In this paper, the principle of rsync algorithm and the workflow of rsync are analyzed in detail through examples. rsync Official Technical Report and Official Recommendation Articles Explanation.
Following is the rsync series:
1.rsync(1): Basic commands and usage
2.rsync(2): inotify+rsync and sersync
3.rsync algorithm principle and workflow analysis
4.rsync Technical Report (Translation)
5.rsync working mechanism (translation)
6.man rsync translation (rsync command Chinese manual)
Contents of this article:
1.2 rsync incremental transmission algorithm
1.3 Analysis of rsync algorithm with examples
1.4.1 Several processes and terminology
1.5 Analysis of rsync workflow based on execution process
1.5.1 Full-Volume Transmission Execution Process Analysis
1.5.2 incremental transmission execution process analysis
The core function of rsync is to synchronize files between local and remote hosts. Its advantage is incremental transmission. This article will not show you how to use the rsync command (see Basic usage of rsync Rather, it explains in detail how it achieves efficient incremental transmission.
Before starting to analyze the principle of the algorithm, the incremental transmission function of rsync is briefly described.
Assuming that the file to be transferred is A, if there is no file A in the target path, rsync will transfer the file A directly. If there is a file A in the target path, the sender will decide whether to transfer the file A according to the situation. By default, rsync uses the "quick check" algorithm, which compares the file size of the source file with that of the target file (if it exists) and the modification time mtime. If the size or mtime of the file at both ends are different, the sender will transfer the file, otherwise the file will be ignored.
If the "quick check" algorithm decides to transfer file A, it will not transfer the whole file A, but only the different parts of source file A and target file A, which is the real incremental transmission.
That is to say, rsync's incremental transmission is embodied in two aspects: file-level incremental transmission and block-level incremental transmission. File-level incremental transmission refers to the source host, but the target host will not directly transfer the file. Data block-level incremental transmission refers to the transmission of only the different parts of the data between the two files. But in essence, file-level incremental transmission is a special case of block-level incremental transmission. After reading through this article, it is easy to understand this point.
1.1 Problems to be Solved
Assuming that there is a file A on the host alpha and a file B on the host beta (actually the two files are named A and B in order to distinguish them), it is time to synchronize the B and A files.
The simplest way is to copy the A file directly to the beta host. But if file A is large and B and A are similar (meaning that only a few of the actual contents of the two files are different), copying the entire file A can take a lot of time. If you can copy the different parts of A and B, the transmission process will be very fast. rsync incremental transmission algorithm makes full use of the similarity of files and solves the problem of remote incremental copy.
Suppose that the content of file A is "123xxabcdef" and that of file B is "123abcdefg". Compared with B, the same data section has 123/abc/def. The contents of A are xx and a space, but file B has more data g than file A. The ultimate goal is to make the content of B and A exactly the same.
If rsync incremental transfer algorithm is adopted, alpha host will only transfer xx and space data in file A to beta host. For those same contents 123/abc/def, beta host will copy directly from B file. According to the data from these two sources, the beta host can form a copy of file A, and finally rename the copy file and overwrite the B file to ensure synchronization.
Although the process seems simple, there are many details to be explored. For example, how does alpha host know which parts of A file are different from B file, how does beta host receive data from different parts of A and B sent by alpha host, and how to make copies of file A?
1.2 rsync incremental transmission algorithm
Suppose the rsync command is to push the A file onto the beta host to keep the B file and A file synchronized, that is, the host alpha is the source host, the sender of data, the target host beta is the receiver of data. When ensuring the synchronization of B and A files, there are roughly six processes as follows:
(1) The alpha host tells the beta host file A to be transmitted.
(2) After receiving the information, the beta host divides the file B into a series of fixed size data blocks (the recommended size is between 500-1000 bytes), and numbers the data blocks with the chunk number. At the same time, the initial offset address of the data blocks and the length of the data blocks are recorded. Obviously, the size of the last data block may be smaller.
For the content "123 abcdefg" of file B, assuming that the size of the partitioned data block is 3 bytes, it is divided into the following data blocks according to the number of characters:
count=4 n=3 rem=1, which means that four data blocks are divided, the size of which is 3 bytes, and the remaining 1 byte is given to the last data block. chunk[0]: offset=0 len=3 This block corresponds to 123 chunk[1]: offset=3 len=3 This block corresponds to abc chunk[2]: offset=6 len=3 This block corresponds to def chunk[3]: offset=9 len=1 This block corresponds to g
Of course, the actual information will certainly not include the content of the document.
(3) Beta host calculates two check codes for each data block of file B according to its content: 32-bit rolling check sum and 128-bit MD4 strong check code (the current version of rsync uses 128-bit MD5 strong check code). All rolling checksum and strong check codes calculated by file B are followed by corresponding data block chunk[N] to form a set of check codes, which are then sent to host alpha.
That is to say, the content of the set of check codes is roughly as follows: sum1 is rolling checksum, sum2 is strong check code.
chunk[0] sum1=3ef2c827 sum2=3efa923f8f2e7 chunk[1] sum1=57ac2aaf sum2=aef2dedba2314 chunk[2] sum1=92d7edb4 sum2=a6sd6a9d67a12 chunk[3] sum1=afe74939 sum2=90a12dfe7485c
It should be noted that rolling checksum calculated by data blocks with different contents may be the same, but the probability is very small.
(4) When the alpha host receives the check code set of file B, the alpha host calculates the hash value of 16-bit length for each rolling check sum in the check code set, and puts each 216 hash value into a hash table in hash order. Each hash entry in the hash table points to the chunk number of rolling check sum corresponding to it in the check code set, and then checks the check code set according to the H sequence. The value of ash is sorted so that the order in the sorted set of check codes corresponds to the order in the hash table.
Therefore, the corresponding relationship between hash table and the sorted set of check codes is roughly as follows: assume that the hash value in hash table is sorted according to the order of the first character [0-9a-f].
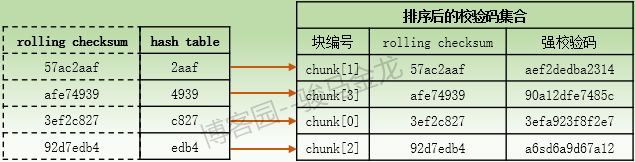
It is also important to note that hash values calculated by different rolling checksum are likely to be the same, and the probability is relatively small, but the probability of duplication is larger than rolling checksum.
(5) The host alpha will then process the file A. The process of processing is to take the same size data block from the first byte, and calculate its check codes and check codes in the set of check codes to match. If a block entry in the upper check code set can be matched, it means that the block is the same as the block in file B. It does not need to be transmitted, so host alpha jumps directly to the end offset address of the block and continues to take the block from the offset for matching. If the data block entries in the check code set cannot be matched, it means that the data block is a mismatched data block, which needs to be transmitted to host beta. Then host alpha will jump to the next byte and continue to take the data block from this byte for matching. Note that the whole block of matching data is skipped when matching is successful, and only one byte is skipped when matching is unsuccessful. It can be understood in conjunction with the examples in the next section.
The data block matching mentioned above is only a description, and the specific matching behavior needs to be refined. rsync algorithm divides the data block matching process into three levels of search matching process.
First, the host alpha calculates its rolling checksum for the acquired data block based on its content, and then calculates the hash value based on the rolling checksum.
Then, the hash value is matched with the hash entry in the hash table. This is the first level of search matching process, which compares the hash value. If a match can be found in the hash table, it indicates that the data block has the potential of identical possibilities, and then goes to the second level of search matching.
The second level of search matching is rolling checksum. Since the hash value at the first level matches the result, rolling checksum corresponding to the hash value in the search check code set is used. Since the set of check codes is sorted according to hash values, its order is the same as that in the hash table, that is to say, only rolling chcksum corresponding to hash values can be scanned downwards. In the scanning process, if rolling checksum of A file data block matches an item, it indicates that the data block has the potential of the same possibility, so stop scanning and enter the third level of search matching for final determination. Or if no matches are scanned, the data block is mismatched and the scan will stop. This means rolling checksum is different, but the hash value calculated from it has a small probability of repeated events.
The third level of search matching is stronger check code. At this time, a new strong check code will be calculated for the data block of A file (before the third level, rolling check sum and its hash value will be calculated only for the data block of A file), and the strong check code will match the corresponding strong check code in the set of check codes. If the data block can be matched, the data block will be identical, if it can not be matched, the data block will be different, and then the next number will be taken. Processing according to blocks.
The reason why we need to calculate hash value and put it into hash table is that rolling checksum is not as good as hash value, and hash search algorithm has very high performance. Because the probability of hash value duplication is small enough, most data blocks with different contents can be directly compared by hash value of the first level search. Even if a small probability hash value duplication event occurs, it can quickly locate and compare rolling checksum with smaller probability duplication. Even rolling checksum calculated with different contents may duplicate, but its duplication probability is smaller than hash value duplication probability, so almost all different data blocks can be compared through these two levels of search. Assuming that rolling checksum of data blocks with different contents still has a small probability of duplication, it will compare the strong check codes at the third level. It uses MD4 (now MD5). This algorithm has "avalanche effect". As long as a little bit different, the results are different, so in the actual use process, it can be assumed that it can make the final comparison.
The size of data blocks will affect the performance of rsync algorithm. If the size of data blocks is too small, the number of data blocks will be too large, the number of data blocks that need to be calculated and matched will be too much, the performance will be poor, and the possibility of hash value duplication and rolling checksum duplication will also increase; if the size of data blocks is too large, many data blocks may not match, resulting in the transmission of these data blocks, reducing the increment. The advantages of transmission. By default, rsync automatically determines the size of the data block based on the file size, but the "B" (or "block-size") option of the rsync command supports manual size assignment. If you specify it manually, the official recommended size is between 500 and 1000 bytes.
(6) When the alpha host finds that it is a matching block, it will send only the additional information of the matching block to the beta host. At the same time, if there are mismatched data between two matched data blocks, these mismatched data will also be sent. When the beta host receives these data one after another, it creates a temporary file and reorganizes the temporary file through these data to make its content the same as A file. After the temporary file reorganization is completed, the attribute information of the temporary file (such as permission, owner, mtime, etc.) is modified, and then the temporary file is renamed to replace the B file, so that the B file keeps synchronization with the A file.
1.3 Analysis of rsync algorithm with examples
So many theories have been mentioned before, maybe we have seen in the clouds and mists. Here, we will analyze the incremental transmission algorithm principle in the previous section in detail through the examples of A and B files. Because the process (1) - (4) in the previous section has given examples, we will continue to analyze the process (5) and process (6).
First, look at the set of check codes sorted by file B (the content is "123 abcdefg") and the hash table.
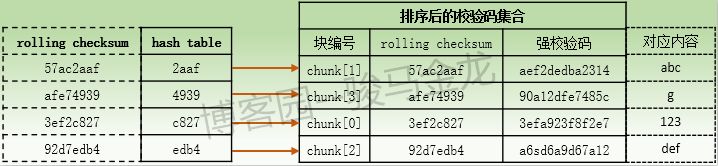
When host alpha starts processing file A, for the content "123xxabcdef" of file A, the data block of the same size is taken from the first byte, so the content of the first data block is "123". Since the content of the first data block is exactly the same as that of chunk[0] of file B, the rolling checksum value calculated by host alpha for this data block must be "3ef2e827", and the corresponding hash value is "e827". Then the alpha host matches the hash value to the hash table. During the matching process, it is found that the hash value pointing to chunk[0] can be matched, so the alpha host enters the rolling checksum comparison of the second level, that is, the entry pointing to chunk[0] from the hash value begins to scan downward. The rolling checksum of the first information (i.e. the item corresponding to chunk[0]) scanned during the scanning process can be matched, so the scanning terminates and the search matching enters the third level. Then the alpha host calculates a new strong check code for the data block "123", and compares it with the strong check code corresponding to chunk[0] in the set of check codes. Finally, it finds that the matching can be achieved, and determines the matching. The "123" data block in file A is a matching data block and does not need to be transmitted to the beta host.
Although matching blocks need not be transmitted, matching related information needs to be transmitted immediately to the beta host, otherwise the beta host does not know how to reorganize the copy of file A. The information to be transmitted by the matching block includes: the chunk[0] data block in the B file matches, and the initial offset address of the data block offset in document A is the first byte, and the length is 3 bytes.
After the transmission of matching information of the data block "123" is completed, the alpha host will take the second data block for processing. The data block should have been fetched from the second byte, but because three bytes of the data block "123" match successfully, the whole data block "123" can be skipped directly, that is, the data block should be fetched from the fourth byte, so the content of the second data block obtained by the alpha host is "xxa". Similarly, we need to calculate its rolling checksum and hash values, and search for hash entries in the matching hash table. We find that there is no hash value that can match, so we immediately determine that the data block is not a matching data block.
At this point, the alpha host will continue to take forward the third data block in the A file for processing. Since the second block is not matched, the length of one byte is skipped when the third block is taken, that is, from the fifth byte, the content of the data block is "xab". After some calculation and matching, it is found that this data block, like the second data block, is an unmatched data block. So we continue to skip ahead one byte, that is, to take the fourth data block from the sixth byte. The content of the data block obtained this time is "abc". This data block is a matched data block, so the processing method of the first data block is the same. The only difference is that the first data block is to the fourth data block, and the middle two data blocks are not matched data blocks, so we are determining the fourth data block. After matching data blocks, the non-matching content in the middle (i.e. XX in the middle of 123xxabc) is sent byte by byte to the beta host.
(As mentioned earlier, hash value and rolling checksum have a small probability of duplication. How do matches occur when duplication occurs? See the end of this section.
After processing all data blocks in A in this way, there are finally three matching data blocks chunk[0], chunk[1] and chunk[2], as well as two segments of mismatched data "xx" and ". In this way, the beta host receives matching information of matched data blocks and byte-by-byte mismatched pure data, which is the key information for the beta host to reorganize the copy of file A. Its general contents are as follows:
chunk[0] of size 3 at 0 offset=0 data receive 2 at 3 chunk[1] of size 3 at 3 offset=5 data receive 1 at 8 chunk[2] of size 3 at 6 offset=9
To illustrate this information, first look at the contents of files A and B and mark their offset addresses.
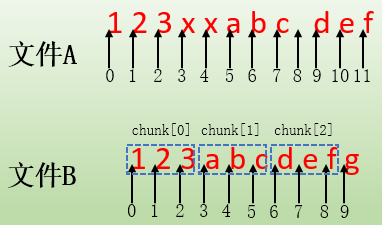
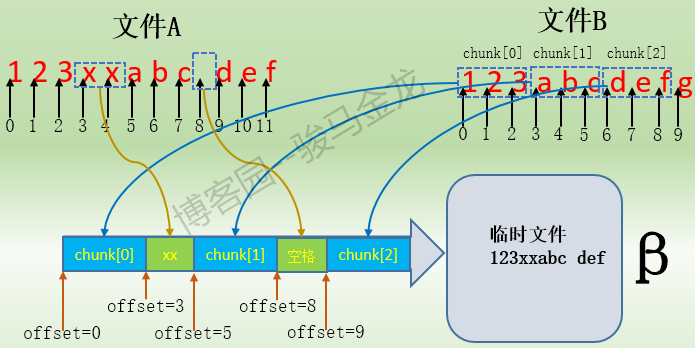
For "chunk[0] of size 3 at 0 offset=0", this paragraph indicates that it is a matching block. The matching block is chunk[0] in file B. The size of the data block is 3 bytes. The keyword at indicates that the starting offset address of the matching block in file B is 0. The keyword offset indicates that the starting offset address of the matching block in file A is 0. It can also be considered as a reorganization temporary file. Migration. That is to say, when the beta host reorganizes the file, the chunk[0] corresponding to the length of 3 bytes will be copied from the "at 0" offset of file B, and the data block content will be written to offset=0 offset of temporary file, so that the first piece of data "123" in temporary file.
For "data receive 2 at 3", this paragraph indicates that this is the pure data information received, not the matching data block. 2 denotes the number of bytes received, and "at 3" denotes the data written in these two bytes at the beginning offset of the temporary file. So the temporary file contains the data "123 xx".
For "chunk[1] of size 3 at 3 offset=5", this paragraph represents a matched data block, representing a chunk[1] corresponding to 3 bytes in length copied from the starting offset address at=3 of file B, and the contents of this data block are written to the starting offset offset=5 of temporary file, so that the temporary file has "123 xxabc".
For "data receive 1 at 8", this description receives pure data information, indicating that the received 1 byte of data is written to the starting offset address 8 of the temporary file, so there is "123 xxabc" in the temporary file.
The last paragraph "chunk[2] of size 3 at 6 offset=9" means to copy the chunk[2] corresponding to 3 bytes in length from the starting offset address at=6 of file B, and write the content of the chunk to the starting offset offset=9 of the temporary file, so that the temporary file contains "123 xxabc def". So far, the temporary file reorganization is over. Its content is exactly the same as the content of A file on alpha host. Then only need to modify the properties of the temporary file, rename and replace the file B, so that file B and file A can be synchronized.
The whole process is as follows:
It should be noted that the alpha host does not send the relevant data to the beta host after searching all the data blocks, but every time a matching data block is searched, the related information of the matching block and the mismatching data between the current matching block and the last matching block will be sent to the beta host immediately, and the next data block will be processed. When the beta host receives a piece of data, it will send the relevant information to the beta host immediately. It will be reorganized into temporary files immediately. Therefore, both alpha and beta hosts try not to waste any resources.
Matching process of 1.3.1 hash value and rolling checksum repetition
In the above example analysis, hash value duplication and rolling checksum duplication are not involved, but they may be duplicated. Although the matching process after duplication is the same, it may not be easy to understand.
Or look at the set of check codes after sorting B files.
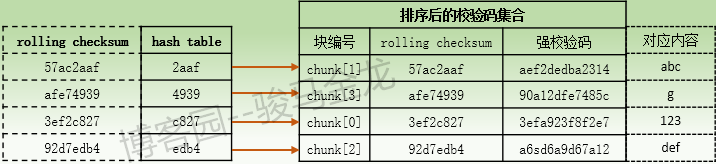
When file A processes data blocks, it is assumed that the second data block is a mismatched data block. Rolling checksum and hash values are calculated for this data block. Assuming that the hash value of this data block is successfully matched from the hash table, such as the value "4939" in the figure above, rolling checksum of this second data block is compared with rolling checksum of chunk[3] pointed to by the hash value "4939". The possibility of hash value duplication and rolling checksum duplication approaches almost zero, so it can be determined that this data block is not a matching data block.
Consider an extreme case, if file B is large and the number of data blocks is large, then rolling checksum of data blocks contained in file B itself may have duplicate events, and hash values may also have duplicate events.
For example, rolling checksum of chunk[0] and chunk[3] is different, but hash values calculated according to rolling checksum are the same. At this time, the corresponding relationship between hash table and check code set is roughly as follows:
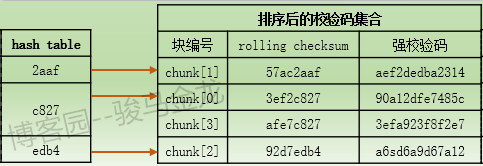
If the hash value of the data block in file A matches to "c827", we are ready to compare rolling checksum. At this time, we will scan down the checksum from the chunk[0] pointed to by the hash value "c827". When the rolling checksum of data blocks is found to match a rolling checksum, such as the rolling checksum corresponding to chunk[0] or chunk[3], the scan terminates and enters the third level of search matching. If the rolling checksum is not found until chunk[2], the scan terminates because the hash value of chunk[2] is different from the hash value of the data block. Finally, it is determined that the data block is a mismatched data block, and the alpha host proceeds to process the next data block.
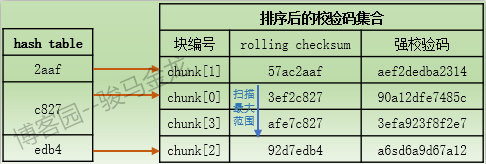
If the rolling checksum of the data block in file B is duplicated (that's just one thing, you're lucky), it will only be matched by a strong check code.
1.4 rsync workflow analysis
The core of rsync incremental transmission has been analyzed above, and the implementation of rsync incremental transmission algorithm and the whole process of rsync transmission will be analyzed below. Before that, it is necessary to explain the related concepts of client/server, sender, receiver, generator involved in rsync transmission.
1.4.1 Several processes and terminology
rsync works in three ways. One is the local transmission mode, the other is the remote shell connection mode, and the third is the rsync daemon mode using the network socket connection.
When using remote shell such as SSH connection mode, the remote shell connection, such as SSH connection, is established between the request and the remote host after typing the Rsync command locally. After the connection is established successfully, the fork remote shell process is invoked to the remote Rsync program on the remote host, and the options required by Rsync are passed to the remote Rsync through the remote shell command such as ssh. Both ends start rsync, and then they communicate via pipes, even if they are local and remote.
When a network socket is used to connect rsync daemon, when a connection is established between a network socket and a remote running rsync, the rsync daemon process creates a subprocess to respond to the connection and is responsible for all subsequent communications of the connection. In this way, the Rsync needed for connection is also started at both ends, and the communication mode is completed by network socket.
Local transmission is actually a special way of working. First, when the rsync command is executed, there will be an rsync process. Then, according to the process fork, another rsync process will act as the opposite end of the connection. After the connection is established, all subsequent communications will be pipelined.
Whatever connection mode is used, one end that initiates the connection is called client, that is, the section that executes Rsync command, and the other end of the connection is called server. Note that the server side does not represent the rsync daemon side. Server end is a general term in rsync, which is relative to client end. As long as it is not client end, it belongs to server end. It can be local end, remote shell end, or remote rsync daemon end. This is different from the server end of most daemon-like services.
The concepts of client and server of rsync survive very short. When both client and server start the rsync process and establish the rsync connection (pipeline and network socket), sender and receiver will be used to replace the concepts of client and server. Sender is the file sender and receiver is the file receiver.
When the rsync connection between the two ends is established, the rsync process on the sender side is called the sender process, which is responsible for all the work on the sender side. The rsync process on the receiver side is called the receiver process, which receives the data sent by the sender side and completes the file reorganization. The receiver side also has a core process, the generator process, which is responsible for performing the'- delete'action on the receiver side, comparing the file size and mtime to determine whether the file is skipped, dividing data blocks for each file, calculating the check codes and generating the set of check codes, and then sending the set of check codes to the sender side.
The whole transmission process of rsync is completed by these three processes. They are highly pipelined. The output of generator process is the input of sender end, and the output of sender end is the input of recevier end. Namely:
generator process - > sender process - > receiver process
Although these three processes are pipelined, it does not mean that they have data waiting delays. They work completely independently and in parallel. Generator calculates a set of check codes of a file and sends it to sender, which immediately calculates the set of check codes of the next file. Sender process will start processing the file as soon as it receives the set of check codes of generator. When a matching block encounters a file, it will send this part of relevant data to the receiver process immediately, and then process the next block immediately, while Reci process the next block. When the server process receives the data sent by sender, it immediately begins to reorganize. That is to say, as long as the processes are created, the three processes will not wait for each other.
In addition, pipelining does not mean that there is no communication between processes, but that the main work flow of rsync transmission process is pipelining. For example, the receiver process sends the file list to the generator process after it receives the file list.
1.4.2 rsync workflow
Suppose that rsync commands are executed on the alpha host and a large number of files are pushed to the beta host.
1. First, the client and server establish the connection of rsync communication. The remote shell connection mode establishes the pipeline. When connecting rsync daemon, the network socket is established.
2. After the rsync connection is established, the sender process on the sender side collects the files to be synchronized according to the source files given in the rsync command line, puts them into the file list and transmits them to the beta host. In the process of creating a list of files, there are several points to be explained:
(1) When creating a file list, the files in the sorted file list will be sorted according to the directory first, then the files in the sorted file list will be numbered, and then the files will be referenced directly using the file number.
(2) The file list also contains some attribute information of the file, including: permission mode, file size len, owner and group uid/gid, the latest modification time mtime, etc. Of course, some information is attached after specifying options, such as not specifying "-o" and "-g" options will not include uid/gid, specifying that "-sum" will also include file-level checksum value.
(3) When sending a list of files, it is not sent once after the collection is completed, but sent a directory by collecting a directory in sequence. Similarly, receiver s receive a list of files from a directory to a directory, and the list of received files has been sorted.
(4) If the exclude or hide rules are specified in the rsync command, the files filtered by these rules will be marked as hide in the file list (the essence of the exclude rule is also hide). Files with hide flags are not visible to receivers, so the receiver side assumes that the sender side does not have these hide files.
3. The receiver side receives the contents of the file list from the beginning, and immediately exits the generator process according to the receiver process fork. The generator process scans the local directory tree based on the list of files, which is called base file if the file already exists under the target path.
generator's work is generally divided into three steps:
(1) If the "- delete" option is specified in the rsync command, the deletion action is first performed on the beta host, deleting files that are not in the source path but in the target path.
(2) Then, according to the file order in the file list, compare with the file size and mtime of the local corresponding file one by one. If the size or mtime of the local file is found to be the same as in the file list, it means that the file does not need to be transferred and will be skipped directly.
(3) If it is found that the size or mtime of the local file is different, it means that the file needs to be transmitted. generator will immediately divide the file into data blocks and number them. Rolling checksum and strong checksum are calculated for each data block, and these checksum codes are combined with the data block numbers to form a set of checking codes, and then the number of the file is combined. Check code sets are sent to sender side together. After sending, start processing the next file in the file list.
It is important to note that files on the alpha host are not available on the beta host. Generator sets the check code of this file in the file list to send to sender empty. If the "-whole-file" option is specified, the generator will set the check codes of all files in the file list to empty, which will force rsync to adopt full transmission instead of incremental transmission.
Beginning with step 4 below, these steps have been explained in detail in the previous analysis of rsync algorithm, so they are only described in a general way. If you have any questions, please turn to Preceding text View the relevant content.
4. The sender process receives the data sent by the generator and reads the collection of file numbers and check codes. Then the hash value is calculated according to the rolling checksum in the set of check codes, and the hash value is put into the hash table, and the set of check codes is sorted according to the hash value, so that the order of the set of check codes and the hash table can be exactly the same.
5. After the sender process has finished sorting the set of check codes, the local corresponding files are processed according to the number of the read files. The purpose of processing is to find matching data blocks (i.e. data blocks with identical contents) and non-matching data. Whenever a matching block is found, some matching information is sent to the receiver process immediately. When all the data of the file is sent, the sender process generates a file-level whole-file check code for the file to the receiver.
6. The receiver process immediately creates a temporary file under the target path after receiving the sender's instructions and data, and reorganizes the temporary file according to the received data and instructions in order to make the file completely consistent with the file on the alpha host. In the process of reorganization, the matchable data blocks will be copied from the base file and written to the temporary file, while the unmatched data will be received from the sender.
7. After the temporary file reorganization is completed, the file-level check code will be generated for the temporary file. Compared with the whole-file check code sent by sender, if the match is successful, the temporary file and the source file are identical, which means that the temporary file reorganization is successful. If the check code matching fails, it means that there may be errors in the reorganization process, and it will be processed completely from scratch. This source file.
8. When the temporary file reorganization is successful, the receiver process will modify the attribute information of the temporary file, including permission, owner, group, mtime, etc. Finally, rename the file and overwrite the existing file (base file) under the target path. At this point, the file is synchronized.
1.5 Analysis of rsync workflow based on execution process
In order to feel more intuitively the rsync algorithm principle and workflow explained above, two examples of rsync execution process will be given below, and the workflow will be analyzed. One is an example of full transmission, the other is an example of incremental transmission.
To view the execution process of rsync, execute by adding the "- vvv" option to the Rsync command line.
1.5.1 Full-Volume Transmission Execution Process Analysis
The commands to be executed are:
[root@xuexi ~]# rsync -a -vvvv /etc/cron.d /var/log/anaconda /etc/issue longshuai@172.16.10.5:/tmp
The purpose is to transfer the / etc/cron.d directory, / var/log/anaconda directory and / etc/issue files to the / tmp directory on the 172.16.10.5 host. Because these files do not exist in the / tmp directory, the whole process is a mass transfer process. But its essence is still to adopt incremental transmission algorithm, but the set of check codes sent by generator is all empty.
The following are the hierarchies of the / etc/cron.d and / var/log/anaconda directories.
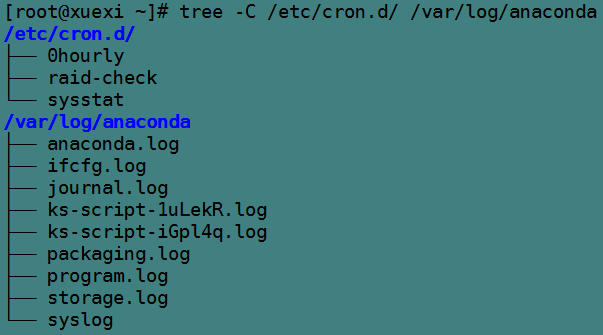
The following is the implementation process.
[root@xuexi ~]# rsync -a -vvvv /etc/cron.d /var/log/anaconda /etc/issue longshuai@172.16.10.5:/tmp # Using ssh(ssh is the default remote shell) to execute remote rsync commands to establish connections cmd=<NULL> machine=172.16.10.5 user=longshuai path=/tmp cmd[0]=ssh cmd[1]=-l cmd[2]=longshuai cmd[3]=172.16.10.5 cmd[4]=rsync cmd[5]=--server cmd[6]=-vvvvlogDtpre.iLsf cmd[7]=. cmd[8]=/tmp opening connection using: ssh -l longshuai 172.16.10.5 rsync --server -vvvvlogDtpre.iLsf . /tmp note: iconv_open("UTF-8", "UTF-8") succeeded. longshuai@172.16.10.5's password: # Both sides send each other the version number of the protocol and negotiate to use the lower version of the protocol. (Server) Protocol versions: remote=30, negotiated=30 (Client) Protocol versions: remote=30, negotiated=30 ######### sender The end generates a list of files and sends them to receiver end ############# sending incremental file list [sender] make_file(cron.d,*,0) # The first file directory to be transferred: the cron.d file. Note that here cron.d is the file to be transferred, not the directory. [sender] make_file(anaconda,*,0) # The second file directory to be transferred: anaconda file [sender] make_file(issue,*,0) # The third file directory to be transferred: issue files # Specify that starting with Item 1 of the file list, and determine that there are three items to be transferred to receiver this time [sender] flist start=1, used=3, low=0, high=2 # Generate list information for these three items, including this file id,The directory, permission mode, length, uid/gid,Finally, there's a modifier [sender] i=1 /etc issue mode=0100644 len=23 uid=0 gid=0 flags=5 [sender] i=2 /var/log anaconda/ mode=040755 len=4096 uid=0 gid=0 flas=5 [sender] i=3 /etc cron.d/ mode=040755 len=51 uid=0 gid=0 flags=5 send_file_list done file list sent # The only thing to note is the directory in which the file is located, such as/var/log anaconda/,But what is actually specified on the command line is/var/log/anaconda. # In this information log and anaconda The use of spaces separated, this space is very critical. Representation of implied directories on the left side of the space(seeman rsyncOf"-R"option), # On the right is the entire file or directory to be transferred, which by default will be in the receiver End Generation anaconda/Catalogs, but hidden catalogs on the left are not created. # But you can specify special options(as"-R"),Give Way rsync Can also be in receiver The end creates the hidden directory at the same time to create the entire directory hierarchy. # For example, if A Host/a Under the catalogue are b,c And so on many subdirectories, and b In the catalogue d File, now just want to transfer/a/b/d And retain/a/b The directory hierarchy, # Then you can use special options to change the directory where the files are located to"/ a/",For specific implementation methods, see"rsync -R Examples of options". ############ sender End-Send File Attribute Information ##################### # Since two entries in the previous file list are directories, attribute information is generated for each file in the directory and sent to the receiver side. send_files starting [sender] make_file(anaconda/anaconda.log,*,2) [sender] make_file(anaconda/syslog,*,2) [sender] make_file(anaconda/program.log,*,2) [sender] make_file(anaconda/packaging.log,*,2) [sender] make_file(anaconda/storage.log,*,2) [sender] make_file(anaconda/ifcfg.log,*,2) [sender] make_file(anaconda/ks-script-1uLekR.log,*,2) [sender] make_file(anaconda/ks-script-iGpl4q.log,*,2) [sender] make_file(anaconda/journal.log,*,2) [sender] flist start=5, used=9, low=0, high=8 [sender] i=5 /var/log anaconda/anaconda.log mode=0100600 len=6668 uid=0 gid=0 flags=0 [sender] i=6 /var/log anaconda/ifcfg.log mode=0100600 len=3826 uid=0 gid=0 flags=0 [sender] i=7 /var/log anaconda/journal.log mode=0100600 len=1102699 uid=0 gid=0 flags=0 [sender] i=8 /var/log anaconda/ks-script-1uLekR.log mode=0100600 len=0 uid=0 gid=0 flags=0 [sender] i=9 /var/log anaconda/ks-script-iGpl4q.log mode=0100600 len=0 uid=0 gid=0 flags=0 [sender] i=10 /var/log anaconda/packaging.log mode=0100600 len=160420 uid=0 gid=0 flags=0 [sender] i=11 /var/log anaconda/program.log mode=0100600 len=27906 uid=0 gid=0 flags=0 [sender] i=12 /var/log anaconda/storage.log mode=0100600 len=78001 uid=0 gid=0 flags=0 [sender] i=13 /var/log anaconda/syslog mode=0100600 len=197961 uid=0 gid=0 flags=0 [sender] make_file(cron.d/0hourly,*,2) [sender] make_file(cron.d/sysstat,*,2) [sender] make_file(cron.d/raid-check,*,2) [sender] flist start=15, used=3, low=0, high=2 [sender] i=15 /etc cron.d/0hourly mode=0100644 len=128 uid=0 gid=0 flags=0 [sender] i=16 /etc cron.d/raid-check mode=0100644 len=108 uid=0 gid=0 flags=0 [sender] i=17 /etc cron.d/sysstat mode=0100600 len=235 uid=0 gid=0 flags=0 # From the above results, no i=4 and i=14 File information, because they are directories anaconda and cron.d Document information # It was also found that no messages were sent./etc/issue File information, because issue It's a normal file, not a directory, so it's sent before it's sent. ############# All contents of the file list have been sent out #################### ############### server End-related activity content ################ # Start the rsync process on the server side first server_recv(2) starting pid=13309 # Receiving the first data transmitted by client, the server receives three pieces of data, which are files or directories in the root directory of the transmission. received 3 names [receiver] flist start=1, used=3, low=0, high=2 [receiver] i=1 1 issue mode=0100644 len=23 gid=(0) flags=400 [receiver] i=2 1 anaconda/ mode=040755 len=4096 gid=(0) flags=405 [receiver] i=3 1 cron.d/ mode=040755 len=51 gid=(0) flags=405 recv_file_list done # Completion of First Receive Data ############ stay receiver End-to-end startup generator process ######## get_local_name count=3 /tmp # Get the local path name generator starting pid=13309 # Start the generator process delta-transmission enabled # Enabling Incremental Transfer Algorithms ############ generator The process has been set up ################ ############# Processing the received ordinary files first ############## recv_generator(issue,1) # generator Received receiver Documents for process notifications id=1 Documents issue send_files(1, /etc/issue) count=0 n=0 rem=0 # This is the block information split by file issue on the target host. count s denote the number and n denotes the fixed size of the block. # rem means remain, which means the length of the remaining data, that is, the size of the last data block. # Because there is no issue file on the target side, all of them are set to 0. send_files mapped /etc/issue of size 23 # sender End Mapping/etc/issue,bring sender Relevant content of the file can be obtained calling match_sums /etc/issue # sender calls check code matching function issue sending file_sum # After matching, send file-level checksum to receiver false_alarms=0 hash_hits=0 matches=0 # Relevant Statistical Information of Output Block Matching sender finished /etc/issue # file/etc/issue Send out, because the target does not exist issue Files, so the whole process is very simple, direct transmission issue All the data in it will be enough. ############## Start processing directory format file lists ############# # First receive two id=2 and id=3 Documents recv_generator(anaconda,2) recv_generator(cron.d,3) # Then you begin to get the file information from the directory of the file list. recv_files(3) starting # First you get the file information in the dir 0 directory [receiver] receiving flist for dir 0 [generator] receiving flist for dir 0 received 9 names # Represents receipt of nine document information from the catalog [generator] flist start=5, used=9, low=0, high=8 # The id number of the file starts at 5, and there are nine entries in total. [generator] i=5 2 anaconda/anaconda.log mode=0100600 len=6668 gid=(0) flags=400 [generator] i=6 2 anaconda/ifcfg.log mode=0100600 len=3826 gid=(0) flags=400 [generator] i=7 2 anaconda/journal.log mode=0100600 len=1102699 gid=(0) flags=400 [generator] i=8 2 anaconda/ks-script-1uLekR.log mode=0100600 len=0 gid=(0) flags=400 [generator] i=9 2 anaconda/ks-script-iGpl4q.log mode=0100600 len=0 gid=(0) flags=400 [generator] i=10 2 anaconda/packaging.log mode=0100600 len=160420 gid=(0) flags=400 [generator] i=11 2 anaconda/program.log mode=0100600 len=27906 gid=(0) flags=400 [generator] i=12 2 anaconda/storage.log mode=0100600 len=78001 gid=(0) flags=400 [generator] i=13 2 anaconda/syslog mode=0100600 len=197961 gid=(0) flags=400 recv_file_list done # dir 0 File information in the catalog has been received [receiver] receiving flist for dir 1 # Then you get the file information in the dir 1 directory [generator] receiving flist for dir 1 received 3 names [generator] flist start=15, used=3, low=0, high=2 [generator] i=15 2 cron.d/0hourly mode=0100644 len=128 gid=(0) flags=400 [generator] i=16 2 cron.d/raid-check mode=0100644 len=108 gid=(0) flags=400 [generator] i=17 2 cron.d/sysstat mode=0100600 len=235 gid=(0) flags=400 recv_file_list done # dir 1 File information in the catalog has been received ################# Start transferring directories dir 0 And its internal documents ############# recv_generator(anaconda,4) # generator Receiving Directory anaconda Information, its id=4,Do you remember the above? sender Not sent id=4 and # id=14 Directory information? Only if you receive the directory first can you continue to receive the files in the directory. send_files(4, /var/log/anaconda) # Because anaconda is a directory to be created on the receiver side, the sender side sends the directory file first. anaconda/ # The anaconda directory was sent successfully set modtime of anaconda to (1494476557) Thu May 11 12:22:37 2017 # Then set the directory anaconda Of mtime(Namely modify time) # The anaconda directory on the receiver side has been established, and now it is time to transfer files in anaconda # The first file processing procedure in the first anaconda directory below recv_generator(anaconda/anaconda.log,5) # generator Process reception id=5 Of anaconda/anaconda.log file send_files(5, /var/log/anaconda/anaconda.log) count=0 n=0 rem=0 # Calculate the relevant information of the file data block send_files mapped /var/log/anaconda/anaconda.log of size 6668 # sender side mapping anaconda.log file calling match_sums /var/log/anaconda/anaconda.log # Calling Check Code Matching Function anaconda/anaconda.log sending file_sum # After data block matching, send file-level checksum to receiver false_alarms=0 hash_hits=0 matches=0 # Statistical information in the process of output matching sender finished /var/log/anaconda/anaconda.log # Anconda.log file transfer completed recv_generator(anaconda/ifcfg.log,6) # Start processing the second file in anaconda send_files(6, /var/log/anaconda/ifcfg.log) count=0 n=0 rem=0 send_files mapped /var/log/anaconda/ifcfg.log of size 3826 calling match_sums /var/log/anaconda/ifcfg.log anaconda/ifcfg.log sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /var/log/anaconda/ifcfg.log # The second file has been transferred. recv_generator(anaconda/journal.log,7) # Start processing the third file in anaconda send_files(7, /var/log/anaconda/journal.log) count=0 n=0 rem=0 send_files mapped /var/log/anaconda/journal.log of size 1102699 calling match_sums /var/log/anaconda/journal.log anaconda/journal.log sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /var/log/anaconda/journal.log # The second file has been transferred. #The following similar processes are omitted ...... recv_generator(anaconda/syslog,13) # Start processing the last file in anaconda send_files(13, /var/log/anaconda/syslog) count=0 n=0 rem=0 send_files mapped /var/log/anaconda/syslog of size 197961 calling match_sums /var/log/anaconda/syslog anaconda/syslog sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /var/log/anaconda/syslog # All files in the anaconda directory have been transferred ################# Start transferring directories dir 1 And its internal documents ############# recv_generator(cron.d,14) send_files(14, /etc/cron.d) cron.d/ set modtime of cron.d to (1494476430) Thu May 11 12:20:30 2017 recv_generator(cron.d/0hourly,15) send_files(15, /etc/cron.d/0hourly) count=0 n=0 rem=0 send_files mapped /etc/cron.d/0hourly of size 128 calling match_sums /etc/cron.d/0hourly cron.d/0hourly sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /etc/cron.d/0hourly ......Similar process ellipsis...... recv_generator(cron.d/sysstat,17) send_files(17, /etc/cron.d/sysstat) count=0 n=0 rem=0 send_files mapped /etc/cron.d/sysstat of size 235 calling match_sums /etc/cron.d/sysstat cron.d/sysstat sending file_sum false_alarms=0 hash_hits=0 matches=0 sender finished /etc/cron.d/sysstat ############## The following are receiver End-file reorganization related process ################ generate_files phase=1 # generator process enters the first stage # Reorganization of the first file issue recv_files(issue) data recv 23 at 0 # The data recv keyword denotes the pure file data obtained from the sender side, and 23 denotes that the received piece of pure data is 23 bytes in size. # at 0 means that the received data is placed at the start offset of the temporary file 0. got file_sum # Get the checksum at the file level sent to the sender end and check it. Check through indicates that the reorganization is completed formally. set modtime of .issue.RpT9T9 to (1449655155) Wed Dec 9 17:59:15 2015 # After the temporary file reorganization is completed, set the mtime of the temporary file renaming .issue.RpT9T9 to issue # Finally, rename the temporary file to the target file # So far, the first file really completes synchronization # Reorganize the second file list anaconda and its internal files recv_files(anaconda) # Restructuring directory anaconda recv_files(anaconda/anaconda.log) # The first file in the reorganization directory anaconda data recv 6668 at 0 got file_sum set modtime of anaconda/.anaconda.log.LAR2t1 to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.anaconda.log.LAR2t1 to anaconda/anaconda.log # Synchronization of the first file in the anaconda directory recv_files(anaconda/ifcfg.log) # Reorganization of the second file in the directory anaconda data recv 3826 at 0 got file_sum set modtime of anaconda/.ifcfg.log.bZDW3S to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.ifcfg.log.bZDW3S to anaconda/ifcfg.log # Synchronization of the second file in the anaconda directory recv_files(anaconda/journal.log) # The third file in the reorganization directory anaconda data recv 32768 at 0 # Since the maximum amount of data transferred per time is 32 kB, the larger journal.log is divided into several transfers. data recv 32768 at 32768 data recv 32768 at 65536 .............. got file_sum set modtime of anaconda/.journal.log.ylpZDK to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.journal.log.ylpZDK to anaconda/journal.log # Synchronization of the third file in the anaconda directory .........Elimination of intermediate similar processes........... recv_files(anaconda/syslog) data recv 32768 at 0 data recv 32768 at 32768 data recv 32768 at 65536 ................ got file_sum set modtime of anaconda/.syslog.zwQynW to (1494476557) Thu May 11 12:22:37 2017 renaming anaconda/.syslog.zwQynW to anaconda/syslog # So far, anaconda and all its files have been synchronized # Reorganize the third file list cron.d and its internal files recv_files(cron.d) recv_files(cron.d/0hourly) ......Elimination of intermediate similar processes.......... recv_files(cron.d/sysstat) data recv 235 at 0 got file_sum set modtime of cron.d/.sysstat.m4hzgx to (1425620722) Fri Mar 6 13:45:22 2015 renaming cron.d/.sysstat.m4hzgx to cron.d/sysstat # So far, cron.d and all its files have been synchronized send_files phase=1 touch_up_dirs: cron.d (1) # sender process modifies various timestamps of cron.d in the upper directory set modtime of cron.d to (1494476430) Thu May 11 12:20:30 2017 # Setting mtime of cron.d directory recv_files phase=1 generate_files phase=2 send_files phase=2 send files finished # The sender process fades and outputs matching statistics and the total amount of pure data transmitted total: matches=0 hash_hits=0 false_alarms=0 data=1577975 recv_files phase=2 generate_files phase=3 recv_files finished generate_files finished client_run waiting on 13088 sent 1579034 bytes received 267 bytes 242969.38 bytes/sec # A total of 157934 bytes of data were sent. This statistic includes pure file data. # And all kinds of non-file data, received 267 bytes of data from receiver side total size is 1577975 speedup is 1.00 # sender The total size of all files on the end is 157775 bytes, because receiver No end at all. basis file, # So the total size is equal to the amount of pure data transmitted. [sender] _exit_cleanup(code=0, file=main.c, line=1052): entered [sender] _exit_cleanup(code=0, file=main.c, line=1052): about to call exit(0)
1.5.2 incremental transmission execution process analysis
The commands to be executed are:
[root@xuexi ~]# rsync -vvvv /tmp/init 172.16.10.5:/tmp
The purpose is to transfer the / etc/init file to the / tmp directory on the 172.16.10.5 host. Because the file already exists in the / tmp directory, the whole process is incremental transmission.
The following is the implementation process.
[root@xuexi ~]# rsync -vvvv /tmp/init 172.16.10.5:/tmp # Using ssh(ssh is the default remote shell) to execute remote rsync commands to establish connections cmd=<NULL> machine=172.16.10.5 user=<NULL> path=/tmp cmd[0]=ssh cmd[1]=172.16.10.5 cmd[2]=rsync cmd[3]=--server cmd[4]=-vvvve.Lsf cmd[5]=. cmd[6]=/tmp opening connection using: ssh 172.16.10.5 rsync --server -vvvve.Lsf . /tmp note: iconv_open("UTF-8", "UTF-8") succeeded. root@172.16.10.5's password: # Both sides send each other the version number of the protocol and negotiate to use the lower version of the protocol. (Server) Protocol versions: remote=30, negotiated=30 (Client) Protocol versions: remote=30, negotiated=30 [sender] make_file(init,*,0) [sender] flist start=0, used=1, low=0, high=0 [sender] i=0 /tmp init mode=0100644 len=8640 flags=0 send_file_list done file list sent send_files starting server_recv(2) starting pid=13689 # Start the receiver process remotely received 1 names [receiver] flist start=0, used=1, low=0, high=0 [receiver] i=0 1 init mode=0100644 len=8640 flags=0 recv_file_list done get_local_name count=1 /tmp generator starting pid=13689 # Start the generator process remotely delta-transmission enabled recv_generator(init,0) recv_files(1) starting gen mapped init of size 5140 # generator process maps the base file file file (that is, the local init file), and only after mapping can each process obtain the relevant data block of the file. generating and sending sums for 0 # Generate the set of weak scroll check codes and strong check codes of init files and send them to sender send_files(0, /tmp/init) # Check code set information generated by the following generator count=8 rem=240 blength=700 s2length=2 flength=5140 count=8 n=700 rem=240 # count=8 Represents that the file calculates a total of 8 data blocks of check codes. n=700 Indicates that the size of a fixed data block is 700 bytes. # rem=240(remain)Represents the final 240 bytes, the length of the last data block chunk[0] offset=0 len=700 sum1=3ef2e827 chunk[0] len=700 offset=0 sum1=3ef2e827 chunk[1] offset=700 len=700 sum1=57aceaaf chunk[1] len=700 offset=700 sum1=57aceaaf chunk[2] offset=1400 len=700 sum1=92d7edb4 chunk[2] len=700 offset=1400 sum1=92d7edb4 chunk[3] offset=2100 len=700 sum1=afe7e939 chunk[3] len=700 offset=2100 sum1=afe7e939 chunk[4] offset=2800 len=700 sum1=fcd0e7d5 chunk[4] len=700 offset=2800 sum1=fcd0e7d5 chunk[5] offset=3500 len=700 sum1=0eaee949 chunk[5] len=700 offset=3500 sum1=0eaee949 chunk[6] offset=4200 len=700 sum1=ff18e40f chunk[6] len=700 offset=4200 sum1=ff18e40f chunk[7] offset=4900 len=240 sum1=858d519d chunk[7] len=240 offset=4900 sum1=858d519d # After sender receives the set of check codes, it is ready to start the data block matching process. send_files mapped /tmp/init of size 8640 # sender Process Mapping Local/tmp/init File, only after mapping can each process obtain the relevant data block of the file calling match_sums /tmp/init # Start calling the check code matching function, right/tmp/init File search matching init built hash table # sender generates a 16-bit hash value based on the rolling check code in the received set of check codes and puts the hash value into the hash table hash search b=700 len=8640 # First floor hash Search, the size of the data block searched is 700 bytes, the total search length is 8640, that is, the whole./tmp/init Size sum=3ef2e827 k=700 hash search s->blength=700 len=8640 count=8 potential match at 0 i=0 sum=3ef2e827 # stay chunk[0]Potential matching blocks are found, where i The expression is sender Number of End Matching Block match at 0 last_match=0 j=0 len=700 n=0 # Finally, it is determined that the data block on the starting offset 0 can match perfectly, and j represents the chunk number in the set of check codes. # rolling checksum and strong check codes may also be matched in this process. potential match at 700 i=1 sum=57aceaaf match at 700 last_match=700 j=1 len=700 n=0 # The last_match value is the last matching block termination offset potential match at 1400 i=2 sum=92d7edb4 match at 1400 last_match=1400 j=2 len=700 n=0 potential match at 2100 i=3 sum=afe7e939 match at 2100 last_match=2100 j=3 len=700 n=0 potential match at 7509 i=6 sum=ff18e40f # stay chunk[6]Potential matching blocks are found. match at 7509 last_match=2800 j=6 len=700 n=4709 # The initial offset address of the matching block is 7509, and the last offset of the matching block is 2800. # The middle 4709 bytes of data are not matched, and these data need to be sent to the receiver in a pure data way. done hash search # Matching End sending file_sum # After matching on the sender side, the checksum at the file level is regenerated and sent to the receiver side. false_alarms=0 hash_hits=5 matches=5 # Output the statistical information in the matching process, there are five matching blocks, all of which are matched by hash. # Layer 2 rolling checksum check was not performed sender finished /tmp/init # sender completes the search and matching process send_files phase=1 # The sender process enters its first phase # The sender process is temporarily over # Enter the receiver side for operation generate_files phase=1 # generator process enters the first stage recv_files(init) # Reciver process reads local init file recv mapped init of size 5140 # receiver Process mapping init Documents, namely basis file ##################### Following is the file reorganization process ##################### chunk[0] of size 700 at 0 offset=0 # receiver The process follows basis file Chinese copy chunk[0]Corresponding data blocks to temporary files chunk[1] of size 700 at 700 offset=700 # receiver The process follows basis file Chinese copy chunk[1]Corresponding data blocks to temporary files chunk[2] of size 700 at 1400 offset=1400 chunk[3] of size 700 at 2100 offset=2100 data recv 4709 at 2800 # The receiver process receives 4709 bytes of pure data sent by sender from 2800 offset to temporary files. chunk[6] of size 700 at 4200 offset=7509 # receiver The process follows basis file 4200 copies of the initial offset chunk[6]Corresponding data blocks to temporary files data recv 431 at 8209 # The receiver process receives 431 bytes of pure data sent by sender to temporary files from offset 8209. got file_sum # Get the file-level checksum and compare it with the file-level checksum sent by the sender process renaming .init.gd5hvw to init # Rename the temporary file successfully reorganized as the target file init ###################### File reorganization completed ########################### recv_files phase=1 generate_files phase=2 send_files phase=2 send files finished # The sender process ends and reports are output on the sender side: Five matching blocks are found in the search process, all matched by 16-bit hash values. # In the second layer, the number of weak check codes is 0, that is to say, there is no small probability event with hash value conflict. Total pure data transferred is 5140 bytes total: matches=5 hash_hits=5 false_alarms=0 data=5140 recv_files phase=2 generate_files phase=3 recv_files finished # Reciver process termination generate_files finished # generator process termination client_run waiting on 13584 sent 5232 bytes received 79 bytes 2124.40 bytes/sec # sender sends 5232 bytes, including 5140 bytes of pure data and non-file data, and receives 79 bytes. total size is 8640 speedup is 1.63 [sender] _exit_cleanup(code=0, file=main.c, line=1052): entered [sender] _exit_cleanup(code=0, file=main.c, line=1052): about to call exit(0)
Back to the outline of the series: http://www.cnblogs.com/f-ck-need-u/p/7048359.html