1. Source code modification
(1) Error reporting
UnicodeDecodeError: 'gbk' codec can't decode byte 0x9a in position 8: illegal multibyte sequence
Load ../data/PHP-WEBSHELL/xiaoma/1148d726e3bdec6db65db30c08a75f80.php Traceback (most recent call last): ...... t=load_file(file_path) for line in f: UnicodeDecodeError: 'gbk' codec can't decode byte 0x9a in position 8: illegal multibyte sequence
Change the code to
def load_file(file_path):
t=""
with open(file_path,encoding='utf-8') as f:
for line in f:
line=line.strip('\n')
t+=line
return t(2) Error 2:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbe in position 15: invalid start byte
Load ../data/PHP-WEBSHELL/xiaoma/6b2548e859dd00dbf9e11487597b2c06.php
Traceback (most recent call last):
t=load_file(file_path)
for line in f:
File "C:\ProgramData\Anaconda3\lib\codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbe in position 15: invalid start byte
If this error is reported, save the file as and change it to utf-8 code


2. Black and white sample acquisition in data set processing
The data set used in this section is the black samples collected on the Internet, that is, the collection of all kinds of horses and ponies.

Open the pony directory and you can see the pony file with 54 php suffixes
Open a file and you can see that the content is a one sentence Trojan horse

The samples should include black samples and Aries bar. For the detection of webshell based on the text features of webshell, it is mentioned above that the webshell collected on the Internet is used as the black sample, and the white sample adopts the latest wordpress source code, as shown below
3. Sample Vectorization
In this article, the PHP suffix file is a black-and-white sample, which needs to be converted into a vector. Treat a PHP file as a string, cut it based on word 2-gram, and traverse all the files to form a vocabulary based on 2-gram. Then further vectorize each PHP file
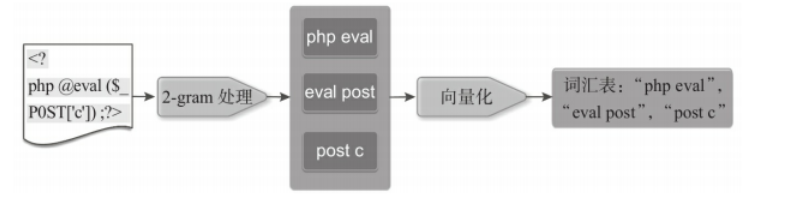
The idea of webshell is to divide the php webshell file into words (regular r'\b\w+\b') and get the word set according to the 2-gram algorithm, so as to get the distribution of each line of the file on the word set and the feature vector; Then, the normal php file is also used to obtain the feature vector on the above word set according to the above method.
(1) What are N-gram and 2-gram
N-gram is an important language model in NLP processing in machine learning. Its basic idea is to operate the contents of the text in a sliding window of size n according to bytes to form a sequence of byte fragments with length n. N-gram model refers to a sequence of N consecutive words. N=1 is called unigram, N=2 is called bigram, N=3 is called trigram, and so on.
The model is based on the assumption that the occurrence of the nth word is only related to the first N-1 word, but not to any other word. The probability of the whole sentence is the product of the occurrence probability of each word. These probabilities can be obtained by directly counting the number of simultaneous occurrences of N words from the corpus. Binary Bi gram and ternary tri gram are commonly used.

(2) Black sample
The code is as follows:
webshell_bigram_vectorizer = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",
token_pattern = r'\b\w+\b',min_df=1)
webshell_files_list=load_files("../data/PHP-WEBSHELL/xiaoma/")
x1=webshell_bigram_vectorizer.fit_transform(webshell_files_list).toarray()
print(len(x1), x1[0])
y1=[1]*len(x1)Print feature
print(webshell_bigram_vectorizer.get_feature_names())
The results are as follows:

Print vocabulary
vocabulary=webshell_bigram_vectorizer.vocabulary_
The contents are as follows: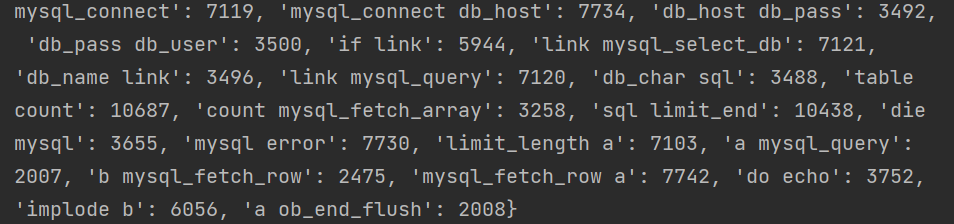
(3) White sample
The code is as follows
vocabulary=webshell_bigram_vectorizer.vocabulary_
wp_bigram_vectorizer = CountVectorizer(ngram_range=(2, 2),
decode_error="ignore", token_pattern = r'\b\w+\b',min_df=1,vocabulary=vocabulary)
wp_files_list=load_files("../data/wordpress/")
x2=wp_bigram_vectorizer.fit_transform(wp_files_list).toarray()
print(len(x2), x2[0])
y2=[0]*len(x2)(4) Construct training set
The code is as follows
x=np.concatenate((x1,x2))
y=np.concatenate((y1, y2))5. The complete code is as follows:
The basic operating environment is Python 3. The following is the modified source code that can run normally
import os
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
from sklearn import model_selection
from sklearn.naive_bayes import GaussianNB
def load_file(file_path):
t=""
with open(file_path, encoding='utf-8') as f:
for line in f:
line=line.strip('\n')
t+=line
return t
def load_files(path):
files_list=[]
for r, d, files in os.walk(path):
for file in files:
if file.endswith('.php'):
file_path=path+file
#print("Load %s" % file_path)
t=load_file(file_path)
files_list.append(t)
return files_list
if __name__ == '__main__':
webshell_bigram_vectorizer = CountVectorizer(ngram_range=(2, 2), decode_error="ignore",token_pattern = r'\b\w+\b',min_df=1)
webshell_files_list=load_files("../data/PHP-WEBSHELL/xiaoma/")
x1=webshell_bigram_vectorizer.fit_transform(webshell_files_list).toarray()
print(len(x1), x1[0])
y1=[1]*len(x1)
vocabulary=webshell_bigram_vectorizer.vocabulary_
wp_bigram_vectorizer = CountVectorizer(ngram_range=(2, 2),
decode_error="ignore", token_pattern = r'\b\w+\b',min_df=1,vocabulary=vocabulary)
wp_files_list=load_files("../data/wordpress/")
x2=wp_bigram_vectorizer.fit_transform(wp_files_list).toarray()
print(len(x2), x2[0])
y2=[0]*len(x2)
x=np.concatenate((x1,x2))
y=np.concatenate((y1, y2))
clf = GaussianNB()
# Use three fold cross validation
scores = model_selection.cross_val_score(clf, x, y, n_jobs=1, cv=3)
print(scores)
print(scores.mean())
6. Operation results (30% cross validation)
[0.71153846 0.88235294 0.74509804] 0.7796631473102061
7.10 cross validation results
The code is as follows
# Use three fold cross validation
scores = model_selection.cross_val_score(clf, x, y, n_jobs=1, cv=10)
print(scores)
print(scores.mean())The operation results are as follows
[0.75 0.4375 0.625 0.6875 0.73333333 0.66666667 0.73333333 0.53333333 0.46666667 0.53333333] 0.6166666666666666