementation process is as follows:
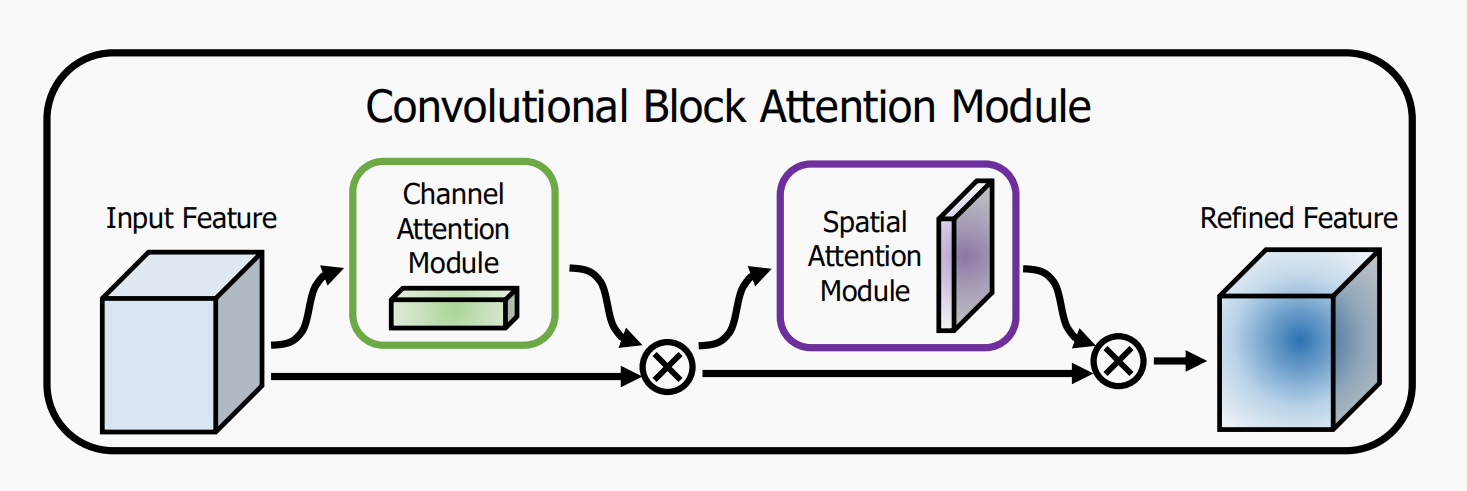
For a feature map of an intermediate layer: for a feature map of an intermediate layer: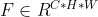 , CBAM will sequentially infer a 1-dimensional channel attention map
, CBAM will sequentially infer a 1-dimensional channel attention map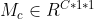 , and 2-dimensional spatial attention map
, and 2-dimensional spatial attention map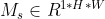 , the whole process is shown in the figure below:
, the whole process is shown in the figure below:
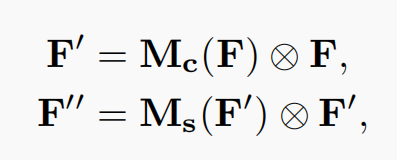
2.1 Channel Attention Module
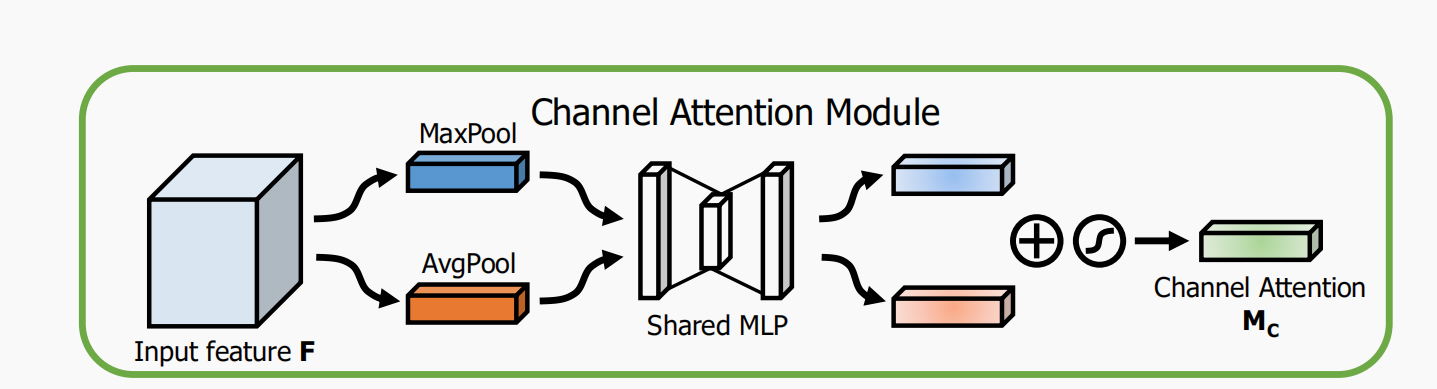
Each channel in the input feature map is regarded as a feature detector, and channel attention mainly focuses on what is meaningful in the input image. In order to calculate channel attention efficiently, this paper compresses the feature map in the spatial dimension using average pooling and Max pooling to obtain two different spatial background descriptions: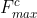 And
And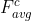 . The shared network composed of MLP (multi-layer perceptron) is used to calculate the element wise of these two different spatial background descriptions, and then the channel attention map is obtained through sigmoid function:, the calculation process is as follows:
. The shared network composed of MLP (multi-layer perceptron) is used to calculate the element wise of these two different spatial background descriptions, and then the channel attention map is obtained through sigmoid function:, the calculation process is as follows:
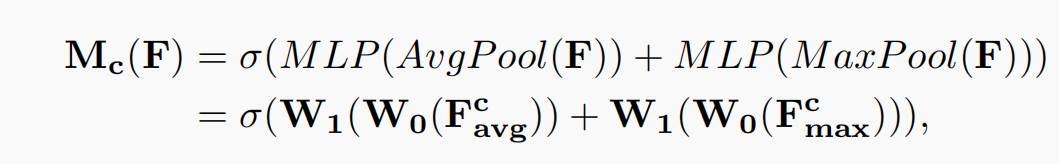
among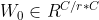 ,
, 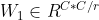 , the relu activation function is used after W0. The weight parameters of MLP are W0 and W1.
, the relu activation function is used after W0. The weight parameters of MLP are W0 and W1.
The code above is implemented as follows:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)Q: Why does the number of channel s in MLP decrease first and then increase?
A: If it goes through a layer of convolution, NN Conv2d (in_planes, in_planes, 1), assuming that the number of input channels is 32 and the parameter quantity is 32 × thirty-two × one × 1 = 1024, parameter quantity in the paper, 32 × two × one × 1+2 × thirty-two × one × 1 = 128, it can be seen that the parameter quantity is 8 times of the original.
2.2 Spatial attention channel
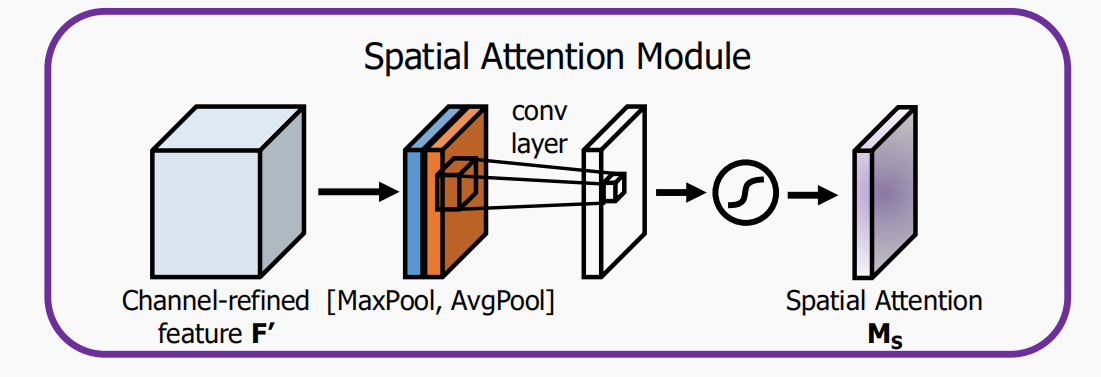
Spatial attention mainly focuses on the location (where) information of the input feature map. In order to calculate spatial attention, the paper first obtains two different feature descriptions by using maximum pooling and average pooling in the dimension of channel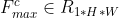 and
and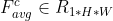 Then use concatenation to merge the two feature descriptions, and use convolution to generate spatial attention map
Then use concatenation to merge the two feature descriptions, and use convolution to generate spatial attention map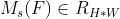 , the calculation process is as follows:
, the calculation process is as follows:
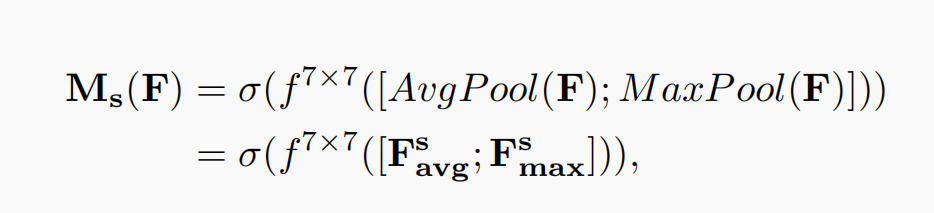
among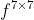 Represents a convolution layer of 7 * 7.
Represents a convolution layer of 7 * 7.
The code implementation is as follows:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)2.3 CBAM integrated with a ResBlock in ResNet
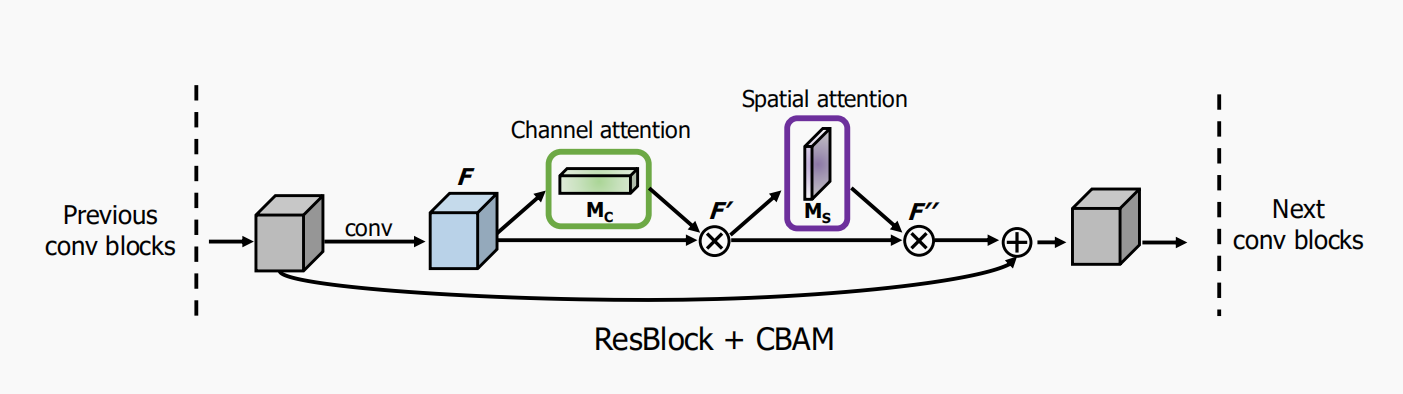
The implementation process is as follows:
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.ca(out) * out # Broadcasting mechanism
out = self.sa(out) * out # Broadcasting mechanism
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return outCBAM module:
import torch.nn as nn
class CBAMLayer(nn.Module):
super(CNAMLayer).__init__()
def __init__(self, channel, reduction=16, spatial_kernel=7):
# channel attention
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.mlp = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, bias=False),
)
# spatial attention
self.conv = nn.Conv2d(2, 1, kernel_size=spatial_kernel, padding=spatial_kernel//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# channel attention
max_out = self.mlp(self.max_pool(x))
avg_out = self.mlp(self.avg_pool(x))
channel_out = self.sigmoid(max_out + avg_out)
x = channel_out * x
# spatial attention
max_out, _ = torch.max(x, dim=1, keepdim=True)
avg_out = torch.mean(x, dim=1, keepdim=True)
spatial_out = self.sigmoid(self.conv(torch.cat([max_out, avg_out], dim=1)))
x = spatial_out * x
return x
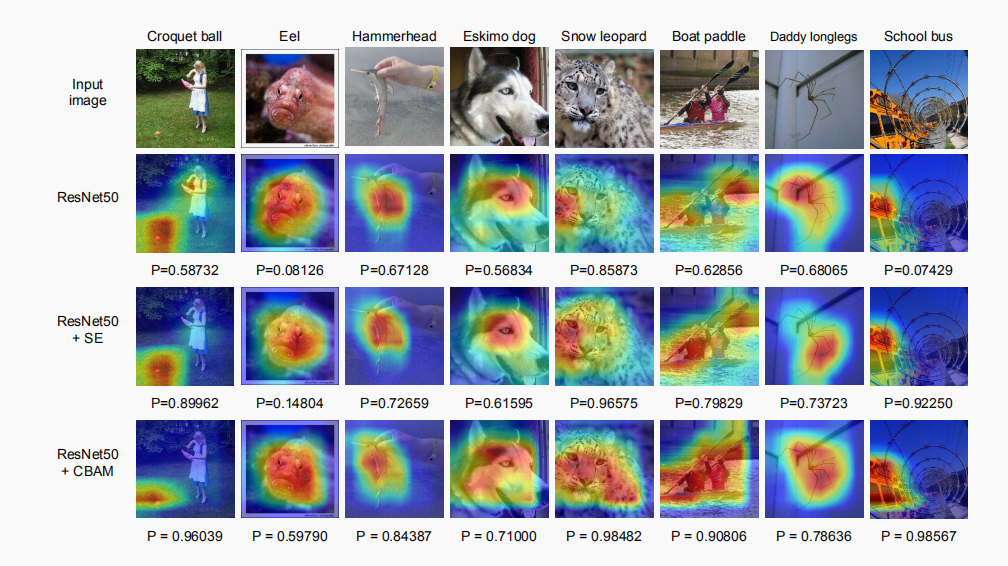
2.4 experimental results
1. Comparing the serial and parallel experiments on channel and space, it is found that the experimental results of channel first and space later will be better.
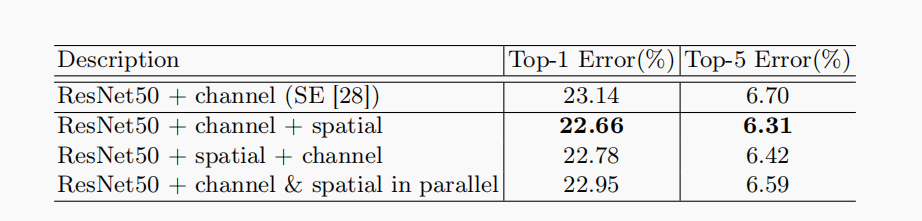
Therefore, the CBAM mechanism starts with the channel attention model and then the spatial attention map
2. Experimental results of adding CBAM mechanism to the model