The project is advanced to build a safe and efficient enterprise service
Spring Security

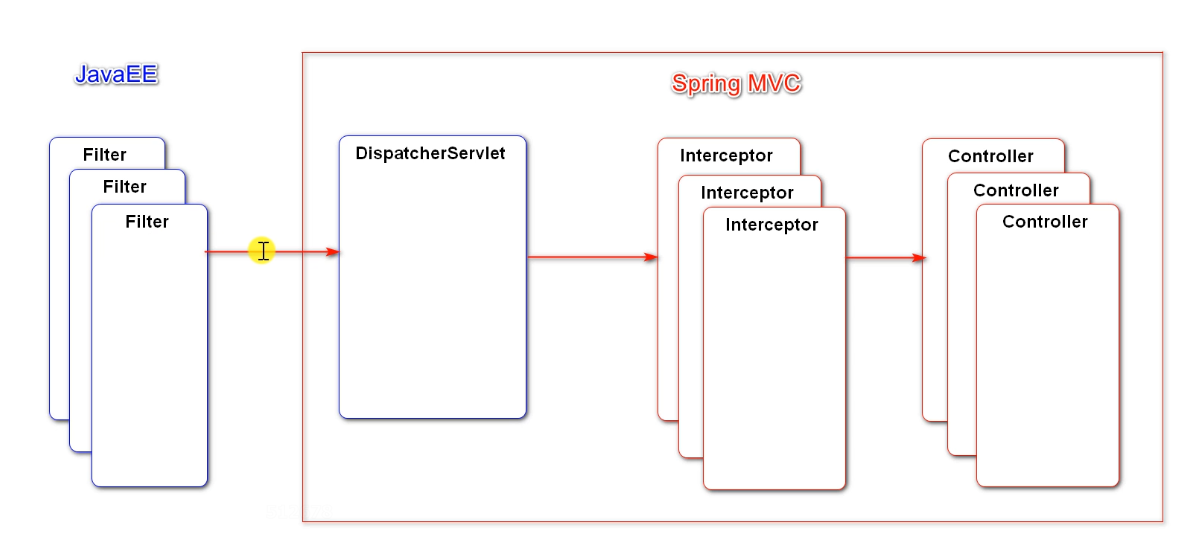
The bottom layer of Spring Security intercepts the whole request by using filter (many special login, permission, exit...) and Java EE specification. The control of permission is relatively advanced. If the permission is not available, you can't get to DispatcherServlet, let alone controller
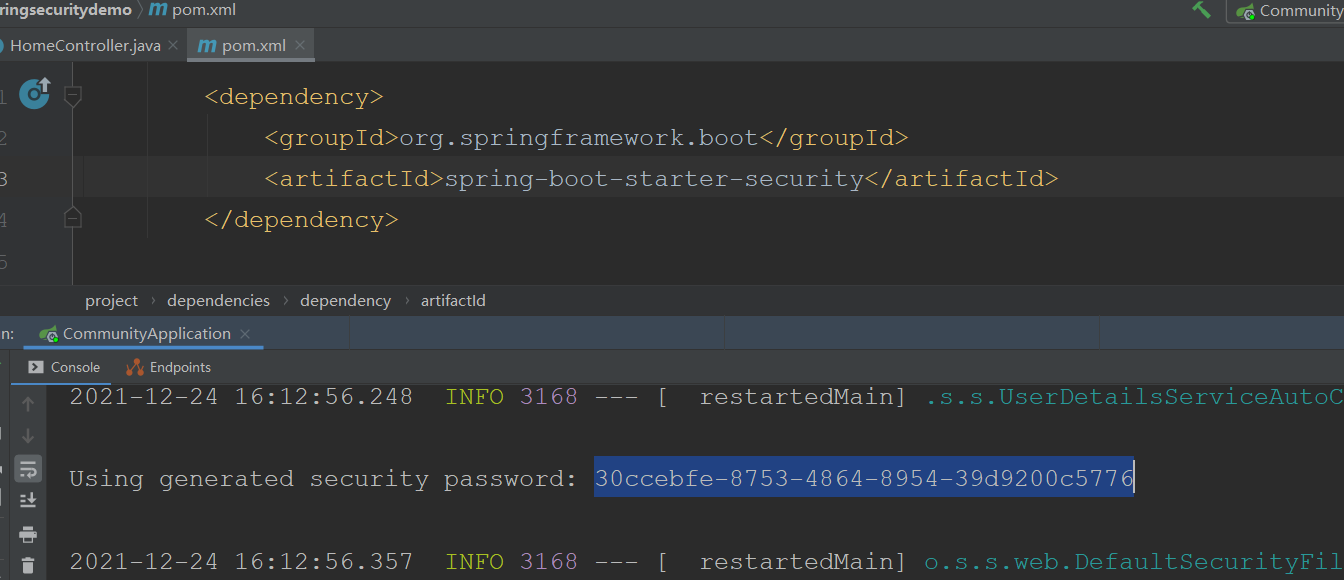
Guide Package
After importing the package, the security management of the project will be carried out automatically. The login page is provided. The console has a password and the user name is user
How to change its landing page to its own? Log in with the data in your own database?
Authentication and authorization are processed in the business layer. How do you reflect the permissions of the current user? You can create a role table. The type field of user (0 ordinary, 1 administrator, 2 moderator) requires a clear permission string when using Security for authorization?
1. Let the user entity class implement the UserDetails interface and implement the methods inside.
public class User implements UserDetails {
//true: the account has not expired
@Override
public boolean isAccountNonExpired() {
return true;
}
//true: the account is not locked
@Override
public boolean isAccountNonLocked() {
return true;
}
//true: the voucher has not expired
@Override
public boolean isCredentialsNonExpired() {
return true;
}
//true: the account is available
@Override
public boolean isEnabled() {
return true;
}
//Returns the permissions the user has
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
List<GrantedAuthority> list=new ArrayList<>();
list.add(new GrantedAuthority() {
@Override
public String getAuthority() {//Each method encapsulates one permission (multiple encapsulates multiple permissions)
switch (type){
case 1:
return "ADMIN";
default:
return "USER";
}
}
});
return list;
}
2. Let userservice implement the UserDetailsService interface
Check the user according to the user name and automatically judge whether the account and password are correct
public class UserService implements UserDetailsService {
@Override
public UserDetails loadUserByUsername(String s) throws UsernameNotFoundException {
return this.findUserByName(s);
}
}
3. Use security to authorize the project
Configure in the configuration class, inherit WebSecurityConfigurerAdapter, and override the parent class method
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
private UserService userService;
@Override
public void configure(WebSecurity web) throws Exception {
//Ignore all static resources under resource
web.ignoring().antMatchers("/resources/**");
}
//Process authentication
//Authentication manager: the core interface of authentication
//AuthenticationManagerBuilder: a tool for building AuthenticationManager objects
//Providermanager: default implementation class of AuthenticationManager interface
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
//Built in authentication rules
// auth.userDetailsService(userService).passwordEncoder(new Pbkdf2PasswordEncoder("12345"));// Original password + 12345 encryption
//Custom authentication rules
//AuthenticationProvider:ProviderManager holds a group of authenticationproviders, and each AuthenticationProvider is responsible for one kind of authentication
//Delegation mode: ProviderManager delegates authentication to AuthenticationProvider
auth.authenticationProvider(new AuthenticationProvider() {
//Authentication: an interface used to encapsulate authentication information. Different implementation classes represent different types of authentication information
@Override
public Authentication authenticate(Authentication authentication) throws AuthenticationException {
//Obtain the account password for verification
String username = authentication.getName();
String password = (String) authentication.getCredentials();
User user = userService.findUserByName(username);
if (user==null){
throw new UsernameNotFoundException("Account does not exist!");
}
password = CommunityUtil.md5(password + user.getSalt());
if(!user.getPassword().equals(password)){
throw new BadCredentialsException("Incorrect password!");
}
//principal: main information, credentials: certificate, authorities: Authority
return new UsernamePasswordAuthenticationToken(user,user.getPassword(),user.getAuthorities());
}
//What type of authentication does the current AuthenticationProvider support
@Override
public boolean supports(Class<?> aClass) {
//Use account password authentication
return UsernamePasswordAuthenticationToken.class.equals(aClass);
}
});
}
//to grant authorization
@Override
protected void configure(HttpSecurity http) throws Exception {
//Avoid the default login page
//Login related configuration
http.formLogin()
.loginPage("/loginpage")//Tell me who the landing page is
.loginProcessingUrl("/login")//Log in to the path when submitting the form, blocking
.successHandler(new AuthenticationSuccessHandler() {//Successful processor, processing on success
@Override
public void onAuthenticationSuccess(HttpServletRequest request, HttpServletResponse response, Authentication authentication) throws IOException, ServletException {
//Redirect to home page
response.sendRedirect(request.getContextPath()+"/index");
}
})
.failureHandler(new AuthenticationFailureHandler() {//Failed processor, processing in case of failure
@Override
public void onAuthenticationFailure(HttpServletRequest request, HttpServletResponse response, AuthenticationException e) throws IOException, ServletException {
//Go back to the home page (no redirection, redirection will make the client send a new request, the request changes, and the next parameter cannot be passed)
//Bind the request to the request and forward the request (within the same request, you can pass parameters through req) to the home page
request.setAttribute("error",e.getMessage());
request.getRequestDispatcher("/loginpage").forward(request,response);
}
});
//Exit related configuration
http.logout()
.logoutUrl("/logout")
.logoutSuccessHandler(new LogoutSuccessHandler() {
@Override
public void onLogoutSuccess(HttpServletRequest request, HttpServletResponse response, Authentication authentication) throws IOException, ServletException {
response.sendRedirect(request.getContextPath()+"/index");//Exit successfully redirected to home page
}
});
//Authorization configuration (corresponding relationship between permission and path)
http.authorizeRequests()
.antMatchers("/letter").hasAnyAuthority("USER","ADMIN")
.antMatchers("/admin").hasAnyAuthority("ADMIN")
.and().exceptionHandling().accessDeniedPage("/denied");
//Access path without permission
//Add Filter to process verification code
http.addFilterBefore(new Filter() {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request=(HttpServletRequest)servletRequest;
HttpServletResponse response=(HttpServletResponse) servletResponse;
if(request.getServletPath().equals("/login")){//The request path is login
String verifyCode = request.getParameter("verifyCode");
if(verifyCode==null || !verifyCode.equalsIgnoreCase("1234")){
request.setAttribute("error","Verification code error!");
request.getRequestDispatcher("/loginpage").forward(request,response);
return;
}
}
//Let the request continue down
filterChain.doFilter(request,response);
}
}, UsernamePasswordAuthenticationFilter.class);
//Remember me
http.rememberMe()//The default will remember me in memory
.tokenRepository(new InMemoryTokenRepositoryImpl())
.tokenValiditySeconds(3600*24)//Expiration time
.userDetailsService(userService);//Find out the user information according to the id in the next login
}
}
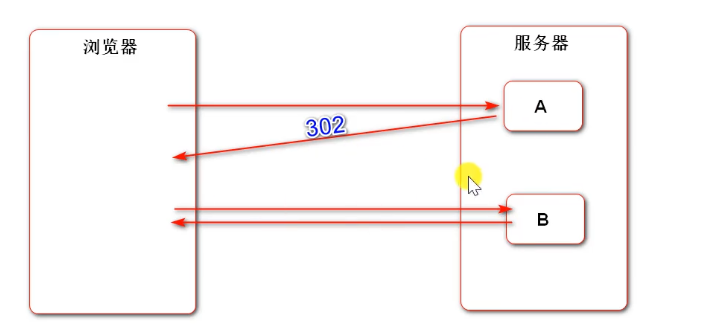
The difference between forwarding and redirection
Redirect:
The browser accesses component A, but component A has no information to feed back to the browser (for example, deletion). After deletion, you want to query the page, but the two have no relationship. Two independent components are suitable for redirection at this time. The address bar changes
B's access is accessed by the browser itself, and A just gives A suggestion and path, low coupling jump. However, if A wants to bring A message to B, it won't work because A new request request is opened (two requests need A cookie or session if they want to share data).
forward:
The browser accesses a, but a can only process part of the request, and the other part needs to be processed by B (A and B cooperate). The whole process is a request. A can store the data in the request and B can take it out. The address bar remains unchanged
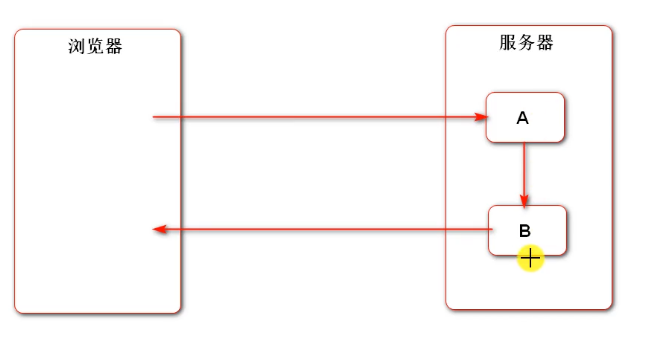
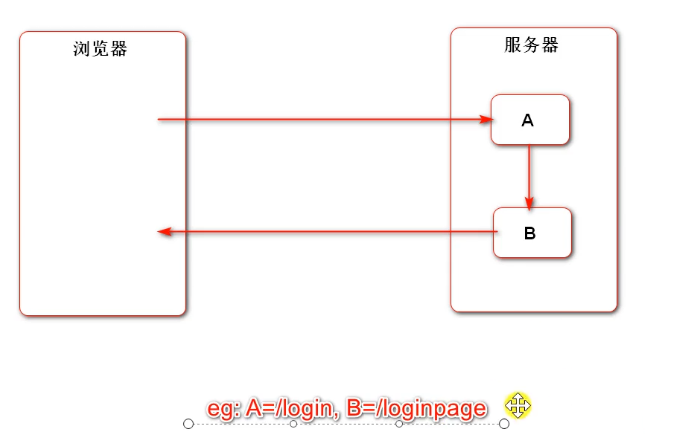
In short, the server has two components that want to jump. Check whether the two components are cooperative or independent, and choose forwarding or redirection
For example, A is the form submitted by login, B is the page of login failure, and after A fails, transfer the request to B (we directly use the return template in the project), so that B can reuse A's code logic and add other logic
Security requires that the exit must be a post request
<li>
<form method="post" th:action="@{/logout}">
<!--Push out the submission form with js realization-->
<a href="javascript:document.forms[0].submit();">sign out</a>
</form>
</li>
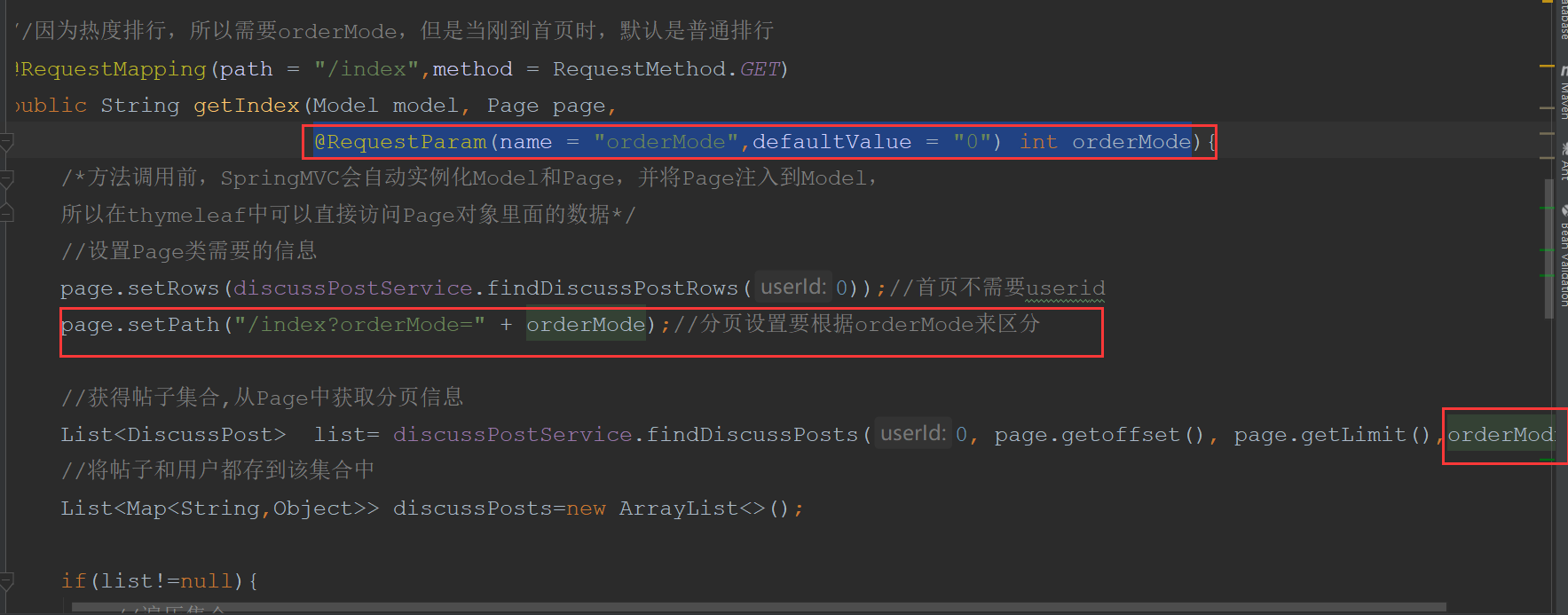
@RequestMapping(path = "/index", method = RequestMethod.GET)
public String getIndexPage(Model model) {
//After successful authentication, the results will be stored in the SecurityContext through the SecurityContextHolder
Object obj = SecurityContextHolder.getContext().getAuthentication().getPrincipal();
if(obj instanceof User){
model.addAttribute("loginUser",obj);
}
return "/index";
}
After successful authentication, the results will be stored in the SecurityContext through the SecurityContextHolder
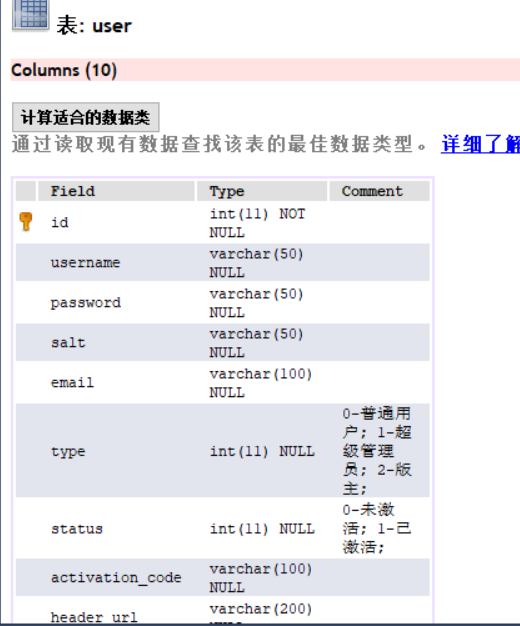
Permission control

1. Log out the logged in interceptors
2. Write a configuration class and inherit the parent WebSecurityConfigurerAdapter
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter implements CommunityConstant {
@Override
public void configure(WebSecurity web) throws Exception {
//Ignore interception of static resources
web.ignoring().antMatchers("/resources/**");
}
@Override
protected void configure(HttpSecurity http) throws Exception {
//Configure authorization (which paths must be logged in to access, and which identities can access)
http.authorizeRequests()
.antMatchers(
"/user/setting",
"/user/upload",
"/discuss/add",
"/comment/add/**",
"/letter/**",
"/notice/**",
"/like",
"/follow",
"/unfollow"
)
.hasAnyAuthority(
//Any permission can be accessed
AUTHORITY_USER,
AUTHORITY_ADMIN,
AUTHORITY_MODERATOR
)
.anyRequest().permitAll();//Requests other than these can be accessed directly
}
}
What is SRF
When there is an identity cookie in your browser, you go to the server and want it to return a form. After the server returns, you get that the form is not submitted and visit another insecure website B. website B contains a virus that can steal your cookie information and submit the form to the server. If this is a bank account system, This operation is very harmful
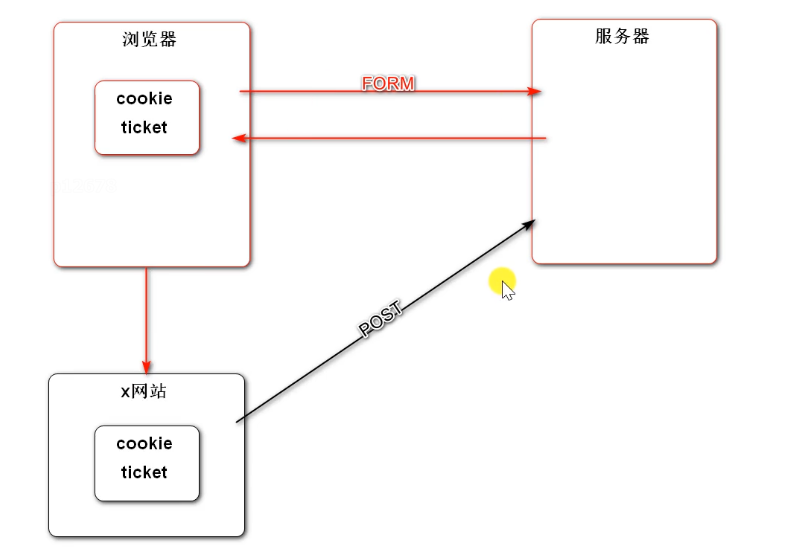
Conclusion: a website uses cookie s to imitate your identity to visit the server and submit forms to achieve some purpose
When Security returns the form, it will hide a data token Certificate (randomly generated). A website can steal your cookie, but it can't get the token. When it submits, the server will compare the cookie with the token
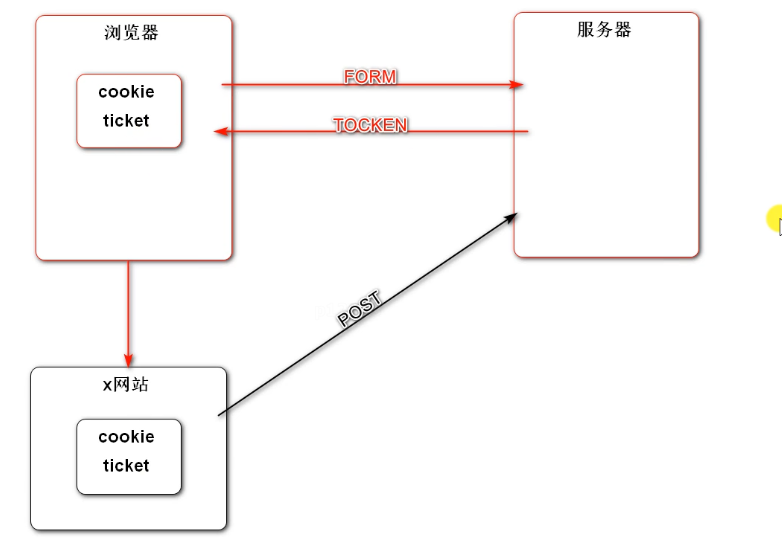
However, asynchronous requests have security risks, because asynchronous requests have no forms and cannot generate csrf vouchers
Asynchronous request when processing post
When we visit this page, we will generate the key and value of csrf (just get the value when making asynchronous requests)
<!--Generated here when accessing this page CSRF token-->
<meta name="_csrf" th:content="${_csrf.token}">
<meta name="_csrf_header" th:content="${_csrf.headerName}">
Asynchronous request (js) modification
//Before sending the AJAX request, set the CSRF token into the request header
var token=$("meta[name='_csrf']").attr("content");
var header=$("meta[name='_csrf_header']").attr("content");
$(document).ajaxSend(function (e,xhr,options) {
xhr.setRequestHeader(header,token);
});
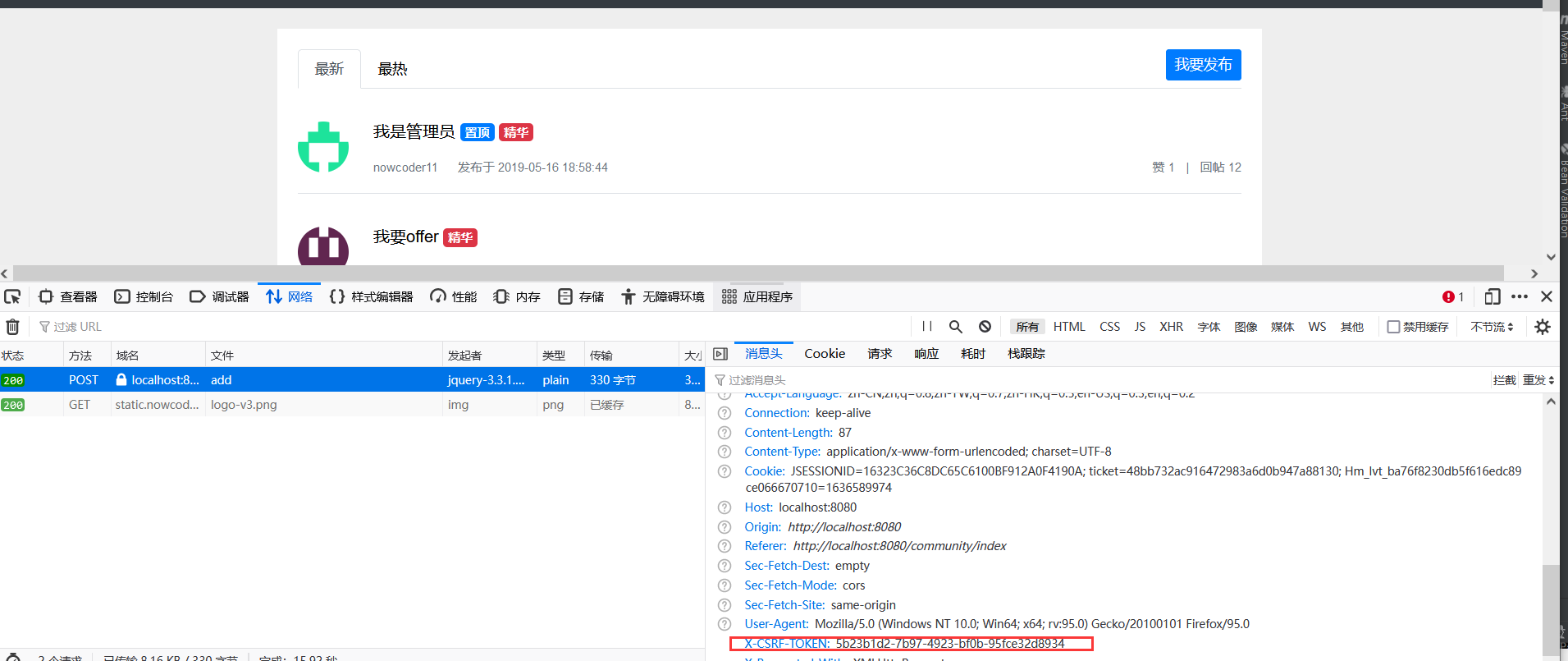
After you write this, each asynchronous request should be processed, otherwise the security will not pass, because there are many asynchronous requests in the project, which are not processed by one, so they are logged out.
Disable csrf in security and do not let it go through this logic (disable it in authorization)
Top, refine, delete
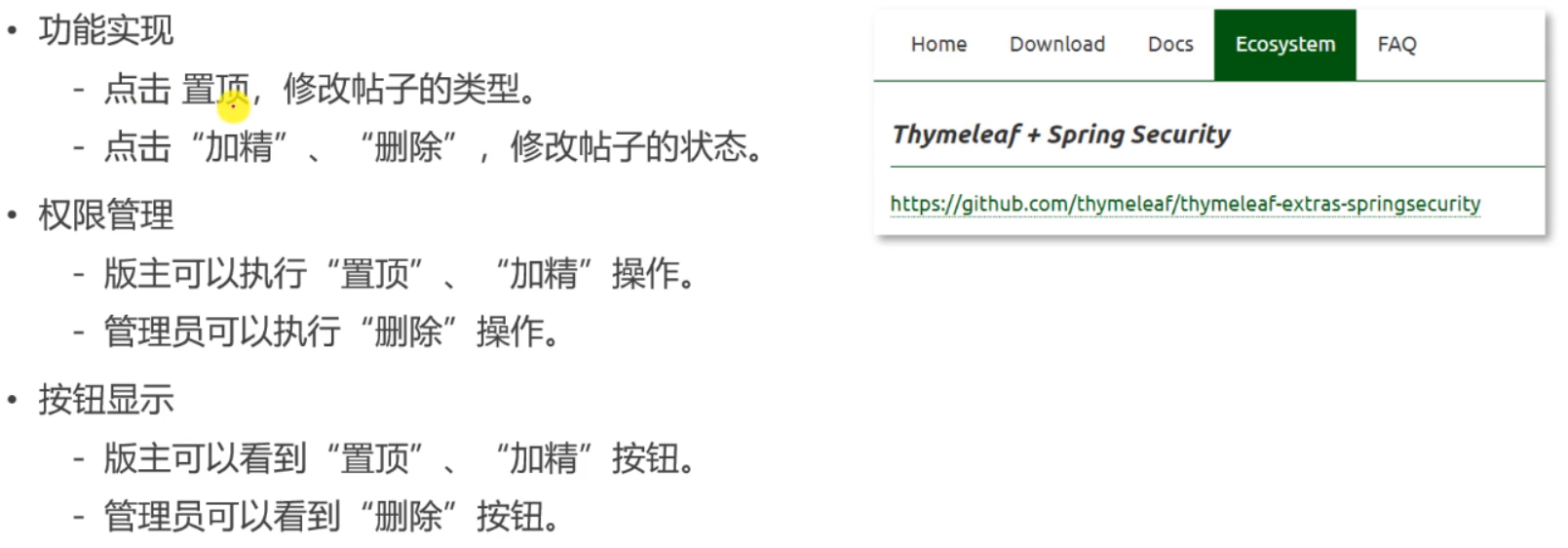 Write sql modification statements in the data layer.
Write sql modification statements in the data layer.
Asynchronous request, local refresh, so @ ResponseBody needs to be added
Synchronize the post to es, trigger the post event, and then return a prompt message
Set the post deletion event, and then consume the event in EventConsumer
//Consumption post deletion event (after deleting a post, the post in es is also deleted)
@KafkaListener(topics = TOPIC_DELETE)
public void handleDeleteMessage(ConsumerRecord record){
//Sent an empty message
if(record==null || record.value()==null){
logger.error("Send message is empty!");
return;
}
//Turn the json message into an object and specify the specific type corresponding to the string
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
//Turn to object and then judge
if(event==null){
logger.error("Message format error!");
return;
}
elasticsearchService.deleteDiscussPost(event.getEntityId());
}
In SecurityConfig, add permissions for configuration top setting, refinement and deletion (background processing)
Moderator: topping, refining
Administrators: deleting
.antMatchers(
"/discuss/top",
"/discuss/wonderful"
)
.hasAnyAuthority(
AUTHORITY_MODERATOR
)
.antMatchers(
"/discuss/delete"
)
.hasAnyAuthority(
AUTHORITY_ADMIN
)
Implement what functions can only be seen by the user with what permissions? (front end processing)
Pilot package, and then add a namespace to the corresponding page
<dependency>
<groupId>org.thymeleaf.extras</groupId>
<artifactId>thymeleaf-extras-springsecurity5</artifactId>
</dependency>
xmlns:sec="http://www.thymeleaf.org/extras/spring-security"
<button type="button" class="btn btn-danger btn-sm" id="topBtn"
th:disabled="${post.type==1}" sec:authorize="hasAnyAuthority('moderator')">Topping</button>
<button type="button" class="btn btn-danger btn-sm" id="wonderfulBtn"
th:disabled="${post.status==1}" sec:authorize="hasAnyAuthority('moderator')">Refining</button>
<button type="button" class="btn btn-danger btn-sm" id="deleteBtn"
th:disabled="${post.status==2}" sec:authorize="hasAnyAuthority('admin')">delete</button>
Advanced data types of Redis

Hyperlog: it can be used to count the number of visits to a website (once a user visits multiple times) and automatically remove duplicates
Bitmap: it can be used to count whether you work every day in a year (0, 1)
// Count the independent total of 200000 duplicate data
@Test
public void testHyperLogLog() {
String redisKey = "test:hll:01";
for (int i = 1; i <= 100000; i++) {
redisTemplate.opsForHyperLogLog().add(redisKey, i);
}
long size = redisTemplate.opsForHyperLogLog().size(redisKey);
System.out.println(size);
}
// A Boolean value that counts a set of data
@Test
public void testBitMap() {
String redisKey = "test:bm:02";
// record
redisTemplate.opsForValue().setBit(redisKey, 1, true);
redisTemplate.opsForValue().setBit(redisKey, 4, true);
redisTemplate.opsForValue().setBit(redisKey, 7, true);
// query
System.out.println(redisTemplate.opsForValue().getBit(redisKey, 0));
System.out.println(redisTemplate.opsForValue().getBit(redisKey, 1));
System.out.println(redisTemplate.opsForValue().getBit(redisKey, 2));
// Statistics
Object obj = redisTemplate.execute(new RedisCallback() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
return connection.bitCount(redisKey.getBytes());
}
});
System.out.println(obj);
}
// Count the Boolean values of the three groups of data, and perform OR operation on the three groups of data
String redisKey = "test:bm:or";
Object obj = redisTemplate.execute(new RedisCallback() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
connection.bitOp(RedisStringCommands.BitOperation.OR,
redisKey.getBytes(), redisKey2.getBytes(), redisKey3.getBytes(), redisKey4.getBytes());
return connection.bitCount(redisKey.getBytes());
}
});
Website data statistics
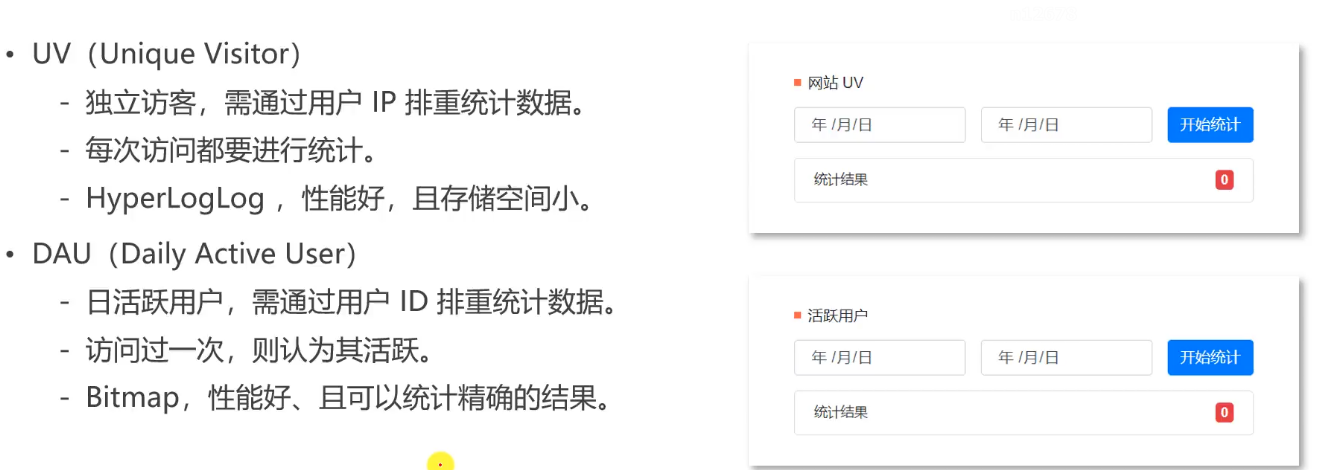
UV focuses on the number of visits, not whether to register or log in. Tourists also need to record, so IP statistics are used instead of user id. Each visit is recorded and then redone.
DAU counts active users. It uses user id statistics. userid is an integer and is used as an index. 1 means active and 0 means inactive. It also saves space.

Records are in days. You can consolidate the records of one week during query
There are two types of redis key s: one is for a single day, and the other is for a certain interval
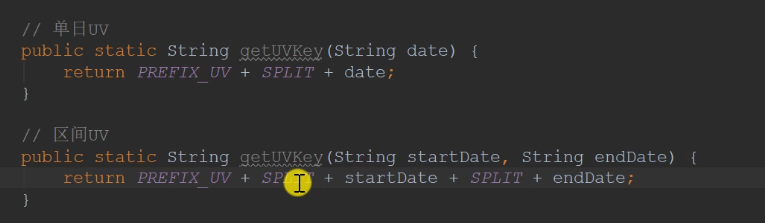
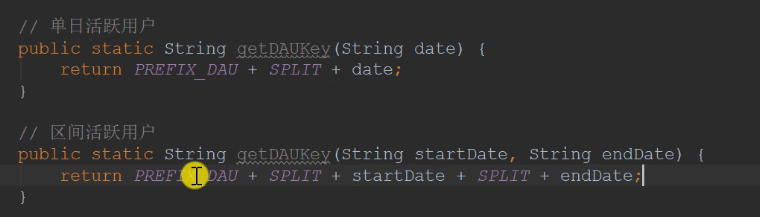
redis does not need to write the dao layer. Instead, it writes the service directly and calls the redisTemplate directly
service
@Service
public class DataService {
@Autowired
private RedisTemplate redisTemplate;
//format date
private SimpleDateFormat df=new SimpleDateFormat("yyyyMMdd");
//Statistical data (1. Recorded data 2. Can be queried)
/*
* Statistical UV
* */
//1. Takes the specified IP into account
public void recordUV(String ip){
//Get the key first
String redisKey = RedisKeyUtil.getUVKey(df.format(new Date()));
redisTemplate.opsForHyperLogLog().add(redisKey,ip);//Save into redis
}
//Counts UV s within the specified date range
public long calculateUV(Date start,Date end){
//First judge whether the date is empty
if(start==null || end==null){
throw new IllegalArgumentException("Parameter cannot be empty!");
}
//Merge the key s of each day in the range into a collection
List<String> keyList=new ArrayList<>();
//Use calendar to calculate the date
Calendar calendar=Calendar.getInstance();//Instantiate abstract class objects
calendar.setTime(start);
//Cycle only after time < = end
while (!calendar.getTime().after(end)){
//Get key
String key = RedisKeyUtil.getUVKey(df.format(calendar.getTime()));
//Add key to collection
keyList.add(key);
//calendar plus one day
calendar.add(Calendar.DATE,1);
}
//Merge these data and store the merged values
String redisKey = RedisKeyUtil.getUVKey(df.format(start), df.format(end));//Get the merged key
redisTemplate.opsForHyperLogLog().union(redisKey,keyList.toArray());//Merge and save to redis
//Returns the result of the statistics
return redisTemplate.opsForHyperLogLog().size(redisKey);
}
/*
* Statistical DAU
* */
//Statistics of dau on a single day
public void recordDAU(int userId){
//Get key
String rediskey = RedisKeyUtil.getDAUKey(df.format(new Date()));
//Save to redis
redisTemplate.opsForValue().setBit(rediskey,userId,true);
}
//Count the dau of a certain interval (if you log in one day in the interval, it will be active, so you need to use or operation)
public long calculateDAU(Date start,Date end){
//First judge whether the date is empty
if(start==null || end==null){
throw new IllegalArgumentException("Parameter cannot be empty!");
}
//Merge the key s of each day in the range into a collection
//bitmap operation requires arrays, so byte arrays are stored in the list set
List<byte[]> keyList=new ArrayList<>();
//Use calendar to calculate the date
Calendar calendar=Calendar.getInstance();//Instantiate abstract class objects
calendar.setTime(start);
//Cycle only after time < = end
while (!calendar.getTime().after(end)){
//Get key
String key = RedisKeyUtil.getDAUKey(df.format(calendar.getTime()));
//Add key to collection
keyList.add(key.getBytes());
//calendar plus one day
calendar.add(Calendar.DATE,1);
}
//Get merged key
String redisKey = RedisKeyUtil.getDAUKey(df.format(start), df.format(end));
//Store the merged or operation results in redis
return (long) redisTemplate.execute(new RedisCallback() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
connection.bitOp(RedisStringCommands.BitOperation.OR,
redisKey.getBytes(),keyList.toArray(new byte[0][0]));
return connection.bitCount(redisKey.getBytes());
}
});
}
}
The presentation layer is divided into two steps: recording and viewing. Each request should be recorded, so it should be implemented in the interceptor.
@Component
public class DataInterceptor implements HandlerInterceptor {
@Autowired
private DataService dataService;
@Autowired
private HostHolder hostHolder;
//Before the request is intercepted, only the data is recorded, so return true and let it continue to execute downward
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
//Statistics of UV in a single day
//Get ip through request
String ip = request.getRemoteHost();
dataService.recordUV(ip);//Call service statistics
//Count DAU on a single day
//Get the current user, and judge to log in before recording
User user = hostHolder.getUser();
if (user!=null){
dataService.recordDAU(user.getId());
}
return true;
}
}
Inject the interceptor to make it effective
registry.addInterceptor(dataInterceptor)
.excludePathPatterns("/**/*.css","/**/*.js","/**/*.png","/**/*.jpg","/**/*.jpeg");
controller
@Controller
public class DataController {
@Autowired
private DataService dataService;
//The method of opening the statistics page, get and post requests can be processed
@RequestMapping(path = "/data",method ={RequestMethod.GET,RequestMethod.POST} )
public String getDatePage(){
return "/site/admin/data";
}
//The page uploads the date string. Tell the server the format of the string, and he can help you convert it,
// Use annotation @ DateTimeFormat
@RequestMapping(path = "/data/uv",method = RequestMethod.POST)
public String getUV(@DateTimeFormat(pattern = "yyyy-MM-dd") Date start,
@DateTimeFormat(pattern = "yyyy-MM-dd")Date end, Model model){
long calculateUV = dataService.calculateUV(start, end);
model.addAttribute("uvResult",calculateUV);//Save statistical results to model
//Save the date of the form into the model to facilitate the page display after jumping
model.addAttribute("uvStartDate",start);
model.addAttribute("uvEndDate",end);
return "forward:/data";//Forwarding (this request can only complete part, and the following part is left to this request, that is, the above request)
}
//Statistical DAU
@RequestMapping(path = "/data/dau",method = RequestMethod.POST)
public String getDAU(@DateTimeFormat(pattern = "yyyy-MM-dd") Date start,
@DateTimeFormat(pattern = "yyyy-MM-dd")Date end, Model model){
long dau = dataService.calculateDAU(start, end);
model.addAttribute("dauResult",dau);//Save statistical results to model
//Save the date of the form into the model to facilitate the page display after jumping
model.addAttribute("dauStartDate",start);
model.addAttribute("dauEndDate",end);
return "forward:/data";//Forwarding (this request can only complete part, and the following part is left to this request, that is, the above request)
}
}
Adding this feature can only be accessed by administrators
.antMatchers(
"/discuss/delete",
"/data/**"
)
.hasAnyAuthority(
AUTHORITY_ADMIN
)
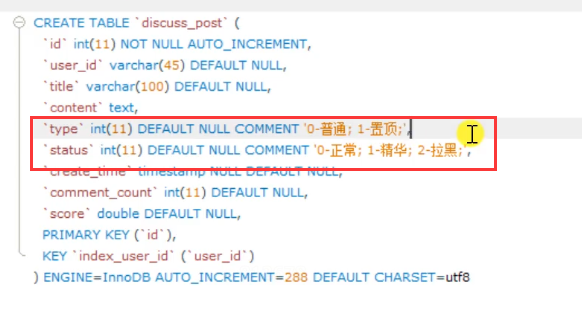
Entity is an entity that can comment on posts or comments on posts. (1 for posts, 2 for comments, 3 for users)
entityid, the specific target of a type.
targetid, reply to a comment (directional)
status, 0 indicates normal, 1 indicates deletion disabled
Task execution and scheduling

Some tasks are not started when we visit the server. For example, calculate the score of Posts every other hour and clean up the files stored on the server every half an hour.
Why is there a problem using jdk thread pool and Spring thread pool in distributed environment? Need to use distributed scheduled tasks?
Distributed (multiple servers, one cluster). The browser sends Nginx requests to the server. According to the policy, Nginx sends them to the server. The codes of the two servers are the same. There is no problem with ordinary codes, but for scheduled tasks, problems may occur when the two are executed at the same time.
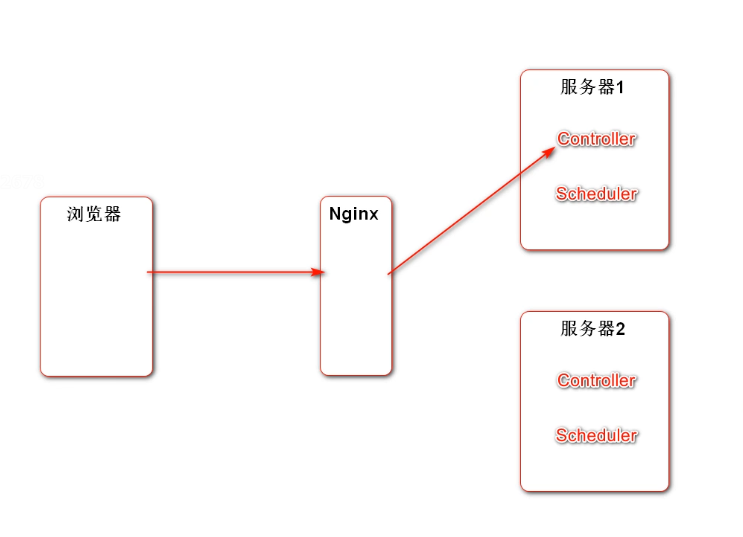
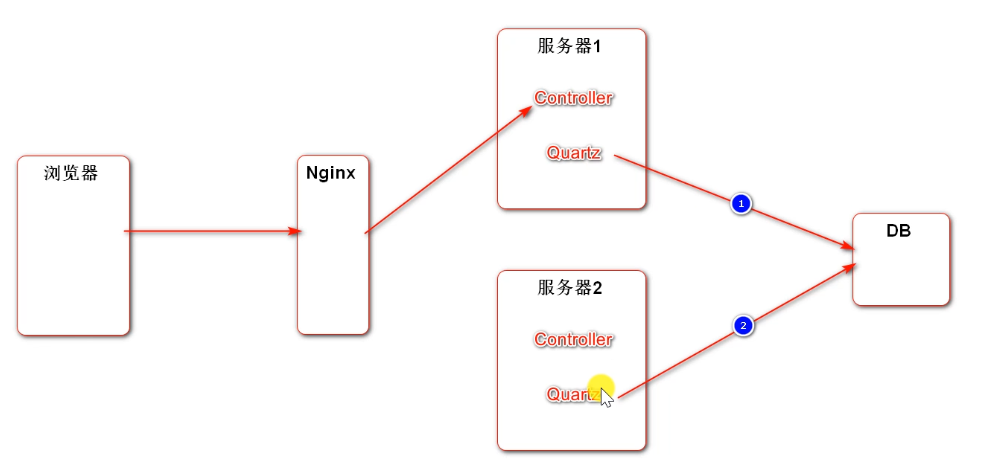
How to solve the problem for QuartZ?
jdk and spring timing task components are based on memory, and the configuration parameters are in memory, that is, server 1 and server 2 cannot share data. QuarZ's scheduled task parameters are saved in the database. Even if two servers execute scheduled tasks at the same time, they will grab the lock by locking the database. Only one thread can access them. When the next thread accesses them, first check whether the task parameters have been modified. If they have been modified, they will not do it.
When using the thread pool with spring, you first need to configure the following
#spring common thread pool configuration spring.task.execution.pool.core-size=5 spring.task.execution.pool.max-size=15 spring.task.execution.pool.queue-capacity=100 #Thread pool configuration for spring scheduled tasks spring.task.scheduling.pool.size=5
In addition, you also need a configuration class with relevant annotations. The configuration class can be executed regularly and called asynchronously
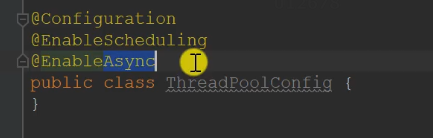
How long the method is executed after being called and how often it is executed.

As long as there is a program running, it will be executed.
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class ThreadPoolTests {
private static final Logger logger = LoggerFactory.getLogger(ThreadPoolTests.class);
// JDK common thread pool
private ExecutorService executorService = Executors.newFixedThreadPool(5);
// JDK thread pool that can execute scheduled tasks
private ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
// Spring common thread pool
@Autowired
private ThreadPoolTaskExecutor taskExecutor;
// Spring thread pool for performing scheduled tasks
@Autowired
private ThreadPoolTaskScheduler taskScheduler;
@Autowired
private AlphaService alphaService;
private void sleep(long m) {
try {
Thread.sleep(m);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 1.JDK common thread pool
@Test
public void testExecutorService() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ExecutorService");
}
};
for (int i = 0; i < 10; i++) {
executorService.submit(task);
}
sleep(10000);
}
// 2.JDK timed task thread pool
@Test
public void testScheduledExecutorService() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ScheduledExecutorService");
}
};
scheduledExecutorService.scheduleAtFixedRate(task, 10000, 1000, TimeUnit.MILLISECONDS);
sleep(30000);
}
// 3.Spring common thread pool
@Test
public void testThreadPoolTaskExecutor() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ThreadPoolTaskExecutor");
}
};
for (int i = 0; i < 10; i++) {
taskExecutor.submit(task);
}
sleep(10000);
}
// 4.Spring timed task thread pool
@Test
public void testThreadPoolTaskScheduler() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ThreadPoolTaskScheduler");
}
};
Date startTime = new Date(System.currentTimeMillis() + 10000);
taskScheduler.scheduleAtFixedRate(task, startTime, 1000);
sleep(30000);
}
// 5.Spring common thread pool (Simplified)
@Test
public void testThreadPoolTaskExecutorSimple() {
for (int i = 0; i < 10; i++) {
alphaService.execute1();
}
sleep(10000);
}
// 6.Spring timed task thread pool (Simplified)
@Test
public void testThreadPoolTaskSchedulerSimple() {
sleep(30000);
}
}
Using QuartZ
You need to initialize the table first
2. Guide Package
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
3,
# QuartzProperties puts the configuration in the database spring.quartz.job-store-type=jdbc #Scheduler name spring.quartz.scheduler-name=communityScheduler #Automatic generation of scheduler id spring.quartz.properties.org.quartz.scheduler.instanceId=AUTO spring.quartz.properties.org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX spring.quartz.properties.org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate #Cluster or not spring.quartz.properties.org.quartz.jobStore.isClustered=true spring.quartz.properties.org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool spring.quartz.properties.org.quartz.threadPool.threadCount=5
First, define a task (the job interface execute declares what I want to do), what needs to be configured (JobDetail name, group to configure the job) (Trigger trigger, when and how often the job runs), initialize the read configuration to the database, and then directly access the database to read the configuration.
BeanFactory is the top-level interface of the container,
Factorybeans simplify the instantiation of beans:
1. Encapsulate the instantiation process of Bean through FactoryBean.
2. Assemble the FactoryBean into the Spring container.
3. Inject factorybeans into other beans.
4. The Bean gets the object instance managed by the FactoryBean
For example:
//It is only useful for the first time. Read the configuration into the database, and then read it directly from the database
@Configuration
public class QuartzConfig {
@Bean //Assemble JobDetailFactoryBean into container
public JobDetailFactoryBean alphaJobDetail(){
return null;
}
@Bean //I need JobDetail for the parameters here. I pass in the method name of the bean above. Here, I get the object managed by JobDetailFactoryBean
public SimpleTriggerFactoryBean alphaTrigger(JobDetail alphaJobDetail){
return null;
}
}
use case
1,
public class AlphaJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println(Thread.currentThread().getName()+":execute a quartz job.");
}
}
2,
//It is only useful for the first time. Read the configuration into the database, and then read it directly from the database
@Configuration
public class QuartzConfig {
//Configure JobDetail
@Bean //Assemble JobDetailFactoryBean into container
public JobDetailFactoryBean alphaJobDetail(){
JobDetailFactoryBean factoryBean=new JobDetailFactoryBean();
factoryBean.setJobClass(AlphaJob.class);
factoryBean.setName("alphajob");
factoryBean.setGroup("alphaJobGroup");
factoryBean.setDurability(true);//The task is not running, the trigger is gone, and there is no need to delete it. Keep it
factoryBean.setRequestsRecovery(true);//Is the task recoverable
return factoryBean;
}
//Configure trigger
@Bean //I need JobDetail for the parameters here. I pass in the method name of the bean above. Here, I get the object managed by JobDetailFactoryBean
public SimpleTriggerFactoryBean alphaTrigger(JobDetail alphaJobDetail){
SimpleTriggerFactoryBean factoryBean=new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(alphaJobDetail);//The parameter name is consistent with the bean name
factoryBean.setName("alphaTrigger");
factoryBean.setGroup("alphsTriggerGroup");
factoryBean.setRepeatInterval(3000);//Execution frequency
factoryBean.setJobDataMap(new JobDataMap());//Specify which object to save the state
return factoryBean;
}
}
After startup, the configuration will be transferred to the database every three seconds

Delete task
@Test
public void testDeleteJob(){
boolean b = false;
try {
b = scheduler.deleteJob(new JobKey("alphajob", "alphaJobGroup"));
System.out.println(b);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
Hot post ranking

After comments, likes and refinements, it is calculated immediately. The efficiency is relatively low. Start the scheduled task to calculate, and then display it according to the score.
Idea:
Comments, likes and refinements are not calculated immediately, but are thrown into the redis cache. The changed posts are calculated regularly, and the unchanged posts are not calculated
The score is also calculated after the newly added post and saved in redis
Put the top directly on the top, so you don't have to calculate the score.
Also calculate at the refinement section and put the post in redis

Comment: comment on the post before putting it in redis
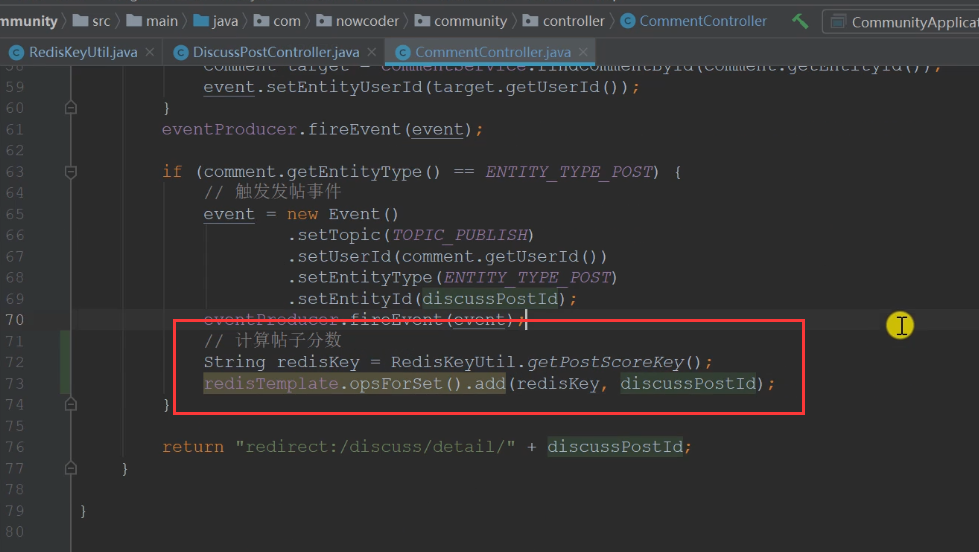
Like: first judge whether you like the post, and then put the post in redis
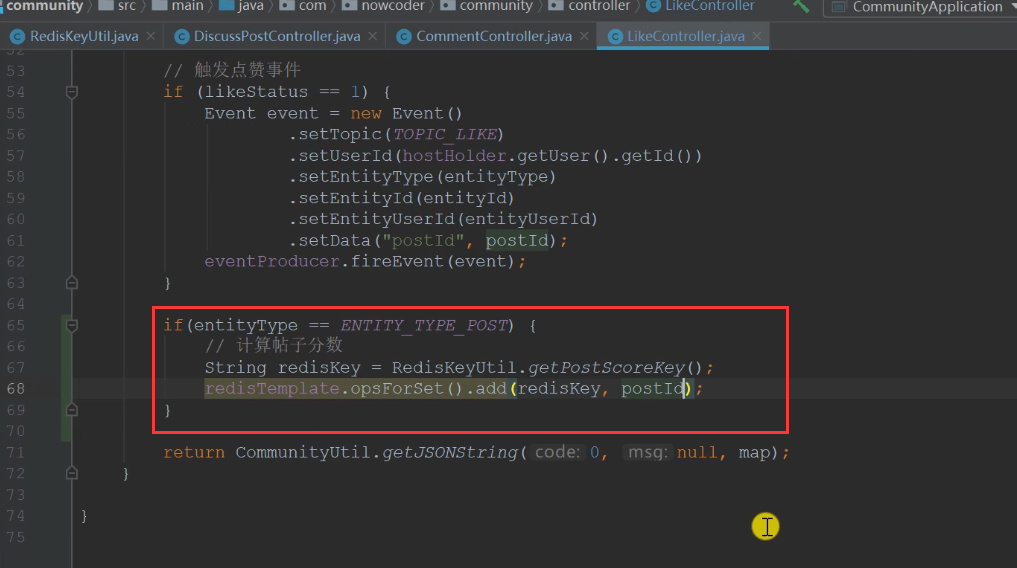
Write scheduled task (post refresh)
1. Job (log)
Check the posts and synchronize the calculated posts to the es search engine
Declare constants (only need to be initialized once, so they are initialized in the static block) to facilitate calculation
private static final Date epoch;
static {
try {
epoch=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2014-08-01 00:00:00");
} catch (ParseException e) {
throw new RuntimeException("Failed to initialize Niuke era!",e);
}
}
public class PostScoreRefreshJob implements Job, CommunityConstant{
private static final Logger logger= LoggerFactory.getLogger(PostScoreRefreshJob.class);
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private DiscussPostService discussPostService;
@Autowired
private LikeService likeService;
@Autowired
private ElasticsearchService elasticsearchService;
private static final Date epoch;
static {
try {
epoch=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2014-08-01 00:00:00");
} catch (ParseException e) {
throw new RuntimeException("Failed to initialize Niuke era!",e);
}
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
//Get the value from redis (get the key first). Each key needs to be calculated and operated repeatedly, so use BoundSetOperation
String redisKey = RedisKeyUtil.getPostScoreKey();
BoundSetOperations operations=redisTemplate.boundSetOps(redisKey);
//First judge whether there is data in the cache, and do not operate if there is no change
if(operations.size()==0){
logger.info("[Task cancellation] There are no posts to refresh!");
return;
}
//Use logging time intermediate process
logger.info("[Task start] Refreshing post scores: "+operations.size());
while (operations.size()>0){//As long as there is data in redis
//Pop up a value in the collection
this.refresh((Integer)operations.pop());
}
}
private void refresh(int postId) {
//Check out the post first
DiscussPost post = discussPostService.findDiscussDetail(postId);
//Null value judgment (the post was liked by people, but later deleted by management)
if(post==null){
logger.error("Post does not exist: id= "+ postId);//Logging error prompt
return;
}
//Calculate the post score (refinement-1, number of comments, number of likes)
boolean wonderful = post.getStatus() == 1;
int commentCount = post.getCommentCount();
long likeCount = likeService.findEntityLikeCount(ENTITY_TYPE_POST, postId);
//Weight first
double w=(wonderful? 75 : 0) + commentCount*10 + likeCount * 2;
//Score = post weight + distance days
//In order not to be negative, take the maximum value between the weight and 1. Convert the milliseconds obtained from the time into days
double score=Math.log10(Math.max(w,1)+
(post.getCreateTime().getTime()-epoch.getTime())/(1000 * 3600 * 24));
//Update post scores
discussPostService.updateDiscussScore(postId, score);
//Synchronously search the data of the corresponding post (reset the score of the post before saving to es)
post.setScore(score);
elasticsearchService.saveDiscussPost(post);
}
}
After writing the scheduled task, you have to configure it. Don't forget
//Refresh post score task
@Bean //Assemble JobDetailFactoryBean into container
public JobDetailFactoryBean postScoreRefreshJobDetail(){
JobDetailFactoryBean factoryBean=new JobDetailFactoryBean();
factoryBean.setJobClass(PostScoreRefreshJob.class);
factoryBean.setName("postScoreRefreshJob");
factoryBean.setGroup("communityJobGroup");
factoryBean.setDurability(true);//The task is not running, the trigger is gone, and there is no need to delete it. Keep it
factoryBean.setRequestsRecovery(true);//Is the task recoverable
return factoryBean;
}
@Bean
public SimpleTriggerFactoryBean postScoreRefreshTrigger(JobDetail postScoreRefreshJobDetail){
SimpleTriggerFactoryBean factoryBean=new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(postScoreRefreshJobDetail);//The parameter name is consistent with the bean name
factoryBean.setName("postScoreRefreshTrigger");
factoryBean.setGroup("communityJobGroup");
factoryBean.setRepeatInterval(1000 * 60 *5);//Execution frequency
factoryBean.setJobDataMap(new JobDataMap());//Specify which object to save the state
return factoryBean;
}
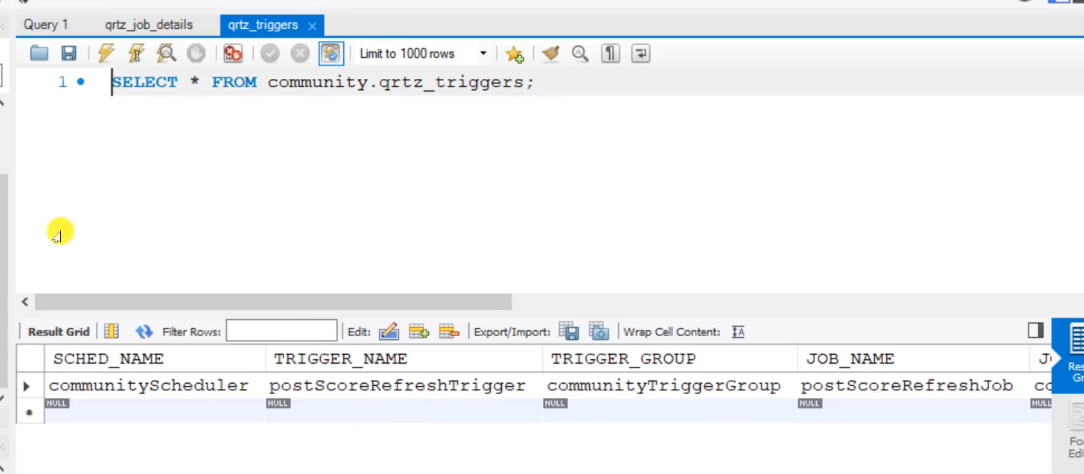
Update every five minutes
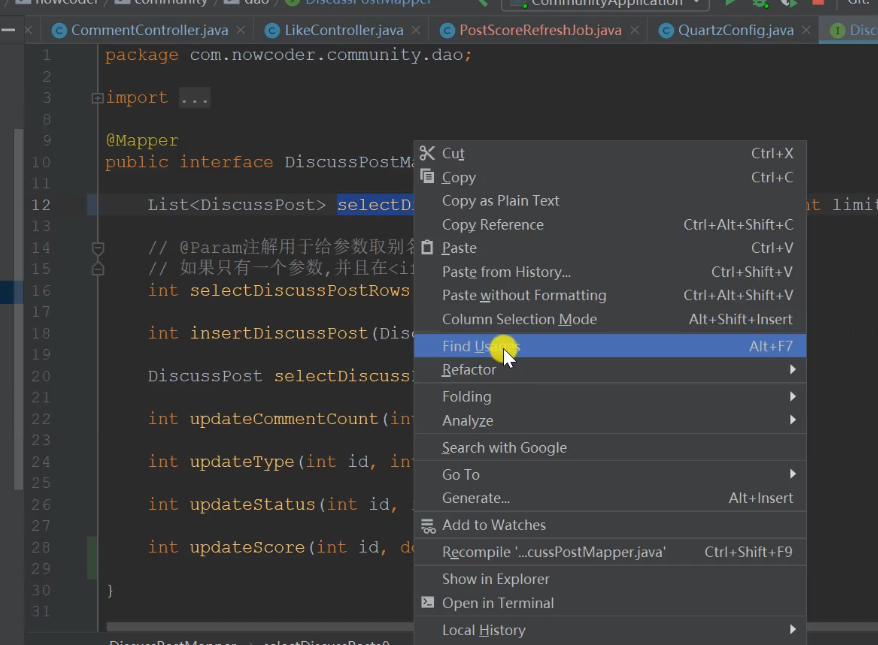
mapper to find posts before refactoring
//Paging display of search posts (userId is a dynamic requirement, 0 means no splicing, and the rest are spliced) List<DiscussPost> selectDiscussPosts(int userId,int offset,int limit,int orderMode);
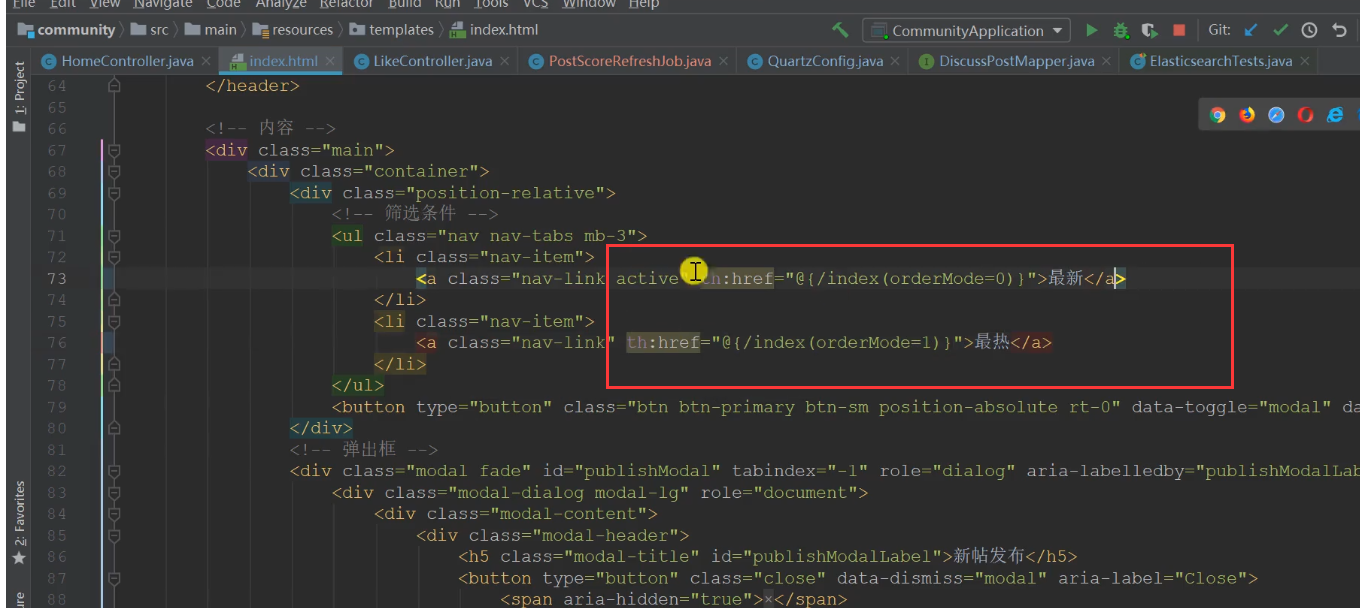
<!--orderMode A value of 0 indicates normal display, and a value of 1 indicates ranking according to heat scores, first the top, then the score, and then the time-->
<select id="selectDiscussPosts" resultType="DiscussPost">
select <include refid="selectFields"></include>
from discuss_post
where status!=2
<if test="userId!=0">
and user_id=#{userId}
</if>
<if test="orderMode==0">
order by type desc,create_time desc
</if>
<if test="orderMode==1">
order by type desc,score desc, create_time desc
</if>
limit #{offset},#{limit}
</select>

Student growth chart

Commands: 1. Generate pdf from the content of the template; 2. Generate pictures from the web page
wkhtmltopdf https://www.nowcoder.com
C:\nowcoder_community\data\wk-pdfs/1.pdf
wkhtmltoimage https://www.nowcoder.com C:\nowcoder_community\data\wk-images/1.png
Compress pictures 75%
wkhtmltoimage --quality 75 https://www.nowcoder.com C:\nowcoder_community\data\wk-images/2.png
Using growth graph in java
package com.nowcoder.community;
import java.io.IOException;
public class WKTests {
public static void main(String[] args) {
String cmd="C:/user/soft/wk/wkhtmltopdf/bin/wkhtmltoimage --quality 75 https://www.nowcoder.com C:/nowcoder_community/data/wk-images/3.png";
try {
Runtime.getRuntime().exec(cmd);
System.out.println("ok!");
} catch (IOException e) {
e.printStackTrace();
}
}
}
The operating system executes commands and programs concurrently and asynchronously.
Configure the path and the file path where the picture is saved
#wk wk.image.command=C:/user/soft/wk/wkhtmltopdf/bin/wkhtmltoimage wk.image.storage=C:/nowcoder_community/data/wk-images
Verify whether the path exists and whether the file can be created automatically
Delete the previously created folder first to test whether it can succeed.
Create a directory when the service starts.
When the server starts, instantiate the configuration class first, automatically call @ PostConstruct and initialize it once
@Configuration
public class WKConfig {
private static final Logger logger= LoggerFactory.getLogger(WKConfig.class);
//Injection path
@Value("${wk.image.storage}")
private String wkImageStorage;
@PostConstruct
public void init(){
//Create wk picture directory
File file=new File(wkImageStorage);
if(!file.exists()){
file.mkdir();
logger.info("establish wk Picture Directory:" +wkImageStorage);
}
}
}
Handle the front-end request (generate a picture, generate a request to allow you to access the picture)
It takes a long time to generate pictures. The asynchronous method is adopted. The event can be thrown to Kafka without waiting for it to process all the time..
Inject domain name, project name and image storage location
//Consumption sharing event
@KafkaListener(topics = TOPIC_SHARE)
public void handleShareMessage(ConsumerRecord record){
//Sent an empty message
if(record==null || record.value()==null){
logger.error("Send message is empty!");
return;
}
//Turn the json message into an object and specify the specific type corresponding to the string
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
//Turn to object and then judge
if(event==null){
logger.error("Message format error!");
return;
}
//Get htmlUrl, file name, suffix
String htmlUrl = (String) event.getData().get("htmlUrl");
String fileName = (String) event.getData().get("fileName");
String suffix = (String) event.getData().get("suffix");
//Spell command
String cmd= wkImageCommand + " --quality 75 "
+htmlUrl+" "+wkImageStorage +"/" +fileName +suffix;
//Execute the command, and log the success and failure
try {
Runtime.getRuntime().exec(cmd);
logger.info("Student growth chart success:"+cmd);
} catch (IOException e) {
e.printStackTrace();
logger.error("Failed to generate growth chart:"+ e);
}
}
@Controller
public class ShareController implements CommunityConstant {
private static final Logger logger= LoggerFactory.getLogger(ShareController.class);
@Autowired
private EventProducer eventProducer;
@Value("${community.path.domain}")
private String domain;
@Value("${server.servlet.context-path}")
private String contextPath;
@Value("${wk.image.storage}")
private String wkImageStorage;
//Request for sharing (return json asynchronously and pass the function path to be shared)
@RequestMapping(path = "/share",method = RequestMethod.GET)
@ResponseBody
public String share(String htmlUrl){
//Randomly generated picture file name
String fileName = CommunityUtil.generateUUID();
//Asynchronous generation of growth graph construction events (topic: sharing, carrying parameters to save in map, htmlUrl, file name, suffix,)
Event event=new Event();
event.setTopic(TOPIC_SHARE)
.setData("htmlUrl",htmlUrl)
.setData("fileName",fileName)
.setData("suffix",".png");
//Trigger events (handle asynchronous events and don't forget consumption events)
eventProducer.fireEvent(event);
//Return the access path to access the picture to the client
//Save path to map
Map<String,Object> map=new HashMap<>();
map.put("shareUrl",domain+contextPath +"/share/image/"+fileName);
return CommunityUtil.getJSIONString(0,null,map);
}
//Get long graph
//Return an image and process it with response
@RequestMapping(path = "/share/image/{fileName}",method = RequestMethod.GET)
public void getShareImage(@PathVariable("fileName")String fileName, HttpServletResponse response){
//Judge the null value of the parameter first
if(StringUtils.isBlank(fileName)){
throw new IllegalArgumentException("File name cannot be empty!");
}
//Declare what is output (picture / format)
response.setContentType("image/png");
//Instantiation file, image storage path
File file = new File(wkImageStorage + "/" + fileName + ".png");
// The picture is a byte, so get the output byte stream
try {
OutputStream os=response.getOutputStream();//Output is to write to other files
FileInputStream fis = new FileInputStream(file);//To enter is to go in and read
//Output while reading files (read buffer, cursor)
byte[] buffer=new byte[1024];
int b=0;
while ((b=fis.read(buffer))!=-1){
os.write(buffer,0,b);
}
} catch (IOException e) {
logger.error("Failed to get long graph: "+e.getMessage());
}
}
}

Upload files to ECS

1. Guide Package
2. Configure key, bucket name and corresponding url
3. Inject the information configured in the configuration file, discard the upload and xx uploaded by the avatar
4. Write code in setting. When successful, return json string, code: 0. As long as this is not returned, it is considered a failure.
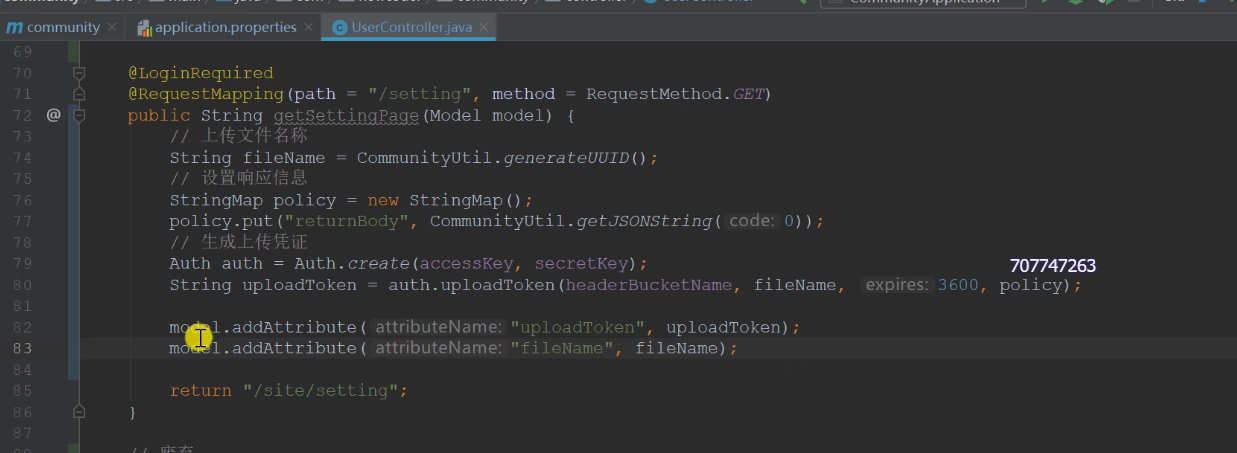
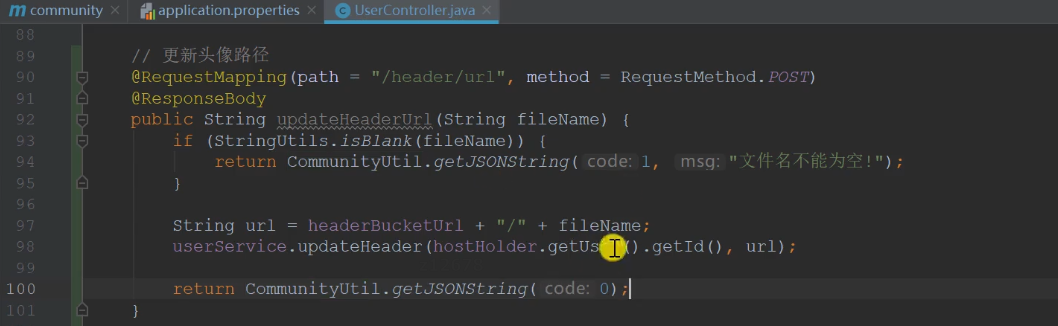
After the new method is returned successfully, it will be added asynchronously under the url update of the user table
When updating data, you need to enter the data, so it is post, and asynchronous, so it is @ ResponseBody
//First judge the null value of the parameter
//Splice url (url of space + file name)
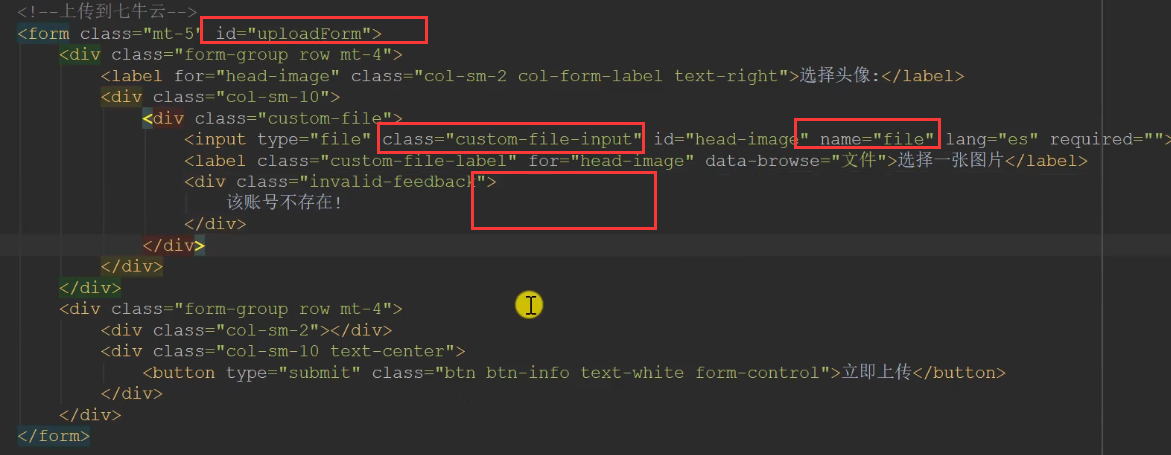
Find the form setting and note out the previous,
Asynchronous upload, get id
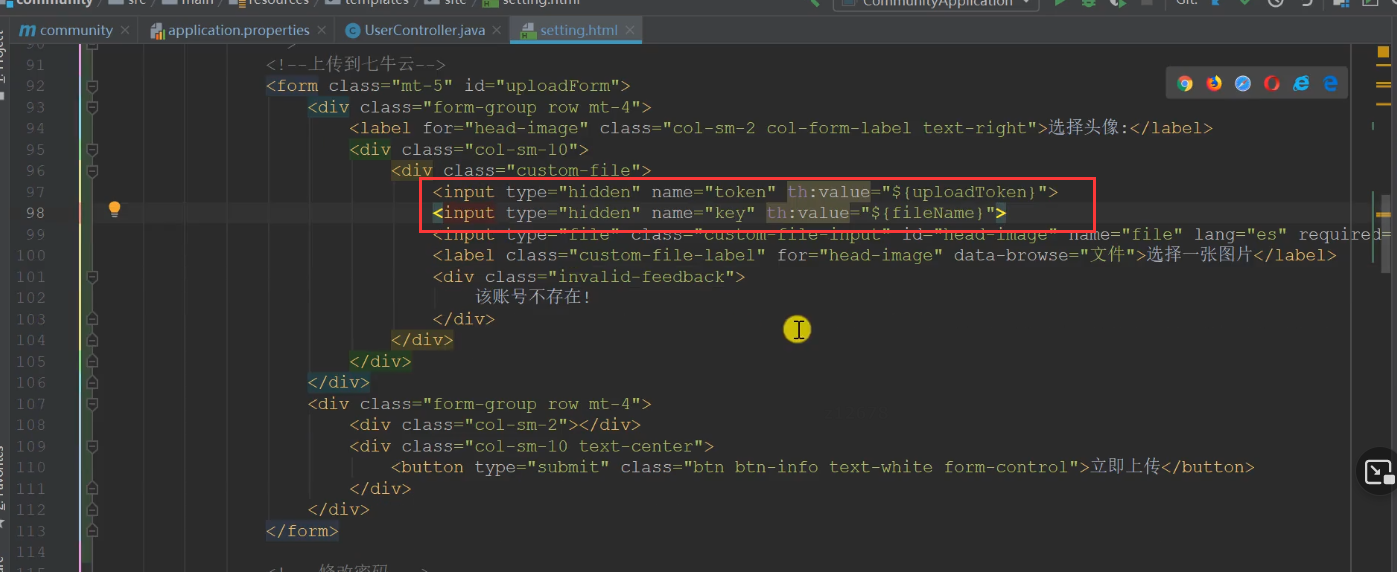
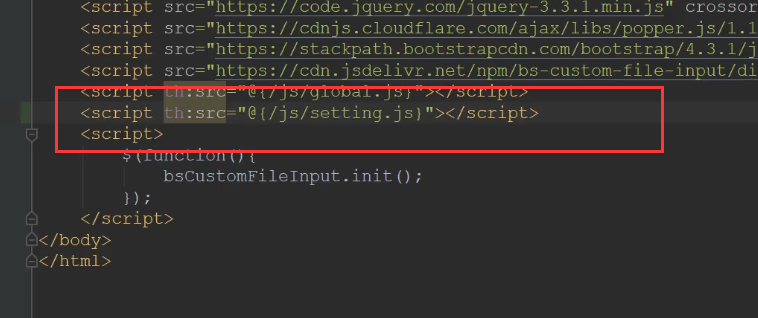
Click submit to trigger the form submission event. The return false event is here. Therefore, it will not go down because there is no action,
Do not convert the contents of the form into strings. If jquery is not allowed to set the upload type, the browser will configure it automatically.
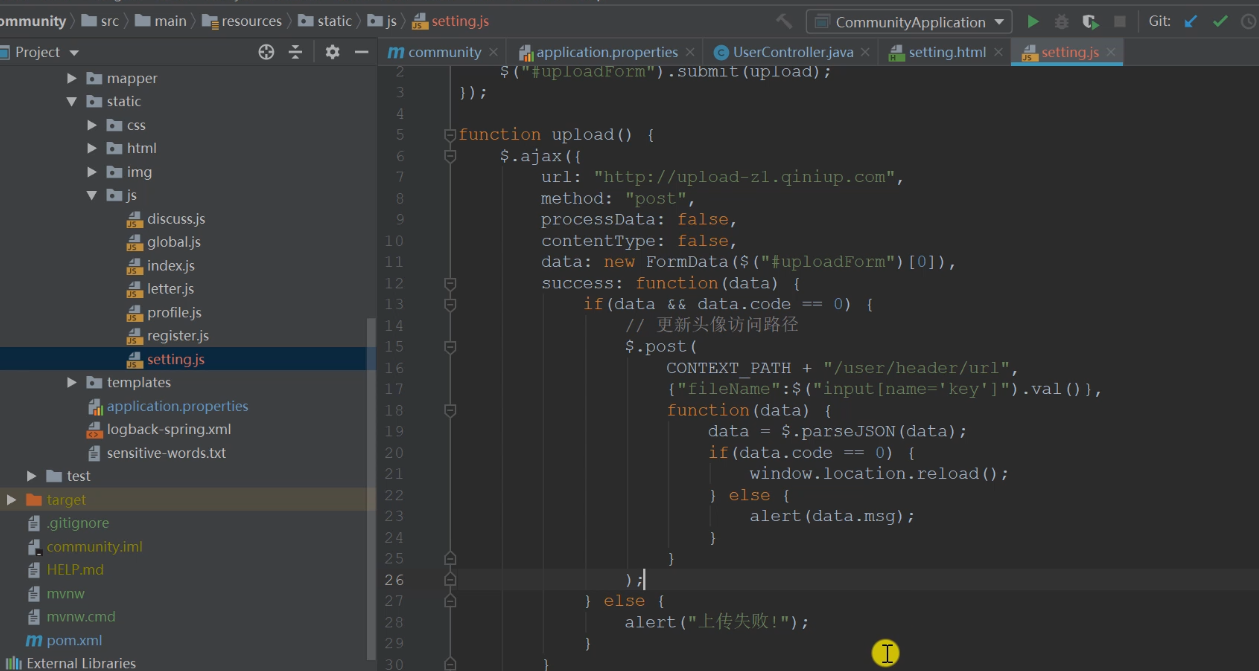
Asynchronously update the avatar path and get the file name from the form
Optimize website performance

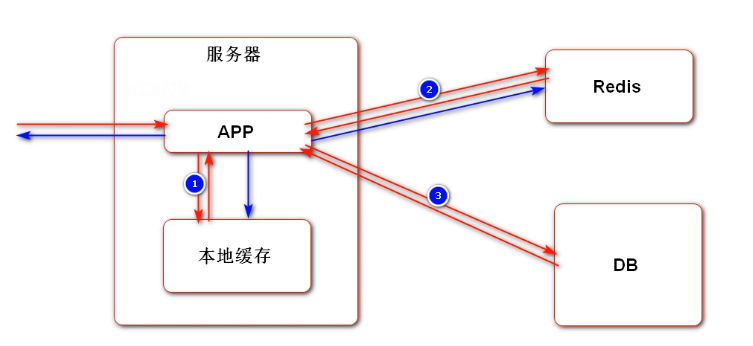
Two level cache,
The L1 cache is the cache of the server and exists in local memory. If there is no in the local cache, access the DB and update it to the cache.
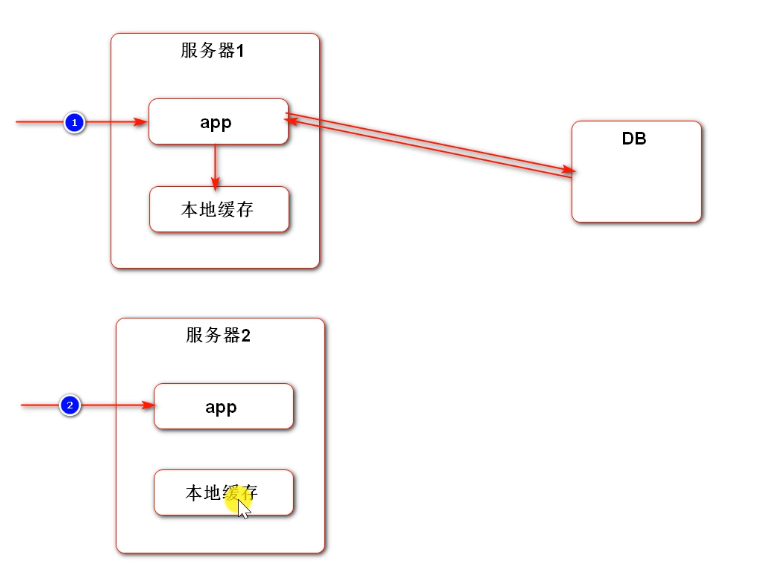
The user's first access falls on server 1 and generates a user information cache (possibly whether to log in or not). If the user accesses server 2 for the second time and there is no user information, he will not access the DB, but directly think that you have not logged in, so it is inappropriate to cache the user related information in the local cache.
However, the local cache can put some popular posts. The first time you visit server 1, you can go to the database and synchronize to the cache. If the second request falls on server 2, perform the same operation as server 1. No matter which server the next request falls on, there will be a cache.
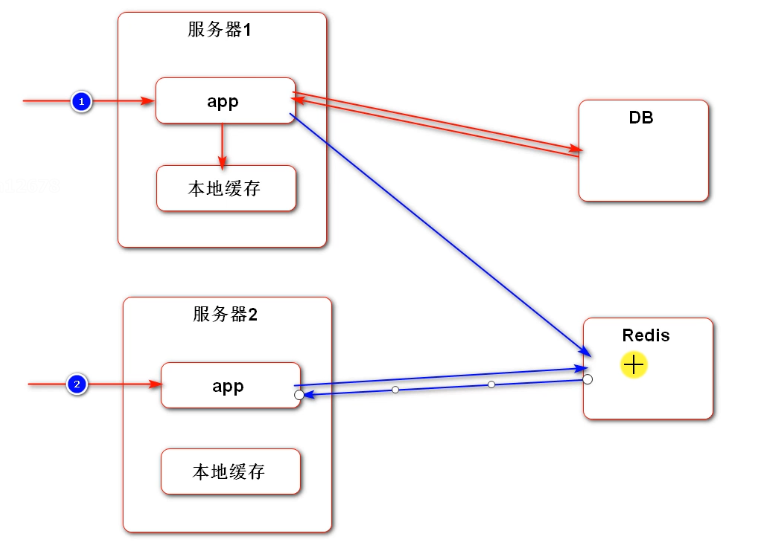
Redis cache can store data associated with users. When the application sees that there is no data in redis, it accesses the DB and caches it in redis. The next time the user accesses server 2, he / she also goes to redis to see if there is any data. If there is, he / she will return directly.
Redis can cross servers. Distributed cache. Local cache is faster than redis cache.
Use two-level cache:
Access the local cache first, then the redis cache, and then the DB. Then update the data to the local cache and redis. We need to set the expiration time of the cache to improve the access speed.
The cache has a certain elimination strategy based on time and size,
Optimize the sequential cache of popular post list (the frequency of data change is low, and the score is updated only after a period of time, which can ensure that it remains unchanged for a period of time),
The local cache uses Caffeine and spring integration. It uses a cache manager to manage all caches (Unified elimination and expiration time). Each cache business is different and the cache time is different. Spring is not required to integrate.
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.7.0</version>
</dependency>
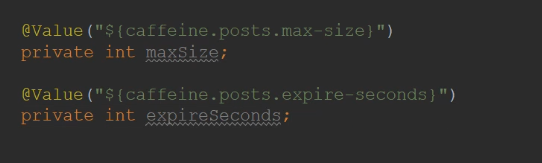
Setting parameters, user-defined parameters, cache post list, how many posts can be stored in the cache (15 pages), cache expiration time (3 minutes),
Active elimination (when the post data changes, clear the cache). Automatic elimination (timing) caches one page of data. If it is inappropriate to eliminate the whole page of data due to the change of a post on a page, active elimination is not set.

Optimize business method (service) DiscussPostService
Initialize the logger and inject the parameters just configured
The total number of cached posts. There are many calls
Using LoadingCache, a list of cached posts and the total number of cached posts. Declare first, after initialization. The cache stores values according to key value.

The cache only needs to be initialized when the service is started or called for the first time. Only once.
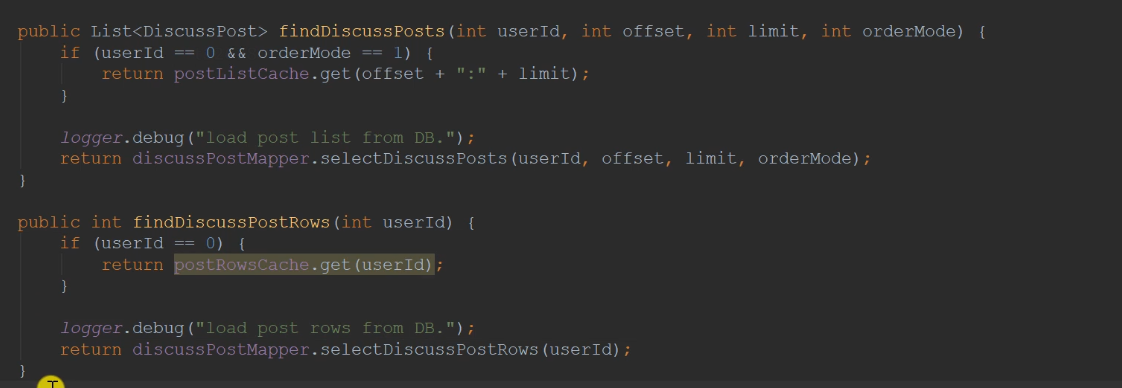
Only popular posts are cached, and only the home page is cached. The user on the home page does not log in. The userId is 0. A page of data is cached. The key is related to offset and limit.
The cached is the post list. When users query their posts, they pass in the userId. At this time, they do not go through the cache. Only when userId is 0 can the cache be left. Because there must be a key, use userId as the key, although it must be null.
Initialize cache
Maximum number of pages, expiration time, make the configuration effective, build (anonymous Implementation), how to query the database to get data (how to get the cache)
@Value("${caffeine.posts.max-size}")
private int maxSize;
@Value("${caffeine.posts.expire-seconds}")
private int expireSeconds;
//Post list cache
private LoadingCache<String,List<DiscussPost>> postListCache;
//Total number of Posts cache
private LoadingCache<Integer,Integer> postRowsCache;
public List<DiscussPost> findDiscussPosts(int userId,int offset,int limit,int orderMode){
//Only popular posts are cached, and only the home page is cached. The user on the home page does not log in. The userId is 0. A page of data is cached. The key is related to offset and limit.
if(userId==0 && orderMode==1){
return postListCache.get(offset+":"+limit);
}
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(userId,offset,limit,orderMode);
}
public int findDiscussPostRows(int userId){
//The cached is the post list. When users query their posts, they pass in the userId. At this time, they do not go through the cache. Only when userId is 0 can the cache be left.
if(userId==0){
return postRowsCache.get(userId);
}
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPostRows(userId);
}
//Initialize popular posts and total number of Posts cache
@PostConstruct
public void init(){
//Initialize post list cache
postListCache= Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build(new CacheLoader<String, List<DiscussPost>>() {
@Nullable
@Override
public List<DiscussPost> load(@NonNull String key) throws Exception {
if(key==null || key.length()==0){
throw new IllegalArgumentException("Parameter error!");
}
//Parse data
String[] params = key.split(":");
//Judge and analyze the data (whether two are obtained by cutting)
if(params==null || params.length!=2){
throw new IllegalArgumentException("Parameter error!");
}
//With parameters, check the data (CACHE)
int offset = Integer.valueOf(params[0]);
int limit = Integer.valueOf(params[1]);
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(0,offset,limit,1);
}
});
//Initialize the total number of Posts cache
postRowsCache=Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds,TimeUnit.SECONDS)
.build(new CacheLoader<Integer, Integer>() {
@Nullable
@Override
public Integer load(@NonNull Integer key) throws Exception {
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPostRows(key);
}
});
}
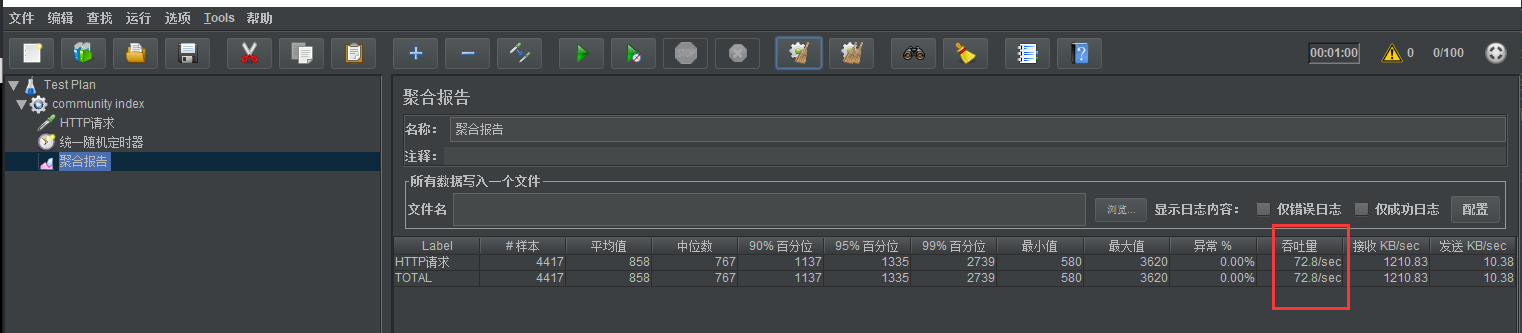
Fill it out first and conduct pressure test for 100 requests
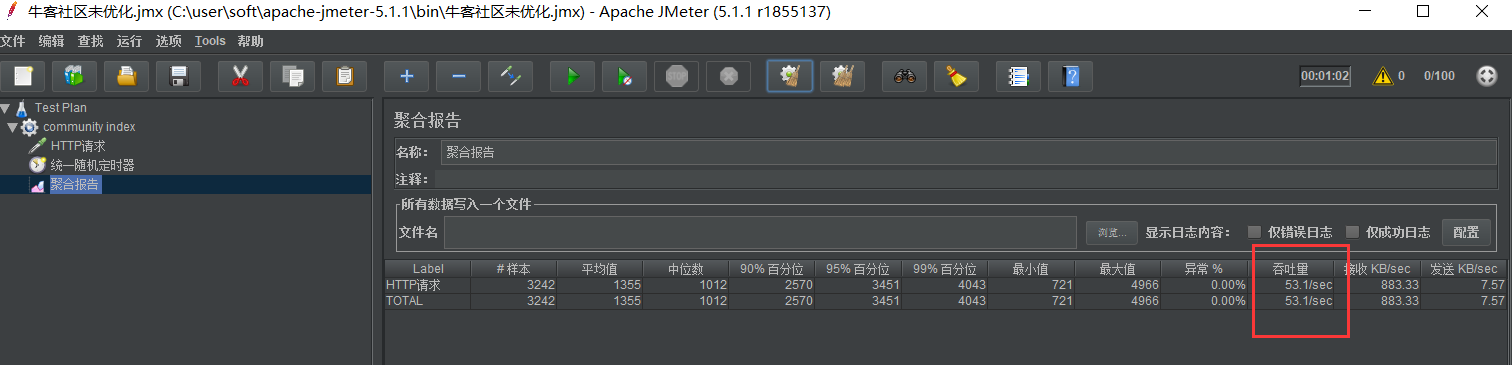
After optimization: about 1.5 times the original